
面向代码设计质量监控的软件度量指标集研究
2020-03-13 10:24张海锐吴毅坚赵文耘
计算机应用与软件 2020年3期
张海锐 吴毅坚 赵文耘
(复旦大学软件学院 上海 201203) (上海市数据科学重点实验室 上海 201203)
0 引 言
随着软件技术的不断发展,软件的应用领域在不断扩大,软件的规模和复杂性不可避免地日益提升,软件模块的相互影响更加隐蔽和复杂,开发者难以做到既完成繁重的开发任务,又保证软件的可维护性。代码设计质量的不断下降给软件开发者的持续开发和维护带来了很大的挑战。人们开始重视软件的质量,并渴望采用一些可以评估软件质量的手段。软件度量是其中一种重要的量化评估手段,量化结果能够通过多种方式影响软件过程和软件产品。
目前已经存在大量的软件度量指标和工具,它们基于多种软件信息从不同角度描述软件的设计特征。对度量指标知识的缺失会阻碍开发者的实际应用[22],但是度量指标的数量众多,了解所有指标需要耗费大量时间。即使用于度量同一软件设计特征,不同指标的度量结果也可能不同,开发者难以兼顾所有度量指标结果。由于代码设计质量直接影响开发过程,开发者尤其关心与代码设计质量相关的指标,希望关注少量度量指标就能够快速定位可能存在质量问题的类,而不需要了解所有指标。
本文的贡献主要包括两方面。一方面是整理归类了现有的软件度量指标,将指标分为规模、耦合、内聚、封装、继承和多态等6方面。另一方面是分析了现有指标与代码设计质量的关系。本文收集开源项目的源代码作为分析对象,计算每个类的指标度量值,挑选出度量值为最大值或最小值的类,然后通过分析这些类的提交历史判断它们是否存在代码设计质量问题。指标与代码设计质量问题越相关,越多被挑选出的类会出现代码设计质量问题。
1 相关工作
软件度量学这一概念最早是由Rubey等[23]提出,在此之后,许多研究者在这一领域进行了大量的研究。软件度量方法主要可以分为面向过程和面向对象两种类型[12]。结构化设计是早期软件的主要开发方法,那个时期经典的度量方法包括基于代码行数的度量、基于文本分析的度量[14]、McCabe复杂性度量法[16]以及软件科学法[15]等。为了适应大规模的、复杂的软件开发,20世纪80年代出现了面向对象的设计开发方式,该方式快速得到了广泛应用,针对面向对象的度量研究也随之成为了一个研究热点。Chidamber等[1]1994年提出了CK度量集,包括了6种面向对象度量指标,可以度量继承、复杂度和耦合等软件特征。文献[8-9,17-20]分别对CK度量集的指标进行了验证和改进。Albreu等[2]提出了系统层次的面向对象度量指标集MOOD度量集,可以度量封装、继承、耦合和多态等软件特征。Harrison等[24]对MOOD度量集进行了详细的论述。Lorenz等[3]提出的LK度量方法,包括规模、继承、外在特征和内在特征四种类型的类层次度量指标,其中内在特征主要通过类的内聚度度量,外在特征主要通过类的耦合度度量。Bansiya等[21]提出了一个四层质量度量模型,通常被称为QMOOD模型,其中面向对象设计指标层提出了11种度量指标,将度量指标分为数量、层次、抽象、封装、耦合、内聚、组合、继承、多态、信息传递和复杂性等11种类型。董琳[6]综合用例模型和面向对象度量方法提出了系统对象点软件度量方法,包括了6个系统层次的度量指标,用于评估项目的工作量。
目前存在多种关于软件质量的定义,上海计算机软件技术开发中心参照McCall模型提出了SSC软件质量评价体系,定义6个软件质量特性为功能性、可靠性、易用性、效率、可维护性和可移植性[10]。面向对象度量指标集被提出后,学者常将这些度量指标与软件设计质量建立联系,使用度量指标考察软件系统的可维护性、可靠性,或者预测缺陷。Denaro等[13]的研究表明代码度量值与代码缺陷之间存在相关性。潘森等[11]通过代码度量值和缺陷库等软件开发过程中的数据监控软件质量的变化。冼伟成等[7]的研究发现面向对象度量因子值存在长尾分布,认为这些少数类的代码质量提升有利于提高软件整体的质量。
2 指标定义和分类
已有的研究文献中提出了许多不同用途的度量指标,但是对于度量指标的分类没有形成共识。本文通过对文献[1-3,5,21]的指标类别进行汇总,将度量指标分为规模、耦合、内聚、封装、继承和多态等6种类型。
