
基于图像语义分割的物体位姿估计
2020-04-24 10:56王宪伦张海洲安立雄
机械制造与自动化 2020年2期
王宪伦,张海洲,安立雄
(青岛科技大学 机电工程学院,山东 青岛 266042)
0 引言
随着机器人技术、计算机视觉与人工智能技术的发展,复杂场景下的物体识别与姿态估计问题逐渐成为机器视觉领域研究的重点。对于三维物体的识别最早出现在20世纪50年代。开始的研究者主要探索单一背景的物体识别,并将此问题叫做“积木世界”问题。ROBERTS提出了一套针对此问题的识别方案,将多面体分为多个部件进行识别[1]。但是此模型对于真实世界做了过分的简化,因此对于曲面较多的物体难以适用。BOLLES开发出一种面向三维工件的识别方案,根据工件的CAD模型,在工件的顶点、边、面、体之间建立拓扑关系,通过图匹配的方法实现工件的识别[2]。CHEN开发了一种以不同视角的图像建立物体立体模型的方法,在图像匹配的过程中使用方向、轮廓等信息,进行识别定位[3]。近年来,针对此问题的解决方案大多是以点云数据为基础。首先是离线采集点云数据,通过分割算法进行点云聚类[4],计算点云的特征描述子,获得物体的最小包围盒[5],实现对目标物体的识别与定位。国内外许多科研机构在这方面都取得了较好的成果,例如:Willow Garage公司PR2机器人、中国科技大学的“可佳”机器人等。但是随着深度学习的普及,尤其是卷积神经网络[6]在图像分类取得突破之后,深度学习也开始应用于图像语义分割,所以对比之前的解决方案使用的3D点云数据,现在只需要通过对2D图像进行语义分割便可以实现对图像分割与分类,大大加速了物体的识别过程。
本研究设计的基于图像语义分割技术的物体姿态估计算法,它的最终目标是实现复杂场景下目标物体的识别与定位,依靠Kinect视觉传感器拍摄场景RGB图像与深度图,利用全卷神经网络[7]实现RGB图像语义分割,将分割后的目标图像与深度图配准得到点云图,最后利用迭代最近点[8]算法将目标点云图与模型库中已有的目标模型进行配准,最终实现物体的识别与位姿估计。
1 物体识别与位姿估计算法
物体识别与位姿估计算法主要包括基于图像语义分割技术的物体识别与位姿估计两部分。
1.1 物体识别
图像语义分割属于图像理解的范畴。语义分割要求将图中的每一个像素点分割并标注为某个物体类别(图1)。

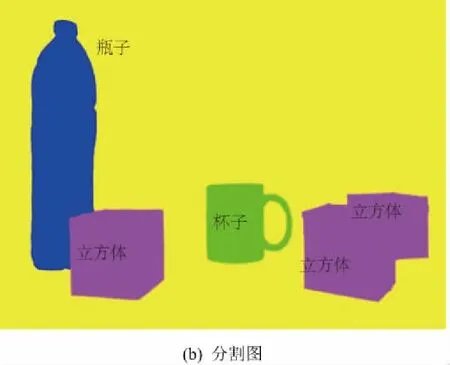
图1 场景原图与分割图
本文采用的语义分割网络是FCN(全卷积神经网络),通过改进主流的深度卷积神经网络在数据集上训练,以RGB图像为输入,然后输出图像的像素语义分割图,实现像素级别端对端的分割。在语义分割网络的设计中输出的语义分割图像需要与输入的图像有相同的尺寸,但是在做图像分类的网络模型中使用了多个卷积层与池化层,在经过多次的卷积与池化操作之后会让原始输入的图像尺寸越来越小,所以为了得到与输入图像尺寸一致的输出,必须进行反卷积[9]操作。
整个语义分割网络的设计架构以分类效果较好的ResNet[10](深度残差网络)为基础。ResNet的产生是为了解决随着网络深度不断增加而出现梯度消失或者梯度爆炸的问题。形式上,输入的数据表示为x,将期望的底层映射表示为H(x),将堆叠的非线性层拟合后的映射为F(x)。传统的卷积网络直接以F(x)作为下一层的输入,但是随着网络深度不断增加会使梯度变得越来越小,丢失更多的原始信息。所以ResNet以H(x)=F(x)+x作为下一层的输入,使网络深度可以达到较深的层数,从而使训练模型对于输出与输入的微小波动更加敏感,最终的分类效果更好。
语义分割网络为了获得更好的分割效果,选择以ResNet为基础,去掉原网络的全局池化层,因为全局池化层会丢失图像的空间信息,然后将全连接层替换为核尺寸为1的卷积层,最后一层接入一个卷积转置层,使网络的输出等于输入尺寸。输出的图像中可以将不同类别的物体以不同颜色表示出来,并且将实现不同物体之间的分割。整体网络设计架构示意图见图2。

