
基于欠定盲源分离理论与深度学习的声音样本集获取与分类方法
2020-08-05 13:36律方成潘亦睿郭佳熠赵晓宇耿江海
华北电力大学学报(自然科学版) 2020年4期
律方成, 潘亦睿, 郭佳熠, 赵晓宇, 耿江海
(1.华北电力大学 新能源电力系统国家重点实验室,北京 102206; 2.华北电力大学 河北省输变电设备安全防御重点实验室,河北 保定 071003; 3.中国电力科学研究院有限公司,北京 100192)
0 引 言
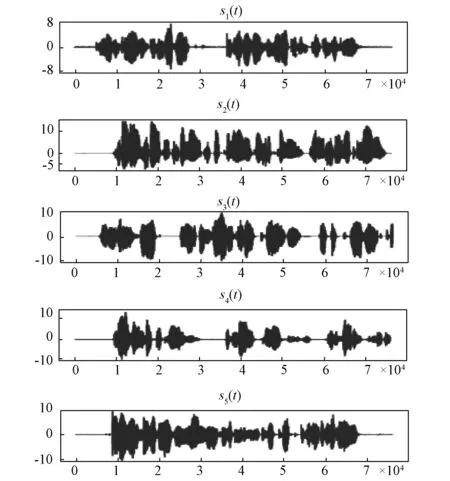
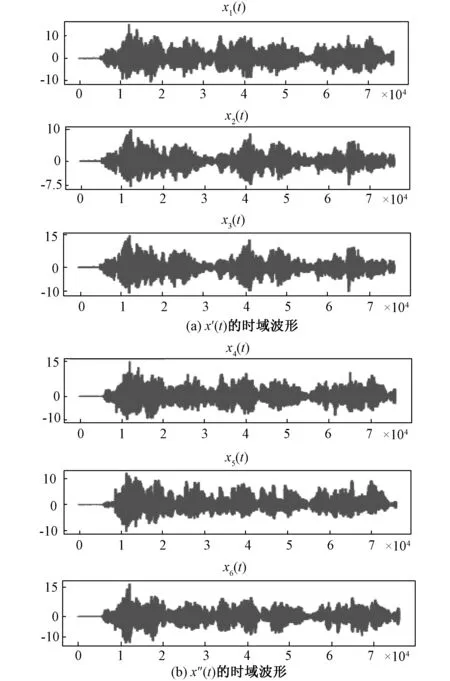
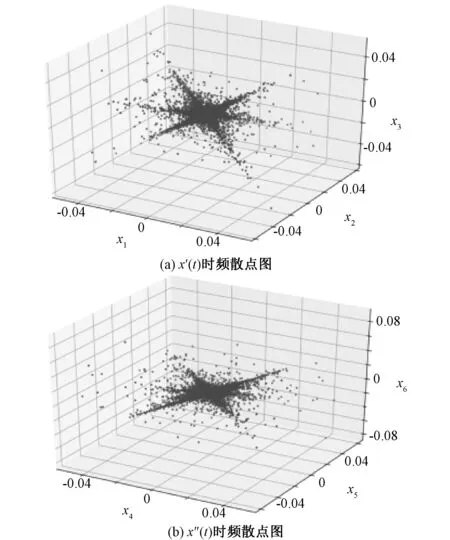
随着工业水平的不断提高,工业噪声问题日益严重,噪声污染和治理迫在眉睫。进行噪声治理的前提是对噪声进行分类,例如城市噪声需要确定其在不同地点的分布和种类,有利于对其治理。盲源分离(Blind source separation algorithm,BSS)作为近些年迅速发展的信号分离技术,在声源识别、信号处理等领域的使用已成为噪声治理领域发展的重要手段[1-2]。盲源分离算法能够在源信号数量和传输过程未知的情况下,仅依靠观测信号恢复源信号的过程。通过对比观测信号数量(M)和源信号(N)的数目可以把盲源分离算法分为三类,即超定盲源分离(M>N)、正定盲源分离(M=N)和欠定盲源分离(M 目前,国内外在欠定盲源分离领域取得了一系列的进展,在语音处理、数据分析和图像解混等领域获得了许多有价值的成果[3-4]。文献[5-6]主要通过增加支持向量机(SVM)的办法提高混合估计矩阵的精度。文献[7-8]以联合盲源分离算法(J-BSS)为工程背景,提出一种基于耦合秩检测的代数DC-CPD算法,该算法把欠定问题转换成一组超定的CPD问题,可在无噪声的情况下返回精确解。上述文献所提的欠定盲源分离算法主要从算法精度的角度出发,对含有噪声的声音信号处理以及稀疏性问题方面的研究则较少。 近年来,随着人工智能的发展,深度学习算法在目标识别、故障定位和图像分类等领域广泛应用[9-10]。卷积神经网络(CNN)目前作为深度学习领域中最具有代表性的神经网络之一,在图像处理和识别等方面发挥着极为重要的作用。文献[11-12]分别以局部放电的超声信号图和配电网故障电流数据图作为训练样本,采用CNN实现深度学习的训练和识别,获得了很高的识别准确率。文献[13]通过增加判别目标函数的方法优化CNN模型,使得遥感图像场景分类的性能得到了显著的提高。由此可见,CNN在图像识别、分类方面具有独特的优势。然而,对于声音信号的时频谱图训练和识别分类方面的研究则较少。 针对上述问题,本文结合欠定盲源分离算法和深度学习理论,提出了一种基于混合估计矩阵的声音时频谱图特征学习实现声源识别分类的方法。论文的主要贡献如下:1)针对现有的UBSS算法进行了改进,提升了其在处理稀疏性较差的声音信号时的效果。2)提出了一种基于混合估计矩阵的声音时频谱图获取方法,通过设定基准矩阵,调整合适步长,在进行少量UBSS运算后便可获得大量的声音时频谱图,解决了深度学习样本不足的问题。3)利用已有的CNN模型验证了时频谱图在识别分类时具有较高的准确性。 本文首先从信号的稀疏性角度出发,通过改进现有UBSS算法提出了一种新的单源点检测和K-DPC聚类算法结合的稀疏K-UBSS算法。 