
LSTM-TextCNN联合模型的短文本分类研究*
2020-07-13 13:47:44李志杰耿朝阳
西安工业大学学报 2020年3期
李志杰,耿朝阳,宋 鹏
(西安工业大学,计算机科学与工程学院,西安 710021)
互联网的迅猛发展,带来数据量的爆炸,电子文档信息越来越多,怎样对这些电子文档进行准确的分类是一个非常重要的问题。文本分类是给一个文档(一段文字)“粘上”一个或多个标签,以便对文档进行分类和管理。
由于文本的特殊性,传统的文本分类模型的分类效果往往不够理想,使用联合模型进行文本分类的分类效果较优于单模型。文献[1]提出了一种ATT-Capsule-BiLSTM模型,使用多头注意力机制(Multi-head Attention),结合胶囊网络(CapsuleNet)与双向长短期记忆网络(BiLSTM)方法对文本进行多标签分类,有效的提升了分类的性能。文献[2]将LSTM与其变型门控循环单元(Gated Recurrent Unit,GRU)也应用于标题的语义理解与领域分类,实验验证其性能可达81%的F1值。文献[3]将卷积神经网络引入到了自然语言处理中的许多任务,且都取得了良好的处理效果。文献[4]提出了一种基于上下文的图模型文本表示方法,使用一种类似于PageRank的图模型来建立词和词之间的相互推荐关系,该方法克服了传统文本表示认为词和词之间相互独立 ,忽略词的上下文环境的缺陷。文献[5]较全面地讨论了贝叶斯方法、k近邻方法和AdaBoost等3种中文文本分类方法,作者采用3个模型,实现了朴素贝叶斯分类器、k近邻分类器和Adaboost分类器三个中文文本分类器,集成了一个实用性较强的实验系统。
上述作者在实验的过程中为了获取文本信息,大多使用只能获取单一文本特征的单模型,而这种单模型获取到的文本信息在一定程度上并不能代表整个文本的信息[6-8]。近年来,一些学者在研究中为了获取到更加丰富的文本信息,将单模型联合起来组成联合模型来对文本的信息进行提取[9-10]。本文提出了将LSTM和TextCNN组成一个联合模型,将两个模型提取到的多层次、多特点的文本特征进行融合来进行分类实验,并与传统的TextCNN和LSTM模型进行比较。
1 文本处理
1.1 文本预处理
由于文本整体上没有固定的格式,词语间没有明显的区分标记。因此在工作之前,必须对获得的文本进行相应的处理才能进行下一步的工作。
分词是文本预处理中很重要的一个步骤,它是将连续的字序列按照一定的规范重新组合成此序列的过程,以方便对文本进行向量化。国内外有许多已成熟的分词系统,在这里采用jieba分词组件,对文本进行分词处理,同时去掉无用的标点符号和停留词。
1.2 词嵌入
词嵌入就是将字典中的单词和词组映射为实向量,是一种将文本中的词汇转化为数值向量的方法,由于文本不能被计算机直接识别这一特殊的性质,词向量在自然语言的处理中就显得异常的重要。用低维向量表示词,可以避免矩阵稀疏的问题,同时可以捕捉词的语义信息。
Word2Vec是由谷歌公司创建的无监督模型组,以大型的文本语料为输入,可以生成词汇的向量空间,且空间维度低于One-hot,Word2Vec向量空间比One-hot更为稠密。Word2Vec提供了CBOW(Continuous Bag of Words)和Skip-gram两种结构。在 CBOW 结构中 ,模型通过周围的词预测当前词。Skip-gram 模型训练的目标是通过给定的当前词来预测周围词。在本文中选用Skip-Gram模型(如图1所示)训练词向量模型。其中WVN和WNV为权重矩阵。
