
基于卷积神经网络的桥梁裂缝识别和测量方法
2020-06-01 10:54梁雪慧程云泽张瑞杰
计算机应用 2020年4期
梁雪慧,程云泽,张瑞杰,赵 菲
(1. 天津市复杂系统控制理论与应用重点实验室(天津理工大学),天津300384;2. 天津理工大学电气电子工程学院,天津300384)
(∗通信作者电子邮箱*1871545564@qq.com)
0 引言
桥梁是交通设施互连的关键节点和枢纽项目,是国民经济发展和社会生活安全的重要保障。中国桥梁总数稳居世界第一[1],桥梁的维护和管理已成为确保桥梁安全运行的关键。桥梁的质量和安全与经济和民生息息相关,桥梁上事故的发生往往是由于缺乏科学及时的病害检测。裂缝是最主要的桥梁病害之一,如果不及时处理,很有可能造成桥毁人亡的意外。因此,选择科学有效的检测措施对桥梁进行定期检查迫在眉睫。
近年来,为了准确、快速地提取桥梁裂缝,国内外研究者开展了全面而深入的研究,并取得了显著的成就。Aerobi EU项目已在欧洲建立,旨在开发和验证创新的智能空中机器人系统的原型。Sanchez-Cuevas 等[2-3]设计了无人机的桥梁检测系统;Amhaz 等[4]针对路面裂缝的对比度低、连续性差等特点,提出了一种基于最小代价路径搜索的路面裂缝检测算法;王耀东等[5]针对全局图像检测精度低的问题,采用分块的思想处理图像。还有很多其他检测算法[6-12]被提出,但这些图像处理方法检测裂缝大都需要手动设计特征及设定参数,准确率低且周期长,不能很好地对桥梁裂缝进行检测。
深度学习是近些年才提出的智能识别方法[13],在其他领域表现突出,但应用到桥梁裂缝检测上还有很大挑战:1)训练网络需要大量样本,目前裂缝标签样本数据匮乏;2)经典的深度学习模型直接用于桥梁裂缝检测时,效果不甚理想。针对这些局限性,本文提出一种基于改进GoogLeNet 网络的桥梁裂缝检测方法。该方法的主要流程如图1 所示,主要设计内容包括数据来源和标签、裂缝图像预处理、裂缝图像分类识别及裂缝的定位和测量。

图1 本文方法的流程Fig. 1 Flowchart of the proposed method
1 数据来源和标签
