
基于深度学习的疲劳驾驶检测算法
2020-07-17 07:35:24郑伟成李学伟刘宏哲代松银
计算机工程 2020年7期
郑伟成,李学伟,刘宏哲,代松银
(北京联合大学 北京市信息服务工程重点实验室,北京 100101)
0 概述
疲劳驾驶是指驾驶人员在长时间连续行车后,造成生理和心理机能的失调,而在客观上出现驾驶技能下降的现象。驾驶人员疲劳后继续驾驶车辆,身体会出现困倦瞌睡、注意力不集中、驾驶操作停顿或对危险情况的预判能力下降等不安全因素,极易发生道路交通事故。近年来,世界各大汽车厂商与科研机构将疲劳驾驶检测技术作为研究重点并取得了相关研究成果,其主要分为主观检测和客观检测两大类。主观检测方法主要靠驾驶人员的主观因素进行判断,可靠性不高,很难成为评价疲劳驾驶的标准,而客观检测方法可靠性相对较高,已成为疲劳驾驶检测的主要方法。
客观检测方法主要分为基于生理特征的检测方法、基于车辆行驶信息的检测方法及基于驾驶人员行为特征的检测方法3类。其中,基于驾驶人员行为特征的检测方法通过分析驾驶人员的眼睛状态(如眨眼幅度、眨眼频率等)、嘴部运动、头部姿态等,实现驾驶人员的疲劳检测。此类方法与前两者相比,有非接触性、准确性高、成本低及易实现等优点,因此疲劳驾驶预警系统具有极其广阔的市场前景。
基于驾驶人员行为特征的检测方法根据面部疲劳特征又可分为基于眼部特征的检测方法、基于嘴部特征的检测方法及基于头部姿态的检测方法3类。在基于眼部特征的检测方法中,当驾驶人员出现疲劳驾驶时,其眼睛闭合持续时间会明显变长,眨眼频率会加快或减少,因此眼部特征直接反映驾驶人员的精神状态。文献[1]定位出人眼区域后,在人眼定位过程中,采用OSTU阈值分割、非线性点运算和积分投影等预处理过程消除眉毛,并利用模糊综合评价算法对眼睛矩形区域的长宽比、拟合椭圆面积、瞳孔黑色素所占比例这3个影响因子进行分析,判别出眼睛的睁开闭合状态,最后根据PERCLOS[2]原理对驾驶人员的疲劳状态做出判断。在基于嘴部特征的检测方法中,当驾驶人员感到疲劳时,嘴部会自发地发生打哈欠的行为,嘴部张开程度大,张开时间持久。文献[3]通过分析标注剥夺睡眠的驾驶人员视频数据集,说明面部触摸、人脸遮挡及打哈欠之间的关系,提出面部触摸可作为检测打哈欠的新线索,并提出一种通过提取嘴部和眼部区域的几何和外观特征来检测打哈欠的方法。在基于头部姿态的检测方法中,当驾驶人员产生疲劳时,打瞌睡点头次数会增多,出现长时间不正视前方等姿态。文献[4]提出一种基于面部特征点定位的头部姿态估计方法。在检测到的人脸区域,使用Hough圆检测方法定位眼睛和鼻孔,利用人眼和鼻孔的位置信息,将眼睛、鼻子定位结果与正脸头部姿态中的眼睛、鼻子进行对比,从而对不同的头部姿态进行粗估计。文献[5]提出一种简单且鲁棒的头部姿态确定方式,通过训练一个多损失函数的卷积神经网络,直接使用RGB结合分类和回归损失来预测头部姿态欧拉角。
传统基于驾驶人员行为特征的检测方法使用HOG、SIFT、Haar等特征描述子,人工提取特征进行模式识别,在实际复杂的驾驶环境下检测精度通常不能满足需求,且鲁棒性也有待提高。深度学习[6-7]技术是一类能从数据中自动学习特征表示的方法,近年来在目标检测[8-9]、目标跟踪[10-11]、人脸识别[12-13]、场景理解[14]等图像处理领域取得了快速发展,其强大的特征学习能力,对部分遮挡、光照变化等外界条件表现出较强的鲁棒性。因此,本文提出基于深度学习的疲劳驾驶检测算法,选取表征疲劳驾驶常用且有效的眼睛闭合程度、嘴巴张开程度和头部姿态等参数指标,利用多特征融合策略检测驾驶人员的疲劳程度。
1 疲劳驾驶检测算法整体框架
本文提出的基于深度学习的疲劳驾驶检测算法具体步骤为:1)利用改进的MTCNN[15]人脸检测模型检测出摄像头实时获取画面中的驾驶人员人脸图像;2)基于人脸图像,使用具有较高效率和准确率的PFLD[16]模型进行人脸关键点检测,从而定位出眼部和嘴部;3)根据人脸关键点计算出人脸图像的头部姿态欧拉角,即俯仰角(Pitch)、偏航角(Yaw)及滚转角(Roll);4)采用多特征融合策略,根据眼部、嘴部和头部的疲劳特征建立疲劳驾驶预测模型,实现对疲劳驾驶的预警。算法总体流程如图1所示。