2 模型搭建
2.1 TextCNN
卷积神经网络(CNN)具有卷积层和池化层,可以对局部特征进行提取。TextCNN是CNN的一个变型,它通过设置不同的过滤核的大小,可实现对不同大小的局部特征进行提取,可以使得网络模型提取到得特征向量具有多样性且更具代表性。
TextCNN的模型示意图如图2所示。
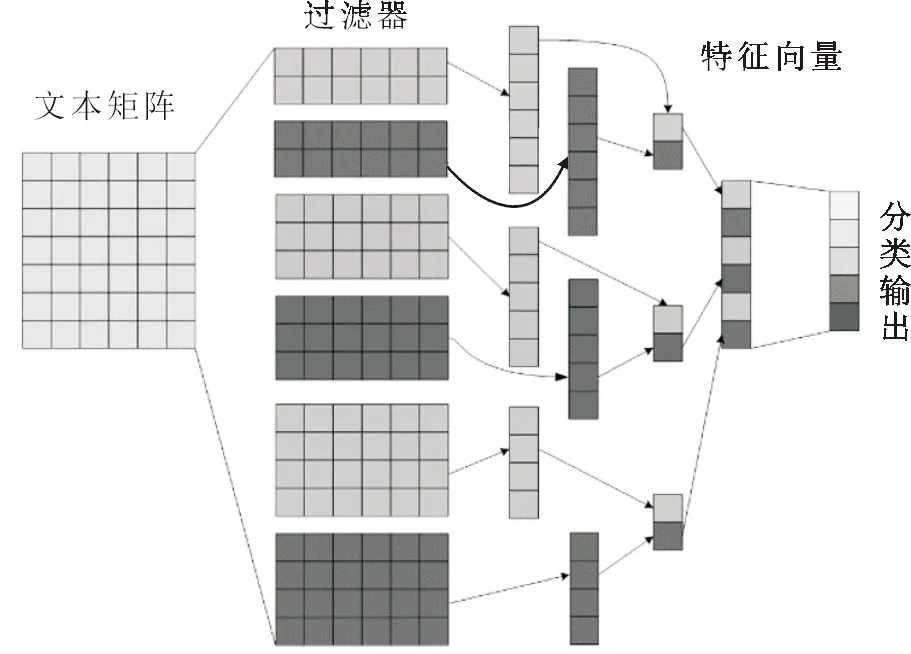
图2 TextCNN模型示意图
图2中,文本矩阵由词向量组成,过滤器的卷核大小分别为2,3,4,经过卷积池化得到特征向量,其维数=卷积核尺寸的个数×每种尺雨卷积核的个数,TextCNN分为以下4层:
① 卷积层:在本文的TextCNN模型中,有卷积核大小为2、3、4的三个过滤器,可以分别提取不同的文本特征。过滤器将大小为3×3×1的节点矩阵变化为单位节点矩阵,假设以wix,y来表示对于输出单位节点矩阵中的第i个节点,过滤器输入节点(x,y)的权重,使用bi表示第i个输出节点对应的偏置项参数,那么单位矩阵中的第i个节点的取值a(i)为
(1)
其中cx,y为过滤器中节点(x,y)的取值;f为激活函数。所有a(i)组成的单位向量就是卷积层所得的特征图记作A,A可以作为池化层的输入。
② 池化层:池化层的汇合操作,可以让模型更加关注某些特征而不是特征的具体位置,同时能够得到降维的效果,减小计算量和参数的个数,在一定程度上还能够防止过拟合的发生。
③ 融合层:将3个池化层所得的特征进行拼接,融合成一个对文本向量来说更具有代表性的向量。
④ 全链接层:通过在融合层之后加入隐含层和最后的Softmax层,来充当一个分类器,对文本进行最终的分类。
2.2 LSTM
长短时记忆网络(LSTM)是循环神经网路的一个变型,它能学习长期依赖。LSTM靠一些“门”的结构让信息有选择性的影响循环神经网络中每个时刻的状态,同时可有效的决定哪些信息应被遗忘,哪些信息应被保留,这一特性使得LSTM能够获取文本序列的长距离的特征的关系。
LSTM利用以特别方式交互的四个层的递归操作实现。c为单元的状态,i,f,o分别为输入门、遗忘门和输出门。LSTM的神经单元以前一时间步的隐藏,状态(输出值)ht-1来计算当前时间步的隐藏状态h′t计算式为
(2)
式中:W,U为每个门的两个权重矩阵;σ为Sigmoid函数;⊗和⊕分别为向量的内积和加法;g为内部隐藏状态,用当前的输入xt和前一状态ht-1来进行计算。给定i,f,o和g,根据时间步(t-1)上的状态ct-1,和遗忘门做乘法,得到时间步t的单元状态ct;和输出门做乘法,得到g。“门”利用Sigmoid函数进行调节,“门”输出0到1之间的值。遗忘门为0时会忽略掉以前所有的记忆,输出门为0时忽略掉新计算出的状态。
从以上LSTM神经单元的处理中,可以分析出它对以往的信息能够进行很好的记忆,同时对RNN(循环神经网络)出现的梯度消失的问题能够有很好的解决。
由于本文研究的是分类问题,所以,在构建LSTM模型时,在LSTM隐藏层之后添加了一个全链接层,之后再接输出层。LSTM模型如图3所示。