使用实地随机环境下采集的800 张不同桥梁的裂缝图像样本,首先将其归一化为2 048× 1024 分辨率的图片,然后采用固定大小256 × 256的窗口进行滑动裁剪,裁剪后的图片分为包含裂缝的裂缝图片和不包含裂缝的背景图片,共24 000张。从中挑选7 500张裂缝图片组成裂缝数据集,挑选15 000张背景图片组成背景数据集,并将其拆分成训练集和测试集。数据集构建成功后,利用Jupyter Notebook 分别对训练集和测试集的裂缝和背景图片构建相应的类别标签,组成带标签的原始的数据集,如表1所示。

表1 裂缝带标签原始数据集Tab.1 Crack tagged original dataset
2 桥梁裂缝的预处理
为了保证检测方法能应对各种复杂的情况,800 张图片中包含若干低质量的图片,如雾天、阴天等特殊天气,桥梁上建筑物遮挡导致的光线不足等,如图2(a)为阴天、光照不足时的裂缝图片。为了保证训练图片的质量,需要对裂缝图片进行一系列特殊的处理。
图片经过双边滤波[14]和Retinex[15]图像增强算法后图像明显要比原始图像亮,达到处理特殊天气和有建筑物遮挡光照不足的情况,效果如图2(b)所示。拉普拉斯锐化是一种提高图片对比度的图像处理方法,此方法也可以提高裂缝边缘细节,效果如图2(c)所示。为了进一步提高对比度,将锐化后的图像进行灰度化处理后,采用直方图均衡化(Histogram Equalization)的方法[16]提升裂缝和背景的对比度,效果如图2(d)所示,经过均衡化操作,与原始图像相比清晰程度有明显提升。
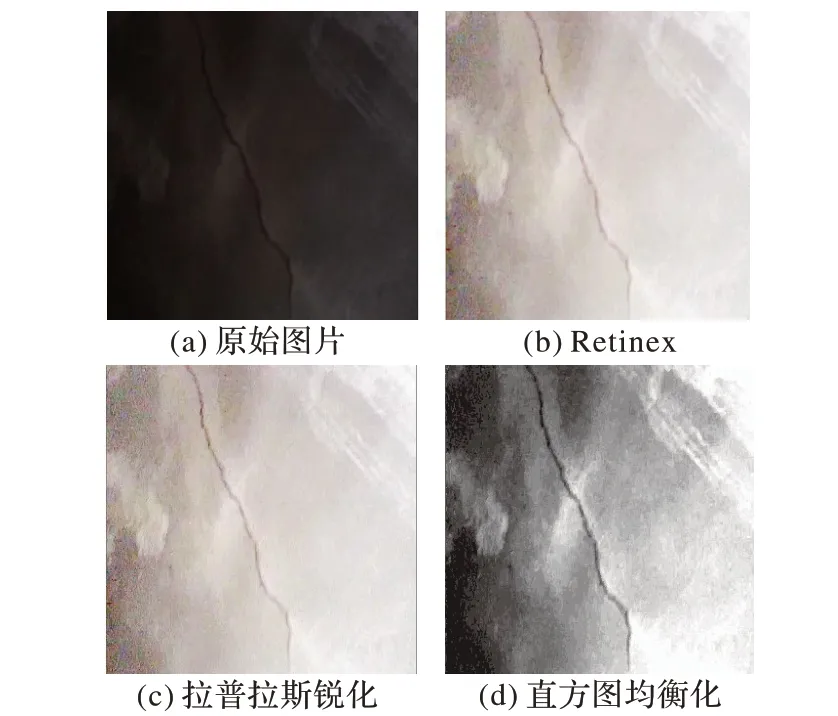
图2 预处理效果Fig.2 Preprocessing effect diagram
将7 500 张裂缝图片和15 000 背景图片进行双边滤波、Retinex 图像增强、拉普拉斯锐化、直方图均衡化一系列的图像预处理操作,命名本文预处理方法为RLH(Retinex-Laplace-Histogram Equalization),可以发现处理后的图像增强了人眼观察的视觉效果,图片更清晰。将经过RLH 处理的数据集命名为RLH数据集。
本文中,对训练集和测试集的图片都进行预处理操作,以保证训练和测试的准确率。当新图片放入训练好的网络中识别是否为裂缝时,虽然需要先经过预处理操作,但也提高了分类的准确率,所以对测试集图片进行预处理操作非常必要。
3 桥梁裂缝图像分类识别方法
3.1 GoogLeNet卷积神经网络
