
基于英语翻译应用视角下的计算机智能校对系统开发研究
2020-05-11 11:44孙瑞
微型电脑应用 2020年2期
关键词:英语翻译


摘 要: 随着人工智能等计算机相关技术的发展,利用计算机进行英语翻译工作也逐渐成为研究方向之一,受限于算法及匹配度等因素影响,英语翻译仍存在瓶颈。因此,提出了基于英语翻译应用视角的计算机智能校对模型并进行开发研究,该模型能够在单词级别上直接整合附加注释——包括语言标记或自动生成的单词类。基于此模型的实验表明,基于英语翻译应用视角下的计算机智能校对模型可以在自动得分和更多语法连贯性方面带来更好的翻译表现,最后还从硬件、软件两方面探讨了计算机智能校对系统开发。
关键词: 英语翻译; 智能校对; 训练样本
中图分类号: TP311 文献标志码: A
Research on the Development of Computer Intelligent Proofreading System
Based on the Perspective of English Translation Application
SUN Rui
(Xian Innovation College, Yanan University, Xian 710100)
Abstract: With the development of computer-related technologies such as artificial intelligence, the use of computers for English translation has gradually become one of the research directions. Due to factors such as algorithm and matching degree, English translation still has bottlenecks. Therefore, this paper proposes a computer intelligent proofing model based on the perspective of English translation application and conducts research and development. This model can directly integrate additional annotations at the word level, including language markers or automatically generated word classes. Experiments based on this model show that the computer intelligent proofing model based on the perspective of English translation application can bring better translation performance in terms of automatic score and more grammatical coherence. Finally, the development of computer intelligent proofreading system is discussed from both hardware and software aspects.
Key words: English translation; Intelligent proofreading; Training samples
0 前言
随着人工智能等计算机相关技术的发展,利用计算机进行英语翻译工作也逐渐成为研究方向之一[1、2]。当前最先进的计算机机器翻译方法,即所谓基于短语的模型,但仅限于小文本块的映射,由于没有明确使用语言信息,可能是形态学、句法或语义。通过将其集成到预处理或后处理步骤中,已经证明这些附加信息是有价值的[3-5]。一般而言出于两类原因,需要将语言信息更紧密地整合到翻译模型中:以更一般表示形式操作的翻译模型,例如词条而不是表面形式的词,可以利用更丰富的统计数据并克服由有限的训练样本引起的数据稀疏性问题,翻译的许多方面可以在形态学、句法或语义层面上得到最好的解释[6]。将这些信息提供给翻译模型可以直接建模这些方面,例如:句子级别的重新排序主要由一般句法原则驱动,局部协议约束在形态学中出现等,然而这些翻译却只能针对短语有效[7]。许多学者已经进行了许多尝试以向统计机器翻译模型添加更丰富的信息,其中大部分都集中在对统计系统的输入进行预处理或对其输出进行后处理[8、9]。因而我们将基于短语的方法扩展到统计翻译,提出了基于英语翻译应用视角下的计算机智能校对模型,该模型允许在单词级别进行额外注释,在框架中的一个词不仅是一个标记,而是一个代表不同注释级别的因子向量如图1所示。
