
具有约束的规范混料模型最优设计
2020-06-18 06:10张崇岐
广州大学学报(自然科学版) 2020年6期
苏 晴, 张崇岐
(广州大学 经济与统计学院, 广东 广州 510006)
混料试验设计具有特殊的研究意义:单独使用某种要素的效果不如(或优于)几个要素一起使用产生的效果[1].这几种要素可以被认为是几种特性指标,根据它们的作用效果不同称几种要素间有对抗(或协同)作用,而这些特性指标与混料试验中的混料占比息息相关[2].在混料试验中响应指标只与各成分在配方中所占比例有关而与总量无关.混料试验的目的是考察各成分所占比例对响应指标的影响,从而找到最优的配方比例.
混料试验在实际生活和工业领域应用广泛,在农业上,李红伟等[3]在磷酸盐对肉制品持水力影响的研究中通过混料试验设计进行研究,王鑫系[4]运用混料模型研究西瓜包膜控释尿素配比的问题,王晨光等[5]在做超微粉碎预处理沙柳原料酶解条件优化中同样运用了混料试验.在工业上,黄垒等[6]进行了铁基金刚石钻头胎体配方的混料试验研究,贾春林等[7]研究了基于混料试验优化煤气化复配助熔剂的问题,王大成等[8]基于混料的理论建立了混合垃圾燃烧试验及活化能回归方程的建立.在理论研究中,张崇岐等[9]对混料试验的变量选择AIC准则进行了研究,李光辉等[10]研究了具有复杂约束混料试验的渐进D-最优设计,燕飞[11]将混料模型结合组合投资进行了研究.
混料试验设计在传统的求最优的过程中有不足之处,或是优化的效率较低,或是获得的最优解为局部最优解等现象.按照最优化的结果,可把最优化方法分为局部最优和全局最优.在实际问题中,所要求得的最优解常为全局最优解.为了弥补这一类的情况发生,从20世纪50年代起进化算法得到了发展.通常情况下,进化算法被认为是由遗传算法、进化规划和进化策略组成的[12].本文主要研究遗传算法,首先介绍了混料模型的基础知识并说明混料模型使用遗传算法求解的基本原理,然后通过实例分析说明运用遗传算法求解混料的最优设计的过程,并验证运用遗传算法求解混料试验模型是具有可行性且获得的结果是较优的,最后进行了总结与展望.
1 具有约束的规范混料模型最优设计
一般混料模型为
y=βTf(x)+ε,x∈,
其中,y为响应变量,x=(x1,x2,…,xq),β为未知参数组成的d维列向量,f(x)为x∈χ上给定的d维函数列向量,χ为一个封闭紧集,ε是均值为0方差为常数的随机误差.每个分量都必须表示成混料的百分比.对于q分量的混料试验设计,各分量比例x1,x2,…,xq需要满足基本约束条件
从而由各分量构成了(q-1)维正规单纯形
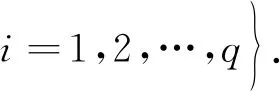
在实际应用中,混料试验往往还受其他约束条件的限制,此时混料试验域可表示为
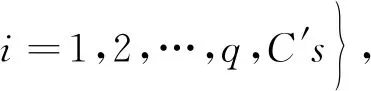
其中,C′s为附加的约束条件.常见的附加约束条件主要有三种形式[13]:
(1)兼有上、下界约束的条件
SCCs:0≤ai≤xi≤bi≤1,j=1,2,…,q;
(2)线性约束条件

(3)非线性约束条件
NCCs:aj≤φj(x1,x2,…,xq)≤bj≤1,j=1,2,…,l,
其中,aj,bj都为已知的常数,φj(x1,x2,…,xq)是各变量的非线性函数.
混料模型因其特殊的试验域,若使用常规的完全多项式模型,无论试验设计如何,其信息矩阵总是退化的.因此,在一般混料试验设计中常选择Scheffé规范多项式模型,常用的q分量m阶混料规范多项式形式如下:
当m=1时,
当m=2时,
当m=3时,
由上可知,模型参数个数会随着分量q和模型阶数m的增加而快速增加.
