
基于共识和分类改善文档聚类的识别信息方法
2020-06-01 10:54王留洋俞扬信陈伯伦
计算机应用 2020年4期
王留洋,俞扬信,陈伯伦,章 慧
(淮阴工学院计算机与软件工程学院,江苏淮安223003)
(∗通信作者电子邮箱wangly@hyit.edu.cn)
0 引言
目前,大量数据通过不同的渠道源源不断地汇集到互联网数据库中,并有针对性地作为互联网的副产品进入社会。网络信息的巨大容量对搜索引擎的信息检索效率造成了巨大威胁。在搜索引擎返回数千个搜索结果中,只有极少部分与用户感兴趣的话题有关[1]。对无标记数据可进行无监督数据分析。数据聚类是一种无监督学习技术,聚类利用数据中的非结构化信息揭示数据间潜在的关系[2]。
个人资料库和公共论坛中的信息通常以文本形式出现,这样的数据无法用传统数据库工具进行抓取、管理和处理。文本数据一般属于未标记数据类别,可通过数据聚类技术进行分析。数据聚类技术在计算机中的应用已超过50 年,现有的技术有共识聚类、多视图聚类、集合聚类和累积聚类等。
近年来,不同的聚类算法用于设计各自的策略,然而,每种技术在执行特定数据集时都有一定的局限性。因此,缺少一种通用的数据聚类方法,支持不同技术的混合聚类,即共识聚类。共识聚类可通过以下几步实现:首先,划分训练数据,并使用不同聚类方法对每个数据进行分区,以便获得基本结果;其次,使用相同的算法,进行不同的初始化或使用不同的参数,通过聚类技术间的关系建立共识;最后,使用不同的特征空间给共识分配新标签,并在第一时间通过聚类更改基础分区,设计最终的聚类方案[3]。本文提出了一种使用监督学习方法集成文档聚类的共识构建方法,该共识构建方法是现有文档聚类的共识聚类技术的新补充,共识功能使用了一种基础聚类生成的标签训练分类器,且训练分类器通过预测标签生成最后的分区。
1 相关研究
数据聚类是开发未标记数据的底层结构的基本工具之一。文本数据种类繁多,数据聚类技术需不断发展,以适应未来的挑战。目前,大多数设计的数据聚类方法都具有已知的潜力,但在大多数情况下,没有一种通用的技术能够保持良好的性能。可靠的解决方案是将不同的聚类技术融合成一个单一策略。
将多种聚类技术结合起来进行最终数据划分的想法启发于分类器和信息融合中使用的类似策略启发。与此类似,K 均值(K-means)方法先从n 个数据对象任意选择k 个对象作为初始聚类中心,然后计算每个所获新聚类的聚类中心,进行多次K均值聚类分区,最后直到每个聚类不再发生变化为止,以找出结果中的任何关联。然而,已有文献尚未意识到数据分布对K 均值算法的影响,并未理解算法与数据具有很强的耦合关系。文献[4]提出了一种使用共同关联样本矩阵映射相关联的方法,通过在最终分区的关联矩阵上应用基于最小生成树(Minimum Spanning Tree,MST)的聚类,对任意形状的聚类进行扩展。Fred 等[5]利用相似矩阵上的单链路和平均链路方法对EAC(Evidence Accumulation Clustering)的计算缺陷进行分类。和一般的集成聚类不同,EAC 并不直接组合不同的划分,而是由这些不同的划分得到一个邻近度矩阵。之后便可在这个邻近度矩阵上运用层次聚类中的单连接算法得到最终的划分,即从多个分区中获得的公共信息,进行最终聚类。
聚类融合结合了多种数据集群技术,可以生成初始标签并形成最终统一的群聚解决方案。据了解,在早期的划分步骤中,在构造和积累知识时会丢失一些有价值的信息,如关联矩阵这样的中间表征特征缺少一些参与聚类技术的数据条目。文献[6]研究了丢失信息对融合聚类结果的影响,并提出了一种通过聚集间的相似性链接方法,通过揭示集群之间的相似性来猜测未知条目。最后,利用图分割技术得到最终的聚类结果。投影聚类集合结合了输入数据子空间聚类和集合聚类本身,利用集合聚类的知识对数据子空间进行优化。文献[7]提出了自适应集成聚类,并设计了一种输入数据子采样的自适应集成策略。子样本利用了以往的聚类结果,并强调在共识过程中存在不良历史的样本。聚类可以利用分类技术,通过比较基本聚类方法的比例结果来达成共识。
多视图聚类的灵感来自多视角学习的概念。多视图聚类通过对多维数据进行预处理和对处理后的数据进行聚类投影、分类解决聚类时所涉及的技术[8]。其中一个技术是描述无监督学习问题的共正则化,文献[9]提出了一个光谱聚类目标函数,该函数隐式地将来自多个数据视图的图结合起来,以获得更好的聚类。多视图聚类的另一个技术是使用标准化来解决共识的非负矩阵分解(Non-negative Matrix Factorization,NMF)。它从多个视图中学习到的集群结构的表示应该规范化,以达成共识。类似的想法将多流形正则化纳入NMF,从而保留了数据空间的局部几何结构。
共识聚类有助于确定最佳的聚类集。文献[10]提出了一种在分布式环境下实现幂迭代聚类的方法。利用某种相似性度量方法,将原始数据转换成一个可以视为图的亲和矩阵。通过顶点切割,把行归一化后的亲和矩阵切分成若干个小图,图的每一个划分子图对应一个类簇。通过从多个聚类算法形成共识矩阵来猜测聚类的数量,根据关联图的近似非耦合结构受益的有效性,确定最佳聚类集。