丰富的形态通常对统计机器翻译构成挑战,因为源自相同引理的多种单词形式将数据分段并导致稀疏的数据问题。如果输入语言在形态上比输出語言更丰富,那么在将输入传递到翻译系统之前,它有助于在预处理步骤中对输入进行干扰或分段[10、11]。
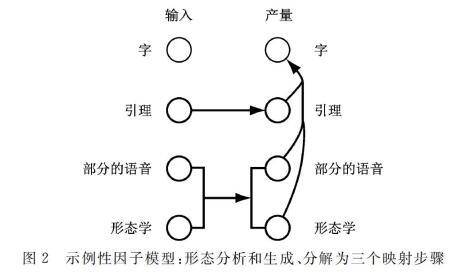
本文描述了因式转换模型的动机、建模方面和计算有效的解码方法,并简要介绍了许多语言对的结果。统计机器翻译中的缺点是形态学处理不当,每个单词形式在其中被视为一个标记[12-13]。这意味着翻译模型会将单词“house”视为完全独立于单词house,样本数据中的任何房屋实例都不会为房屋的翻译增加任何知识。在极端情况下,虽然房屋的翻译可能是模型已知的,但房屋可能是未知的,系统将无法翻译它。虽然这个问题在英语中没有显示出来——由于英语形态学上的变形非常有限,但它确实构成了形态丰富的语言,如阿拉伯语、德语、捷克语等的重大问题[1]。因而,可以在引理水平上对形态丰富的语言之间的翻译进行建模,从而汇集来自共同引理的不同单词形式的证据。在这样的模型中,我们引入了因式转换模型分别翻译引理和形态信息,并在输出端组合这些信息以最终生成输出表面词,如图2所示。
2 基于英语翻译应用视角下的计算机智能校对模型 基于英语翻译应用视角下的计算机智能校对模型(Computer Intelligent Proofing,简称CIP模型)严格遵循基于短语的模型的统计建模方法,主要区别在于样本数据的准备和从数据中学习的模型类型。
2.1 翻译分解
将输入词的因式表示转换为输出词的因式表示被分解为一系列映射步骤,这些步骤将输入因子转换为输出因子,或者从现有输出因子生成额外的输出因子。在本模型中,转换过程分为以下3个映射步骤:1、将输入引理转换为输出引理;2、翻译形态和POS因素;3、根据引理和语言因素生成表面形式[2]。分解的翻译模型建立在基于短语方法的基础上,该方法将句子的翻译分解为小文本块(所谓的短语)的翻译,如图3所示。
2.2 样本训练
首先,训练数据须用其他因素注释,会涉及在语料库上运行自动工具,因为手动注释的语料库很少且生产成本很高。其次,需要为并行训练中的所有句子建立一个单词匹配机制,单词对齐方法可以对单词的表面形式或任何其他因素进行操作。再者,每个映射步骤都构成整个模型的一个组成
部分,从训练的角度来看,这需要从单词对齐的平行语料库中学习翻译和生成表,并定义评分方法,帮助用户在模糊映射之间进行选择。
2.3 组件组合
与基于短语的模型一样,CIP模型可以将因式分析模型视为几个组件的组合,这些组件定义了一个或多个在对数线性模型中组合的要素函数[3]如式(1)。pef=12exp∑ni=1λihie,f
(1) Z是在实践中被忽略的归一化常数,为了计算给定输入句子f的翻译概率,必须评估每个特征函数hi,如式(2)。hLMe,f=pLMe=
pe1pe2e1..pemem-1
(2) 需要考虑由语言模型翻译和生成步骤引入的特征函数,输入句子f到输出句子e的翻译分解为一组短语翻译j,j。
对于翻译步骤组件,给定评分函数τ,在短语对j,j上定义每个特征函数hT如式(3)。hTe,f=∑jτj,j
(3) 对于生成步骤组件,给定评分函数γ的每个特征函数hG仅在输出字ek上定义如式(4)。hGe,f=∑kγek
(4)2.4 高效解码
CIP模型将短语翻译分解为若干映射步骤会产生额外的计算复杂性。在基于短语的模型中,很容易识别短语表中可用于特定输入句子的条目。波束搜索解码算法以空假设开始,通过使用所有适用的翻译选项生成新假设,以相同的方式产生进一步的假设,依此类推,直到创建覆盖整个输入句子的假设,最高得分完全假设表示根据模型的最佳翻译[4]。
由于所有映射步骤对相同的短语分段进行操作,可以在启发式波束搜索之前有效地预先计算这些映射步骤的扩展,并将其存储为转换选项。
在给定映射步骤的情况下,需要注意转换数量的组合过量,可能会创建太多的翻译选项来处理。目前通过早期筛选扩展来解决这个问题,并且默认情况下将每个输入短语的翻译选项数量限制为最大数量,然而,这并不能完全解决选项过多的问题。
3 实验与系统开发
3.1 语法输出
在第一组实验中,翻译单词的表面形式并从中生成额外的输出因子(见图4),通过添加形态学和浅层句法信息,使用高阶序列模型使得句法连贯,结果如表1[3-6]所示。
