
融合多信息句子图模型的多文档摘要抽取*
2020-03-26 10:56蒋亚芳徐广义邓忠莹
计算机工程与科学 2020年3期
蒋亚芳,严 馨,徐广义,周 枫,邓忠莹
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500; 3.云南南天电子信息产业股份有限公司,云南 昆明 650041)
1 引言
多文档摘要抽取的研究是自然语言处理研究的一个分支,多文档摘要抽取是将大量的信息用简短的语言进行高度浓缩,提炼成一个简短连贯的摘要。多文档摘要的相关研究可以让我们迅速地筛选和浏览文档的重要信息,很好地缓解了信息过载所带来的困扰。多文档自动摘要技术经过多年的发展,取得了一定的研究成果。Radev等人[1]提出了利用聚类中心与聚类簇中句子的相似程度并结合句子位置抽取摘要;Erkan等人[2]通过LexRank算法计算句子重要程度的图模型抽取摘要;Bian等人[3]利用LDA主题模型,计算出文档的主题分布在语料中的重要度,并通过计算句子的后验概率来生成最终的摘要;Wu等人[4]利用基于主题模型的新模式,抽取出丰富度高的文本摘要;Li等人[5]通过将贝叶斯模型与句子自身的特征相结合的方法,实现了摘要的抽取;Wang等人[6]提出利用句子主题概率模型BSTM(Bayesian Sentence-based Topic Models),把每个主题中概率最高的句子抽出来,构成摘要;Yang等人[7]提出了一种将n-gram融入到分层潜在主题的分层贝叶斯主题模型,在层次主题的基础上抽取出最终的摘要。以上研究都是基于机器学习的方法得到摘要,但是忽略了句子与句子之间的语义关系对抽取摘要的影响。
随着深度学习算法的发展,已被广泛应用于多文档摘要抽取任务中。Kaageback等人[8]提出通过对词向量的各种运算来构建句子和文档的表示向量空间模型,以抽取文档的句子;Liu等人[9]提出了一个2层的稀疏表示模型,利用稀疏编码技术,解决在覆盖率、稀疏性以及多样化等方面的问题,进而提取多文档摘要;Yin等人[10]提出一个基于卷积神经网络的语言模型,通过卷积神经网络学习建模句子表示,使用一个多样化的选择过程来抽取多文档摘要;Nallapati等人[11]提出一种神经网络模型,通过生成式的损失函数来训练抽取式摘要;Yasunaga等人[12]提出一种融合句子关系图和神经网络模型的方法,即GCN(Graph Convolutional Network),来增加句子重要性的建模方式以抽取摘要。Narayan等人[13]利用在Seq2Seq 框架中加入外部特征的方式来抽取摘要;Zhou等人[14]提出了一种端到端的抽取式文本摘要模型,即NEDSUM(Neural Extractive Document SUMmarization),通过端到端的神经网络框架,并联合学习对句子进行评分和选择,实现文档摘要抽取。通过对神经网络模型的训练,将对句子的选择融入到打分模型中,进而抽取摘要。以上研究利用了深度学习模型,并融入了许多文本特征,在一定程度上提高了摘要的质量。这些研究融入了一些附加条件,使抽取的摘要覆盖率较高,冗余较少,但是有监督的神经网络模型需要大量有标注的数据集作为训练数据,在一定程度上存在着模型较为复杂的问题。