“规模”描绘了类的规模大小。文献[21]中数量类型的指标反映了数据和方法的多少,复杂度类型的指标反映了复杂程度,本文认为它们都是表示规模大小的一个维度,相关指标可以被合并到规模类型。“耦合”反映了类与外部类的互相依赖程度。“内聚”反映了类内部成员的关联关系是否密切。“封装”对应于面向对象设计的封装特性,主要涉及对属性的封装和隐藏、对方法的隐藏等。文献[5]中信息隐藏类型的指标就是用于度量封装性,相关指标可以合并到封装类型。“继承”对应于面向对象设计的继承特性。文献[5]中复用类型的指标度量了子类对父类代码的复用情况,而这种代码复用依赖于继承机制的实现,本文将相关指标合并到继承类型。“多态”对应于面向对象设计的多态特性,主要涉及方法重写、抽象方法实现等。


表1 度量指标分类
2.1 指标整理
本节介绍了每种类型的各个度量指标的定义,并分别建立了每种类型度量指标的关系表。关系表中不带下划线的指标表示它属于类层次指标,带下划线的指标表示它属于系统层次指标。如果两个指标等价,它们的名称会通过左斜杠相连,如NOC/NODD。如果指标名称后面有上升箭头,表示它的度量值可能与代码设计质量有正相关关系。如果名称后面是下降箭头,则表示它的度量值可能与代码设计质量有负相关关系。例如,AC↑表示AC是一个类层次的度量指标,AC值越大的类越可能存在代码设计质量问题。
2.1.1耦合度量指标
本节介绍了10个度量耦合的指标,该类型指标为了判断两个类是否存在耦合关系,采用的方法主要是查看一个类是否访问了另一个类的属性或调用了另一个类的方法。耦合度量指标的关系表如表2所示。
表2 耦合度量指标关系表

Measure of Aggregation(MOA):聚合度量,等于指定类中属性的数据类型个数(基本数据类型除外)。
Coupling Factor(COF):耦合因子,等于系统中耦合类对占总类对的比例。如果一个类A使用了另一个类B的方法或属性,则它们组成一个耦合类对。
Direct Class Coupling(DCC):直接类耦合,等于与指定类直接相关的其他类的个数。如果指定类的属性声明或方法调用的参数中使用了其他类,则认为它们直接相关。
Coupling between Objects(CBO):对象类之间耦合,表示指定类与多少类耦合。如果一个类的实例调用了其他类实例的方法或属性,则这两个类存在耦合关系。
Changing Classes(CC):影响类数,等于受指定类影响的其他类的个数。如果指定类A的方法被其他类B调用,并且A、B之间没有血缘关系,则B受A的影响。
Afferent Coupling(AC):传入耦合。计算方式与CC基本一致,当类B与类A之间存在血缘关系时,AC会统计B,CC不会。
Number of Called Classes(FANOUT):被调用类数,表示指定类调用了多少个属于无血缘关系类的方法或属性。
Number of Coupled Classes(NCC):耦合类数。NCC表示指定类会被多少个无血缘关系类影响。对于被指定类使用的方法/属性,如果它属于与指定类无血缘关系的类,则NCC统计该类,同一个类只会被统计一次。文献[26]将该指标缩写成CBO,为了区别于已有的CBO,本文写为NCC。
Access To Foreign Data(ATFD):访问的外部数据数,表示对于指定类可以直接访问或调用访问器方法访问的所有属性,其中有多少个来自与指定类无血缘关系的类。
Foreign Data Providers(FDP):外部数据提供者数,表示被ATFD统计的属性属于多少个与指定类无血缘关系的类。
2.1.2继承度量指标
本节介绍了13个继承类型的度量指标,该类型指标的计算方式主要分为基于继承树和基于子类对父类成员的复用两种方式。继承指标的关系表如表3所示。
表3 继承度量指标关系表

Number of Children(NOC):孩子个数,等于指定类的子类个数。
Number of Direct Descendants(NODD):直接后代个数,等价于NOC。
Number of Descendants(NOD):后代个数,等于指定类的所有后代类个数。
