
语义省略“的”字结构自动识别研究*
2020-05-20 01:52戴茹冰侍冰清曲维光
语言科学 2020年1期
戴茹冰 侍冰清 李 斌 曲维光,**
1南京师范大学文学院 江苏 南京 210097 2南京师范大学计算机科学与技术学院 江苏 南京 210023
提要 语义省略是语言使用中存在的一类普遍现象,其省略的信息给机器自动理解造成困难。其中具有语义省略“的”字结构,在省略概念添加的类型中所占比例最高。文章利用“的”字局部上下文的词性和句法信息,通过动词框架找出具有语义省略的“的”字结构。实验表明,该方法能够在CTB8.0(Chinese Treebank)语料中有效识别出含有语义省略的“的”字结构,在测试集中F1值达到87%,取得了较好的实验效果,为机器对深层语义的理解奠定基础。
1 引言
1.1 研究理由
省略是语言中存在的一种普遍现象,也是语言研究中不可回避的问题之一。对于省略的界定,朱德熙(1982:248)、吕叔湘(1979:67-68)、王维贤(1997:25-26)等学者分别从句法、语义和语用三个平面给出定义。但不管哪种形式的省略,总是语形隐而语义存。对于省略的语义信息,人类可通过百科知识和语境信息加以理解,但对机器而言,语义省略无疑会给机器理解造成巨大障碍。在语言理论方面,已有学者从传统语法、功能语法和认知语法等角度做了大量研究。在自然语言处理领域,省略研究多集中在零代词类别的恢复和零代词的指代消解(尹庆宇等 2015)。对于语义表示,国内外现有的语义资源,包括PropBank(Palmer et al.2005),FrameNet(Collin et al. 1998),Chinese FrameNet(刘开瑛 2011)等,对省略成分的语义标注问题均未涉及。
近几年一种新型的句子语义表示方式——AMR(Abstract Meaning Representation,抽象语义表示)(Laura et al. 2013)受到学界的广泛关注。该方法突破了传统基于句法形式表示语义的方式,允许补充省略或隐含的语义概念以还原句子完整语义。这种概念添加方式对于汉语中的省略结构同样有着良好的表示能力,能够较为完整地补充出省略成分(曲维光等 2017)。李斌等(2017)将AMR语义表示体系引入到汉语中,并对AMR语料中需要添加的省略语义概念进行统计分析,发现“的”字结构在所有省略概念添加类型中所占比例为45.7%,占有最高比重。
“的”作为现代汉语使用频率最高的虚词之一,意义和用法灵活,在各种虚词中的研究也最为普遍。其中存在部分具有语义省略“的”字结构,如“卖菜的”“开车的”等。这些不依附任何成分而独立充当名词性成分的“的”字结构通常在语义上伴有省略的成分。具有语义省略“的”字结构虽然在整个“的”字语料中所占比例较小,但其所隐含的成分对于整体语义的理解却有至关重要的作用。正确识别带有语义省略的“的”字结构能够有效减少因省略造成的语义自动理解障碍,为补充句子完整的语义打下基础。
1.2 已有研究
在现代汉语中,对于“的”的研究可追溯到1961年朱德熙《说“的”》。他将“的”的用法分为副词性语法单位的附加成分、形容词性语法单位的附加成分和名词性语法单位的附加成分三个类别。之后,朱德熙(1966)又进一步完善关于“的”字的分类体系,将由谓词性成分构成的“的”字分为两类:一类是如“吃的”“穿的”可独立使用的,表示转指的用法;另一类是不能独立表示事物,用来修饰名词的表示自指的用法,如“跑步的(时间)”等。