本文借鉴上述研究,针对现有多文档摘要抽取方法不能很好地将句子主题信息和语义信息相融合的问题,提出了一种融合多信息句子图模型的多文档摘要抽取方法。该方法首先以句子为单位构建图的节点;然后利用基于句子的贝叶斯主题模型和词向量模型得到句子主题概率相关性和语义相关性,对两者进行加权求和,同时结合主题信息和语义信息作为句子图模型的边权重;最后,借助句子图最小支配集的通用摘要抽取方法来得到多文档的摘要。
2 融合多信息句子图模型的多文档摘要抽取方法
本文基于最小支配集的句子图模型,并融合主题信息以及具有语义信息的句向量计算句子的重要程度,该方法包括4个部分:主题相似性表示,词向量模型构建,基于句向量的语义相似性表示,最小支配集的句子关系图生成摘要表示,如图1所示。
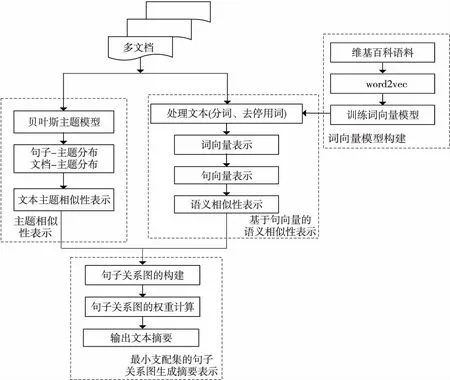
Figure 1 Multi-document summarization extraction framework based on multi-information sentence graph model图1 融合多信息句子图模型的多文档摘要抽取框架
2.1 主题相似性表示
基于最小支配集的句子图模型[15],使用最小路径覆盖算法得出摘要,该模型使用基于TF-IDF(Term Frequency-Inverse Document Frequency)的向量方法,判断句子与句子之间是否存在边,在抽取的过程中,抽取摘要仅仅描述某一个主题信息,从而会导致抽取的摘要概括性低。引入主题因素对边权重的影响,可以帮助理解上下文,并指导摘要抽取过程中的句子选择。基于句子的贝叶斯主题模型BSTM[6]是一个生成概率模型,该模型选择一种有效的参数估计变分贝叶斯算法,得到句子主题模型的概率分布。
整个文档集用D表示,对于每个文档d∈D,该基于句子的贝叶斯主题模型,生成单词是独立于文档的,本文使用句子语言模型作为基础模型。这样做的好处是,每个主题都用有意义的句子来表示,而不是直接用关键字来表示。句子语言模型公式表示如下:
p(Si=s|Ti=t)p(Ti=t|θd)
(1)
其中,θd表示文档d的模型参数,Ti表示第i个主题集,Si表示第i个unigram模型,s表示句子,Wi表示句子中的词。
在此,我们使用参数Ust来表示给定主题t的基础模型句子s的概率,p(Si=s|Ti=t)=Ust,其中,∑sUst=1。我们使用参数θd来表示给定文档d中主题t的概率,其中,∑tθdt=1,给定概率的集合{Bws},即p(Wi=w|Si=s)=Bws,通过句子s的经验概率分布词来获得Bws。
对于抽取摘要任务,我们关注的是如何用给定的句子描述每个主题。首先,对句子主题矩阵U、文档主题矩阵V初始化,通过矩阵相乘并归一化来更新U和V,如式(2)和式(3)所示:
(2)
(3)
