
基于视觉注意机制的大范围水体信息遥感智能提取
2020-06-01 10:54汪权方张梦茹汪倩倩陈龙跃杨宇琪
计算机应用 2020年4期
汪权方,张梦茹,张 雨*,汪倩倩,陈龙跃,杨宇琪
(1. 湖北大学资源环境学院,武汉430062; 2. 湖北省农业遥感应用工程技术研究中心(湖北大学),武汉430062)
(∗通信作者电子邮箱864711182@qq.com)
0 引言
近年来,随着天地一体化对地观测网络的形成和智能计算技术的快速发展,遥感信息技术正逐渐进入一个以数据模型驱动、大数据智能分析为特征的遥感大数据时代,信息智能提取已成为遥感大数据时代的必然趋势[1],特别是机器视觉识别技术的巨大成功,更是为遥感信息智能提取提供了重要机遇。不过,当前以基于深度学习为代表的人工智能算法主要是针对真彩色的RGB 三波段自然图像来研制的,而遥感图像由于在数据产生方式、获取条件、数据信息和应用等诸多方面都相对常规自然图像具有非常明显的独特性,特别是中高分辨率的遥感图像观测尺度大、场景复杂、所含波段数较多(通常超过三个波段)等特点,使得现有的机器学习模型和人工智能算法对遥感图像的理解和特征提取还存在明显不足[1-2]。因此,要实现包括水体在内的大范围地表信息高精度遥感智能采集,关键在于需要结合对地观测信息的理解和应用需求,研究契合遥感数据内在特征的智能信息提取模型、方法与系统工具,这也是解决遥感大数据时代信息智能提取与知识挖掘的必由之路[1]。
水是人类赖以生存和发展不可缺少的基础资源之一,广域分散式大范围分布的水体高精度智能检测与定位是遥感信息智能提取研究的重要内容[3]。目前用于水体信息遥感提取的方法主要有单波段阈值法、谱间关系法、比值指数法、图像分类法和基于多特征多分类器组合的水体信息提取方法等[4-6]。其中,基于多特征多分类器组合的水体信息提取法主要针对仅以单一特征构造的分类器往往只能利用水体局部特征信息,从而导致水体提取效果不理想的现象而提出的,该方法首先利用水体的光谱、指数等多个基本特征构造弱分类器,然后将各弱分类器加权组合生成一个强分类器,据此再基于AdaBoost 算法进行水体识别[7-8],因此,与其他几种水体遥感识别方法相比,基于多特征多分类器组合的水体信息提取法不仅能在一定程度上实现水体信息的遥感智能采集,而且也往往具有较高的水体信息提取精度。例如李长春等[7]在三种水体比值指数(归一化差异水体指数(Normalized Difference Water Index,NDWI)、改 进 的NDWI(Modified NDWI,MNDWI)和水体比值指数(Water Ratio Index,WRI))所形成的特征空间上,应用AdaBoost算法进行山区水体信息提取,所得结果的错误率较NDWI 阈值法减小了20%~27%;宋英强等[8]将谱间关系以及NDVI、NDWI 和K-T 变换的wetness 分量等特征相结合,利用AdaBoost 算法实现了地势平缓地区的水体快速精确提取,与使用单个指数提取的结果相比,平均分类精度提高了5.15%。