
基于改进YOLOv2和迁移学习的管道巡检航拍图像第三方施工目标检测
2020-06-01 10:54谌贵辉李忠兵钱济人
计算机应用 2020年4期
谌贵辉,易 欣*,李忠兵,钱济人,2,陈 伍,2
(1. 西南石油大学电气信息学院,成都610500; 2. 浙江浙能天然气运行有限公司科创中心,杭州310000)
(∗通信作者电子邮箱1171866631@qq.com)
0 引言
石油、天然气等能源输送管道是现代社会经济发展的基础设施,但是油气管道在使用过程中会受到外界环境、内部运输物质等因素的影响,存在很高的风险,一旦发生危险,将产生巨大的危害。而外界环境风险事故中,第三方损害占比是最高的[1]。第三方损害中包括直接的威胁管道安全的挖掘机、打桩机以及定向钻等工程机械,间接威胁管道安全的有违章占压建筑、重型车辆碾压等。随着无人机技术的快速发展,在电力行业中无人机已经得到了较好的实际应用[2-3]。在油气管道巡检应用中,对无人机采集的图像信息的处理方式是人工判别[4-5]或者应用于其他场景[6],存在着劳动强度大、时间成本高和结果不稳定等问题。为解决该问题,本文将深度学习目标检测算法引入到天然气管道无人机巡线监测系统中,通过全球定位系统(Global Positioning System,GPS)信息以及目标的位置信息判断目标距离管道的信息,所以整个图像智能检测系统关键是获取目标类别及准确的位置信息。
传统的目标检测方法采用手工设计特征,然后针对特征设计相应的检测模型,其应用范围、检测精度和速度都有很大的局限性。近年来,基于深度学习的目标检测算法获得了很大的进展,根据检测方式可以分为两大类:一类是基于区域推荐的两阶段算法,首先通过滑动窗口获得候选目标,再使用卷积神经网络(Convolution Neural Network,CNN)进行类别和位置的预测;其特点是精度较高但实时性较差,代表性算法有RCNN(Regions with CNN)[7]、Fast RCNN[8]、Faster RCNN[9]等,尽管该类算法的检测精度较高,但是出于对第三方施工目标监测的要求,需要算法拥有较高的检测速度。另一类是基于回归方法的端到端算法,将目标检测看作回归问题,直接通过网络预测出目标的类别及位置信息;其特点是速度快但精度相对而言要低一些,代表性算法有YOLO(You Only Look Once)[10]、YOLOv2[11]、YOLOv3[12]、单阶段多边框目标检测算法(Single Shot multibox Detector,SSD)[13]和针对SSD存在的小目标检测能力弱而改进的反卷积单阶段多边框目标检测算法(Deconvolution Single Shot multibox Detector,DSSD)[14]等。其中,YOLOv2 和YOLOv3 都是在YOLO 算法的基础上对特征提取和目标预测方面逐步进行改进、演变而来的,相较于YOLO和YOLOv3,YOLOv2 在检测精度和检测速度上拥有更好的综合性能。SSD 采用VGG16 网络结构进行特征提取,在多个尺度下通过锚点机制对目标进行检测,提高了检测效果,但是同时检测速度也有所降低。DDSD 除了用Res-101 替换VGG16外,还引进反卷积模块和残差连接方式,提高SSD对小目标的检测能力。目前前沿的目标检测算法虽然在常规数据集上能取得较好效果,但是应用在无人机管道巡检航拍图像上的效果并不好,主要面临图像目标小、数据集较少以及图像质量等多方面问题。
