
基于重复数据删除技术的雾存储数据去冗余方案
2020-03-11 13:17陈思佳
计算机应用与软件 2020年2期
陈思佳 温 蜜 陈 珊
(上海电力大学计算机科学与技术学院 上海 200090)
0 引 言
当今社会数字化信息呈爆炸式增长,《数据时代2025》白皮书中预测,2025年全球的数据量将达到163 ZB,是目前的10倍之多。数据量的剧增和泛滥对数据存储管理技术提出了巨大的挑战,如何高效地管理和存储数据已成为研究热点。微软[1]和EMC[2-3]生产的主存储系统和二级存储系统中,分别有50%和85%的冗余数据,随着时间的推移,冗余数据的比例也会成倍上升,企业在存储这些的数据时所需要的开销也是巨大的。
如此庞大的数据对传统存储系统提出了挑战。于是技术人员将目标转向容量更大,成本更低廉的云存储系统。云存储架构集成了大规模用户数据,数据中会存在许多重复数据,因此数据去重对于维护数据开销具有重要的意义。
根据IDC最近的一项研究[4]表明,目前近80%的企业正在寻求存储设备的重复数据删除技术,从而消除设备中的冗余数据。重复数据删除技术是一种数据缩减技术,在单机设备和云平台中都有广泛应用,其主要作用于文件内部和文件之间的冗余数据,通过与源数据进行对比,删除相同的数据块(文件),达到在磁盘中存储更多数据的目的。在工业界Datadomain的DDFS、IBM Diligent、EMC的Avarma、Veritas的PureDisk以及Commvault的Simpana都是比较知名的重复数据删除产品,这些产品通常可以达到20∶1的重复删除率。数据分块和指纹管理是控制重复数据删除性能的流程中关键的技术部分。传统的重复数据删除模块是将数据流进行分块,分块的方式有多种:可变大小的分块(CDC)、固定大小的分块(fixed-size partion)以及两者的混合,即滑动分块(sliding block)。根据哈希函数(MD-5或SHA-1)计算每个数据块的Hash值(我们称之为指纹),与已有指纹表中的指纹进行对比,判断是否为重复数据块。这一系列的指纹查询操作会导致指纹表在内存中的随机读取,每次读取都存在磁盘访问,从而增加输入和输出(I/O)。
云存储采取的是数据外包模式,许多云服务提供商为了降低成本,往往会将数据中心建立在低成本的偏远地区,当云服务器距离客户较远时,必然会增加数据传输延迟。传输过程中的重复数据也会占用大量的网络带宽,造成数据中心和移动端的I/O瓶颈。据最新研究结果显示,在各类云存储产品中数据的重复率达到60%,庞大的重复数据对云中心去重同样造成很大压力。
