
海量数据的分析研究
2020-07-08 02:00黄素萍常加强
科学技术创新 2020年15期
黄素萍 常加强 高 妍
(咸阳师范学院 计算机学院,陕西 咸阳712000)
1 概述
近十年来,互联网迅速发展,资讯来源也从过去的报刊杂志、电视、电台,变成当下的网络新闻门户、博客网站、微博、推特等各种各样的网络舆情平台。获得资讯的方式也从过去的定时播报、定时收听收看变成了现在的即时订阅,随时随地访问。网络已成为人们获取各类信息的重要渠道。然而,网络中每天如潮水般的大量信息,使人们很难快速获取到自己想要的信息,因此,如何从海量的数据中快速筛选、过滤出用户需要的重要信息的分布状况,帮助用户快速获取有用信息,已成为当今研究的热点之一。本文以新闻信息为例,介绍了海量新闻信息的分析处理过程,以可视化的结果,向用户展示了热点新闻的分布状况,帮助人们快速了解掌握热点新闻信息。
2 海量数据分析的相关技术
在进行海量新闻信息的数据采集、数据消费、处理和数据分析过程中涉及到如下核心技术:
2.1 Hadoop
Hadoop 是一个分布式处理框架,是大数据技术中最核心的组件,像Hbase,Spark,ZooKeeper 都是基于Hadoop 搭建的[1]。它里面有两个核心的组件Hdfs 和Mapreduce, 其中Hdfs 用来存储海量数据,Mapreduce 用来进行数据计算。
随着Apache Hadoop 系统开源化的发展,Hadoop 平台从最初只包含HDFS、MapReduce、HBase 等基本子系统,到现在已演变成包含很多相关子系统的完整的大数据处理生态系统[2]。
2.2 ZooKeeper
ZooKeeper 是集群的管理者,它监督着Hadoop 各个组件集群的节点,当某一个集群的节点挂掉时,ZooKeeper 中flower 就会检测到接收请求并向observer 传递消息,observer 接收到请求后会将请求转发给leader,随后leader 就会及时更新状态,所以ZooKeeper 主要是用来协调Hadoop 各个组件集群的工作,当集群中一个节点出现故障,ZooKeeper 会自动检测正常节点,并安排它进行工作,保证集群的正常运行。ZooKeeper 只适合存储一些少量信息如配置文件、发布信息、订阅信息等,而不适合存储大规模的信息。Hadoop、Storm、消息中间件、RPC 服务框架、分布式数据库同步系统,这些都是Zookeeper 的应用场景。
2.3 Flume
Flume 是一个可以从不同的数据源有效的进行数据采集,并将数据传输到数据中心的分布式、可靠、和高可用系统,它可以接受任何数据源,在日志系统中进行设置,用于收集、聚合从许多来源传来的大量流数据事件,并将它们转移到一个中央数据存储中,它提供对数据进行简单处理,并写到各种数据接收方。
2.4 Spark
Spark 是一个开源的基于内存计算的集群计算系统,包含了Spark Core、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX 等大数据领域常见的各种计算框架[3]。其中Spark Core是离线计算,主要对已加载的数据进行计算处理;Spark Streaming 是实时流式计算,主要对传输中数据进行计算;Spark SQL 是交互式查询,通过SQL 语句查询数据;Spark MLlib 用于机器学习;Spark GraphX 用于进行图计算[4]。这些组件可以使它完成一站式的大数据任务。同时,Spark 提供了更多的数据集操作的方法,帮助开发人员处理更复杂的任务。
3 海量数据的分析过程
3.1 数据的采集
目前,数据采集主要使用爬虫采集器和网络爬虫,两种网络爬虫技术。网络爬虫获取数据的过程较繁琐,需要用户编写代码,效率较低,容易出现问题。采用爬虫采集器无需用户编写代码,操作方便,效率较高。本次采用八爪鱼采集器获取网络新闻数据。
八爪鱼采集器获取数据的流程:先采集器选择采集数据方式,设置要采集数据的网址,如https://news.sina.com.cn/china/并保存,选择相应的流程滚动设置,设置要爬取的数据项(如,新闻标题),保存设置后可开始采集数据。数据采集完成,选择导出数据格式,如Excel 格式文档。
3.2 数据预处理
