
定性比较分析:融合定性与定量思维的组态比较方法
2020-06-05 01:35:46李永发
广西师范大学学报(哲学社会科学版) 2020年3期
李永发
(安徽财经大学 工商管理学院,安徽 蚌埠 233000)
一、引言
QCA(定性比较分析,Qualitative comparative analysis)探索引致特定结果发生的各种共同起作用的条件组合。相比其他实证方法,QCA具有三个常见的显著特征:(1)并发性。为了方便表述,考虑在二分世界中,即不管是条件变量还是结果变量,其取值只有两个可能值,要么为0,要么为1,并发性的数学公式表达为 “X·Y→O”,即“当X=1且Y=1时,导致结果O=1”。条件“X=1”或条件“Y=1”不是靠其独自发挥作用就能使得结果“O=1”,每一个条件需要和其他条件联合决定特定的结果出现或不出现。由于条件组合并发性,因此不需要去验证条件变量之间是独立的、非相关的,而且很难做到研究中两个变量是独立的、非相关的。(2)非对称性。现实世界可能同时存在 “X·Y→O”与“~X·Z→O”,其表达的意思是“当X=1且Y=1时,导致结果O=1;当X=0且Z=1时,也可以导致结果O=1”。举例子来说,男性创业可以成功,女性创业也可以成功,而不是女性就一定失败;初始资源丰富可以成功,初始资源贫乏也可以成功,而不是一定失败。引致结果发生与不发生的前因条件组合不是互补性的、对称性的,不是线性假设关系。(3)多重等效性。根据“X·Y→O”与“~X·Z→O”,可知导致结果“O=1”存在两个路径“X=1且Y=1”或者“X=0且Z=1”。只要满足“X=1且Y=1”或者“X=0且Z=1”,都能导致结果“O=1”。因此导致特定结果“O=1”的路径(不同的条件组合方式),可能不止一个路径,可能存在多个路径,即多重性;而且每一个路径可产生同样的结果,即等效性。举例子来说,进入重点大学学习,可以有多个路径,一种是通过高考这种较为大众化的方式,而另外一种是个别方式,如获得某一个比赛的世界冠军。对于一个特定个体而言,只要具备某一个路径的条件,就可以进入该校学习。
正由于QCA具有鲜明特性,其重要性被研究者日益重视,如表1所示,近年应用QCA 文献快速增长,但中文文献出现晚,且同年度占比不足5%。表1中,Glgoo学术搜索方式是直接在搜索框中输入“Qualitative comparative analysis”;中国知网搜索方式是按照主题“定性比较分析”搜索中文文献;在中国社会科学引文索引(CSSCI)按照篇名检索“定性比较分析”。以Glgoo学术搜索为例,2019年文献数量是2005年文献数量的11.35倍;以中国知网搜索为例,文献数量超过10篇的学科依次是工商管理(43条)、公共管理(23条)、新闻传播(20条)、政治(15条)与社会(11条);以CSSCI搜索为例,代表着近年重要学术期刊对QCA方法的逐步认同,文献数量超过4篇的学科依次是管理学(30条),政治学(10条),图书馆、情报与文献学(9条),经济学(7条),社会学(6条),新闻学与传播学(4条)。Ragin(2007)曾认为多数社会科学理论的集合特性普遍未被社会科学研究者所认知,而从表1可知,这一点正在改观,QCA的应用有着广泛前景,正被越来越多地用于社会科学,成为一种主流方法(Rihoux等,2013)。QCA在社会科学研究领域快速兴起,但未被正确使用、技法粗糙的现象较为普遍,例如,个案的选取、数据的处理、解的报告、解的测试等问题突出。对QCA特定的优势和劣势没有给予足够重视的情况下模仿使用QCA是危险的(Cooper和Glaesser,2011)。尽管QCA方法或软件仍在发展中,但本文不是研究QCA方法或软件本身的问题,如前因条件的时间顺序、前因条件组合背后的机制等(蒋建忠,2016),而在于促进QCA方法或软件正确规范的应用。
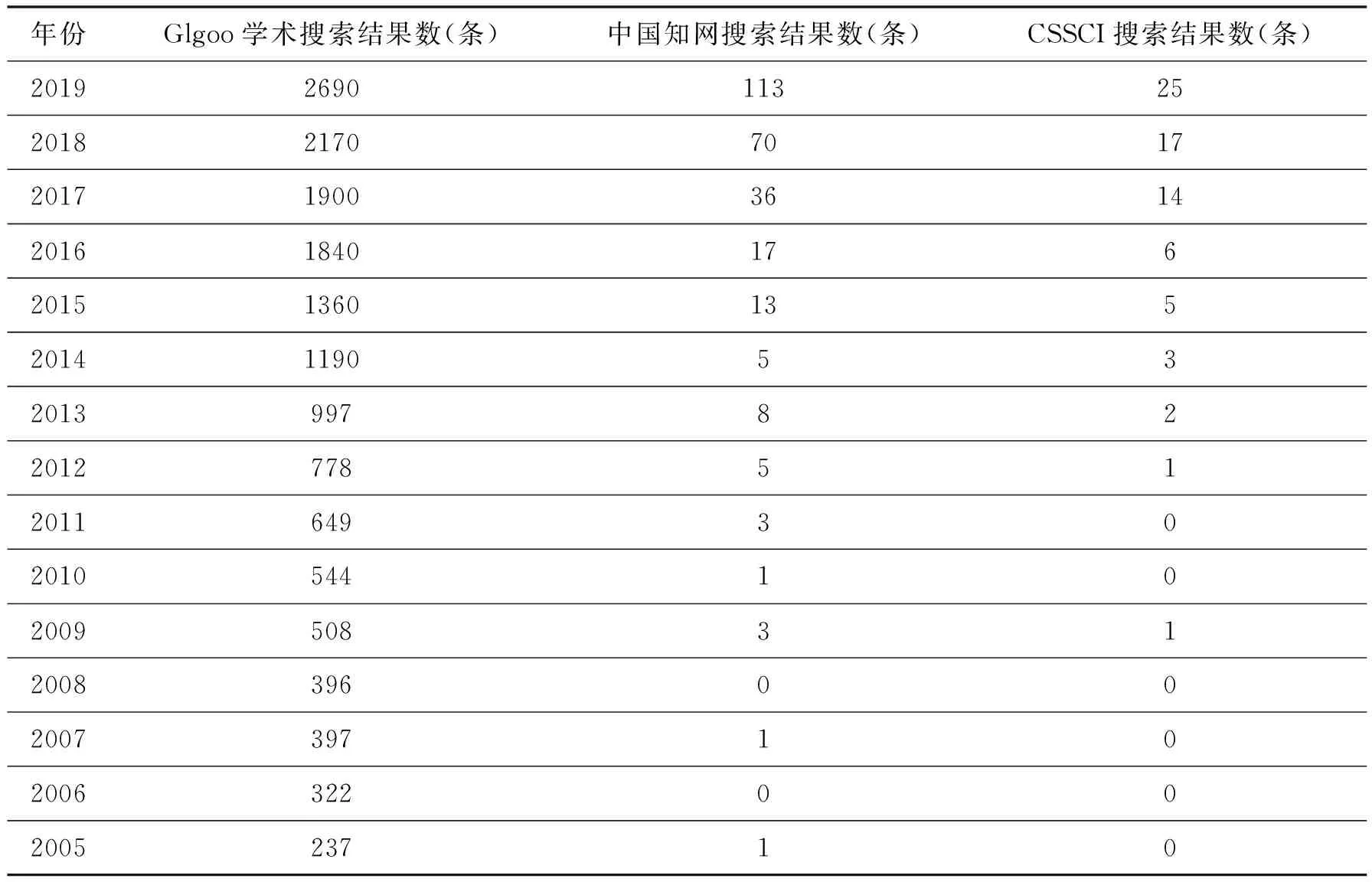
表1 应用QCA的文献数量
注:搜索时间:2020年2月12日。
二、研究设计
QCA包括三种技术:清晰集QCA,所有变量值都是二分的,要么是0要么是1;多值集QCA,所有变量值都是0,1,2或3等离散的数字;模糊集QCA,所有变量值,依据隶属于一个集合的程度,可被定义为 0、1与0~1之间任何精细的刻度值。 QCA不仅仅是一个技术集合,也是一个具有自身目标和假设集的研究方法(Rihoux和Marx,2013)。QCA不仅仅是解决系统的、定性的跨实例分析的一种形式化集合分析方法,也是一种软件工具,被用于识别导致特定结果的前因条件组合。基于比较方法、集合理论和布尔代数,QCA研究聚焦3个关键问题:(1)导致某一个现象(结果)发生的前因条件组合是什么?不发生的前因条件组合是什么? 有多大程度上相信这个条件组合能够导致特定结果发生?符号实现特定结果的特定前因条件组合的案例数量的比例是多少?(2)导致结果发生条件数量是否可以比预先考虑的条件总数有减少?(3)促使某一个现象(结果)发生的充分条件是什么?必要条件是什么?核心条件是什么?外围条件是什么?如果某个条件(或条件组合)X总是在某个结果O时出现,没有O就没有X,那么X就是O的必要条件。如果O总是在X下出现,有X就有O,那么X就是O发生的充分条件。O也可以由其他条件(或条件组合)Y引致产生。充分条件是必然引致结果发生的条件,因而具有充分条件的实例将显示出结果发生。充分条件可能不是导致结果发生的唯一条件,因而基于集合论视角充分条件集合可视为结果集的子集。必要条件是结果发生所必需的条件,因而所有显示结果发生的实例也必然具有必要条件。仅仅依靠必要条件本身还不足以使结果发生,基于集合论视角结果集可被视为必要条件集的子集。Baumgartner(2015)概略地认为现有文献用于分析因果关系概念的有两种不同类型因果关系理论,即差异制造理论(Difference-making theories)和力理论(Power theories)。差异制造理论规定原因是以它们对其效果产生某种差异的属性为特征;力理论认为,因果依赖的特征在于将原因与其效果联系起来的某种物理关系。很显然,数据分析的布尔代数方法不会彻底审查原因和结果之间的物理关系,因而是寻找差异制造理论所定义的因果依赖性,判断哪些前因条件是结果必要条件或充分条件的差异制造者。
与QCA方法比较,单案例或多案例形式化相对较弱,且依赖于研究者的知识、经验与洞见,不同研究者获得的结论很难取得一致性,可复制性低;传统的量化多基于线性回归分析,对于非线性问题的解决能力被越来越广泛地质疑。回归分析旨在发现自变量对因变量的影响净效应大小与方向,而QCA的目标是确定与一个结果发生有着因果关系的条件的不同组合(Ragin和Strand,2008)。作为一种新的研究范式,QCA究竟在哪些层面上弥补传统定量与定性方法上的缺陷或瑕疵?如何规范QCA在方法和技术层面的应用方案?为了回答这两个问题,首先,本文将理清QCA一些基本术语定义以及符号表示;其次,设计QCA应用的典型情景,通过这些情景展示QCA应用过程中的关键决策点以及处理技巧;最后,完整地描述QCA求解的规范过程,列举常见的应用误区和处理策略。
