
基于重引力搜索链接预测和评分传播的大数据推荐系统
2020-03-11 12:50耿海军
计算机应用与软件 2020年2期
李 贞 吴 勇 耿海军
1(晋中职业技术学院电子信息学院 山西 晋中 030600)2(山西大学软件学院 山西 太原 030013)
0 引 言
随着移动互联网和电子商务领域的蓬勃发展,目前已经进入信息严重过剩的网络时代,为提高用户浏览网络信息的效率,自动推荐系统应运而生[1]。庞大的信息量和高复杂度的社交网络为自动推荐系统带来了巨大的挑战,当前的推荐系统对于大规模数据和复杂网络难以实现快速、准确的推荐服务[2]。
稀疏性问题和冷启动问题是推荐系统的一个重要问题,直接影响推荐系统的推荐准确性、多样性等性能[3]。深入挖掘并利用用户的社交关系信息以及语义信息是目前解决这些问题的重要手段,文献[4]提出的近邻矩阵分解算法,将用户近邻与项目近邻评分信息融合为一个近邻评分矩阵,挖掘目标用户对目标项目的评分信息。该算法降低了原始评分矩阵的稀疏性问题,并且有效地提高了推荐的准确性,但其未利用社交关系的社区信息,不支持分布式计算的扩展方法,对于大规模复杂网络的搜索时间较长。文献[5]运用SVD降维技术得到项目的隐式特征空间,引入项目信任因子,建立信任模型并融入到相似度空间中。该算法充分应用了用户的社交关系,并且通过降维技术加快了系统的处理时间,但其采用余弦相似度计算项目间的相似度,存在较高的冗余度[6]。文献[7]将Tri-training框架加以扩展,提出基于用户活跃度生成无标记教学集合的算法和对矩阵分解模型扩充的形式,该算法对于复杂网络的计算效率较低,难以提供高效的推荐列表。结合大量的研究和分析,现有的推荐系统大多存在以下的不足之处:① 未利用社交关系的社区信息;② 对于大规模复杂网络的搜索时间较长;③ 不支持并行计算的扩展方法;④ 学习语义信息的过程中需要大量的时间。
皮尔森相似度、余弦相似性[8-9]是协同过滤推荐系统中广泛采用的相似性度量方案,为充分考虑用户环境的作用[10],采用相对相似性指数(Relative Similarity Index,RSI)度量用户的相似性,应用Meta Path概念[11]构建网络结构。为支持并行计算的可扩展性,将大规模复杂网络划分社区结构,再对小规模的子图做并行处理。为解决稀疏性问题和冷启动问题,设计了基于重引力搜索[11]的链接预测机制和评分信息传播机制(Gravitational Search based Link Prediction & Rating Propagation,GSLPRP),以较短的学习时间获得充足的隐藏评分信息。
1 推荐系统的主要结构
图1所示是推荐系统的主要模块。本算法主要由3个阶段组成:第一阶段:计算用户之间的相似性,该阶段结合RSI和Meta Path来增强用户间的相似性计算。第二阶段:应用链接预测算法发现隐藏的网络链接,该阶段设计了基于重引力搜索的链接预测算法,发现隐藏的用户链接来缓解稀疏性问题。第三阶段:应用评分传播机制,该阶段设计了基于传染病模型的评分信息传播机制,进一步丰富用户的评分信息。

图1 推荐系统的主要模块
2 相似性计算
2.1 RSI相似性
文献[12]提出了RSI,有效地提高了推荐系统的准确率和多样性。两个用户ui和ui+1之间的RSI指数计算为:
(1)
式中:sim为两个节点的余弦相似性,co_rate是与目标用户共同评分的项目数量,max(co_rate)为网络中每对用户共同评分的项目数量。
2.2 构建基于meta-path的相似性图
构建一个广义的用户-项目网络(User-Item,U-I),网络的节点为用户和项目,边为加权的链接,表示用户对于各个项目的评分。图2所示是一个网络的实例,图中U表示用户,I表示项目,网络由4个用户和6个项目组成,链接为用户对于项目的评分。