(1) 英语——德语系统在完整的751 088句Europarl语料库上进行了训练,在输出端添加词性和形态因子并进行微小改进,因子模型将长度≥3的名词短语中的不一致误差从15%减少到4%。
(2) 英语——西班牙语系统在Europarl语料库的40 000个句子子集上进行了训练,使用序列模型在输出端使用形态学和词性因子,导致仅变形和变形+POS的绝对改善。
(3) 英语——捷克系统接受了华尔街日报20 000句的训练,表明添加所有特征会导致较低的表现(27.04%),所有模型的得分远高于BLEU 25.82%的基线。
3.2 形态分析与生成
本文使用52 185句新闻评论语料库对语言对德语—英语进行了实验。实验结果表明使用词性语言模型时的改进——BLEU评分从18.19%增加到19.05%。从表面单词翻译映射转向引理/形态映射会导致性能下降至BLEU得分为14.46%[10、11],如表2所示。
替代路径模型优于+POS LM的表面形式模型,BLEU得分为19.47%,该测试集具有3 276个未知单词形式与2 589个未知单词形式。因此,引理/变形模型能够翻译687个附加单词。
3.3 使用自动Word类
最后,通过将词语通过其上下文相似性聚集在一起,能够找到可能导致更通用的模型统计相似性。在IWSLT 2006任务上训练了模型,在输出侧添加词类作为附加因子(如图4所示)。
通过分解翻译模型,可以通过添加生成步骤将此步骤集成到模型中。综合评估模型的表现优于标准方法,BLEU评分为21.08%至20.65%,如表3所示。
3.4 系统的开发
3.4.1 系统架构
此研究英語翻译计算机智能校对系统架构设计图5中的5大模块共同组成了该校对系统主要结构部分,如图5所示。
图5中的5大模块在进行英语翻译校对过程中形成的工作行为数据,通过工作日记模板记录下来的,然后这些记录就是为后台工程师查看系统工作状况提供了真实的依据,从而为他们研究本系统工作过程存在的问题,制订有针对性,且有效的处理措施提供了便利,最后达到优化校对系统的目的。
用户模块主要为用户提供登陆、搜索、查询等服务的模块;翻译校对模块顾名思义就是对英语翻译模块翻译的结果进行校对;搜索模块主要对语句中词汇特点进行分析与选择;工作模块的功能就是立足于英语翻译智能校的基础之上,对英语翻译智能校对进行及时完成。工作模块接收到校对命令之后,它就会接收到来自翻译模块的搜索链接,英语翻译模块依据分析等待校对语句的各个词汇特点,依据它的相似度把翻译结果进行排序,最后从中选出最符合实际的翻译结果。那么用户就能够在用户模块就能查寻到相应译文结果[11]。
3.4.2 硬件设计
(1) 关于搜索模块设计。 搜索模块在接收到用户登陆系统提供的信息时,立即对有相关词汇进行处理与特点搜索等方面工作。此模块为了完成此操作,通过建立映射线程方式,获取等待校对词汇实际意义,以及搜索学科内容,从而为即将校对的词汇的特点提取奠定基础。此映射线程是属于一对多模式的线程,等待校对词汇的学科内容包括线程上的全部映射点,与学科内容非常接近的学科也将含括了少数映射特点。这种能够保障在可能接近答案的出现在搜索范围之内,户由于其表达过错而导致搜寻结果的错误率大大减少。
(2) 行为日志设计。行为日志主要是对用户在使用该校对系统时,所发生的各种行为,以数据展现出来的记录。倘若用户第二次使用此系统时,行为日志就会对用户使用的足迹出现了记录。倘若用户对同一类英语翻译产生了多次校对,系统就能够智能地增添词汇翻译范围。就能够搜索到更多用户可能所需要的结果,以此来提升系统的校对性能,从而使得该智能校对系统的精准性得到提升。
3.4.3 软件设计
英语翻译与英语翻译校对两者共同之处,就是通过一种方式的文本向另一种方式文本转换。所以,英语翻译计算机智能校对过程,从本质上而言,就是对没有翻译的语句进行翻译的过程。把校对的结果与刚开始翻译的结果进行对比与更换,从而实现英语的翻译的智能校对。
此文中英语翻译错误的结果用H来进行表示,而正确的英文翻译结果是由来表示,由H向转变就是英语翻译的整个过程。优化短语翻译模型的英语机器翻译措施如式(5)。=arg max M(D|H)=arg max M(M|D)×M(D)
(5) 英语机器翻译的措施所取得的结果中的词汇翻译精确度还是有所欠缺,而采用智能英语翻译措施就对其词汇翻译精准度比较重视。也就是(5)式中的M(D)精准度。因此对(5)进行优化的基础实现计算机智能校对;此外还有从优化短语翻译模型的计算机智能化校对措施所对应的伪代码来实施代码校对[12]。由于篇幅关系,其实施的详细方法,笔者在此就不再展开论述。在英语翻译智能化校对过程中,最重要的就探寻适合划分等待校对词汇的H措施,对划分结果进行一个一个校对,从而获得排列成D顺序的校对结果。