由此可见,采用多特征多分类器“带权投票式”组合的AdaBoost 算法,能够提高水体信息的提取精度。不过,传统的水体信息AdaBoost 提取方法存在两个明显的缺陷:一是分类器的构建对于样本的依赖性较高;二是在像素层次上直接进行图像阈值分割,容易产生椒盐噪声现象[9-10],由此限制了AdaBoost 算法对于水体信息遥感智能提取的性能发挥。
为解决算法上述问题,本文将人类的视觉注意机制引入到遥感影像中水体信息的智能检测。视觉注意机制是人类视觉系统的一个重要特征,已有研究表明,在面对复杂场景时,人类视觉系统能够快速地将注意力集中在图像中的显著区域,并对其进行优先处理[11-13]。另外,人类视觉选择性注意机制包括由底向上(bottom-up)和由顶向下(top-down)两种类型。其中:bottom-up 视觉注意机制是原始快速机制,也称数据驱动方式,是一种不带主观目的、仅从颜色亮度等图像底层特征去观察的视觉注意机制;而top-down 视觉注意机制则属于高级认知机制,也称任务驱动方式,是从先验知识的角度看待图像。由此可见这两种视觉选择性注意机制各有自己的优点和适用范围[12-13]。不过,在大范围地表信息遥感提取实践中,往往面临着水体等目标对象通常呈广域分散式分布且空间异质性较为突出等问题[1-3],因此,与依赖于高层特定任务驱动的top-down 视觉注意机制相比,只受输入图像底层特征影响的bottom-up 视觉注意机制更适合于大范围分散式分布的水域遥感图像智能检测。
基于以上分析,本文提出一种将bottom-up 视觉选择性注意机制与AdaBoost算法相结合的通用型水体信息遥感智能采集方法。该方法首先从颜色拥有更高视觉注意优先级的角度出发,通过遥感多特征指数的RGB 配色方案优化设计,进行图像上水体表现特征的增强和可视化,使得具有相同或相近颜色特征的水体像元在空间上集聚,形成能被计算机视觉注意系统快速准确识别的显著区域;然后,在HSV 颜色空间中基于色差图像直方图和AdaBoost算法构建水体智能识别分类器,并据此从HSV 图像色彩聚类结果中进行水体分布区域的自动检测与定位。
1 数据与方法
1.1 主要数据来源与预处理
本文选取了分别成像于2016 年7 月23 日(洪水期)和2018 年4 月8 日(枯水期)的两景Landsat8/OLI 影像(Path/Row编号均为123/039)作为实验数据(见图1),覆盖范围主要包括武汉市、孝感市、鄂州市、天门市、仙桃市、荆州市等县市的部分区域,地表覆被以植被(含作物)为主。从实验图像的质量来看,主要存在少量的云污染。为避免这些云覆盖对于后续的水体遥感识别过程产生影响,主要采用人工勾绘的方式将其从影像中进行剔除。另外,部分河流与湖泊在洪水期图像(见图1(a))上的表现特征明显区别其他水域,这主要是由于2016 年夏季长江洪灾的影响,该年7 月研究区内发生了严重涝灾,从而使得部分地区的水体泥沙含量等普遍较高。