图2 一个U-I网络的实例
异构网络中存在不同类型的节点和链接,采用广义路径Meta Path模型,定义为异构网络中从一个节点到另一个节点之间包含的节点和链接,计算网络中所有的Meta Path需要极大的计算负担。Meta Path需要计算路径内所有的用户节点和项目节点,结合评分信息构建网络,基于Meta Path计算用户间的相似性。
采用“用户-项目-用户”的Meta-Path,简称为simUIU。simUIU计算加权Meta-Path的相似性,假设评分范围为{1,2,3,4,5},将评分信息分为三个级别:低:{1,2},中:{3,4};高:{5}。图3是评分分级的示意图,将Meta-Path细分为三个加权的子Meta-Path{P1,P2,P3},图中P1子Meta-Path对应评分值在R1区间的情况。
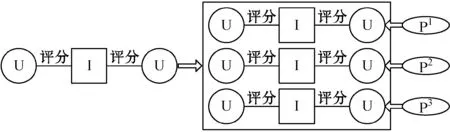
图3 评分分级的示意图
然后将U-I网络分为3个子网,如图4所示。将从细粒度转化为粗粒度的目的是提高评分的可理解性,有助于观察用户的相似度。
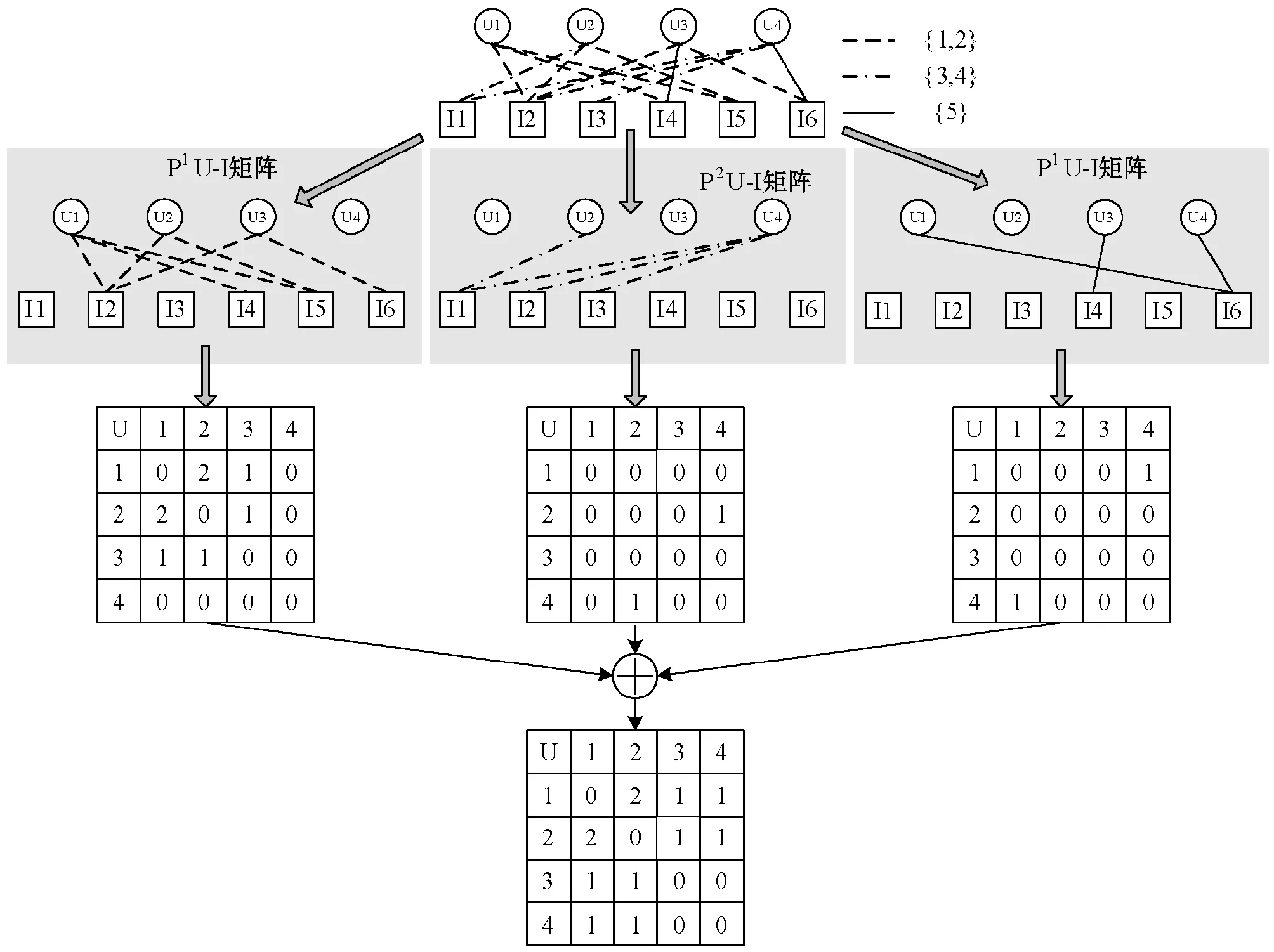
图4 U-I网络的子网划分和Meta-Path图
Meta-Path路径的计算方法为:
(2)

