
基于GRU和LightGBM特征选择的水位时间序列预测模型
2020-03-11 12:50许国艳周星熠司存友胡文斌
计算机应用与软件 2020年2期
许国艳 周星熠 司存友 胡文斌 刘 凡
1(河海大学计算机与信息学院 江苏 南京 211100)2(江苏省水文水资源勘测局信息应用科 江苏 南京 210000)
0 引 言
水文时间序列是指水文信息中水位、降雨量等因素随着时间变化产生的序列。其中水位时间序列的研究是数据挖掘领域的重点研究方向,通过对水位的预测分析,不仅可以准确地对水资源进行调度管理更能即时预报洪涝灾害,对于防灾减灾有着至关重要的作用。
水位时间序列的预测在近十多年取得了较大的进展,中外学者都对其做出一定的研究。在数据量较小,且特征丰富时机器学习模型甚至传统的数学模型也能取得较为良好的效果。商其亚等[1]利用ARIMA(自回归综合移动平均)对民勤绿洲水位进行预测,提取了人口、耕地面积等多个影响因素,较为准确地预测了上游水位的变化趋势。黄发明、殷坤龙[2]等使用SVM模型对水位进行预测,并采用了混沌理论的粒子群算法克服了支持向量机中存在的参数选择困难的特点,以此预测水位系统发展演化的过程。随着水位时间序列预测的处理越发复杂化,对于预测的精度要求也随之提高,采用深度学习的方式能够建立更高效的模型,提高预测精度。孙菊秋等[3]将人工神经网络中的BP算法应用到秦皇岛地区的水位预测中,模拟出未来2年的水位情况,表现出精准、快速的优势。冯钧等[4]提出了一种基于LSTM-BP的组合模型预测方法,通过两个模型的组合降低了误差,提高了预测的准确度。随着数据量的增大,对于数据的真实性判断成了预测中不可或缺的一环。花青等[5]提出了一种基于多滑窗的异常数据检测方法,能够及时对预测值进行处理,避免因为误差造成的错误报警。对于预测残差等其他影响因素的处理,王华勇等[6]提出了一种基于lightGBM改进的梯度提升算法,能高效并行地处理更多的实验样本,通过增加决策树的方法减少了过拟合的出现,使得预测精度更高。
水文数据有着强烈的季节性和复杂性,在非汛期水位时间序列的影响因素较少,预测结果较为精确;而汛期时降雨量对水位的影响较大,因此需要将其作为输出的另一项特征进行建模。单一的GRU模型对于水文数据的复杂性及其非线性部分处理存在不足,为了优化模型,更好地处理、分析预测残差及其他影响因子对结果的影响,本文将LightGBM梯度提升算法用来处理残差及降雨量数据,与GRU建立基于GRU-LightGBM的组合模型。
1 相关研究
1.1 GRU
GRU(Gated Recurrent Unit)是一种改进的循环神经网络,比起原始的RNN模型具有更远的传播距离,并且能解决梯度消失的问题。与循环神经网络的另一个变种LSTM[7](长短期记忆网络)相比减少了一个遗忘门,且其单元中的细胞没有状态,因此该模型网络结构更易被理解,可以减少过拟合且训练更为简单。GRU[8]的一大特点是可以基于历史值和当前值来预测未来某个时刻的值,所以用来处理时间序列比较合适。GRU预测的原理是利用门单元控制历史和当前信息,并在当前步作出预测。GRU的一次前向传播过程如下:
1) 更新门对t-1时刻的隐藏状态ht-1做线性变换,并通过激活函数压缩结果到[0,1]区间。在生成记忆内容过程中,重置门应用于t-1时刻的信息上,来存储t-1时间的隐藏状态ht-1的状态信息。