遗传算法是一种模拟生物界的自然选择机制和仿照自然界的遗传机制的随机搜索算法,其本质特征在于群体搜索的策略和简单的遗传算子[14].群体搜索策略可以实现整个解空间上的分布式信息采集和探索,遗传算子可以降低一般启发式算法在搜索过程中对人机交互的依赖性[14].
基于遗传算法求混料模型最优的基本步骤如下:
(1)编码.将一个混料试验设计的试验域转换到遗传算法所能处理的搜索空间;
(2)选择.在混料试验域转换到的搜索空间中选择适应度较强的个体,从而产生新的群体;
(3)交叉.在混料试验域转换的搜索空间中,进行两组试验点的选择,然后交换选择出来的两组试验点的某个或某些混料分量.其中,交叉算子的设计需要考虑两方面:如何确定交叉点位置和如何进行部分基因的交换;
(4)变异.以较小的概率对混料试验点的某个或部分混料分量值进行改变.变异可以避免混料模型得到的最优解为局部最优解,并防止早熟现象的出现;
(5)适应度函数.是度量在混料试验域转换的搜索空间中个体适应度的函数.该函数基于实例情况中的目标函数所确定,主要作用是区分群体中个体的好坏;
(6)结合混料模型和实际情况选择控制的参数.该参数的选择会影响算法的收敛性,混料模型中的群体规模大小会对收敛性和计算效率两个方面有所影响;
(7)根据模型需求分析出满足实际的约束条件并加以处理.
在实际运用的过程中,通过遗传算法求混料模型最优的工作流程[12]如下:
迭代开始:
t=0,
初始化:
P(0)={a1(0),a2(0),…,an(0)},
适应性评价:
P(0)={f(a1(0)),f(a2(0)),…,f(an(0))},
循环条件:
T(P(t))≠truedo,
选择:
P′(t)=s(P(t),ps),
交叉:
P″(t)=c(P′(t),pc),
变异:
P‴(t)=m(P″(t),pm),
新一代群体:
P(t+1)=P‴(t),t=t+1,
适应性评价:
P(t+1)={f(a1(t+1)),f(a2(t+1)),…,f(an(t+1))},
结束.
2 实证分析
由混料试验设计的基本约束条件可知,其中的各个分量最小值为0,即在单纯形格子设计中,绝大多数的试验点混料的分量都有一个或者多个的分量为0.但在实际应用和试验中,很多情况下是不允许大多数的分量为0的,否则就会失去该模型的意义[15].为更清晰地说明运用遗传算法获得混料模型最优设计的方法,结合实例加以分析.
2.1 数据来源
数据来源于文献[16],摘取该文献中研究煤矸石与不同基质不同配比下小白菜生长的研究的部分数据.原数据作者旨在研究煤矸石与壤土、煤矸石与沙土的混合基质,分别对小白菜生长的平均株高的影响.为了优化试验,本次试验的目的是研究同时含有煤矸石、壤土和沙石三种成分的混合基质对小白菜生长的平均株高的影响,并且寻求达到小白菜最优生长的平均株高时煤矸石、壤土和沙石的比例.原始数据来源于三个表格:供试基质及其配比比例、煤矸石与壤土不同比例对小白菜种子出苗率的影响和煤矸石与沙土不同比例对小白菜种子出苗率的影响.
2.2 数据预处理
本例共有20组数据.由于实例问题为研究三种不同物质的共同作用,所以该混料试验模型选定为3分量规范混料模型,x1、x2和x3分别对应煤矸石、壤土和沙土的混料分量,小白菜的平均株高为响应值y.经过处理后的数据表1满足混料试验模型的要求.