3 基于重引力搜索的链接预测
3.1 问题定义
连接预测的主要思想是通过引入社区信息来提高局部链接预测的准确率,从强社区提取优化的子图来实现局部链接的预测,其中通过重引力搜索对子图做优化处理,从而缩小搜索空间。

3.2 重引力搜索算法(GSA)
GSA的每个agent具有4个属性:位置、惯性质量、主动引力质量和被动引力质量,agent的位置即为问题的解集。设两个agent的质量分别为M1和M2,两者的距离为R,那么其中一个agent受到的引力为F=G((M1M2)/R2),G为引力常量。GSA的搜索过程如下:
Step1初始化。根据下式随机初始化N个agent的位置:
(3)

Step2评价适应度。在每次迭代中分别通过下式计算最优适应度和最差适应度:
fmax(t)=maxfitj(t)
(4)
fmin(t)=minfitj(t)
(5)
式中:fitj(t)为第j个agent在第t次迭代的适应度值。
Step3计算引力常量。第t次迭代G的计算方法为:
(6)
式中:G0与α均为初始化参数,T为迭代的总次数。
Step4计算agent的引力。第t次迭代agent惯性质量和引力的计算方法为:
Mαi=Mpi=Mii=Mi
(7)
(8)
(9)
式中:Mpi和Mαi分别为被动引力质量和主动引力质量,Mii为第i个agent的惯性质量,fiti为第i个agent的适应度函数。
Step5计算agent的加速度。第t次迭代agent加速度的计算方法为:
(10)
第i个agent总引力的计算方法为:
(11)

(12)
式中:Kbest为前K个agent的最优适应度值,最大质量随着迭代线性降低,最终仅有一个agent对其他agent产生引力。G(t)为当前迭代的重引力常量,ε为常量,Rij(t)为agenti和j之间的RSI相似性。
Step6更新agent的速度和位置。搜索过程的速度和位置更新方法分别为:
(13)
(14)
Step7重复Step 2-Step 6。如果未达到结束条件,那么重复Step 2-Step 6。将最后一次迭代的最优适应度作全局适应度。
3.3 基于GSA预测网络链接
基于重引力的链接预测参数、适应度函数和其他的参数建模为:
(1) 初始化网络参数。随机初始化agent的位置和网络参数,N个agent的位置初始化为:
Xi=Init+(Xup-Init)×rand(0,1)+
(Xlo-Init)×rand(0,1)
(15)
式中:Init表示第i个agent的位置,Xup为最大的平均分簇系数,Xlo为最小的平均分簇系数(Average Clustering Coefficient,ACC)。
(2) 适应度函数。为将ACC参数最大化,通过以下的适应度函数评价质量:
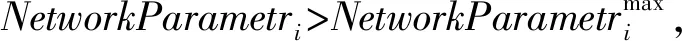

