
大数据企业技术创新的主要影响因素
2020-07-03 10:27梅洪常
科技管理研究 2020年12期
刘 畅,梅洪常
(重庆工商大学管理学院,重庆 400067)
1 研究背景
随着大数据在社会经济发展中越来越重要,我国在“十三五”规划(2016—2020 年)中明确指出大数据是一种基础性战略资源,其利于产业升级。大数据企业便是在此类国家政策的号召之下出现的新兴企业,其业务集中于数据资源的采集、存储、分析及应用[1]。为更好发挥大数据企业在产业升级中的作用,有必要认清我国大数据企业发展现状。相关研究表明,虽然我国大数据企业增速快,有着巨大发展潜力[2],但赵传仁等[3]学者研究发现近年来大数据企业的全要素生产率为负增长,并指出主要原因在于技术效率不足。因此本文主要从中低技术创新水平大数据企业的主要影响因素出发,以采取“补短板”方式提升我国大数据企业的整体技术创新水平,以改善大数据企业的生产力较低局面,进而增强大数据企业在产业升级和促进数字经济与实体经济融合中的重要作用。
目前直接关于大数据企业技术创新影响因素评价的研究较少。为进一步认识与提升大数据企业技术创新能力,本文基于技术创新理论和大数据数量极大(volume)、类型繁多(variety)、增长与处理速度快(velocity)及价值密度低(value)的4V 特点[4],并通过文献研究,构建了大数据企业技术创新评价指标体系;然后通过层次分析法(AHP)找出影响大数据企业技术创新的主要影响因素;接着采用K-Means 动态聚类方法分析大数据企业整体发展情况,结合动态聚类指标的可操作性和合理性,选取大数据企业技术创新主要影响因素中的相关定量指标作为动态聚类指标,找出技术创新处于中低水平的大数据企业,再通过熵值法分析其技术创新的主要影响因素。通过AHP、K-Means 聚类和熵值法的集成应用,既更加明确地认识我国大数据企业技术创新能力的主要提升方向,又更了解我国大数据企业技术创新的整体格局,并可判断出中低水平大数据企业技术创新的重心所在。
2 基于AHP 判断技术创新的主要影响因素
本文基于技术创新理论、大数据4V 特点和文献研究构建大数据企业技术创新评价指标体系,采用层次分析法得出各指标权重情况,据此分析出大数据企业技术创新的主要影响因素。
2.1 得出评价指标权重
层次分析法是一种系统分析方法,由美国运筹学家Saaty[5]于20 世纪70 年代提出,其优点在于对非结构化定性问题转化成半定量分析,给多准则评价决策提供参考意义。AHP 的步骤是首先通过构建大数据企业技术创新评价指标体系的层次结构模型,再据此建立判断矩阵,由通过一致性检验的判断矩阵得出各指标权重结果。
2.1.1 构建评价指标体系的层次结构模型
本文构建的大数据企业技术创新评价指标体系的层次结构模型以大数据企业的技术创新评价为目标层,以技术创新理论在管理学、经济学和社会学中的不同学科视角为准则层,以产品创新、激励机制和知识资源等要素作为指标层。回顾技术创新理论发展概况,技术创新理论总体上依次经历了经济学、管理学和社会学3 个发展阶段[6]16-22:首先1934 年熊彼特[7]4开始从经济学视角研究技术创新,随后学者们将他的技术创新理论部分分成产品创新与工艺创新两个层面;然后随着企业技术创新逐步居于企业获取与维持竞争优势的核心地位,大批学者开始从管理学视角研究技术创新,主要从缩小技术创新成果商业化层面来理解技术创新,国内学者则主要从协同创新角度进行思考技术创新;最后在技术创新研究的高度专业化,且需要企业之间建立起密切合作关系才能满足技术创新需求的背景下,形成了社会学视角下的技术创新理论,也称为技术创新社会网络理论。社会学视角的技术创新重点关注外部知识的获取和利用,学者们证明了知识对于企业竞争力提升的重要性[6]16-22。
本文结合大数据企业技术创新影响因素的实际情况,将技术创新分析视角细化为从管理经济学、企业经营效益以及技术创新的社会网络理论三方面,结合大数据4V 特点,并整合企业技术创新相关文献[1-3,8],得出大数据企业技术创新评价指标体系的递阶结构模型如表1 所示。

