
一种基于情感特征的短文本分类方法
2020-07-15 08:56张英俊潘理虎
计算机与现代化 2020年7期
周 灵,张英俊,潘理虎
(太原科技大学计算机科学与技术学院,山西 太原 030024)
0 引 言
随着电子商务与社交应用软件的广泛使用和普及,移动支付使用率越来越高,使得互联网行业取得长足进步[1]。网购平台、在线政务服务平台等产生海量的短式评论,这类文本大部分字数较少而数量庞大,加之更新速度很快,对这些海量数据进行短文本分类从中挖掘潜在价值成为当今大数据时代至关重要的一步。这些短文本数量的急剧增加,使短文本分类在舆情分析、趋势分析、情感倾向分析方面发挥越来越重要的作用[2]。短文本稀疏、及时和海量的特点同时也造就了特征词较少而文本规模庞大的难点,因此在文本分类过程中,研究者主要在特征提取方法或分类器改进上进行选择和优化以提高分类效果。
近年来,短文本分类倍受国内外学者关注。陈海燕[3]提出了一种集成网页计数和Web搜索引擎返回片段的方法,有效解决了Web数据中隐藏的噪声和冗余以及准确性不高的问题,显著地提高了基于页面计数方法的查询建议质量。Yang等人[4]使用贝叶斯和支持向量机在3个文档集合上评估了9种著名特征选择方法的改进版本,有效地减弱了语料库中的不平衡因素所造成的不利影响。张谦等人[5]合并加权Word2vec和TF-IDF这2种模型并用此模型对微博数据集进行短文本分类,分析了准确率与分类类别、类别数量等因素的关系,解决了Word2vec模型无法区分文本中词汇的重要程度的问题。孙志远等人[6]提出了在文本表示过程中采用Word2vec进行词项加权语义映射的方法,解决了移动营销文本语句残缺等性质令依赖词共现的方法无法有效衡量相似度等问题,该方法在分类性能上比基于词统计特征的方法能更有效地衡量移动营销类别短文本的相似度。
上述方法在一定程度上改进了传统算法,但也存在缺陷,大多数模型都是通过改进词语权重计算方法来改进特征提取[7],从而影响之后的短文本分类效果或者直接改进分类器效率来改进分类效果[8],这些方法忽略了短文本自身有着强烈情感这一特性。针对这个问题,本文提出一种基于情感特征的短文本分类方法,在短文本分类中融入情感特征,不仅考虑词频而且将具有强烈情感特征的词权重加大,通过这种方法建立基于情感特征的短文本分类模型,并输入不同的分类器进行实验。相对于其他方法,本文所提出的基于情感特征的短文本分类模型的优势在于不仅只考虑词频对于区分词语重要程度的影响,而且考虑了词语本身的情感信息,更加丰富地表达了文本自身包含的信息。
1 相关工作
