
基于NVIDIA JetsonTX2的视频行为检测研究
2020-03-13 10:56卿粼波李诗菁何小海
计算机应用与软件 2020年3期
李 龙 卿粼波 李诗菁 何小海
(四川大学电子信息学院 四川 成都 610065)
0 引 言
行为检测是计算机视觉领域和图像处理中的一个重要研究方向[1]。在传统行为检测领域,DT[2]算法是最经典的算法之一,它主要包括密集采样特征点,特征点轨迹跟踪以及基于轨迹的特征提取三个部分。2013年由IEAR实验室发表的iDT[3]算法,对DT算法做了改进,主要包括对光流图像的优化、特征正则化方式以及特征编码方式,大大提升了算法的效果。自深度学习应用到行为检测领域后,使用基于深度学习的方法[4]得到的效果已经明显超过了使用传统算法。
深度学习理论提出以来,研究人员发现应用深度学习进行行为检测,可以有效提高检测效果和性能,因此深度学习在实时视频的行为检测[5-6]开始广泛应用,到现在为止,其检测效率和精度已经有了很大提高。在深度学习理论中,Two-Stream[7]是一个主流方法,它由时间、空间两个网络组成。该方法提出对视频序列中每两帧计算密集光流,得到密集光流的序列。然后对光流序列和图像序列分别训练卷积神经网络模型,再训练一个fusion网络进行融合图像序列和光流序列的网络。C3D[8](3-Dimensional Convolution)是另一个主流方法,在目前来看,使用C3D方法得到的效果要比Two-Stream方法略差些,但C3D网络结构简单,而且C3D运行时间短,处理速度快,所以仍然是当前研究热门。因为嵌入式平台如NVIDIA JetsonTX2携带方便,性能强大,所以使得更大型、更复杂的神经网络可以广泛地部署到嵌入式平台上。为提高检测精度以及减少参数量,本文以C3D网络为基础,结合ResNet[9]的short-cut结构以及改进的SqueezeNet[10]来进行网络结构调整,并将网络模型部署到NVIDIA JetsonTX2上进行行为检测,总体结构如图1所示。

图1 总体结构图
1 C3D网络与网络结构改进
1.1 C3D网络
采用C3D卷积神经网络来进行视频行为检测,网络结构如图2所示。该网络采用三维卷积对视频连续帧进行操作,相比于二维卷积更能简单有效地处理时间信息,是一种简单、高效、通用、快速的行为识别神经网络。但是C3D网络参数量较大,难以将它跟其他参数量较大的网络同时部署到同一个NVIDIA JetsonTX2上,并且准确度不高。为提高检测的准确度以及减小网络参数量,本文借鉴SqueezeNet网络对C3D网络进行改进。

图2 C3D网络结构
1.2 网络结构改进
由UC Berkeley与Stanford研究人员设计完成的SqueezeNet网络,其设计目标并不是想得到更好的检测精度,而是希望能够简化网络复杂度。所以SqueezeNet主要是为了降低卷积神经网络模型参数数量而设计的,相比较直接使用3×3的卷积核,SqueezeNet的参数量和理论计算量理论上都降为原来的5/36。与传统的卷积方式不同,SqueezeNet把原本为一层的卷积分解为两层:squeeze层和expand层,每层卷积后都有一个激活层,squeeze层里都是1×1的卷积,数量为s1;expand层里有1×1和3×3两种卷积核,数量分别为e1、e3,在数量上4×s1=e1=e3。expand层之后将1×1和3×3卷积后得到的feature map进行拼接,然后把这两层封装为一个Fire_Module,如图3所示。Fire_Module输入的feature map为H×W×C,输出的feature map为H×W×(e1+e3),可以看到feature map的分辨率是不变的,变化的是通道的数量。

图3 Fire_Module
综上所述,SqueezeNet可以有效减少网络参数量,为进一步减少网络参数量并提高检测准确度,本文对SqueezeNet提出如下两种修订,以应用到C3D网络中。
(1) 因为所用网络使用的是三维卷积,所以将Fire_Module中的1×1和3×3卷积改为使用三维卷积1×1×1和3×3×3。为提高准确度,借鉴InceptionV1[11]结构,在Fire_Module的expand层中增加一个数量为e5的5×5×5卷积支路,如图4所示,输出大小为H×W×(e1+e3+e5)。这样不仅增加了网络的宽度,而且改进后的Fire_Module包含了3种不同尺寸的卷积,同时也增加了网络对不同尺度的适应性,从而提高准确度。而网络越到后面,特征也越抽象,每个特征所涉及的感受野也更大,因此随着网络深度的增加,3×3×3和5×5×5的卷积比例也会增加。

