
TED演讲视频中动态多模态话语的模态协同
2020-03-21 18:03:52王丽娟
黑河学院学报 2020年1期
王丽娟
(广东培正学院,广东 广州 510830)
自从20世纪90年代以系统功能语言学为理论基础的社会符号学者开始研究多模态语法以来,国内外对多模态话语的研究已经如火如荼。迄今为止,多模态话语的研究从不同方面、不同角度得到了更进一步的发展。Kress & Van Leenwen (1996) 研究了视觉语法,从功能的角度探讨了图像的功能[1]。张德禄(2009)探索了多模态话语分析的综合理论框架[2]。目前的多模态话语研究除了对图像、符号、图表等静态形式展开探讨,也对动态多模态话语进行了分析。如张德禄,袁艳艳(2011)以电视天气预报多模态语篇为例研究了动态多模态话语的模态协同问题[3]。管乐(2017)分析了动态演讲视频的多模态话语[4]。虽说目前动态多模态话语的研究有一定的进展,但相对静态多模态研究还是不足,需要再进一步扩展。本文以TED演讲视频为例,研究动态视频中各个模态之间的关系。
一、动态多模态话语分析综合理论框架
以系统功能语言学为理论基础,张德禄(2009)提出了动态多模态话语分析综合理论框架,如图1所示[2]。该框架由文化语境、情景语境、内容层面和表达层面四部分组成。根据该框架,文化语境主要指的是意识形态和体裁系统,讲话者为完成交际目的会根据情景语境(语场、语旨和语式)来选择交际模态(视觉模态和听觉模态)去表达意义。在意义表达的过程中,主要由图像意义体现的视觉模态和由声音意义体现的听觉模态形成互补(强化、非强化)或非互补(交叠、内包、语境互补)的关系。随着交际进程(时间)的推进,各种模态之间要相互配合,共同完成话语整体意义的表达。
二、动态语料的选择和研究方法
(一)语料
本文选取的动态语料是著名的心理学家Shawn Achor于2012年在TED 大会上的一篇演讲“The happy secret to better work”。作为一家非盈利机构,TED大会以“传播一切值得传播的创意”为宗旨,每年邀请来自科学、设计、文学、音乐等领域的杰出人物进行演讲,分享他们对技术、社会及人性等方面的探索。TED演讲视频有很多,本文在选取材料时有几个因素考虑在内。因素之一是关注度。在TED网站上,Shawn Achor 的这篇演讲是25个最受欢迎的演讲之一,目前这个演讲视频的点击率已超过2 000多万。 因素之二是视频中所使用的模态类型。为了较全面地分析多种模态之间的协同关系,尽可能选择听觉模态、视觉模态,手势等多种模态共同出现的演讲视频。
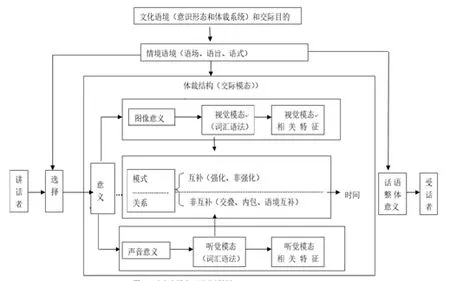
图1 动态多模态话语分析框架
(二)研究方法
本文运用张德禄的动态多模态话语分析框架,主要采用定性的研究方法[3],从文化语境、情景语境及各模态之间的协同关系来对Shawn Achor的TED演讲视频进行分析。采用张德禄对动态多模态语篇的切分标准(语篇结构、经验意义和前景化的事物和特征),根据演讲语篇的四个发展阶段(演讲开始、演讲主题、演讲高潮、演讲结束),本文把Shawn Achor的演讲视频分为7个步骤和情节,包含14个事件和图片。事件是由图片来实现的,每个图片都是一个信息单位[5]。具体的切分结果如下页图2所示。
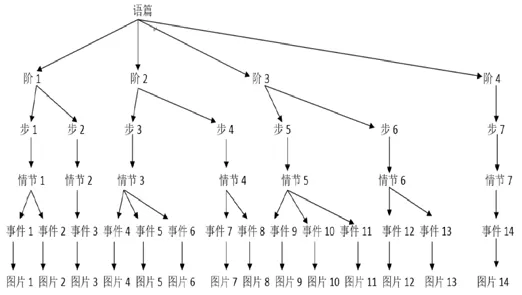
图2 演讲视频切分图
三、动态演讲视频的多模态话语分析
(一)文化语境