现有的短文本分类工作目前主要集中在文本特征(即词语)的提取、选择以及分类器模型的设计方面。之后多采用词向量以及深度神经网络来进行文本分类[9]。随着深度学习的广泛应用,词向量(word embedding)表示方法越来越受到广大研究者的重视,词向量为词语在计算机中的表示,其基本思想是把词语表示为密集的N维向量。词向量表示方法有独热编码、分布式表示等。
分布式表示(Distributed Representation)[9]很好地解决了有效位编码的向量稀疏、维度较大的问题,文本分布式表示可以通过训练把每个词都映射到训练过程中指定维度的词向量上,再进行下一步工作即分析这些词之间的关系。
分布式表达提出时间较早,因Word2vec工具的开源而真正得到大多自然语言处理(Natural Language Processing, NLP)学者的关注[10]。Word2vec模型通俗来说是比较简洁的神经网络,有连续词汇语言模型(Continuous Bag-of-Words, CBOW)和Skip-Gram这2种模型[11],模型图如图1、图2所示。CBOW模型的训练输入是某一个特征词的上下文相关的词,输出是上述词的词向量,其数学表示为:
P(Wt|τ(Wt-k,Wt-k+1,…,Wt+k))
(1)
Skip-Gram模型和CBOW模型的数学思维相反,输入层是词向量而输出层是对应上下文的词向量,当数据集较小时用CBOW较为合适,虽然Skip-Gram时间空间复杂度更高但面对大型语料效果更好,牺牲时长和空间是有必要的[12]。Skip-Gram数学表示为:
P(Wt-k,Wt-k+1,…,Wt+k|Wt)
(2)
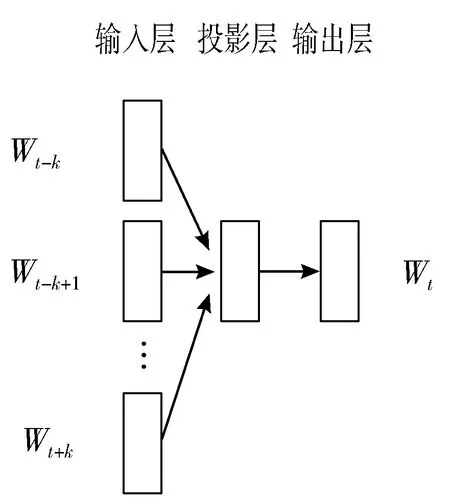
图1 CBOW模型图
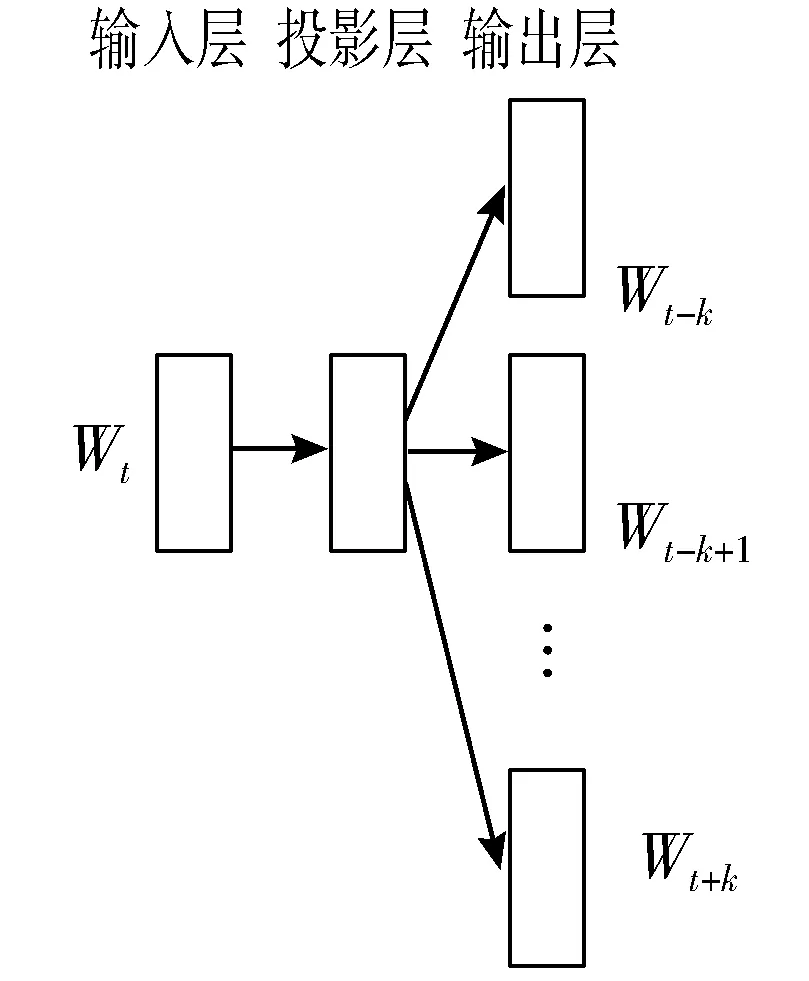
图2 Skip-Gram模型图
目前基于Word2vec的向量表示方法成为热门,综合考虑使用Skip-Gram模型,解决了使用传统向量空间模型处理短文本时的特征稀疏问题。同时结合TF-IDF区分词汇重要程度,使用情感特征进一步优化权重值,实验表明使用情感特征的短文本分类模型在准确率、召回率和F值上都有所提高。
2 情感特征
中文词汇量巨大,情感层次强烈程度不一,人工整理标记工作量巨大耗时耗力[13]。随着网络的普遍应用新型词汇层出不穷,文本中蕴含的情感信息越来越受到广大学者的重视,情感词典也应该随之扩大,情感词典的扩充也成为了情感判断至关重要的影响因素[14]。
2.1 情感词典
短文本中有时词频较低的词语也同样蕴含着有效信息,因此对一些词频较低的词语本文采用TF-IDF结合情感特征的方式修饰其特征权重。情感特征需要使用情感词典,而现阶段的情感词典大部分为公共领域词典[15],因此建立酒店领域的情感词典对修饰情感特征权重大有裨益。
