
一种基于YOLOv3的汽车底部危险目标检测算法
2020-04-09 05:47高春艳赵文辉张明路孟宪春
天津大学学报(自然科学与工程技术版) 2020年4期
高春艳,赵文辉,张明路,孟宪春
(河北工业大学机械工程学院,天津 300130)
车底危险品藏匿由于隐蔽性强、检查难度大、漏检情况多等特点,容易造成重大伤害.近年来,世界各国出于国际反恐、公共安全等多方面考虑,将车底安检技术及装置的研究上升到国家发展战略的高度.
当前探测手段主要采用图像识别,通过对汽车进行快速扫描、成像,然后与原数据库中存储的底盘图像进行比对,检查有否增加可疑物品.实践证明,采用彩色图像车底安检系统是行之有效的防护措施,此类系统中,目标检测及识别是核心问题.
车底检测装置一般设置在道路卡口、封闭场所进出口,为提高车辆通过速率,所以对检测的快速性有一定要求.传统目标检测技术通过模板匹配[1]、SIFT(scale-invariant feature transform)特征提取[2]等技术获取目标特征,然后利用 SVM(support vector machine)[3]等机器学习方法进行分类,从而检测识别目标.但是由于车底危险目标相对整幅车底图像较小,利用传统目标检测方法一般检测准确率较低,检测速度较慢,有待改进.基于此,本文采用深度学习目标检测方法,通过改进YOLOv3网络框架,对车底复杂背景下的多类危险品目标进行了检测和验证.
1 基于深度学习的目标检测方法
2014年,Girshick等[4]开创性地提出了结合区域推荐方法的 R-CNN(regions with CNN features)算法,其在VOC2007数据集上测试的mAP(mean average precision)值达到 53.3%.随后在 2015年,Girshick结合SPPNet(spatial pyramid pooling convolutional networks)[5]的特点,提出了 Fast R-CNN[6].在2016年,Girshick又采用区域提议网络 RPN(region proposal network)提出了Faster R-CNN网络[7],从而产生几乎无代价的区域推荐.2016年,Redmon等[8]提出了YOLO(you only look once)网络,这是一个端到端的网络结构,其不同于 R-CNN把分类用在检测的设计思路,而是将目标检测看作回归模型.随后在2017年,Redmon等[9]借鉴 Faster RCNN 的 anchor,并利用聚类算法代替手工提取 anchor尺度,将网络改进成YOLOv2,该网络还通过增加batch normalization层,使用多尺度高分辨率图像进行训练和微调等手段将网络在VOC2007数据集上的测试mAP值从63.4%提升到了 78.6%.2018年,Redmon等[10]借鉴ResNet的残差思想将网络加深成Darknet-53,并利用多尺度特征提取改进出 YOLOv3.此外还经常使用在多尺度特征图的每个位置使用不同长宽比的缺省框建立的单次检测器SSD(single shot multibox detector)[11]等.
2 YOLOv3网络
2.1 YOLOv3模型
YOLOv3采用了称之为 Darknet-53的网络结构.它借鉴了ResNet(residual neural network)的做法设置残差单元,将网络加深成 53个卷积层.为了能够检测细粒度特征,其在YOLOv2的passthrough结构基础上,更进一步采用了3个不同尺度的特征图进行对象检测;YOLOv3仍沿用 YOLOv2的方法采取K-means聚类[12]得到 anchor,并将数量增加到 9个,对于每个尺度的特征图分配3个不同的anchor,这样使网络在检测小尺寸对象时的能力大大提高;此外其还将预测层的 softmax函数改为 logistic函数,这样能够支持多标签对象的输出.YOLOv3整体网络结构如图1所示.
YOLOv3网络共输出了3个不同尺度的特征图,每个特征图对应的将输入图像分成 Si×Si个单元格,如果检测目标中心落在某个单元中,则该单元负责对这个目标的检测,并预测出 B个边框以及每个边框的置信度分数,该得分可以反映出该边框内含有目标的可信程度[13].其公式为

式中:Confidence表示边框置信度分数;Pr(object)表示边框是否包含目标,若包含则为 1,若不包含则为0;IoU表示预测边框和真实边框的交并比;Detection表示系统预测值;GroundTruth表示真实值.