UBSS的线性混合模型为x(t)=As(t),其中x(t)=[x1(t),x2(t),…,xN(t)]T为观测信号,s(t)=[s1(t),s2(t),…,sM(t)]T为源信号,A为N×M的混合矩阵。 UBSS分为两个部分,即单源点检测和基于混合矩阵估计的聚类分析算法。该算法首先进行短时傅里叶变换(Short-time Fourier transform,STFT),并对时频支撑点进行SSP单源点检测和K-DPC聚类分析,在此基础上完成混合矩阵的估计。 1.1.1 短时傅立叶变换 通过传感器采集的声音一般为时域信号,而时域信号稀疏性不是很强,因此需要对声音信号进行短时傅立叶变换(STFT)[14]。通过添加汉宁(Hanning)窗可以减小频谱泄露,获得较好的时频分辨率。STFT得到的时频域(t,f)信号可以由式(1)和(2)来表示 X(t,f)=AS(t,f) (1) (2) 式中:X(t,f)和S(t,f)分别为x(t)和s(t)在时频域(t,f)下的STFT的系数;ai为混合矩阵A的第i列向量。 1.1.2 基于SSP的单源点检测 SSP单源点检测算法在处理非稀疏性信号上效果显著,该算法通过特征子空间投影发展而来,具有稀疏性好、鲁棒性强和计算简便等优点[15]。 对于任意一种源信号来说,至少存在多个时频观测点,假设观测点数量为S,则混合信号的时频支撑点集合是 (3) 通过STFT的物理意义可知,对于任意一个时频观测点X(t,f)均可分为实部和虚部,分别用Re和Im进行表示,通过定义观测点X(t,f)实部和虚部两者夹角θ: (4) 假设观测信号中仅存在单源点时,可得cosθ=1,此时θ的取值为0°或180°。然而,对于实际的声音信号来说,混合声源的数量越多,满足θ=0°的时频单源点越少。因此,需要在计算前设定一角度限定值Δφ,时频点(t,f)实部和虚部的绝对方向上夹角小于该值时,则该点为SSP[16]。可得 (5) 其中,‖X‖=(XTX)1/2表示矢量绝对值大小,Δφ根据源信号特征分布进行选择。 观测信号归一化通过把线性聚类变换为球形聚类,处于负半球的向量乘以-1,此时所有观测点便映射到正半球上,变换公式为[17] (6) (7) 如此可以保证每条直线仅由唯一方向向量表示,消除聚类分析时异常信号产生的影响。 本文提出一种基于K邻域的密度峰值聚类算法(K-DPC)。该算法通过对样本点构造ρi和δi的决策图,形成中心点领域(类簇)和密度峰值点(类簇中心),并将数据进行噪声点剔除和样本点分类,实现最后的快速高效聚类。具体步骤如下: (1)初始化:选取观测点yi和yj,设观测点个数为N,1≤i,j≤N,i≠j,两点之间距离满足欧几里得度量,即dij=‖yi-yj‖2。 (2)首先定义两个概念:局部密度值ρi和局部高密度点的距离δi (8) (9) 其中,K(i)为样本i的k个邻近域的集合。通过式(11)将样本点局部密度的计算从整体缩短到k个近邻,样本点距离k近邻越近,局部密度越大。δi表示样本i到距离最近的样本j且ρj>ρi的距离。 通过对比ρi和δi的大小,将ρi和δi都比较大的点定义为类簇中心。 (3)将数据集中的所有样本的k个邻近域进行归类和标签,定义式为 kl(i)=maxj∈K(i){dij} (10) (11) 式中:kl(i)为样本i的K距离,thres为判定门限值。当kl(i)>thres时,认为该点即为离群点。 