本文使用BosonNlp情感词典结合知网情感词典再进行词典的扩充,BosonNlp词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典,每一个常用词都有一个分值,利用点互信息算法(Pointwise Mutual Information, PMI)扩充情感词典,点互信息是一种常用的对信息进行度量的方法,统计2个词在文本中同时出现的概率,同时出现的概率越大则相关性越高,关联程度越高[16]。首先计算词语的相关性,计算公式为:
(3)
其中,P(word1&word2)表示2个词共同出现的概率,P(word1)·P(word2)表示词word1出现的概率与word2出现概率的乘积,PMI值越大,2个词语出现的概率越大,2个词语关系越靠近[17]。
其次进行语义倾向性(Sentiment Orientation, SO)计算,选取情感程度强烈的负面种子词与正面种子词若干,使用词与正面、负面种子词的紧密程度来判断一个词的情感倾向,计算公式为:
SO(w)=PMI(w,w+)-PMI(w,w-)
(4)
其中,w是未知情感极性的词语,w+和w-分别表示正面和负面种子词。若SO值大于0,说明该词与正面词共同出现概率更高,所以为正面词,反之为负面词。
种子词的选取方式为按照词频对前10个词语由大到小排列,选出带有情感强烈的正面词和负面词。
用上述方法将语料库分词后的词语与种子词计算扩建酒店领域的专业情感词典,一方面词典中包含网络用语及非正式简称,这样对非规范文本也有较高的覆盖率,另一方面情感词典包含专业领域的词语,相比于公共情感词典分类更加准确、情感判断更加细致。
2.2 情感特征
目前对于特征词的情感判断有基于知网情感词典将情感分为积极与消极2个方面,有学者将情感词分为不同强度来判断句子得分[18],而对于短文本字数较少的特点,存在情感特征词提取准确率不高的问题,对于这一现象,本文提出基于情感特征的短文本分类方法,避免情感特征在提取时情感强度划分不够细致、特征词提取时准确率不高的问题。
特征项的选择和特征权重的计算都属于短文本分类中的特征提取,是短文本分类的核心步骤,是直接影响短文本分类结果的关键环节[19]。特征项的选择即是根据某些公认的评价指标对原始的词语进行评分排序,从而选择出一些代表性的特征项,过滤掉没有代表意义的特征项[20]。常用的特征提取方法有上述提到的词向量表示方法,基于Word2vec对特征进行降维处理。该方法的优点在于解决了短文本分类中向量空间表示高维稀疏产生维度灾难的问题[21],从原始的特征中挑选出一些最具代表性的特征,基于数学的方法选取出最具分类信息的特征。