上下文中最新想法是将不同数据分区视图结果与来自不同集合技术的相似矩阵结合起来,为共识决策计算出最终的相似矩阵[11]。计算机矩阵的相似性度量方法有:基于聚类的相似性矩阵、相似性矩阵和成对相异性矩阵。相似矩阵中分配的权重用于聚集。共识聚类的基本原理是通过几种策略得出的:使用具有相似参数的不同聚类技术、使用具有不同聚类参数的单一策略或两者的组合。另一个想法是对训练数据进行分区,并使用不同聚类方法对数据进行分区,以获得基本结果。聚类的结果来自于早期的基础阶段。共识可以使用投票公式分配新的标签[12]。著名的共识策略有:层次凝聚-聚类共识、最远共识、基于聚类的共识、期望最大化共识、迭代投票共识和基于片段的聚类共识[13]。
近年来,共识聚类在文档聚类中得到了广泛的应用和有效 的 使 用。Topchy 于2003 年 使 用QMI(Quadratic Mutual Information)作为效用函数,提出利用K 均值算法来解决共识聚类的问题,即将共识聚类问题在QMI 下转化成经典的K 均值优化问题[14],如何种效用函数的效果比较优越、如何处理样本不一致问题以及其收敛性等,都亟待解决。共识聚类相比单一聚类算法的优势体现在鲁棒性、新颖性、稳定性、并行性和扩展性等[15]。然而,共识聚类是一个具有挑战性的工作,其主要难点在于从不同聚类结果中求出一个共识划分,使得共识效用函数最大。学者从不同角度解释基础聚类器产生聚类结果的共性,从而找出共识聚类结果。
本文提出一种基于共识和分类的文档聚类(Document Clustering by Consensus and Classification,DCCC)策略,实现共识和分类文档自适应集成聚类。利用基于关键词DIM(Discrimination Information Method)的不同文档聚类算法的优势,揭示它们之间的潜在关系。从有关文献中可明显地看出,每个DIM 都利用来自不同潜在客户的数据,因此会发现不同的聚类解决方案[16]。然而,簇重叠最有可能出现在每个解决方案中,并且有一些文档与其聚类解决方案相符。簇解决方案可以将这些文档保持在相似的簇中。这些带有簇标签的融合文档有助于训练共识分类器[17]。分类器使用从早期聚类解决方案中发现的知识来预测与初始聚集簇标签信息不一致的文档,从而确定最终的聚类解决方案。聚类利用分类技术是本文研究的主要焦点。
2 文档聚类识别信息方法
近年来,利用文档的K 簇识别信息的文档聚类算法的高性能已得到有效的证明。这些聚类算法迭代地将文档投影到K 维识别信息空间上,并将有最大值的簇分配给一个文档。在每次迭代中,关键词识别信息定义了识别信息空间,其中关键词识别信息是根据上一次迭代中生成的标记文档集进行估计的。该聚类方法作为优化问题被提出,目标函数可以使用各种可用的统计和信息理论度量[18]。人们经常使用以下方法发布目标函数的结果:相对危险度(Relative Risk,RR)、识别信息方法(Method of Discrimination Information,MDI)、域相关性(Domain Relevance,DR)和 域 识 别(Domain Consensus,DC)。
使用发布函数方法可能带来另一个风险,即在相同数据的不同解决方案之间如何选择最佳方案。虽然不同的聚类解决方案可选择不同的方法来计算最终簇数,但可计算的簇数之间存在显著的相似性。因此,对来自不同聚类方法的同一簇中的文档须有统一的簇标签。文本分类器使用这些同义文档的簇标签进行训练,随后该分类器再用于预测不同文档的簇标签,使用共识和分类改善文档聚类的工作流程如图1 所示,图2是DCCC过程总结的可视化。
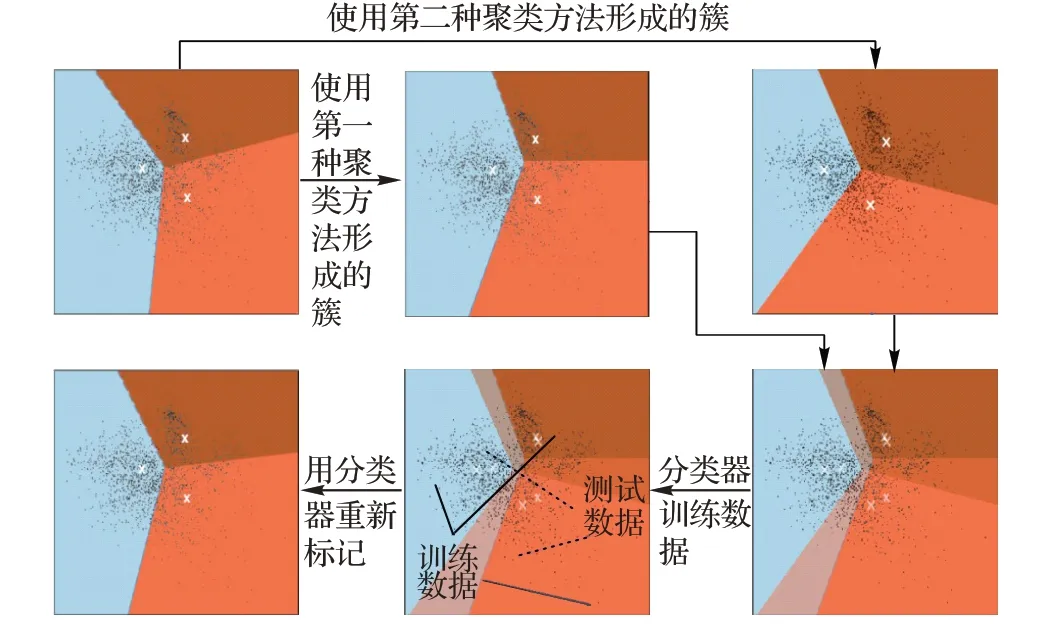
图1 本文方法的简单工作流程Fig.1 Simple flowchart of the method proposed in this paper
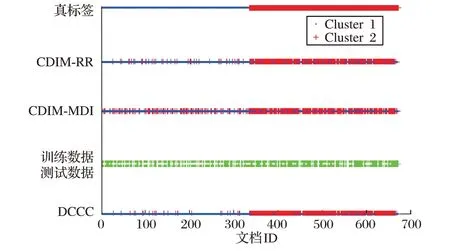
图2 DCCC过程总结的可视化Fig.2 Visualization of DCCC process summary
2.1 使用CDIM初始聚类
本文选择CDIM 作为数据集生成初始聚类的解决方法。CDIM是一种迭代分区文档聚类方法,在从M维输入空间转换的K 维识别信息空间中找到K 组文档,其中M 表示词汇表中不同关键词的总数。通过有效的文挡投影和分配可实现这一目标,最大限度地提高文档的识别数总和。CDIM-RR 和CDIM-MDI 是CDIM 的两种变体,用来寻找初始聚集ERR和EMDI。第一类使用RR,第二类使用MDI、CDIM-RR 和CDIMMDI看作是CDIM识别项加权策略。
2.1.1 CDIM-RR
用CDIM-RR 时,关键词xj在簇Ck中的RR 高于剩余簇-Ck的。簇Ck中的关键词xj的识别信息(如wjk)和剩余簇-Ck中的关键词xj的识别信息(如-wjk)由式(1)~(2)给出。