2) 将重置门和前一时刻的隐藏状态做乘积,再将此结果和当前时刻的输入值xt做线性变换,通过tanh将结果映射到[-1,1]区间内,得到当前记忆内容;(1-Zt)×ht-1表示前一刻隐藏状态保存到当前的值,将其与t时刻的记忆内容保存到现在的记忆量相加得到最终的值ht。
1.2 LightGBM
LightGBM(Light Gradient Boosting Machine)[9]是于2016年提出的一种基于决策树的梯度提升算法。
作为GBDT[10]的一种,LightGBM的设计主要是为了提高对大规模数据的处理速度和精度。传统GBDT算法的缺陷在于:一方面,在单机上处理大规模数据的时候,为了保证速率往往会导致精度的丢失;另一方面,在分布式处理时,各机器之间的通信损失,也在一定程度上降低了数据的处理效率。
LightGBM的核心思想是基于histogram[11](直方图)的决策树算法,将样本中连续的浮点特征值离散化成K个整数并构造与之长度相等的直方图。遍历时,将离散化后的值作为索引在直方图中累计统计量,然后根据直方图的离散值,遍历寻找最优的分割点。这样可以有效地降低内存消耗,同时达到降低时间复杂度的目的。此外,LightGBM采用了区别于传统Level-wise方法的Leaf-wise叶生长策略,即每轮迭代都从现有的叶子中找到最大增益的分裂方法,如此循环直至达到给定的最大深度,此方法有效避免了不必要的开销,提高了计算速率。LightGBM的建模过程如图1所示。

图1 LightGBM决策树算法
基于LightGBM算法能够并行处理海量数据的特性,将该算法用于对时间序列的残差和降雨量进行多特征并行处理,能够更好地降低模型计算的时间复杂度,提高预测的效率和精度。
2 水位数据组合预测模型
2.1 预测模型架构
基于GRU-LightGBM的水位数据组合预测模型架构总体分为三个模块:
模块一:从数据源获取水文信息,将其分解为水位数据和降雨量数据。将水位数据进行差分和归一化[12]处理。
模块二:构建GRU模型,求出水位的预测序列并根据水文信息将其分为汛期预测序列和非汛期预测序列。
模块三:将非汛期的预测残差与原始水位序列构建lightGBM模型,求出非汛期的最终预测序列;将汛期的降雨量序列与原始水位序列构建lightGBM,计算汛期的最终预测序列。
组合模型的建模整体架构图如图2所示。
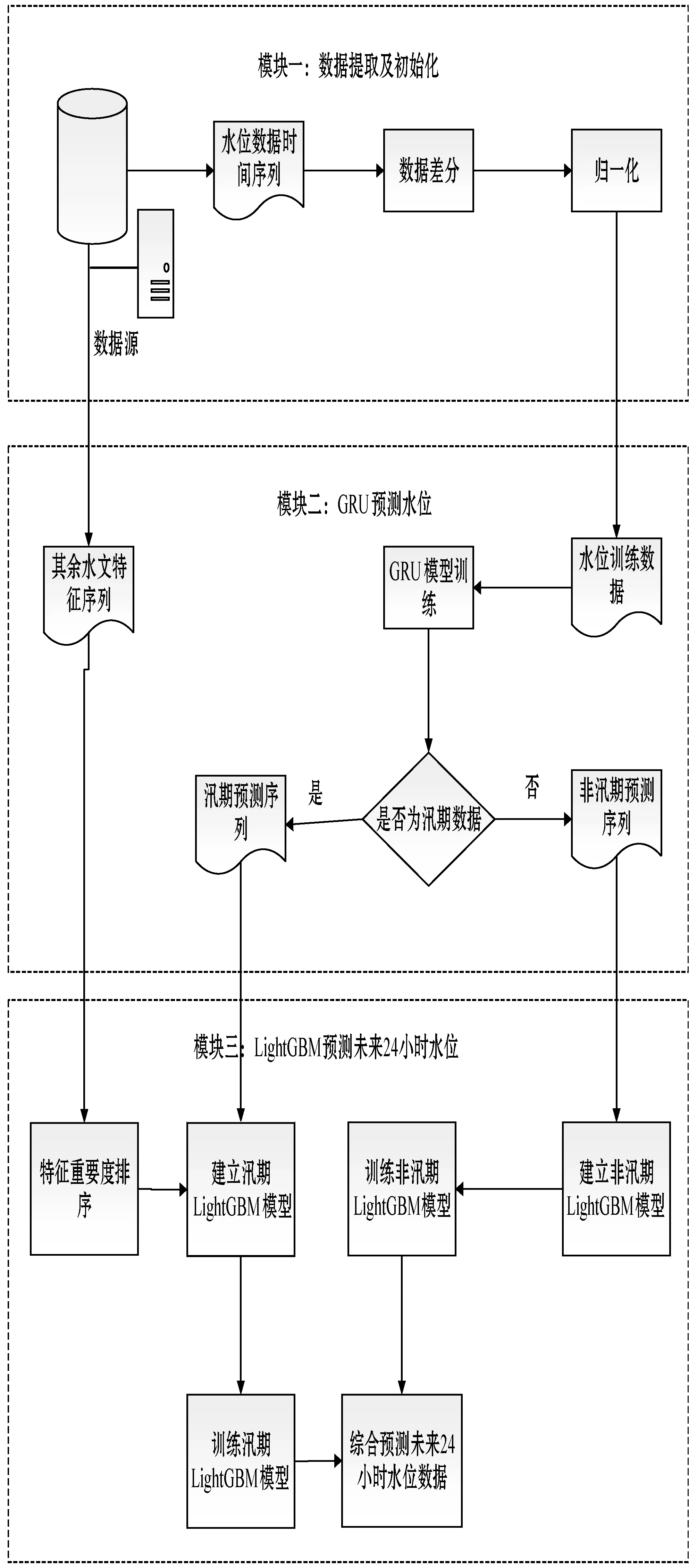
图2 组合模型架构图
2.2 数值预处理
对于给定的水文数据我们进行数据处理,使之具有规范的格式,便于后续处理分析。本文对于时间序列的预处理主要是填充空缺值以及归一化。
归一化旨在消除不同量纲之间的相互影响,解决指标之间的可比性。通常数据量、数据范围较大时,模型的收敛速度和精度会下降,为了解决此类问题,我们通常将数据按比例缩放,本文采用较为常用的(0,1)归一化,将数据映射到(0,1)区间内。归一化公式如下:
(1)
式(1)中数据取自待预测站点的水位数据,ti为待处理水位数据,tmin为水位数据中的最小值,tmax为水位数据中最大值。通过数值归一化[13]的处理,使得数据梯度变化时由原来的窄而长的椭圆形之字走向优化为直接沿着圆心最短路径的走向,大大提高了迭代速度。同时,归一化的处理还能消除样本奇异值带来的计算精度的影响。
对于本文所用模型,在数值预处理上还需对特征值的重要程度进行排序。汛期的水位受到了诸多环境因素的影响,但是对于此类影响因素,传统方法的单个遍历尝试或者组合筛选效率较低,因此本文选取LightGBM将各类环境变量对于水位的影响程度进行排序,选取重要程度较高的多种特征,将水位初步预测值与这些特征组合进行梯度提升建模。
