
基于语义API依赖图的恶意代码检测
2020-06-03 10:55赵翠镕张文杰
四川大学学报(自然科学版) 2020年3期
赵翠镕, 张文杰, 方 勇, 刘 亮, 张 磊
(四川大学网络空间安全学院, 成都 610065)
1 引 言
当前的恶意代码检测主要是基于二进制文件静态特征的静态检测和基于动态行为分析的动态检测.静态检测通过提取二进制文件的反汇编序列,字符串,字节码等特征来表示程序的行为.静态检测即为基于特征码的检测方法,通过匹配特征库中的特征签名来检测恶意代码,是反病毒软件最为常用的检测方法.此类方法的简单,快捷等优点吸引了很多研究者的关注. Ahmadi等人[1]基于微软2015提供的Kaggle数据集[2],提出了一种基于十六进制字节码和反汇编序列层次的恶意代码分类方法,基于XGBoost分类器来进行恶意代码分类,在保证分类精度的前提下,降低了性能开销.Hassen等人[3]提出一种基于函数调用图的恶意代码分类方法,在图匹配算法上进行改进,提高了分类精度和性能.Han等人[4]提出一种基于图像进行恶意代码检测的方法,通过把二进制文件转换为图像和熵图来进行恶意代码分类.以上的方法都是从二进制文件的不同层次来提取特征,在一定范围内可以达到很高的检测率.但是随着越来越多的样本添加了反静态检测的功能,如加壳、多态、混淆等,静态检测的效果越来越差.
基于动态分析的检测方法不受加壳,多态,混淆等因素的影响,可以有效检测已知和未知的恶意代码,受到了众多研究者的青睐[5-8].动态检测是通过在沙箱中执行恶意代码,通过获取样本与系统对象,资源和服务等的实时交互,基于程序的动态行为来构造特征用于恶意代码检测.此类方法大多基于API序列构造特征,因为API是应用程序与操作系统的接口,程序的行为如文件操作,进程操作,注册表操作等都是通过调用特定的API来实现的.因此众多研究人员基于API特征进行恶意代码检测.Hansen等人[5]提出了一种基于API调用及其相关信息作为特征的动态检测方法,相比其他方法,在特征种类和特征剪枝上进行创新,达到了不错的检测效果.Ding等人[6]提出一种基于家族行为依赖图的恶意代码检测方法,采用动态污点分析构建行为依赖图,然后基于最大权重子图匹配来检测恶意代码.Ki等人[7]提出一种新颖的基于DNA序列比对算法的恶意代码检测方法,基于该算法从不同类别的恶意代码中提取恶意行为的常见API调用模式来检测恶意代码.上述的基于动态分析的检测方法大多基于序列挖掘和图匹配的方法进行恶意代码检测.基于序列挖掘的方法易受系统调用注入的影响,如插入一些无关的API调用,从而导致挖掘出来的API序列不再具备普适性.基于图匹配的方法,时间开销较大,并且随着恶意代码行为的越来越复杂,图匹配的复杂度会越来越大.基于系统调用的注入混淆具有改变代码语法特点但是仍保留行为语义的特点,基于语义的检测方法利用这一特点,通过抽象语义特征来进行检测可以达到较好的效果.
本文提出了一种基于程序语义API依赖图的恶意代码动态检测方法,在真机物理环境执行恶意代码,使某些具有反虚拟机特征的恶意代码得以正常运行,提取程序运行中较为完整的API调用来构建API依赖图,基于广泛应用于信息理论领域的AEP概念[9],提取API依赖图的语义相关的典型路径来定义程序的行为,以典型路径的平均对数分支因子和直方图bin技术来构建特征空间,不包含原始的API调用,字符串等信息,从而增加了恶意代码检测模型的鲁棒性,不易被攻击,最后采用集成学习方法-随机森林来分类恶意代码.