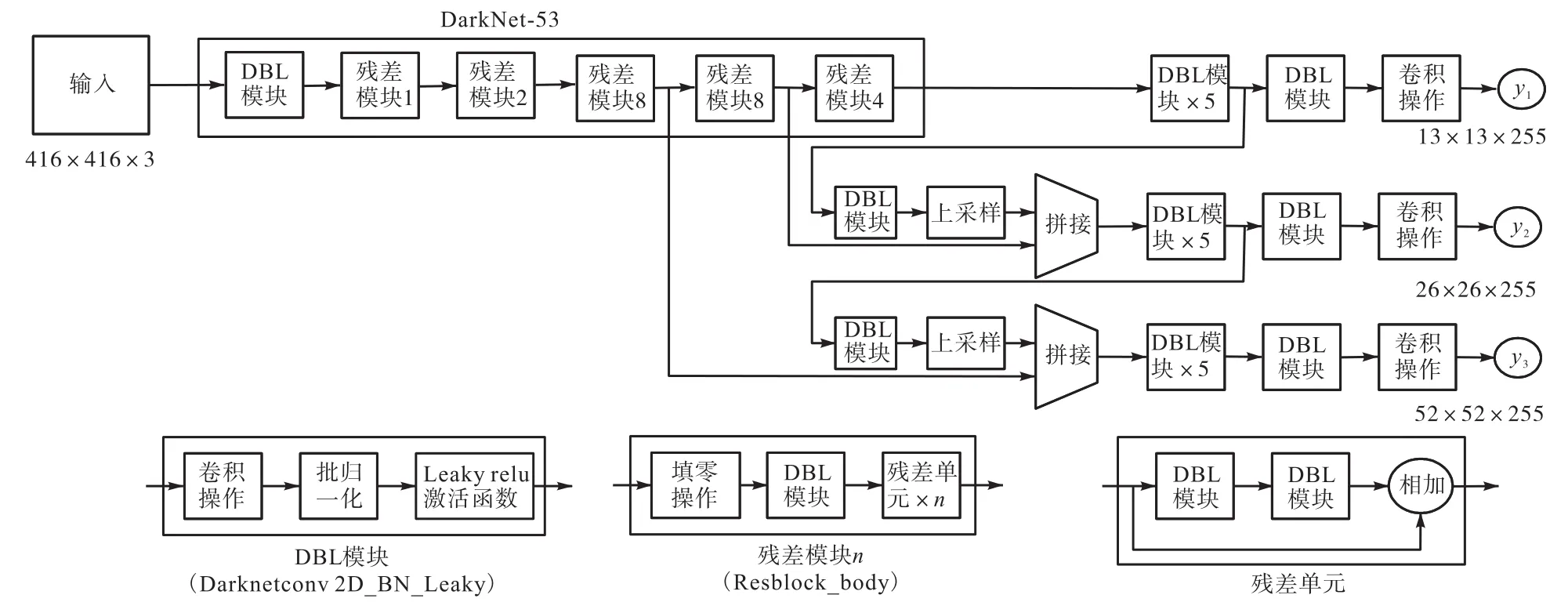
图1 YOLOv3网络结构Fig.1 YOLOv3 network structure
针对车底危险品检测场景的特殊性,使用YOLOv3算法存在以下问题:
(1) 车底拍摄图像一般为 4096×2048的高分辨率长条形图像,直接采用原网络输入会造成图像横向压缩,按照原尺寸输入会造成参数过多;
(2) 车底隐藏的目标危险物一般尺寸大小各异,原网络对各种尺寸目标没有很好的适应性;
(3) 车底结构复杂、零件较多,容易造成误判,且很少存在较大危险目标(相对车底面积).