剔除离群点以后,需要把其余样本点进行分配,分配原则如下:将样本点m分配给距离最近且ρn>ρm的第n类簇,最后得到有关ρ和δ的相关决策图。 (4)混合估计矩阵获取:将每一类簇中得到的N个样本点进行排序,排序点顺序为φ1,φ2,…φN,则该类簇对应的单源点被定义为 (12) (13) 近年来,深度学习算法在图像识别和特征提取等方面应用广泛。目前,基于卷积神经网络(CNN)的深度学习算法在图像分类领域取得了很大的进展,相比于传统的图像分类,该算法具有自身独特的学习框架,能够提取更为抽象、适合计算机环境的图像特征[18]。 根据UBSS的分析,本文提出了一种基于混合估计矩阵获得大量时频谱图的方法,通过构建训练和测试样本,对训练集进行预处理,经过训练模型,完成混合时频谱图的分类。 由UBSS算法可知,不同的混合估计矩阵得到的时频谱图在源信号种类和占比等方面存在一定差异,所以选择更多的训练样本,有利于神经网络模型提取更多、更深层的局部特征[19],因此,本文提出了一种基于混合估计矩阵的样本获取方法,具体步骤如下: (3)将所有源信号通过Ci进行混合,得到新的混合时域波形图。 (4)对所有混合时域波形图进行STFT变换,将得到的时频谱图作为训练样本,根据混合矩阵大小随机生成测试样本,分别得到训练集和测试集。 为了确保训练及测试效果,对含有相同源信号,不同混合矩阵得到的训练样本进行源信号种类标记,并通过设置python脚本,随机生成混合矩阵,对源信号进行混合。 CNN主要由输入层、隐藏层和输出层组成,隐藏层又可分为卷积层、池化层、RELU层和全连接层,当隐藏层超过两层时属于深度卷积神经网络。 为了对比测试集在不同卷积神经网络模型下的识别分类结果,验证本文提出的算法对时频谱图具有较高的识别准确率。选取了2种模型进行验证,分别是VGGNet-16[20]网络和ResNet-50[21]网络。 对测试样本进行和训练样本相同的预处理,将其应用于已经训练完成的模型中进行分类,不同的神经网络模型的分类正确率会有一定的差异,通过对比训练集在不同模型下的分类速度,验证本文所提算法的高效性。 本文硬件环境为Intel(R) Core(TM) i5-6500 CPU @ 3.20 GHz 及GeForce GTX 1080 Ti的64位计算机,系统环境为Ubuntu 16.04.6 LTS操作系统,Python 3.6.9 (64位)及Tensorflow1.12.0深度学习框架。环境管理使用Anaconda3进行环境管理。在训练深度学习模型时使用Tensorflow的GPU版本,利用GPU进行硬件加速。 (1)源信号及混合矩阵的选择 为了证明本文UBSS算法具有普适性,随机选取了声音库5种稀疏性较差的音频作为源信号,分别记为s1(t)、s2(t)、s3(t)、s4(t)、s5(t),其中s1(t)、s2(t)、s3(t)分别来在三段不同的演讲,s4(t)和s5(t)分别为葫芦丝和小提琴演奏时的声音,采样率为48 kHz,采样长度为0.2 s,源信号的时域波形如图1所示。 图1 五类音频源信号的时域波形Fig.1 Time domain wave forms of five audio source signals 因混合矩阵的估计在时频域中完成的,为了分析和验证算法归一化后的准确性,本文构造单一混合矩阵B为随机生成,矩阵中元素正负值均需体现,该混合矩阵为 由混合矩阵的性质可知,该矩阵代表源信号数目M=4,观测信号数目N=3,通过B得到两组观测信号,分别记作x′(t)=[x1(t),x2(t),x3(t)]和x′(t)=[x4(t),x5(t),x6(t)],对应的时域信号分别为s′(t)=[s1(t),s2(t),s3(t),s4(t)]和s″(t)=[s2(t),s3(t),s4(t),s5(t)],观测信号的时域波形如图2所示。 