Depth of Inheritance(DIT):继承树深度,等于指定类在继承树中与根节点的距离。对于C++等多继承的编程语言,DIT等于指定类与根节点的最长距离。
Number of Father(NOF):父亲个数,等于继承树中指定类的祖先节点个数。对于Java等单继承的编程语言,NOF等价于DIT。
Method Inheritance Factor(MIF):方法继承因子,等于系统中继承的方法占所有方法的比例。
Attribute Inheritance Factor(AIF):属性继承因子,等于系统中继承的属性占所有属性的比例。
Height of Inheritance(HIT):继承树高度,等于指定类在继承树中距离后代叶子节点的最长距离。
Inheritance Methods Per Class(IMPC):继承方法,等于指定类中继承的方法占所有方法的比例。
Measure of Functional Abstraction(MFA):方法抽象性度量,等价于IMPC。
Inheritance Attributes Per Class(IAPC):继承属性,等于指定类中继承的属性占所有属性的比例。
Average Number of Ancestors(ANA):平均祖先类个数,等于系统中所有类的祖先类个数的平均值。
Base Class Usage Ratio(BUR):复用父类比例,等于指定类使用的“遗产”占父类所有“遗产”的比例。“遗产”是指protected修饰的属性和方法。如果子类访问了父类的保护属性、调用或重写了父类的保护方法,则子类使用了该遗产。
2.1.3封装度量指标
本节介绍了6个封装类型的度量指标。一个类破坏封装性的方式包括提供可以直接访问的数据和操作。封装指标的关系表如表4所示。
表4 封装度量指标关系表
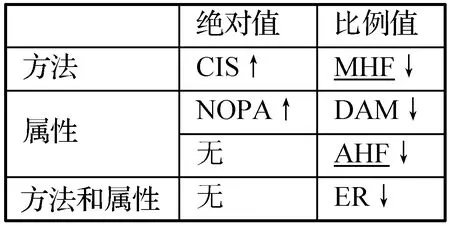
Method Hiding Factor(MHF):方法隐藏因子,等于隐藏方法占所有方法的比例。
Attribute Hiding Factor(AHF):属性隐藏因子,等于隐藏属性占所有属性的比例。
Number of Public Attributes(NOPA):公共属性个数,等于指定类中公共属性的数量。
Encapsulation Ratio(ER):封装率。假设系统类总数为N,指定类的属性和方法个数和为T。对于指定类的任意一个属性或方法,分别统计项目中有多少个类无法访问它,汇总求和得到M,则ER=M/T/(N-1)。
Data Access Metrics(DAM):数据访问指标,等于指定类中私有属性占所有属性的比例。
Class Interface Size(CIS):类接口数量,等于指定类中公共方法的个数。
2.1.4规模度量指标
本节介绍了8个规模类型的度量指标,这些指标通过统计属性的个数、复杂度,方法的个数、复杂度等方式评估类的规模。规模指标的关系表如表5所示。
表5 规模度量指标关系表

Response for a Class(RFC):类的响应集合,等于指定类收到消息时调用的方法加上该类的所有方法。
Number of Attributes per Class(NOA):属性个数,等于指定类所有属性的个数。
Number of Methods per Class(NOM):方法个数,等于指定类所有方法的个数。
Weighted Methods per Class(WMC):类加权方法,等于指定类所有方法的复杂度之和。
Weighted Attribute Argument Complexity per Class(WACC):类加权属性复杂性,等于指定类所有属性的权重之和。属性的权重等于它所属数据类型的权重,每种数据类型都有一个自定义权重。
Weighted Method Argument Complexity per Class(WMACC):类加权方法参数复杂性,等于指定类所有方法的权重复杂度之和。一个方法的权重复杂度等于该方法所有参数的权重之和。参数的权重等于其所属数据类型的权重,数据类型的权重设置与WACC一致。
Complexity Per Class(CPC):类复杂度,等于a×(NOA/NOT)+b×WMC,a、b建议设置为0.25、1。