2 恶意代码检测方法实现
2.1 方法概述
本文提出了一种新的恶意软件检测机制,通过利用系统级信息流来描述程序行为.表征的行为是用于构建和训练特征空间的语义相关路径来表示的.为了提取和识别语义相关的路径,本文基于信息论中AEP的概念来实现.根据AEP,在任何图形中,都存在几条路径,几乎包含图形的所有信息.遵循这个概念和文献[10]给出的证明,将AEP应用于本文所提出的提取与语义相关的路径的方法,构造出一组语义相关路径.在该路径上本文应用了一个称为平均对数分支因子(ALBF[11])来构建样本的特征空间.最后采用随机森林的机器学习方法来训练和分类恶意代码.这篇文章所提出的方法如图1,分为三个阶段,API序列提取,特征空间构建和检测模型训练.

图1 方法流程图Fig.1 Flow chart of the method
(1) API序列提取:通过改造现有的CuckooSandbox[12]环境,采用真机作为样本分析环境,捕获较为完整的系统API调用,作为原始的API序列数据.
(2) 特征空间构建:基于预处理后的API调用顺序构造API依赖图;然后,根据AEP概念提取语义相关的API序列路径;最后,采用平均对数分支因子构建特征空间.
(3) 检测模型训练:首先,对得到的特征进行筛选,降低特征维度;然后,进行随机森林分类器进行训练得到检测模型,用于恶意代码检测.
2.2 API依赖图构建
本节主要工作是把API调用转换为有序的API依赖图.图的顶点对应于程序跟踪中的API调用,顶点u到顶点v的边对应为与

(1)
其中,Si→Sj代表从Si到Sj的转变,284代表着WinXP的284个NTAPI函数.如前所述:路径假设为马尔科夫链,所以满足马尔科夫属性公式(2).
(2)
API序列{S1,S2,S3,S4,S5,S1,S2,S5,S1,S2,S3,S5,S1,S3,S4,S5,S1,S3,S5}的图表示如图2所示,每一个边上的数字代表其转移概率Pij.表1为对应的TPM矩阵.

图2 API依赖图Fig.2 API Dependency Graph
表1 API依赖对应的TPM矩阵
Tab.1 The TPM matrix corresponding to the API dependency graph
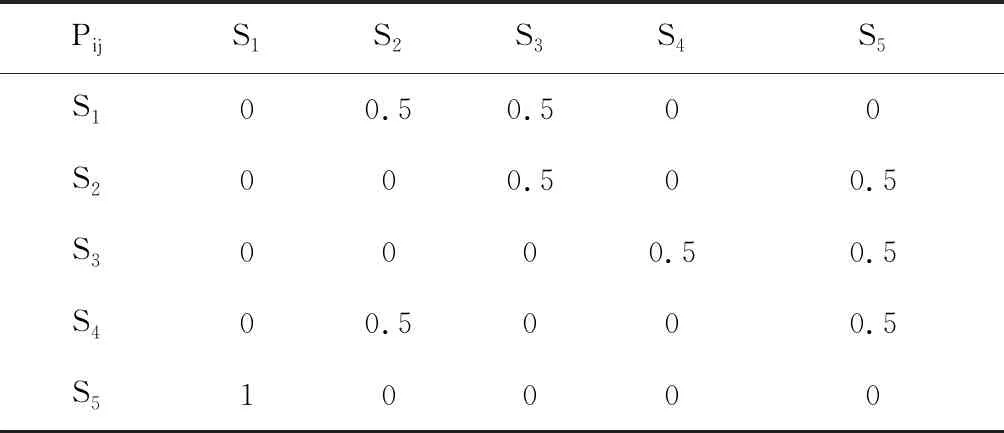
PijS1S2S3S4S5S100.50.500S2000.500.5S30000.50.5S400.5000.5S510000
2.3 抽取语义相关路径
根据AEP,对于随机过程,存在几条路径比图形的其他路径拥有很多的语义信息.作者已经证明了这个观点,并且称之为“典型路径”.本文也遵循同样的概念,假设也存在典型路径,图的路径有以下定义.
定义2 路径P={S1,S2,...Sn}代表从S1开始到Sn结束的路径.