使用TF-IDF计算酒店短文本语料库的特征权重,TF-IDF是文本分类中最常用的特征权重计算方法,根据一个词在文本中出现的次数与在整个语料中出现的次数相乘来衡量这个词语的重要程度,从而筛选频率较高的日常用语和频率较低的无意义词语,比如:我们、我的、这些那些等;保留对于文本来说较为重要的词语,计算公式为:
tfidfi,j=tfi,j×idfi,j
(5)
tfidfi,j表示词频是tfi,j和倒文本词频idfi,j的乘积。TF-IDF值越大,表示该特征词对这个文本的重要性越大[22]。TF(Term Frequency)表示某个关键词在整篇文章中出现的频率。计算公式为:
tfi,j=ni,j/∑knk,j
(6)
其中,分子表示为这个词在文本中出现的次数,分母表示为特征词个数,结果为这个特征词的词频。IDF(InversDocument Frequency)表示逆文本频率,也就是这个词在语料里所有文章中出现的次数取倒,计算公式为:
idfi,j=log (|D|/(1+|Di|))
(7)
|D|表示所有语料文本的总数,|Di|表示语料中包含特征词的个数。为防止计算出无穷大即分母为0的现象,分母加一便于计算。
由公式可以看出,一个词汇是否重要取决于在所有文章中的频率,和所有语料中出现次数的倒数成正比关系。虽然能够分辨一个词语对于语料的重要程度,但是只从频率这方面考虑还是有所欠缺,对短文本中蕴含的大量情感信息没有捕捉到[23]。
将酒店评论语料使用结巴分词算法进行分词处理,首先使用TF-IDF计算出特征词的权重,实验确定阈值范围,分词得到的所有词语融合情感词典计算每个词语的权值PMI值。将特征权重过低的特征词的TF-IDF值与PMI值进行比较,若特征词的PMI值在TF-IDF的阈值范围内,则将PMI值作为修正后的TF-IDF值。
文本的特征、特征提取、特征权重计算就像三角关系一样,并不是每一个越长越好,正如可以表征文本的特征有很多,但并不是构建的特征越多,其分类效果越好。
3 实 验
3.1 实验数据
实验所使用的数据集为谭松波老师整理的酒店评论数据集一万条与爬虫携程酒店的评论数据集约一万条,其中一万二千条为正面,八千多条为负面,数据集和测试集划分比例为4:1,文本长度最多不超过80个词。将收集到的短文本进行分词是文本分类中一个重要的步骤,分词的效果好坏对最后短文本的分类准确率和召回率影响巨大,本实验使用Python中自带的结巴(jieba)分词工具,该分词工具分词效果较好且操作简单,分词之后进行去停用词的操作,去掉文档中不必要的一部分词,如哎呀、常用人称、数字等无实际意义的词语和符号。