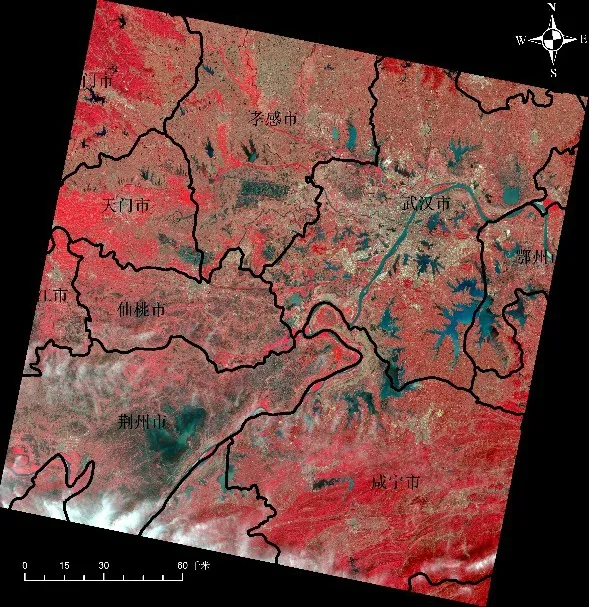
图1 实验影像及其覆盖区域示例Fig.1 Experimental images and their coverage areas
1.2 基于视觉注意机制的分类特征集构建
1.2.1 水体遥感多特征表达可视化
根据人类视觉特性,所有颜色都可看作是由红、绿、蓝三原色组合而成,且三个分量比例不同,组合后的图像颜色也不同。本文根据水体在绿光波段上的高反射,此后随着波长的增加,其反射率不断减弱的波谱特征,以及水体与易混淆的建设用地等地类之间的差异性,构建了NDVI、MNDWI 和MNWI三种水体增强指数[5-6],然后将NDVI 嵌入红色通道、将MNWI嵌入绿色通道、将MNDWI 嵌入蓝色通道,生成能够突出水体信息的RGB 假彩色影像,结果如图2 所示。对比河流和湖泊两类典型水体在图1中差异明显的表现特征来看,二者在图2中具有较好的色彩一致性,由此可见,利用上述方法所生成的RGB假彩色专题图像,能稳定地凸显水体的“类别”色彩特征,这为本研究建立普适性的水体信息遥感智能提取方法提供了较高的可行性。上述各指数的计算公式如下:
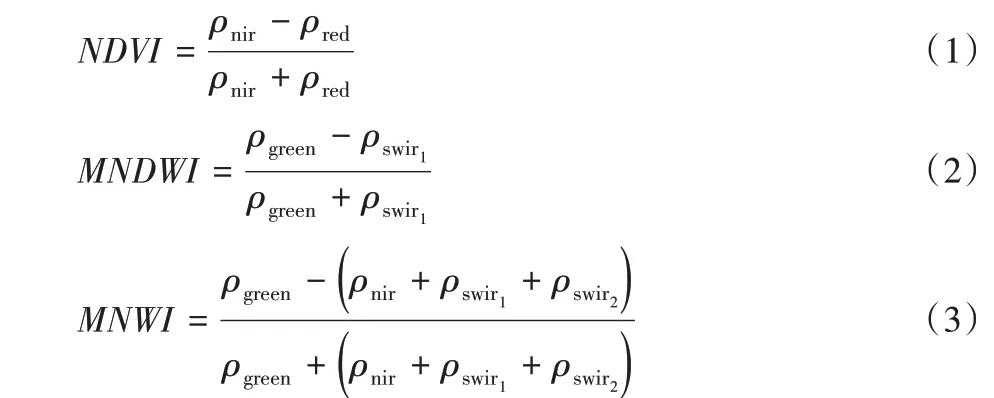
其中:ρgreen、ρred、ρnir分别为图像中的绿光波段(0.525 μm~0.600 μm)、红光波段(0.630 μm~0.680 μm)和近红外波段(0.845 μm~0.885 μm),ρswir1和ρswir2则都指图像中的中红外波段(波长分别是1.560 μm~1.660 μm、2.100 μm~2.300 μm),它们依次对应于陆地成像仪(Operational Land Imager,OLI)影像中的第3、第4、第5、第6和第7波段。

图2 基于RGB色彩模式的研究区(局部)水体信息遥感多特征表达可视化效果演示Fig.2 RGB color mode based visualization demonstration of remote sensing multi-feature representation for research area(local)water information
1.2.2 图像颜色空间转换
与形状纹理等图像几何特征及空间关系相比,颜色拥有更高视觉注意优先级,是人类识别图像中目标对象的主要感知特征[13-14],再加上颜色特征对图像本身的尺寸、方向、视角的依赖性较小,从而具有较高的鲁棒性,因此,将图像颜色引入机器视觉识别过程中可以简化目标物的提取过程,图像颜色已成为基于视觉注意机制的感兴趣区域机器检测的重要依据[12,15-18]。