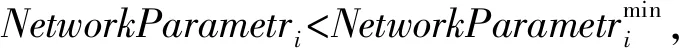


在求解最优解的问题中,在每次迭代t中通过式(4)和式(5)分别求解最优适应度和最差适应度,fitj(t)为第t次迭代、第j个agent的适应度值。
(3) 重引力搜索的常量值。重引力搜索的agent常量设为:G0=100,α=10,T=100。
(4) 重引力质量和惯性质量。GSA的每次迭代中通过式(7)-式(9)计算重引力的质量和惯性质量。
(5) 总体引力。Agent的引力和总引力计算方法分别如下:
(16)
(17)
式中:ε=0.1。
(6) 加速度和速度。网络参数的加速度和速度分别如下:
(18)
(19)
3.4 GSA搜索速度
GSA倾向于开发搜索空间的中心位置,该性质严重影响了GSA的多样性,而大多情况下,Xg附近的搜索空间才应该被局部地深入开发。为提高GSA的收敛速度和求解质量,对质量分配机制进行了改进。为每个agent的质量分配一个范围[LM,UM],约束GSA的局部搜索空间。定义时间不变线性递增函数如下,建立适应度和质量的映射:R→R,f(Xi)→g(f(Xi)),∀Xj∈X。
Mi=g(f(Xi))=
(20)
式中:j∈{1,2,…,S}。
3.5 基于GSA的链接预测算法
采用特征相似性降低特征之间的冗余度,最大化簇内特征的相似性,最小化簇间特征的相似性。从每个社区中选择一个特征组成降维的子集,然后采用GSA技术优化子集之间的冗余度。特征选择由两个步骤组成:(1) 原特征集分为若干的社区;(2) 从每个社区选择一个代表性特征。
观察发现,预测外部链接对于链接预测结果的准确性没有明显提高。图5所示是链接预测算法的主要模块,图6所示是链接预测算法的流程框图。

图5 链接预测算法的主要模块

图6 链接预测算法的流程框图
算法1是本文基于GSA的链接预测算法。输入变量为社交网络的图模型,输出结果为预测的链接集。算法分为4个阶段:(1) 社区检测阶段:将复杂网络划分社区,将网络划分为子图能够有效地提高算法的效率,算法的第1行通过社区检测将社区分簇。(2) 子图优化阶段:算法的第5行通过GSA对每个社区Cis的子图ci进行优化处理。(3) 链接预测阶段:算法的第3行预测了社区的外部链接,第7行预测社区的内部链接。(4) 链接分类阶段:将预测的所有链接分类,输出最终的预测链接集。
算法1基于GSA的链接预测算法
输出:L={l1,l2,…,lm}
/*社区检测C=c1,…,ck*/
/*应用链接预测和ELP预测内部链接和外部链接*/
2.intlink=AAL(C);
3.extlink=ELP(ci,cj);
/*预测每个社区的外部链接*/
4.F=CalForce(ci,cj);
5.OptGraphList=GSA(C);
6. foreachjfrom 1 to l do
7.IntLinks=AAL(cj);
/*预测每个社区的内部链接*/
8. endfor
9. foreachcicjinOptGraphListdo
10.Fij=CalForce(ci,cj);
11.Flist←Fij;
12. endfor
13. foreachcicjinOptGraphListdo
14. ifFij>γ
15.PreLinks←ELP(ci,cj);
16.Mark(PreLinks,Fij);
/*为链接标记引力大小*/
17. endif
18. endfor
4 评分信息传播方案
4.1 方案设计
评分信息是推荐系统的一个重要部分,采用基于传染病模型的网络传播策略,根据已有的模式探索隐藏的模式。定义一个传播阈值θd,如果N(u,i)≥θd,用户u则接受项目i,N(u,i)为用户u的邻居数量。根据增强的相似性矩阵将评分信息在网络中传播,相似性矩阵建模为一个网络,节点为用户,评分信息为节点的特征。定义一个u的邻居用户集PN,PN中的用户与u的相似性得分为正。
图7所示为评分信息传播的效果图,图中共有7个用户,评分信息作为用户的特征,黑色用户u为目标用户,u评分的项目为{0,7},灰色用户为u的PN集,假设θd=0.1,u2、u3、u4的评分项目均包含了31和41,所以项目31和项目41的评分次数较多,因此用户u接受PN对31和41两个项目的评分。