图4 基于Inception V1的Fire_Module V1
(2) 如果将网络中的卷积全部应用为上述改进后的Fire_Module V1,因为5×5×5卷积所需的计算量太大,会造成特征图厚度增大,网络参数量也会随之增加。为减少网络参数量,借鉴InceptionV3[12]结构,提出另一种方法,将Fire_Module中的3×3×3卷积替换为3×1×3卷积,在不影响网络性能的情况下,大大减小参数量,如图5所示。
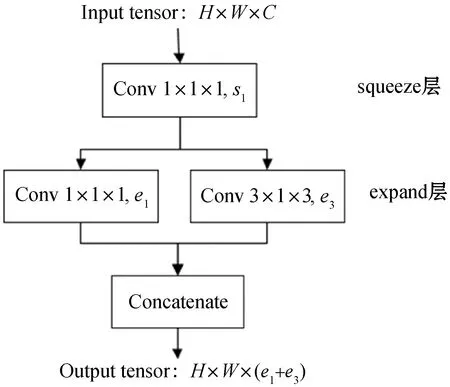
图5 基于InceptionV3的Fire_Module V2
1.3 整体网络结构
本文在C3D网络基础上,对网络结构进行调整,首先,紧跟着卷积层引入BN[13](Batch Normalization)层与short-cut结构,如图6所示。BN层在神经网络层的中间,它起到预处理的功能,也就是对上一层的输入进行归一化后,再送到网络的下一层,这样做可以有效防止梯度弥散,也可以在网络训练过程中加快网络收敛速度,加速网络训练。其次,将网络中的卷积层替换为Fire_Module V1、Fire_Module V2,如果全部使用Fire_Module V1,会造成网络参数量增大,经多次实验得出,Fire_Module V1、Fire_Module V2按图7所示进行卷积层替换,参数量会大大减小。最后,替换后的网络深度变深,为防止训练时出现梯度退化问题以及提高精度,在Fire_Module V2通道数量相同的模块之间,添加short-cut结构。

图6 Short-cut结构
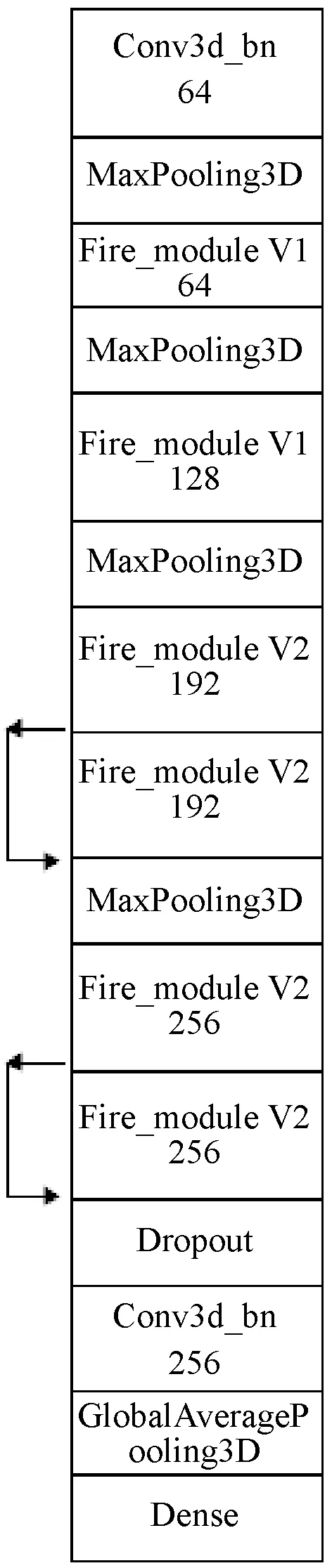
图7 整体网络结构
2 训练及测试结果
2.1 网络训练
本文在服务器上采用GPU模式进行网络训练,其中训练平台配置:Intel(R) Core(TM) i7-6700 3.4 GHz处理器;显卡为显存12 GB的NVIDIA Titan X;Ubuntu 16.04 64位操作系统;深度学习框架为Keras。使用UCF101数据集,该数据集包含动作101类,共有13 320个视频,每个视频大小为320×240。开始训练前,先将数据集中的视频转换为图片格式,按照3∶1的比例将数据集分为训练集、测试集。
如图8、图9所示,当训练约15个epoch后,网络收敛趋于平稳,约20个epoch后准确率达到97.1%。