不过,RGB颜色空间中红、绿、蓝三个分量之间高度相关,从而导致该颜色系统具有不稳定性的缺陷;同时,在RGB 颜色空间中采用欧氏距离进行色差计算,难以有效地进行颜色分离[19]。与RGB 颜色空间相比,HSV 颜色模型能较好地反映人类视觉对颜色的感知和判别能力,其色调(Hue)、饱和度(Saturation)和亮度(Value)3 个分量之间相互独立,并且色调分量(H)和饱和度分量(S)与人眼感知颜色的方式接近,亮度分量(V)则与图像的彩色信息无关,因此,HSV 颜色空间更有利于采用计算机视觉颜色检测技术进行感兴趣目标的图像自动识别[20]。
本文采用文献[20]中的方法将上述彩色专题图像(见图2)从RGB色彩空间转换到HSV色彩空间,具体公式如下:
设 Colormax= max(R,G,B),Colormin= min(R,G,B)。 当Colormax≠Colormin时,定义

其中:R,G,B ∈[0,255],H ∈[0°,360°],S ∈[0,1],V ∈[0,1]。
1.2.3 色差专题图像生成及其物理属性分析
将已有水体样本作为训练样本,依据式(8)在HSV 颜色空间中进行色差距离计算[20],生成水体遥感色差专题图像,以使得具有相同或相近颜色特征的像元在空间上集聚,形成能被计算机视觉注意系统快速准确识别的显著区域。
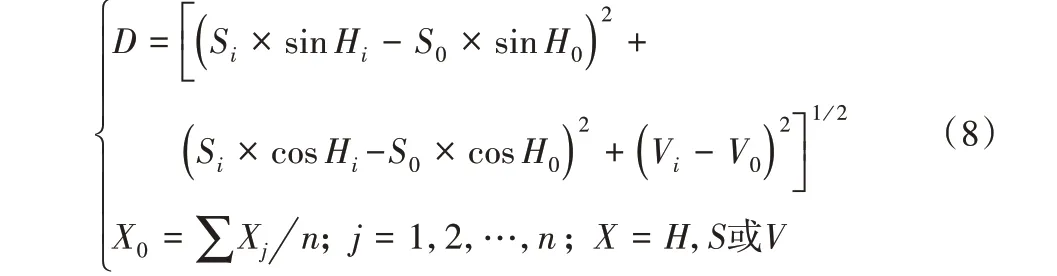
其中:D 表示色差距离系数;(Hi,Si,Vi)是图像上第i 个像元的HSV 坐标值;(Hj,Sj,Vj)是第j 个训练样本点的HSV 坐标值;(H0,S0,V0)是所有训练样本点的HSV均值坐标。
由于在上述水体遥感色差专题图像中,各像元灰度值(D)是基于水注记点中的训练样本计算得到的,因此其大小能反映像元尺度上的“水隶属度”:D 值越小,属于水的可能性越高;反之则属于非水的背景地物。因此,在水体遥感色差专题图像上,水体像元的D 值都普遍低于非水的背景地物。同时,由图3 可以看出,易与水混淆的建设用地和裸地等普遍具有较高的D 值,而植被的像元灰度值介于两者之间,即D水<D植被<D建设用地。再加上实验区内的植被覆盖较高,从而导致该色差图像的直方图(见图3)具有一系列独特但又有着明确物理含义的形态特征:在水体分布的低值区和背景地物分布的高值区之间存在险峻的“峭壁”;在邻近峭壁的左侧低值区,因为具有较大色差距离值(D)但像元个数较少的水体像元集聚而形成了“谷底”和“洼地”;在邻近峭壁的右侧高值区,则因为植被像元个数较多而集聚形成了“险峰”。
1.2.4 分类特征集的构建
利用色差图像直方图上的峭壁、险峰、波谷、洼地等关键形态节点信息,构造分类特征集。具体方法如下:
1)利用极差法对色差距离图像(D)进行拉伸,得到值域介于1~255的图像SD:
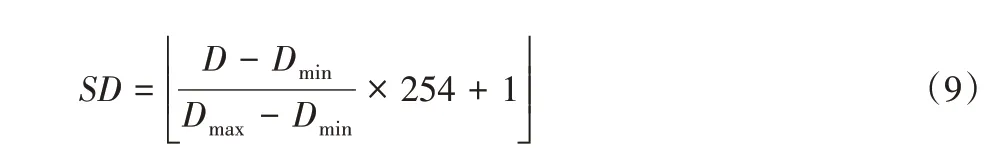
2)计算SD图像中每个灰度级的频坡比系数(Dslope):