图7 评分信息传播的效果图
θd决定了目标用户是否接受PN集传播的评分信息,定义为u接受PN评分的比例,将阈值设为θd=0.1。基于权重将评分信息融合,用户u对于目标项i评分的融合方法为:
(21)
式中:sim(u,v)为用户u和v的相似性,相似性越高,对于评分结果的贡献度越大。ru,i为用户u对于项i的评分。C(u,i)表示对项i评分的PN用户集。
4.2 评分信息传播算法
算法2为评分信息传播算法。算法的输入是用户评分R,输出是增强的评分信息Re与相似性矩阵Se。算法的第5、第6行计算用户之间三个加权的Meta Path,第9行计算相似性矩阵,第14行计算新的评分信息Re。
算法2评分信息传播算法
输入:评分信息:R
输出:增强的评分信息Re,相似性矩阵Se
1.NI←R中的项目数量;
2.NU←R中的用户数量;
3. 将R分为子Meta-Path{P1,P2,P3};
4. 建立U-I矩阵;
5. 根据式(1)计算Sim;
/*根据式(1)计算相似性*/
6. 将Sim归一化为[-1,1]区间;
7. foreachu,vfrom 1 toNUdo
8. ifSim(u,v)=0 &&u≠vdo
/*根据已有连接建立网络*/
9. 根据式(2)计算Meta-Path路径;
10. endif
11. endfor
12. 应用算法1预测隐藏的链接;
12.Se=Smain+Se;
13. foreachufrom 1 toNUdo
/*在网络中传播评分信息*/
14. 根据式(21)计算Re(u,Item(u));
15.Re=R+Re;
16. endfor
5 仿真实验与结果分析
5.1 实验环境与实验方案
(1) 实验环境。实验环境为:Intel(R) Core(TM) i5-5200 CPU, 2.2 GHz主频,8 GB内存容量,操作系统为Windows 10操作系统,编程环境为MATLAB R2016a。
(2) 实验数据集。实验采用三个经典的公开数据集,分别为FilmTrust、Epinion和Flixster[13]。FilmTrust数据集是电影评分的数据集,Epinions是产品评论数据集,Flixster是Flixster.com网站用户对于电影评价和兴趣的数据集。表1是3个实验数据集的简介。

表1 数据集的主要属性
(3) 性能评价指标。采用5折交叉验证分别进行训练和测试:每个数据集随机分为5个子集,4个子集组成训练集,另1个子集为测试集,轮流完成5次验证,将测试数据集的结果统计为最终的平均性能。平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)是评价推荐准确率的常用指标,MAE对异常点的敏感度较低,RMSE对异常点的敏感度则较高。MAE和RMSE的计算方法为:
(22)
(23)
式中:Ω为测试集,|Ω|为测试集的大小,用户u对项目i的实际评分和预测评分分别记为ru,i和pu,i。
此外,评价了系统的评分覆盖率RC(Rating Coverage),覆盖率度量了系统对长尾项目的挖掘能力,定义为系统推荐的项目占总集合的比例。
(4) 实验方法。首先使用基本协同过滤推荐算法(Collaborative Filtering,CF)观察本方法对于推荐系统的增强效果。然后选择其他近期的协同过滤推荐算法进行对比实验,进一步评价本算法的性能,分别为TrustSVD[14]、TrustMF[15]和BKCF[16]三个算法。TrustSVD是一种基于信任的矩阵分解方案,该方案为推荐模型引入了多种信息源,并且引用了社交关系的信息,与本算法具有相似之处。TrustMF[15]采用了信任传播机制,利用矩阵分解方法将用户映射至低维的特征空间,探索用户观点之间的影响,该方案是一种新颖且性能较好的推荐系统。BKCF设计了一种新的布尔核,并将布尔核嵌入协同过滤推荐系统中,该方案提高了推荐系统的语义感知能力,具有较好的推荐效果。
5.2 链接预测与评分传播实验
首先,测试了基于重引力搜索算法的链接预测效果。表2所示是通过链接预测增加的链接结果,表中显示本算法有效地增加了数据量,对于数据密度较高的Filmtrust数据集,预测率达到了9.5%,对于密度较低的数据集,也实现了有效的补充。