文化语境主要指的是与人们交际相关的社会文化背景,包括文化习俗、生活习惯、思维方式、社会规范等,是完成交际的重要层面。文化语境决定人们根据不同的交际目的采取不同的体裁来完成交际意义的传递。具体到TED演讲来说,演讲者主要通过有声语言的形式,借助于文字、图像、肢体语言等其他手段针对某一个能引起观众共鸣的话题,清楚、完整地表达自己的见解。TED的演讲者从最初的技术、娱乐、设计三个领域扩展到几乎各个领域,包括心理学家、哲学家、慈善家、探险家等。演讲者要求在18分钟之内向观众阐述自己在某一领域的独特观点或主张。本文选取的是心理学家Shawn Achor关于“改善工作的快乐之道”的演讲。在12分钟左右的演讲中,Shawn Achor指出积极的大脑对人们工作的影响,以及如何去创建积极的心理。这篇演讲可以分为四个阶段:(1)演讲开始:演讲者从自己儿童时期的故事入手引出“积极心理学”概念;(2)演讲主题:科学平均数概念对人们生活的负面影响; (3)演讲高潮:如何建立积极的心理(大脑);(4)演讲结束:演讲者的致谢。
(二)情景语境
根据系统功能语言学,情景语境主要有语场、语旨和语式构成。语场指的是语篇所涉及的活动,即要做什么;语旨指的是语篇涉及的参与者,即交际双方的角色和社会关系;语式指的是交际的媒介和渠道。在本文的演讲视频中,语场就是Shawn Achor于2012年在TED大会上的关于“更好工作的快乐之道”的一次演讲。语旨是指演讲者Shawn Achor本人,参加TED大会的观众及TED大会媒体。语式是指TED大会通过网络的形式向全球播放心理学家Shawn Achor的演讲,演讲者着装得体,语言正式,语速适度,表达清楚流畅,在主要通过口语形式表达主题的同时,结合了图像、文字及手势等其他模态,共同完成了交际意义的传递。
(三)动态多模态间的协同
下面按照Shawn Achor演讲视频的三个主要阶段:演讲开头、演讲主题、演讲高潮对视频中各个模态间的协同性进行分析。
1.演讲开头部分
演讲的开始,Shawn Achor 面带微笑,目光正对观众,双手自然下垂,走向讲台。然后通过语言模态(口语)开始演讲,同时伴随着双手交叠放在身前(事件1:自身经历的小故事介绍)。这时听觉模态是主要模态,演讲者和背景图形成的视觉模态及手势并没有参与交际过程,对听觉模态意义的体现基本上没有贡献,因此,这时的听觉模态处于前景化的位置。随着演讲的进行,出现了文字模态,这是对演讲者身份和演讲主题的介绍,这时的视觉模态对听觉模态所传递的意义可以说是一种互补的非强化扩充关系(事件2)。之后随着导入故事的结束,Shawn Achor引出了“积极心理学”这一概念。在通过口语形式(听觉模态)引出这一概念的同时,可以发现Shawn Achor的两只手从打开的状态慢慢靠拢,直至碰触(事件3)。打开的手的状态是对口语内容“we had no idea at the time”的一个补充强化,双手慢慢靠拢说明了时间的发展——从“at the time”到“two decades later”。同时双手的碰触说明时间发展到了现在,即今天的演讲话题“positive psychology”。因此,在话题导入过程中,可以发现听觉模态为主要形式,而手势则起到了互补强化的作用。
2.演讲主题部分
在演讲视频的主题部分,Shwan Archor 主要阐述了人们在日常生活中对科学平均数的迷信(事件4),积极心理学家对待平均概念的看法(事件5),举例说明平均概念带给人们的负面影响(事件6),以及对异常数据的研究(事件7和事件8)。 从事件4和事件5来看, 演讲者主要是通过展示一个图表(视觉模态)配合口语形式(听觉模态)来阐述积极心理学家和其他人对待平均概念的不同看法,同时伴随着一定的手势。这时的口语和图表相互结合,共同完成了意义的传递,因此,两者都是主要模态,构成了互补非强化联合的关系。通过事件6,Shwan Archor列举了自己生活中的一个例子,来说明平均概念给人们带来的负面影响,在这个过程中口语是意义表达的主要形式。在事件7中演讲者阐述了自己申请哈佛大学的经历(听觉模态),同时以ppt的形式展示了哈佛大学的图片(视觉模态),这时的视觉模态是对听觉模态的强化。事件8 中Shwan Archor通过图片展示了电影哈利·波特里面霍格瓦茨魔法学校的食堂和哈佛大学食堂的相似性,这时的听觉模态和视觉模态共同担当了传递意义的作用,构成了互补非强化联合关系。