Dslope(i)=( )ni+1- nini× 100;i = 1,2,…,255 (10)其中:ni+1、ni分别为SD 图像中灰度值等于i+1 和i 时的像元个数。
3)计算各关键形态节点对应的灰度值:
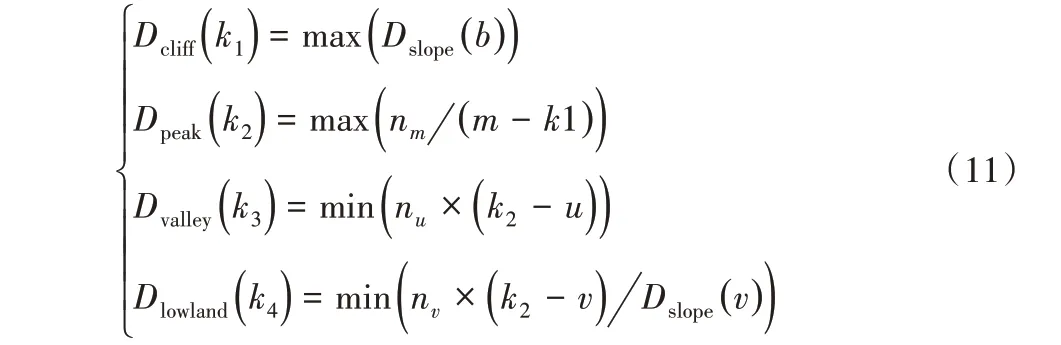
其中:k1、k2、k3、k4分别为峭壁(Dcliff)、险峰(Dpeak)、波谷(Dvalley)、洼地(Dlowland)所在位置处的灰度值;Dslope(b)为SD 图像中灰度值等于b 时的频坡比系数,并且b≠1,aw<b <ap;aw和ap分别为水体训练样本和植被训练样本在SD 图像中的像元灰度值均值;nm、nm-1、nm+1分别为SD 图像中灰度值等于m、m - 1 或m + 1 的像素个数,并且m >k1,nm>nm-1,nm>nm+1;nu为SD 图像中灰度值等于u 的像素个数,并且1 <u <k2;nv为SD图像中灰度值等于v的像素个数,并且1 <v <k2,Dslope(v)>0。
4)利用上述结果,生成AdaBoost 算法所需的关键特征分类集:
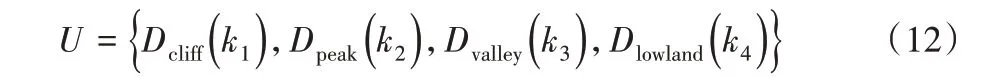
1.3 AdaBoost分类器的生成
AdaBoost 算法是1995 年由Freund 等[21]提出的一种投票式分类算法。其基本原理是通过将不同的弱分类器组合成强分类器来提高分类精度。该算法的基本思路是:首先,给训练样本赋予相同的初始权重。然后,进行弱分类器训练,若样本点被错误地分类,那么在下一轮训练中,该样本点的权重被提高;反之,正确分类的样本点的权重被降低。最后,对所有弱分类器的判决结果进行加权求和,生成强分类器[8,10,22-23]。算法实现的过程如下:
1)对每个样本的归属类别进行赋值:类别属于水的样本赋值为1,类别属于非水的样本赋值为-1,据此构造训练样本集S:
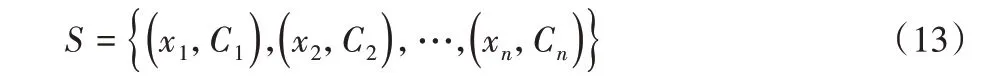
其中:n 为样本编号;xn表示第n 个样本的像元灰度值;Cn∈{1,- 1}表示第n个样本的类别归属。
2)初始化n个样本的权重wi0= 1/n,则训练样本集的初始权值分布函数为:
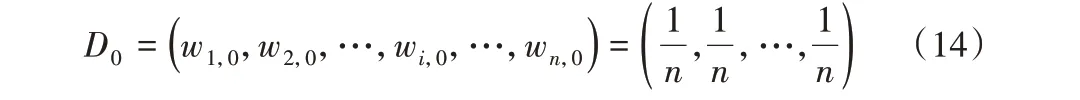
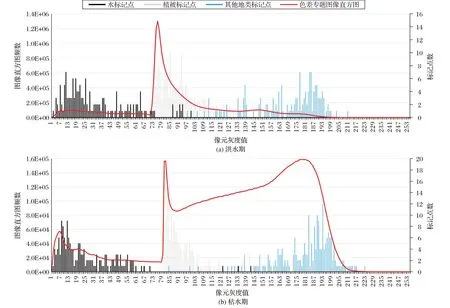
图3 研究区域色差图像直方图及典型地物的训练样本色差灰度值分布情况Fig.3 Histogram of chromatic aberration image in research area and distribution of chromatic aberration grayscale values of training samples of typical ground objects