4 总结
总之,本文采取短语模型的统计建模方法设计了一款新型智能化英语翻译校对系统。文章首先从翻译分解、样本训练、组件组合、高效解码等方面方分析英语翻译应用视角下的计算机智能校对模型;接着对其进行语法丰富输出实验,实验结果表在自动分数(BLEU高达2%的增益)方面,以及语法一致性的衡量标准,CIP模型都有所增加。因而说明在分解翻译模型的框架内,可以成功地利用附加信息来克服当前主导的基于短语的统计方法的一些缺点;最后从系统架构、系统硬件、以及软件等方面简要了分析系统设计过程。
参考文献
[1] 马云彤. 基于Android和iOS移动终端的作者远程校对方法[J]. 中国科技期刊研究, 2015, 26(2):180-184.
[2] 程显毅, 孙萍, 朱倩. 基于HNC的中文文本校对系统模型的研究[J]. 微电子学与计算机, 2009, 26(10):49-52.
[3] 李春兰. 英语口语自动发音校对系统设计[J]. 现代电子技术, 2017, 40(24):59-61
[4] 基于统计翻译框架的蒙古文自动拼写校对方法[J]. 中文信息学报, 2013, 27(6):175-180.
[5] Haehn D, Knowles-Barley S, Roberts M, et al. Design and Evaluation of Interactive Proofreading Tools for Connectomics[J]. Visualization & Computer Graphics IEEE Transactions on, 2014, 20(12):2466-2475.
[6] Aiawami A K, Beyer J, Haehn D, et al. NeuroBlocks-Visual Tracking of Segmentation and Proofreading for Large Connectomics Projects[J]. IEEE Transactions on Visualization & Computer Graphics, 2015, 22(1):738-746.
[7] Chan A H, Tsang S N, Ng A W. Effects of Line Length, Line Spacing, and Line Number on Proofreading Performance and Scrolling of Chinese Text[J]. Journal of the Human Factors & Ergonomics Society, 2014, 56(3):521-534.
[8] 王文辉,吴敏华,骆力明,等.基于相似度算法英语智能问答系统设计与实现[J].计算机应用与软件,2017,34(6):62-68.
[9] 斯·劳格勞.蒙古语固定短语识别算法的设计与实现[J]. 中文信息学报,2017,31(5):1316-1320.
[10] 李业刚,梁丽君,孙福振,等.融入双语最大名词短语的机器翻译模型[J].计算机应用研究,2017,34(5):1316-1320.
罗滔.试论英汉语言差异对英语笔译的影响及翻译策略[J].鄂州大学学报,2004(20):64-65.
[11] 朱丽云,徐静娴.中华文化负载词翻译研究——基于2013—2018年全国大学英语四级段落翻译题的分析[J].英语教师,2019():67-69.
[12] 王茹.英汉翻译中的插入语翻译策略——以《自尊心理学》的汉译为例[D].北京:北京外国语大学,2018.
(收稿日期: 2019.06.24)
作者简介:孙瑞(1983-),女,榆林人,硕士,讲师,研究方向:机器翻译等。文章编号:1007-757X(2020)02-0145-04
猜你喜欢
速读·中旬(2021年5期)2021-07-28
现代职业教育·高职高专(2020年44期)2020-04-26
新闻爱好者(2020年1期)2020-04-13
校园英语·上旬(2019年9期)2019-09-16
现代职业教育·高职高专(2019年1期)2019-06-11
旅游纵览·行业版(2018年11期)2018-12-21
广东教育·职教版(2018年8期)2018-10-09
现代职业教育·高职高专(2018年10期)2018-05-14
现代职业教育·中职中专(2018年7期)2018-05-14
现代职业教育·中职中专(2018年2期)2018-05-14