为了解决现存的云存储去重问题,并且满足物联网发展的需求,便产生了一种新的体系结构。即在终端和云数据中心之间加入网络边缘层,配上带有存储功能的小型服务器或路由器,将不需要放到云端的数据在边缘层直接进行处理和存储。其主要思想是将一些数据中心的任务迁移到边缘服务器,目的是减少云端去重压力,提升数据传输速率,从而快速响应底层设备的需求,减少用户响应时间,降低时延,由此便诞生了“雾计算”[5]。
雾作为一种小型“云中心”,对附近的移动终端用户或边缘用户的数据进行存储、通信、控制、管理和测量。与云存储不同的是,雾节点处理大多是无需放在远端云数据中心的用户经常访问的数据。随着连接雾节点的移动终端不断变化,在雾节点中同样存在存储过程中产生的数据冗余问题。目前大部分去重方案为云数据中心这种分布式环境,去重对象多为数量较为庞大的数据,用来满足云数据中心下按需分配、弹性增长、快速部署等方面的要求。对于雾环境中轻量级存储设备目前还没有提出重复数据删除方案。因此,本文主要针对雾节点中的轻量级服务器提出了重复数据删除方案[6],在数据指纹的生成和查询两个关键技术上,对于雾服务器中频繁访问的数据在内存中建立数据查询机制。方案的贡献有以下几方面:
(1) 为了实现高效查询,针对雾节点中访问频率较高的数据,在内存中构建索引表,每个索引值对应的红黑树作为存储数据指纹的结构,减少磁盘与内存间的I/O,提高查询速度。
(2) 为解决计算数据指纹时产生的Hash冲突问题,利用循环冗余码(CRC)技术判断具有相同数据指纹的数据块是否重复,并将冲突数据块用链表结构存储在指纹节点中。
(3) 为防止系统的突然崩溃,提出在内存中持久化保存指纹表,分为内存某一时刻的映射文件和记录更新的日志文件。通过固定时刻刷新内存将内存中的指纹表永久保存在磁盘的映射文件中,新的数据指纹插入时,将更新情况记录在日志文件中。一旦系统崩溃重启,内存中的数据会消失,此时磁盘中的两个文件合并重新构建内存中的指纹表,同时两个文件内容清空重新记录。
1 预备知识
1.1 去重相关研究
重复数据删除研究过程主要包括基于粒度的划分、指纹的查询、数据去冗余的时机。
Won等[7-8]发现分块是重复数据删除过程的主要开销之一。基于粒度的重复数据删除技术包括基于文件级的、块级的[13-14]和字节级的。基于文件级的情况比较少见,只有当两个文件内容完全相同时,才能利用去重技术删除,所以这种方式的去重率很低。基于字节级的方式在数据量非常庞大的情况下,显然也是不现实的,这种方式会耗费过多CPU资源,运算效率不理想。基于块级的粒度是目前应用最广泛的,散列值(MD-5,SHA-1等)可以作为唯一块的标识,概括数据块的内容,无需对数据块进行读取,从而提高查询速度。