“的”字结构是名词性偏正结构的语境变体(徐阳春 2003:126),实质是定中关系的偏正短语中心词隐去后的短语。其形成特征为词语后附着一个“的”字。然而并不是所有具有定中关系的偏正短语中心词都可以隐去从而形成“的”字结构。对于中心词可省的条件限制,黄国营(1982)、吕叔湘(1999:159-160)从语法角度分析了形如“X+的”结构中X与中心词的句法关系,即当中心词为X的主宾语时,中心词可省。孔令达(1992)则从意义角度区分了X与中心词的语义类别关系,并对X是否具有区别性总结了一套形式化的鉴别方式。此外,石毓智(2000)从语言认知角度阐释了“的”字结构的生成机制。
在语言理论及认知方面对“的”字结构研究较为普遍。在自然语言处理领域,韩英杰等(2011)将“的”纳入虚词用法研究中,基于“三位一体”(虚词用法词典、虚词用法规则库和虚词用法语料库)现代汉语广义虚词用法知识库(昝红英和朱学峰 2009)对“的”字的用法进行自动识别。但因其出现频率高且用法复杂,基于规则的方法识别效果并不理想。并且鲜有人从省略的语义成分角度关注“的”字结构表示的语义完整性问题。仅从句法角度分类描述“的”的用法和特征,并不能深入挖掘受语境和语言经济原则制约而省略的中心语,还原“的”字结构完整语义。这也是传统句法表示无法解决词内分析困境的缺陷之一。
本文以省略“的”字结构为研究对象,以宾州中文树库CTB8.0语料(Chinese Treebank,以下简称 CTB)的10000句网络媒体语料作为统计样本和实验语料,利用中文AMR的人工标注结果抽取出省略“的”字结构并进行人工校对,形成可用于比对的标准答案。对其中前5000句AMR语料中因语义省略而需要添加的概念进行统计分析,并以此作为样本总结“的”字结构内部构成规律及上下文信息特点,针对不同类别“的”字结构制定识别策略。后5000句作为开放测试语料来验证省略“的”字结构的识别效果。实验结果表明,该方法能够有效地提取省略“的”字结构,从而更好地促进机器对深层语义的理解。
2 “的”字结构特征及识别策略
2.1 “的”字结构类型特征
本文从“的”外部信息出发,结合语法类词典《现代汉语八百词》(吕叔湘 1999)、《现代汉语词典》(2012年,第六版)、现代汉语广义虚词用法知识库(昝红英和朱学峰 2009)及CTB8.0网络媒体真实语料,分析省略与非省略“的”字所在上下文特征,并针对各类别给出不同的识别策略。
《现代汉语八百词》把“的”的意义分为7个义项,29种用法,其中省略“的”字结构用法分散在两个义项中。《现代汉语词典》(2012年,第六版)把“的”的意义分为6个义项,14种用法,对省略“的”字结构的描写细分为5小类,但未给出具体的用法特征。在“三位一体”虚词用法词典中,“的”的意义分为11个义项,39种用法,并通过释义、用法、例句、搭配等属性对助词“的”的用法进行描述。为便于统计,刘秋慧等(2018)对虚词用法词典中“的”的用法设置合并方案,将出现频率较低的用法向上合并。合并后的“的”字共为5个义项,9种用法。对于每类用法的形式化描述规则主要基于上下文词性特征。综合以上语言资源,结合CTB8.0真实语料中各类型“的”的分布情况,本文针对语义省略“的”字结构识别任务,整合使用频率较低的用法,总结了“的”的4个主要义项和17种用法,基本覆盖“的”字结构在语料中出现的各种类型。“的”的主要义项和用法及在CTB8.0前5000句样本分析语料中的出现频率如表1所示。
表1 “的”主要义项及用法描述
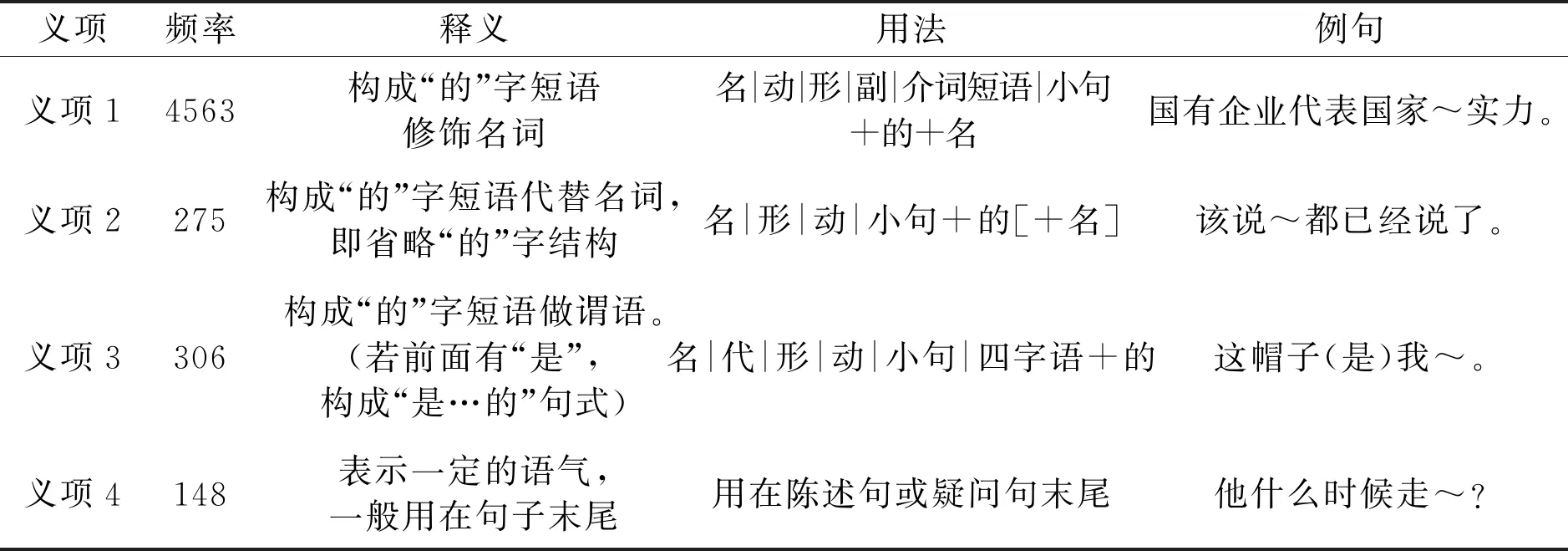
义项频率释义用法例句义项14563构成“的”字短语修饰名词名|动|形|副|介词短语|小句+的+名国有企业代表国家~实力。义项2275构成“的”字短语代替名词,即省略“的”字结构名|形|动|小句+的[+名]该说~都已经说了。义项3306构成“的”字短语做谓语。(若前面有“是”,构成“是…的”句式)名|代|形|动|小句|四字语+的这帽子(是)我~。义项4148表示一定的语气,一般用在句子末尾用在陈述句或疑问句末尾他什么时候走~?