由于第三方施工目标尤其是挖掘机对管道危害性较大,出于管道安全保护考虑,对检测速度有较高的要求。因此在优先考虑检测速度的前提下,综合考虑检测精度,本文提出基于YOLOv2 的改进算法和结合迁移学习的航拍图像小目标实时检测算法。
本文主要工作如下:
1)提出能够有效提高小目标检测能力和位置信息检测精度的Aerial-YOLOv2实时检测的卷积神经网络;
2)通过数据增强的方法扩大数据集规模并结合迁移学习训练网络;
3)使用K-means 算法聚类分析出适合本文数据集特点的锚点框尺寸以及数量;
4)使用自适应对比度增强算法对航拍图像进行处理。寸。2)回归预测。首先将Darknet-19 提取的特征经过2 层卷积运算后,将其和特征提取模块中的26 × 26 × 512 的特征矩阵进行降采样后进行合并,随后通过3×3 的卷积计算对其特征整合,最后在使用1×1 的卷积层调整输出维度为13× 13×425 的输出矩阵,YOLOv2 最后对这个输出矩阵进行检测。YOLOv2 借鉴Faster RCNN 锚点框的思想引入锚点机制,选择5 个符合数据集特点的锚点框,并利用锚点框对输出矩阵解码。其中,13× 13× 425 的矩阵将图像分成13× 13 个网格,每个网格包含5 个锚点,每个锚点都预测目标的置信度、目标位置及类别。随后获得每个锚点最大的预测概率对应的类别,然后将该类别概率与置信度相乘获得该锚点的分数,然后删除每个网格中的锚点分数低于0.6 的锚点,再进行非极大值抑制(Non-Maximum Suppression,NMS)操作,去除重复率过大的预测框。
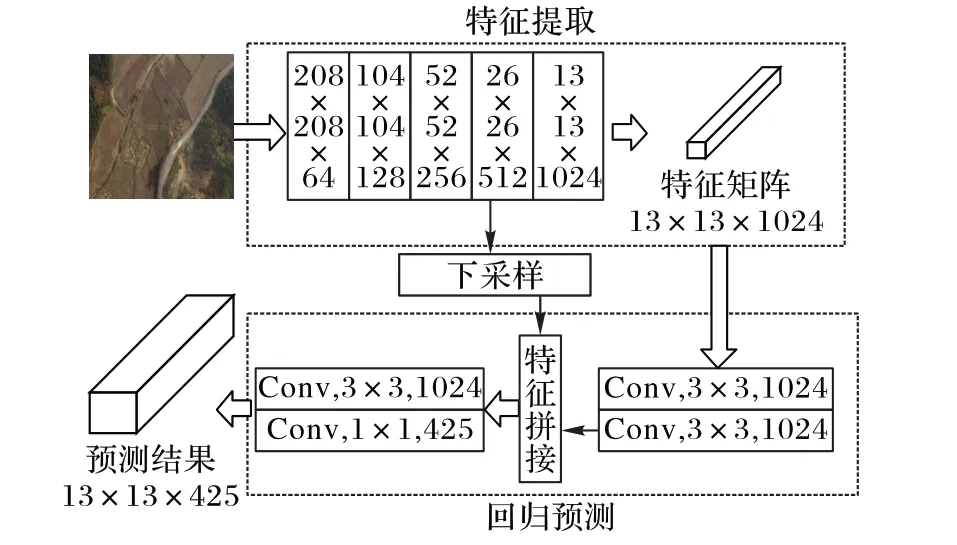
图1 YOLOv2目标检测算法流程Fig.1 Flowchart of YOLOv2 target detection algorithm
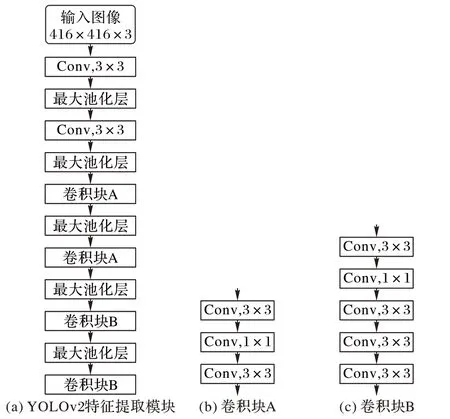
图2 YOLOv2特征提取模块及其组成Fig.2 YOLOv2 feature extraction module and its composition
1 相关知识
YOLOv2延续了YOLOv1的核心思想,将目标检测问题看作回归问题,用一个卷积神经网络完成对目标的定位以及识别,同时也针对YOLOv1 的特征提取和回归预测部分作了改进。
YOLOv2 目标检测的算法流程如图1 所示。由图1 可知,YOLOv2 网络结构主要由两部分组成:1)特征提取。采用包含19层卷积层(不包含池化层)的名为Darknet-19的结构来对416 × 416 × 3 的输入图像特征进行提取,生成一个大小为13× 13× 1024 的特征矩阵。Darknet-19 特征提取部分如图2(a)所示,由池化层和卷积块组成,池化层起到下采样及降维作用,卷积块根据所包含卷积数量不同又分为A、B两种类型,如图2(b)~(c)所示。其中,Conv 表示该层是卷积层并包含批归一化和Leaky-Relu激活函数,3× 3或者1× 1表示卷积核尺
2 基于Aerial-YOLOv2的航拍图像目标检测
YOLOv2 目标检测算法不能直接应用在无人机航拍图像目标的检测,主要存在以下几个问题:
1)航拍图像目标具有尺度多样性,但在网络结构上,YOLOv2 仅在单一尺度上进行检测,无法在多个尺度下对目标尤其是小目标进行有效检测;另一方面,YOLOv2 使用的最大池化层使目标位置信息出现丢失[15],预测目标位置会出现较大偏差。
2)在深度学习中,模型质量与所使用的数据集的数量有直接关系。在传统的深度学习训练方法下直接使用已有标签的数据训练的模型检测性能较差,需要根据航拍图像的特点使用针对少量样本训练模型的方法。