卷积神经网络[17]是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。GoogLeNet[18]网络模型是具有22 层的深度网络,该模型说明了采用更多的卷积核和更深的网络可以达到更好的预测结果,而且相对于AlexNet和同年提出的VGG(Visual Geometry Group),参数数量要小得多。模型如图3所示。
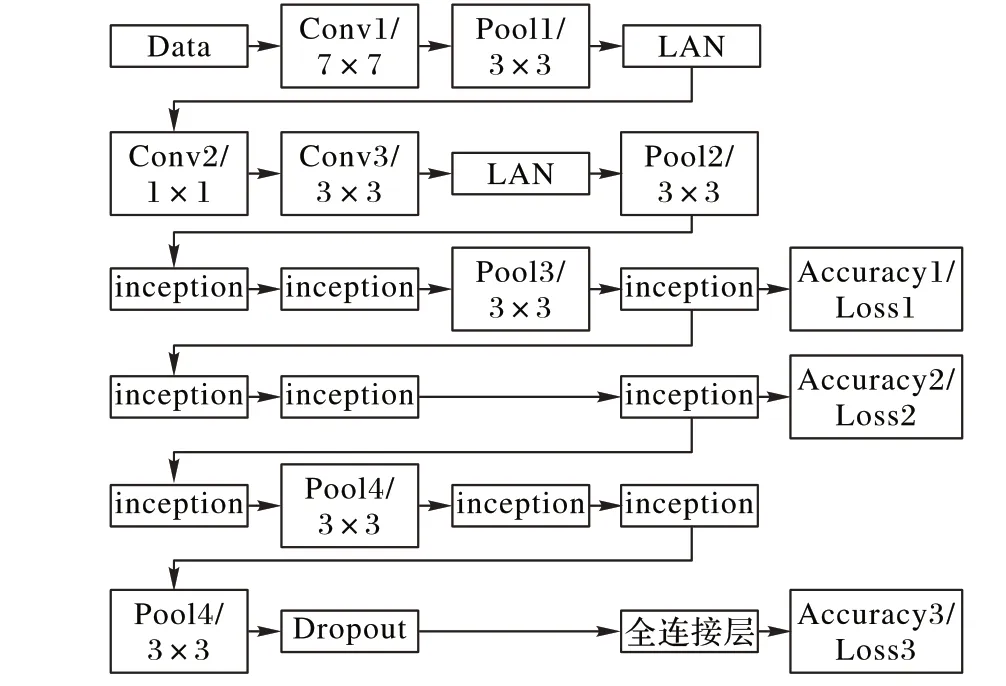
图3 GoogLeNet网络结构Fig. 3 GoogLeNet network structure
3.2 原始数据与RLH处理数据对比
在caffe 框架下采用GoogLeNet 网络模型分别训练原始数据集和经过RLH 处理的数据集,训练次数定为2 000 次,定义测试集准确率为被正确分类的裂缝和背景图片与放入网络的总裂缝和背景图片的比值,测试集准确率对比如表2 所示。统计4次训练结果平均值,相对于原始数据,采用RLH 处理的数据训练集准确率提升了1.91 个百分点,测试集准确率提升了3.07个百分点。

表2 原始数据集和RLH数据集训练对比 单位:%Tab. 2 Comparison of training between original data set and RLH data set unit:%
3.3 改进的GoogLeNet网络结构
1)GoogLeNet 网络各inception 层仍然使用了5× 5 的卷积核,大的卷积核不利于网络提取裂缝特征,而且网络的参数也会大大增加,因此对网络的inception 层的卷积核进行归一化处理,将inception 层中全部使用1× 1 的卷积核和3× 3 的卷积核,如图4 所示,将原始的5× 5 的卷积核变成两个3× 3 的卷积核,这样处理原本的25(5× 5)个参数能减少到18(2 ×3× 3)个,原始的GoogLeNet网络中存在9个inception 层,这样采用归一化的卷积核不仅可以增加网络的深度,也可以减少训练参数,提高训练速度。
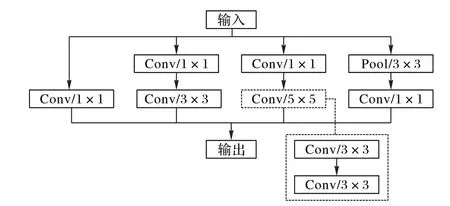
图4 改进inception层前后对比Fig. 4 Comparison before and after improving the inception layer
2)由图3 可知,原始的GoogLeNet 网络开头用的也是7×7 的卷积核,因此对网络开头作3 种尝试,具体结构如图5 所示。3 种结构全部采用3× 3 卷积核,准确率和时间复杂度对比如表3 所示,数据显示,结构三网络模型的识别裂缝的准确率比GoogLeNet 模型提升了2.06 个百分点且时间复杂度更低,表明结构三模型识别裂缝更合适。