表2 链接预测处理的结果
链接预测的目标是缓解网络的稀疏性,为后续的评分传播处理提供支持,因此对评分传播处理也进行了实验和评价。对FilmTrust、Epinion和Flixster做预处理,删除一些不完整的数据。然后测试评分传播处理的效果,表3所示是评分传播处理的结果,表中显示评分传播处理对于密度低的Flixster数据集增加了4%的信息。

表3 评分传播处理的结果
5.3 与基本CF推荐系统的比较
将本文算法与基本的协同过滤推荐算法集成,评估本文算法对推荐系统的改进效果。图8所示为基本CF算法和集成CF算法对于三个数据集的RMSE结果,基本CF算法随着领域阈值的增加缓慢提高,而集成CF算法的增长较快,具有明显的优势。

(a) Filmtrust数据集

(b) Epinion数据集

(c) Flixster数据集图8 RMSE的实验结果
图9所示为基本CF算法和集成CF算法对于三个数据集的MAE结果,基本CF算法随着领域阈值的增加缓慢提高,而集成CF算法的增长较快,具有明显的优势。

(a) Filmtrust数据集

(b) Epinion数据集
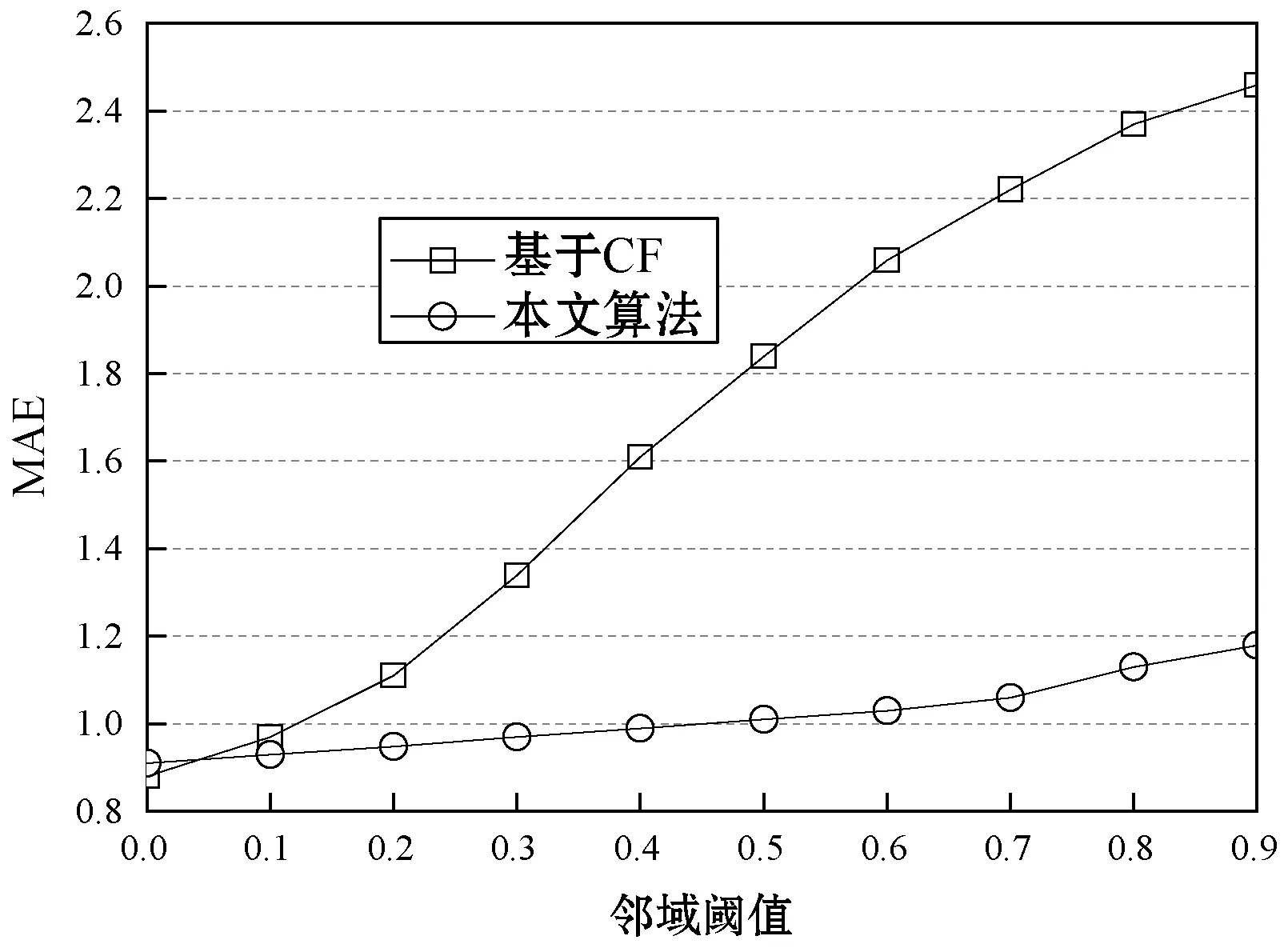
(c) Flixster数据集图9 MAE的实验结果
图10所示为基本CF算法和集成CF算法对于三个数据集的覆盖率结果,基本CF算法随着领域阈值的增加迅速降低,而集成CF算法随着领域阈值的提高表现得较为稳定,始终高于0.85。