(一)符号说明与定义
QCA的数学基础是集合理论和布尔代数。布尔代数将任何一个变量只设置两个可能值0或1,如若“真”设为T,则“非”记作~T;若“男性”设为X,则“女性”记作~X;若“高收入”设为Y,则“非高收入”记作~Y。T、X与Y默认表示其发生、出现,其取值为1;~T、~X与~Y分别表示T、X与Y未发生、未出现,其取值为0。表2列举QCA的9个基本概念、符号表示与说明。

表2 QCA基本术语、符号表示与说明
(二)设计QCA应用情景与关键决策点
QCA基于比较两个及两个以上对象或个案的属性的取值,分析特定现象及其因果关联,因此,QCA需要控制背景因素,操纵一些特定的变量参数,观察引起、产生特定现象的条件组合。必要条件和充分条件不能脱离于特定的理论视角。抽象出来的属性集合赋予不同的值,将产生不同的结果效应。当一些实例的多数属性值相似,但是结果不同,那就需要考虑这些实例中不同值的属性;当一些实例的多数属性值不同,但是结果相同,那就需要考虑这些实例中相同值的属性。因果关系与背景和并发特性有关,因而QCA 拒绝任何永久性因果关系的形式,也就是说当情境、时间、区域等发生变化,导致特定结果的前因组合形式可能存在差异。QCA每一个研究问题可以用三个方面描述:所分析实例、被考虑实例的属性特征(条件变量、结果变量及其取值)以及实例分布状况。在清晰集QCA中,一种组态是指与各个条件变量的一种取值情况。N个条件变量就有2N组态,每一种组态都存在一种结构效应,即与一种特定结果相对应。
(三)说明QCA规范的求解过程、易错点和技巧
QCA应用情景设计聚焦关键决策点及其处理策略,但还需要完整性描述QCA的求解过程与每一个步骤,揭示每一个环节的核心活动,嵌入分析其中的易错点与应用技巧。
三、QCA应用情景与关键决策点
QCA解题是问题导向的,作为一种方法和技术,其应用存在特定的情景。因此,设计QCA特定情景和理清关键决策点,对于QCA正确应用具有重要的启发意义。
(一)情景A:基本的手工求解过程
先定义情景A:假设发现一个有趣的或重要的、或能引起广泛共鸣且未被很好解决的问题,即Y1出现(1结果)或者不出现(0结果)是一个被广泛关注的事件或现象,那么有必要去探索引致Y1出现或者不出现的前因条件组合。假设现实中只发现表3中列举的36个实例,基于实质性知识(文献梳理、理论推导)和经验预测引致结果变量Y1发生的可能的前因条件变量存在三个:X1、X2和X3。每一个变量都只有两个可能值0或1,当取值为1时表示该条件出现,当取值为0时表示该条件未出现,则3个前因变量的取值共有23=8个组态。如表3所示,8个实例分别对应8个组态。引致1结果或0结果的路径在理论上各存在33-1=26种形式,其中三个变量值表达形式8种,两个变量值表达形式12种,1个变量值表达形式6种。

表3 情境A数据
表3提供三类关键信息:(1)8个组态及各个条件变量取值;(2)各个实例的结果变量取值;(3)各个组态上的实例数量或频次。结果变量Y1有两个值0或1,一般情况下,导致0结果和导致1结果的条件变量组合不是对称关系。假设Ni表示第i组态上的实例总数,Ni,1表示第i组态上1结果的实例总数,Ni,0表示第i组态上0结果的实例总数,则第i组态上1结果的原始一致率=Ni,1/Ni,第i组态上0结果的原始一致率= Ni,0/Ni=1-Ni,1/Ni。
1.计算引致1结果的解
观察表3,只有组态[R7]和[R8]导致1结果(可以用“1”“Y1”或“Y1=1”表达),其表达式为:
X1·X2·X3+ X1·X2·~X3→1
(1)
⟹X1·X2→1
(2)
其中符号“→”表示“引致”或“使得”,符号“⟹”表示“推导出”。由(2)式可知,导致1结果的充分条件是X1·X2,前因条件组合X1·X2被称为引致1结果的项或路径。由于1结果只有X1·X2一个路径,因此,1结果→X1·X2,即X1·X2、X1和X2都是1结果的必要条件。X1·X2 ↔1结果,其中“↔”表示充要条件,即X1·X2 是1结果的充要条件。
QCA提供两大类指标判断项或解的合适度:一致率(Consistency)和覆盖率(Coverage)。一致率表示对给定路径或解的信任度,用“具有给定结果并且包含给定路径或解的实例总数与包含给定条件组合的实例总数之比”度量。覆盖率表示达成特定结果中具有给定路径或解的实例比例,用“具有给定结果并且包含给定条件组合的实例总数与具有给定结果的实例总数之比”度量。一致率表达“多大程度的相信给定路径或解一定会导致给定结果发生”,与引致结果的充分条件相关;覆盖率表达“特定结果发生的个案中具有给定路径或解的个案比例”,与引致结果的必要条件相关。覆盖率的测量暗示不是全部给定结果的实例都被解释或覆盖。假设用K表示解、路径或者组态,即K是某个条件值或某些条件值组合,根据一致率和覆盖率的定义,K产生给定结果的一致率和覆盖率的计算公式如下:




观察表3,根据(3)式,K= X1·X2,因此,具有条件“X1·X2”且具有1结果的实例共有3个,具有条件“X1·X2”的实例共有3个,因此,前因条件组合“X1·X2”导致1结果的一致率CON(K→1)=3/3=1。观察表3,具有1结果的实例共有3个,则前因条件组合“X1·X2”导致1结果的覆盖率COV(K→1)=3/3=1。
2.计算引致0结果的解
观察表3中导致0结果(可以用“Y1=0”或者“~Y1”表示)组态[R1]、[R2]、[R3]、[R4]、[R5]和[R6],直接可以发现0结果的规律,即X1=0或者X2=0。或者,根据布尔逻辑代数规则,列出导致结果0结果的解的表达式为:
~X1·~X2·~X3+
X1·~X2·~X3+
~X1·~X2·X3+
X1·~X2·X3+
~X1·X2·~X3+
X1·~X2·X3→0
(7)
⟹~X1+~X2→0
(8)
(8)式表明~X1+~X2是引致~Y1的解,即~X1和~X2是导致0结果的2个路径(或称为“项”)。
由于两个路径的存在,需要将路径的覆盖率进一步分成原始覆盖率和独特覆盖率。引致特定结果的一个路径的独特覆盖率,是指具体特定结果且仅仅包含该路径而不包含其他路径的实例数量与具有特定结果的实例数量之比。假设解K=K1+K2,K1和K2是解的两个路径,则K的覆盖率=K1的原始覆盖率+K2的独特覆盖率= K2的原始覆盖率+K1的独特覆盖率。
观察表3,根据(5)式,求出:
~X1导致0结果的一致率CON(~X1→0)=(8+6+4+3)/(8+6+4+3)=1;
~X2导致0结果的一致率CON(~X2→0)=(8+7+6+5)/(8+7+6+5)=1;
同理,CON(~X1+~X21→0)=(8+7+6+5+4+3)/(8+7+6+5+4+3)=1。
根据(6)式,求出:
~X1导致0结果的原始覆盖率COV(~X1→0)=(8+6+4+3)/(8+7+6+5+4+3)=0.636;
~X2导致0结果的原始覆盖率COV(~X2→0)=(8+7+6+5)/(8+7+6+5+4+3)=0.788;