图2 语义分割网络设计图
1.2 位姿估计
位姿估计部分主要分为两部分,第一部分是目标点云的获得,第二部分是将目标点云模型库中目标的点云配准,求取物体位姿。
目标点云的获得主要依赖于RGBD传感器的成像模型。在不考虑镜头畸变的情况下,摄像机的成像模型为小孔成像,如图3所示。空间中的点坐标为P=[x,y,z]与其在图像成像平面上坐标p=[u,v]满足如下关系:u=(x·f)/z,v=(y·f)/z,其中f为Kinect视觉传感器的焦距。深度图中的每一个像素的值d(u,v)保存了场景中的点到镜头中心的距离。通过标定[11],可以将彩色图与深度图的各个像素一一对应起来,实现彩色图像中像素点到空间中三维坐标的映射:
(1)
其中cx、cy为摄像机光心坐标。将分割出来的目标物体的彩色图与深度图对齐之后便可以得到其点云图。

图3 摄像机成像模型
点云配准过程一般分为两个阶段:第一阶段为粗配准,使得目标点云与模型库中模型之间位姿差距最大可能地减小,达到大致的重合状态;第二阶段为精配准,其目的是通过精确的配准算法使得目标点云与模型库中点云达到最佳的重合状态。
设P={Pi}Ni=1,Q={Qi}Ni=1为两个点云集,P是上文中获得的目标点云,Q是模型库中对应的模型点云。粗对准算法步骤如下:
首先计算点云P和Q的协方差矩阵Cp和Cq:
(2)
(3)

(4)
(5)
其中:UP是点云P的特征向量,Uq是点云Q的特征向量。
则点云P和Q之间的旋转矩阵R和平移向量T为:
R=UpUq-1
(6)
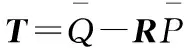
(7)
R和T便是点云粗匹配的结果。