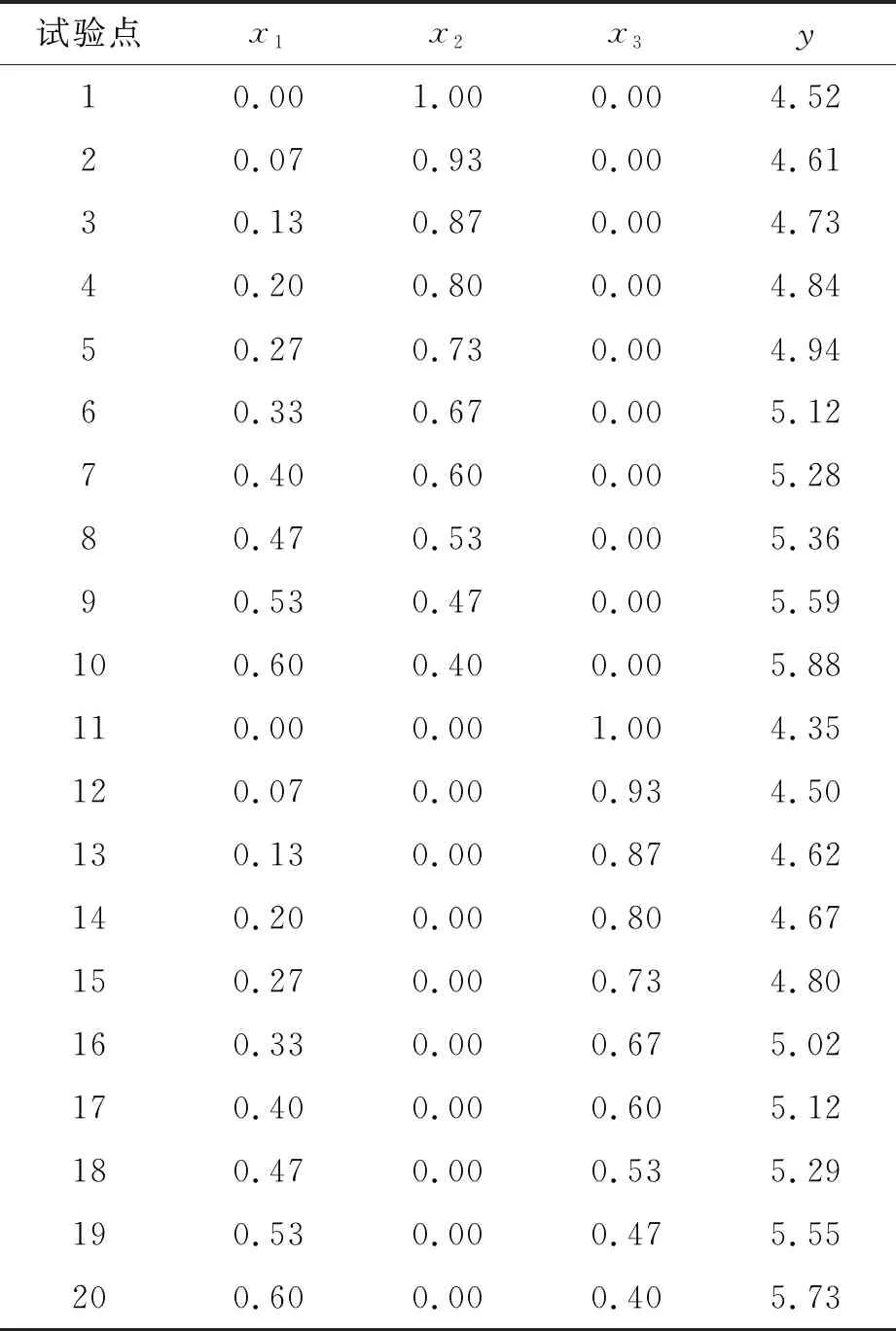
表1 混料模型试验点坐标值与对应的响应值
结合数据来源的实际应用情况以及本次试验的目的,该模型的混料分量需满足以下的约束条件:
在此前提下进行模型拟合,寻找其最优设计.
2.3 拟合混料试验模型
使用表1的数据,选择3分量3阶混料规范多项式拟合得到如下:
y=8.258 52x1+4.511 83x2+4.361 07x3-
3.497 32x1x2-3.617 26x1x3-
1.437 71x1x2(x1-x2)-1.549 70x1x3(x1-x3)
(1)
并绘制该混料规范多项式的三维响应曲面图(左)和预测响应(右)等值线图如图1.