3.演讲高潮部分
Shwan Archor视频演讲的高潮部分主要包括两个情节:一是人们的大脑对于快乐和成功关系的认知(事件9、事件10、事件11),二是如何去建立积极的心态(事件12、事件13)。在第一个情节中,当演讲者提到积极的大脑对成功的影响时(事件9),这时出现的文字形式(视觉模态)是对所传递意义的补充强化,听觉模态还是作为主要的模态形式。在事件10和事件11中,Shwan Archor主要阐述了传统的关于快乐和成功关系的观点及这种观点的落后,这时演讲者本人形成的视觉模态可以说是无效的,而演讲者的手势则起到了意义传递的强化作用。在第二个情节中,当Shwan Archor介绍到提高人们的积极心理程度会大大改善人们工作的结果时(事件12),以ppt的形式出现了文字模态。文字模态主要列举了积极心理带来的一些具体的良好的结果,如高效的生产力、销售量的提高等。这时的文字模态强化了语言模态所传递的内容,因此,听觉模态和视觉模态构成了一种互补强化关系。事件13主要阐述了5种建立积极心态的方法。当演讲者说道:“We've found there are ways that you can train your brain to be able to become more positive.”时,出现了带有文字模态的图像,这时的听觉模态和视觉模态相互协调,共同表达了交际过程的意义,完成了交际目的。
四、动态多模态之间的协同关系
通过对Shwan Archor演讲视频的分析可以看出,在演讲的开始、发展、高潮的每一个阶段,口语形式都是传递信息的主要手段,即听觉模态始终处于前景化的位置中。这是由听觉模态的线性化决定的,也符合信息获取循序渐进的特点。在Shwan Archor的演讲视频中,听觉模态单独处于前景化的比例约为71%,视觉模态和听觉模态共同处于前景化的比例约为29%,视觉模态主要是作为听觉模态的补充强化或协调。有时手势也产生对听觉模态的补充强化作用,但很多时候由演讲者本身和手势形成的视觉模态对传递意义并无多大贡献。 从分析结果还可以看出,模态之间的协同并不是随意的、任意的。如果听觉模态(口语)能完成意义的传递,那么其他模态就没有出现的必要。如果听觉模态不能完全表达演讲者所传递的信息,那么视觉模态、手势或面部表情就会对听觉模态进行补充强化,甚至协调。同时各个模态之间的配合不能产生矛盾和冲突,要以增加正效应为原则。
综上所述,通过对TED动态演讲视频的分析可以看出,演讲者在演讲的不同阶段会根据不同的交际目标来选择不同的模态或模态组合,从而完成整体意义的传递。在整个演讲过程中,听觉模态始终是演讲者所采用的主要形式,这也是由演讲的特点决定的。本文通过对TED动态演讲视频的分析,一方面能够让人们对演讲中各个模态的运用有更好的了解;另一方面也希望能够进一步拓宽动态多模态话语分析理论的实践应用。当然,本文也存在一些不足的地方,如缺乏详尽的定量分析,语篇的切分带有一定的主观性等。希望以后的研究能进一步改正不足,促进多模态理论的发展。
猜你喜欢
天津外国语大学学报(2021年1期)2021-03-29 03:07:20
发明与创新·小学生(2016年4期)2016-08-04 09:04:23
发明与创新(2016年15期)2016-04-16 07:30:47
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
当代修辞学(2014年1期)2014-01-21 02:30:16
当代修辞学(2014年1期)2014-01-21 02:30:12
意林(2011年9期)2011-05-14 16:48:56
外语学刊(2010年2期)2010-01-22 03:31:03