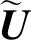
上述步骤需要通过最大期望算法EM来寻找最优的变分界。为了避免内部EM循环,可以直接优化变分界,得到更新规则,变分界最大化定义为:
(4)
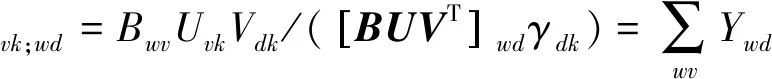
在获得句子主题矩阵的前提下,句子与句子之间就可以利用其对应的主题分布进行映射表示,因此,计算2个句子的相似度就可以通过计算与之对应的主题概率分布来实现。大体上,都使用KL距离[16]作为相似度的判断依据。KL距离如式(5)所示:
(5)
其中,θp和θq表示句子p和q的主题概率分布,TN为主题个数,θp,i表示第i个主题在句子p中的主题概率分布。随着KL距离值越小,句子与句子之间的主题相似性就越高,通过式(6)对距离值进行转换用以表征句子主题相似度:
(6)
其中,Rt-sim(p,q)表示句子p和句子q之间的主题相似度,该相似度的取值为[0,1]。
2.2 词向量模型表示
词向量是将单词映射到向量空间里,并用向量来表示,最早出现在2001年,Bengio等人[17]提出了神经网络语言模型,利用神经网络模型对上下文及目标词之间的关系进行建模,与此同时得到词向量。 在此背景下,训练词向量模型在2013年就被Mikolov等人[18,19]提出,词表示模型有CBOW和Skip-gram模型,有效地将每一个词语表征为K维的实数向量形式,可以充分反映词语的依赖关系。通过Skip-gram模型训练出来的词向量不仅具有更好的语义区分性,同时还可以更全面地评价词语间的语义关系,因此选择Google的开源工具包word2vec[20],使用Skip-gram模型进行训练,鉴于本文不是针对词模型训练的评价,在此并未做该模型不同参数的特定实验。
2.3 基于句向量的语义相似性表示
句子的语义信息对摘要抽取时存在着一定程度的影响,最小支配集MDS(Minimum Dominant Set)的句子图模型没有考虑语义信息对摘要抽取的影响。词向量的研究热潮已经成功激发了用于生成长文本片段(句子和段落)的语义向量的研究。词嵌入,其含义是使用具有语义相似性的向量来表征语言文本中的词语。引申为句子嵌入,则是用向量来表征文本中的句子,使得文本语句拥有了表征自己语义信息的向量。由此可以很好地让语义信息融入到摘要抽取以及文本信息检索等领域。本文使用一种无监督模型求句向量的方法[21],计算词嵌入在未标记的语料中,通过词向量的加权平均来表示句子,然后使用PCA/SVD方法移除句向量在第1主成分上的投影,最终得到句向量。
2.3.1 多文档文本的句向量表示
针对多文档句向量的表示,利用一种词向量的加权平均求句向量的方法。首先对多文档文本集进行预处理(分词、去停用词、去除标点符号),利用词向量模型训练得出多文档文本集的词向量;然后根据每个单词在句子中的影响程度,使用一种加权词袋模型,利用句子中词向量加权的均值来表征句向量,对句子加权求和后,借助主成分分析PCA(Principal Component Analysis)方法移除句向量中无关紧要的部分,对句向量进行修正去冗余,去掉第一个主成分的投影。句向量Ks的计算公式如式(7)所示:
(7)
其中,b是自定义的标量参数,实验表明在b=10-3时性能最佳;p(w)表示单词w的词频;Kw是训练的词向量;|s|表示该句子的长度,即句子的单词数;b/(b+p(w))表示词w的权重计算,这一权值的计算可以使高频词的权重值有所下降,对句子词向量加权的求和,得出初步的句向量 。
在整个语料库中,对文本集进行1次主成分分析,寻找到第1奇异向量,即所有的文本句向量构成的矩阵第1主成分u,让每个句向量减去它在第1主成分u上的投影,计算如式(8)所示:
Kst=Ks-ProjuKs
(8)
其中,Kst表示为移除第1主成分投影的句向量。1个向量K在另1个向量u上的投影定义如下:
(9)
在此,使用PCA的方法对加权后的句子进行修正,找到第1奇异向量,对每个句向量减去它在主成分上的投影,移除句向量中无关的部分,得到最终的多文档文本句向量Kst,该句向量的得出,为下面计算语义相似度做好铺垫。
2.3.2 句子的语义相似性表示
利用训练好的句向量模型得到的蕴含语义信息的句向量表示计算句子之间的相似度。利用句子的向量表示句子之间的相似度,任意2个句子的相似度可以用对应的余弦相似度计算,如式(10)所示:
(10)
其中,Rs-sim(sp,sq)表示为句子p和句子q之间的语义相似度。sp和sq表示句子p和句子q的向量表示。最终得到的句子语义相似度,为下面抽取多文档摘要做好了铺垫。
3 最小支配集的句子关系图生成摘要表示
本文采用最小支配集MDS的方法来得到多文档摘要。句子图的最小支配集可以自然地用于描述摘要:它具有代表性,因为每个句子都在最小支配集中或连接到集合中的1个句子;并且它具有最小冗余,得到概括性高的多文档摘要。最小支配集的定义为:给定图G=〈V,E〉,其中V是图G的顶点集,E是G的边集,最小支配集就是指从顶点集V中抽取出尽量少的点组成1个集合,使得V中剩余的点都与抽取出的点有边相连,假如在抽取的顶点集合中除去任何元素,都不再是支配集。因此,我们认为在所有支配集中,顶点个数最少的支配集为最小支配集。
基于最小支配集的句子关系图生成摘要表示,以文档集合中的所有句子为顶点构建句子图,边表示顶点与顶点之间的权重。借鉴句子图模型的思想[22],确定句子与句子之间存在边,我们需要确定构成边的条件,如果判断1对句子p和q之间边的权重高于给定的阈值λ,则判定这2个句子之间存在边。边的权重表示为:
W(p,q)=αRt-sim(p,q)+(1-α)Rs-sim(p,q)
(11)
其中,α表示可调参数,权衡主题因素和语义因素对句子权值计算的影响程度,其具体取值是由大量的实验数据来确定的。W(p,q)表示句子p和句子q之间边的权重,Rt-sim(p,q)表示2个句子之间的主题相似度,Rs-sim(p,q)为2个句子之间的语义相似度。