在指纹管理方面,也提出了许多方法。第一个方案就是Bloom等[9]提出的主存储过滤器,即布隆过滤器(Bloom Filter)。Bloom Filter由k个散列函数和m位的数组构成,当插入n个元素时,只需要判断该元素通过k个Hash函数映射在数组的点是否为1,若k个点都为1,则表示存在,否则不存在。其好处在于在查找指纹是否重复时可以避免不必要的磁盘I/O,同时Bloom Filter占用空间小,所以广泛应用于备份[10]、分布式文件系统[11]和Web代理[12]。但Bloom Filter存在假阳性,即返回的结果不一定正确,存在概率性。误报率如下式所示:
(1)
另一种方案就是指纹表存放数据指纹。利用传统搜索结构,例如B+树或散列表,查找序列中的相邻指纹不可能以聚类方式存储,这样就会导致指纹的随机读取,导致查询效率降低。
数据去冗余的时机一般分为3种:先备份再去重策略(Deduplication Ater Backup strategy,DAB)、先去重再备份策略(Deduplication Before Backup strategy,DBB)和边备份边去重策略(Deduplication During Backup strategy,DDB)。DBB在传输前将数据进行去重,可以有效提高传输效率,节省带宽。
1.2 数据结构分析
对于在内存中的查找结构中,平衡二叉树是使用较为广泛的检索树。AVL树和红黑树都是平衡二叉树的一种,与AVL树相比,红黑树可以确保没有一条搜索路径会比其他路径长2倍,因而是近似平衡的。所以相对于严格要求平衡的AVL树来说,它保持平衡的插入和删除旋转次数较少,从而保证了系统运行时间,总体性能优于AVL树。AVL树与红黑树性能对比如表1所示。
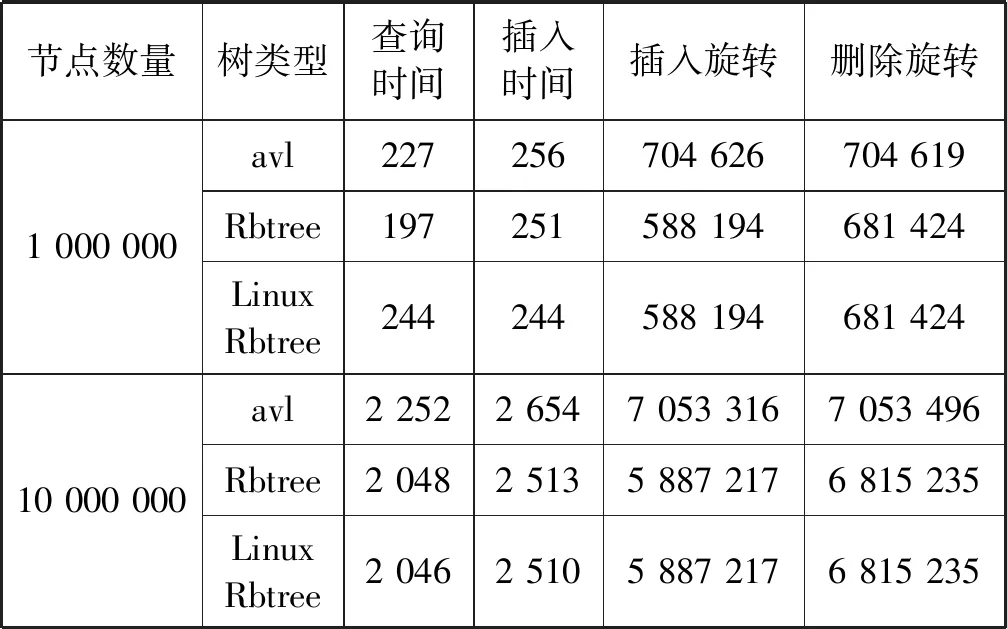
表1 AVL树与红黑树性能对比
2 系统模型
雾计算框架如图1所示,结构分为三部分:移动终端区、雾计算区和远端云计算区。雾计算位于云服务器和移动终端之间。作为云节点的服务者,移动终端区的执行者,雾计算在框架中为上下两层服务,起到了承上启下的作用。
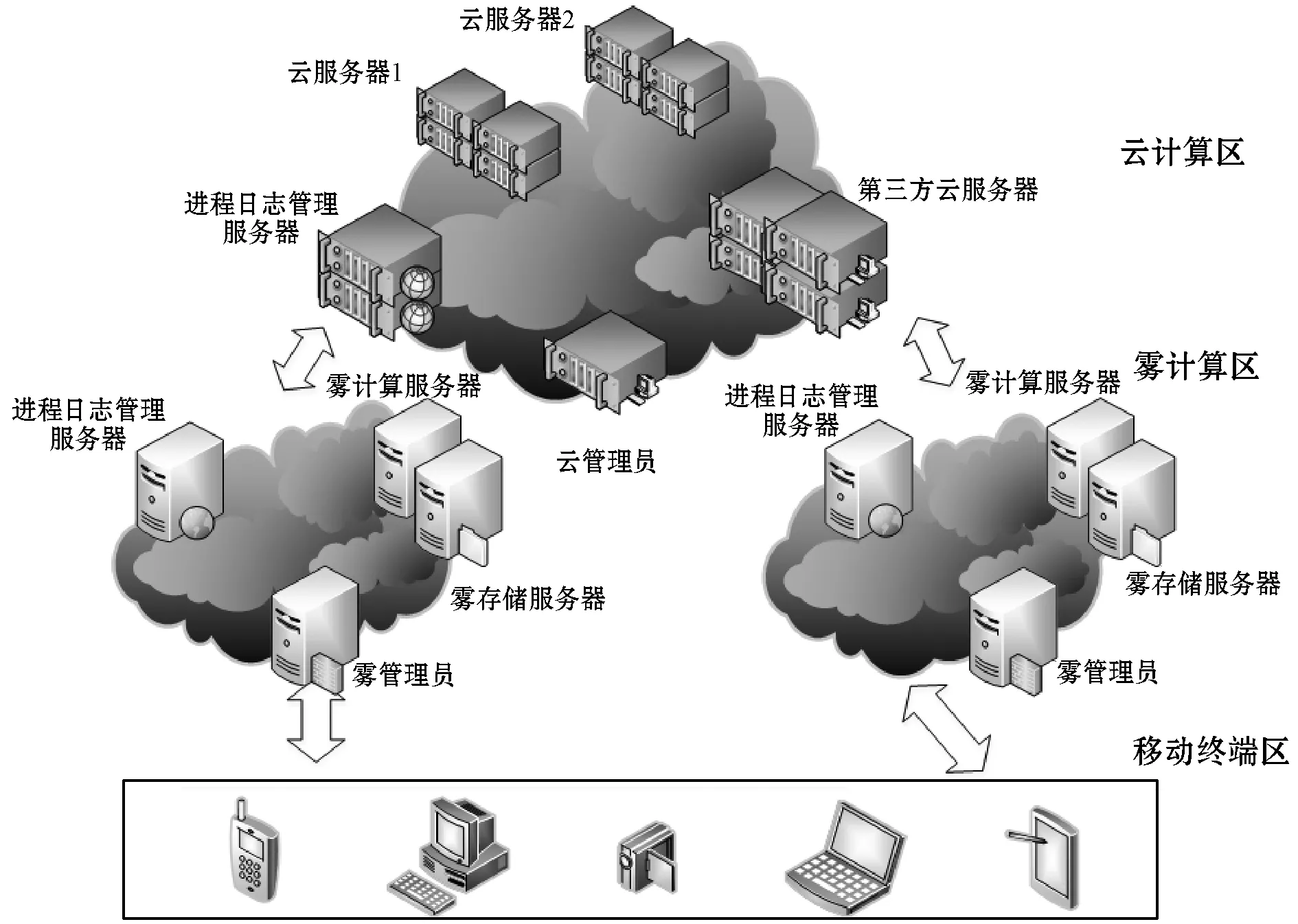
图1 系统结构图
系统结构三个部分的作用如下:
• 移动终端区:移动可连接局域网络设备,如手机、电脑、平板电脑、智能手表等。