2.2 评价函数
对于目标检测领域,一般选用准确率和召回率来衡量目标检测系统的性能[14].准确率是指在所有被判定为正确目标的目标中,真正正确目标所占的比例;召回率是指在所有真实的目标中,被系统正确检测出来的目标所占的比例.即准确率衡量的是查准率,召回率衡量的是查全率.其公式分别表示为

式中:Precision表示准确率;Recall表示召回率;TP表示系统正确检测出来的目标个数;FP表示系统错误检测出来的目标个数;FN表示系统漏检的正确目标个数.
在实际操作中,这两个参数往往是此消彼长,很难兼得,所以一般综合考虑两个指数用AP值来确定模型的性能,且有

式中:N为测试集中所有图片的个数;Precision(k)表示在能识别出k个图片时Precision值;ΔRecall(k)表示识别图片个数从k-1变化到k时Recall值的变化情况.
针对多个分类 C,一般用平均 AP值 mAP来作为模型整体评价结果,其计算公式为

3 改进的YOLOv3网络
针对 YOLOv3网络在本应用场景中的不足,本文从多尺度图像训练、增加 Inception-res结构、省去大尺寸特征图输出3方面进行改进.首先使用K-means聚类方法得到适合自制数据集的锚点(anchor):(8,15)、(20,35)、(40,19)、(33,65)、(80,42)、(53,130)、(121,82)、(148,188)、(382,311).
3.1 多尺度图像训练
由于车底拍摄图像有限,本文采用网络下载图像扩充样本.网络下载图像一般长宽比接近1∶1,但是车底拍摄图像尺寸约为 4096×2048.如果采用适合网络图像的 416×416、480×480、544×544等图像尺寸,则车底图像会造成横向压缩;如果采用适合车底图像的 640×320、704×352、768×384等图像尺寸,则网络图像会造成严重横向拉伸,从而影响样本精度.本文将训练集分成两个子训练集:车底拍摄图像集和网络图像集.将网络分别在两个训练集上交替训练,每5个epochs交替一次.这样可在充分利用有限车底图像的基础上利用网络图像进行扩充样本容量,且图像不发生较大畸变.
3.2 增加Inception-res结构
Inception模块是 GoogLeNet网络的关键性结构,它的目的是设计一种有良好局部拓扑结构的网络,对输入图像并行进行多个不同尺度卷积操作,并将所有输出结果拼接成一个更深的特征图.运用Inception模块可以在增加网络深度和宽度的同时减少网络参数.这样可以更好地增加网络对尺度的适应性.Inception-res模块即为引入残差思想的Inception模块.
YOLOv3网络结构通过从第36层和第61层引出浅层特征,并与网络输出的深层特征的上采样结果进行拼接得到包含浅层特征的输出结果.这里可以引用 Inception-res模块使网络在减少参数代价的条件下更好地增强对检测目标尺度的适应性.具体结构如图2所示,与DarkNet网络连接如图3所示.
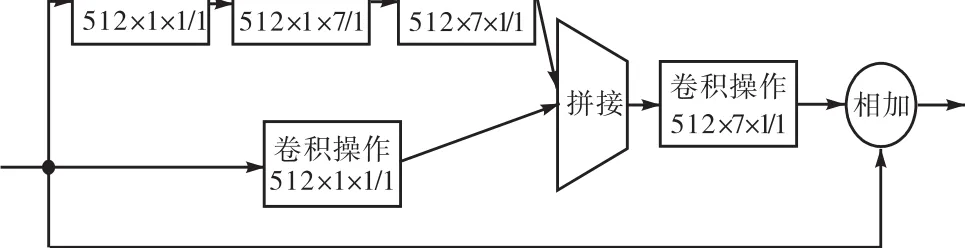
图2 Inception-res单元Fig.2 Inception-res unit

图3 DarkNet-Inception-res结构Fig.3 DarkNet-Inception-res structure
3.3 省去大尺寸特征图输出
针对车底危险物图像检测场景,车底相机拍摄图像尺寸一般为 4096×2048,但是车底部位能够隐藏的危险品相对车底来说一般较小,从而使大感受野特征图一般不起作用.并且由于车底零件较为复杂,与部分危险物外观比较相似,使用大感受野特征图往往造成结果误判或定位不精确.