其中,义项2“的”字短语代替名词的用法和义项3的部分“是……的”用例表示的“的”字结构含有语义省略成分,即本文所要识别的“的”的主要用法。
为识别省略“的”字结构,我们考察其语义省略与非省略用法的差异,通过比对二者词性和句法信息特征,从样本语料中提取“的”的邻接成分与共现成分并进行统计分析,总结其中具有可操作性的判断特征,制定形式化规则以有效识别省略“的”字结构。采用的特征为目标词(“的”)上文离合共现的词性序列特征及下文紧邻共现的词语或词性特征。
2.1.1 下文特征
非省略“的”字用法主要包含义项1和义项3的部分用例及义项4。从各义项在语料中的出现频率来看,非省略用法在整个语料中所占比例较高,在绝对数量上也远超省略类型。对比其与省略“的”字结构用法差异如下:
省略“的”字结构与非省略中义项1用法主要区别在其下文特征:“的”字下文是否含有被修饰的中心语。例如:(1)本文所举例句均出自CTB8.0语料。例句中括号内为省略的语义成分。因识别规则基于词性信息,为便于描述,例句中的词语均采用中文宾州树库词性标记集来标注词性。具体信息参见Santorini(1990:1-5)。
(1)国家/NN 的/DEG 实力/NN
(2)没/AD 来/VV 的/DEC(人)请/VV 举手/VV
例(1)中,“的”字前后的修饰语与中心语在句法和语义层面都是完整的,因此判为非省略结构助词。例(2)“的”字结构修饰的中心语“人”受语境或经济原则制约而省略,表达的语义信息不完整,因此判为省略类型。
在区别二者时主要观察“的”字下文的词语或词性特征:义项1的“的”字用法中,“的”字下文若为名词或名词短语,则判断其后存在中心语,为非省略结构,即义项1的“的”字下文特征为“的+名词|名词短语”。在义项2的“的”字结构中,通过对下文邻接词位置的词语和词性进行统计,发现出现频次最高的词语和词性分别为“是”和动词,其中“是”出现频次为156次,动词出现38次,二者占据70%以上的比例。从语法结构上看,若“的”下文为动词,动词前的“的”字结构会被看作一个整体,作为动词的主语,而该主语以“的”字结尾,缺少中心语,可看作语义省略结构。因此我们将义项2“的”字下文特征界定为“的+是|动词”。
对“的”字用法义项1与义项2的下文特征分析表明,“的”字下文紧邻共现的词语或词性有较明显的特征。表2中省略结构在“的+名词|名词短语”和“的+是|动词”两类的比例也让我们有理由预测将“的”字下文特征作为识别规则可以得到较好的分类效果。
2.1.2 上文特征
省略“的”字结构与义项3和义项4在用法描述上并无明显的下文特征区别,并且上文特征如陈述句、疑问句及小句因结构复杂,在虚词用法规则库上也未能抽取出严格的形式化特征。结合吕叔湘(1999:159)对“的”后中心语可省条件的描述:中心名词能做前面动词的主语或宾语的,可省。因此我们将省略“的”字结构和非省略语气词用法的上文特征区别定义为:判断“的”字上文紧邻的动词所包含的论元结构是否完整,若论元结构完整,“的”字为语气词,属于非省略结构;否则,判断为省略结构。例如:
(3)事物/NN 都/AD 有/VE 正反面/NN 的/SP
(4)你/PN 能/VV 想到/VV 的/DEC(事情),/PU 国家/NN 早/AD 就/AD 能/VV 想到/VV
例(3)中,动词“有”的必有论元成分“事物”(主语)和“正反面”(宾语)完整,因此判为非省略类型。例(4)中“的”前动词“想到”的宾语成分缺失,因此判为省略类型。
义项3“的”字短语作谓语,包含一类较为特殊句式,即“是……的”句,其中“是”所承担的句法功能分为主要谓语动词和与“的”连用表示判断语气两种用法。在样本分析语料中,该类别中省略“的”字结构所占比例为25.8%(见表2)。鉴于该类没有明显的上下文紧邻词性特征,仅将“是……的”句式单独列出。