图1 基于深度学习的疲劳驾驶检测算法流程
2 改进的MTCNN人脸检测模型
MTCNN是结合级联与由粗到精思想的深度学习模型(级联结构包括PNet、RNet及ONet),其是目前应用十分广泛的特定目标检测器,也是少数能在传统硬件上进行实现的检测器。对于人脸检测任务,在人脸数少于5的情况下,其具有较高的检测水准并且有极大的优化空间,通过模型训练可在移动端达到极快的检测速度。实验结果表明,原始MTCNN模型在速度方面存在瓶颈,具体为:1)输入图片越大,PNet耗时越长;2)人脸越多,ONet和RNet耗时越长;3)噪点比较多的夜晚图像会导致PNet误检增加。
针对PNet、ONet和RNet耗时长的问题,采取优化网络结构的策略,使其在精度下降不明显的情况下,尽可能减少计算量。改进方法主要为使用ShuffleNet[17]中的shuffle-channel思想,将特征的通道平均分到不同组中,使每个组在卷积时能得到其他组的信息,增加不同channel之间的关联性。实验为对比改进方法的优越性,采用Xception[18]中depthwise卷积思想以减少计算量和提升效率。首先对输入图的每个通道进行卷积,然后由1×1卷积将通道进行合并。实验结果证明,此操作基本可以等同于普通的空间卷积,并且在I/O效率和性能不变的情况下,计算量降低了90%。因此,利用该方法替换PNet、RNet和ONet中的卷积操作,可使模型检测速度得到大幅提升。
由于驾驶场景下摄像机采集的一般为单张人脸图像,因此实验仅在单张人脸数据集上进行测试,使用的深度学习框架为TensorFlow,测试硬件环境为i7-9750H CPU,测试软件为Pycharm2018。在某些监控场景的夜晚图片中,会有大量噪点的出现,导致PNet产生大量的误检候选区。为减少这些噪点的出现,实验在PNet检测前,使用一次中值滤波进行快速去噪,具有较好的实验效果。
3 人脸关键点检测模型
在疲劳驾驶检测应用场景中,除了根据人脸关键点定位眼部及嘴部外,还可利用关键点进行头部姿态估计,计算头部姿态的欧拉角。图2为人脸中的68个关键点。
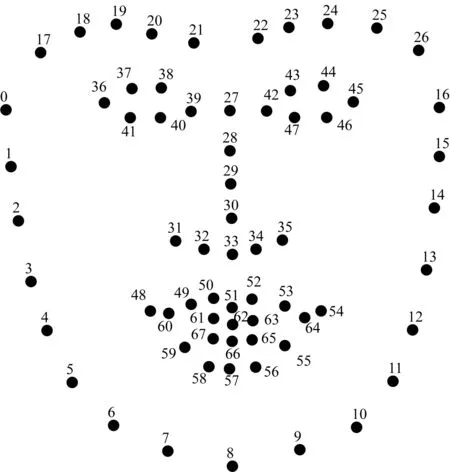
图2 人脸中的68个关键点
从实用性角度来看,人脸关键点检测面临诸多问题:1)人脸表情变化很大,真实环境光照复杂,而且现实中存在大量人脸局部被遮挡的情况等;2)人脸是3D的,位姿变化多样,另外,因拍摄设备和环境影响,成像质量也有所不同;3)现有训练样本的各个类别存在不平衡问题;4)在计算受限的设备(如手机)终端时,必须考虑计算速度和模型规格问题。
为解决以上问题,本文提出人脸关键点检测模型PFLD。该模型的主干网络用于定位关键点的位置,在训练时加入预测人脸姿态的辅助网络以提高定位精度,但在测试时省略该网络。对于训练样本类别不平衡问题,PFLD通过修改loss函数,在训练时关注稀有样本,如果某类别样本较少则赋予较大的权重,并使用轻量级模型提高计算速度和降低模型规格。
在模型设计上,PFLD模型的骨干网络未采用VGG16[19]、ResNet[20]等网络,但为增加模型的表达能力,对MobileNet[21]的输出特征进行结构修改,通过融合3个不同尺度的特征来增加模型表达能力,并且为更好地兼容嵌入式设备,PFLD模型进行了性能优化,在骁龙845芯片中的效率可达140 frame/s,模型内存为2.1 MB,在许多关键点检测的Benchmark中也取得了较好的结果。
4 头部姿态估计
在实际驾驶环境中,头部姿态主要用来判断驾驶人员的注意力情况,如检测长途司机是否在目视前方,若长时间不目视前方,则给予相应警告,以保证安全,减少事故。
头部姿态欧拉角的计算分为:1)2D人脸关键点检测(使用PFLD模型),该部分采用的人脸关键点有鼻尖、下巴、左眼的左角、右眼的右角、左嘴角、右嘴角;2)3D人脸模型匹配;3)求解3D点和对应2D点的转换关系;4)根据旋转矩阵求解欧拉角。
人脸相对于相机的姿态可以使用旋转矩阵和平移矩阵进行表示,其中:平移矩阵(t)表示物体相对于相机的空间位置关系矩阵;旋转矩阵(R)表示物体相对于相机的空间姿态关系矩阵。具体的计算过程为:人脸特征的3D坐标是以世界坐标系进行表示,如果旋转和平移均已知,那么可以将世界坐标中的3D点转换到相机坐标系中的3D点;然后采用相机的内在参数(焦距、光学中心等),将相机坐标系中的3D点再投影到图像平面(如图像坐标系)。图3为坐标系统的工作原理。