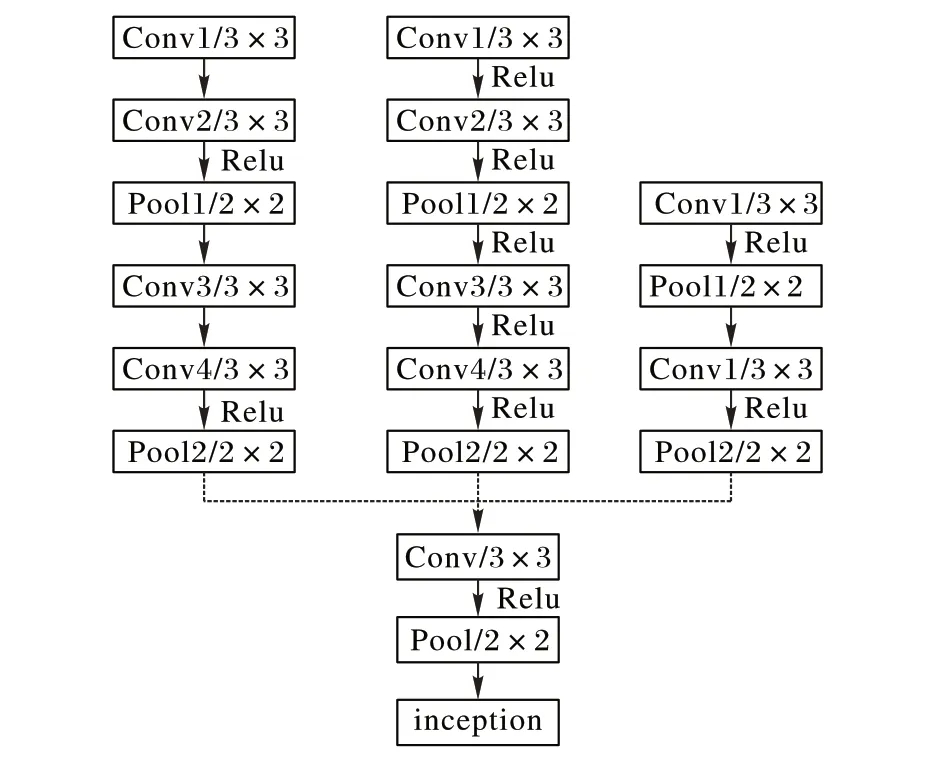
图5 GoogLeNet网络开头三种方案Fig. 5 First three schemes for GoogLeNet networks

表3 三种修改方案性能对比Tab. 3 Performance comparison of three modified schemes
3)针对桥梁裂缝,在利用经过RLH 处理数据集对改进的GoogLeNet 网络进行训练的过程中,发现GoogLeNet 网络中的Accuracy2、Accuracy3(具体位置见图3)随时间变化的数值基本一样,Loss2、Loss3(具体位置见图3)的数值也相差不多。对比如表4所示,考虑到在第6个inception后裂缝识别的准确率和损失值已经达到完整网络的训练效果,那么可以去掉七层及以后的inception 层以缩减训练时间。经后期分析,出现上述情况的原因是GoogLeNet 模型是ILSVRC(ImageNet large Scale Recognition Challenge)竞赛中针对1 000 种标签的分类模型,其中个别类别特征细节比较难提取,所以需要更多的inception 层提取它的微小特征。裂缝纹理相对简单,所以到第6个inception层已经能够提取出它的特征。
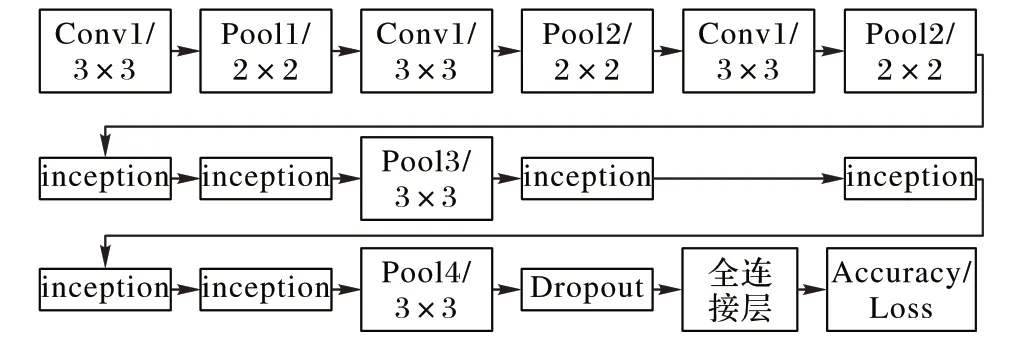
图6 改进GoogLeNet网络结构Fig. 6 Improved GoogLeNet network structure

表4 GoogLeNet网络各层测试准确率和损失值对比Tab. 4 Comparison of test accuracy and test loss value of each layer of GoogLeNet network
3.4 实验结果分析
本实验采用随机梯度下降法(Stochastic Gradient Descent,SGD)[19]训练网络,分类结果采用Softmax 函数进行计算。

其中:Pi为网络输出结果为类别i 的概率;xi为网络最后一层第一个节点的输出值;n为划分类别总数。