Number of Data Type(NOT):数据类型个数,等于指定类中属性所属的数据类型的个数。
2.1.5内聚度量指标
本节介绍了4个内聚类型的指标,该类型指标主要使用相似方法对来度量类的内聚程度。判断两个方法是否相似主要通过查看它们是否使用了同一个属性。内聚指标的关系表如表6所示。
表6 内聚度量指标关系表

Lack of Cohesion(LCOM):类的内聚缺乏度,等于指定类内非相似方法对数与相似方法对数的差值,如果差值为负数,则LCOM为0。如果两个方法中使用了同一个属性,则它们组成一个相似方法对,否则组成一个非相似方法对。
Cohesion in Methods(CM):方法间内聚。基于LCOM中相似方法对的定义,P表示该类中个数非相似方法对数,Q表示该类中相似方法对数,CM=(P-Q)/(P+Q)。
Tight Class Cohesion(TCC):紧密方法内聚。基于LCOM中相似方法对的定义,TCC等于指定类中相似方法对占所有方法对的比例。
Loose Class Cohesion(LCC):松散方法内聚,计算方式与TCC相同,但是LCC认为间接使用同一个属性的方法也可以组成相似方法对。
2.1.6多态度量指标
本节介绍了3个多态类型的指标。面向对象软件中,多态分为两种情形:一个类中两个方法具有相同方法名,但方法参数列表不同;子类重写了父类中声明的方法。多态度量指标主要关注第二种情况。多态指标的关系表如表7所示。
表7 多态度量指标

Baseclass Overwriting Methods(BOvM):重写方法个数,等于被子类重写的方法个数。
Polymorphism Factor(POF):多态因子,等于系统中被重写的方法占所有方法的比例。
Number of Polymorphic Methods(NOP):支持多态方法个数,等于指定类中可以支持多态的方法的个数。支持多态方法在C++语言中就是被virtual修饰的方法,而Java语言中所有非私有实例方法都是可以支持多态的方法。
3 实 验
3.1 实验设计
不同类型的度量指标描述了软件的不同设计特征,不同的软件特征与代码设计质量的关联程度不同,可以分别进行讨论。本文提出了六个研究问题(RQ1~RQ6),与随机挑选任意类的方式相比,每种类型的度量指标能否有效找出项目中存在代码设计质量问题的类,其中哪些指标与质量问题关系最密切。
为了回答上述问题,对每种类型的度量指标,综合同一类型指标的关系表和常识判断,本文会挑选部分指标进行实验验证。对于待验证的指标,如果指标与代码设计质量存在正相关关系,选取度量值最高的前20个类;如果指标与代码设计质量存在负相关关系,则选取度量值最低的前20个类。实验分析它们未来一个月的提交信息,如果提交信息中出现了单词“fix”或“refactoring”,则认为该类涉及缺陷修复或代码重构,存在代码设计质量问题。被选取的20个类中存在代码设计质量问题的类数量越多,表示指标与代码设计质量的关系越密切。
本文实验分析的项目是一个Java开源项目:dbeaver。dbeaver是一个通用的多平台数据库管理工具和SQL客户端,支持几乎所有常见的数据库。dbeaver项目在GitHub上已获得8 700个的星标关注,开发团队主要成员都有超过20年的开发经验。项目当前仍处于活跃更新状态,社区活跃,提交历史丰富。本文选取了该项目在GitHub上最早的发布版本(3.5.2)进行指标度量值计算,该版本包含了1 560个类,203 118行代码,数量达到了一定的规模。由于dbeaver项目中版本发布的间隔约为一个月,本文只统计3.5.2版本发布后1个月之内的提交记录。项目中只有6.35%的类的提交历史中涉及缺陷修复,9.87%的类的提交历史中涉及重构,即在项目中随机挑选一个类,它有6.35%的概率与代码缺陷有关,9.87%的概率与代码重构有关。对于待验证指标挑选出的20个类,本文分别统计并计算其中提交历史涉及缺陷修复、涉及重构或者两种情况都不涉及的类的个数和所占比例。
1) RQ1:耦合度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,耦合类型的度量指标能否有效找出项目中存在代码设计质量问题的类,其中哪些指标与质量问题关系最密切?