图3 坐标系统工作原理
世界坐标系到相机坐标系的转换、相机坐标系到像素坐标系的转换如式(1)、式(2)所示:
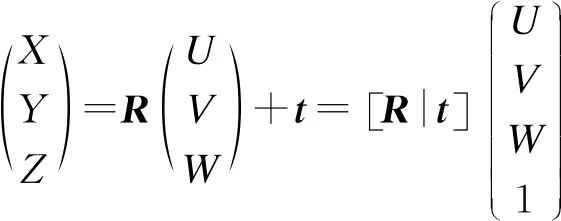
(1)
(2)
像素坐标系和世界坐标系的关系为:
(3)
式(3)可用DLT算法结合最小二乘进行迭代求解,最小二乘的目标函数为:
(4)
其中,带“^”的变量为预测值,其余为测量值。若相机存在径向和切向畸变,则需先将相机坐标系转换到图像中心坐标系(如式(5)所示),然后计算畸变(如式(6)所示),最后得到图像中心坐标系和像素坐标系的关系(如式(7)所示)。

(5)
(6)
(7)
由式(7)可以看出,若已知世界坐标系内点的位置、像素坐标位置和相机参数,则可以使用Opencv中求解PnP问题的solvePnP函数计算旋转和平移矩阵,计算得到的旋转矩阵为:
(8)
其中:

(9)

(10)

(11)
最终得到的欧拉角为:
(12)
其中,世界坐标系的中心位置由3DMM模型进行确定[22]。实验中首先对DLT算法进行了改进,即随机轻微地改变姿态(R和t),然后检查重投影误差的衰减情况,如果是衰减,则接受为新的姿态,最后继续调整R和t以寻找更好的姿态。
5 疲劳特征提取
5.1 眼部疲劳特征提取
驾驶人员眼部的运动和眨眼信息被认为是反映疲劳状态的重要特征,眼部疲劳检测算法利用PERCLOS中的P80标准和眨眼频率进行眼部疲劳特征提取。
5.1.1 PERCLOS值
PERCLOS是卡内基梅隆研究所经过反复实验和论证提出的度量疲劳/瞌睡的物理量。研究表明,在PERCLOS常用的判定标准中,P80标准与疲劳驾驶的相关性较高,P80标准指当眼睑遮住瞳孔的面积超过80%时记为眼睛闭合,统计在一定时间内眼睛闭合时所占的时间比例,其原理如图4所示。