3)YOLOv2使用3个锚点框作为先验知识进行目标检测,但是这些锚点框并不适合本文数据集的数据特点。
4)受天气、背景和拍摄高度等影响,使用时部分输入图像的边缘纹理模糊、对比度低,会降低算法检测效果。
为了解决上述问题,本文提出基于Aerial-YOLOv2的航拍图像的检测算法,总体框架如图3 所示。本文算法主要包括4 个部分:基于YOLOv2 改进的Aerial-YOLOv2 网络结构、基于DOTA(Dataset for Object Detection in Aerial Images)[16]数据集的迁移学习、基于聚类分析的锚点框选择以及自适应对比度增强(Adaptive Contrast Enhancement,ACE)预处理。在训练阶段使用DOTA 数据集在拥有同样特征提取部分的网络上进行训练,然后将其迁移到Aerial-YOLOv2网络对应部分。随后对采集的关于第三方施工相关车辆以及违章占压建筑物的航拍图像数据集使用数据增强方法后,再对经过迁移学习的Aerial-YOLOv2网络进行训练,并使用聚类分析出适合该数据集特点的锚点框。在实际使用过程中,使用ACE 图像预处理对图像进行处理,然后将其送入训练好的Aerial-YOLOv2网络进行检测,将检测出的正样本添加至航拍图像数据集中,扩大数据集规模。
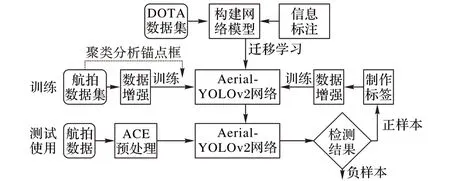
图3 低空航拍图像检测算法总体框架Fig.3 Overall framework of low-altitude aerial image detection algorithm
2.1 Aerial-YOLOv2网络结构设计
为预防漏检目标对管道安全产生威胁和提高检测信息准确度,需要降低漏检率并且能够对目标实现精确定位检测,本文设计适合航拍图像目标检测的网络结构Aerial-YOLOv2,如图4 所示。从中可看出:Aerial-YOLOv2 网络采用全卷积网络(Fully Convolutional Network,FCN)[17]结构,整体结构由特征提取和回归预测两个模块组成,Conv 表示该层是卷积层,每个卷积层分别表示出了卷积核尺寸和卷积核数量(“/”后的数字表示步长,省略的默认步长为1),卷积组由3× 3卷积和1×1卷积组成。
YOLOv2 为扩大特征感受野,使用最大池化层对特征进行降采样,但是最大池化层在计算过程中会丢失部分信息,所以Aerial-YOLOv2 使用步长为2 的卷积核代替最大池化层进行降采样,更好地保留目标的位置信息。
除此之外,Aerial-YOLOv2 将YOLOv2 特征提取部分中用于提取特征的卷积块使用本文提出的卷积模块替换,通过同一尺度下的卷积信息的融合,强化特征表达能力。YOLOv2在回归预测部分对特征提取部分中的16 降采样特征最后一层卷积特征继续降采样后,与32 倍降采样特征进行融合后进行检测,Aerial-YOLOv2 为加强网络对小目标的检测能力,首先在32倍降采样尺度下都进行预测,然后对32倍降采样特征进行2倍上采样后与特征提取部分的16倍降采样特征融合后进行预测。
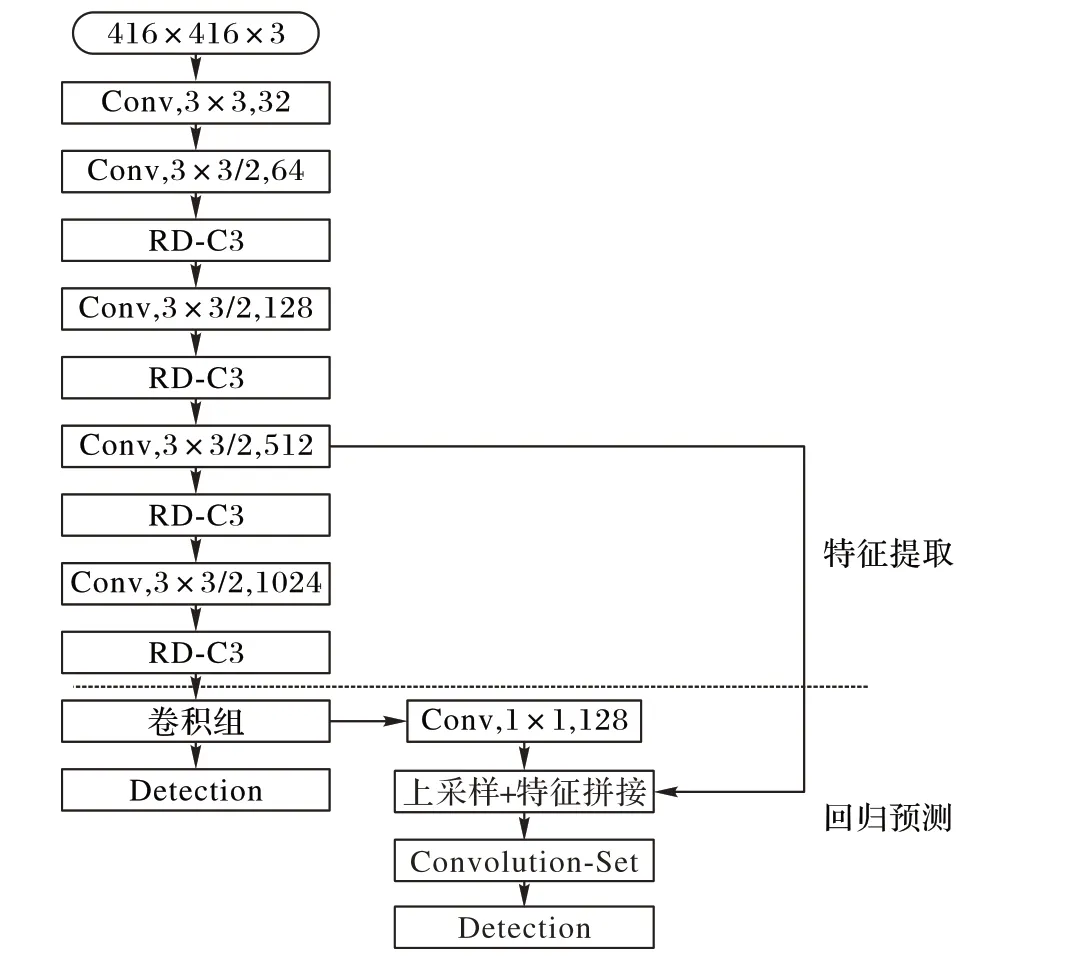
图4 Aerial-YOLOv2网络结构Fig.4 Aerial-YOLOv2 network structure
2.1.1 特征提取模块