表1 大数据企业技术创新评价指标体系递阶层次结构模型
2.1.2 建立判断矩阵
判断矩阵是基于递阶层次结构模型所得,作用在于判断各个指标相对重要程度。根据表1,本文构建4 个判断矩阵,具体见表2 至表5 所示。
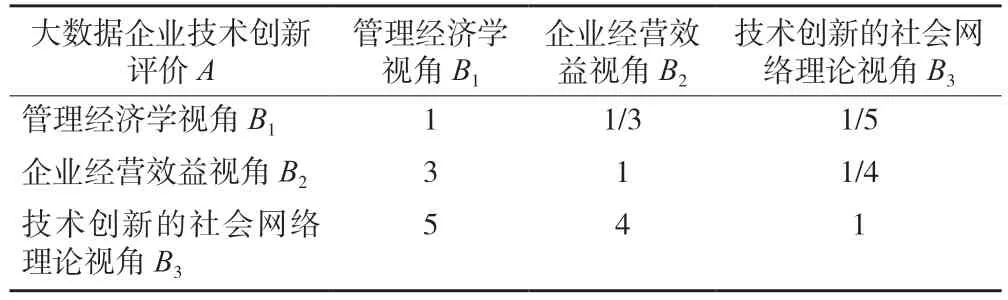
表2 判断矩阵A-B

表3 判断矩阵B1-C
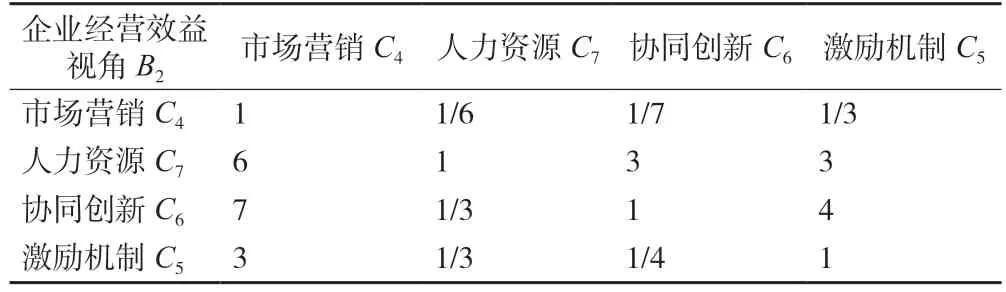
表4 判断矩阵B2-C

表5 判断矩阵B3-C
2.1.3 一致性检验
以B1-C判断矩阵为例,求得各指标权重并进行一致性检验,求各指标权重步骤如下:先得出B1-C判断矩阵每列之和,再将原有各矩阵元素分别除以每列元素之和,从而得出新的矩阵,再将矩阵每行相加得出最后通过归一化得出指标权重,公式为:如表6 所示。

表6 管理经济学视角下技术创新的B1-C 判断矩阵指标权重
接着求最大特征根,公式为:


表7 判断矩阵在不同阶数下的RI 对应参照值
2.1.4 评价指标权重结果
通过对各个判断矩阵的计算和一致性检验,得出各个指标权重,如表8 所示。从一级指标权重情况来看,技术创新的B3视角权重值最高,原因在于社会专业分工越来越集中,知识的重要性越来越重要,尤其是对于知识经济时代下的大数据企业而言;其次是B2视角,随着技术创新在企业竞争优势获取的重要性越来越大,企业慢慢通过内部优化来进行技术创新,大数据企业作为新兴企业也离不开企业的经营管理;最后是B1视角,这是基于熊彼特[7]4-10创新视角的技术创新,是技术创新理论的最初阶段,对于大数据企业,其重要性相对较小。
从二级指标权重情况看,知识资源权重值最高,原因在于知识对于大数据企业这样的知识密集型企业,知识对企业的业绩有着极其关键的影响;其次是大数据技术应用效益,大数据企业的数据收集、储存、分析及应用能力是保证决策可靠的前提;接着是人力资源方面,大数据企业作为知识型企业,对优质人力资源的要求较高,其技术创新更加需要尖端人才的助力;关系网络、产品创新、协同创新3 个指标权重情况大致处于同一层级,关系网络反映了大数据企业知识和信息来源是否充足,产品创新是业绩提升的重要因素,协同创新可以从侧面反映大数据企业内部数据共享程度;激励机制作为企业鼓舞士气的重要法宝,对大数据企业技术创新起着辅助性作用;工艺创新、市场营销和企业规模权重情况大致处于同一层次,工艺创新在大数据企业里体现较少,主要是企业人员合作方式的改进,市场营销反映了大数据企业技术创新成果是否快速进行商业化以及得到市场认可的程度,根据文献,企业规模和技术创新有着正相关关系,而大数据企业里企业规模对技术创新直接影响较小。
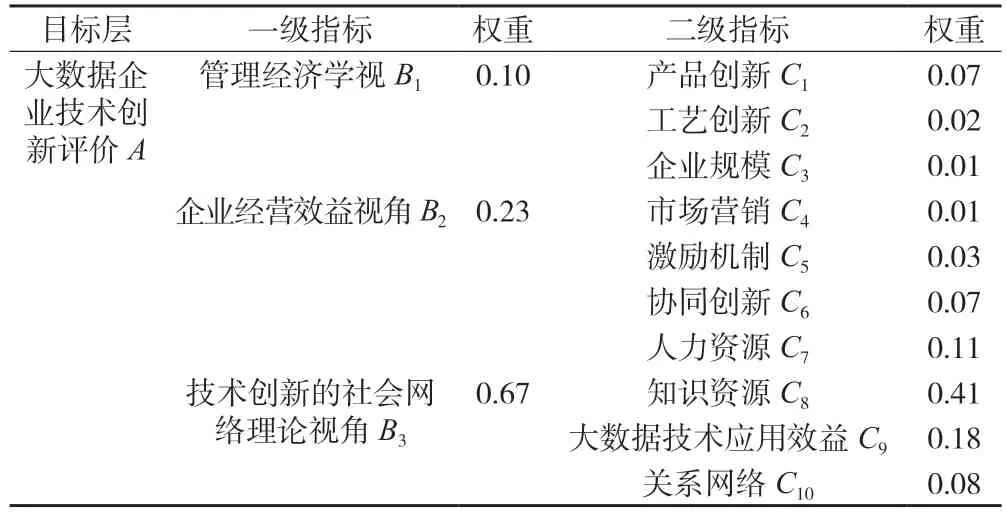
表8 大数据企业技术创新评价指标权重
2.2 主要影响因素
基于AHP 所得的权重结果判断,影响大数据企业技术创新的主要因素有以下6 个,其权重值之和达92%:一是知识资源量,如专利数、无形资产比例等;二是大数据企业的大数据技术综合应用效益,体现大数据企业的综合数据能力;三是大数据企业的人力资源情况,主要表现大数据企业的人才力量,技术创新直接来源于人才的努力;四是大数据企业的关系网络;五是产品创新;六是协同创新。
3 基于主要影响因素的大数据企业聚类
根据AHP 得出的大数据企业技术创新的知识资源量等6 个主要影响因素,同时考虑动态聚类操作的可得性、简便性及合理性,选取主要影响因素中合适的相关定量指标作为动态聚类的标准指标,再通过K-Means 算法得出大数据企业技术创新的整体状。
3.1 K-Means动态聚类
动态聚类又称为逐步聚类法,其与系统聚类、模糊聚类等方法都属于聚类分析法的一种,对大样本数据处理有较强优势。K-Means 算法是动态聚类常用方法,其主要思想在于采用距离作为样本相似性的评价标准,样本距离与样本相似度之间是正相关关系[9]。K-Means 动态聚类常采用欧式距离来度量样本之间的相似度,两个样本i、j之间的欧式距离公式记为:
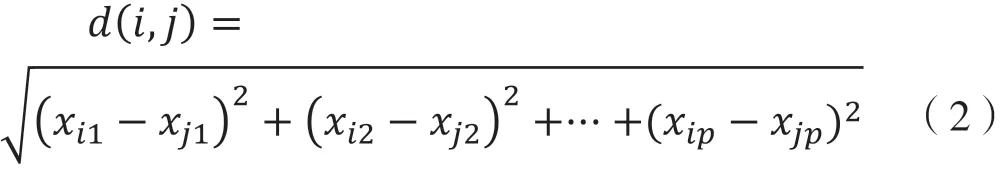
公式(2)中:i为样本的第j个属性指标(j=1,2,…,p)记为
K-Means 动态聚类的划分原则在于使样本和簇中心之间的距离最小。样本与簇中心之间距离记为同时簇与簇之间的距离最大,簇与簇之间距离记为其中表示簇的聚类中心。聚类目的是实现组内距离最小化且组间距离最大化。用误差平方和SSE 表示K-Means 动态聚类质量的目标函数,公式为:


K-Means 动态聚类计算过程如下,第一步随机选取K个样本作为初始聚类中心;第二步分别计算各个样本到每个初始聚类中心的距离,并将各样本分配到离自身最近的聚类中心;第三步重新计算出新的K个聚类中心。如果新计算出的聚类中心和初始聚类中心不同,则需不断重复第二步与第三步过程,直到质心不变。
3.2 样本选取
借鉴茶洪旺等[1]学者对我国大数据企业层级类型划分方法及部分样本,本文选取各个层级的上市大数据企业共19 家作为样本,如表9 所示。

表9 我国大数据产业链代表性企业
3.3 样本数据来源
本文所选19 家样本上市大数据企业的数据均依据2017 年上市公司所公开披露的年报信息,以及从CCER 中国经济金融数据库整理所得。
3.4 动态聚类评价指标
首先选出动态聚类评价指标,然后将指标标准化,以消除量纲不利影响。
3.4.1 评价指标选取
结合层次分析法得出的知识资源量等6 个影响大数据企业技术创新的主要影响因素,考虑定量指标可得性和合理性基础上,再结合文献研究构建K-Means 动态聚类的评价标准指标[10-16],如表10所示。

表10 大数据企业技术创新整体水平动态聚类评价指标
3.4.2 指标标准化
由于各个定量评价指标的单位不同,为了消除量纲的影响,本文采用离差标准化方法进行指标的标准化。由于定量指标都是数量值越大越利于大数据企业进行技术创新能力提升,记标准化后的指标为:

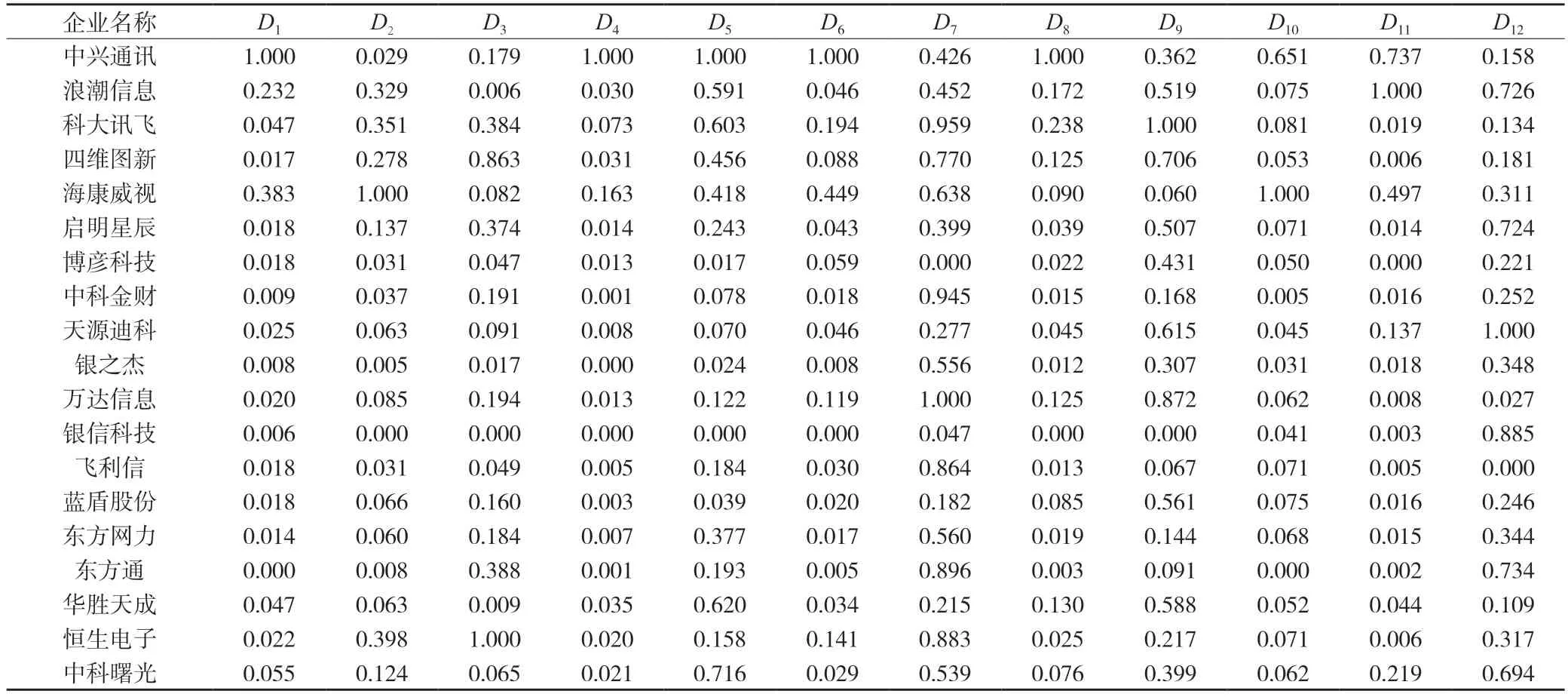
表11 样本评价指标数据预处理
3.5 结果
本文借助SPSS 软件计算,迭代两次后收敛,并得出初始中心间的最小距离为1.846。运行结果分别如表12、表13 所示。通过表12 可知,第一类企业的总体均值为0.628 5,第二类企业的总体均值为0.382 5,第三类企业的总体均值为0.185,所以判断第一类大数据企业技术创新整体水平“较强”,第二类大数据企业技术创新整体处于“中等”水平,第三类大数据企业技术创新整体居于“较弱”水平。