• 雾计算区:考虑到轻量级移动设备的有限存储空间和计算能力,雾计算区接收来自移动终端的请求/服务,处理和存储无需放在云端的少部分访问频繁的数据。每个雾计算区由雾管理员(Fog Manager)、进程日志管理服务器(Services Logging Server)、雾计算服务器(Fog Computing Server)和雾存储服务器(Fog Storage Server)四部分构成。其在雾节点中的功能如表2所示。

表2 系统组成成员
• 远端云计算区:大规模虚拟化的计算机集群,接收来自雾计算区的请求/服务。当雾计算区没有可用虚拟机容量处理终端区的请求服务时,会将服务委托给云计算。云数据中心将请求分配给有足够容量完成服务的其他雾节点服务器。作为系统的上层结构,其成员功能与雾计算区大致相同。但云数据中心作为由大量服务器聚合而成的高可靠性、高拓展性的资源共享池,其接收到的用户请求远超小规模的雾节点。故云节点还包括了第三方云服务器,其功能如表2所示。
进程日志管理器中的两个记录雾节点进程和当前虚拟机可用容量的两张列表内容的样例,如表3、表4所示。

表3 虚拟机资源占用表
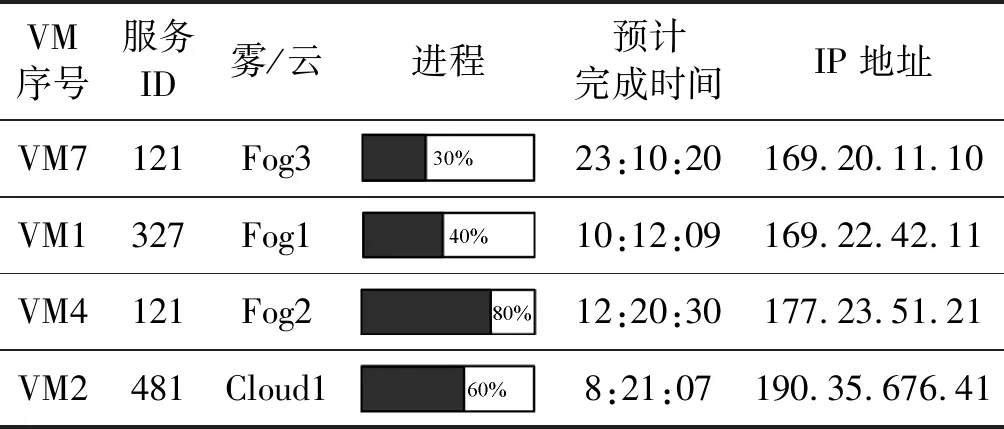
表4 服务(请求)进程表
雾计算[15]的理念是将一些轻量级的智能处理设备部署在靠近移动用户的地方,方便用户可以在比较近的距离范围内直接连接雾服务器,通常雾服务器与用户是一跳(one-hop)的通信距离。雾节点存储和处理的数据多是在一定的距离内用户经常访问的数据,将这些数据存储在雾节点中,用户无需将任务请求发送到远端的云数据中心进行处理,这样避免了发送过程中产生的网络延迟,进而提升数据传输速度,减少云服务提供商的计算压力。
购物中心作为人流量较大的公共场所,用户对与商场有关的购物信息会有较高的访问频率,包括餐厅的类型、位置、用户评价,品牌商店的购物信息、位置、产品价格等。将购物中心的详细信息放到云数据中心,让顾客通过手机实时获取云端上存储的商场信息是一种可行方案,但是存在不足之处。首先用户通过手机访问云端具有不稳定性,会受到信号的影响,而且云端信息需要经过网络多路转发才能到达用户,会影响用户的服务体验。如果在商场的每个角落里部署雾服务器,用户在访问这些数据时就会避免查询延迟、信号弱等情况,提高了用户的购物体验。
3 基于雾存储的去重方案
雾存储中的数据通常是用户经常访问和查询的,针对这些高访问频率的存储数据,雾存储系统中同样存在同一文件的多个副本,以及文件中出现重复数据块的问题。目前已经提出许多有效的重复删除机制来解决文件冗余副本问题。这些方案通常解决的是分布式云存储中数据量达到PB级以上的数据,大规模的数据直接导致指纹表增大。庞大的指纹表读取时只能将一部分内容置入内存,只有置入的部分得当,才能保证查询的命中率,并且这种方式会占用大量的随机磁盘访问。为了防止磁盘的随机访问,我们提出将雾计算中访问频繁的数据指纹表保存在内存中进行读取,这样可以减少磁盘I/O。利用红黑树作为数据指纹表结构,提升查询效率。