表8分别列出了FANOUT、NCC、CC、AC和CBO度量值最高的20个类中,存在代码设计质量问题的类统计数据。其中,每项指标分别统计了涉及缺陷修复、涉及重构以及两者都不涉及的类的数量和占20个类的比例。与随机挑选的概率相比,这些指标挑选出来的类与代码设计质量问题相关的概率更大。NCC挑选出的类中涉及缺陷修复的比例最大,涉及重构的比例最大,两种情况都未涉及的比例最小,所以NCC挑选的类存在代码设计质量问题的概率最大。
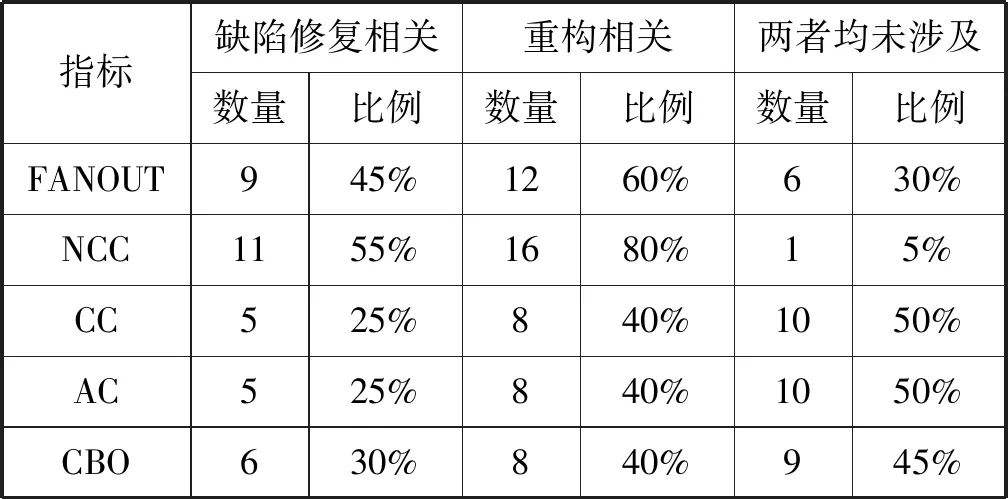
表8 耦合度量指标挑选类中存在质量问题的数量统计
ResultSetUtils是项目中NCC值最高的类,NCC值为39,说明该类依赖39个无关类的服务。在未来的一个月中,它被修改了10次,其中4次与缺陷修复相关,3次与重构操作相关。ResultSetUtils依赖的数据处理器类更新后,原来的处理方式产生了bug,因此开发者在一次提交中对它进行了缺陷修复。因为依赖类数量越多,被依赖类出现bug的概率越高,所以ResultSetUtils的缺陷修复提交较多,它的4次缺陷修复提交都来源于不同的依赖类变更。当依赖的类发生重构且服务方式发生变更时,被依赖类也会随着发生变更。例如ResultSetUtils需要调用DB2DataSource的方法,当DB2DataSource因为重构将部分功能转移到DBUtils后,ResultSetUtils也会受到这次重构的影响进行相应的修改。由于ResultSetUtils依赖的类较多,当这些类发生重构时,ResultSetUtils也可能在这次重构提交中被修改,所以ResultSetUtils会与较多的重构操作相关。这也是NCC值高的类中与重构相关的概率较高的原因。
CC/AC值越高意味着越多的外部类使用了该类的服务,该类可能是一个基础服务类。Log是CC/AC值(316)最高的类,在未来的一个月之内发生了两次修改,都是重构相关的修改。Log是日志记录类,提供了大量记录日志的方法,功能比较独立,只依赖两个外部类。与ResultSetUtils不同,Log发生的重构修改是自发的,而不是由依赖类引起的。在未来一个月中开发者通过提取代码到新方法的方式对Log进行了重构。这种基础服务类功能比较稳定,需求变更很少,常见的缺陷也早被修复。同时由于较少依赖其他类,其他类的变化很少影响到它们。因此,CC/AC值高的类中总体上发生修改的类比例较少,发生重构的类比例高于发生缺陷修复的类。
CBO可以认为是AC/CC和FANOUT/NCC的数量汇总,但AC/CC的最高值(319)远大于NCC的最高值(39)。对于度量值较高的类,指定类受外界影响的类的个数远少于受指定类影响的类的个数,所以CBO最高值的类往往也是AC/CC高的类,CBO的概率与AC/CC非常接近。
结论:实验数据表明,耦合类型的度量指标能够有效地找到项目中存在代码设计质量问题的类,其中耦合类数(NCC)与质量问题关系最密切。
2) RQ2:继承度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,继承类型的度量指标能否有效找出项目中存在代码设计质量问题的类,其中哪些指标与质量问题关系最密切?