综上所述,“的”字用法特征可总结为以下四类: 1)的+名词|名词短语;2)的+是|动词;3)“是……的”句式;4)其他类型。其中1)类为非省略类型“的”字下文特征,2)类为省略类型“的”字下文特征,3)和4)类型没有明显的上下文紧邻词特征,需要进一步挖掘深层的语义特征或配合使用语义语法知识资源来制定识别策略。上述4类“的”字结构用法特征中省略及非省略的类型及所占比例详见表2。
表2 各类“的”字结构省略类型比例
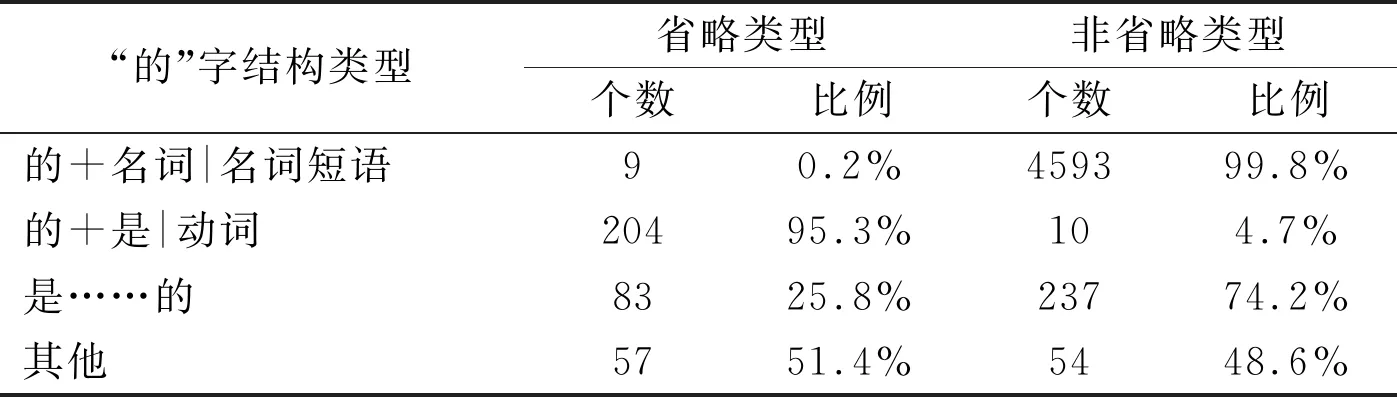
“的”字结构类型省略类型非省略类型个数比例个数比例的+名词|名词短语90.2%459399.8%的+是|动词20495.3%104.7%是……的8325.8%23774.2%其他5751.4%5448.6%
2.2 “的”字结构的识别策略及形式化描述
根据表2数据,观察到“的+是|动词”和“的+名词|名词短语”两个类别可直接根据下文信息判断省略与非省略类型。对于“是……的”句式和“其他”两类,识别策略主要依靠“的”字上文的句法成分及所在短语的核心动词的论元结构判断,每种类型具体识别策略如下。
2.2.1 “的+名词|名词短语”类型识别策略
对于名词短语的判断,本文基于词性从CTB样本分析语料中总结出65种基本名词短语及扩展模板。该类别“的”下文内容主要形式为限定性词语+名词|名词短语(n|np),其中限定性词语包括:形容词(VA)|区别词(JJ)|动词(VV)|名词(NN)|代词(PN)等。在名词短语中,常会出现多个“的”字短语共现的现象。在句法结构中,其结构类型可分为嵌套结构和并列结构,即中心语前的多个限定语之间的结构关系。但在词性序列中,表现为多个限定语+的+n|np 的线性序列,“的”前限定语成分为多种类型,只有中心语为强制出现成分,可为名词或名词短语。例如:
(5)他/PN 的/DEG 无私/AD 奉献/VV 的/DEC 精神/NN……
其中“的”后的名词短语为中心语前多个修饰语的嵌套结构。
本文以有序的BNF(Backus-Naur Form)范式描写每类语言规则,名词短语具体形式化描述为:{[AD]+VA|JJ|VV|PN+[的]}+n|np,即“的”下文能与该字符串模式匹配的用法为非省略类型。
2.2.2 “的+是|动词”类型识别策略
对于该类别,我们主要判断“的”下文一元邻接词是否为“是”或动词,有时动词会受副词成分修饰,在“是”或动词前加上副词表达一定的语气或程度差异,此时“是”或动词会出现在下文二项共现词的位置。对于这类现象采取缩减策略对副词性成分进行归并处理,避免识别过程受副词成分干扰。该策略识别结果为省略类型。
2.2.3 “是……的”类型的识别策略
该类别主要判断依据为“是”和“的”之间的词语序列,即主谓宾句法成分是否完整。若是完整的序列结构,“的”属于语气词,判断为非省略,否则为省略结构。对于“是”“的”之间的词语序列,本文主要依据词性序列判断其语法成分。通过对语料中符合该句式的句子统计分析,得到词性序列模板(其中每类所列出的模板都为该结构的基本模板,语料中存在大量扩展式小类,本文采取缩减策略对各类扩展模板整合归并,以还原为基本模板,具体缩减策略详见下页表4)。
通过观察“的”字上文信息,参考《现代汉语八百词》对“是……的”用法描写,我们将其细分为以下四个小类。表3给出了各小类在“是……的”句中所占比例及是否为省略类型。
表3 “是……的”句式类型比例表
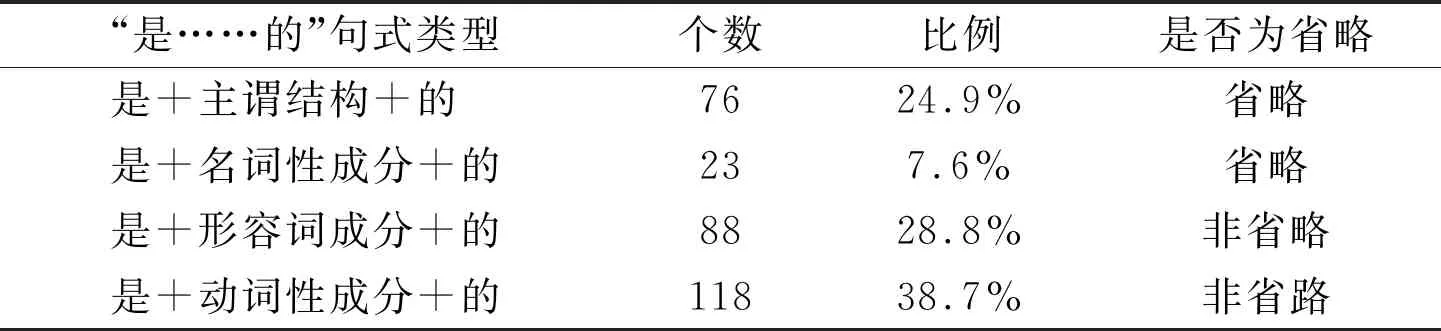
“是……的”句式类型个数比例是否为省略是+主谓结构+的 7624.9%省略是+名词性成分+的237.6%省略是+形容词成分+的8828.8%非省略是+动词性成分+的11838.7%非省路
每种类型的具体分析及词语序列的形式化模板描述如下:
1)是+主谓结构+的