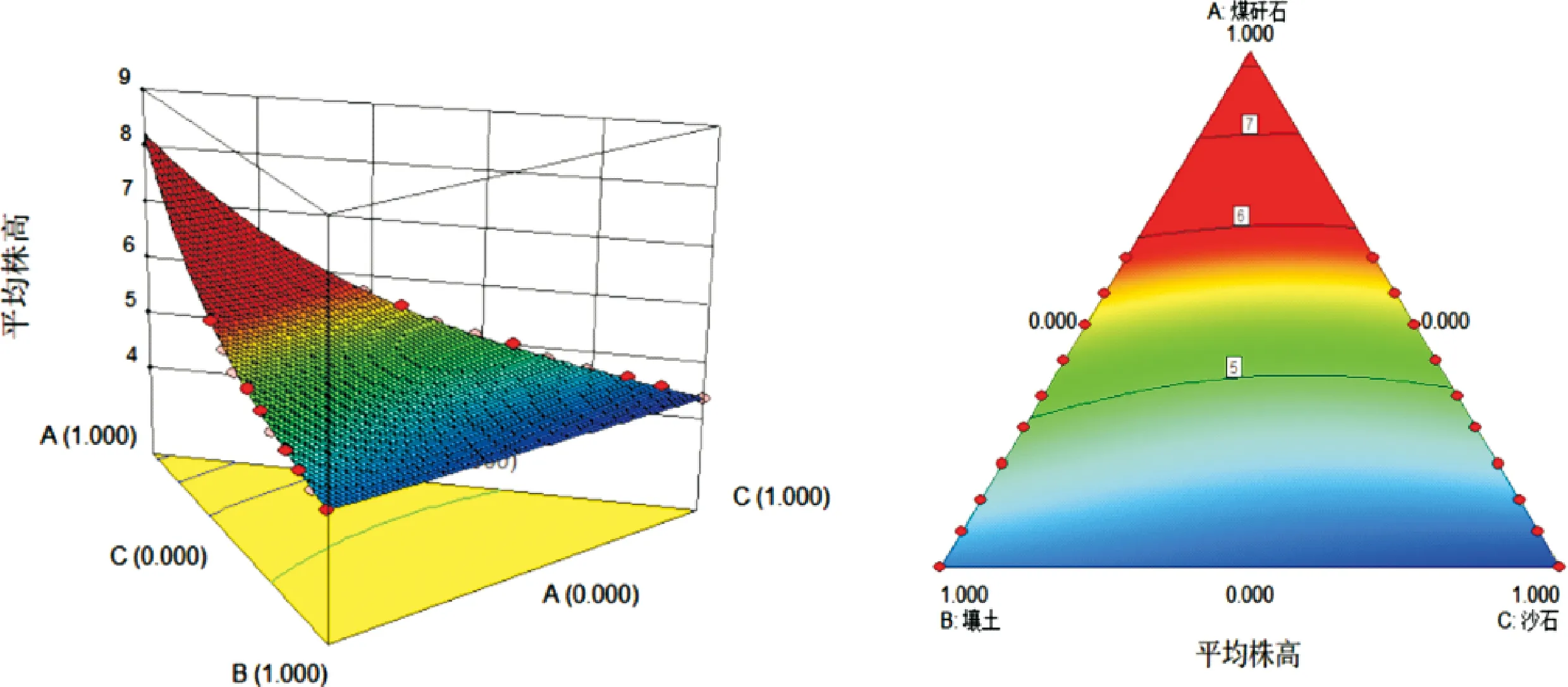
图1 三维响应曲面图(左)和预测响应等值线图(右)
为验证该模型的拟合程度,通过方差分析表进行检验(表2).