3.1 方案流程
本文提出的数据指纹查询方案,将完整的指纹表保存于内存中,将非重复数据块置于磁盘中。当判断数据指纹是否重复时,可以直接在内存中进行查询,无需磁盘I/O读取。若指纹表中没有相同指纹,即为非重复数据块指纹,插入指纹表中。若指纹表中存在相同指纹,将该指纹的数据块与指纹表中相同指纹对应的数据块的循环冗余码(CRC)进行比较。如果不同,判断该数据块为非重复数据块,保存在该指纹的数据块链表中;反之,返回该数据块的地址指针。方案流程如图2所示。
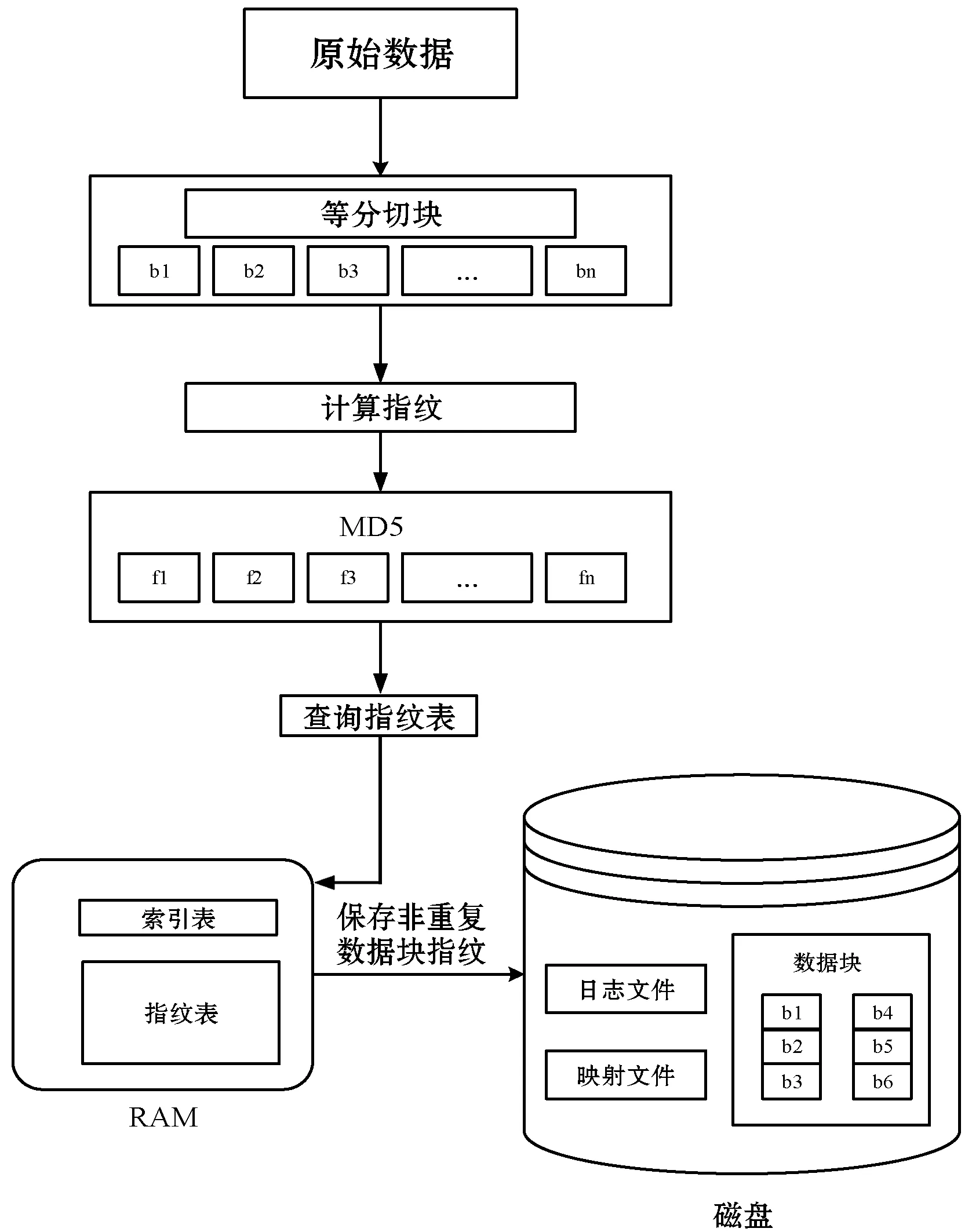
图2 方案流程图
3.2 索引表
通过将数据指纹进行哈希计算得到索引值(由0到n构成的整数)。将数据分成非重叠等分数据块b1,b2,…,bn。运用MD5哈希算法计算每个指纹,f1=h(b1),f2=h(b2),…,fn=h(bn)。将数据指纹再次进行哈希计算,得到整数型索引值,i1=h(f1),i2=h(f2),…,in=h(fn)。用户查询冗余数据块时,计算该数据块的索引值,查询该索引值下的指纹表。遍历索引表的时间复杂度为O(1),索引表如图3所示。
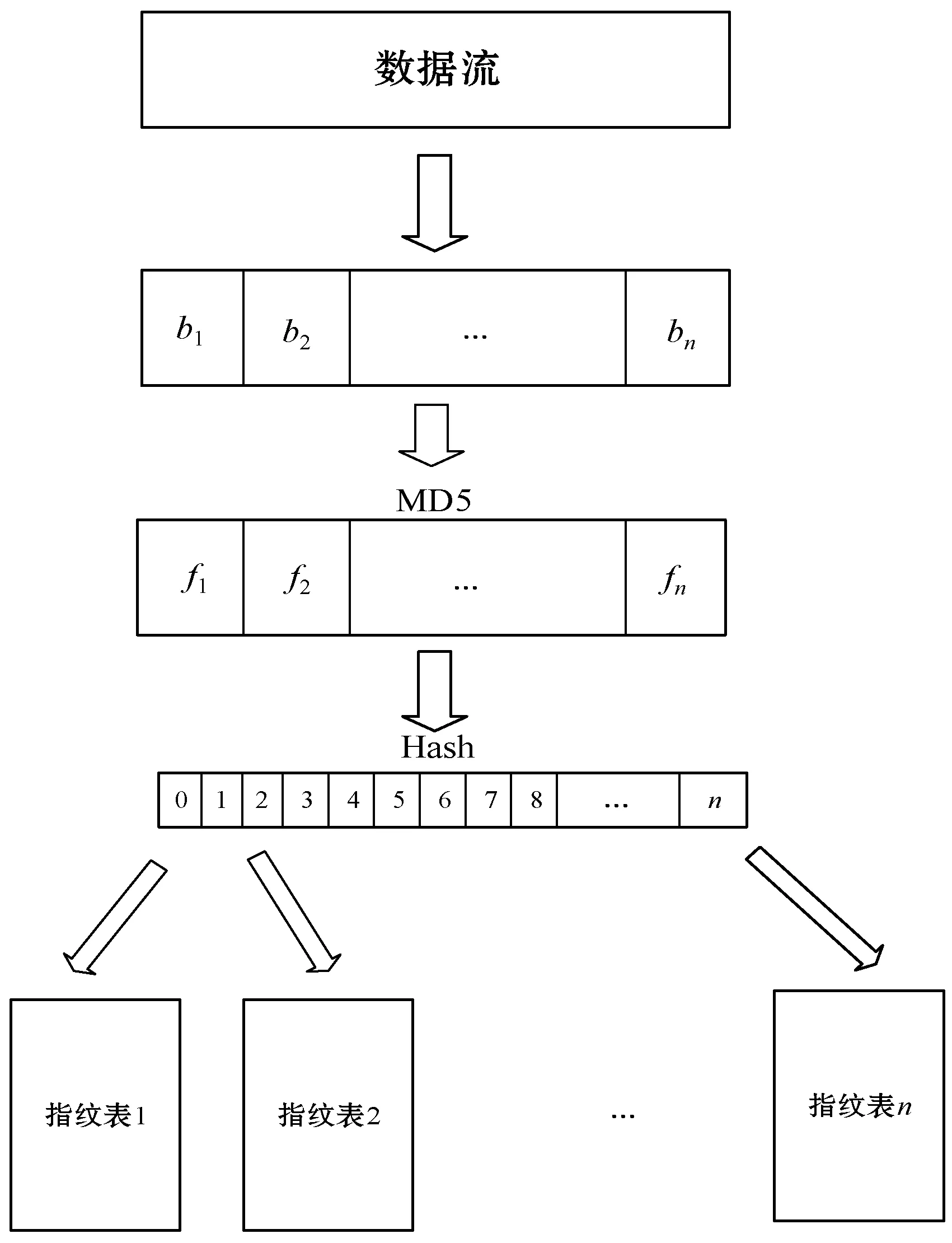
图3 索引表生成
3.3 基于红黑树的指纹查询
红黑树作为数据指纹的搜索结构,与其他在内存中的数据结构相比,具有较低的时间复杂度。与在磁盘中的数据结构相比,查询过程中降低了磁盘I/O读取,加快查询速度。遍历红黑树,找到数据块指纹的所在地址,避免存在哈希冲突情况,在计算数据块指纹的同时,计算出数据块的循环冗余码附加在数据后面。当出现数据指纹相同的情况时,比较数据块的CRC。若相同,表示该数据块重复;否则,存在哈希冲突,将数据块保存在其指纹的链表中(链表中保存的是指纹相同的不同数据块)。若没有找到与该数据块指纹相同的指纹,则数据块为非重复数据块,将其插入在相应的红黑树节点中。红黑树的指纹插入和查询过程如图4所示。
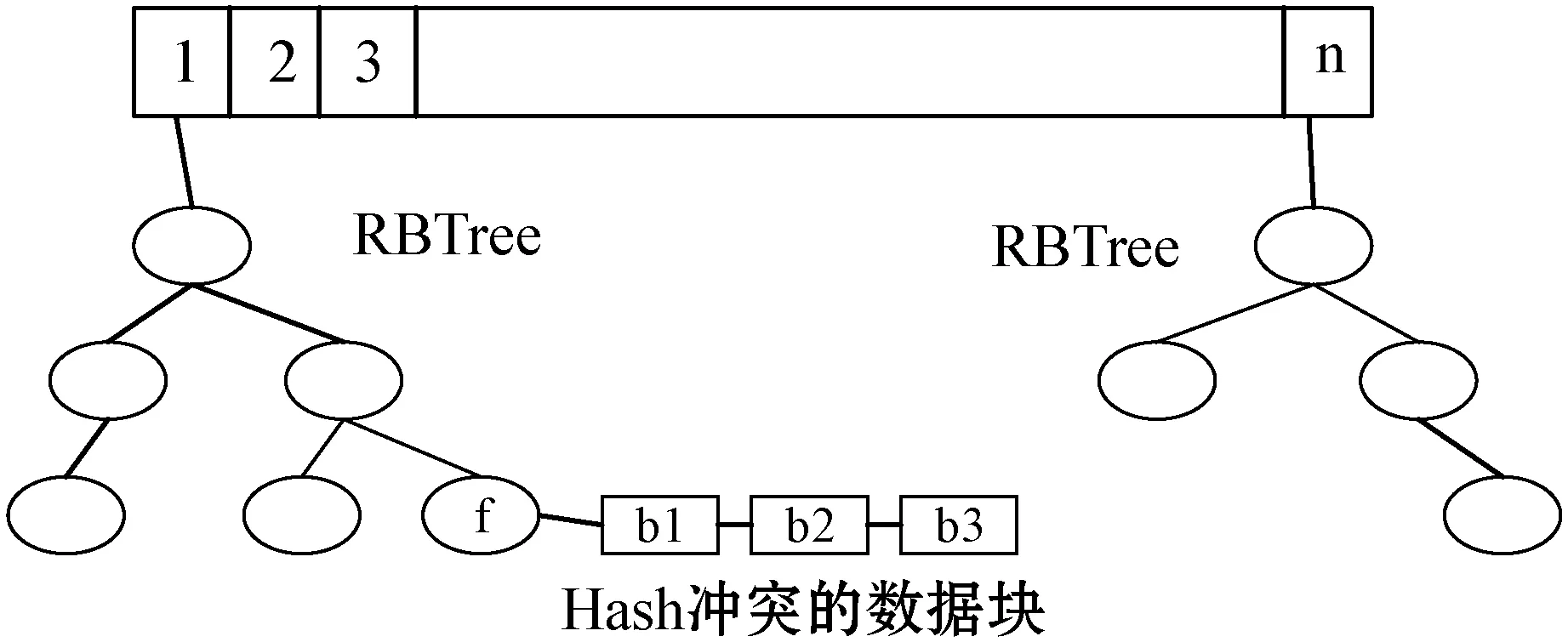
图4 指纹的插入与查询
3.4 内存中持久化保存指纹表