算法建立如下损失函数:
(8)
其中:R(q)表示旋转矩阵;T(q)为平移向量。求解式(8),使其值最小。
初始迭代时,令目标点云的初始位置为P0,刚体变换向量为m,迭代次数k=0。迭代执行步骤如下:
1) 寻找对应点集:计算点云集P的最近点集合为Q,Q=C(P,X),其中C为搜索最近点操纵;
2) 计算配准参数:按照粗对准算法计算两个点云集之间的R、T;
3) 将配准参数作用到P0得到新的位置:Pk+1=qk(P0);
4) 若相邻两次迭代求得的误差dk小于给定的阈值t,即dk-dk+1 最终通过目标点云与模型库中模型点云的精配准得到目标点云的旋转矩阵R与平移向量T,即目标物体的位姿。 为了加速精确配准中两块点云的对应点对匹配,本文采用Kd-tree[12]近邻搜索算法进行加速。Kd-tree是对于高维数据中的快速最近临查找算法,其本质是一种二分查找树,被ZHANG等[13]第一次运用到ICP算法中。对于点云数据来说,Kd-tree中存储的是三维数据,Kd-tree的建立过程就是对三维空间的一个划分过程,实际运用中,建立过程如下: 1) 计算三个维度中各个维度上的数据方差,将最大方差的维度定义为划分轴。 2) 在划分轴上计算中值作为临界值,将全部的三维空间分为两份。同时创建一个结点,用于存储划分的维度与划分值。 3) 将三维数据在划分轴的维度上与临界值进行对比,小于临界值的数据归为左子树,大于临界值的数据归为右子树。 4) 对左右两棵子树循环进行步骤1)到步骤3),直到全部的子集合都不能再划分,并将该数据保存为叶子节点。 Kd-tree为点云数据建立了一个快速查找的拓扑结构,加速了点云的匹配点查找过程。 整个实验主要分为两步,第一步是基于图像语义分割技术的目标物体分割,第二步是物体位姿的估计。因为第一步的图像分割质量对位姿估计结果影响较大,所以首先对第一步的分割质量做了明确的评价。 实验环境采用MXNet[14]平台搭建网络,MXNet是Amazon旗下的深度学习框架。实验硬件配置如下:CPU为Intel(R)i5-8600K,GPU为GeForce GTX1070Ti,操作系统为Window10。 本次实验采用PASCAL challenge[15]目标检测评价体系中提出的评价标准IoU(intersection over union)。此标准是计算预测值与真值的交集和预测值与真值并集的比值。交并比的定义如下: (9) 其中:GT是真实的目标物体分割图的像素区域;DR是预测的目标物体分割图的像素区域,如图4、图5所示。 图4 DR区 图5 GT区 本文采用的数据集是自建数据集,其格式按照PASCAL VOC2012格式建立,其中涉及6种类别,分别为“motor”、“ruler”、“box”、“mouse”、“cola”和“ball”。原始数据集包括1 000张,其中400张用于训练,600张用于模型测试。 在对目标网络进行训练时,模型训练的超参数设置如下:基础学习率为0.001,学习率的变化率为0.1,最大迭代次数为20 000,步长为3 000。 在Windows下目标检测速度为0.978秒/张。算法结果在数据集上的IoU值最终为82.26%。目标检测实验结果如图6所示。 从图6可以看出,原来场景中5种物品全部被分割出来,并且以不同的颜色代表不同的物体,从而实现了物体识别的功能。把可乐作为目标物,将可乐提取出来,与深度图配准,得到可乐的点云图(图7)。 图6 目标检测实验结果 图7 目标点云图 将获得的目标点云图与模型库中可乐模型运用基于ICP算法的点云匹配方法进行位姿计算,可以得到目标物体准确位姿。 为了评价最终位姿估计的精度,引入机械臂作为结果量化工具。具体操作方法是:通过算法计算出一组位姿数据,并且转换到机器人坐标系下,同时人工操作机械臂到达实际物体的位姿位置,记录下一组位姿数据(表1)。数据格式为x、y、z、α、β、γ,距离单位为mm,角度单位为(°)。 实验结果分析,算法平均误差为3.96mm、1.59mm、2.64mm、2.35°、1.7°、4.15°。通过以上数据可以看出位姿估计基本可以满足机器人对于可乐、水杯类似物体的抓取,具有一定的应用性。 表1 8组算法与实际测量的误差对比 本研究提出的基于语义分割的物体位姿估计算法得到了实验验证,实验结果表明此方法可以实现复杂场景下目标物体的识别以及位姿估计,可以达到实际应用的要求,并为以后的研究提供了重要参考依据。 在下一阶段,本研究将会把此算法应用到机械臂抓取的实验中,将此算法与机械臂联合使用完成目标物体识别抓取的工作。由于此算法并未达到100%的物体识别率,所以在高精度的应用场景中无法使用,因此在今后的研究中,可能需要进一步改进基于语义分割的物体识别方法,减少实验误差,以实现高精度作业。2 实验结果与分析







3 结语
猜你喜欢
光学精密工程(2022年22期)2022-11-28
中原商报·科教研究(2021年4期)2021-03-03
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
开放教育研究(2020年2期)2020-03-31
电子技术与软件工程(2019年6期)2019-04-26
中国科技纵横(2017年1期)2017-03-10
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
湘潭大学学报(哲学社会科学版)(2015年5期)2015-11-25