本文将YOLOv3网络进行改进,将13×13特征图省去,只保留26×26和52×52特征图.这样在保证识别较小目标的前提下可以在一定程度上提高识别速率.
4 实 验
4.1 实验平台配置
本文选用keras开源框架,并使用TensorFlow开源框架作为后端进行卷积神经网络训练,基于 win10操作系统,python语言编程,实验平台配置为 Intel i7-8750H,主频 2.20GHz,32G 内存,显卡 GTX 1080.
4.2 车底图像扫描设备
本文选用海康威视的 MV-PD030001-03移动式车底检测装置进行图像采集,如图4所示.
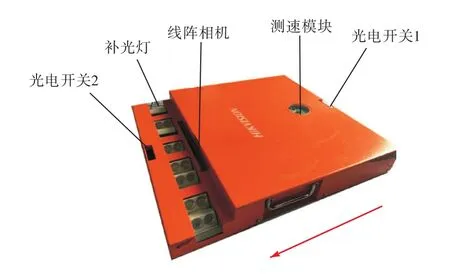
图4 车底图像扫描设备Fig.4 Image scanning device of vehicle bottom
当汽车驶入时,触发光电开关1,测速模块、补光灯和线阵相机开启;当汽车驶离时,触发光电开关2,测速模块、补光灯和线阵相机关闭,完成图像采集.
4.3 数据集
在危险物识别领域,目前几乎没有公开的大型数据集,本实验所用数据集为自制数据集,主要包括刀具危险物、枪支危险物、瓶类危险物、包裹危险物 4类.总共包含 1000张图像,其中 750张作为训练图像,250张作为测试图像,在训练集中随机选取75张图像作为验证集.图像使用 labelimg工具进行图像标记.
数据集图像由两部分组成,一部分来源车底相机实拍图像,一部分来源于网络图像.由于现实中车底存在危险物的图像很少,所以实验中选取指定车底人为安装危险物进行拍摄.但是由于条件的限制无法得到更多图像,于是通过网络图像补充使样本具有多样性.如图5所示.
4.4 模型训练