表12 样本企业技术创新整体水平聚类结果
根据表12、表13 可知,处于大数据产业链各个层级的样本企业的技术创新整体水平,实力较强的企业居于少数,只有1 家企业达到此水平,只占5.26%;居于中间实力的企业有2 家,占比为10.53%;大部分企业的技术创新整体水平处于较弱状态,共有16 家,占比最高,为84.21%。本文得到的动态聚类分析结果与赛迪智库于2017 年发布的我国大数据企业整体水平基础画像以及技术研发评估报告结果大致相符:从大数据企业技术创新评价指标总体均值来看,水平较强的大数据企业明显高于其他类别大数据企业[17],技术创新整体水平处于“中等”和“较弱”的大数据企业之间差别较小,表明较弱大数据企业之间竞争激励。

表13 样本企业技术创新水平动态聚类结果
4 中低型大数据企业技术创新主要影响因素
本文通过聚类分析发现,技术创新水平处于中下的样本大数据企业占比达94.74%,因而提升这类大数据企业技术创新水平具有十分重要的经济价值。提升技术创新水平较差大数据企业的技术创新能力,需要重点把握关键环节与方向,因而为进一步探析技术创新处于中低水平的大数据企业在技术创新上的主要影响因素,本文采用客观性和有效性较强的熵值法进行分析。
4.1 熵值法
熵值法作为一种客观赋权法,依靠客观指标数据进行实证研究,因而可靠性与科学性较强,多被学者应用于评价研究和求取各个指标权重的相关问题中。熵值法无须设置参数、函数及相关假设,操作简便,因而应用范围较广,如田雪莹[18]和蔡玉胜等[19]分别将熵值法用于我国城镇化水平测度和京津冀区域发展质量评价研究中。本文采用熵值法,可以在一定程度弥补前文所应用到的层次分析法在非结构化定性问题中存在一定主观性这一不足,为大数据企业技术创新水平提升提供了另一个观察角度。
4.2 熵值法的计算及结果
根据研究目的,本文以浪潮信息等18 家中低技术创新水平的大数据企业为样本,以表7 中数值为数据来源。第一步是通过样本数据建立初始指标数据矩阵,即以18 家样本企业的每家企业的12 个指标构成一个18 行12 列的矩阵。第二步是进行指标数据再标准化,由于在K-means 动态聚类分析中已经对指标进行了离差标准化处理,熵值法计算部分直接省去第二步。第三步是计算各样本指标的比重,公式记为:

式(6)中:Pij为各样本指标的比重;ej为各指标的熵值。计算结果如表14 所示。
第四步是通过以下公式(7)计算各指标的熵值:

第五步是计算各个指标的有效性,公式记为:

第六步是算出各指标的有效性比重,即求出各指标权重,公式为:


表14 样本中低型大数据企业技术创新影响因素权重
4.3 结果分析
根据熵值法计算结果,样本中低型大数据企业创新技术的最主要影响因素是关系网络中的前五名供应商合计采购金额,这与前文采用层次分析法得到一级指标权重值最大的技术创新的社会网络理论视角相符合。根据技术创新的社会网络理论,大数据企业建立社会关系网络,可以帮助其获取外部先进的知识而增加自身数据库资源;通过与供应商合作,直接购买获取大数据企业自身业务及其他发展所需的资源。其中很重要的一项资源就是知识资源,通过直接购买获取大数据企业所需的知识资源,这种方式与企业内部员工创造知识相比具有更高的效率:员工自身对知识的创造需要花费一定的培养成本(经济成本和时间成本等),这种知识资源获取方式的效果并非立竿见影,并且在一定程度上面临失败风险、增加沉没成本;而大数据企业直接从外部获取知识资源,这种知识获取方式的针对性强、时间效率较高。其次权重值位居第二的是产品创新下的营业收入和大数据技术应用效益下的利润总额。大数据企业的产品创新带来的直接影响在于生产出新产品,或是对旧产品的功能升级,其直接带动营业收入的增加;同时大数据企业在产品创新过程中慢慢积累了技术创新所需的经验与知识,相关专利与发明的申请与授权则是知识经验积累的典型证明,显著影响着大数据企业技术创新水平的提升。大数据技术应用效益主要包括数据挖掘、储存、预处理及分析和应用等方面的效益。数据本身作为一种重要资源,可以通过合理的挖掘与分析,得出其中有价值的数据资源,进而转化成极具意义的知识资源,推动大数据企业技术创新水平的提升。而其中大数据技术应用效益则是衡量大数据企业将大量数据转化为有用的知识资源的能力与效率,在绩效上表现为能够为大数据企业增加多少利润。接着是协同创新下的硕博学历员工数。协同创新是企业内部的一种知识分享机制,而知识的分享需要依靠人才彼此之间不断的交流,人才数量越多越利于创新理念数量和创新效率的增长,也利于新知识的产生。根据熵值法计算结果,作为技术创新核心力量的人才并未处于一个较高的权重值状态。结合本文采用硕博学历员工数作为协同创新的代替指标,出现这种状态的原因可能是硕博学历员工虽然在一定程度上具有科研能力,但是其对大数据企业技术创新水平提升的作用还不是特别明显。硕博学历员工需要进一步提升相关技术创新能力;大数据企业自身也应认识到,企业技术创新并不是只看高学历员工数量的多少,应该更加看重其质量,因此在人才引进时关注具有一定创新能力的高学历人员,培养更多有实践价值的技术创新人才。
5 结论与建议
本研究的实证结果表明,将层次分析法、K-Means 聚类和熵值法集成应用在分析大数据企业技术创新整体水平的主要影响因素以及中低型大数据企业技术创新的主要影响因素上具有可靠性。本文的结论如下:一是可以根据AHP 判断出大数据企业技术创新的主要影响因素有知识资源量、大数据技术的应用效益、人力资源、和外界的关系网络以及产品创新与协同创新,为我国大数据企业提升技术创新水平提供参考方向;二是采用K-Means 聚类分析发现大数据企业在技术创新上呈现“领先企业少而强,长尾企业多而弱”的非均衡格局,表明我国大数据企业整体技术创新水平需进一步提升;三是采用熵值法揭示中低技术创新水平的大数据企业的技术创新主要受到关系网络(采购金额)、产品创新(营业收入)、大数据技术应用效益(利润总额)、硕博学历员工数和研发投入金额的影响。
根据相关结论,本文提出以下建议:第一,对于大数据企业研发投入占比普遍较低的问题,建议政府增加对大数据企业研发投入的补贴,为大数据企业增加研发投入营造良好政策环境;同时,大数据企业自身应该注重协同创新和合理的高管激励对研发投入的正向促进作用。第二,对于技术创新水平较强的大数据企业存在无形资产占比较低问题,建议政府进一步完善知识产权保护等相关政策,以利于大数据企业无形资产的维护与增值;同时,此类大数据企业应建立与完善员工知识创造的相关奖励制度(如加大对申请与获取专利发明授权等方面的奖励与考核),多开展企业内部知识经验交流活动,注重不同岗位员工之间的知识交流和现有知识的整合,以利于新知识创造,进而利于大数据企业开发无形资产。第三,对于技术创新水平中等的大数据企业面临硕博学历员工数较少问题,建议政府深入改革相关体制以利于促进人才流动与培养;同时,大数据企业自身应加强与高校的合作交流,为硕博在读生提供实习机会,并尽力了解与满足硕博学历人才的个性化内心需求,以吸引和留住高学历人才。第四,对于技术创新水平较弱的大数据企业研发人员数较少和利润总额偏低问题,建议政府结合此类大数据企业实际情况进行相关资源的合理配置;同时,大数据企业自身应加大与技术创新能力较强企业之间的合作创新,引进外部先进技术与知识资源,逐步实现由模仿创新到自主创新的转变,注重企业内部员工的深造与技术创新能力的培养,逐步实现产学研相结合,进而提升综合业务能力。
猜你喜欢
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
现代计算机(2018年27期)2018-10-25
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
读与写·教育教学版(2017年10期)2017-11-10
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
南都周刊(2015年4期)2015-09-10