2.3 组合模型原理
组合模型是指针对某一类问题采用了两种或者两种以上的模型进行处理的方法。针对连续型数值的特性,水位数据与前几个时间点的观测值有较强相关性,可以利用改进的神经网络GRU对于历史时刻的数据进行分析预测,初步建立一个较强的预测器。在强预测器的基础上,传统bagging算法的提升较小。可将水文数据中降雨量时间序列以及GRU建模时预测残差进行boosting[9]操作,在强预测器的基础上进行并行计算,再进行水位预测。
区别于传统的组合模型,对于时间序列中的线性和非线性成分并不是简单相加,而且采用线性预测与非线性捕捉分离的方式分别处理。此外,对于传统模型中未能考虑到的季节性因素,基于GRU-LightGBM的模型也做到了分时段处理,针对不同环境细化建模流程。
组合模型的建模流程如下:
(1) 提取归一化后的水位数据Xi将其分成非汛期数据X1i和汛期X2i建立GRU网络模型,得到预测序列值Ti,通过与水位数据作差可得残差序列Li,将所得残差序列按照汛期和非汛期分解成L1i和L2i,表达式如下:
Li=Xi-Ti
(2)
(2) 依据水文数据指定的时间,5月至9月为汛期,其余为非汛期,提取残差序列:
(3)

(4)

[X2i,L2i,D2i])
(5)
组合模型的网络结构如图3所示。

图3 网络结构图
组合模型将GRU网络预测所得非线性残差与其他影响因素输入梯度提升LightGBM模型中并行计算,有效降低了精度丢失,并提升了计算速率。
2.4 组合模型算法与分析
总体思想:本文中提出的组合模型主要由一个GRU模型和两个LightGBM模型结合而成。GRU模型仅对水位时间序列信息进行相空间重构,求出待预测站点的水位预测序列Ti及预测的残差序列Li;第一个LightGBM将非线性的水位预测残差L1i与原始序列结合,利用梯度提升的原理计算最终的水位预测序列T1i。第二个LightGBM模型利用梯度提升的原理将汛期影响因素重要程度前四的环境变量与汛期水位预测残差L2i组成综合特征矩阵作为输入数据,得到最终的水位预测序列T2i。水位时间序列预测的具体算法如下:
Step1对从数据源得到的数据进行分析,通过检查数据的平稳性和季节性分析其差分次数并剔除其趋势因素。
Step2对处理后的水位数据进行(0,1)归一化。利用相空间重构的方法将一维的水位数据序列以三位步长处理成高维的矩阵Xi,通过reshape变换将矩阵Xi转换成GRU所能识别的维度即[sample,step,feature],sample代表样本值,step为设置的步长,feature为特征。输入层有1个input,隐藏层有32个神经元,模型中利用滑动窗口的原理将每次输出层预测一个值作为下一次预测的输入值进行计算,重复n-3次直至预测结束,对应的输入矩阵Xi以及输出向量Ti关系如下:
(6)
输入矩阵Xi输出向量Ti
Step3将所得预测序列ti的值与原始数据xi相减,计算出残差序列li。
Step4根据水文数据指定时间,将残差序列分为非汛期残差序列l1i以及汛期残差序列l2i。
Step5将非汛期的非线性残差序列l1i与原始序列x1i相结合形成LightGBM的输入矩阵gbm_train1,通过梯度提升的处理方法再度进行预测,得出预测序列t1i,对应的输入矩阵gbm_train1和输出向量T1i关系如下:
(7)
输入矩阵gbm_train1输出向量T1i
(8)
输入矩阵gbm_train2输出向量T2i。
将所得预测序列t1i以及t2i逆归一化得到最终输出结果。具体实现过程的算法1所示。
算法1:
输入:水位时间序列训练数据集dataset_Xi,预测步长step以及特征features;
输出:未来24小时的预测值Predict_24;
c为隐藏门;
inp为隐藏状态的线性变换;
本文根据河北某新区的地理和降雨特点,在保证雨水调蓄池储存雨水功能基础上,研究调蓄系统在无人参与情况下实现自治理功能,主要内容包括:① 雨水收集;② 浮渣隔离;③ 调蓄池蓄水状态下淤泥清除;④ 雨水分级利用;⑤ 污泥分级处理等.
l为输入数据的长度;
s为叶节点宽度;
//训练GRU模型
1. 将输入步长step与特征值feature相结合
/*本实验设置步长为3*/
2. c=inp(feature)+step;
3. 将结合后的数据放入遗忘层,保存状态到候选者层
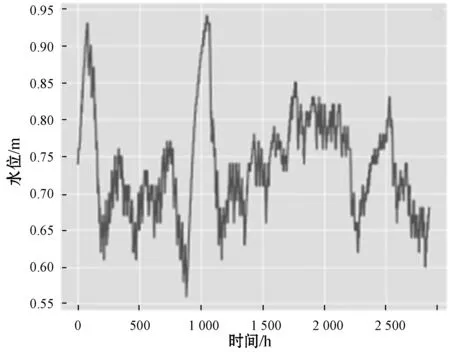
4. if(c.val) /*max_bin为预设的根堆大小*/ 5. for i=0 to l do val.put(bin); /*用leave_wise算法建立树模型*/ 6. endif 7. return arg(max(max(bin))) //特征筛选并进行LightGBM建模 8. while bin /*Leave_size为叶节点宽度*/ 9. 计算特征重要度; 10. end while 11. for i=0 to l 12. lgb建模; 13. i++; 14. end for 实验平台为PyCharm2017.3 x64,Windows 7所搭载的操作系统,使用基于TensorFlow的keras框架进行编码,数据集来源于江苏省水利厅信息科,选用数据集为淮河流域射阳河某站点2016年1月1日0点至2016年5月1日0点的2 864条非汛期数据以及2018年5月1日0点至2018年9月30日12时的3 669条汛期数据。数据集被分为两部分,67%为训练集,33%为测试集,实验采用了对比的方法,将GRU-LightGBM综合模型的预测效果分为非汛期和汛期分别同GRU、ARIMA单个模型相比较。具体的实验步骤如下:1) 定义模型;2) 添加GRU层数;3) 根据数据情况添加dropout层;4) 定义输出层神经元个数为1;5) 添加激活函数进行模型优化;6) 运行模型并保存结果。图4、图5为射阳河流域每小时水位的时间序列图。 图4 非汛期水位数 图5 汛期水位数据 为了综合考量实验模型的效果,本文使用多个参数对实验的结果进行分析,分别为均方根误差(RMSE)[15]、预报准确率(FA)[16]以及决定系数(DC)。 (9) (10) 这两个公式在各大深度学习算法[17]中均有介绍。式中:(pred)表示预测值,y(raw)表示实际值。此外,针对水位时间序列的特殊性,为了比较模型的拟合效果,本文增加了一个指标即为决定系数: (11) 式中:SSE为所有观测点的残差和,SST为所有点和均值差的总和,DC值越接近一代表预测准确率越高。 对于非汛期和汛期的水位数据分别进行预测其接下来的24个点的数据,效果如图6、图7所示。 图6 非汛期水位预测效果对比 图7 汛期水位预测效果对比 对比图6、图7可以看出,非汛期的总体预测效果较好,基本与原始数据重合,而汛期的预测效果较差,三种模型都偏离了原始数据。 