其中:p(xj|Ck)是簇Ck中的关键词xj的条件概率。关键词识别信息要么为0(无识别信息),要么大于1,较大值表示有较强的识别能力。
2.1.2 CDIM-MDI
用CDIM-MDI 时,MDI 用于计算关键词的识别信息,量化关键词间的语义相关性。类别1 和类别2 分别定义为:ifdI1和ifdI2。在文档聚类中,ifdI1和ifdI2分别对应于簇Ck和簇-Ck。方法定义如下:

其中:λ1和λ2分别是Ck和的已有概率。关键词xj的识别具有以下不平等特征:
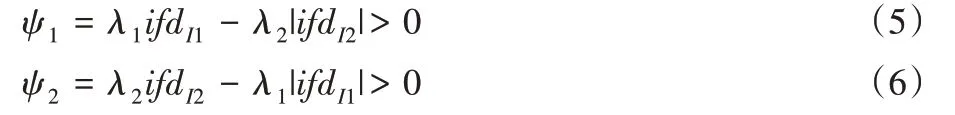
如果满足不等式(5),则关键词xj支持ifdI1超过ifdI2;当满足不等式(6),则关键词xj支持ifdI2超过ifdI1。根据不等式(5)~(6),CDIM的wjk和-wjk的识别项权重如下:

2.2 寻找共识
在分别使用CDIM-RR 和CDIM-MDI 获得两个簇集ERR和EMDI后,下一步就是将这两簇集结合起来,寻找相符的文档。由于无监督特性的原因,导致CDIM-RR 和CDIM-MDI 分配给文档的簇标签不同。为了解决这一问题,需将每个簇Ci∈ERR和Cj∈EMDI进行比较,将ERR和EMDI中最相似的两个聚类分配相同的簇标签,依次共产生K 个簇标签,并使用Jaccard 指数计算两簇集的相似度。Jaccard 相似度为:Ci和Cj交集的大小与并集大小的比值,即

相似度值越大说明两聚类集共识文档数越多。当Ci和Cj都为空时,J(Ci,Cj)= 1。

2.3 使用分类器进行改进
位于CDIM-RR和CDIM-MDI同一簇中的文档很可能正好聚集在一起,将这些文档与它们的簇标签信息一起生成文本分类器的训练集。
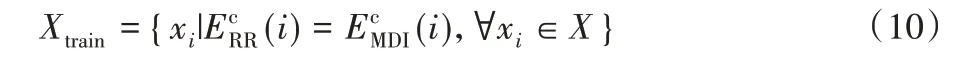
其中:Xi是数据集X中第i个文档。
对于没有在CDIM-RR和CDIM-MDI同一簇中的剩余文档则生成文本分类器的测试集。
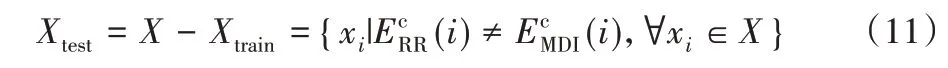
本文选择DTWC 文本分类器。DTWC 是一种基于识别式加权的线性识别方法,可用于文本分类,而且实践表明具有良好的分类结果[19]。尽管可以使用任何文本分类器,但除了其效率和良好结果外,选择DTWC 的另一个原因是该方法的识别特性与初始聚类方法CDIM 相匹配。是簇标签的最终列表,融合了训练集中文档的共识簇标签和测试集中被DTWC预测的文档簇标签。算法1为本文算法的流程。
算法1 DCCC。
输出 X(关键词-文档数据集),K(簇编号)。

3 实验与结果分析
3.1 数据集
在8个网络数据集上评估了本文的聚类方法DCCC。表1给出了这些网络数据集的关键特征。数据集1、3 到8 进行预处理,同时对数据集2进行了停用词的删除和封堵。

表1 数据集及其特征Tab.1 Datasets and their characteristics
数据集pu 是从Internet Content Filtering Group 的网站获得,包含标记为垃圾邮件或非垃圾邮件的特定用户收到的电子邮件;数据集movie 来自Internet 电影数据库(Internet Movie DataBase,IMDB)的电影评论,每个电影文档都有正面或负面评论;hitech、tr31、re0 和wap 数据集来自明尼苏达大学的Karypis实验室;数据集hitech 来源于圣何塞水星报,这些文章作为TREC(Text Retrieval Conference)系列的一部分发布;数据集tr31 来自TREC-6,此数据集中的查询类别与其最相关的文档对应;数据集re0 来自Reuters-21578 文本分类测试集分发版1.0;数据集wap 是从WebACE 项目中获得的,每个文档对应于Yahoo!主题层结构中列出的网页;数据集cora是一个指标矩阵,表示文档中某个关键词的存在或不存在;citeseer是出现在网站上的文章的集合,这些文章的视图与关键词-文档矩阵相对应。
3.2 聚类验证方法