为减少参数数量[18]和缓解梯度消失问题[19],使网络对不同层的卷积信息都能够被充分利用[20],提高网络对小目标的特征提取能力,本文提出一种残差密集卷积(Residual Dense-Convolution3,RD-C3)模块结构。RD-C3 模块在同一个尺度下通过加强对不同层次的卷积特征的传递,实现对目标特征的高效利用并且由于简化了低层特征和高层特征间的联通路径,提高了反向传播的效率。具体结构如图5所示。
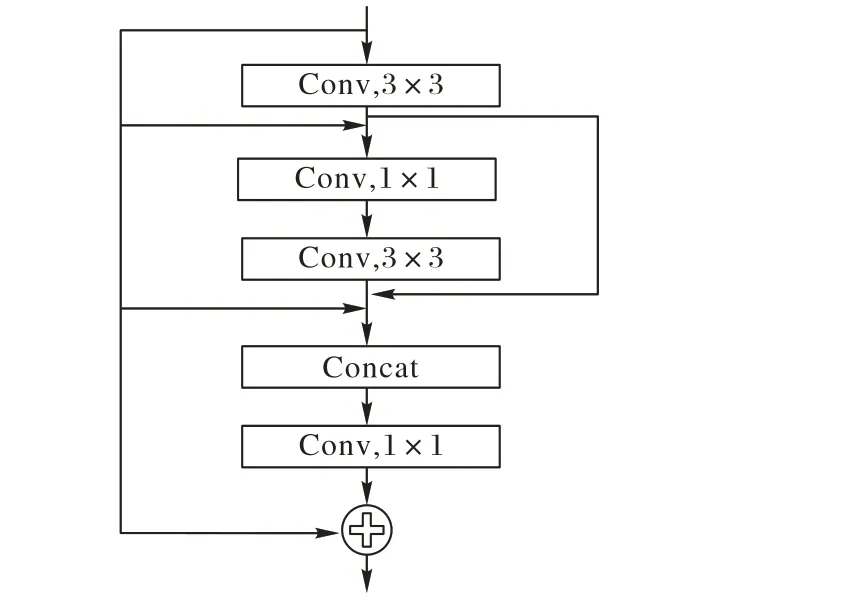
图5 RD-C3模块的结构Fig.5 Structure of RD-C3 module
整个RD-C3模块能够充分利用同一尺度下的信息,由3×3和1× 1的卷积组成。将尺度内的3×3 卷积通过类似密集连接中的旁路方式连接,通过1× 1卷积自适应地聚合特征信息并起到降低网络计算量的作用,最后聚合所有局部卷积特征的信息和该尺度下的输入端进行残差连接,实现该尺度下的全局残差学习,最后2 个RD-C3 模块中卷积核的数量相较YOLOv2 中对应卷积减少一半。另外,每个卷积层经过卷积计算后,都要再经过一个批归一化和非线性的Leaky-Relu 激活函数计算,Leaky-Relu计算如式(1)所示:

其中:xi为卷积层的输出值;a 一般为(0,0.5)区间的一个固定值;yi为输出值。
2.1.2 回归预测模块
在回归预测模块中通过融合底层纹理特征和高层语义特征的多尺度的方式进行目标检测。YOLOv2仅仅在32倍降采样的特征图上进行检测,而经过32 倍降采样之后,高层特征难免会丢失部分细节信息,该检测尺度下的目标检测层对小目标的检测能力是有限的。为了加强网络对小目标的检测能力,Aerial-YOLOv2 对网络输出的32 倍降采样特征进行检测之外,还增加一层16 倍降采样特征检测层。图像特征在Aerial-YOLOv2 中的传递过程如图6 所示,该图可直观地表示多尺度回归预测。
由图6 可知,原始图像通过特征提取模块多层卷积计算后生成大小为13× 13× 425(仍以416 × 416 图像尺寸为例)的高层语义特征,后经过3× 3和1个1× 1组成的卷积组计算后,生成13× 13× 425 的预测矩阵后直接在该尺度下进行一次检测。随后将大小为13× 13× 512 的32 倍降采样特征进行2倍上采样后与特征提取模块中16倍降采样层的输出进行特征拼接,然后再经过一个卷积组后生成大小为26 × 26 ×425的预测矩阵,然后在该尺度下在对其进行一次检测。
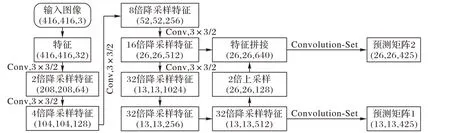
图6 Aerial-YOLOv2特征传递流程Fig.6 Flowchart of Aerial-YOLOv2 feature transfer
2.2 Aerial-YOLOv2迁移学习
为了训练Aerial-YOLOv2网络,实验数据为使用大疆精灵4Pro 无人机在100~130 m 飞行高度、10~12 m/s 的飞行速度条件下,通过正射角度拍摄的不同天气、不同时段下的共1 500张关于第三方施工相关车辆以及违章占压建筑物的可见光无人机航拍图像,拍摄的地面背景环境包括农村、城镇、河流以及山地,包括挖掘机、推土机以及顶棚3类目标,分别有1 257、439 和2 404 个目标。将图像按照8∶2 原则分为训练集和测试集。