图3中,MAX_SEN_LEN为输入向量的长度,EMBE_SIZE为嵌入层的长度,HIDE_LAY_SIZE为LSTM模型中节点的个数。
2.3 LSTM-TextCNN
在TextCNN模型中,通过设置不同卷积核的大小来提取不同大小区域的的特征,但是由于文本的特殊性,TextCNN还是不能够获取到不同文本特征之间的依赖关系,这样取得的特征在一定程度上还是不能代表整个文本。长短时记忆网络(LSTM)的记忆机制在处理长文本信息方面具有较大的优势,它对以往的信息能够进行很好的记忆。因此,在本文中,将LSTM模型与TextCNN模型进行融合,取得的文本特征既有局部特征,同时还有全局特征。
在LSTM-TextCNN模型中,将相同的数据集分别交给LSTM和TextCNN进行训练,会得到两种不同的文本特征。将两种模型得到的特征混合在一起,进行进一步的分类处理。
在LSTM-TextCNN模型中,设置损失函数为交叉熵损失函数,交叉熵损失函数使模型的学习率能够被输出的误差控制,且收敛速度快,能够有效的避免学习率低的问题,同时使模型不陷入局部的最优解。交叉熵的公式为
(3)
式中:C为代价;x为实际输入;a为实际输出;y为期望输出;n为输入的总数。
LSTM-TextCNN模型如图4所示。
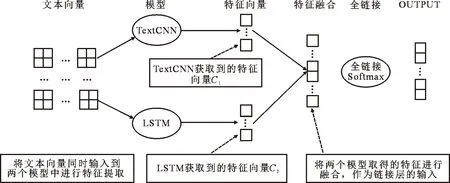
图4 LSTM-TextCNN模型示意图
Fig.4 Schematic diagram of an LSTM-TextCNN model
由于TextCNN模型获取到的只是文本的局部特征,而LSTM模型获取到的是文本更加长远的特征,两种特征都能在一定程度上来代表整个文本。在LSTM-TextCNN模型的融合层,可以使用Keras框架里面的Concatenta()函数对两个模型得到的特征进行融合,这样得到的特征向量C。C由两部分拼接而成,前半部分记作C1,代表由TextCNN模型获取到的文本特征,后半部分记作C2,代表由LSTM模型获取到的文本特征。因此,由C1和C2融合(拼接)而成的特征向量C中既有文本的局部特征,又有全局特征。因此可以将C作为全链接层的输入,来进行文本最终的分类。
3 实验及分析
3.1 数据集
本论文所使用得数据来源于故障诊断手册,里面的文档在去除无用的格式信息之后,得到的文本信息专业性强,且文本特征明显,用此数据集训练得出的模型在对专业领域内的文档进行分类整理有很大的参考作用。本数据集采集到的文档包括10 000余个短文本样本,将每个短文本作为单独的一条数据,按照文本的特征和结构,为其加上相应的标签(单标签)。标签共分为5类,具体类别见表1。

表1 文本分类类别以及说明
将样本按照9比1的比例分为训练集和测试集。对采集到的文档进行分词、去停留词和加标注后,再选用基于20 GB(1 GB大约能存5亿个汉字)百度百科词条、12 GB搜狐新闻和90 GB小说合并的语料进行训练得出的中文词向量模型来得到文本向量,此模型是根据各种情景下的大量中文语料所训练的模型,由此生成的词向量具有一定的普适性。
3.2 LSTM-TextCNN参数设置
实验在深度学习框架Keras下完成。