图4 PERCLOS中的P80标准原理
PERCLOS值的计算公式如下:
(13)
其中,fp是PERCLOS值,若D为眼睛完全睁开时的上下眼睑距离,则t1是D减少20%的时刻,t2是D减少80%的时刻,t4是眼睛由闭合增加至D的20%的时刻,t5是眼睛由闭合增加至D的80%的时刻。PERCLOS值与眼睛睁开程度密切相关,眼睛睁开程度由眼睛上下眼睑围成面积的变化进行表示。将眼睛上下眼睑的轮廓与虹膜看作两个嵌套的椭圆,如图5所示。

图5 P80标准的眼睛轮廓模型
眼睛面积为S=πwh,其中,w表示眼睛宽度,h表示上下眼睑的垂直距离。w和h的计算公式如下:
(14)
其中,x39、x36为第39个和第36个关键点的横坐标,y40、y38为图2中第40个和第38个关键点的纵坐标(索引下标从0开始)。S的最终取值为左右眼睛面积的平均值,设眼睛睁开百分比为R,则可以得到:
(15)
其中,wmax、hmax、Smax分别为眼睛完全睁开时的值,终端采集视频中每帧图片的眼睛睁开程度按照R值进行评定,再根据某时间段推算得到fp值。在一般情况下,正常人的闭眼速度为0.2 s,如果闭眼持续时间超过0.8 s,则为疲劳状态。
5.1.2 眨眼频率
据统计,正常人每分钟眨眼约20次,每次眨眼时间间隔约3 s,发生疲劳时眨眼的频率会加快,若平均每秒眨眼一二次,属于应预警的疲劳级别,因此可以通过眨眼频率(即单位时间内眨眼次数)来判断驾驶人员是否疲劳。眨眼频率fblink为:
(16)
其中,NB为时间段T内发生眨眼动作的次数,可由眼睛纵横比(Eyes Aspect Ratio,EAR)来确定,NP为时间段T内的视频总帧数。以图2中的左眼为例,提取的人脸左眼关键点分布如图6所示。

图6 人脸左眼关键点分布
EAR的计算公式为:
(17)
其中,y37、y41、y38、y40分别为第37个、第41个、第38个和第40个关键点纵坐标的坐标值,x36、x39分别为第36个、第39个关键点横坐标的坐标值。EAR的最终取值为左右眼EAR的平均值。EAR在眼睛睁开时基本保持不变,在小范围内会上下浮动;当眼睛闭合时,EAR会迅速下降,即进行一次眨眼动作,由此计算出时间段T内发生眨眼动作的次数NB。
5.2 嘴部疲劳特征提取
嘴部状态通常有闭合、说话及打哈欠3种,在疲劳状态下,人会频繁地打哈欠。类似于眼部疲劳特征的提取,提取的人脸嘴部区域的关键点分布如图7所示。