深度学习模型效果与训练样本数量有极大的关联性,在拥有大量训练样本的基础上,才能得到高质量的深度学习模型。由于已知标签的航拍图像数据集较少,直接将数据用来训练Aerial-YOLOv2模型,得到的模型泛化性能较差从而不能够对多样、复杂背景下的目标进行准确检测。对此,本文采用迁移学习的方式[21]来训练模型,Yosinski 等[22]验证了迁移学习中特征迁移的可行性。将包含2 806 张遥感图像,共15 个类别、18万个目标的DOTA数据集[22]作为源域,本文的数据集作为目标域,通过迁移学习的方法将从源域学习到的模型参数与Aerial-YOLOv2模型共享,从而解决模型训练数据量不足的问题。
根据所拥有数据的情况,本文将迁移学习分为两部分:1)利用DOTA 数据集的训练集共2 100 张图像训练特征提取模块,根据模型在包含706 张图像的测试集上的召回率和准确率之和评价模型训练效果;2)迁移特征提取模块参数到Aerial-YOLOv2模型对应部分,在此基础上再训练回归预测模块。对于特征提取模块的训练,根据Aerial-YOLOv2模型中特征提取模块来构建检测模型。如图7 所示,该检测模型以Aerial-YOLOv2模型的特征提取模块为基础,经过两层卷积层运算,最后通过YOLOv2检测层获取检测结果。
建立检测模型后,利用DOTA 数据集进行训练。检测模型训练完毕后,将其特征提取模块的参数迁移到Aerial-YOLOv2的特征提取部分,迁移过程如图7所示。
将迁移学习的特征提取模块的参数进行冻结,即这部分的学习率为0,锁定特征提取模块的卷积核。回归预测部分参数使用随机值,然后使用本文的数据集对Aerial-YOLOv2进行训练。
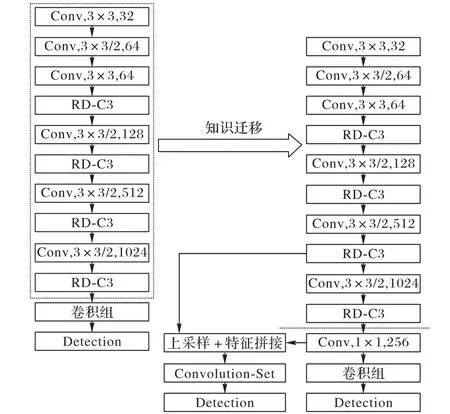
图7 迁移学习过程Fig.7 Transfer learning process
为了直接扩大数据集的规模,本文采用结合数据增强的迁移学习训练方法。本文采用的数据增强的方法有:1)随机旋转、翻转图像。随机旋转原始图像-30∘∼30∘,左右随机翻转原始图像。2)平移。将原始图像在上下左右某一个随机方向上整体移动图像尺寸的1/10。3)曝光度、饱和度和亮度调整。将图像从RGB空间转换到HSV空间后,在原始图像0.8~1.2倍范围内调整曝光度和饱和度,在原始图像0.7~1.3倍范围内调整亮度。4)ACE 图像预处理:在某个范围内随机调整核心尺寸阈值和系数参数值,获得不同的对比度增强的图像,提升模型泛化能力。按照每种方法扩增一倍的策略,数据集扩增到共7 500张图像。
2.3 基于无人机航拍数据集的锚点框选择
Aerial-YOLOv2在回归预测部分使用锚点预测,符合数据集特点的锚点框数量和尺寸可以加强模型检测能力和减少训练时间。本文通过K-means 聚类方法确定合适的锚点框数量以及尺寸。K-means 算法通常使用的距离度量函数为欧氏距离、曼哈顿距离等,但是在聚类锚点框的时候,希望能使候选锚点框和边界框之间有尽可能高的交并比(Intersection Over Union,IOU),而如果采用常规的距离度量函数会导致同样的交并比误差,而大尺寸的边界框比小尺寸的边界框会在度量函数上产生更多偏差,而影响聚类结果准确性,所以本文使用新的距离度量公式[12]:
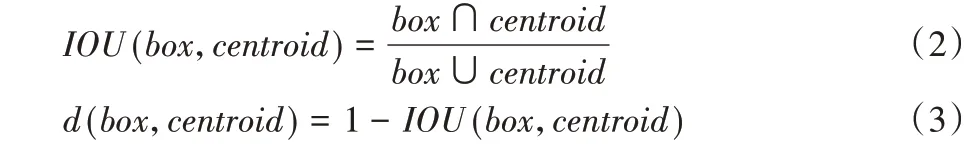
其中:centroid 表示簇的中心的边界框;box 表示样本框;IOU(box,centroid)表示聚类中心的边界框和样本框的交并比。
本文分别递增地选取K-means 的锚点框数量K,获得K 与交并比之间的关系如图8所示。
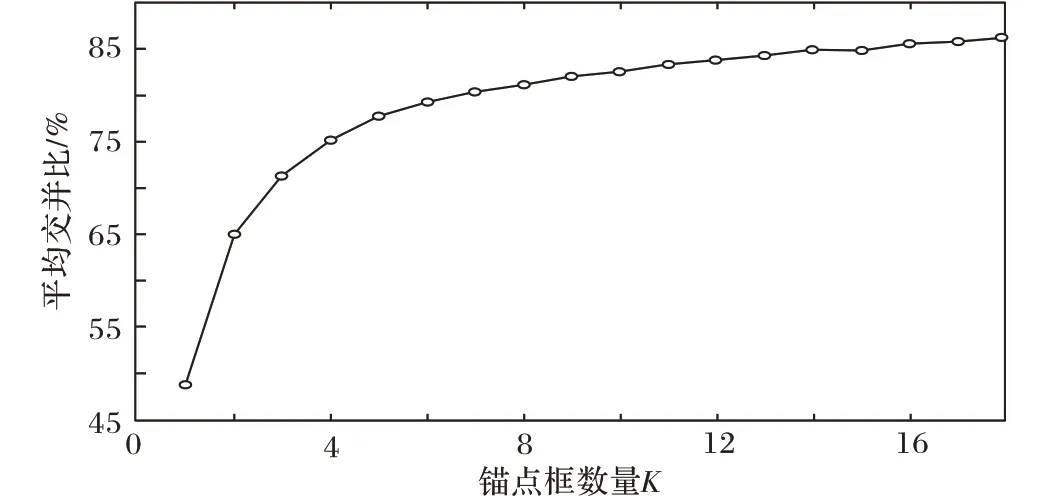