最小支配集(MDS)与集合覆盖SC(Set Covering)问题密切相关,这是一个众所周知的NP难问题,可以采用最小支配集的贪婪近似逼近算法近似求解。该算法从空集开始,如果当前的顶点不属于支配集,将继续计算下1个顶点,判断是否属于最小支配集,不与当前集合中的任何顶点相邻的节点都将会被添加,直到遍历所有的顶点。
1973年Johnson[23]证明了贪婪算法的近似因子不小于H(b),如式(12)所示:
(12)
其中,H(b)是时间复杂度;lnb+1表示贪婪近似算法的逼近因子,其中b是最大集合的大小。
在构建句子图之后,就可以使用最小支配集来表示摘要。通用摘要是提取最具代表性的句子来概括输入到最小支配集框架中的文档的重要内容,即我们所要抽取出的摘要。通常情况下,存在着抽取摘要的长度限制,使用贪心算法构造支配集的子集作为最终的摘要可以达到很理想的效果。基于最小支配集的多文档摘要抽取算法如下所示:
算法1基于最小支配集的多文档摘要抽取算法
输入:句子图G,摘要的最大长度W。
输出:摘要S。
步骤1S=∅;
步骤2T=∅;
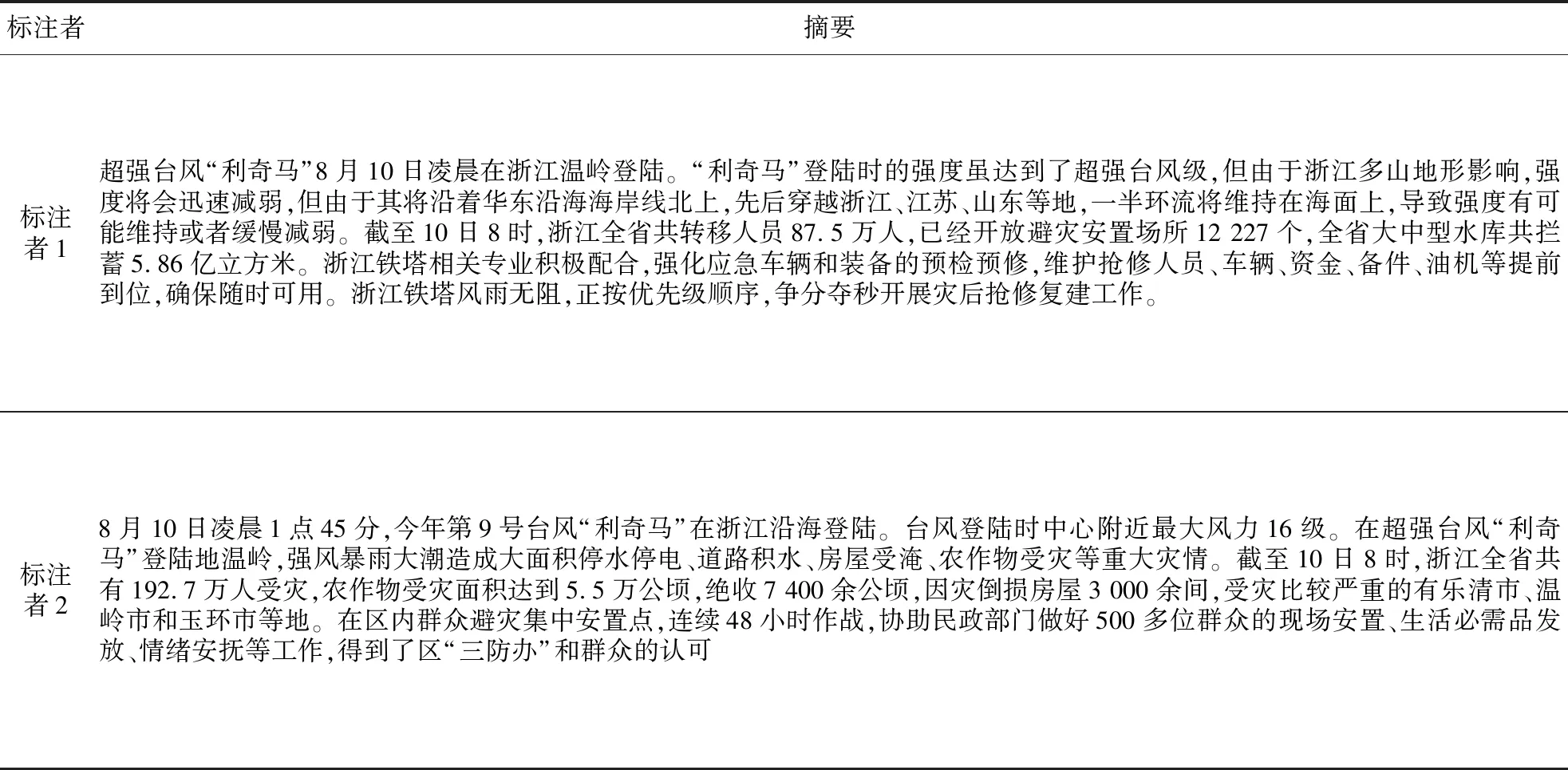
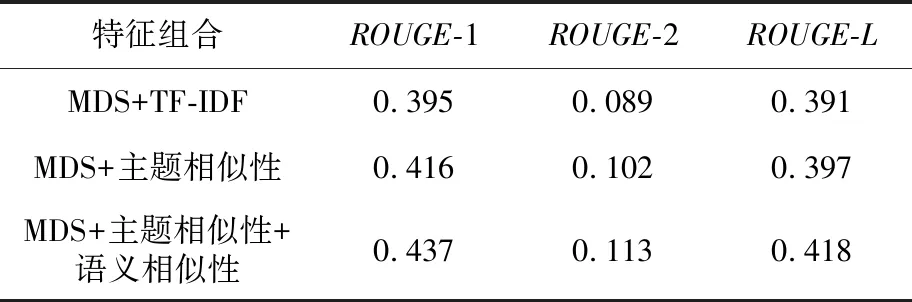
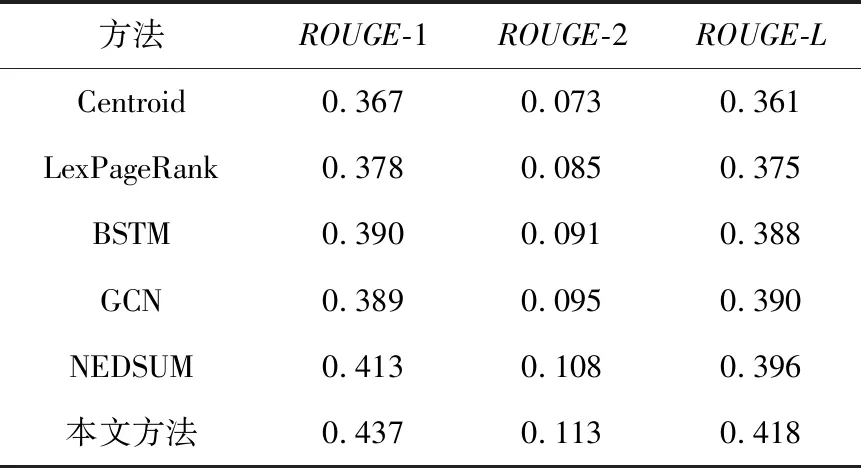
步骤3whileL(S) 步骤4forv∈V(G)-Sdo 步骤5s(v) = |ADJ(v)-T|; 步骤6v*=arg maxvs(v); 步骤7S=S∪{v*}; 步骤8T=T∪ADJ(v*); 步骤9end 在上述算法中,每个阶段,将提取局部标准最优的句子,描述了通用概括的近似算法。G是句子图,L(S)是摘要的长度,W是摘要的最大长度,ADJ(v)={v′|(v′,v)∈E(G)}是与顶点v相邻的顶点集合。L(S) 本文通过爬取中国新闻网、新华网、人民网、国际在线、中国日报网等网站获得人工收集的新闻语料,共计1.84 GB的新闻语料,用于训练词向量模型。同时,在人工收集的新闻语料中随机选取500篇热点新闻事件的新闻报道作为摘要抽取的测试数据。其中,该测试集包含有50个主题的新闻文本,每个主题包含有10篇文档,所选取的语料具有代表性和区分性,既有时政新闻,又有社会新闻;既有国际新闻,又有国内新闻;既有突发事件,又有热点问题。对测试语料的摘要进行人工抽取,具体的抽取方法为:挑选2名标注者进行摘要抽取并且每名标注者的抽取过程都是相互独立的。本文抽取多文档摘要的标准是选择同一话题在新闻事件中报道频率相对较高的新闻以及与事件发展紧密相连的新闻。 抽取多文档摘要时,从每个主题中抽取250个字左右的原文本作为参考摘要。表1是2名标注者针对台风利奇马新闻事件的中文语料摘要的标注结果。 人工摘要抽取具有很强的主观性,由于标注者对语义理解的不同以及知识背景的不同,使得2名标注者之间的结果存在着主观性的差异。若差异性太大,表明测试集的争议性和主观性较大,抽取摘要的可信度就会很低;与此相反,如果差异性小,则表明测试集标注的争议性就小,可信度高。表2给出了人工标注的ROUGE(Recall-Oriented Understudy for Gisting Evaluation)值。