该句式强调动作的施事,但当“是”前面仅为指示代词时,由于“是”与“的”之间缺少宾语,所以需要将其省略的宾语补充出来。补充信息多为整个句子的主语,在标注时需要将代词和前面的指代信息相关联,这样才能较为完整地表示句义。因此该类型为省略结构。词语序列基本模板:是+NN|NR|PN+{VV}+的。例如:
(6)这/PN 根本/AD 不/AD 是/VC印度/NR 想/VV 看到/VV的/DEC (事情)
2)是+名词性成分+的
此类型的“是……的”句式,名词性成分与主语的语义关系多为领属、解释关系。日常使用中我们为凸显焦点,经常将“的”后的从属类省略。在此类别中需要将主语的上位信息补充完整。因此该类型为省略结构。词语序列基本模板:是+{NN|NR|PN}+的。例如:
(7)楼主/NN 是/VC淮南/NR 矿业/NN 集团/NN的/DEG(人)吧/SP
3)是+形容词成分+的
这里的形容词性成分既可以为性质形容词,也可以是形容词短语。此句式中形容词性成分已承担谓词功能,因此不必增加省略信息。词语序列基本模板:是+{VA|JJ}+的。例如:
(8)绝大多数/CD 中国人/NN 都/AD 是/VC舒心/VA 愉悦/VA的/SP
4)是+动词性成分+的
这一类别在“是……的”句式中所占比例最高。这里的动词性成分一般是“能愿动词+动词”结构、“动词+可能补语”结构或动宾短语。由于动词性成分已出现且不缺少宾语,因此这类结构不需要在“的”字后增补内容,为非省略结构。词语序列基本模板:是+{VV}+[NN]+的。例如:
(9)许多/CD 事情/NN 原/AD 是/VC可/VV 避免/VV的/SP
本文将语料中的“是……的”句式,分为以上四种类型。若修饰语过长则采用缩减策略,将其修饰语成分归并再处理,再统一进行分类。表4为主要词语序列缩减策略的示例。
表4 缩减策略示例

缩减序列类型缩减前序列缩减后序列定中结构{JJ}+NNNN状中结构{AD}+VV数量结构CD+M+NNNN并列名词结构{NN}+CC+{NN}NN方位结构NN+LCNN
该类别的识别策略具体步骤如下:
步骤1:提取“是”“的”中间的词语序列,依据表4缩减策略对提取的词语序列进行缩减;
步骤2:将步骤1缩减后的词语序列进行字符串模式匹配,匹配到表2中的四种类型;
步骤3:根据步骤2得到的类型结果,判断“的”字结构是否为省略类型。
2.2.4 其他类型的识别策略
在去除“的”字下文特征及“是……的”特殊句式后,剩余的其他类型中,观察发现省略“的”所在短语的核心动词的必有论元成分必定是缺失的。如“的”字结构“当官员的”指代“当官员的人”,其中核心动词“当”的必有论元,即施事与受事没有全部出现。针对该类别本文利用动词框架,(2)动词框架(verb frame)指谓语动词所带核心论元结构。基于斯坦福依存分析结果和中文谓词库(Chinese Proposition Bank,以下简称CPB)的谓语动词框架词典识别“的”字所在短语的核心动词的论元结构,进而判断该结构是否含有语义省略成分。该词典含有每个谓词在不同义项下的语义角色框架,共收录24510个中文谓词(包括动词、形容词等)的26650个义项的不同语义角色框架(Xue 2008)。上例中,“当”在CPB中的动词框架为“Arg0:position holder;Arg1:position”。(3)CPB中使用Arg0,Arg1,Arg2,Arg3,Arg4五种论元表示动词的论元种类。该“的”字结构中“当”的必有论元仅出现了框架中的Arg1,而施事未出现,这也与上文中吕叔湘对“的”字结构中心语可省的条件描述相对应。因此可以认为,对比完整意义的“的”字结构,在带有省略语义性质的结构中,动词必有论元成分是不完整的。
不同于以上三类基于上下文共现的词语或词性序列模板匹配的识别策略,该类别的识别策略具体步骤如下:
步骤1:提取“的”字左边所有的动词在句中的位置,依次放入列表中;
步骤2:根据列表中内容,执行以下操作:
1)如果列表中仅存在一个位置元素,该位置的动词即为核心动词,则跳转至步骤3;