3)进行多次循环迭代,训练弱分类器。
a)假设总迭代次数为T,在每一次迭代循环t(t =1,2,…,T)时,对于分类特征集U 中的每个特征,都使用具有权值分布Dt的训练数据集进行学习,得到弱分类器函数:

计算ft(x)在训练数据集上的分类误差率εt(x):
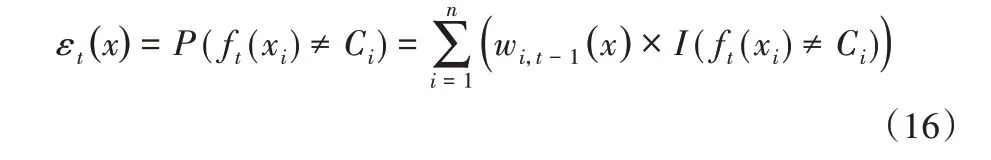
其中:Ci为第i个训练样本的类别归属;Wi,t-1为训练样本x在经过t - 1 次迭代后的权重;I( ft(xi)≠Ci)为指示函数,当ft(xi)≠Ci时输出1,否则输出0。
b)选择训练错误率最小的弱分类器作为本轮训练的基本分类器Gt(x),并计算其权重系数at(x),该系数表示基本分类器Gt(x)在最终的强分类器中的重要程度。
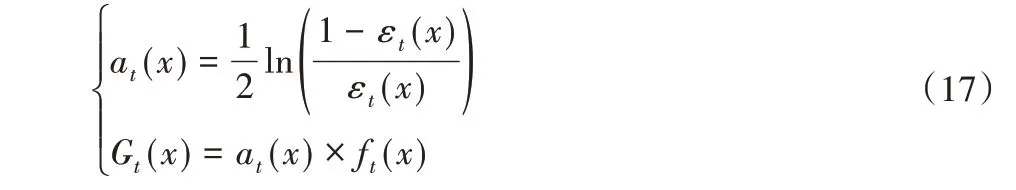
c)更新训练样本的权值分布函数,得到Dt+1,用于下一轮迭代。
若为错误分类样本,则权重更新为:

若为正确分类样本,则权重更新为:

4)组合各弱分类器,构建强分类器。
将经过T 次迭代而得到的各个弱分类器,先根据其权重进行组合:

2 实验与结果分析
2.1 研究区域水体遥感识别结果及精度评价
考虑到在像素层次上直接应用AdaBoost强分类器进行大范围广域分散式分布的地面目标遥感识别时,容易出现严重的椒盐噪声[9-10],以及研究区内的水体信息在经过遥感多特征可视化表达后呈现独特且较为均一的图像色彩特征(见图2)等,本文先在HSV 颜色空间上进行图像色彩聚类,使得具有相同或相近颜色的像元在空间中聚集,形成同质图斑;然后在类别图斑色差度量的基础上,应用AdaBoost强分类器,自动识别出水体所属的类别。从提取结果(见图4)的目视效果看,各类水体没有产生明显的椒盐噪声现象。
另外,将随机生成的309 个评价样点(其中,水体和非水体各有182 个和127 个),依据亚米级的google earth 影像分别赋予真实的水体标签或非水体标签,并构建本次识别结果的精度评价混淆矩阵,由此获得了漏分误差(Leak Rate,LR)和复合分类精度系数(Composite Classification Accuracy,CCA)两个量化评价指标。其中:漏分误差主要用来反映目标类别(水)的漏分概率[22],复合分类精度系数则是目标类别分类准确性的综合评价指标,等于生产者精度(Producer's Accuracy,PA)与用户精度(User's Accuracy,UA)的乘积,因此CCA 系数实际上同时包含有错分和漏分信息。评价结果(如表1)显示,本次实验的漏分误差为4.4%,CCA 系数约95.1%,这表明本研究对于大范围水体的提取结果具有较高精度。