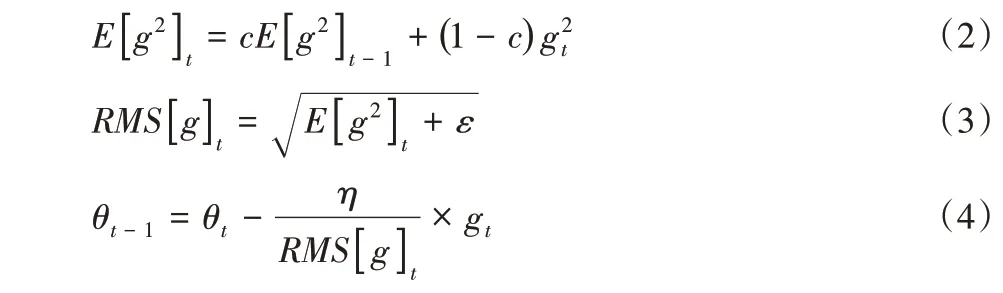
其中:gt为t时刻的梯度;c为衰减因子,用于控制在t时刻之前要累计多少之前的梯度信息;θt-1、θt代表更新前后参数;η 为学习率;RMS[g]t为均方根;ε是为了防止分母为0。上述更新方法解决了对历史梯度一直累加而导致学习率一直下降的问题,但还需要自己选择初始的学习率,因此采用下面公式确定学习率的自适应变化:
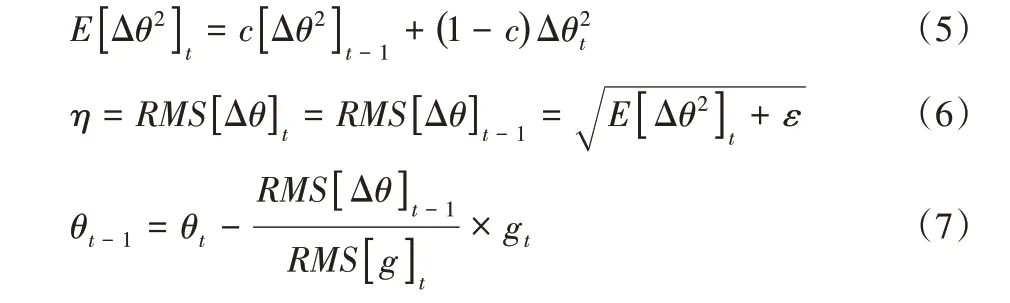
将η 换成一个能够根据梯度信息自动变化的量,从而做到学习率的自适应变化。假设需要学习的函数映射在局部是光滑的,那么可以用前一次更新的参数Δθt-1近似Δθt,参数更新如式(7)所示。
通过将大卷积核变成小卷积核的操作分别修改GoogLeNet 的inception 层和网络开头,再加上裁去第7 个及以后 的inception 层,对 比 本 文 网 络 与AlaxNet、GoogLeNet、improved_CNN 的测试集准确率、训练时间和测试集损失值,结果如表5 所示。可以发现相对于原始GoogLeNet 网络训练本文网络准确率提升了3.13 个百分点,训练时长缩短为原来的64.6%。相对于AlaxNet、improved_CNN 本文网络训练时间稍长,但准确率明显更高,通过对比数据可以发现,本文网络训练裂缝图片具有更好的识别效果和训练速度。
在caffe 框架下,采用上述4 种网络模型分别训练原始数据集和经过RLH 处理的数据集各3 次,测试集准确率对比如表5 所示,统计3 次训练结果平均值可以发现,相对于原始数据,采用RLH 处理的数据训练网络四种网络的测试集准确率都有所提升,本文网络测试集准确率更是提升了2%,说明采用RLH数据集训练效果更好。
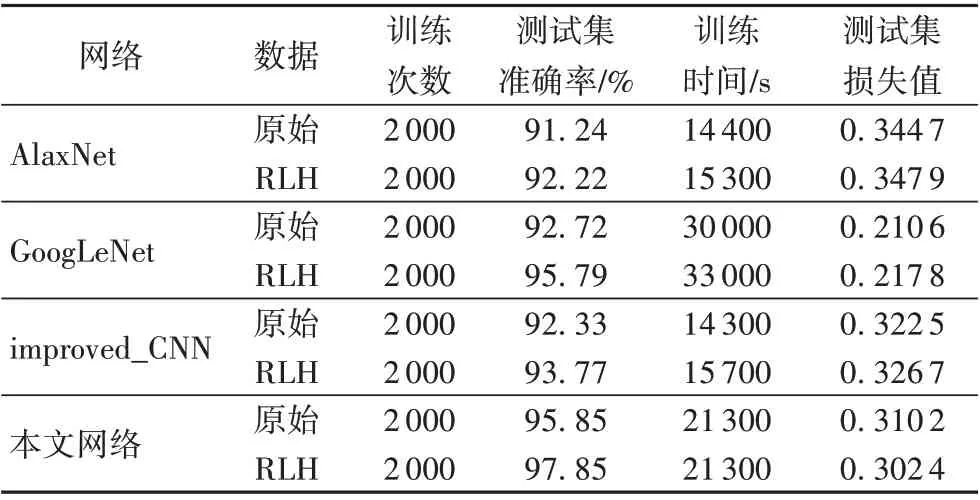
表5 本文网络与其他网络训练效果对比Tab. 5 Comparison of training effects between the proposed network and other networks
4 裂缝的定位和测量
4.1 裂缝定位