2)如果列表中存在多个位置元素,提取最后两个位置元素Windex1和Windex2,执行以下操作:
① 构造临时句子Snt:Windex1…… Windex2;
② 借助斯坦福依存分析工具,得到Snt中最后两个动词间的机标依存分析结果;
③ 根据②中机标结果,判断两个动词间的依存关系,并根据依存关系和动词在CPB中的论元(即后一个动词是否能做前一个动词必有论元成分)来确定后一个动词是否为核心动词:如果是,则利用依存结果为后一个动词补充主语或宾语,改造Snt并将原“的”字结构用新Snt替代,跳转至步骤3;如果不是,则将后一个动词的位置元素从列表中移除,跳转至步骤2。
这里我们就步骤2中若存在多个动词的“的”字结构时,核心动词的判断举例说明:
(10)而/AD 同样/AD应该/VV 申请/VV 世界/NN 纪录/NN 的/DEC,/PU 还/AD 有/VE 当地/NN 负责/VV 治安/NN 的/DEC 部门/NN
例(10)中,根据“的”字前的动词,从后向前构造Snt:应该 申请。Windex1是Snt中第一个动词“应该”位置元素,Windex2是Snt中第二个动词“申请”位置元素。根据构造的Snt调用斯坦福依存分析器,得到依存分析结果dobj(应该-1,申请-2)。在依存关系中dobj(direct object)表示直接宾语,即“申请”为“应该”的直接宾语,则后一个动词做前一个动词的必有论元成分,因此判断“申请”为该“的”字结构的核心动词。
步骤3:将核心动词的主宾语与其所在CPB中的最少论元数义项的论元结构匹配,若核心动词的主宾语与CPB中论元结构不匹配,即核心动词的主语或宾语缺失,则判断为省略;否则,判断为非省略。
3 识别省略“的”字结构实验
3.1 评价指标
省略“的”字结构识别任务可以看作是一个分类问题,普遍使用的性能评价指标是精确率(Precision,P),召回率(Recall,R),F1值(F1 score)。精确率是指正确判断出省略类别的“的”字结构数量占所有判断出省略类别的“的”字结构数量的比例,如公式(i)所示:
(i)
召回率是指正确判断出省略类别的“的”字结构数量占所有省略类别“的”字结构数量的比例,如下页公式(ii)所示:
(ii)
F1值(F1 Score,又称F1 Measure)是精确率和召回率的调和平均值,如公式(iii)所示:
(iii)
3.2 语料来源
本文基于的AMR表示方法,允许根据语义灵活增删概念节点。该方式通过 thing(物)、person(人)、location(地点)等概念节点的添加,对于省略“的”字结构,能够较为完整地补充出省略成分,弥补了传统句法表示的严重缺陷。图1给出AMR句子对于省略“的”字结构的示例。

图1 AMR概念补充省略“的”字结构示例
AMR将句中省略的概念“person(人)”补充出来,作为“开车”的arg0(施事),使省略“的”字结构的意义得到较为完整的表达,也体现出其对汉语省略结构语义表示的价值。
本文采用的语料为宾州中文树库 CTB8.0的10000句网络媒体语料,利用中文AMR的人工标注结果(4)目前CTB8.0的AMR语料标注数据已通过语言数据联盟(LDC)平台发布,由于本文使用早期版本,句子总数相差149句。语料下载地址https://catalog.ldc.upenn.edu/LDC2019T07。以及后期人工校对,抽取出含有增补概念节点的“的”字结构作为本文主要的研究对象。其中前5000句作为样本语料观察分析“的”上下文特征及规则制定,得到省略“的”字结构识别策略,后5000句作为测试集验证识别策略的效果。表5是CTB8.0分析和测试语料中所包含“的”字类型的基本情况。
表5 CTB“的”字语料数据集

语料省略实例非省略实例总数分析语料32049725292测试语料34461936537
3.3 实验与分析
3.3.1 实验步骤