图4 基于视觉注意机制的研究区水体的遥感信息智能识别提取结果(局部)Fig.4 Sensing information intelligent recognition and extraction results of water in research area(local)based on visual attention mechanism
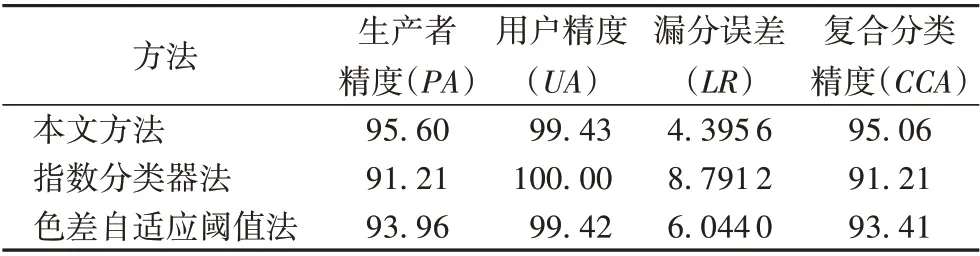
表1 不同方法提取结果的精度对比 单位:%Tab. 1 Precision comparison of different methods in extraction results unit:%
2.2 不同方法的水体遥感识别效果对比
为了验证本文方法的可靠性和高效性,本文与两种方法进行了对比实验:
1)指数分类器法。这是目前应用较为广泛的一种水体AdaBoost 遥 感 识 别 方 法[7-8],它 利 用 水 体 训 练 样 本 集,在NDVI、MNWI 和MNDWI 构成的特征空间上,通过自适应阈值算法分别确定各自的分割阈值,并以此构造AdaBoost 算法所需的关键特征分类集;然后再通过多次迭代进行弱分类器训练和强分类器的生成,据此实现水体信息的识别提取,而在此过程中存在对训练样本的高度依赖性现象。
2)色差自适应阈值法。该方法与本文方法的共同之处在于它也是利用NDVI、MNWI、MNDWI 数据集构建基于RGB 色彩模式的水体信息增强图像,并在HSV 颜色空间下通过色差距离系数的计算,生成水体遥感色差专题图像;不同之处在于该方法直接在像元尺度上将自适应阈值算法应用于色差专题图像,以此提取出水体信息,而本文方法是在经过上述三指数图像色彩聚类而形成的同质斑块尺度上,应用基于色差图像直方图多个关键节点而建立的AdaBoost 分类器,进行目标区域(水体)的自动检测与定位。因此,通过与色差自适应阈值法的对比,可以反映出本文方法能否在有效提高水体的智能识别精度的同时克服椒盐现象。
对于上述两种方法所提取的水体信息也采用相同的随机样点进行了精度评价,结果如表1 所示。与指数分类器法和色差自适应阈值法相比,本文方法在漏分误差上分别降低了4.4 个百分点和1.6 个百分点,CCA 系数则分别提高了3.9 个百分点和1.7 个百分点,由此可见,应用本文方法能有效提高水体的分类精度。
此外,还对不同方法的提取结果(见图4)进行了实地对比,发现基于另外两种方案所获取的洪水期水体信息提取结果有较多的错分现象,对此,从中选出三个代表性区域(A、B、C)进行定点比较分析,其详细对比情况如图5~7所示,由此可以看出,采用指数分类器法未能完整地提取A、C 区域的水体(见图5(c)、图7(c)),色差自适应阈值法是对B区域的水体有较多的漏分(见图6(d))。究其原因主要在于2016 年洪灾期间,研究区内多次强降雨,使得部分区域的水体泥沙含量有所增加(见图7(a)),有的地方还因为洪灾[24]而产生了一些淹没区等临时性的水域(见图5(a)、图6(a)),它们的波谱特性及其在影像上的表现也因而有别于常见的水体特征。不过,应用本文方法,则较好地克服了上述漏分情况。