为了保证数据结构在内存中的持久性,防止操作系统在崩溃状况下内存中数据消失,指纹表原有的数据信息通过映射的方式写入映射文件,在对数据指纹表做更改前,将数据指纹的插入操作信息写入日志文件。由于日志是立即持久化的,可以作为恢复其他所有持久化结构的可靠来源。当系统发生崩溃,内存中的内容消失,此时再次启动映射文件和日志文件中的内容合并成新的数据结构存入内存中,清空文件内容,新的指纹表映射到映射文件,日志文件记录下一次的数据变更,为数据提供容灾保障。
算法1介绍了数据流等分块的过程。将数据流作为去重系统的输入,根据设置的数据块大小(size)将数据流进行等分切块,将等分后的数据块传入列表中输出。
算法1数据流定长分块
输入:数据流
数据流长度:len
等分数据块的大小:size
begin:
list=[]
count=len/size+1
//等分的数据块数量
for i in count do
将等分后的数据块依次放入list中
end for
end
输出:list={b1,b2,…,bn}
//每个数据块的首地址
算法2介绍了指纹和循环冗余码的生成过程。等分后的数据块作为输入。MD5、SHA-1、SHA-256都是目前较为常用的散列算法,我们选择生成指纹较小的MD5算法,得到f1=h(b1),f2=h(b2),…,fn=h(bn)。我们选择应用最广泛的crc32作为循环冗余码的生成公式,得到的CRC值附加在数据后面。
算法2生成数据指纹和CRC
输入:等分后的所有数据块bx
数据块数量:num
指纹生成公式(MD5):h
CRC生成公式:crc32
begin:
for j in num do
数据指纹fx=h(bx)
CRC码cx=crc(bx)
end for
end
输出:数据块指纹fx和CRC码cx
算法3介绍了索引表的生成以及指纹的插入、查询过程。MD5算法得到的数据块指纹作为输入,重哈希确定索引表中索引值的位置,遍历索引值对应的指纹表,若没有相同的指纹,确定该数据块为非重复块,指纹插入指纹表中。若存在相同指纹,通过比较数据块的CRC值判断是否存在哈希冲突情况,如果两个数据块的CRC值相同,则为重复数据块,返回其数据块所在地址指针,反之,则为非重复数据块,将该数据块插入其指纹所在的链表中。
算法3生成索引表和指纹插入、查询
输入:生成的数据指纹fx
数据指纹数量:n
索引表的索引数量:m
索引值对应的红黑树:T
计算索引的二次哈希公式:h1
CRC生成公式:crc32
begin:
索引值ix=h1(fx) % m
for i in n do
for j in m do
if fxin T(ix) then
//T(ix) 表示索引ix对应的红黑树
if crc32(fx)==crc32(T(fx)) then