图8 锚点框数量K与交并比的关系Fig.8 Relationship between number of anchor boxes K and intersection ratio
从图8 可知,在K = 6 时曲线增长明显放缓,所以选择锚点框的数量为6,对应的边界框的大小设置为6个锚点框中心的大小,按照(锚点框长,锚点框宽)的形式表示,其值分别为(7.6,4.1)、(29.5,35.5)、(22.0,29.8)、(4.6,9.5)、(8.7,12.4)和(34.1,22.6)。
2.4 基于ACE的航拍图像增强预处理
由于航拍图像是在一定高度下拍摄的,并且受天气和周围环境的影响,目标的部分重要特征会出现纹理模糊、图像噪声大的情况,所以本文采用自适应局部对比度增强算法(ACE)进行图像预处理。
ACE算法流程如下,首先将图像分为两部分:一部分主要包含低频信息的反锐化掩膜,通过图像的低通滤波(平滑、模糊技术)获得;另一部分是高频成分,通过原图像减去反锐化掩膜获得。随后对高频部分进行放大(方法系数为对比度增益(Contrast Gain,CG)),最后将其加入到反锐化掩膜中,得到ACE增强后的图像。
ACE 算法的核心是计算增益系数CG,通过计算以该像素为中心的像素平均值和方差获得CG 系数。局部区域的中心点的像素平均值和方差按照式(4)~(5)计算:
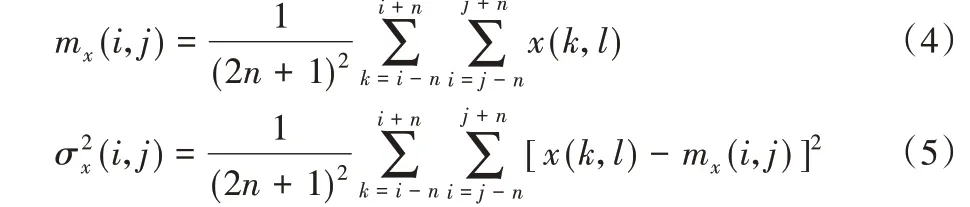
其中:n 为以像素点(i,j)为中心点、大小为(2n + 1) ×(2n + 1)的局部区域的尺寸;x(k,l)为该局部区域内的像素点(k,l)的像素值;mx(i,j)为该局部区域的像素平均值;σx(i,j)为该局部区域的标准差(Local Standard Deviation,LSD)。ACE 算法可表示如下:
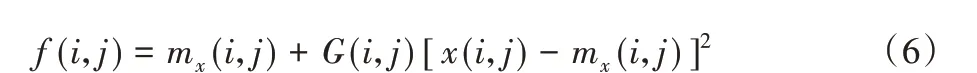
其中:f(i,j)表示像素点(i,j)对应的对比度增强后的像素值;G(i,j)为对比度增益(即前文所提CG),一般为常数,但是为了预防出现过分增强的情况,针对不同的像素点采用不同的增益。采用如下的解决方法:
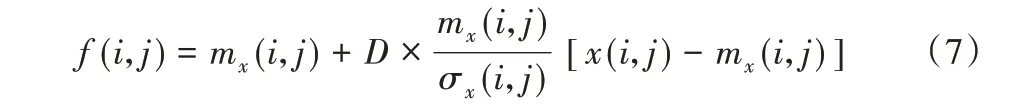
其中:D 是个取值范围为0~1的常数;mx(i,j)/σx(i,j)的值为对比度增益(即CG),是空间自适应的,并且和局部均方差成反比,在图像的边缘或者其他变化剧烈的图像部分,CG 值就较小,不会产生振铃效应。
3 实验与结果分析
为了验证Aerial-YOLOv2 网络结构的有效性以及基于Aerial-YOLOv2网络实现无人机航拍图像目标检测的可行性,将YOLOv2 和Aerial-YOLOv2 应用于无人机航拍图像目标检测。实验过程中所采用的数据集为人工标注的航拍图像。实验设备配置为英伟达GTX1080显卡,英特尔XREON处理器。
实验主要分为两部分:1)比较YOLO 系列、SSD 网络与Aerial-YOLOv2 网络的性能,验证Aerial-YOLOv2 网络的有效性;2)使用经过数据增强和自适应对比度增强处理的数据集,作为迁移学习的目标域数据集来训练网络,验证本文所使用训练策略的有效性。
3.1 Aerial-YOLOv2网络验证结果