同理, COV(~X1+~X2→0)=(8+7+6+5+4+3)/(8+7+6+5+4+3)=1。
根据独特覆盖率的定义,则~X1导致0结果的独特覆盖率= COV(~X1+~X2→0)—COV(~X2→0)=1-0.788=0.212;~X2导致0结果的独特覆盖率= COV(~X1+~X2→0)—COV(~X1→0)=1-0.636=0.364。
(二)情景B:同组态上的个案频次
定义情景B:在情景A的基础上,将组态[R2]和[R7]的实例数量均调整为10,其他组态的实例数量均调整为1,则现实世界中总共只存在26个实例,而这26个实例与8个组态对应,如表4所示。

表4 情景B数据
1.计算引致1结果的解
情景B时引致1结果的解与情景A时引致1结果的解完全一致。观察表4,根据(5)式,X1·X2一定导致1结果,因此路径或解的一致率与覆盖率相同,计算结果如下:
CON(X1·X2→1)=(10+1)/(10+1)=1;
CON(X1·X2→1)=(10+1)/(10+1)=1。
2.计算引致0结果的解
情景B时引致0结果的解与情景A时引致0结果的解完全一致,即解为~X1+~X2,~X1与~X2是两个路径。
观察表4,根据(5)式与(6)式,求出:
CON(~X1→0)=(1+1+1+1)/(1+1+1+1)=1;
CON(~X2→0)=(1+10+1+1)/(1+10+1+1)=1;
CON(~X1+~X2→0)=(1+10+1+1+1+1)/(1+10+1+1+1+1)=1;
COV(~X1→0)=(1+1+1+1)/(1+10+1+1+1+1)=0.267;
COV(~X2→0)=(1+10+1+1)/(1+10+1+1+1+1)=0.867;
COV(~X1+~X2→0)=(1+10+1+1+1+1)/(1+10+1+1+1+1)=1。
根据独特覆盖率的定义,则~X1导致0结果的独特覆盖率=~X1+~X2导致0结果的覆盖率-~X2导致0结果的覆盖率=1-0.867=0.133;~X2导致0结果的独特覆盖率=~X1+~X2导致0结果的覆盖率-~X1导致0结果的覆盖率=1-0.267=0.733。
(三)情景C:矛盾组态
定义情景C:在情景B的基础上,组态[R1]存在另外3个实例支持,但是结果变量Y1=1,如表5所示。这样总共实例数量是29个,但组态[R1]上4个实例结果不一样,组态[R1]被称为一个矛盾组态。引致特定结果的组态原始一致性表示同一组态上显示特定结果的实例比例。观察表5,引致1结果的组态[R1]原始一致率=3/4=0.75,而引致0结果的组态[R1]原始一致率=1/4=0.25。

表5 情景C数据
注:“0(1),1(3)”表示0结果有1实例支持,1结果有3实例支持。
1. 设定实例频数阈值=1且组态原始一致率阈值=0.8,计算引致1结果的解
QCA使用“删除与编码”(“Delete and Code”)操作,删除实例频数低于阈值的组态,并将原始一致率低于阈值的组态结果赋值为0,这个操作是显示求解结果之前的必要操作。若设定实例频数阈值=1且组态原始一致率阈值=0.8,即将实例数量≥1且原始一致率阈值≥0.8的组态纳入引致1结果的条件组态的求解过程。观察表5,由于[R1]原始一致率=0.75,小于0.8,因此QCA认为 [R1] 上缺乏足够的实例数量支持1结果,因此,将[R1]组态所对应的结果变量视为0。[R7]和[R8]包含条件组合X1·X2,[R7]上10个实例,[R8]上1个实例,因此,此时的解为X1·X2,且CON(X1·X2→1)=(10+1)/(10+1)=1,再考虑到[R1] 上3个实例具有1结果,COV(X1·X2→1)=(10+1)/(10+1+3)=0.786。
2. 设定实例频数阈值=1且组态原始一致率阈值=0.7,计算引致1结果的解
使用“删除与编码” 操作,设定实例频数阈值=1且组态原始一致率阈值=0.7,则QCA将实例频数阈值≥1的组态纳入求解过程,并将原始一致率≥0.7的组态的结果变量值视为1。观察表5,引致1结果的组态分别是[R1]、 [R7]和[R8],实例[R1]上3个、 [R7]上10个和[R8]上1个。因此,引致1结果的解为X1·X2+~X1·~X2·~X3,包括2个路径X1·X2和~X1·~X2·~X3,两个路径完全不同,不存在任何重叠效应。其中,路径X1·X2的一致率=(10+1)/(10+1)=1,原始覆盖率=独特覆盖率=(10+1)/(10+1+3)=0.786;路径~X1·~X2·~X3的一致率=3/4=0.75,原始覆盖率=独特覆盖率=3/14=0.214;解X1·X2+~X1·~X2·~X3的覆盖率=(3+10+1)/(3+10+1)=1,一致率=(3+10+1)/(4+10+1)=0.933。
3. 设定实例频数阈值=2且组态原始一致率阈值=0.8,计算引致1结果的解
使用“删除与编码”操作,设定实例频数阈值=2且组态原始一致率阈值=0.8,则QCA将实例频数阈值<2的组态视为逻辑余项(Logical remainder)而不纳入后面的求解过程,并将原始一致率≥0.8的组态的结果变量值视为1。QCA中的逻辑余项是指理论上存在而现实中缺少对应实例的条件组态。经过这样的处理,表5中只有三个组态[R1]、[R2]和[R8]纳入最终的1结果求解过程,[R1]、[R2]和[R8]三个组态上的结果变量值分别是0、0和1,其他组态都视为逻辑余项,正确处理方式如同情景D,这里不再提供计算过程。
在情景C下手工求解0结果的条件组态相对复杂,故省略。
(四)情景D:逻辑余项与三种解的表达
定义情景D:在情景B的基础上,将组态[R3]和组态[R8]的实例数量调整为0,则现实世界中总共只存在24个实例,而这24个实例与6个组态对应,如表6所示。组态[R3]和组态[R8]成为2个逻辑余项。逻辑余项是理论上存在但未达到特定频数个案的组态。逻辑余项的存在是一个较为常见的现象,由于实例的有限多样性(Limited diversity),即使实例的数量超过理论上k个条件的组态数量2k,也或许这些实例聚类至2k个组态中的某些个中,那么依然会产生逻辑余项。在特定的研究问题视角下,现实世界中或许根本不存在覆盖所有2k个组态的实例集合。

表6 情景D数据
注:“?”表示在一行(组态)上没有实例,对应的结果变量值不确定。
1. 逻辑余项与反事实假设