步骤1:从样本分析语料中,提取所有“的”字结构。依据中文AMR人工标注结果,得到所有“的”字结构省略与非省略类别;
步骤2:将所有“的”字结构匹配到2.1节介绍的4种类型;
步骤3:对每个“的”字类型,根据2.2节介绍的基于规则的识别策略,形成机标结果;
步骤4:将机标语料与人工校对的语料即标准答案进行对比,对数据进行统计分析,评价规则之间的覆盖性,确定规则的处理顺序;
步骤5:在封闭集中,使用步骤1提取所有“的”字结构。按照步骤4确定的规则处理顺序,处理每个“的”字结构,得到机标结果。具体如下:1)遍历规则处理顺序,保留第一个和该“的”字结构匹配的类型;2)使用1)中该类型对应的识别策略处理该“的”字结构,判断该“的”字结构是否为省略类型;
步骤6:将机标语料与人工校对的标准答案进行对比,最终得到语义省略“的”字结构识别的精确率和召回率等指标结果。
3.3.2 规则处理顺序
本文根据“的”字结构的分类,旨在找到最有利于正确分类的处理顺序,判断具体哪一种类型需要优先处理,然后针对每种类型分别制定识别策略得到类型结果。即需要确定一个固定的遍历顺序对省略“的”字结构进行识别。考虑各规则之间的相互覆盖程度及各类用法在真实语料文本中的分布概率,规则描述清晰以及自动识别精确率较高的规则优先级别高,排在前面优先处理。
表6 单独抽取类别错误比例表

抽取类别的+名词|名词短语的+是是……的的+动词其他的+是0.0%/0.0%0.0%0.0%是……的97.2%0.0%/2.8%0.0%的+动词54.3%14.2%31.5%/0.0%其他4.0%0.0%96.0%0.0%/
表6为针对每种类型单独从样本分析语料中抽出属于该类型“的”,并列举采取了对应的策略得到的省略类型中错误分类比例。其中每一行是一种“的”字结构类型的处理结果,每一列是其错误分类的“的”字结构中其他类型的比例,旨在寻找是由于哪一种类型没有优先遍历而产生错误分类的比例。表6“的”字结构抽取类别中,单独列出“的+是”因为该类型识别策略的精确率高达98.2%,如果合并成“的+动词|是”,则会忽略其他动词的分析。其中,“的+动词”与“的+是”类型可通过“的”字下文词语或词性信息直接判断且精确率较高,因此优先处理这两类。此外,“是……的”对“其他”类型影响较大,因此将“是……的”置于“其他”类型之前处理。
综上,省略“的”字结构识别模型最优的类型处理顺序为:的+是→的+名词|名词短语→的+动词→“是……的”→其他类型。
3.3.3 实验结果
表7和表8是省略“的”字结构识别模型分别在封闭训练集和开放测试集上的效果。实验结果精确率及召回率均在85%以上,在测试集上整体F1值也达到87.1%,取得了较好的分类结果。
表7 省略“的”字结构识别级联模型封闭训练结果
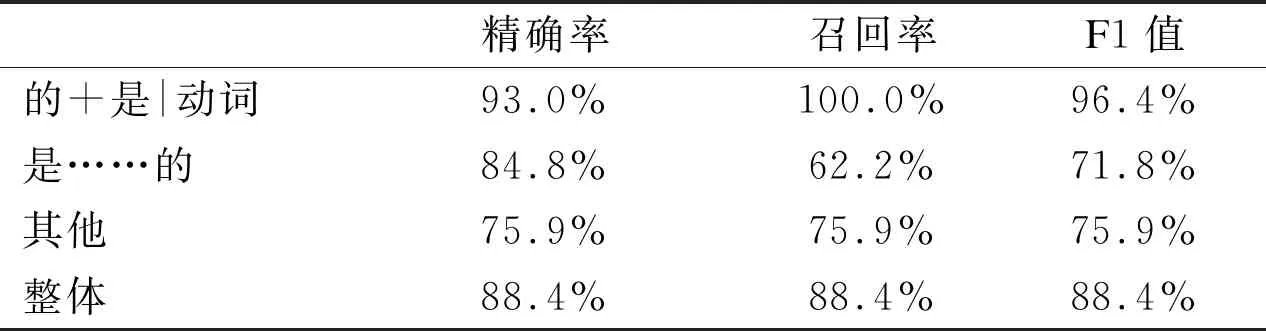
精确率召回率F1值的+是|动词93.0%100.0%96.4%是……的84.8%62.2%71.8%其他75.9%75.9%75.9%整体88.4%88.4%88.4%
表8 省略“的”字结构识别级联模型开放测试结果
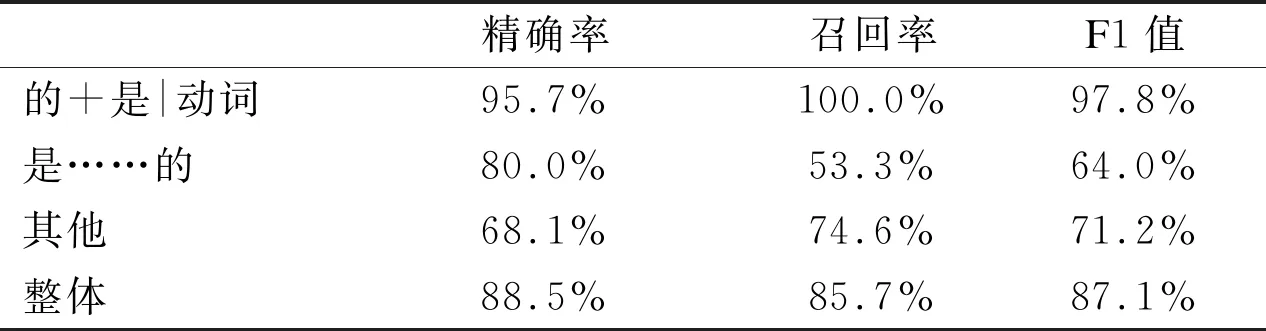
精确率召回率F1值的+是|动词95.7%100.0%97.8%是……的80.0%53.3%64.0%其他68.1%74.6%71.2%整体88.5%85.7%87.1%
为了解不同建模方法对于省略“的”字结构识别任务的优劣,本文基于条件随机场(Conditional Random Field,CRF)模型对同一任务进行对比实验。CRF作为一种判别式的概率无向图模型,是在给定一组输入随机变量条件下,输出随机变量的条件概率分布模型。它结合最大熵模型和隐马尔科夫模型的特点,在词性标注和命名实体识别等自然语言处理任务中得到广泛应用。本文提取当前词、词性及前后两个词和词性等上下文语境作为省略“的”字结构识别特征。为便于和基于规则的级联模型对比,CRF模型以相同数据集进行训练与测试。两种识别方法的对比测试结果如表9所示。