3.2 文本向量化及特征权重改进
传统的文本表示方式对于短文本并不适用,本实验采用Python中的gensim工具库调用Word2vec来实现文本向量化,再进行参数调优并在此基础上使用情感特征的方法对特征进行加权计算。首先对TF-IDF值的范围进行参数调优,对于不在阈值范围内的部分词语也可能含有情感,将这部分词经过情感词典的计算,将情感得分值作为特征权重,从而使得一些TF-IDF值较低而情感强烈的词语能被重新利用。截取与酒店相关的词在特征修饰前后的变化如表1和表2所示。
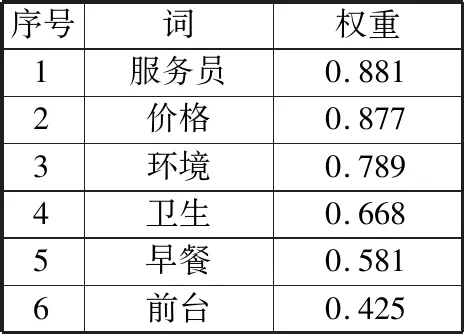
表1 情感特征修饰权重前
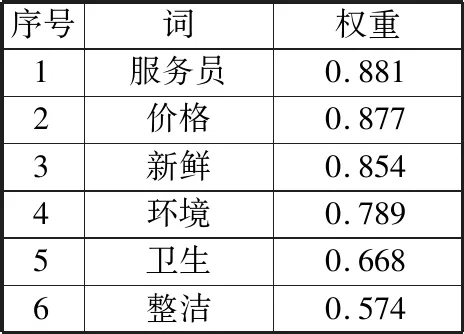
表2 情感特征修饰权重后
3.3 评价指标
文本分类常采用的评估指标包括准确率、召回率、F值。其中准确率(Precision, P)又称“精度”,表示正确分类到该类的文本占分类到该类文本的比例,计算公式为:
P=x/(x+y)
(8)
召回率(Recall, R)又称“查全率”,用来说明分类器在某种意义上是否有效,计算公式为:
R=x/(x+z)
(9)
其中,x是分类正确的短文本数量,y是不应该属于该类别的短文本数量,z是本应该属于该类但未被模型识别出来的短文本数量。而评价模型的另一指标F值(F-measure, F)是准确率和召回率的加权调和平均数,是将准确率与召回率同时考虑的一种指标,其计算公式为:
(10)
本实验同时记录短文本分类过程中分类器的训练时间,和上述中的F值共同用来衡量模型优劣。
3.4 短文本分类模型构建
为了验证该方法的有效性,实验分别在不同的分类器上进行短文本分类实验,流程如图3所示。
实验1使用Word2vec结合TF-IDF算法计算权重。将训练集构建为一个词向量空间,每个词的权重值保存在二维权重矩阵中,把测试数据同样地映射到上述的词向量空间中,此时的测试集与训练集在同一个词向量空间,有着相同的词向量空间坐标。最后输入不同的分类器中,在分类器中用训练集训练,测试集测试。本实验采用KNN分类器与SVM分类器,分类效果见图4、图5。实验同时验证了数据集大小对分类效果的影响,由图4可以看出当数据集大小为8000~25000时F值较高且相对稳定,此时的F值变化范围不大,在SVM分类器上可以看出F值最大值为91.6%,实验数据集越接近2万越趋于稳定,在KNN分类器上可以看出F值最大值为90.7%,数据集越大越稳定。当数据集在8000以下时,无论是SVM分类器还是KNN分类器F值都不高且波动明显。由图5可以看出,在SVM分类器和KNN分类器中,均是数据集增大的同时训练时间增加,在SVM分类器上用时最长为65 s,KNN用时较短,最多为0.5 s。