QCA中各个组态所对应的结果变量的值是根据实例数据来确定。由于逻辑余项缺少一定数量实例的支持,那么逻辑余项的结果变量值进而不能确定,QCA基于真值表评估跨实例模式,采用反事实假设分析(Counterfactual analysis)对逻辑余项的结果变量进行赋值。反事实假设分析克服实证实例不足的限制,被区分成两种类型:容易的反事实假设(Easy counterfactuals)与困难的反事实假设(Difficult counterfactuals)。容易的反事实假设是指将一个多余的前因条件添加到自身就已经能够引致所讨论结果的一组前因条件中;困难的反事实假设是指从可引致结果的一组前因条件中移除一个被假设为多余的前因条件(Fiss,2011)。通俗地讲,求解时,QCA软件在给逻辑余项的结果赋一个值,软件容易做出反事实假设的,就是容易的反事实假设,这样的假设的结果值可靠性较高;软件不容易做出反事实假设的,就是困难的反事实假设,这样的假设旨在让解的表达式尽可能简化,其获得的结果值可靠性较低。当然,对逻辑余项的赋值依赖于QCA软件自身的算法。区分有无反事实假设以及容易的反事实假设和困难的反事实假设,QCA提供3种类型的解:(1)没有做任何反事实假设分析情景下获得的解,称为复杂解(Complex solution);(2)仅仅做了容易的反事实假设分析情景下获得的解,称为中间解(Intermediate solution);(3)不仅做了容易的反事实假设分析,而且做了困难的反事实假设分析情景下获得的解,称为简约解(Parsimonious solution),解的逻辑表达式或许进一步获得简化。QCA是先求复杂解,再求简约解,最后求中间解。中间解条件值的组合包含简约解的条件值的组合,复杂解条件值的组合包含中间解的条件值的组合。
2.计算引致1结果的解
观察表6,使用“删除与编码”操作,设定实例频数阈值=1且组态原始一致率阈值=0.8,首先计算复杂解(如表7所示)。不做任何反事实假设分析的情景下,表7中只有组态[R7]的结果变量Y1=1,[R7]上共有10个实例且都支持1结果。因此,解的表达式为X1·X2·X3,其为引致1结果唯一路径。X1·X2·X3导致1结果的一致率=10/10=1,覆盖率等于10/10=1。其次计算简约解。简约解,不仅做容易的反事实假设分析,而且也做困难的反事实假设分析,目的是尽可能简化解的表达式。观察组态[R7]和[R8],尽管组态[R8]是一个逻辑余项,但是有10个实例支持的[R7]表达式是X1·X2·X3且Y1=1,那么考虑到[R8]表达式是X1·X2·~X3,那么困难的反事实假设是将[R7]表达式X1·X2·X3中的X3删除且仍然可以获得1结果,进而X1·X2·~X3也引致1结果。换句话说,X1·X2·~X3和X1·X2·X3的结果变量一样,都是1结果,进而条件变量X3不管是值为0还是为1,都不影响结果变量的值,X3成为与1结果无关的前因条件(无关条件)。同时,对没有现实实例支撑的 [R3] 组态~X1·~X2·X3进行反事实假设分析,提供一个似乎可信的结果值。因为现有的导致0结果实例共有14个,其中12个存在~X2,可以假定~X2导致0结果,那么容易的反事实假设是在~X2上添加一个条件~X1·X3,这不会改变~X2引致0结果的事实,即~X1·~X2·X3获得0结果。那么这样处理后,重新观察表6,只有[R7] 与[R8] 组态是1结果,因此,如同情景C的解,即引致1结果的解是X1·X2,解的一致率=10/10=1,覆盖率=10/10=1。最后求中间解。中间解仅做容易的反事实假设分析。因为组态[R8]的表达式是X1·X2·~X3,没有现实实例支撑,QCA需要进行反事实假设分析,提供一个似乎可信的结果值。因为有10个实例支持的组态[R2]是X1·~X2·~X3,且引致0结果,此情境中10个实例说明存在大量知识的支持,可以假设X1·~X3引致0结果,那么容易的反事实假设是在X1·~X3上添加一个条件X2,这不会改变Y1=0的结果,即X1·X2·~X3引致0结果。同样,假设[R3] 组态引致0结果是一个容易的反事实假设分析。虽然经过2次容易的反事实假设分析,但真值表中只有组态[R7]具有10个实例支持且引致1结果的情况没有改变,因此,导致Y1=1的中间解表达式为X1·X2·X3,与复杂解相同。该中间解的一致率=10/10=1,覆盖率等于10/10=1。以上只是对容易的反事实假设与困难的反事实假设一个较为简化的推演,实际上,当条件变量更多时,需要依赖于基于一定算法的QCA软件给出三种解。
设定实例频数阈值=2且组态原始一致率阈值=0.8,重新计算引致1结果的复杂解、简约解和中间解(如表7所示)。实例阈值从1提高到2,简约解变化很大。路径X2导致1结果的一致率=10/(10+2)=0.833,覆盖率等于10/10=1;路径X3导致1结果的一致率=10/(10+2)=0.833,覆盖率等于10/10=1;解X2+X3导致1结果的一致率=10/(10+3)=0.769,覆盖率等于10/10=1。
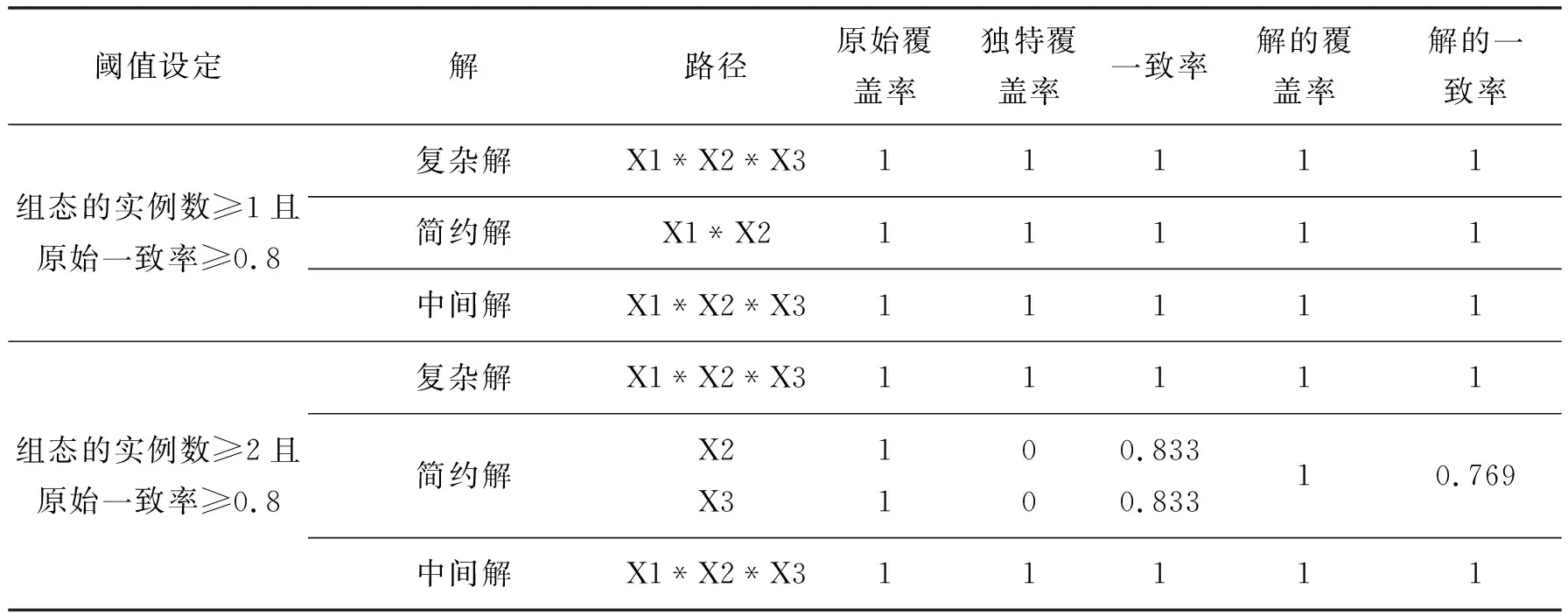
表7 引致1结果的解
观察表8,设定组态的实例数≥1且原始一致率≥0.8的情形下,存在[R3]和[R8]两个逻辑余项,求出引致1结果的三种类型的解。每一个逻辑余项反事实分析的结果取值只有两个:0或1,则[R3]和[R8]两个组态的反事实假设结果组合有4种类型:0与0,0与1,1与0,1与1。表8假定[R3]和[R8] 可能结果4种类型组合均存在1个实例,并给出了QCA计算结果。比较表8和表7,则发现[R3] 引致0结果和[R8]引致0结果的反事实假设,获得表7中的中间解X1*X2*X3;同样发现[R3] 引致0结果和[R8] 引致1结果的反事实假设,获得表7中的简约解X1*X2。因而,可以认定表7中“[R3]引致0结果”和“[R8] 引致0结果”两个反事实假设获得现有实例中的多数支持,是容易的反事实假设;而反事实假设“[R8] 引致1结果”并未获得现有实例中的多数支持,是困难的反事实假设。

表8 两个逻辑余项的4种可能的反事实分析
在情景D下求解0结果的条件组态计算相对复杂,故省略。
(五)情景E:模糊集数据处理
定义情景E:(1)前因条件变量X1、X2、X3和结果变量Y1都可被视为一个集合。(2)X1、X2、X3和Y1是各个实例的属性、分析维度。(3)各个实例在X1、X2、X3和Y1上相同、相似或明显差异。(4)将各个实例在作为属性的X1、X2、X3和Y1上的表现分别与一个作为参照标准集合进行隶属程度比较。(5)计算各个实例在X1、X2、X3和Y1上的隶属度值,其中理论上最大的隶属度值为1,表示完全隶属参照标准集合;理论上最小的隶属度值为0,表示完全不属于参照标准集合;最大模糊点(Cross-over point)的隶属度值为0.5,表示有0.5的可能属于且也有0.5的可能不属于参照标准集合,做出归属决策非常困难。(6)经过转化,将涉及X1、X2、X3和Y1总共16实例将原始多种形式信息转换成0和1之间的数据信息,如图9所示。

表9 情景E数据
1.校准
表9中数据全部属于[0,1],适合采用模糊集QCA计算。表9中的数据是经QCA提供的校准函数Calibrate(X,N1,N2,N3)计算而得。若NEWX=calibrate(X,N1,N2,N3),则变量NEWX是X校准后的变量,X经过校准后,X中N1转换成NEWX中的0.95,X中N2转换成NEWX中的0.05,X中N3转换成NEWX中的0.05,X中大于N1的数转换成NEWX中(0.95,1]的值,X中大于N2且小于N1的数转换成NEWX中(0.5,0.95)的值,X中大于N3且小于N2的数转换成NEWX中(0.05,0.5)的值,X中小于N3的数转换成NEWX中[0,0.05)的值。通过校准函数中三个锚点值的设置,可将原数据转换成QCA运行数据,进而影响最终的求解结果。