为了验证Aerial-YOLOv2 算法的有效性,分别对SSD、YOLOv2、YOLOv3 等基础算法和Aerial-YOLOv2 算法进行训练,训练过程中设置相同的超参数。将测试集图像作为模型输入,直接通过网络回归预测出目标类别和位置信息。通过预测目标的边框与标签的边界框之间的平均交并比(mean Intersection Over Union,mIOU)来衡量预测的位置信息的准确性,另外选取预测框得分阈值为0.5,出于安全角度考虑,实际情况相对于准确度而言对漏检的容忍度更低,尤其是对挖掘机这种直接威胁管道安全的目标的漏检,大于阈值表示检测成功。最终,使用准确率、召回率、平均交并比以及检测速度作为模型的评价指标。
以上几种目标检测算法在航拍图像目标检测的实验结果如表1 所示。从表1 可看出,本文所提的Aerial-YOLOv2 网络在准确率、召回率上都高于YOLOv2,而仅仅牺牲了一点检测速度。而YOLOv3 虽然使用了更深的网络结构,并使用了多种改进策略,但是对于包含信息较少的小目标而言,过深的网络结构在提取信息能力上会遇到一个瓶颈,这时反而还会降低网络的检测速度。所以Aerial-YOLOv2 网络通过对网络结构进行多方面的改进后,其检测效果相对于YOLOV3 各方面都有提升,尤其是对一些小目标的召回率有相当大的提升,说明本文算法在检测小目标方面的有效性。
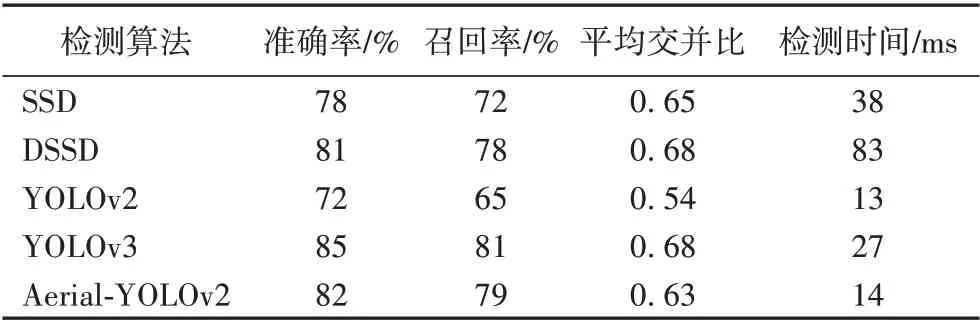
表1 不同算法航拍图像目标检测实验结果Tab.1 Experimental results of aerial image target detection by different algorithms
基础的YOLOv2 网络和Aerial-YOLOv2 进行航拍图像测试,检测出目标的能力对比如图9所示。图9(a)是YOLOv2的检测结果,图9(b)是Aerial-YOLOv2 经过相同训练策略后的检测结果。通过对比两图可以发现,YOLOv2 仅能检测到特征明显的目标,漏检体积较小、并未受到遮挡的目标;而Aerial-YOLOv2 则能够检测到较小,但特征不明显的目标,大幅地提升了模型的召回率。

图9 YOLOv2和Aerial-YOLOv2目标检测结果Fig.9 Target detection results of YOLOv2 and Aerial-YOLOv2
实验结果表明,对于航拍图像目标检测而言,Aerial-YOLOv2 网络能够在YOLOv2 基础之上以较少地增加运算量为代价,通过改进网络特征提取和回归预测模块,使得网络在准确率、召回率以及平均交并比等目标检测指标上有大幅提升。
3.2 训练策略的影响
为了验证不同训练策略对网络目标检测性能的影响。在相同原始数据集的情况下,在训练阶段对Aerial-YOLOv2分别采用不同的训练策略,在相同的测试集上便可获得不同训练策略对网络目标检测性能的影响,结果如表2 所示。表2 中,策略1 表示结合数据增强的迁移学习,策略2 表示通过K-means 方法聚类出数据集合适的锚点数量及尺寸,策略3表示基于ACE 的图像预处理。由表2 可知,直接使用原始数据集进行训练,模型效果泛化性能较差,在测试集上表现为准确率和召回率都较低。策略1 在大量数据的训练下,网络中的参数得到充分训练,测试结果表明综合指标大幅提升。策略2 能为神经网络提供准确的先验知识,预测框更接近真实的锚点框,平均交并比指标明显提高。策略3 通过图像预处理,解决图像目标特征纹理模糊问题,加强模型对目标的检测能力,召回率得到较大提升。策略1+2 通过对训练集更好地利用以及使用更合适的训练方法,准确率和目标位置准确度均获得提高;综合使用策略1+2+3,模型准确率为94%,召回率为91%,平均交并比为0.75。相对于直接训练Aerial-YOLOv2网络,准确率、召回率和平均交并比分别提高12 个百分点、12个百分点和0.12。