图8 模型准确率

图9 模型丢失
2.2 测试结果
将本文提出的网络所得模型进行评估并与其他文献中的行为识别网络在UCF101数据集上进行对比,其中SqueezeNet-C3D为使用 Fire_Module V1模块的C3D网络,Improved SqueezeNet-C3D为使用Fire_Module V1和Fire_Module V2结合的网络。结果如表1所示。
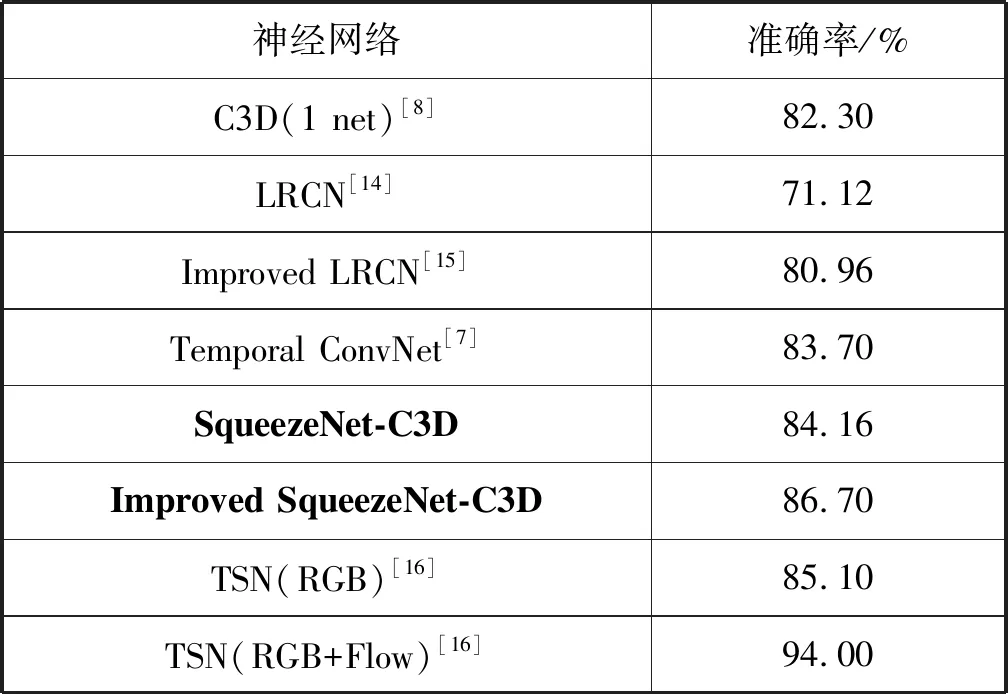
表1 与其他网络对比
Temporal ConvNet为基于深度学习的、以光流(Flow)数据作为输入的人体动作识别网络,TSN(RGB+Flow)为以光流和RGB数据作为输入的人体动作识别网络,其余为以RGB数据作为输入的人体动作识别网络。可以看到,本文提出的网络比只以光流数据作为输入的Temporal ConvNet高出3%;当以RGB图片数据作为输入时,本文提出的网络比C3D高出4.4%,比TSN(RGB)高出1.6%;但与TSN(RGB+Flow)相比,本文的识别率较低。可见当RGB信息与光流信息融合时,能有效提高识别率,表明光流信息在提升识别率中起到重要的作用。本文只以RGB数据作为输入,这也是本文提出的网络识别率比TSN(RGB+Flow)低的原因。但光流信息需要从视频帧形成,这样做会使计算量增加,所用时间也会增加,进而导致实时性变差,不利于实时检测。
本文使用改进的SqueezeNet与使用SqueezeNet网络总的参数进行对比,如表2所示。
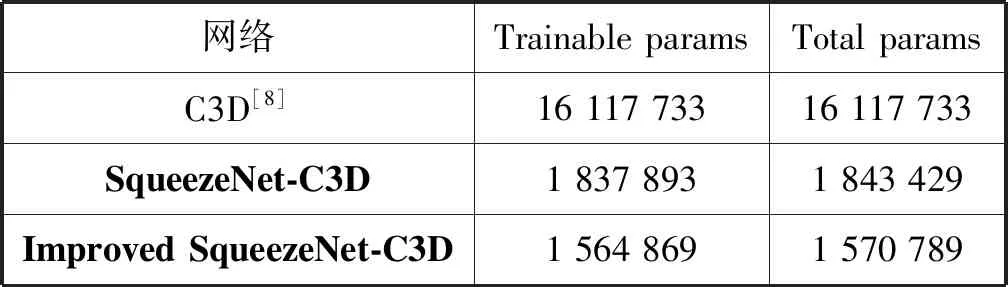
表2 网络参数对比
使用本文的ImprovedSqueezeNet-C3D网络与使用 SqueezeNet-C3D网络相比,参数量降低了15%,与C3D网络参数量相比降低了90.3%。由此可见,本文网络大大降低了对计算机硬件的要求。
3 结 语
本文采用改进的SqueezeNet与C3D相结合的卷积神经网络,引入BN层,随着网络深度的增加采用了ResNet的short-cut结构,对走路、跑步、打架、摔倒、坐、等动作进行检测识别,取得较好的检测结果,并得到以下结论:(1) 本文提出的网络提升了检测的准确度,具有较好的识别率。(2) 本文提出的网络参数量较少,降低了模型的训练及预测时间,使得网络性能在嵌入式平台(如NVIDIA JetsonTX2)上进一步提高。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
小型微型计算机系统(2021年12期)2021-12-08
导航定位与授时(2020年4期)2020-07-29
计算机系统应用(2019年9期)2019-09-24
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
科技视界(2016年18期)2016-11-03