表9分别列出了NOD值最高、HIT值最高、DIT值最高、BUR值最低的20个类中,存在代码设计质量问题的类统计数据。

表9 继承度量指标挑选类中存在质量问题的数量统计
NOD、HIT挑选的类与代码设计质量问题相关的概率略高于随机挑选的概率,DIT的概率低于随机概率。NOD统计类的后代类个数,HIT表示类在继承树中与叶子节点的最远距离。NOD值高的类一般是服务基础类,并且开发者已经基于这些基础类创建了许多子类。由于dbeaver项目已经发布了多个版本,可以认为这些基础类的功能和设计已经比较稳定,所以较少会发生修改。与NOD相比,HIT值高的类虽然也可能是基础类,但是后代类个数可能不多,修改成本比较低,可能还不稳定。例如ObjectListControl的HIT值为3,NOD值为9,在未来一个月中发生了两次修改,其中一次是修复自身的缺陷。而NOD值(76)最高的类AbstractObjectCache没有发生任何修改。
DIT度量值越高,表示类的继承链越长,理解和维护该类的代价越高[1]。实验项目中DIT值高的类由于需要实现的额外功能较少,对外界的依赖也较少,出现缺陷或发生重构的情况反而较少。例如DB2ReorgCheckTableDialog的DIT值最高,度量值为6,只依赖一个外部类,只定义了4个方法,且方法功能简单,开发者在未来一个月没有对它进行任何修改。
保护成员只可以被其定义类的子类以及所在包的其他类使用。文献[26]认为如果子类没有使用这些资源,可能意味着这个父子类设计存在问题。实验数据表明,项目中BUR为0的类不意味着父类的设计不合理,例如DB2TableColumnManager,父类的保护成员最多,数量为13个,但是开发者在未来一个月很少修改它或者它的父类,尤其没有针对继承设计的修改,原因是虽然该子类没有使用父类的任何保护成员,但是这些成员会被父类的其他子类使用,这些保护成员的设置是必要的。
结论:实验数据表明,继承类型的度量指标找出项目中存在代码设计质量问题的类的效果较差,与随机挑选的概率接近,其中继承高度(HIT)的效果相对较好,高于随机概率。
3) RQ3:封装度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,封装类型的度量指标能否有效找出项目中存在代码设计质量问题的类,其中哪些指标与质量问题关系最密切?
封装度量指标包括DAM、NOPA、CIS和ER等4个指标,信息暴露越多的类可能产生越多的质量问题。表10分别列出了NOPA值最高、DAM值最低、CIS值最高、ER值最低的20个类中,存在代码设计质量问题的类统计数据。挑选DAM值最低的类时,所有类首先按照DAM值从低到高排序,然后按照属性数量从大到小排序,因为DAM是比例值,DAM值相同的情况下,总数多的类暴露的内容越多。挑选ER值最小的类时,所有类首先按照ER值从低到高排序,然后按照属性和方法数之和从大到小排序,因为ER最小值意味着类的所有属性和方法都是公共的,它们的数量越多,类暴露的内容越多。

表10 封装度量指标挑选类中存在质量问题的数量统计
NOPA、DAM挑选的类出现代码设计质量问题的概率和随机概率相近。NOPA和DAM只关注公共属性,实验数据表明,一个类的公共属性多不表示该类会出现质量问题。例如CoreMessages是NOPA值(855)最高、DAM值(0)最低的类,它只有一个私有的空方法,855个公开静态属性和1个默认可见静态属性。CoreMessages只提供信息存储功能,任何类都能够直接读写它的属性。其他类对这些属性的不正确读写可能会造成信息交互出错,但是修复缺陷的操作不会影响CoreMessages,而是发生在它的调用者。由于CoreMessages结构非常简单,所以开发者也不会对它进行重构。因此开发者没有对CoreMessages进行任何修改。
ER挑选出的类的功能都比较简单,出现缺陷或需要进行重构的概率很低。例如MySQLConstants的ER值为0,属性和方法的总数是133,没有声明方法,只声明了公共静态属性,属性只允许读。该类存储了MySQL配置常量,开发者没有修改它。与NOPA、DAM相比,ER选择的类中包含了属性个数不是很多的数据存储类如DB2Constants,这些类可能还不稳定,在未来会随着业务的变化而被修改。当项目中的XML处理器类变化后,DB2Constants的部分属性也需要更新,否则会出现bug,这是ER挑选的类中涉及缺陷修复的比例更高的原因。
CIS挑选出的类与代码设计质量问题相关的概率最高,明显高于随机概率。公共方法数量多的类,提供的服务较多。为了提供不同类型的服务,它们对外界的依赖可能较多,发生质量问题的概率较高。由于服务类型多,当服务需求发生变化时,原有的代码可能变成了bug。例如DriverDescriptor的CIS值为86,依赖31个外部类。当这些依赖类发生变化时,DriverDescriptor可能也需要修改。当项目依赖库发生变化时,开发者通过缺陷修复的方式更新了该类的依赖解析功能。与NOPA、DAM、RER相比,CIS值高的类参与缺陷修复或代码重构工作的概率更高。
结论:实验数据表明,与随机挑选的概率相比,在封装类型的度量指标中,类接口数(CIS)能够有效地找到项目中存在代码设计质量问题的类,与质量问题关系最密切。其他指标的概率与随机概率相近。
4) RQ4:规模度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,规模类型的度量指标能否有效找出项目中存在代码设计质量问题的类,其中哪些指标与质量问题关系最密切?