S1代表路径P第一个NTAPI调用,Sn代表路径P最后一个调用,路径的每个边代表从一个API调用到另一个API调用的转变.Pr(S1)表示S1出现的次数占所有出现的API序列次数的比例.而Pr(Si|Si-1=Si-1)则用Si-1到Si的转移概率来表示.计算公式如式(3).此步骤的目的是确定所有从Sstart到Send的路径,然后再来提取相关路径.
Pr(P)=Pr(S1)×Pr(S2|S1=
S1)×...Pr(Sn|Sn-1=Sn-1)
(3)
为了判断路径的相关性,对每条路径应用AEP,首先确定样本的最大熵值,如公式(4).
(4)
其中,n代表路径长度;Tn代表路径为n的路径总数,为了定义具有ε相关的ε语义相关路径,应用以下公式(5)来确定.
(5)
基于以上的理论,相应的语义相关路径提取算法的伪代码如算法1所示.
算法1语义相关路径提取算法
输入API序列S={S1,S2,…,Sn}
输出语义相关系数ε={ε1,ε2,…,εm}与其对应的路径Path P={P1,P1,…,Pm}
1) Function main(S)
2) 初始化ε=Ø,P=Ø,S_temp=Ø,T=Ø,λ=Ø
3) N_sequence=len(S),N_api=len_api(S) #N_sequence是所有序列的长度,N_api是API调用的数量
4) ForSiin S do #计算Si节点的下一个节点以及概率,构造转移概率矩阵
5) IfSinot in S_temp do
6) S_temp.append(Si)
7) S_temp[Si]=Cal_nextAPIandProbability(Si)
8) P=Cal_allpath(S_temp) #利用深度优先算法求出所有的从S1到Sn的路径
9) MinPathLen=Cal_minPathlen(P) #计算路径的最小长度
10) MaxPathLen=Cal_maxPathLen(P)#计算路径的最大长度
11) For I =MinPathLen; i 12) Ti=Cal_lenPath(P,i)#计算路径长度为i的长度数量 13) λi=log(Ti)/i 14) λmax=Max(λi)#计算样本的最大熵值 15) For Piin P do 16) εi=abs(1/(len(Pi)*log(Pr(Pi)))-λmax)#计算每条路径对应的最小语义相关系数 17) Return ε, P 18) Function Cal_allpath(S_temp) #计算所有从S1到Sn的路径 19) S_path= [Si] 20) For Siin S_temp[S1].keys() 21) DFS(Si) 22) Function DFS(Si) #深度优先算法,结束条件是达到Sn,最后一个API调用节点 23) S_path.append(Si) 24) If(Si==Sn) 25) P.append(S_path) 26) Break 27) Else 28) DFS(Si+1) 29) S_path.pop() 算法的输入为在动态分析环境中提取的API序列,输出为所有的路径P以及对应的语义相关系数ε.给定特定的ε,即可得到在ε条件下所有满足条件的语义相关路径. 算法1中,第2)~7)行是获取所有的API调用以及其下一个节点,构建转移概率矩阵;第8)行为针对得到的转移概率矩阵采用深度优先算法进行搜索出所有的从S1到Sn的路径,以节点Sn作为终止条件;第9)~10)行则是通过计算所有路径的长度,求出最小路径长度和最长路径长度;第11)~13)行是计算路径长度从最小到最大的各个路径长度的路径数量,以及对应的熵;第14)行则是计算出路径的最大熵用于下面相关系数的计算;第15)~16)行则是通过式(5)计算每一条路径的语义相关系数;第18)~29)行则是采用深度优先算法计算出从S1到Sn的所有路径的具体过程.算法的返回值为所有的路径和相应的相关系数. 下面通过一个API依赖图来进行解释.如图3所示,图中有6个结点,1号是开始结点,6是结束结点.每个API节点上面的分数代表该API被调用的概率,如节点1的调用概率为2/29,2代表被调用了两次,29代表所有API被调用的次数之和.根据API依赖图可以得到表2的TPM转移矩阵.然后根据所有的路径首先确定最大熵值λ,然后根据式(5)得到每条路径相应的ε值,由表3可以看出ε在1.647到2.929之间变化,选择不同的ε值会得到不同数量的相关路径,选择ε=2.1会有P1,P2,P5三条路径,选择ε=2.0会有P1,P2两条路径,通过这些不同的路径,训练不同的检测模型来比较检测精度.