2.真值表
图9中的各个实例在X1、X2、X3和Y1上取值不完全相同,难以从中快速观察到个案的聚类特性。当利用FsQCA3.0软件中的“删除与编码”操作,设置实例的频数阈值和组态(行)一致率阈值,删除掉低于实例频数阈值的组态(真值表中的行),将一致率不小于一致率阈值的组态的结果变量赋值为1。若将实例频数阈值设置为1和组态一致率阈值设置为0.8,那么FsQCA3.0软件生成了一个真值表(如表10所示)。表10是对表9的重构,将表9中的实例和条件变量重新定义成6个组态,理论上有23=8个组态,因此,有2个逻辑余项没有实例支持。由于实例[C15]的X3=0.5,0.5是最大隶属模糊点,FsQCA3.0软件自动剔除了这个实例,剩余的15个不均匀地分布在6个组态中,其中[R6]组态上聚集的实例最多,达5个。观察表9,实例[C12]的Y1=0.4,但是在表10中,与[C13]、[C14]、[C16]一起被归属于[R2]组态,真值表中Y1=1;同样依据表9,实例[C11]的Y1=0.7,但是在表10中,与[C1]、[C4]、[C9]、[C10]一起被归属于[R6]组态,真值表中Y1=0。

表10 情景E在实例频数阈值=1和组态一致率阈值=0.8设定下的真值表
3.求解引致1结果的条件组态
若将实例频数阈值设置为1和组态一致率阈值设置为0.85,表10中的组态[R2]的原始一致率为0.806<0.85,那么其结果变量Y1将被设置为0。因此,实例频数阈值和组态一致率阈值设置也会影响真值表,从而最终影响到解的表达。表11显示实例频数阈值设置为1,组态一致率阈值分别设置为0.8和0.85,应用FsQCA3.0软件分别获得的解的表达式和相应的评价指标。当组态一致率提高后,解的一致率也会提高,而解的覆盖率会降低。

表11 情景E下引致1结果的条件组态
四、QCA求解过程、易错点与技巧
前文聚焦QCA解题过程、核心观察指标与关键操作,有针对性地设计QCA应用的五个情景。情景A显示QCA通过比较导致1结果的个案及其属性值可以求解引致1结果的各种路径(前因条件组合),也可以通过比较导致0结果的个案及其属性值求解引致0结果的各种路径,导致1结果的各种路径与导致0结果的各种路径之间不一定是互补或对称的关系,这与传统研究方式有所不同。并且,情景A还揭示组态的原始一致率、路径一致率、解的一致率、路径独特覆盖率、路径原始覆盖率、解的覆盖率多个指标的内涵与计算方法。情景B显示QCA中“删除与编码”操作之后的真值表决定解的表达形式,该真值表决定解最终包含的前因条件与路径,真值表中实例的频数(真值表每行的案例数)只改变解与路径的一致率、覆盖率的数值。情景C显示QCA处理矛盾组态的策略,利用“删除与编码”操作设定不同的实例频数阈值和组态原始一致率阈值影响解的计算结果。情景D显示QCA逻辑余项和反事实分析的处理策略,引出复杂解、简约解与中间解的三种类型,推导三种类型解之间的关系。情景E显示QCA解决变量被赋予模糊集数值的策略,关键的一步是校准操作,指出校准后前因条件值是最大模糊点0.5时的软件剔除个案反应。五个QCA应用情景设计目的在于提炼聚焦QCA应用中的关键决策点,但系统性和完整性不足,因此有必要全局性勾勒出QCA解决问题的过程(如图1所示)。完整的QCA求解过程包括从有趣的现象到原始数据、从原始数据到QCA真值表、从QCA真值表到对现象的解释三个大的阶段以及图1中的10个步骤。

图1 QCA解决问题的试错迭代过程
注:实线箭头表示需要实施的活动,虚线箭头表示可以不是必须的或者是迭代的活动。
(一)从有趣现象到原始数据阶段的关键步骤、易错点与技巧分析
步骤①:发现一个有意思的现象或重要的研究主题
发现一个能引起广泛共鸣的好现象或有着远见思考的好问题,是QCA探索研究的开始。QCA基于这个现象定义一个或若干个结果变量,探索各个结果变量发生或者不发生的原因,通过个案、属性组态比较方式获得引致特定结果的各种路径。识别有意思的现象,需要理论和经验知识的积累,而QCA求解或会产生新的知识、理论与技术。需要注意一点:QCA基于被操纵的实例、变量和数值,不能保证所探索到的原因就是“真实的存在”和“长久的有效”,如中国发展每一个阶段引致企业绩效或财富增长的路径或许存在差异,同一个时期中国各区域引致企业绩效或财富增长的路径也或许存在差异。郝瑾等(2017)探索母公司对特定海外子公司所扮演的角色类型与管控方式的适配性,构建主导性与合作性两个被解释变量,基于动机、能力与机会三维框架将子公司划分为8 种角色类型,识别出4个前因条件变量,即母公司战略、子公司能力、当地环境与分权程度,对华为集团 16 家海外子公司样本、中建集团 14 家海外子公司样本、中石油集团 8家海外子公司样本和全部三家集团子公司样本两种行为结果分别运行QCA求解结果。郝瑾等提出的问题是“困扰许多国际化发展企业的一大难题”,因而研究是有意义的,能引起共鸣。
步骤②:贴标签,定义实例集合和结果变量
通过贴标签圈定QCA的样本实例。QCA中的实例是有目的建构出来的,通过比较各个实例的不同属性与结果,从而识别条件属性变量与结果变量之间的一般关系。中小样本情景下(如小于50个样本)实例群组的建构不能简单依赖于机械程序,如随机抽样,而是尽可能全部纳入,去熟悉、掌握每一个实例及其属性。研究者对于案例的熟悉度、亲密度非常重要,有助于QCA运行获得一个可靠的结果。实例的选择基于一定的标签范围,需要测试两个方面:一是足够水平的相似性,全部实例存在一个共同的背景特性,如初创企业、新兴经济体、经历大疫情的创新型企业等;二是最大水平的相异性,全部实例不是仅仅具有一种结果,而应有积极的结果(1结果)和消极的结果(0结果),还需覆盖尽可能多的组态。例如,某一个前因条件在全部案例中都是同样的取值,或者采用7级李克特量表,当给出的全部实例的全部属性取值,都不存在1、2与3,那么为什么不重新设计变量与取值标准,采用5级李克特量表呢?实例的纳入基于理论知识的推演,实例数量常常事先不能固定,新的实例或会添加,初始实例亦或会被剔除。确定结果变量,是思考前因变量范围的前提;而确定前因变量,依赖于研究者已有的经验知识、文献的梳理与专项访谈调研。对于大样本实例研究,研究者难以获得每一个具体实例知识,往往借助于官方的统计数据或项目问卷数据,这需要结合统计分析。每一个属性值依赖于哪些指标数据测量,需要提供透明、有科学性的解释。例如,衡量企业成长,是观察企业利润、企业收入、员工数量变化,还是估值变化?选择不同指标评测,变量取值会有不同,进而QCA求解。
步骤③:定义前因条件变量和调节变量