规模度量指标包括了NOA、NOM、WMC、CPC、WACC、WMACC、NOT等指标。由于WMACC和WACC完全依赖于数据类型的权重设置,而相关文献中数据类型都来源于C++,不能完全对应Java项目的数据类型,本文不作分析。剩余指标中CPC由NOA、NOT和WMC运算得到,同时考虑了方法体和属性。
本文选择CPC进行分析,度量值最高的20个类中发生了缺陷修复的类有7个(占35%),发生了重构的类有7个(占35%),这两种情况都没有发生的类有9个(占45%)。相对于随机挑选的概率,CPC挑选的类与代码设计质量问题相关的概率明显更大。一个类的复杂度越高,与外界的交互越多,代码的可读性越低,出错的概率也越大。例如DBUtils的CPC值为324.42,在未来一个月内被修改了14次,其中与缺陷修复相关的次数为2次,重构相关的修改次数为5次。开发者在该类的开发和维护花费了较多的时间和精力。出现bug的原因是代码分支跳转逻辑比较复杂,开发者忽略了跳转语句的某些分支情况。复杂代码的低可读性会增大bug产生的概率,为了降低这种不良影响,开发者在缺陷修复的过程中增加了断言语句并将长语句变成多条短语句。DBUtils对外部类依赖较多,数量达到56个,这些类发生重构时可能会导致DBUtils进行相应的修改,所以DBUtils的重构相关提交较多。
CPC值高的类中缺陷修复和重构都没有发生的原因是被挑选的这些类整体复杂度高,但是成员并不复杂。例如JDBCResultSetImpl的CPC值为229.33,包含了210个方法,其中200个方法都是方法体代码行数为1、2的简单方法,没有复杂度高的方法。这些简单方法的复杂度为1,它们的复杂度之和提供了主要的复杂度。开发者没有对它们进行代码修改。
结论:实验数据表明,与随机挑选相比,在规模类型的度量指标中,类复杂度(CPC)能够有效地找到项目中存在代码设计质量问题的类,与质量问题关系密切。
5) RQ5:内聚度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,内聚类型的度量指标能否有效找出项目中存在质量问题的类,其中哪些指标与质量问题关系最密切?