图3 计算一个文档的BP和BR示例Fig.3 Example of calculating BP and BR for a Document
3.3 实验结果与分析
通过CDIM 进行聚类可获得高质量结果,但需在方法RR和MDI之间进行选择。
尽管CDIM-RR 和CDIM-MDI 的性能不同没有统计学意义,但从结果中可以看到一个简单的模式,如图4 所示。对于较小的种类数,RR 较强;而对于较大的种类数,MDI较强。这种模式促进了共识聚类方法的融合发展。
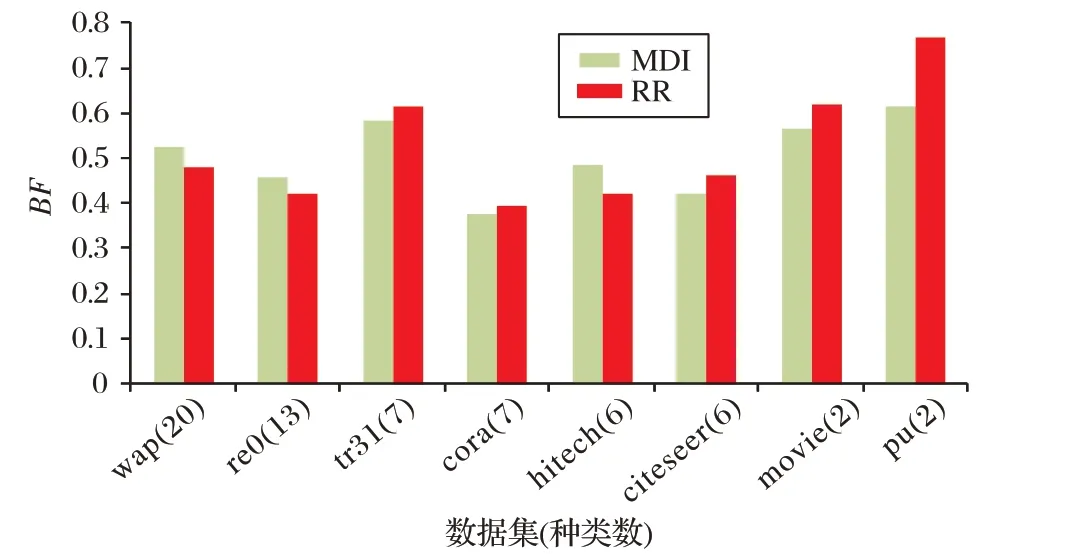
图4 不同数据集的RR和MDI的比较Fig.4 Comparison of RR and MDI of different datasets
表2 是本文提出的DCCC 方法与CDIM-RR、CDIM-MDI 和HierLink方法进行的比较。

表2 DCCC方法与CDIM-RR、CDIM-MDI和HierLink方法的比较Tab.2 Comparison of DCCC with CDIM-RR,CDIM-MDI and HierLink methods
表2 中最后一列显示的是DCCC 方法比单个聚类方法的平均值提高的百分比。在HierLink 方法中,首先,通过基于相同的簇成员计算所有对象的成对相似度矩阵来实现基础的共识聚类。然后,利用“区”链接进行分层聚类,最终达到聚类的目的。利用CDIM-RR和CDIM-MDI的两种初始聚类方法计算相似矩阵。与CDIM-RR、CDIM-MDI 和HierLink 相比,DCCC的结果都有显著改善。
表3 是DCCC 方法与其他共识聚类方法[8]的比较,表中显示的是精度值,本文提出的DCCC方法明显优于其他方法。

表3 DCCC与其他共识聚类方法的精度对比Tab.3 Comparison accuracy of DCCC and other consensus clustering methods
4 结语
本文提出了一种文档聚类的共识构建方法。在不同的数据聚类工具生成的簇解决方法中,DCCC 使用分类工具进行共识度量。本文选择CDIM 寻找初始簇:CDIM 使用识别信息最大化进行文档聚类。起始阶段,使用不同聚类的解决方法寻找共识文档,即哪些文档应该属于最相似的簇。同时,识别文本分类器DTWC 接受共识文档的培训。而后,DTWC 文本分类器预报与初始聚集簇标签信息不一致的文档。为了获得不同的初始视图,本文采用了RR 和MDI 两种识别方法。RR和MDI 具有不同的优势,在DCCC 中进行融合可达到提升性能的效果。利用8 种标准网络数据集验证了本文方法的有效性。
本文方法是一种通用的共识方法,可应用于文档聚类之外的其他领域,并可测试不同的初始聚类方法和不同的分类方法。目前,只有两种方法用于初始聚类。在未来,本文的目标是测试其他识别方法的融合、聚类和分类。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年15期)2022-07-28
客联(2022年3期)2022-05-31
电子产品世界(2022年4期)2022-04-21
南京理工大学学报(2022年1期)2022-03-17
中国新闻周刊(2021年26期)2021-07-27
计算机应用与软件(2021年7期)2021-07-16
电脑爱好者(2021年9期)2021-05-12
计算机系统应用(2021年2期)2021-02-23
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