(a) Filmtrust数据集

(b) Epinion数据集
5.4 与其他推荐系统的比较
将GSLPRP算法与多层协同过滤模型(Multifaceted Collaborative Filtering Model,MCFM)集成,组成GSLPRP_ MCFM算法。将GSLPRP_ MCFM与TrustSVD、TrustMF和BKCF三个推荐系统比较,结果如图11所示。可以看出,GSLPRP_ MCFM算法的RMSE和MAE结果始终低于其他三个算法,并且具有明显的优势。与此同时,GSLPRP_ MCFM算法的覆盖率也略高于其他三个算法。本文算法设计了基于重引力搜索的连接预测机制和评分信息传播机制,有效地补充了数据集的信息,缓解了稀疏性问题。

(a) RMSE结果

(b) MAE结果

(c) RC结果图11 4个推荐系统的性能比较
比较GSLPRP_ MCFM与TrustSVD、TrustMF和BKCF三个推荐系统的处理时间,结果如图12所示。可以看出,GSLPRP_ MCFM算法的RMSE和MAE结果明显低于其他三个算法,随着数据量的增加,GSLPRP_ MCFM的处理时间依然保持较低。GSLPRP_ MCFM通过社区检测算法将原网络图划分成小规模的子图,与MCFM的多层协同过滤模型集成,通过并行处理对每个子图进行处理,因此随着数据规模的增加,算法的总体时间并未呈现剧烈的增长趋势。

图12 4个推荐系统的处理时间
6 结 语
为支持并行计算的可扩展性,将大规模复杂网络划分社区结构,再对小规模的子图做并行处理。为解决稀疏性问题和冷启动问题,设计了基于重引力搜索的链接预测机制和评分信息传播机制,以较短的学习时间获得充足的隐藏评分信息。实验结果表明,本文算法对基本协同过滤推荐系统实现了明显的增强效果,并且优于其他近期的推荐系统。
本文算法主要是一种推荐系统的增强策略,目前主要研究了与协同过滤推荐系统的集成效果,未来将关注与其他类型统计系统的集成方案和效果。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
现代英语(2021年18期)2021-11-22
当代陕西(2020年15期)2021-01-07
雪莲(2017年2期)2017-05-12
当代旅游(2016年10期)2017-04-17
环球市场信息导报(2017年1期)2017-04-08
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
第二课堂(课外活动版)(2015年4期)2015-10-21
财经理论与实践(2015年2期)2015-04-16
数理化学习·高一二版(2009年2期)2009-03-30