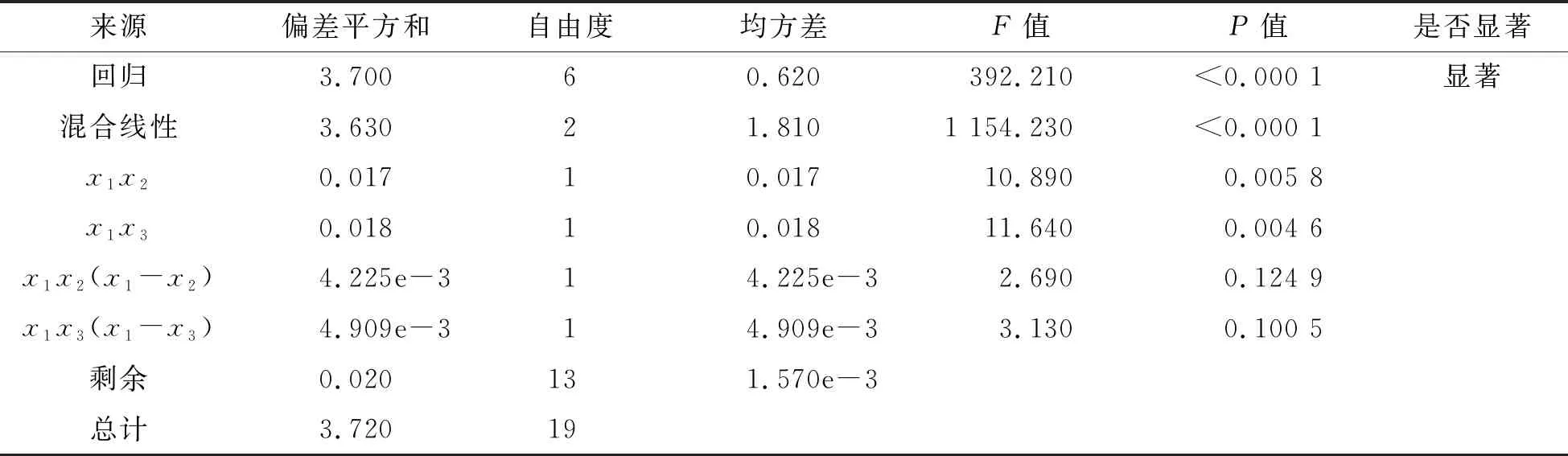
表2 方差分析表
观察表2可知,该模型的P<0.000 1,说明该混料试验模型表示变量间的关系是显著的,通过了F检验,认为式(1)能够合理地描述此混料试验.
2.4 遗传算法求最优设计
使用遗传算法求得本例模型的最优设计.由于最优设计的试验目的是求得目标函数的最大值,且Matlab中函数优化是使适应度函数最小化,需设适应度函数为f=-y,并对遗传算法中所要用到的参数进行初始设定如表3所示.
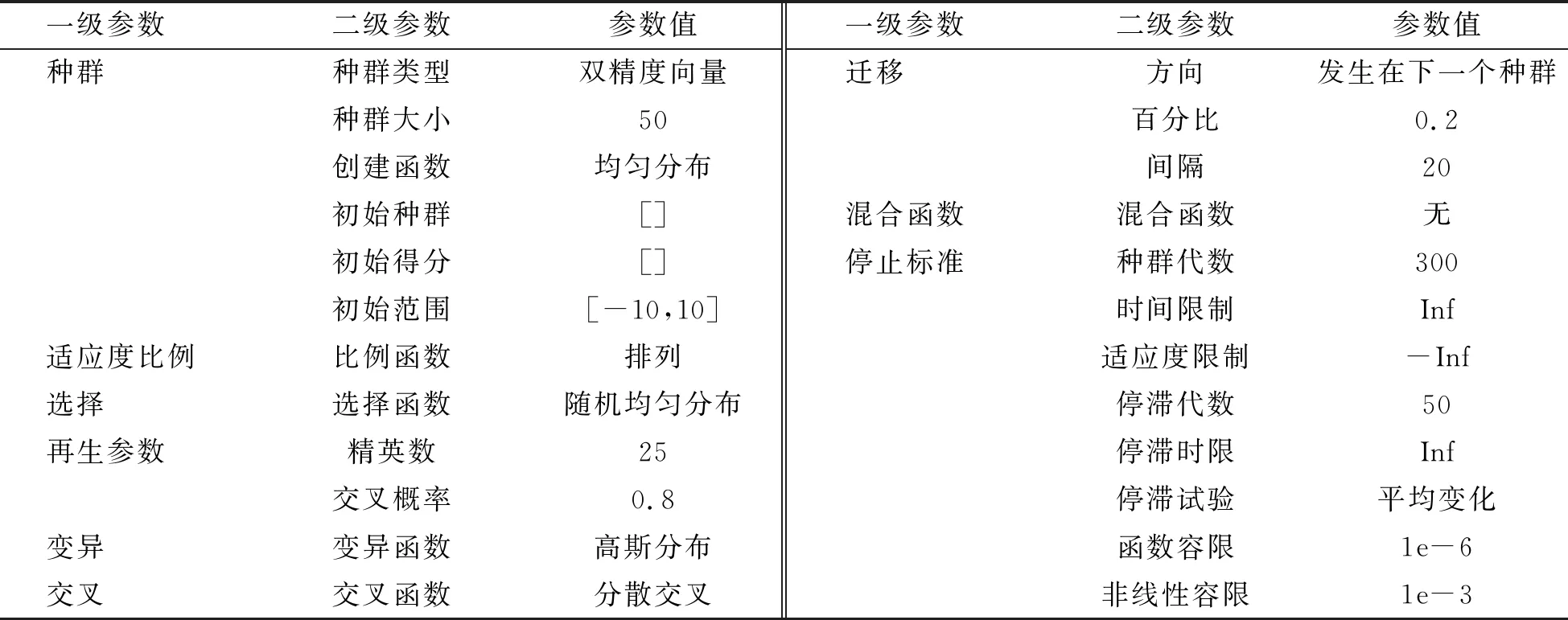
表3 算法参数的初始值
运行程序,遗传算法的输出结果停留在第163代,此时x1=0.600、x2=0.298和x3=0.102时,适应度函数为最小值f=-5.780.最佳适应度值随着遗传算法的代数不断增加而趋于一个稳定情况.每代原始得分对应的期望值随着每代原始得分的不断增加而不断降低,并且从集中分布趋于分散分布.