//T(fx)表示红黑树中指纹fx连接的数据块,返回数据块所在
//地址指针
else
判断为非重复数据块,将指纹插入指纹表中,存入数据块
end if
else
判断为非重复数据块,将指纹插入指纹表中,存入数据块
end if
end for
end for
end
4 实验分析
实验运行平台为Windows 10系统,Intel core i5 CPU,8 GB内存,处理器速度2.30 GHz,使用Python编程实现。实验使用名为gcc-3.4.1和emacs-20.7的数据集,分别为19.4 MB、34.1 MB。指纹搜索效率通过计算搜索一个指纹所需的时间即查找延迟来判定,对数据进行10 KB、100 KB、1 MB、10 MB定长分块。在这两个数据集上对比Prefix indexing与DeFog,结果如图5、图6所示,可以看出,DeFog指纹搜索效率分别提高54.1%、38.78%。
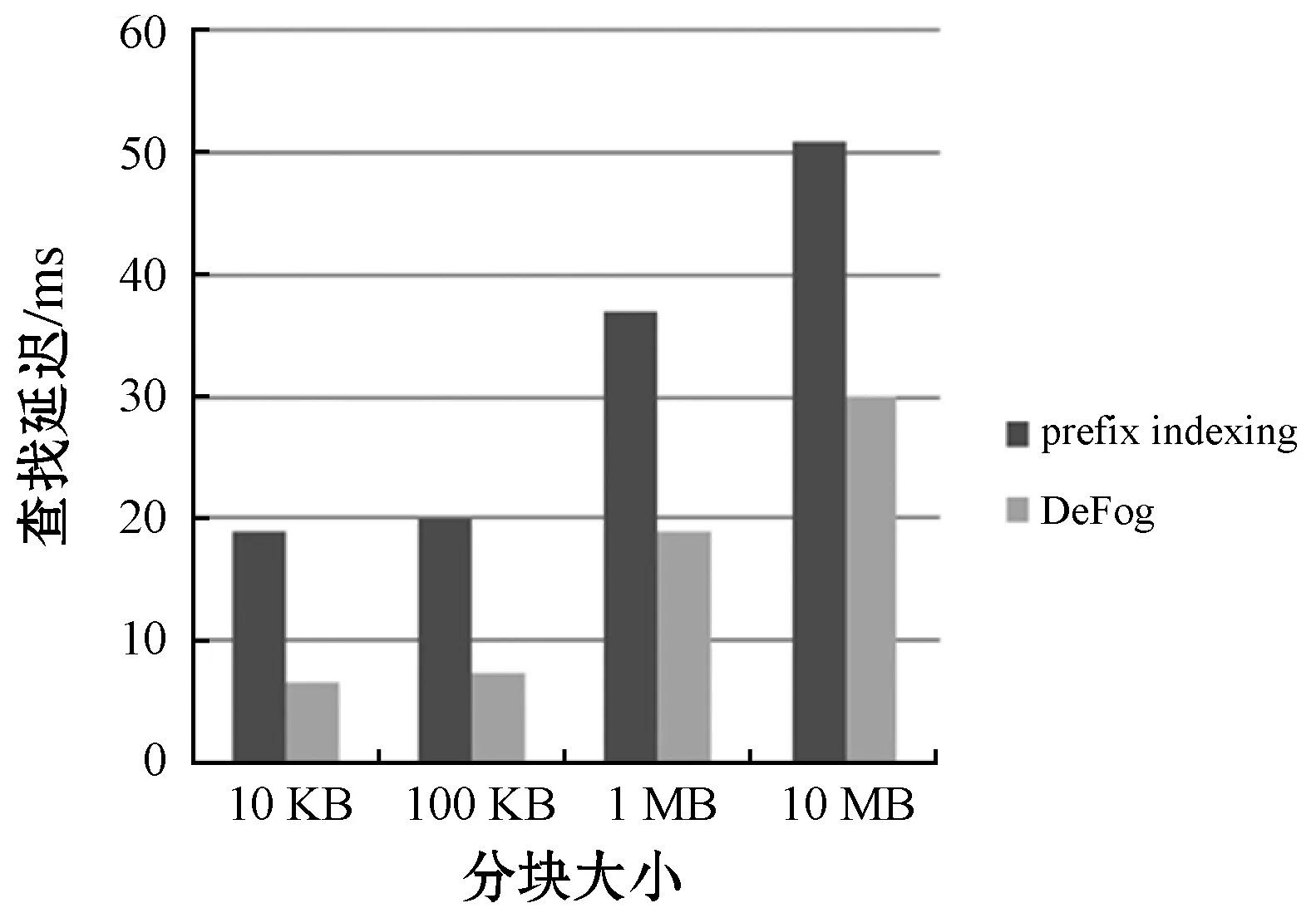
图5 emacs-20.7指纹查询时间
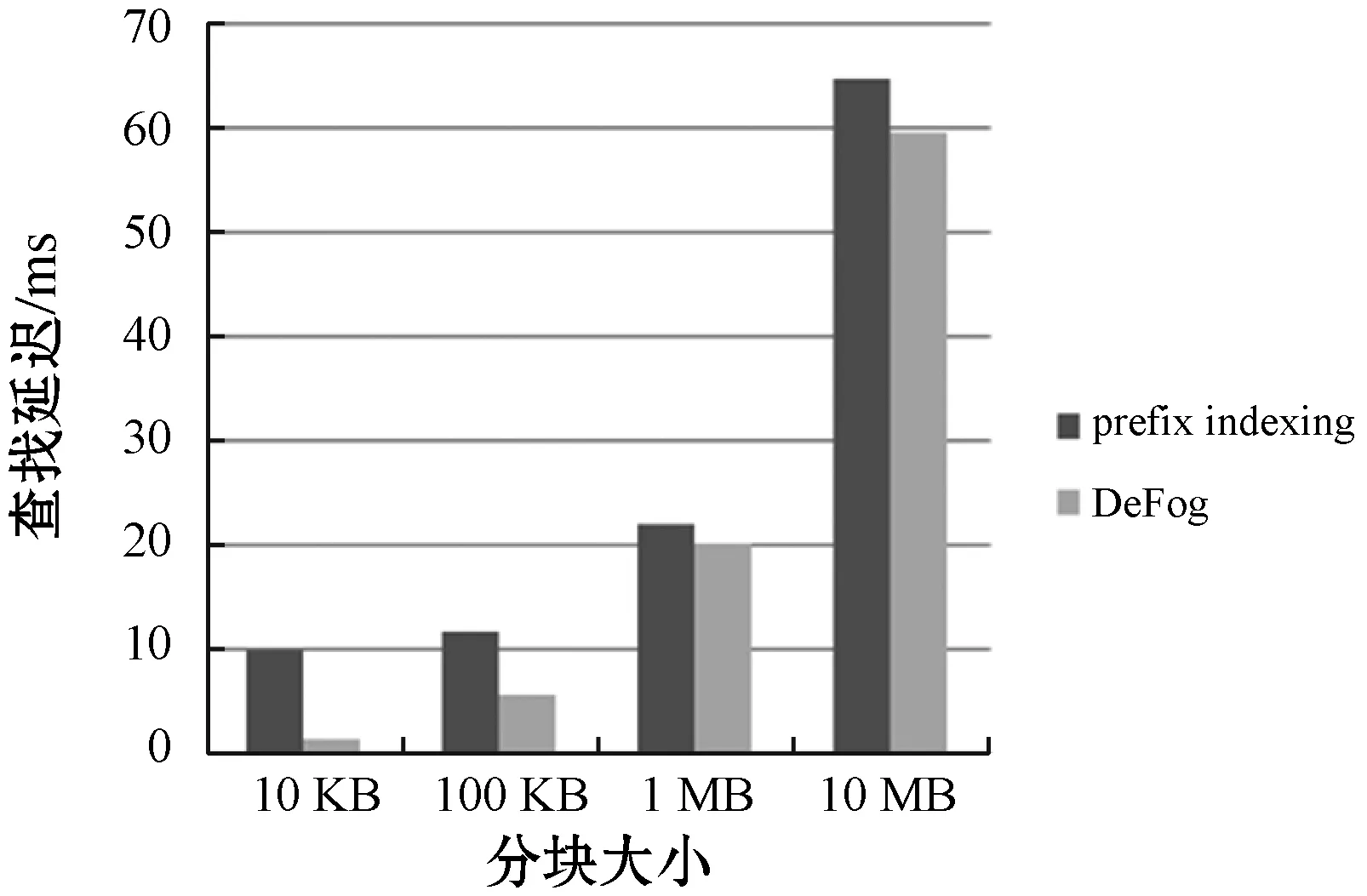
图6 gcc-3.4.1指纹查询时间
雾计算作为云计算的边缘延申,目前没有针对其存储数据的去重方案,DeFog根据雾环境的特征,对已有的prefix[13]方案进行了改进。DeFog减少了磁盘I/O,在不同的分块情况下,查询时间都有一定的减少。数据块为10 KB时,gcc-3.4.1数据集的查询速率从9.8 ms降至1.21 ms,效率提高了87.7%。随着分块大小增加,数据块的个数减少,两方案的查询时间趋于相同。
图7、图8表明在运行时间上DeFog与现有的方案相比,效率也有了一定的提高。将数据流按100 KB、1 MB、10 MB进行分块,索引表长度为1 000。emacs-20.7数据集中,当数据块大小为10 MB时,DeFog的运行时间在240 ms,比现有的方案减少了81.2%。但在数据块为1 MB的情况下,DeFog在两个数据集上的运行时间与原有的方案相比没有太大的改进,这体现了选取合适的数据分块大小对实验结果有一定的帮助。
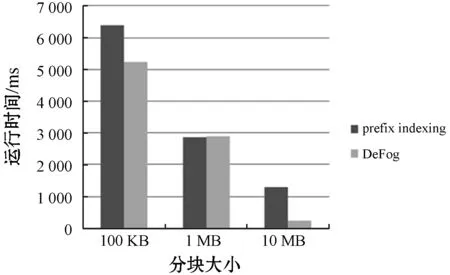
图7 emacs-20.7运行时间

图8 gcc-3.4.1运行时间
在数据集中进行第一次实验时,因为当前指纹表为空,生成的大部分指纹都是非冗余的,多为插入操作,无需检查冗余数据。第二次实验在指纹表非空的情况下进行,需要判断重复数据块,因此延迟时间会随着冗余数据块数量的增加而变长。但由于指纹表全部保存在内存中,不会出现磁盘中部分指纹表随机读取的情况,确保了查询时间。