在第3 章中,将RLH 数据集放入改进的GoogLeNet 网络进行训练,得到训练好的分类识别裂缝模型,即后缀名为caffemodel 的文件。接下来,准备100 张新采集并归一化为2 048× 1024 分辨率的图片,同样采用滑动窗口大小为256 ×256对裂缝进行裁剪,并利用RLH 数据集训练好的caffe model文件预测新裁剪的大小为256 × 256的图片,如果预测为裂缝图片,把裁剪下来的图片用方框标注,并进行标号。按照从左到右、从上到下的顺序,从大图片上裁剪小图片放入分类网络识别裂缝,如果是裂缝用方框标记,直到把整张大图片裁剪完,即实现裂缝的定位。这样通过滑动窗口,对于小图片相当于识别,对于大图片相当于定位,也就是说裂缝的识别和定位其实是同步的。定位图如图7(a)所示,可以看出,相比整张裂缝图片定位,分块处理定位裂缝更加准确。
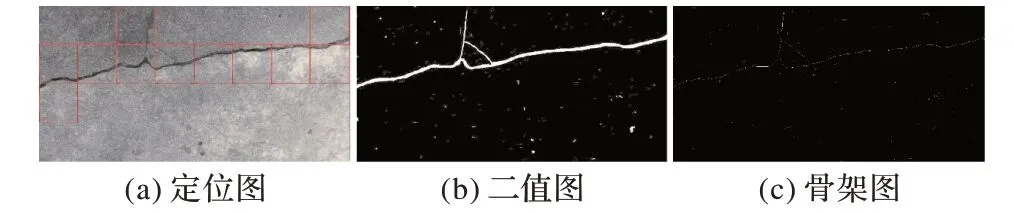
图7 定位和骨架提取Fig.7 Positioning and skeleton extraction
4.2 裂缝的提取
本文采用滑动窗口定位桥梁裂缝,与此同时,也把整张图片分为32 张256 × 256 的小方块,分别对每个小方块采用最大类间方差法分割图像,得到桥梁裂缝的二值图像,并将连通区域像素点的个数定义为Mi,二值图如图7(b)所示。
本文对桥梁裂缝采用滑动窗口分块处理,优点如下:
1)对每个小图片进行预处理的操作,处理更具细节,能更清楚地反映图片的纹理信息。
2)将小图片放进网络中训练,网络更容易提取裂缝特征。
3)相比整张裂缝图片定位,分块处理定位裂缝更加准确。
4)把每张小图片分开进行阈值分割,这样能更准确地提取出裂缝边缘信息,以便后续对裂缝长度和宽度的计算。
4.3 骨架提取算法计算裂缝长度和宽度
4.3.1 裂缝的长度
得到裂缝图像的二值图,再采用骨架提取算法计算裂缝的长度和宽度。遍历整个图像,找出所有像素值为1 且满足周围8 连通区域至少有一个像素为0 的点,如果这些点为Pi,其邻域的8个点顺时针分别为P2、P3、…、P9,如图8(a)所示。
标记同时满足式(8)~(9)条件的边点:
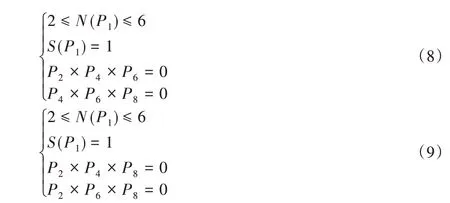
其中:N(P1)为非零邻点的个数;S(P1)为以P2、P3、…、P9为序时,这些点的值从0到1变化的次数。当对所有边界点标记完后,将所有标记点像素值变为0。反复进行上述操作,直至没有满足标记条件的像素点出现,此时剩下的点构成本图像区域的骨架,并将连通区域像素点的个数定义为Ni。由于本文图片全由相机从高度为1 m 的位置拍摄,所以本文设定用0.04Ni代表裂缝的长度,单位为厘米,骨架图如图7(c)所示。