考虑到现象解释的多样性以及引致现象发生的前因组合多重并发特性,QCA前因条件的选择需要基于一个或若干个核心理论视角,并尽可能减少前因条件的数量,一般变量数量控制在不少于3个且不多于9个。Rihoux等(2013)研究1984-2011年应用QCA的期刊论文,发现:小样本(不多于10个实例)、中等样本(10到50个案例)和大样本(超过50个实例)设计的文献数量比例分别是12%、60%和28%;而在大样本设计的文献中,使用100-199个实例的文献占6% 、200-499个实例的文献占3%、超过500个实例的文献占8%;不管采用哪种具体的QCA技术,习惯使用的条件数量范围是4-6个。Emmenegger等(2013)列举的19篇QCA应用文献中,条件数量为4-6个的文献占79%,小样本研究1个,大样本研究2个;QCA文献中案例数量与条件数量较为特别的组合有:6个对4个、78个对4个、25个对3个、11个对8个、14个对11个。尽管实例与条件数量的平衡还没有较为正式、有共识的结论,但一般而言,条件变量个数越多,理论上真值表中的行数(组态数)就成倍增加,就需要更多数量的实例去覆盖更多数量的组态,这样才有助于提升QCA解的解释性、可读性与可靠性。例如,QCA的解只有一个路径且包含12个变量,与QCA的解包括2个路径且每一个路径包括4个变量,仅从这一点信息来看,后者更容易解读、更有实操价值。QCA变量取值的评价标准也因个案对象的不同存在差异是合理的,如判断成人与儿童的心跳频次、运动员与非运动员的心跳频次的健康标准不能“一刀切”,需要设置一些调控变量。例如,按照年龄段、区域类型或者所属集团公司的不同,将全部样本实例分成不同的群组,再将不同群组的实例分别做QCA分析,并比较不同群组QCA的解,或许会有新的发现与启发。
(二)从原始数据到QCA真值表阶段的关键步骤、易错点与技巧分析
步骤④:透明、合理地给出所有变量的初始值
数据质量决定QCA求解质量。确定实例样本池、结果变量和条件变量之后,为了做出正确有效的比较,需要基于实体知识(Substantive knowledge)和理论知识透明、合理地给出所有变量的原始值。实体知识与研究者对于实例本身的熟悉度、经验有关;理论知识与探索的因果关系相关的文献熟悉度有关。所有变量的原始值都应有恰当的依据和可靠的数据来源,并在研究中完整透明地呈现出来。
步骤⑤:设定阈值与校准,将原始值转化成QCA数据
设定阈值、锚点值与校准需要基于研究者的理论知识和实体知识。应用清晰集QCA时,各个变量的原始值不一定是二分的,那么需要设置阈值,将所有变量值转化成0或者1;应用模糊集QCA时,也不一定全部属于集合[0,1],那么需要设置锚点值进行校准。相对于清晰集QCA,校准公式是模糊集QCA提供一个独特的功能。校准是自然科学领域中一个必要和常规的研究实践以匹配或遵照可信任的已知标准,这些标准使得相应的测量值更具有判断力,然而社会科学领域忽视测量值与校准之间的关系长久存在(Ragin,2007)。设定二分阈值和校准函数的锚点值,可以采用较为复杂的技术工具,如聚类分析。实体知识提供外部标准,使得二分与校准测量值成为可能。实体知识与为什么这个范围取值为1,而剩余范围取值为0,以及什么属于全隶属,什么属于全不隶属,隶属和不隶属的交叉点在哪里等有关的知识,外部标准必须显性表达,并被系统性和透明性应用。例如,性别,若男性取值为1,那么女性取值为0,这个容易理解;小康社会的判断指标及其标准需要引用权威来源。若缺少细致的集合隶属度校准,模糊集QCA合理论分析是没有意义的。QCA校准函数式样,如NEWX=Calibrate (X, N1, N2, N3) ,设置完全隶属点N1、交叉点N2与完全不隶属点N3三个定性的锚点,则将变量X转化成新的变量NEWX,各个实例在NEWX变量上的取值都属于[0,1] ,其X变量中N1、N2与N3分别转化为NEWX中0.95、0.5与0.05。在设置这三个锚点时,研究者需要给出充分的理由。若将某个变量的最大值校准为1,最小值校准为0,平均值校准为0.5,这种处理往往欠妥。当校准后的前因条件变量值中包含0.5的案例将不纳入QCA求解过程,即实际上被软件视为一个异常案例剔除。当变量原始值转化成QCA数据时,可在一定的数据技术处理下,确保预期假设中单个前因条件值趋向1与结果值趋向1的同向变化关系。
步骤⑥:设定实例频数和组态一致率
QCA通过“删除与编码”操作,设定实例频数阈值和行的一致率。阈值设定需要考虑:总实例数、条件数、研究者对于每个实例的熟悉程度、模糊集校准的精确程度、测量和赋值误差、研究者对于结果粗糙还是精细程度的兴趣。缺乏实质实例数的组合(低于通组态上的案例频数低于阈值设定)被视为“逻辑余项”。在中小样本案例中,原则上采用默认阈值1,表示个案只要存在,就应该纳入最终解的计算过程。在大样本中,考虑到少数案例变量赋值异常的问题,提升案例的频数阈值时,QCA解的精度或会降低,但解的有效性预期或会增强。与清晰集QCA和多值QCA分析相比,使用模糊集,研究者可以实施更加精确、严格的集合理论一致性、覆盖率评估。行的一致率等于或超过设定的临界值,该行条件值组合被视为结果的充分条件,因而QCA将该行的结果赋值为1;低于临界值设定的条件值组合不构成结果的充分条件,QCA将该行的结果赋值为0。图2显示,求解1结果的前因所形成的真值表中2k个行或组态可以分成三大类型:A类组态,达到实例频数阈值设定,同时达到一致率阈值设定,其组态结果值为1;B类组态,达到实例频数阈值设定,同时未达到一致率阈值设定,其组态结果值为0;C类组态,未达到实例频数阈值设定,同时未达到一致率阈值设定,其组态结果值取决于逻辑余项的反事实分析。

图2 求解1结果的前因所形成的真值表组态类型以及结果值
步骤⑦:评估真值表、有限多样性和矛盾组态
真值表在QCA中起着至关重要的作用,概括当前研究中以集合表示的条件组态与结果取值之间的关系(Cooper和Glaesser,2011)。真值表列出逻辑上可能的前因条件组态、与每一个组态相关的实例的结果值以及组态一致率(行一致率)。评估真值表至少可以基于四个方面的观察:一是检测是否都有结果值大于0.5的实例和结果值小于0.5的实例。全部案例只有一个结果类型,如实例的结果值全部大于0.5,则样本选择或结果变量赋值不好,当然对于这个样本,QCA只能求解1结果的路径,求解0结果没有任何意义。二是检测是否存在矛盾组态或者具有同样组态的实例中一部分结果值大于0.5而另一部分实例的结果值小于0.5。特别是中小样本实例研究有必要处理这种矛盾性组态,或许是研究者自身数据输入等失误、阈值设定或者漏掉关键变量的问题造成的,但不管是哪类问题,解决它都有助于QCA获得更好的发现或更有价值的理论创新。三是检测是否存在有悖常识的组态和实例。这种组态和实例也需要从原始值赋值准确性查起。四是检测全部实例对于组态的分布情况,观察实例的有限多样性。一般而言,较多数量的组态存在实例,QCA求解相对更合理。当然,纳入特定标签下圈定范围中的全样本实例,那么再想增加一个案例变成不可能,若做也是弄虚作假不可接受,可以思考这个标签是否合理。有限多样性和逻辑余项是对应的,因有限多样性导致的逻辑余项过多,将会降低获取有效推理的可能性。如果感知到真值表不合适,那么需要从案例选择、变量定义、原始值设定和实例频数、组态一致率设定一一判断是否操作恰当。矛盾组态的存在是完全正常的,而且是新理论知识生成的一个重要驱动器,研究者应视为机会,而不是视为令人伤心的不好事物。增加一个条件变量,或者改变阈值设定,那么就可能有效降低矛盾组态数量。