训练时首先调用 YOLOv3在 coco数据集上预训练的权值文件进行权值初始化,然后将 YOLOv3网络最后3个输出层冻结并训练50个epochs,随后将网络解冻,再训练 50个 epochs进行网络微调.网络超参数如表1所示.
该网络训练损失函数变化如图6所示,其在冻结网络状态下训练损失函数迅速下降到500左右,网络解冻后权值继续进行微调,当epochs达到88时损失降为 0.125,网络训练早停,训练完成.测试 mAP值为 73.4%.其各类别 PR(precision-recall)曲线如图 7所示.

图5 部分数据库图像Fig.5 Partial database image

表1 网络超参数Tab.1 Network hyperparameters

图6 网络训练损失曲线Fig.6 Network training loss curve
4.5 对比实验
4.5.1 多尺度图像训练
这里设置3组实验做对比,第1组输入图像为固定尺寸 416×416;第 2组输入图像尺寸为{416×416,640×320,480×480,704×352,544×544,768×384},每批次随机选择一个尺寸输入;第 3组网络图像输入尺寸为{416×416,480×480,544×544},车底拍摄图像输入尺寸为{640×320,704×352,768×384},每批次随机选择一个尺寸输入.第1组PR曲线如图7所示,第2组、第3组PR曲线如图8所示.实验结果如表2所示
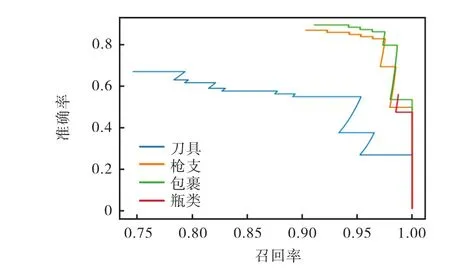
图7 PR曲线Fig.7 PR curves
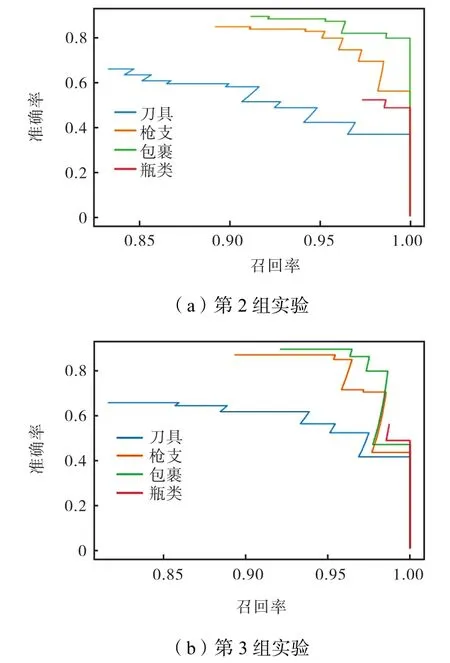
图8 多尺度图像对比实验PR曲线Fig.8 Contrast experiment PR curves of multi-scale image training