4.3.2 裂缝的宽度
在4.3.1 节中得到裂缝骨架图的基础上,本文提出一种基于骨架方向上的裂缝宽度计算方法。
1)由于骨架图上的裂缝图像是单像素图像,即骨架线图像,求骨架线上每一点的切线方向。设M 为骨架线上的任意一点,则其八邻域内有两个点。图8(b)为点M 的八邻域切线示意图,N1、N2分别为点M的八邻域中的两个点,则点M的切线方向等于线段MN1的切线方向与MN2切线方向的均值,即

2)在计算出裂缝各点的切线后,再计算骨架线上各点的法线,法线与裂缝左右边界点的距离(欧氏距离)即为裂缝的宽度。裂缝的左右边界由二值图确定。

图8 细化算法和切线示意图Fig.8 Schematic diagrams of refinement algorithm and tangent
4.4 计算结果分析
近几年研究者提出多种检测裂缝长宽度的方法,具有代表性的为以下两类:1)王睿等[20]通过计算裂缝的面积和周长计算裂缝宽度,这种方法也是目前用得最多的一种方法。2)元大鹏[21]采用纵向切割裂缝取上下边界中点,再连接中点计算长度,接着采用邻域扩张的思想来计算裂缝的宽度,即:选取裂缝的一个内部点,向两侧扩张直至到裂缝边界。计算4 个宽度方向上扩张的像素点个数,取所有内部点宽度的最小值作为裂缝区域的宽度。
如图9 所示:裂缝1 为纵向裂缝,人工测量长度为49.90 cm,宽度为1.05 cm;裂缝2 为横向裂缝,人工测量长度为109.86 cm,宽度为0.36 cm。

图9 裂缝图示例Fig.9 Crack diagram examples
将本文计算裂缝1 和裂缝2 长宽度的方法与以上两种方法对比,测量结果对比如表6~7 所示。从表6~7 可看出,文献[20]方法由于是通过面积和周长计算裂缝宽度,只能处理纹理简单的裂缝,对复杂的裂缝效果不好。文献[21]中计算长度的方法准确率与本文算法相差不多,但由于文献[21]方法是在灰度图上计算裂缝宽度的,没有有效地定位裂缝的边界,这个误差不可避免,因此本文算法精度更高;而且本文算法采用骨架线求法线的方法,考虑了裂缝走势的情况,也是宽度计算准确的一大原因。
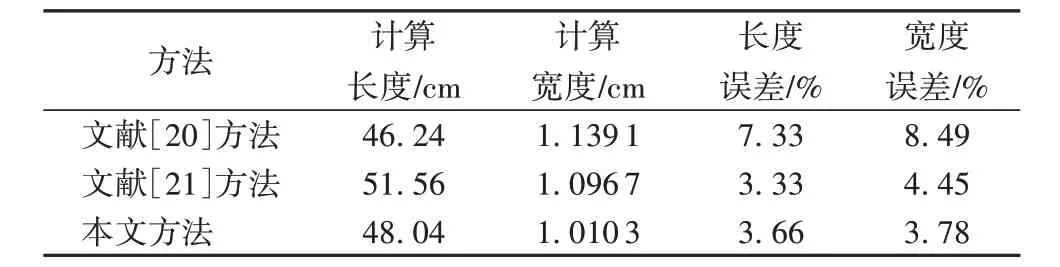
表6 裂缝1测量结果对比Tab. 6 Comparison of crack1 measurement results