(三)从真值表到对现象解释阶段的关键步骤、易错点与技巧分析
步骤⑧:计算三种解,评估解的合适度
比较研究通常只包含为数不多的实证实例,因而反事实分析是比较研究的核心,其在比较研究中有着悠久而卓越的历史(Ragin和Sonnett,2005)。大量QCA研究中的实例未能全部覆盖全部组态,这符合社会现象有限多样性的特征。对于缺乏实例的组态,被称为逻辑余项。正由于缺乏实例支持,需要QCA对于这些组态的结果值做反事实分析。根据现有的实例数据,容易处理的逻辑余项对应的结果变量赋值被称为容易的反事实假设;而对于不容易处理的逻辑余项对应的结果变量赋值被称为困难的反事实假设,这个结果赋值不是很可靠。QCA提供三种解,没有纳入任何逻辑余项的解是复杂解;只纳入容易反事实假设的逻辑余项获得的解是中间解;纳入全部逻辑余项的反事实假设获得的解是简约解。
判断QCA解的合适度依赖于两个指标:一致率和覆盖率。若X描述N个实例在给定条件组合上的值,Y描述N个实例的结果值,即X(i)表示第i个实例在给定条件组合上的值,Y(i)表示第i个实例的结果值,则计算1结果的解的一致率和覆盖率的数学公式分别是:
计算0结果的解的一致率和覆盖率的数学公式分别为:
数学公式(9)至公式(12)不仅适用于清晰集QCA,也适用于模糊集QCA;不仅适用于整体的解,也适用于解的项,而且一致率公式还适用于计算真值表中各行(组态)的一致率。一致率的实际用途在于判断命题“给定的条件组合导致特定结果”为“真”的可信程度;覆盖率的实际用途在于判断命题 “具有给定结果的实例中具有给定条件组合的实例所占比重”。举例来说,假设成为某高校本科生只存在两条路径,一条是高考,需要满足单个课程成绩要求与总成绩要求;另一条是特招,需要满足若干技能竞赛的要求,那么第一条路径的一致率为0.99,其实际意义是满足第一条路径要求,即有99%的可能进入该校学习;第一条路径的覆盖率为0.95,其实际意义是进入该校学习的本科生中通过高考方式的比例为95%。因此,一致率越大,则给定的路径(单个条件或多个条件的组合)引致特定结果的可能性越大。例如,当一致率CON(X→1)=1时,给定的路径X必然导致1结果发生,即可视为1结果发生的充分条件;当一致率CON(X→1)=0时,在当前理论视角下,给定的条件组合X绝不可能导致1结果发生。所以,QCA对于一致率值有要求,文献中常出现两个阈值:一是要求一致率≥0.8,一是要求一致率≥0.75,比较而言,采用0.8的文献数量更多。覆盖率大,表示实现给定结果的现有实例中具有给定条件组合的比例大,但是注意到等效性原理;覆盖率小,不能表明给定结果不能实现。例如前文中成为某高校本科生的两条路径中,通过特招方式进入该校学习的比例为5%,即覆盖率COV(X→1)=0.05。尽管这个值非常小,但当样本个体满足该校特招方式要求,是能够进入该校学习的。所以QCA没有对于“覆盖率的值必须要大于多少”做出规定,但覆盖率可以反映符合不同路径的样本比例。
步骤⑨: 解的表示,解释现象和路径启示
QCA通过实例比较分析,识别出引致1结果或0结果的若干前因条件组合,每一个前因条件组合称为路径,全部路径的集合称为特定结果的解。当QCA解的一致率达到要求后,才可以进行解的现实与理论层面上的解释与意义建构。QCA提供三种解:简约解基于对所有逻辑余项的反事实假设,中间解基于容易的反事实假设,而复杂解没有做任何反事实假设。因此,当QCA数据不存在逻辑余项时,复杂解、简约解和中间解完全相同。当存在逻辑余项时,为了获取表达形式最简单的简约解,QCA依据Q-M(Quine-McCluskey)算法最优化操作,常常被迫引入站不住脚的简化假设(Baumgartner,2015)。中间解被预期为简约解的子集,并且是复杂解的超集(Maggetti和Levi-Faur,2013),中间解的复杂性处于复杂解和简约解之间;复杂解形式最复杂使得难以获得理论上更有意义的解释,而简约解由于引入不可靠的反事实分析,其最简单的表达形式令人质疑。由于样本数据结构问题,不是每一个样本池都能求出简约解与中间解。采用什么解,怎么表达解,这是QCA的一个重要选择,多数文献选择报告中间解。
另一个常用报告解的方法是同时考虑简约解和中间解,将解中的条件区分核心条件(Core condition)和外围条件(Peripheral condition),其中核心条件是简约解中包含的条件,与结果保持强关系;而外围条件属于中间解但被简约解剔除的条件(Fiss, 2011;Ragin,2007),简约解与特定结果之间的因果关系更为紧密(如图3显示)。解的图表表达可以存在不同的方式。例如,用“Y”与“N”分别表示核心条件发生(值为1)与不发生(值为0),用“y”与“n”分别表示外围条件发生与不发生,亦或用“●”与“⊗”形状以及其大小分别表示核心条件发生、核心条件未发生、外围条件发生与外围条件未发生。
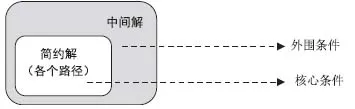
图3 核心条件与外围条件
检查和比较解的表达形式,特别是观察各个路径的条件组合,对路径简单分类与意义构建,从而分别解释每一个路径与焦点现象之间的关联,判断哪些条件或条件组合是引致特定结果发生的充分条件,哪些条件或条件组合是引致特定结果发生的必要条件。QCA中子集关系表示为:全部实例中某一条件或条件组合的集合隶属分数小于或等于结果集合的隶属分数,该条件或条件组合与结果变量之间存在子集关系,即支持充分性论断。考察两个集合X和Y,当全部X(i)≤Y(i)时,X是Y的子集,X是Y的完全充分条件,~X是~Y的完全必要条件;当极少数X(i)>Y(i)、大多数X(i)≤Y(i)时,X是Y的准子集,X是Y的准充分条件;当全部Y(i)≤X(i)时,Y是X的子集,Y是X的完全充分条件,~Y是~X的完全必要条件(如图4所示)。Mahoney和Barrenechea(2019)聚焦与集合理论四种核心逻辑关系类型相关的反事实假设:必要条件、 SUIN 条件、充分条件和INUS 条件。其中,SUIN 条件是指 “一个因素的充分但非必要的部分,对于一个结果是不充分但必要的” (Mahoney,2008),成为塑造现实生活复杂性特征的关键要素;INUS 条件是指“一个条件组合中的不充分但非冗余的部分,对于一个结果发生是非必要的但充分的”,典型地通过最小化过程产生(Bol 和Luppi,2013)。

图4 集合X与集合Y的关系
步骤⑩:解的稳健性或敏感性检验