选择检测精度最高时对应的ε值应用于实际的检测工作. 图3 API依赖图示例 表2 TPM矩阵 表3 路径概率和相关系数 ε 构建特征空间,本文采用“直方图分组bin”技术,这主要应用于信息检索,图像处理和文本处理领域.因为它包含近似匹配,所以降低了对调用序列轻微变化的敏感性.然后使用ALBF(平均对数分支因子)来构建样本的特征空间.平均对数分支因子定义如式(6). (6) 其中, B(S1,S2,S3,...,Sn)=∏1<=i<=nb(Si) (7) 其中,b(Si)代表结点Si的分支因子,我们定义每个bin代表一个ALBF的范围,这些bin以均匀的间隔分割,其中包含着各个相关路径的频率次数,也即是特征.比如如果特征空间有4个bin构成,b1,b2,b3,b4.对于某个程序来说各自的频率次数为f1,f2,f3,f4,那么得到的特征向量就是 对于得到的特征,采用机器学习的方法来分类.并不是所有的特征对最后的分类效果都是有用的,为了去除无关的特征,降低维度,减少时间代价,本文选择采用信息增益来进行特征选择,去除一些对分类无用的特征.最后使用基于集合的学习算法-随机森林来区分恶意样本和良性样本.随机森林在恶意代码分类中应用广泛[4-5,13-15].在众多研究者的对比中,应用在恶意代码分类时,在准确性和有效性方面都优于支持向量机(SVM),逻辑回归(LR),K近邻(KNN)等算法,即使在噪声存在的情况下也能提供很好的信息泛化,并且当数据较大时也能得到相当好的效果.因此,本文采用随机森林的方法来实现分类.在给定的样本空间之中,采用3折交叉验证来分类预测.将数据集分成3份,轮流把两份做训练,一份做验证. 实验中选用了1 110个恶意代码样本和667个正常样本,恶意样本来源于是VirusShare[16]网站,对恶意样本的标注则是基于VirusTotal[17]网站的众多扫描引擎给出的结果.正常样本则来源于Windows操作系统中正常的应用程序.实验环境则是基于改造的Cuckoo环境,通过更改虚拟机为物理机器,并对现有的一些易被检测到的Cuckoo沙箱的特征进行了隐藏,在一定程度上避免样本的检测,获得较为完整的行为. 本文根据流行评估指标真阳性率TPR,假阳性率FPR,真阴性率TNR,假阴性率FNR和精确度Precision来评估这篇文章所提出的方法的有效性,如表4所示. 表4 评估指标 实验结果如表5所示. 表5 实验结果 从表5可知,当ε∈{1.5,2.0,2.5,3.0}的时候产生较高的检测精度.可以从表统计中很容易判断出构建的特征空间能够有效的区分出恶意样本和正常样本.而且可以看到检测模型在ε=2.0的时候达到最高的97.1%的检测精度.因此可以选择ε=2.0作为阈值来进行实际的检测工作.实验中应用ε的各种值来进行实验验证假设,即较小的ε值排除了一些信息比较丰富的路径,而较大的ε值又导致信息泛化从而导致检测精确率的降低. 虽然应用了真机分析系统,反虚拟机的手段不再奏效,但是由于本文使用的Cuckoo沙箱,由于一些反沙箱技术的流行,一些恶意样本在运行期间,这些样本很快终止,并没有表现实际的恶意行为,所以仅产生部分日志,引起了错误分类从而导致了FNR的增加.另外也有一些正常的应用程序与恶意代码呈现高度的相似性,比如调用与内存访问,进程和线程处理活动等相关的系统调用,这也会导致FPR的增加. 为了表示所提出的方法的有效性,本文与文献[18]提出的基于图匹配的分类算法,文献[19]提出的基于序列挖掘的方法,和文献[20]中提出的基于组合学习的检测方法进行了对比,实验结果表6所示,本文所提出的基于语义API依赖图的方法检测精度上要明显优于其他方法. 表6 与其他算法的对比结果 本文设计了一种基于程序语义API依赖图的动态行为检测方法,采用真机作为分析环境,以Cuckoo的修改版作为分析框架,获得较为完整的系统信息流-API调用序列.本文采用程序语义来定义程序的行为,基于API序列构造API依赖图,然后基于信息论AEP概念,提取API依赖图中语义信息丰富的相关路径来表征程序行为,然后基于相关路径的平均对数分支因子来构建特征空间,最后采用机器学习算法-随机森林进行训练然后进行分类.实验结果表明这篇文章提出的方法能够有效进行恶意代码检测,达到了97.1%的检测精度. 本文提出的恶意代码检测方法从分析框架方面来看,整体框架是基于Cuckoo框架改造而来,而Cuckoo是从应用层进行监控API函数的调用,很多较为底层的函数就无法监控到,从而得到的信息并不全面,从而影响到分析效果. 下一阶段的工作要着重于搭建一个内核态监控的分析框架;另一方面,本文并没有考虑到PE文件的多路径执行问题,因此,不能有效监测满足一定触发条件才进行恶意行为的恶意代码.