图7 人脸嘴部关键点分布
嘴部宽度W及高度H计算如下:
(18)
W与H的比值K为:
(19)
其中,xmax、xmin分别为第54个和第48个人脸关键点的横坐标,ymax为第56个、第58个关键点纵坐标的平均值,ymin为第50个、第52个关键点纵坐标的平均值。打哈欠时嘴巴的张开程度最大,此时K值变小,由此可判断驾驶员是否打哈欠。打哈欠的频率fyawn为:
(20)
其中,NY为时间段T内打哈欠的次数,NT为时间段T内的视频总帧数。NY的计算方法同眨眼次数NB,可由嘴部纵横比(Mouth Aspect Ratio,MAR)来确定。
5.3 头部姿态疲劳特征提取
文献[23]研究发现,成年人的头部运动范围包括-60.4°~69.6°的矢状屈曲和伸展(即从颈部向后运动,Pitch),-40.9°~36.3°的正面侧向弯曲(即颈部从右向左弯曲,Roll),-79.8°~75.3°的水平轴向旋转(即从头部向左旋转,Yaw)。当驾驶人员处于疲劳状态时,通常会无意识地出现身体的前倾后仰、左右倾斜或其他疲劳姿态,导致不能进行正确的驾驶操作,最常见的表现为驾驶人员头部的点头频率和异常姿态,即Roll、Pitch及Yaw旋转角度的变化。
5.3.1 点头频率
头部姿态检测得到的欧拉角中前后方向的Pitch与驾驶人员的点头频率相关。当Pitch达到一定阈值时判定为点头动作。点头频率fnode为:
(21)
其中,NN为时间段T内发生点头动作的次数,NT为时间段T内的视频总帧数。
5.3.2 异常姿态
本文疲劳驾驶检测算法在头部姿态检测的基础上,结合PERCLOS的P80标准,当头部姿态欧拉角发生20%的角度变化时,则判定驾驶人员处于异常姿态,即Roll的异常范围为-56.3°~-40.9°、36.3°~51.7°,Pitch的异常范围为-86.4°~-40.9°、69.6°~95.6°,Yaw的异常范围为-110.8°~-79.8°、75.3°~106.3°。异常姿态指标fpose为:
(22)
其中,NP为时间段T内检测出异常姿态的帧数。
6 实验结果与分析
6.1 生成模型
6.1.1 人脸检测模型
改进的MTCNN人脸检测模型使用基准人脸数据集WIDER FACE[24]进行训练,在下载的数据集上共有12 880幅图像,其中包括159 424张人脸。如图8所示,其中矩形框为人工标注边界框,人脸在尺度、姿态、遮挡、表情、装扮、光照等方面都有很大差异,人脸特征具有多样性。在训练模型时,根据图像的识别难度将数据集划分为3个子集,其中50%作为测试集,40%作为训练集,10%作为验证集。训练模型正负样本的处理参考原始MTCNN的训练方法。为验证MTCNN改进模型的性能,实验分别采用ShuffleNet中的shuffle-channel和Xception中的depthwise思想进行模型训练和测试,实验结果如表1所示,其中第2组比第3组速度慢的原因为1×1卷积占据了depthwise卷积80%~90%的计算量,shuffle-channel正好解决了计算量和不同通道通信的问题,可以看出shuffle-channel方法具有更高的效率。在驾驶环境下,MTCNN-shuffle人脸检测模型的检测效果如图9所示。

图8 WIDER FACE数据集样本

表1 MTCNN及其改进模型的比较

图9 驾驶环境中的人脸检测
6.1.2 人脸关键点检测模型
人脸关键点检测模型PFLD使用300W[25]和AFLW[26]两个基准数据集训练和测试模型。300 W是用于人脸关键点检测的竞赛数据集,其中每幅图像的每张人脸有68个关键点。300W数据集包含LFPW[27]、AFW[28]、HELEN[29]及IBUG[30]4个数据集,共3 837幅人脸图像。实验使用3 148幅图像作为训练集,689幅图像作为测试集。具体地,测试集分为3个子集:1)具有挑战性的集合(IBUG中的135幅图像);2)一般集合(LFPW测试集中的224幅图像,HELEN测试集中的330幅图像,共554幅图像);3)全集(全部测试图像,共689幅图像)。AFLW数据集提供了大规模人脸图像集合,每张人脸面部有21个标志,表现出各种各样的外观及一般的成像和环境条件。实验分别使用20 000幅图像和4 386幅图像作为训练集和测试集。
在训练期间,所有人脸图像被裁剪或重置大小至112×112。实验采用深度学习框架TensorFlow,批量大小(BatchSize)设置为512,优化器为Adam,权重衰减设置为10e-6,动量为0.9,最大迭代次数为70 000次,整个训练过程的学习率固定为10-4。训练硬件环境为单卡Nvidia GTX 2060 GPU。对于300W数据集,实验采用数据增强技术,如对每个样本水平翻转并以5°为间隔从-30°至30°对图像样本进行旋转。考虑到真实驾驶环境,进一步增强模型泛化能力,并对每个样例中的人脸图像做了20%的随机遮挡。对于AFLW数据集,实验没有使用任何数据增强技术而是直接输入原始图像。图10为驾驶环境下人脸关键点检测及定位出的眼部及嘴部。