内聚度量指标包含了LCOM、CM、TCC和LCC。LCOM无法判断相似方法对的数量是否远多于非相似方法对,CM改进LCOM并解决这个缺陷。根据指标定义,CM=1-2×TCC,可以认为两者本质上相同。TCC=0、LCC=0代表内聚度最差的类,根据指标定义,TCC为0当且仅当LCC为0,所以在找出内聚度最差的类方面,两者完全等价。因此,本文只对TCC进行分析。
挑选TCC值最低的类时,首先将类按照TCC值从低到高排序,然后按照NCC值从高到低排序,选取最前面的20个类。这些类的TCC值都为0,其中涉及了缺陷修复的类有6个(占30%),涉及了重构的类有7个(占35%),这两种情况都没有发生的类有11个(占55%)。TCC挑选的类与质量问题有关的概率高于随机概率。NCC值越高,类承担的职能可能越复杂,越可能出现质量问题。例如GenericMetaModel的NCC值是24,其中loadProcedures方法中调用的外部方法最多,它是职能最复杂的方法,开发者的缺陷修复发生在该方法。由于类依赖的外部类数量较多,当这些类发生重构变化时,类也需要修改。
而NCC值低的类,它们的方法虽然互相独立,但是方法的功能一般很简单,类比较稳定,所以修改较少。例如DB2TableColumn的方法基本都是访问器方法,对外界依赖程度小,使用简单,出错概率低。CommonUtils的所有方法都是静态方法,每个方法完成一个小功能,提供对字符串、集合类、链表等类型数据的简单操作。开发者对这些类的修改很少。
结论:实验数据表明,与随机挑选相比,在内聚类型的度量指标中,紧密方法内聚(TCC)能够有效地找到项目中存在代码设计质量问题的类,与质量问题关系密切。
6) RQ6:多态度量指标与代码设计质量的关系。
问题:与随机挑选任意类的方式相比,多态类型的度量指标能否有效找出项目中存在质量问题的类,其中哪些指标与质量问题关系最密切?
类层次的多态度量指标包括NOP和NMO/BOvM,NMO/BOvM是NOP的子集。NOP值最高的20个类中,涉及缺陷修复或重构的类分别有4个(占20%)、5个(占25%),这两种情况都没有发生的类有13个(占65%)。NOP挑选的类与代码设计质量问题有关的概率高于随机概率。对于实验项目,NOP等于非私有实例方法的个数。NOP值越高表示方法数量越多,需要完成的工作越多,对外界的依赖可能越多,类参与缺陷修复或代码重构的概率较高。例如DataSourceDescriptor的NOP值为80,依赖28个外部类,发生了4次修改,其中3次与重构相关。由于依赖类发生了重构,它也随之发生了修改。
结论:实验数据表明,与随机挑选相比,在多态类型的度量指标中,支持多态方法个数(NOP)能够有效地找到项目中存在代码设计质量问题的类,与质量问题关系密切。
3.2 有效性威胁分析
内部有效性:本文通过分析提交信息中是否包含单词“fix”或“refactoring”来判断该次提交是否与缺陷修复或重构相关。如果开发者在某次提交中进行了这两项工作却没有在提交信息中提及,或者提交信息中没有使用这两个单词,那么这次提交就会被认为是一次普通的提交。本文的实验对象dbeaver项目的开发人员经验丰富,遵循开发规范,提交信息中都会对本次提交的工作进行总结,而“fix”和“refactoring”是他们总结缺陷修复和重构工作的常用词,上述情形出现几率较低。
外部有效性:本文的实验项目只包含了一个项目,分析数据相对较少,需要更多的项目数据支撑。不同类型的软件可能由于存在不同的业务特点,对不同的度量指标敏感度不同,本文实验分析结果在不同类型的软件上可能不适用。
4 结 语
本文将度量指标分为规模、耦合、内聚、封装、继承和多态等6种类型。对于不同度量指标,选取了20个度量值为最大值或最小值的类进行分析,其中存在代码设计质量问题的类的数量多少代表了指标与代码设计质量的关联程度。实验分析发现,耦合类数(NCC)、类接口数(CIS)、类复杂度(CPC)、紧密内聚度(TCC)、支持多态方法数(NOP)、继承树高度(HIT)分别是耦合类型、封装类型、规模类型、内聚类型、多态类型、继承类型的度量指标与代码设计质量关系最密切的指标,可以更有效地找出存在代码设计质量问题的类。
在未来的工作中,可以把这些度量指标应用在不同类型的软件上,观察它们是否在不同软件上都适用。不同类型的软件可能由于存在不同的特征,对不同的度量指标敏感度不同。这些度量指标也可以被用于对项目质量的持续监控,结合项目的演化历史分析,可以通过度量值的变化提醒开发者项目的质量变化趋势。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
小学生学习指导(低年级)(2021年9期)2021-10-14
小学生学习指导(低年级)(2019年9期)2019-09-25
江西教育B(2019年2期)2019-04-12
学生导报·东方少年(2019年27期)2019-01-14
中国诗歌(2018年6期)2018-11-14
小学生学习指导(低年级)(2018年9期)2018-09-26
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