针对汛期水位受多重因素影响[20]从而导致精度不足的情况,采用lightGBM进行特征筛选[18]。 在分析水位数据及其影响后,得出了影响水位的九种环境因素,分别是:1) 上游第一个水位数据;2) 上游第二个站点水位数据;3) 下游第一个水位数据;4) 下游第二个水位数据;5) 温度;6) 降雨量;7) 去年同期水位;8) 前6小时降雨量总和;9) 去年同期降雨量。使用LightGBM评估环境因素重要性,结果如图8所示。 图8 环境因素重要程度排序 可以看出,重要程度前四的特征相关度[19]更高,从特征“温度”往后的特征对预测结果几乎不产生影响。因此,将这四类特征与预测值再度建立LightGBM模型进行预测,所得预测结果如图9所示。 图9 加入环境因素后汛期预测对比 通过实验验证,随着时间的推移,SVM-ARIMA模型以及LSTM循环神经网络网络模型在拟合程度上渐渐偏离原始数据,而经过改进的GRU和lightGBM组合模型在预测效果上表现得更加优秀,预测值更接近实际值。非汛期的总体预测效果较好,基本与原始数据重合,而经过特征选择的汛期的预测效果比最初模型的效果更好。实验证明了GRU和lightGBM组合模型相较于其他算法在预测精度有了提高。 通过实验验证,随着时间的推移,SVM-ARIMA[21]模型以及LSTM循环神经网络模型在拟合程度上渐渐偏离原始数据,而经过改进的GRU-lightGBM在预测效果上表现地更加优秀,预测值更接近实际值。实验证明了GRU-lightGBM组合模型相较于其他算法在预测精度有了提高。 非汛期以及非汛期预测效果对比的实验结果如表1、表2所示。 表1 非汛期预测效果对比表 表2 汛期预测效果对比表 通过分析表1、表2可知,在非汛期时,基于GRU-lightGBM的组合预测模型无论是在预报准确率还是决定系数上表现均为最佳,而汛期的水位由于受到降雨量的影响,预测准确率较之非汛期稍低。但综合各项指标,组合模型的预测值更接近实践值,体现出了模型的合理性和优越性,总体来说GRU-lightGBM组合模型在水文数据的预测上优于单一模型。 针对单一模型对于具有季节性、复杂性的水文数据预测精度不足,本文提出了一种基于GRU和lightGBM的组合预测模型,将其应用于射阳河的小时预测。为了验证方法的有效性,将组合模型和传统机器学习模型SVM-ARIMA及LSTM模型进行对比,经实验验证组合模型预测准确率和效率均高于单一模型。但水文数据信息影响因素较多,本文所用模型未考虑一些特殊的变化因素,有待进一步的改进。未来将在单节点预测水位时间序列的基础上将模型推广至多个空间节点,建立上下游的对应关系,真正体现出组合模型的优势。3 实 验
3.1 实验准备

3.2 评价指标
3.3 实验结果与分析






4 结 语
猜你喜欢
黄河之声(2022年10期)2022-09-27成都信息工程大学学报(2022年2期)2022-06-14中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化·高二版(2022年4期)2022-05-09心理学报(2022年4期)2022-04-12北京大学学报(自然科学版)(2022年1期)2022-02-21计算机系统应用(2020年1期)2020-01-15中学生数理化·七年级数学人教版(2008年10期)2008-01-21