索引表对指纹的插入与查询的影响如图9所示。利用索引表可以迅速定位到指纹所在的红黑树,进而判断指纹是否重复。索引表是链式结构,读取时间基本可以忽略,与没有索引表的方案相比,效率有所提高。但索引表的长度对运行时间影响不大,两个数据集在索引表为10、100、1 000时运行时间基本相同。
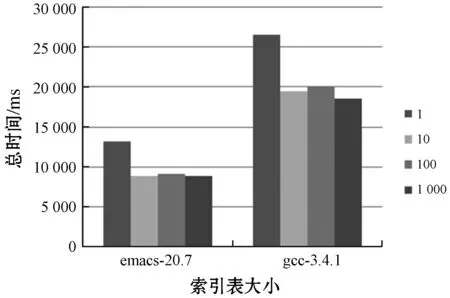
图9 索引表对时间的影响
雾计算作为云计算在网络边缘的延伸,其与云计算在原理是相似的,但在环境布局上也有不同之处,其方案不能直接应用于雾计算中。因此,将DeFog与近年来提出的方案进行性能对比,结果如表5所示。
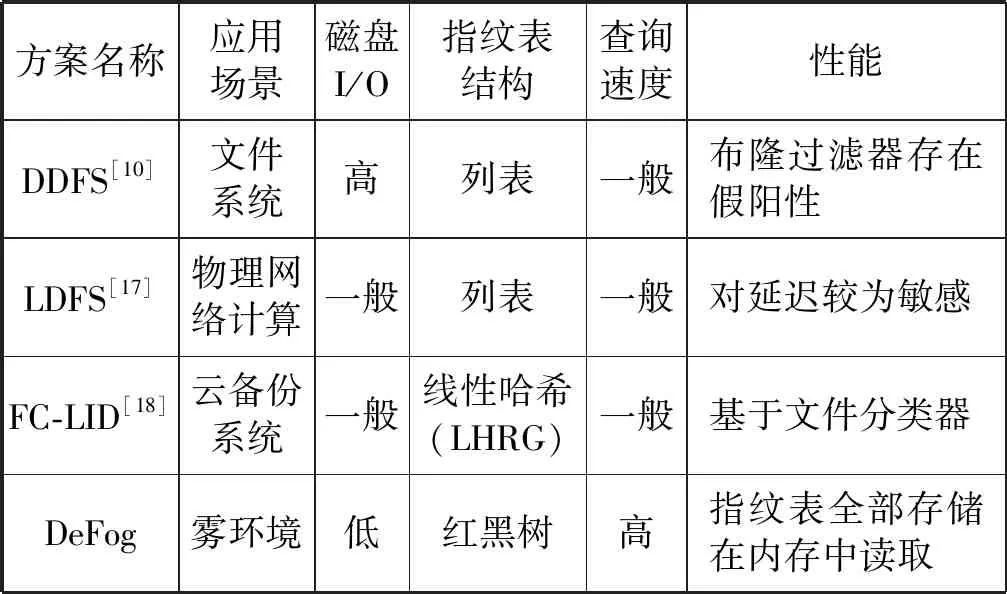
表5 方案性能对比
DeFog适用于雾环境,在数据量较大且单一的情况下能够加快查询速度,防止查询延迟。
5 结 语
本文提出了在雾服务器内存中置入红黑树作为指纹插入与查询的数据结构,从而实现重复数据删除系统(DeFog)。为防止系统突然崩溃,提出用日志文件记录指纹的更新,为数据容灾提供保障。所提出的系统通过减少指纹查找时间和消除冗余数据来提高重复数据删除系统的性能和效率。根据实验证明,固定分块对冗余检测有较好结果,并且可以减少一定的计算开销。索引表在一定程度上加快了指纹查询的速度,时间复杂度为O(1)。红黑树作为指纹表与其他数据结构相比在插入和查询时间上都比较短,适合作为存储指纹的结构。
雾节点的出现一定程度上缓解了云计算中心的压力,DeFog针对雾服务器中频繁访问的数据提出了重复数据删除技术,减少了网络数据传输量,优化系统的整体功能。在人流较大、对通信速度要求较高的雾节点中,可以加快冗余查询速度,保证去重效率。实验证实,本文的方案更适用于访问频繁的小范围数据,通过更快的数据结构提高整体性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
小天使·一年级语数英综合(2020年10期)2020-12-16
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2019年2期)2019-10-30
新生代·下半月(2019年5期)2019-09-10
电脑知识与技术(2017年14期)2017-07-10
科教导刊(2016年27期)2016-11-15
儿童时代·快乐苗苗(2016年2期)2016-10-22
青少年科技博览(中学版)(2015年7期)2015-08-12