ROUGE是模型生成摘要和已有摘要之间的n元共现次数,在自动文摘评价方面应用最为广泛。其中,ROUGE-1、ROUGE-2、ROUGE-L可以在一定程度上反映摘要的质量,ROUGE的值越高,说明抽取出的摘要质量越好。 Table 1 Summary annotation results of two markers表1 2名标注者的摘要标注结果 Table 2 ROUGE values of manual labeling 表2 人工标注ROUGE值 从表2中得出的数据可以反映出抽取的结果一致性较高 。 本文的实验过程包括词向量模型的训练、主题相关性计算、基于句向量的语义相关性计算、句子关系图生成摘要等过程。词向量模型的训练,使用网络爬虫收集的语料集,选择Google的开源工具包word2vec,使用 Skip-gram模型进行训练,根据往常的实验得出,窗口大小设置为5,维度设为200,低频词阈值设为5,迭代100次;句向量模型中,实验表明在b=10-3时性能最佳[21]。针对最小支配集的句子关系图生成摘要模块,实验数据表明,可调参数的值为0.4时,实验效果更好。 本文采用内部评价指标,使用ROUGE来判断该模型生成的摘要和已有摘要之间的一致性关系。ROUGE-N的计算公式如下所示: ROUGE-N= (13) 其中,N表示n元组的长度,Countmatch(n-gram)表示该模型抽取出来的摘要与已有参考摘要之间的共现n-gram数量总和,n-gram表示n元词,RS表示已有参考摘要集合。 以人工抽取的新闻摘要作为参考摘要,将本文模型所抽取的摘要与人工抽取的参考摘要进行对比,以验证本文方法的可行性。本文设置了3个对比实验。 实验1验证权重参数α对摘要抽取的影响。使用本文模型设置不同加权参数进行了对比实验,实验结果如表3所示。 Table 3 Evaluation results of different weighting parameters表3 不同加权参数的评测结果 实验结果表明,当权重参数取0.4时,实验结果达到最佳状态,这有力地证明了句子的语义信息对于多文档摘要的抽取具有很重要的影响。与此同时,也要结合主题信息所发挥的作用,两者相辅相成,缺一不可,既不能过度依赖于语义信息,同样也不能忽略主题信息所带来的影响。表3数据显示,将句子主题信息和语义信息相融合的方法,在多文档摘要抽取上得到了较好的效果。 实验2不同信息特征组合的对比实验。验证在多文档摘要抽取任务中,句子主题因素、语义因素、句子图模型的关系因素对抽取多文档摘要的影响程度。本文方法选取不同信息特征组合进行实验,实验结果如表4所示。 从表4的实验结果来看,仅仅使用MDS+ TF-IDF特征组合方法,本文方法的ROUGE-1和ROUGE-2的值明显低于结合主题相关度和语义相关度的数值,其主要原因是MDS+TF-IDF仅仅利用词语的TF-IDF来确定句子间的关系信息,没有考虑到句子与句子之间的语义相关度,也没有考虑到句子的主题相关度。