前期从各大新闻网站爬取的大量新闻数据格式杂乱无章,没有统一格式,没有规律,各类符号都混杂在一起,如果直接使用这些原始新闻数据进行处理,既浪费精力,工作效率又低。所以要对采集的新闻数据进行预处理,即是对新闻数据进行统一格式化处理,此处是将原始新闻数据格式统一转换成以逗号分隔的连续字符串。具体的做法是将数据集文档格式转换为log类型文档,再使用命令cat,将数据集文档中的制表符,空格符等更换为逗号。
3.3 数据清洗和存储
接下来需要在Hadoop 数据处理集成平台中进行数据的处理。这个过程需要进行Flume 和Kafka 系统的安装和部署。
3.3.1 数据清洗
数据清洗主要是把有用的数据留下,无用的数据删掉。它是整个数据处理分析过程中最核心的一个环节。这里使用了SparkStreaming 并行计算框架,通过其Transformation 转换算子进行数据的转换和处理,对实时传输过来的新闻数据进行清洗,从中获取新闻标题、分类名、新闻网站等信息,分别统计出标题出现的次数,标题分类名和新闻网站出现的次数。
数据清洗的过程为:先获取Kafka 从Flume 中消费的数据,同时创建DStream。DStream 是以键值对的形式存在,对DStream进行Map 操作获取到它的value 值,即所有实时传输进来的数据,返回一个新的DStream。再对DStream 进行Map 操作返回多行数据,随后用函数获取到新闻标题、分类名、新闻网站等关键数据,最后进行聚合操作,获取各个项目名对应的出现次数。
3.3.2 数据存储
清洗后的数据需要进行存储,这里采用MySQL 数据库完成。
数据存储的具体实现:先将获取到的Dstream 转换成Spark中的RDD,再对RDD 进行分区,然后遍历每个分区中出现的信息。并和MySQL 数据库进行连接,调用存储过程将对应数据插入到相应表的字段中,完成数据存储。
进行数据存储的表有三张:标题表(Title),分类表(Classify)和新闻网站表(Url)。标题表主要存储新闻的标题名和出现的次数。分类表存储新闻分类名和出现的次数。新闻网站表存储新闻网站名和出现的次数。
3.4 数据分析和结果展示
3.4.1 程序框架及插件简介
本次研究开发的程序使用Spring Boot 和Echarts 框架。Spring Boot 框架可以非常容易和快速的创建应用程序,从而使开发人员不再需要定义样板化的配置。Echarts 是一款非常优秀的可视化前端框架,支持如IE,Chrome,Firefox 在内的多种浏览器。它提供了丰富的API 接口以及文档,通过合理设置并结合后台传送的JSON 数据,即可展示所需的数据主题。
3.4.2 程序功能设计和实现
通过研究,新闻标题出现的频度可以反映新闻话题的热度,程序基于已处理的新闻数据,按新闻出现的次数,结合echarts图表库,展示出排名前5 的新闻话题。同时,基于排名的新闻话题,分别对其所属的新闻类型和来源的新闻网站的次数进行统计,获得热点新闻所属的新闻类型和来源网站统计结果,展示出排名前10 的新闻领域和排名前6 的新闻网站。

图1 热点新闻话题排名
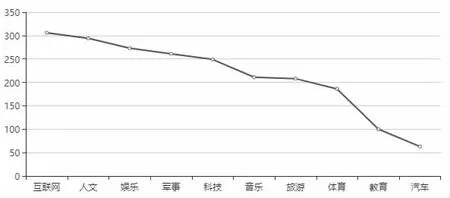
图2 新闻分类展示结果
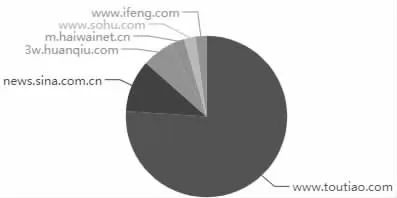
图3 新闻网站展示结果
4 结论
本次研究是基于数据采集、数据处理和数据分析等技术,通过采集器采集新闻数据,用Kafka 和Flume 集成环境对海量的新闻数据进行传输,使用SparkStreaming 并行计算框架进行数据处理,将数据存储在MySQL 数据库,最后结合Echarts 可视化插件,将热点新闻数据状况以动态,以更直观的方式展示热点新闻的分布信息。由于各方面的局限性,本次工作只是在现有技术的基础上,做了一些具体的实现。今后在海量信息的处理方面,还需进一步的深入研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
轻工机械(2022年1期)2022-03-23
现代仪器与医疗(2021年1期)2021-06-09
陕西科技大学学报(2020年5期)2020-10-12
当代陕西(2019年14期)2019-08-26
消费导刊(2018年10期)2018-08-20
计算机测量与控制(2017年12期)2018-01-05
学理论·下(2016年11期)2016-12-27
中学数学杂志(初中版)(2016年5期)2016-11-01
科教导刊·电子版(2016年21期)2016-08-23