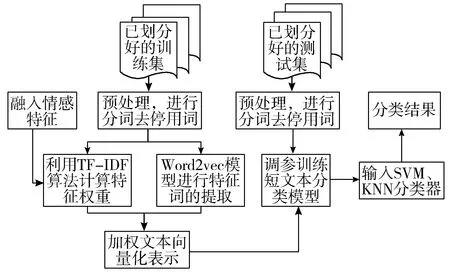
图3 短文本分类流程图
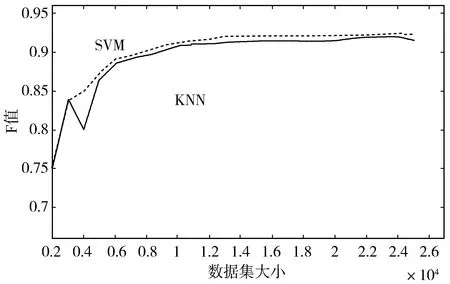
图4 实验1不同数据集时分类F值

图5 实验1不同数据集时分类时间
实验2融合情感特征的短文本特征提取方法。构建情感词典用于因特征权重较低而被删除的词语,将情感词典计算得到的情感值作为权重赋予该词,为避免出现负数情况,情感得分一律取其绝对值。同样地将训练集构建为一个词向量空间,每个词的权重值保存在二维权重矩阵中,把测试数据同样映射到上述的词向量空间中。此时的测试集与训练集在同一个词向量空间有着相同的词向量空间坐标,得到融入情感特征后新的特征权重。最后输入分类器。融入情感特征的分类结果如图6和图7所示。由图6可以看出,融入情感特征后的分类效果优于普通特征,尤其是在数据集的数量增加之后优势更为明显,在SVM分类器上F值最大值为91.4%,数据量越大越呈稳定趋势,在KNN分类器上F值最大值为92.6%。从图7可以看出,在2个分类器上训练时间随着数据量的增加而增加,在SVM分类器上用时最长75 s,而在KNN分类器上训练用时最长为6 s,这说明在提高分类效果的同时增大训练时间的消耗是可行的。
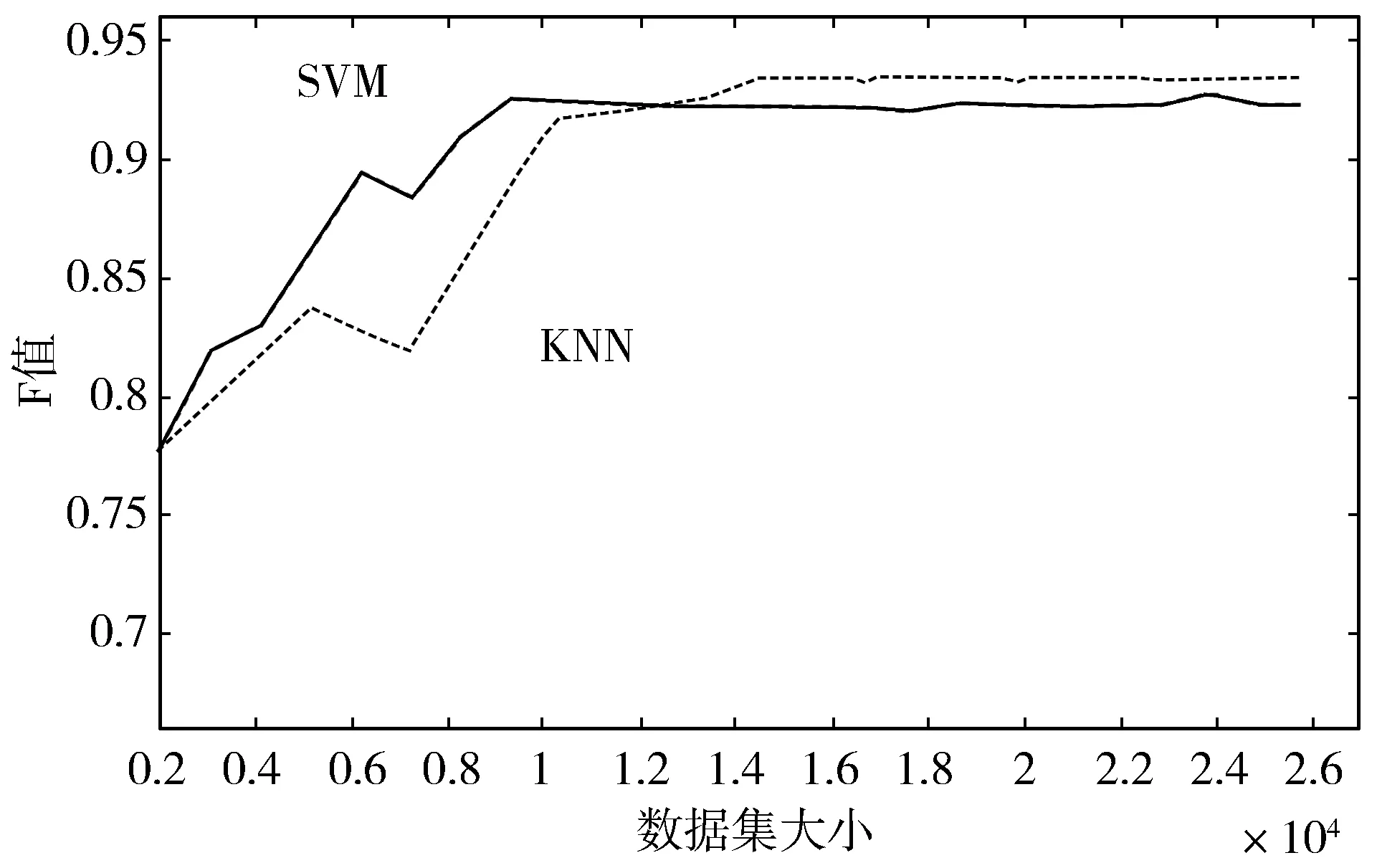
图6 实验2不同数据集时分类F值

图7 实验2不同数据集时分类时间
4 结束语
改进的特征权重计算方法充分考虑了词频较低而情感强烈的词语,在文本分类过程中同时解决了传统方式适用于长文本而在短文本上维度较高向量稀疏,和传统短文本分类方式只考虑词频不考虑词语本身带有效信息的问题。从改进的特征权重计算方式中可以看出融合情感特征的短文本分类模型能更加准确地提取特征词,不仅仅是从频率而且从情感上判断特征的重要程度,相对于其余融合情感特征模型,因使用专业领域情感词典,所以对情感特征的权重赋值更加准确。实验表明,基于情感特征的特征选择方法在分类器上准确率和召回率都有所提高。今后进一步工作重点为:
基于情感特征的分类效果取决于情感词典的好坏,现阶段情感词典不够完善,情感数值不够细致,无法解决多义词的问题。词向量可以衡量2个词之间关联程度的强弱,无法分辨一个词的多重含义。之后将构建更加完善的情感词典以及寻找解决一词多义问题的解决办法。
猜你喜欢
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
中关村(2014年5期)2014-05-15
中原工学院学报(2014年4期)2014-04-01