TextCNN在第2层一共设置了6个卷积层,卷积核大小分别为2,3,4,且每个卷积核对应的都有两个卷积层。卷积层的输入维度为(1,20,64),1代表深度为1。每个卷积层设置50个卷积核,且不使用全0填充。池化层的大小都设置为(2,2)。特征融合使用keras下的Concatenate函数将特征向量进行拼接,将拼接后的特征向量记作C1。
在LSTM模型中,输入维度为(20,64),同时将单元数量设置为50,这些单元都是并列的。将参数Droupout和Recurrent_droupout均设置为0.2。LSTM层的输出维度为(20,3),后加Resahpe层将其宽度调整为C1的宽度,得到C2。需要注意的是由于LSTM的复杂性,模型训练所消耗的时间量非常大。因此融合之后的特征向量C由以下代码所得。
C=Concatenta(axis=-1)([C1,C2])
特征向量C的前半部分是具有局部特征的特征向量C1,后半部分是具有局部特征的特征向量C2。这样以来,特征向量C既具有文本的局部特征,又具有全局特征,因此其能更加全面的代表整个文本。
在得到特征向量C后,调用Flatten层将特征向量C拉平,后接节点数分别为250和125的两个全链接层,再接节点数为5的softmax层。
3.3 实验及结果
为了体现本模型在数据集上的表现,实验中,在相同数据集的情况下分别采用了LSTM、TextCNN以及LSTM-TextCNN 3种不同的模型对数据集进行分类,实验步骤如下:
① 先对短文本语料进行标注,并进行预处理,执行数据清洗、分词、去停用词等操作。
② 对分词结果用已训练好的(中文)Word2 Vec模型进行向量化。
③利用LSTM、TextCNN及LSTM-TextCNN 3种不同的模型对数据集进行分类,并计算准确率。
不同模型的分类分类准确率见表2。

表2 不同模型的准确率
在不同模型的实验中,根据迭代步数在测试集上得到的准确率曲线如图5所示。
由图5可知,在相同的数据集上,LSTM-TextCNN模型的分类准确率明显高于LSTM和TextCNN。主要原因为LSTM-TextCNN能融合两种模型提取到的不同的文本特征,而融合后的文本特征可以更加具体的代表整个文本。
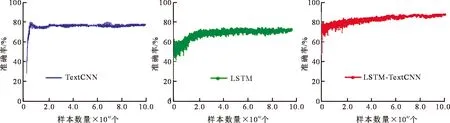
图5 不同模型准确率
4 结 论
1) 本文将LSTM模型和TextCNN模型结合成一种LSTM-TextCNN联合模型。通过收集故障诊断手册中的文档,并对文档进行相应的预处理,利用Woed2Vec模型将语料映射成计算机可以识别的向量,且搭建LSTM-TextCNN模型,完成对模型的训练,并与LSTM和TextCNN单模型进行了测试比较。
2) LSTM-TextCNN联合模型的分类准确率为83.3%,比TextCNN模型高4.2%,比LSTM模型高9.1%。文中方法获取的信息更具有代表性,分类准确率更高。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2019年11期)2019-07-04 00:34:38
许昌学院学报(2018年4期)2018-05-02 12:27:37
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中华建设(2017年1期)2017-06-07 02:56:14
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