表9 省略“的”字结构识别级联模型及CRF模型对比测试结果

精确率召回率F1值CRF模型82.6%76.2%79.3%级联模型88.5%85.7%87.1%
从表9可以看出,基于规则的方法实验效果明显优于基于统计的CRF模型,且基于统计的方法对数据需求比较高,即在大规模语料上表现要优于小数据集。但从表5实验数据及真实语料来看,省略与非省略“的”字结构数量悬殊,相较于非省略类型,省略“的”字结构在训练和测试语料的出现频率较低,因此在类别不均衡的数据集上基于统计的方法效果并不理想。基于规则的方法虽然在精确率上结果较好,但召回率在一定程度上受到规则适用限制的影响,在“是……的”类型和“其他”类型的“的”字结构识别上表现较差。即便如此,从整体结果来看,在现有同等规模数据集下,基于规则的级联模型F1值超过CRF模型7.8%,优势还是较为明显。
综上,基于规则的级联模型和基于统计的CRF模型在省略“的”字结构识别任务中各有优劣。但从现有数据规模及实验结果来看,基于规则的级联模型拥有更好的实验效果,更适用于省略“的”字结构识别任务。
3.3.4 错误分析
通过对实验中172个错误实例进行分析,发现其中特殊句式依存分析的错误所占比例较大,如宾语前置句、定语后置句等。
一般在口语使用中,当说话者有意强调宾语时,会将宾语前置,形成宾语+主语+谓语的语序。例如:
(11)吃住/NN 不/AD 花钱/VV ,/PU午饭/NN 单位/NN 负责/VV 的/SP
例(11)的正常语序为“单位负责午饭”,但语料中说话者将宾语“午饭”放在主语“单位”之前,形成宾语前置句。对于此类句子,现有基于依存分析的方法无法正确识别各成分间的句法关系,只能将核心谓词“负责”的论元结构施事定位到“单位”,而受事则为空,因此造成了省略判断的错误。
此外,对于一些定语后置的“的”字结构用法,可将其理解为“中心语在前关系小句在后”的一种古已有之的汉语句法结构在现代汉语中的延续。例如:
(12)法律/NN 上/LC 有/VE 规定/NN ,/PU 对于/P终身/NN 伤害/NN 非/VC 一次性/AD 能/VV 赔清/VV 的/DEC,/PU 以后/NT 在/P 需要/VV 时/LC 还/AD 可/VV 继续/VV 提出/VV 索赔/NN
(13)故意/AD 伤害/VV 他人/PN 身体/NN 致/VV 人/NN 重伤/VV 的/DEC,/PU 处/VV 三/CD 年/M 以上/LC 十/CD 年/M 以下/LC 有期/JJ 徒刑/NN
对于这种定语后置句造成的省略结构,由于其结构复杂经常会判断错误,但其所在的文本类型比较集中,多为法律文书,后期我们针对这类文体的“的”字结构进行单独分析和处理。
4 结语
本文通过对“的”字结构的分析,对比省略与非省略“的”字结构在句法和语义上的差异,结合上下文词性信息和动词框架下论元结构匹配的判断方法,能够较为准确地识别出带有语义省略的“的”字结构。
在接下来的工作中,我们会进一步研究各类文本中复杂的定语后置“的”字结构及特殊句式,引入特征模板或其他语义语法资源来提高识别性能。另外针对省略“的”字结构对其缺省的信息进行补全,并尝试将补全的“的”字结构用于语义自动解析等工作中。
猜你喜欢
通信技术(2021年12期)2022-01-25
汉字汉语研究(2020年1期)2020-04-21
诗选刊(2015年6期)2015-10-26
知识窗(2015年1期)2015-05-14
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
Beijing Review(2012年37期)2012-10-16
诗歌月刊(2009年4期)2009-05-22
杂文选刊(2008年2期)2008-05-14