表2 多尺度图像训练对比实验结果Tab.2 Comparison experiment results of multi-scale image training
4.5.2 增加Inception-res结构
笔者通过设置3组实验做对比,第1组为原始网络 YOLOv3;第 2组在3个支路分别添加 Inceptionres模块为(1×1;7×7),如图2所示;第3组在y1支路添加 Inception-res1模块为(5×5;7×7),在 y2支路添加 Inception-res2模块为(3×3;5×5),在 y3支路添加Inception-res3模块为(1×1;3×3).具体结构如图9所示,第1组PR曲线如图7所示,第2组、第3组PR曲线如图10所示.实验结果如表3所示图12所示.

表3 增加Inception-res结构对比实验结果Tab.3 Comparison experiment results of the added Inception-res structure
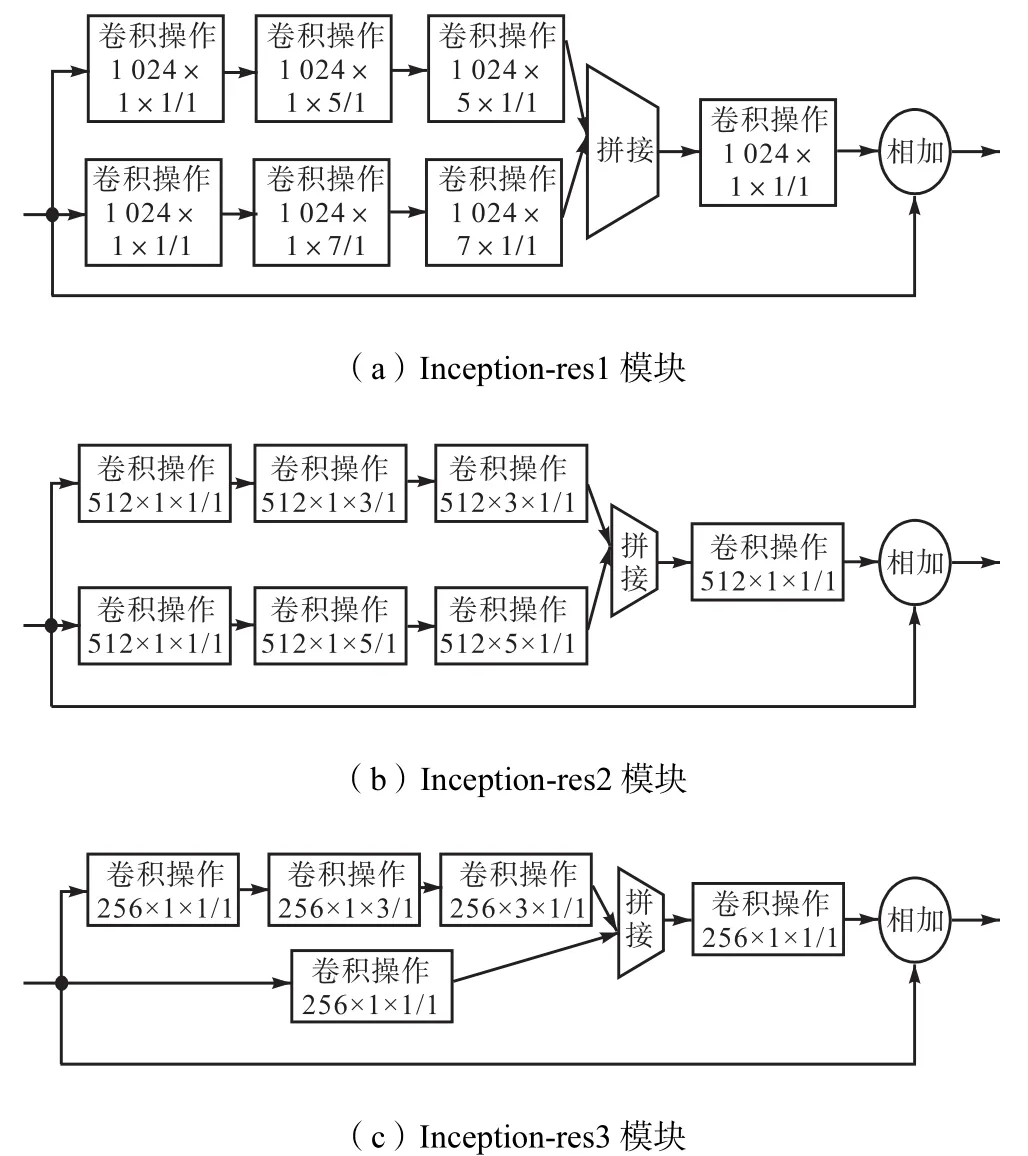
图9 3种Inception-res结构Fig.9 Three modules of the Inception-res structure
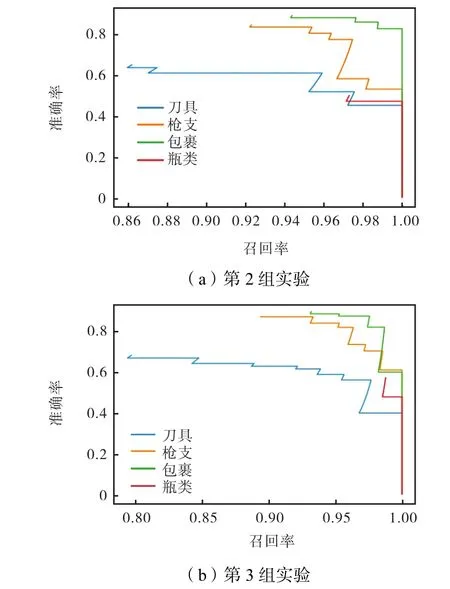
图10 增加Inception-res结构对比实验PR曲线Fig.10 Comparison experiment PR curves ofthe added Inception-res structure
4.5.3 省去大尺寸特征图输出
本文通过两组对比实验验证其有效性,第1组为原始网络YOLOv3;第2组为省去大尺寸(13×13)输出的网络.其对比实验PR曲线如图11所示.其实验结果如表4所示.