每代个体的范围由初始范围[-10,10]开始一直逐渐减小并趋于稳定,除了70代到90代区间有明显的波动趋势,90代以后稳定于-5.790左右.遗传个体的谱系图(图2)展现了其中父辈的个体数和子代的个体数比例差异,并且可以发现,该比例是较为稳定的.
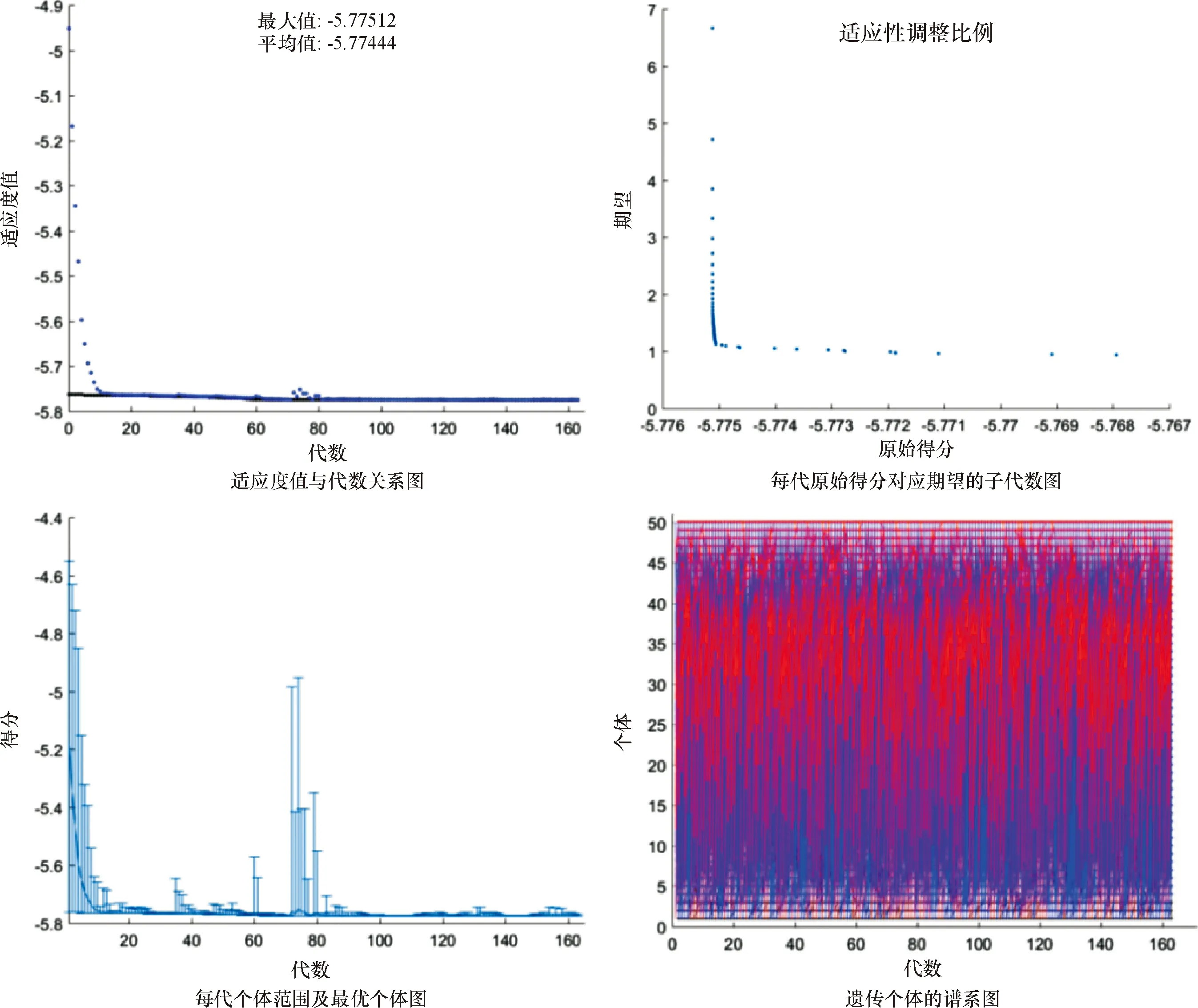
图2 算法的输出结果
因此,在混合基质同时含有三种成分的前提下,当煤矸石、壤土和沙石三种成分所占比例分别为60.00%,29.80%和10.20%时,小白菜达到最优生长的平均株高5.78 cm.
3 总结与展望
本文给出使用遗传算法求混料模型最优设计的实证分析.混料试验模型最传统获取其最优解的方式是通过观测等值线图获取,但由于人为观测的不准确性,容易造成较大误差.在理论研究和工农业应用中,混料模型的试验域通常情况下不是标准的单纯形,而是不规则的试验域,这使得通过观测等值线图获取最优解的方法更困难.该情况下,凸显了遗传算法的优势所在,遗传算法在保证混料试验模型满足已知的约束条件情况下,通过群体搜索与遗传算子的交叉变异和不断的迭代,获取混料试验模型的最优设计,且该算法计算速度较快,获得的结果较为准确,说明使用遗传算法获得混料模型最优设计的方法值得推广.
猜你喜欢
建材发展导向(2022年18期)2022-09-22
新型建筑材料(2022年5期)2022-05-31
山西化工(2021年6期)2022-01-20
新农业(2019年20期)2019-11-02
作文世界(小学版)(2017年8期)2017-09-07
作文大王·低年级(2017年1期)2017-02-16
电子制作(2016年21期)2016-05-17
中国酿造(2016年12期)2016-03-01
陶瓷(2015年7期)2015-10-17
泰州职业技术学院学报(2014年5期)2014-02-28