图10 驾驶环境中的人脸关键点检测
6.1.3 疲劳驾驶检测模型
疲劳驾驶检测模型使用YawDD[31]数据集作为疲劳检测的标准数据集,该数据集包含不同性别、年龄的驾驶人员在不同光照环境下拍摄的模拟驾驶视频。驾驶人员的面部特征包括:1)正常驾驶(不说话,标签为Normal);2)驾驶时说话或唱歌(标签为Talking);3)开车打哈欠(标签为Yawning)。数据样本如图11所示。

图11 YawDD数据集样本
由于数据集中的视频时间长短不一,为保证准确性,实验随机选取时间大于30 s的测试样本,并将视频的70%作为训练集,30%作为测试集。同时,由于每一个视频中驾驶人员的眨眼、打哈欠及异常姿态次数并未标注,因此实验时寻找10位观察者记录每一个视频中驾驶人员的眨眼、打哈欠及异常姿态次数,最后取10位观察者的平均值作为真实数据,同时使用PFLD模型检测并记录PERCLOS均值,数据样本如表2所示。

表2 基于10位观察者收集的数据样本
由于疲劳特征的多样性,单一的疲劳特征很难作为疲劳驾驶的检测标准,因此疲劳驾驶检测模型采用多种面部疲劳特征相融合的策略,具体过程如下:
1)获取各疲劳特征阈值与连续检测帧数。对单个视频而言,随机抽取样本分别得出眼部EAR阈值α、嘴部MAR阈值β、点头频率阈值γ、异常姿态阈值θ与连续检测视频帧数F的设定对相应检测准确率的影响。实验时所有阈值的设定范围为0.35~0.75,间隔取值为0.05;F设定的值为[10,15,20]。以眼部EAR阈值为例,准确率为检测到的眨眼次数与标注数据的比值,如图12所示。根据以上方法在整个训练集上进行实验,最后计算所有样本的眼部EAR阈值α、嘴部MAR阈值β、点头频率阈值γ、异常姿态阈值θ在准确率最高值时的平均值分别作为疲劳检测时的各特征阈值,F选取准确率最高的值。

图12 眼部EAR阈值与连续检测视频帧数对准确率的影响
2)基于决策树的疲劳驾驶预测与分类模型。根据以上10位观察者的标注数据,使用sklearn机器学习库构建决策树来预测疲劳驾驶检测模型,特征选择标准为Gini指数,输入为所有疲劳特征组成的向量,输出为连续检测给定帧数后判别驾驶人员为正常驾驶、驾驶时说话或唱歌及开车打哈欠这3种情况。
6.2 测试模型
在测试阶段,为验证模型准确率,实验中还检测并统计了测试样本的相关疲劳特征数据,如表3所示。可以看出,驾驶人员在疲劳驾驶时,PERCLOS值、打哈欠次数及头部异常姿态都有所增加或加重。在测试集的所有视频中,本文疲劳驾驶检测模型给出的预警均未出现误判的情况。

表3 测试样本的相关疲劳特征数据
7 结束语
在复杂的驾驶环境下,鲁棒的人脸检测和人脸关键点检测是疲劳驾驶检测的前提,而疲劳特征的选取是疲劳驾驶检测的关键。为此,本文提出一种基于深度学习的驾驶疲劳检测算法,通过改进MTCNN模型提升人脸检测效率,使用PFLD模型保证人脸关键点检测鲁棒性,采用基于决策树构建的疲劳驾驶预测与分类模型提高疲劳驾驶检测准确率。实验结果表明,该算法在疲劳驾驶检测准确率和效率方面均有较大的性能提升。后续将通过解决视频样本中驾驶人员的极端与异常头部姿态估计问题,进一步提高疲劳驾驶检测算法的实时性和准确率。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
科技与创新(2021年21期)2021-11-29 03:08:58
今日农业(2021年8期)2021-11-28 05:07:50
就业与保障(2021年9期)2021-11-22 15:01:07
中学生博览·文艺憩(2020年12期)2020-12-23 09:37:52
黄河之声(2020年19期)2020-12-07 18:32:31
汽车实用技术(2019年9期)2019-11-25 22:35:04
新课程·下旬(2019年3期)2019-05-08 08:06:34
农村百事通(2018年16期)2018-09-29 08:39:30
农业工程学报(2018年10期)2018-06-05 06:54:58