4.5.4 网络综合改进
本实验选用自制数据集,网络图像输入尺寸为{416×416,480×480,544×544},车底拍摄图像输入尺寸为{640×320,704×352,768×384},每批次随机选择一个尺寸输入;省去 13×13输出支路;并在 26×26输出支路添加如图 9中 Inception-res2模块,在52×52输出支路添加如图 9中Inception-res3模块.其实验结果如表 5所示,对比实验 PR曲线如
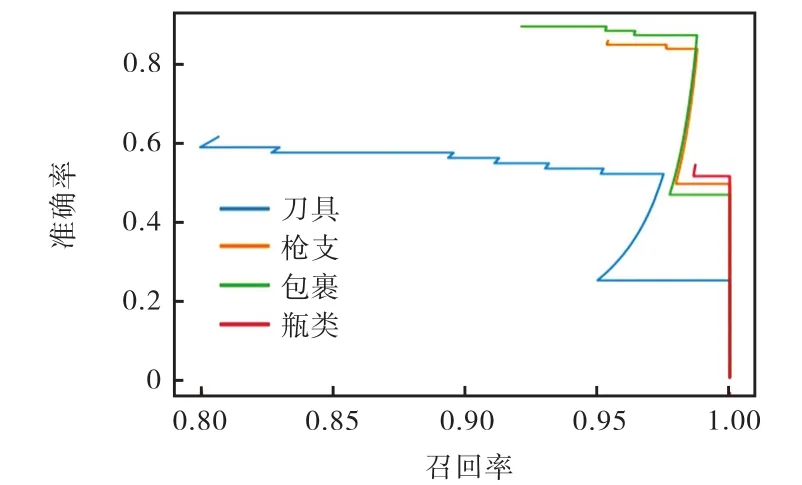
图11 省去大尺寸特征图输出对比实验PR曲线Fig.11 Comparison experiment PR curves of the eliminated large-scale feature output branch
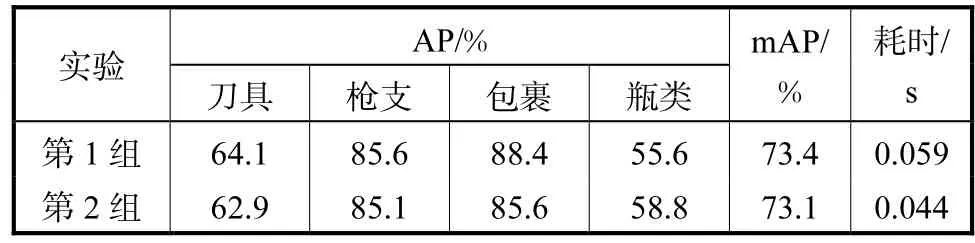
表4 省去大尺寸特征图输出对比实验结果Tab.4 Comparison experiment results of the eliminated large-scale feature output branch
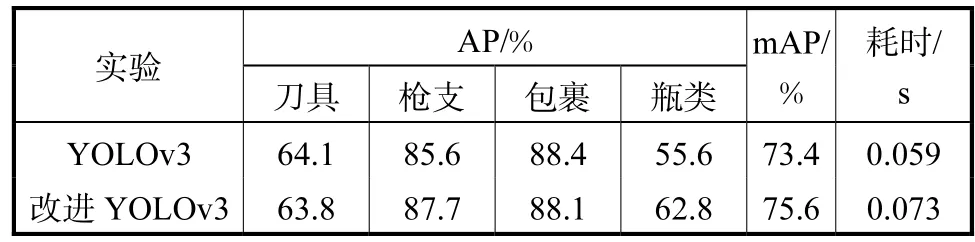
表5 网络综合改进对比实验结果Tab.5 Comparison experiment results of comprehensive network improvement
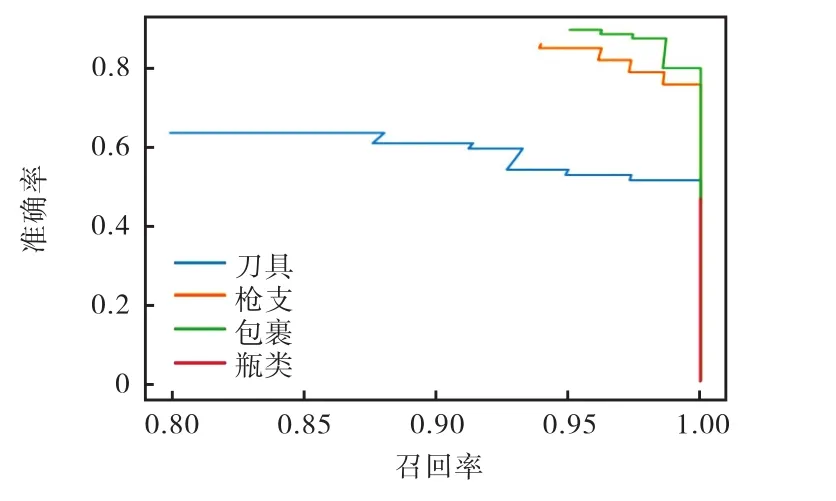
图12 网络综合改进对比实验PR曲线Fig.12 Comparison experiment PR curves of comprehensive network improvement
5 实验结果讨论
(1) 从实验结果可看出,在多尺度图像训练对比实验中,第2组使用多尺度训练,mAP值增加0.3%,枪支、瓶类的AP值都有所提高,但刀具和包裹的AP值有小幅下降,寻其原因是训练集中刀具和包裹图像尺度多样性较差,多尺度训练导致大量误判;第 3组使用双数据集混合训练,克服了训练集图像畸变问题,同时解决车底数据库容量太小问题,mAP值提高了 0.9%左右,但是仍存在上述问题,刀具和包裹类AP值都有所下降.