图2 两组观测信号的时域波形Fig.2 Time domain waveforms of two groups of observed signals (2)性能仿真与分析 通过引入三维散点图可以确定时频观测点在坐标系中的位置和分布,可以直观的反应K-UBSS算法的聚类效果。x、y、z轴分别代表每组观测信号中三路通道的时频散点图。图3(a)为x′(t)的时频域散点图,图3(b)为x″(t)的时频域散点图。 显然得,从图3可以看出,仅仅经过STFT得到的时频散点图的稀疏性很差,这是因为此时的时频观测点分散性较强,聚类特性较弱。 图3 两组观测信号的时频散点图Fig.3 Time-frequency scatter plot of real and imaginary parts of two groups of observed signals 图4 两组观测信号单源点检测后时频域散点图Fig.4 Time-frequency domain scatter plot after single source point detection of two groups of observed signals 采用SSP单源点检测因涉及角度限定值Δφ的选择和观测信号的归一化,所以在进行单源点检测时需要将实部和虚部协同考虑。通过对比不同Δφ下的标准误差,选择Δφ=0.8°[22]。图4分别给出了x′(t)和x″(t)完成单源点检测后的时频散点图,从图中可以看出,观测信号已充分稀疏,呈现了明显的“直线”聚类特性,这是由于采样点数足够多使其单源点检测具有较高的精度。 由图5为经归一化后x′(t)和x″(t)的时频散点图可以看出,通过归一化后的观测信号均形成了4类明显的密集数据簇。由此可知,本文所提的归一化方法有利于K-DPC时的聚类。 图5 两组观测信号单归一化后时频域散点图Fig.5 Time-frequency domain scatter plot after single normalization of two groups of observation signals 图6 K-DPC后两组观测信号的决策图Fig.6 Decision chart of two groups of observed signals after K-DPC 为了评价不同聚类算法下的混合估计矩阵的精度,通过引入归一化均方误差(NMSE)和偏差角(deviation angle)进行评价[25],其数学形式为 (14) (15) 表1 不同聚类算法的归一化均方误差和偏差角对比 最后,本文利用文献[26]提出的最小二乘法对混合估计矩阵进行计算,完成源信号的恢复,如图7所示。 图7 恢复后的源信号时域波形Fig.7 Time domain waveform of the recovered source signal 综上可见,本文所提出的UBSS算法能有效增强声音信号的稀疏性,得到准确的聚类中心和混合估计矩阵。 (1)训练与测试时频谱图样本生成 由于深度学习需要大量数据作为支撑,而在仿真过程中,通过手动改变λ的大小无法完成样本集的获取,因此本文利用Python脚本改变参数大小。 本文设置λ=0.2,共产生104=10 000个1×n的混合矩阵Ci,5路源信号可混合成5种包含有4路源信号的混合声纹图,共产生50 000个样本,设置为测试集,随机矩阵产生的训练集共5 000个样本。将所有样本进行STFT变换,得到对应的时频谱图。 所有训练样本均经过2.2节所述的数据预处理后,每个训练样本均包括所含源信号种类。 (2)分类算法评估与分析 针对2.3节的2种神经网络模型进行比较,其中VGGNet-16共迭代40万次,ResNet-50共训练10个epoch,学习率LR=0.001,分别从训练误差、训练准确率、测试误差和训练准确率进行评价,测评结果如表2所示。从表2中可以直观的看出,VGGNet-16的测试准确率达到93.75%,而ResNet-50的准确率高达99.92%,证明两种模型均可以满足分类要求,ResNet-50的分类效果更佳。 表2 不同CNN模型下的性能比较 本文基于欠定盲源分离算法和深度学习理论提出了一种大量获得混合时频谱图的方法,通过仿真进行验证,得到以下结论: (1)采用改进后的UBSS算法可以实现混合矩阵的精确估计,展示了该算法应用于实际情况的可行性。仿真运行表明,本文提出的K-DPC算法的归一化均方误差和偏差角均小于其他聚类算法,具有精度高、计算简便等优点。 (2)通过设置步长λ能快速得到大量混合矩阵,通过不同的混合矩阵得到的时频谱图对比可知,图像特征有所差异,有利于时频谱图的特征提取。在不同CNN模型下的分类性能表明,本文提出的获得样本的方法能有效的进行分类,解决了声纹图分类时样本不足的问题。 (3)针对实际情况至少需要两个传感器获得的声音信号才可满足UBSS算法,本文提出的基于深度学习的声音信号分类,可实现仅有单一传感器下的声音信号的分类,在真实场景下具有一定价值。 (4)本文选择的声音信号均来源于已有的声音库,对于现场实验数据的采集和处理是接下来需要考虑的问题;如何保证实验获得的声源包含所有种类;以及不同混合矩阵下步长和训练模型的选择等问题值得进一步深入研究。1 K-UBSS算法
1.1 基于单源点检测及改进归一化稀疏算法
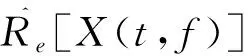
1.2 基于K-DPC算法的聚类分析
2 基于混合估计矩阵的CNN声音信号分类
2.1 基于混合估计矩阵的训练集和测试集的获取
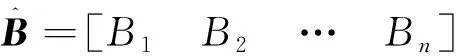

2.2 训练集的预处理和测试集的获取
2.3 卷积神经网络模型
2.4 测试样本分类
3 仿真与分析
3.1 UBSS仿真验证









3.2 深度学习仿真验证

4 结 论
猜你喜欢
空间科学学报(2021年6期)2021-03-09
现代计算机(2018年27期)2018-10-25
通信产业报(2018年40期)2018-01-22
艺术科技(2017年1期)2017-04-05
雷达学报(2017年6期)2017-03-26
移动通信(2017年3期)2017-03-13
人民教育(2016年18期)2016-07-17
互联网天地(2016年1期)2016-05-04
小学教学参考(语文)(2016年3期)2016-03-23
现代计算机(2016年17期)2016-02-28