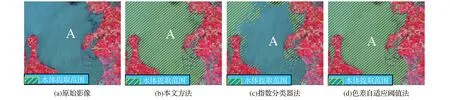
图5 不同方法的水体提取效果对比(一)Fig.5 Extraction effects of water in the 1st experimental area by different methods
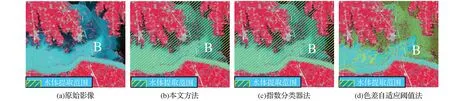
图6 不同方法的水体提取效果对比(二)Fig.6 Extraction effects of water in the 2nd experimental area by different methods
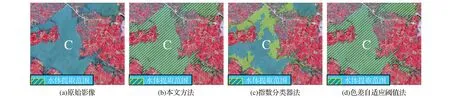
图7 不同方法的水体提取效果对比(三)Fig.7 Extraction effects of water in the 3rd experimental area by different methods
3 结语
契合遥感数据内在特征的智能信息分析模型与方法,是大数据时代遥感信息智能提取技术能否得到广泛应用的关键所在。本文从普适性的大范围水体信息遥感智能采集的需求出发,建立了一种基于人类视觉选择性注意机制与AdaBoost算法相结合的水体信息遥感高精度提取方法。本文方法主要依据颜色拥有较高视觉注意优先级的特性,通过遥感多特征指数的色彩配色方案优化设计,不仅有效抑制了背景信息,而且实现了水体的影像特征增强和可视化,形成能被计算机视觉注意系统快速准确识别的显著区域。同时,为了减少现有的水体信息AdaBoost 提取方法对训练样本的较高依赖性,且避免在像素层次上直接进行图像阈值分割时椒盐现象的产生,本文方法首先通过色差图像直方图上多个关键节点的检测,建立AdaBoost水体智能识别分类器,然后在图像色彩聚类的同质斑块尺度上,应用上述分类器进行目标区域的自动检测与定位,从而使得水体的提取结果更完整、准确,较好地克服了水中泥沙含量较大等所导致的漏分、误分情况。
不过,目前本研究仅针对地表覆被以植被为主的区域展开了实验,当覆被以建筑物或裸地等为主时,需对本研究所提出的水体智能识别方法作进一步的适应性分析。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
宝钢技术(2022年2期)2022-07-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
科技视界(2020年4期)2020-04-26
科技创新与应用(2020年6期)2020-02-29
软件导刊(2017年4期)2017-06-20
现代电子技术(2016年23期)2017-01-12
科技视界(2016年4期)2016-02-22