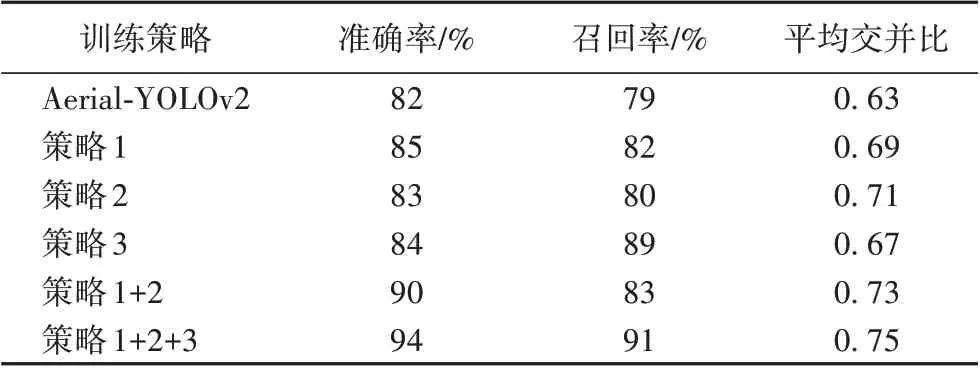
表2 Aerial-YOLOv2在不同训练策略下的检测性能Tab.2 Aerial-YOLOv2 detection performance under different training strategies
由实验结果可知,由于使用多种训练策略,模型的召回率指标提高最多。召回率越高表明漏检率越低,对于第三方施工中可能对管道造成直接威胁的挖掘机、打桩机等,漏检率指标对管道安全至关重要。如果直接使用常规训练方法进行训练,Aerial-YOLOv2 网络召回率仅有79%,这表明可能会有大量目标未被检测到,而使用本文的多种训练策略之后,召回率提高至91%,对保障管道安全至关重要。
图10 为传统训练方法训练Aerial-YOLOv2 和本文训练策略的检测结果的典型对比。图10(a)为传统训练方法后的检测结果,图10(b)为使用策略1+2+3的检测结果。由对比检测结果图可知,两者都对小目标有较好的检测能力,这是Aerial-YOLOv2 网络结构采用合适的锚点框与特征融合的多尺度检测方式的结果。但图10(a)中仍然会有部分漏检目标,图中使用黑色圆圈标注。漏检原因是因为目标仅有部分出现在图像中,使用本文的训练方法使网络对特征的学习和分类能力更强,能对同一目标不同状态进行更好检测,正如表2 所示,由于更少的漏检而较大地提高了召回率。

图10 不同训练方法典型结果对比Fig.10 Comparison of typical results of different training methods
综上所述,结合数据增强的迁移学习可以提升模型多项指标,基于K-means 的锚点框先验选择可以提升目标检测的平均交并比,基于ACE 的图像预处理可以提升目标检测的召回率,综合使用多种训练方法可有效提高模型整体性能。
4 结语
本文利用深度学习技术实现管道巡检中对无人机航拍图像的第三方施工、违章占压建筑物的目标检测,提出基于改进YOLOv2 网络结构与结合数据增强的迁移学习的目标检测算法。首先利用RD-C3 模块替代YOLOv2 中的卷积组和改进网络的回归预测方式,加强网络对小目标的检测能力。为解决数据集的问题,利用数据增强扩大数据集规模并通过K-means算法聚类分析出适合本数据集特点的锚点框,然后再结合迁移学习的方法训练改进后的网络,最后再通过自适应对比度增强的方法提升图像质量。实验结果表明,本文所提改进算法最终准确率、召回率分别可以达到94%、91%,每张图像检测时间为14 ms,可以满足无人机管道智能巡检中目标检测的需要;但本文的数据增强方法会造成部分数据的冗余,在数据处理方法方面仍然需要更进一步的研究。
猜你喜欢
农业工程学报(2022年14期)2022-10-19
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
小型微型计算机系统(2022年10期)2022-10-15
导航定位学报(2022年5期)2022-10-13
时代邮刊·下半月(2020年9期)2020-09-23
移动通信(2020年5期)2020-06-08
北京航空航天大学学报(2019年9期)2019-10-26
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
电机与控制学报(2018年9期)2018-05-14