本文方法充分考虑到主题信息、语义信息以及关系信息对抽取摘要的影响,融合多信息的句子图模型对多文档摘要抽取在质量上有了明显的提高 。 Table 4 Experimental results of different information feature combinations表4 不同信息特征组合的对比实验结果 实验3为了验证本文方法的可行性,将本文方法与其他几种抽取多文档摘要方法BSTM、GCN和NEDSUM进行对比。BSTM方法[6]根据句子主题概率模型得出句子主题矩阵,并抽取出每个主题中概率最高的句子组合成摘要;GCN方法[12]通过融合句子关系图和神经网络模型增加句子重要性建模的方式来抽取摘要;NEDSUM[13]通过一种端到端的神经网络框架,首先使用层次编码器读取文档语句,以获得语句的表示,然后逐个提取句子,然后逐个提取句子,以构建输出摘要之间进行比较。实验结果如表5所示。 Table 5 Experimental results compared with those of other methods 表5 本文方法与其他方法的实验结果比较 从表5给出的实验结果可以看出,本文方法比传统的机器学习方法Centroid、LexPageRank和BSTM在ROUGE-1和ROUGE-2上都有很明显的提升;本文方法与神经网络模型得出的抽取式摘要方法相比也有优势,将本文方法与GCN和NEDSUM的结果进行比较,GCN与NEDSUM法都使用了有监督的神经网络模型,需要大量有标注的数据集作为训练数据,在一定程度上增加了抽取摘要的复杂程度,本文方法与GCN方法相比提升了4.8%,与NEDSUM方法相比提升了2.4%,表明了本文方法是可行的。 针对现有的抽取多文档摘要方法没有能够充分利用句子间的主题信息、语义信息和关系信息的问题,本文提出了一种融合多信息句子图模型的多文档摘要抽取方法。本文方法利用关系句子图模型,基于句子的贝叶斯主题模型、词向量模型以及句向量框架,充分利用主题信息、语义信息和关系信息,综合考虑了句子、主题、语义以及图的全局信息,从而简单有效地抽取出最能代表新闻观点的句子作为多文档的摘要。实验结果表明,与以往的摘要抽取方法相比,本文方法的ROUGE值有很明显的提高,而且本文方法具有一定的鲁棒性。下一步将在已有研究的基础上,融入更多的特征到摘要抽取中,使抽取的摘要代表性更强、冗余更少。4 实验
4.1 实验数据集

4.2 实验设置和评价指标
4.3 实验结果及其分析

5 结束语
猜你喜欢
客联(2022年3期)2022-05-31中国新闻周刊(2021年26期)2021-07-27意林(2021年9期)2021-05-28开放教育研究(2020年2期)2020-03-31时代英语·高一(2019年1期)2019-03-13自动化学报(2017年2期)2017-04-04中国修辞(2017年0期)2017-01-31信息安全研究(2016年4期)2016-12-01Coco薇(2016年8期)2016-10-09中国社会历史评论(2016年2期)2016-06-27