表7 裂缝2测量结果对比Tab. 7 Comparison of crack2 measurement results
为了进一步验证利用骨架提取算法对裂缝长度和宽度计算的精度,在100 张原图上利用本文算法统计检测结果与实际测量结果进行对比。实验结果表明,100 张裂缝图片长度提取平均误差为2.87%,宽度提取平均误差为4.29%,这表明本文算法具有理想的计算能力。
5 结语
针对桥梁裂缝检测问题,提出基于深度卷积神经网络的检测方法对裂缝进行训练,最终实现裂缝的分类、定位和特征提取。
1)深度学习对样本要求比较高,需要大量带标签的数据集,才能保证模型的识别率,还可以防止过拟合现象的发生,面对桥梁裂缝数据集缺失的问题,实地拍摄并制作了桥梁裂缝数据集,但目前数据还远远不够,开展样本收集整理工作将是未来主要任务之一。
2)为了保证其检测方法能应对各种复杂的情况,如光照的不匀、雾天等特殊天气、桥梁上建筑物遮挡导致的光线不足等,本文提出了针对桥梁裂缝的一系列预处理方法,经GoogLeNet 网络验证,训练集准确率提升了1.91%,测试集准确率提升了3.07%,表明桥梁裂缝预处理的必要性。
3)通过将大卷积核变成小卷积核的操作分别修改GoogLeNet的inception 层和网络开头,再加上裁去第七个及以后的inception 层,放入到原始数据集进行训练,网络测试集准确率提升3.13 个百分点,训练时长缩短为原来的64.6%,表明改进GoogLeNet 训练裂缝图片具有更高的准确率和更快的训练速度。
4)采用滑动窗口将图片放入训练好模型文件,并用方框框出预测是裂缝的图片,相对于整张图片送入网络,裂缝定位更加精确。
5)采用骨架提取算法,提取裂缝骨架图,将定位好的裂缝二值图处理为骨架图,并利用裂缝二值图和骨架图像素点的个数计算裂缝的长度和宽度。统计100 张图片的计算结果,长度提取平均误差为2.87%,宽度提取平均误差为4.29%,这表明本文算法具有理想的计算能力。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
发明与创新·大科技(2020年6期)2020-06-22
中国新技术新产品(2020年5期)2020-05-06
农业工程技术·温室园艺(2017年3期)2017-07-13
人生十六七(2015年5期)2015-02-28
销售与市场·管理版(2009年21期)2009-09-03