(2) 在Inception-res结构对比实验中,第2组瓶类 AP值有显著增加,但其余 3类都有所下降,其中包裹类下降约2%,总体mAP值也降低0.2%,究其原因可能是增加 Inception-res模块,使网络分支不能更好地对其负责目标尺寸进行检测;第3组针对此问题对每个分支使用特定 Inception-res单元,总体 mAP值提高 1.5%左右,从测试结果可以看出,网络对小尺寸目标检测能力明显提高.但是由于网络结构的增加,第2组和第3组实验耗时明显增加,第3组实验耗时甚至增加约3倍.
(3) 在省去大尺寸特征图输出实验中mAP值下降约 0.3%,这是由于测试集中图像有部分是大尺寸目标,去掉大尺寸检测框虽然防止了大尺寸误判,也导致这些目标的漏判.从测试结果中可以看出,测试结果mAP值下降0.3%,但网络检测单张图像耗时降低 0.015s,可将其与讨论(2)结合来降低增加Inception-res结构后网络的单张图像检测耗时.
(4) 在网络综合改进实验中,结合以上3种改进策略,mAP值提高了2.2%,网络耗时增加0.014s(在接受范围之内).同样刀具、包裹类AP值出现一定程度下降,枪支和瓶类尤其是瓶类 AP值有大幅度提升.究其原因可能是数据库中刀具、包裹图像整体偏大,而枪支和瓶类图像整体偏小造成的.改进的YOLOv3网络耗时在可接受范围内小幅增加的情况下,mAP值显著提高,且由图像检测结果看出网络对小尺寸目标识别能力明显增强.部分测试图像输出结果对比如图13所示.

图13 测试结果对比Fig.13 Comparison of the test results
6 结 语
本文采用改进的 YOLOv3网络算法,首先对YOLOv3网络的输入尺寸进行调整,使其更加适合应用场景的要求,获得更多图像横向特征信息,从实验结果可看出,使用双数据集多尺寸交替训练效果明显,mAP值提高了 0.9%左右;然后对网络增加Inception-res结构,使网络更加准确地从图像中获得不同尺寸目标,其 mAP值提高了约 1.5%;然后省去大尺度特征图输出分支,测得网络的 mAP值稍微下降约0.3%,但其单张图像检测耗时下降了0.015s,可看出该分支对结果 mAP影响不大,但增加了检测耗时;最后将上述方法结合,使各种策略优势互补,针对自制特定危险品数据集,改进的 YOLOv3网络适应性更强,mAP值显著提高 2.2%,且单张图像检测耗时也在可接受范围之内,网络对较小目标识别能力明显增强.当然,由于数据集的限制,图 7、图 8、图10~图 12中都出现了瓶类样本召回率波动较小,在后续实验还应增加该样本的多样性.
猜你喜欢
China’s foreign Trade(2021年6期)2021-12-26
文萃报·周五版(2020年44期)2020-11-28
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
粘接(2019年5期)2019-03-25
山东工业技术(2018年17期)2018-10-27
小学生作文·小学中高年级适用(2018年7期)2018-08-11
汽车与新动力(2017年3期)2017-06-29
太空探索(2016年5期)2016-07-12
中华奇石(2015年7期)2015-07-09
中华奇石(2015年5期)2015-07-09