2.4 构建特征空间
2.5 分类模型训练与检测
3 实验结果和分析
3.1 实验环境与数据
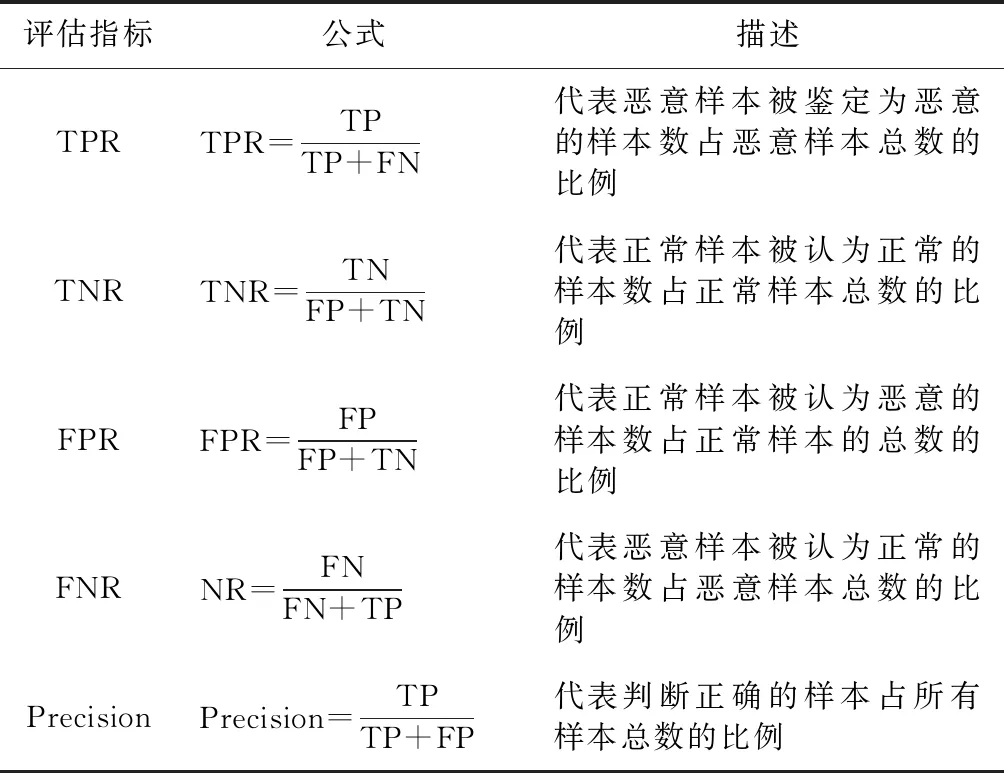
3.2 实验评估指标
3.3 实验结果


4 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
商品与质量(2019年34期)2019-11-29
计算机系统应用(2019年3期)2019-03-11
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
中国信息化·学术版(2013年1期)2013-05-28
西南学林(2011年0期)2011-11-12