适度普适性是QCA追求的研究价值。稳健性检验就是检验类似的分析和决策是否会导致不一样的结果。解的稳健性或敏感性检验效果取决于样本案例的数据结构。现有文献提供的稳健性检验方法有:一是二分阈值、“删除与编码”操作中的阈值以及校准锚点值的设定,如将每个前因变量值依据数值大小排序,再将前5%、前50%、后5%分位点分别设置校准函数的三个锚点;再将前10%、前50%、后10%分位点分别设置校准函数的三个锚点。Fiss(2011)建议将交叉点锚值依次向上、向下浮动25%,重新测评和检查三种解。二是运用调节变量,将全部实例分成不同的群组,检查不同群组实例计算的解的差异。三是随机将全部实例数据分成两组,比较两组数据计算结果的相似性与差异性。四是当纳入计算的实例比较少时,分组评估稳健性不可行,这样可以再去寻找类似背景的一些新的实例,检查现有的解能否给出合理的解释。
需要清楚认识到,应用QCA是思想和证据之间的对话,不要期望一次就可以获得理想的结果。前文已经分析清晰集QCA中消除矛盾组态或需要多次的试错活动。QCA应用具有迭代性特征,图1给出若不满意当前阶段处理结果时可以考虑多种试错路径,而规范的QCA操作会让研究者少走弯路。
五、结论与建议
(一)结论
通过对QCA应用关键情境聚焦性分析以及对QCA应用过程完整性描述,不难看出QCA是融合了定量思维与定性思维的组态比较方法。传统社会科学研究中的定量方法与定性方法在本体论(Ontology,实体的本质及其如何构造的)和认知论(Epistemology,知识及其如何获取的)上存在紧张关系:一些定量研究者强烈认为系统的统计分析是社会科学研究建立因果关系和实现普适化的唯一途径,但一些定性研究者认为使用定量方法无法有效地理解复杂的社会现象。定性社会科学研究基于一个社会设定(Social settings),探索“为什么”与“怎么样”的问题及其背景,追求对特定实例的深度理解,以实例为导向开展研究。定量社会科学研究基于一个受控环境,运用自然科学研究原则和实证方法对于大量实例和变量做一个较为肤浅的描述,调查量表是一个常用的工具,探索一个或多个原因变量平均效应的普适化结论,以变量为导向开展研究。对于解决定性与定量之间的紧张,如因果推理和普适性,QCA是一个有前景的方法,因而其不应视为定性与定量方法的竞争者,而是应作为互补者(Masue等,2013)。QCA超越传统的实证研究技术,是真正形式化的定性分析方法,从而开辟一种知识生产的新方式(Kan等,2013)。在中小样本研究中,QCA要求研究者与实例保持亲密程度,而在大样本研究中,需要借助于一些适用的统计分析工具。QCA基于整体视角揭开给定结果发生的简约的前因路径(Causal Paths),透视社会现象的复杂性,提升对现实的理解。
(二)建议
并发性、等效性与非对称性等QCA思维具有应用价值,识别出引致特定结果的充分条件与必要条件有助于现实问题的解决。当然,QCA本身的方法和技术内核也需要发展,如何用好QCA的原则被忽视,QCA的一些应用场景还未被充分认识,为此提出三点建议。
1.探索QCA方法与技术本身优化升级策略
简约解和反事实假设之间存在着紧张关系,Q-M算法为得到一个最大化简约的解,不可避免地纳入一些错误的或不可靠的假设。Baumgartner(2015)提出一致分析(Coincidence Analysis,CAN),替代Q-M的新优化算法,不必依赖于站不住脚的假设而获得一致性的表达形式最简约的解。除了Q-M算法,校准函数也可以改进。当前多值QCA未能提供一致性和覆盖率数据,需要进一步优化软件。对实例频数的选择、组态原始一致率的选择、校准锚点的设置的合理性,不能仅仅依赖于解的合适度评估与研究者本人的判断标准,而在此之前,QCA软件可否给出一些较为客观的评估指标?例如,有的学者在“删除与编码”操作中将实例频数阈值的设定从1变成3获得一个QCA可以接受的解,那么从1变成3的理由是什么呢?是不是数据本身不可靠?若将实例频数阈值的设定从3变成5,又可能获得QCA可以接受的另外一个表达形式的解,那么这两个解哪一个更好呢?通过观察一致率与覆盖率数值的变化吗?一些文献中前因条件变量值存在大量0.5的情况,QCA软件能否给出提醒或警示?例如,一篇文献作者采用30个实例,而其中16个实例的前因条件中存在0.5,而这16个实例被QCA软件剔除而没有进入最终解的计算,那么研究者辛辛苦苦弄出来的实例意义何在呢?QCA软件若能给出提醒,将有助于提升研究质量水平。因此,作为方法和技术的QCA,其本身需要进一步研发改进,并进而促进QCA应用水平的提高。
2.坚持QCA应用的三个原则
作为一种新兴方法,QCA被日益广泛地应用于社会科学研究。但需要保持三个特性:一是透明性,QCA全过程都应保持透明性,数据和操作显性化。简单地说,其他研究者按照文献作者提供的数据、阈值设定与关键操作可以复制QCA求解过程,并验证文献的解。二是建构性,从现象到研究问题、结果变量、实例选择、前因变量、阈值设定、锚点设定等嵌入研究者本人的意义建构。QCA要求研究者对于研究议题具有一定实体知识和理论知识,中小样本研究需要增强对于各个实例的亲密性,大样本研究需要使用合适的统计分析工具。三是情境性,QCA揭示的因果关系存在于特定的情境。当情境改变时,QCA结论或许也会随之改变,不再适用。例如,过往的一些成功的路径应用于当前可能会招致失败。因此,研究者注重这三个特性,有助于提升QCA应用水平与质量。
3.重视QCA在评估与预测方面的应用
使用集合论和布尔代数,QCA计算出来的路径与给定结果之间的因果关系可以用来评估与预测,这方面被现有的文献所忽视,但确实是QCA应用的重要方向。例如,通过QCA识别出高组织绩效的3条路径:A·B+A·~C+B·D·E,那么可计算当前观察对象个体在3条路径A·B、A·~C、B·D·E上的隶属度值,该组织可选择最大隶属度值的路径发展,清楚哪个条件是组织的短板;当然,该组织也可以不是最大隶属度值的路径发展,也知道组织的挑战在何处。若路径隶属度值最大的那个分值大于0.8,那么该企业获得高绩效预期有80%的可能性。若没有一个隶属度值大于0.8,则可判断如何有效地改进前因变量值,使得某一个路径隶属度值更容易达到0.8,并朝这个方向努力。因此,QCA有助于研究人员应用特定领域的理论和实体知识,预测给定研究对象特定结果发生的可能性,评估对策的合理性与有效性。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
今日农业(2021年21期)2021-11-26 05:07:00
河北农机(2020年10期)2020-12-14 03:13:42
凿岩机械气动工具(2017年2期)2017-07-19 10:21:13
初中生世界·八年级(2017年3期)2017-03-24 15:36:23
中学生数理化·七年级数学人教版(2016年6期)2016-05-14 13:56:13
西南交通大学学报(2016年6期)2016-05-04 04:13:05
工业设计(2016年11期)2016-04-16 02:49:22
中国铸造装备与技术(2015年5期)2015-12-10 10:23:41
初中生世界·八年级(2015年4期)2015-08-04 07:59:48
