
基于深度残差网络图像分类算法研究综述①
2020-01-15 06:44:04赵志成王鹏彦
计算机系统应用 2020年1期
赵志成,罗 泽,王鹏彦,李 健
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
3(四川卧龙国家级自然保护区管理局,卧龙 623006)
深度神经网络的出现,使得图像分类领域取得了一系列的突破.深度神经网络可以通过多级表示,学习到更加复杂的高级语义特征.在一个端到端的多层模型中,低、中、高不同级别的特征以及分类器被整合起来,特征的等级随着通过所堆叠层的数量(深度)逐渐丰富[1–5].2012年,Krizhevsky[6]用5个卷积层和3个全连接层的网络在ILSVRC竞赛上取得了38.1%的Top-1和16.4%的Top-5错误率.2014年,VGGNet[7]首次将网络的深度增加到了19层,在ILSVRC竞赛上取得了24.7%的Top-1错误率和7.3%的Top-5错误率.回顾深度卷积神经网络在图像识别领域的发展历史,可以清楚地发现深度神经网络的表达能力和提取特征的能力随着网络的深度的增加而增加[8,9].
然而,网络的深度并非越深越好.在一定的深度范围内,随着网络层数的增加,模型可以拟合更加复杂的函数,模型性能也可以得到提升.但是在网络层数增加到一定的数目之后,继续增加网络的层数,训练精度和测试精度迅速下降.研究人员发现,随着网络深度的增加,准确率达到饱和后再增加网络的深度分类的效果反而越来越差.实验表明,20层以上的深度网络,继续叠加增加网络的层数,分类的精度反而会降低,50层网络的测试误差率大概是20层网络的一倍[10].这种网络的退化现象表明了直接增加深度的深度学习系统并不是很容易被优化.
为了解决由于深度增加带来的网络退化问题,2015年微软亚洲研究院的He等人[11]提出了深度残差网络(deep residual network).在残差学习(residual learning)的启发下,网络中引入了恒等映射的设计,巧妙的缓解了由于深度增加带来的梯度爆炸或梯度消失以及网络退化的问题,提升了信息传递路径的数量,使得网络的深度可以由几十层推到千层.深度残差网络的出现极大的提高了系统的准确率,使得训练极深的网络成为可能,是图像分类领域具有重要意义的突破性进展.
由于深度残差网络的优良特性,它被应用到多个领域,例如人脸识别[12]、目标检测[13]、行人检测[14]、语义分割[15]、自然语言处理[16]等,取得了很好的效果.本文将以深度残差网络在图像分类领域的进展为线索,简要阐述其成功的原因,介绍深度残差网络在图像分类领域的一些研究进展,比较这些不同的网络在图像分类数据集上的性能表现,探索未来研究的一些方向.
1 深度残差网络概述
1.1 深度残差网络介绍
直接增加网络的深度,会使得深度学习系统很难被优化.假设我们现在有一个浅层的网络,那么应该存在一个深层的网络:它是在由浅层网络的基础上堆叠了多个x→x(恒等映射)的映射构成的,那么该深层神经网络的性能至少应该不会比浅层网络的性能差.然而实验却证明找不到这样一个我们理想当中的深层神经网络,这种现象说明通过直接叠加深度的方式来拟合这样一个x→x恒等映射是非常困难的.
在浅层网络已经达到了饱和之后,通过在它后面再加上恒等映射层(identity mapping),不仅可以使得网络的深度增加使得模型有更强的表现能力,而且保证了系统的误差不会随着深度增加而增加[11].
假设原始神经网络的一个残差单元要学习的目标映射为H(x),这个目标映可能很难学习.残差神经网络让残差单元不直接学习目标映射,而是学习一个残差F(x)=H(x)−x.这样原始的映射变成了F(x)+x.原始残差单元可以看做是由两部分构成,一个线性的直接映射x→x和一个非线性映射F(x).特别地,如果x→x是最优的学习策略,那么相当于把非线性映射F(x)的权重参数设置为0.恒等映射使得非线性映射F(x)学习线性的x→x映射变得容易很多.
深度残差网络的基本组成单元是残差单元,残差单元一般由卷积Conv层,批处理归一化Batchnorm层和非线性激活函数Relu共同构成.图1给出了原始残差单元的示意图,令第l个残差单元的输入为xl,那么下一层的输出为:
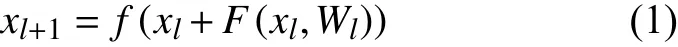
其中,F(xl,Wl)是残差函数,Wl是该残差函数对应的权重参数;f(∗)是非线性激活函数Relu.
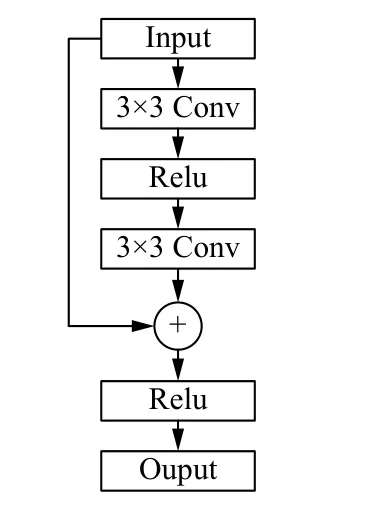
图1 原始残差学习单元结构图
深度残差网络由多个残差学习单元堆叠而成.给定输入的图像数据,深度残差网络首先将输入数据依次送入卷积层Conv、非线性激活函数层Relu和批处理归一化层Batchnorm;然后将处理的结果进一步送入到多个残差单元,再经过批处理归一化层BN 和多个全连接层;最后得到输出结果.
在构建”超深”的网络比如100层以上的网络时,将多个原始残差学习模块直接堆叠起来会造成参数的爆炸.为了在不损失精度的情况下降低深层网络的的参数量,He等人[10]提出了一种称为”瓶颈”(bottleneck)的残差模块结构,如图2.这种瓶颈结构的设计主要目的是为了减少参数量从而减少计算量,使得深度残差网络的训练速度加快.

图2 Bottleneck结构
1.2 残差单元的不同构造方式
在原始残差单元的基础上,研究者对于Batchnorm[17](批归一化)和激活函数Relu的放置位置和组合方式进行了不同的探索.研究发现,残差单元不同的构造方式对于精度、网络的收敛以及训练的速度都有影响.He等[10]在2016年提出了Pre-activation (预激活)的残差单元,提高了模型的泛化能力,减少了过拟合的影响.Han等[18]在此基础上,对于残差单元进行了更多的测试,不同残差单元的结构图如图3所示,不同残差单元在分类任务下的表现结果如表1所示.
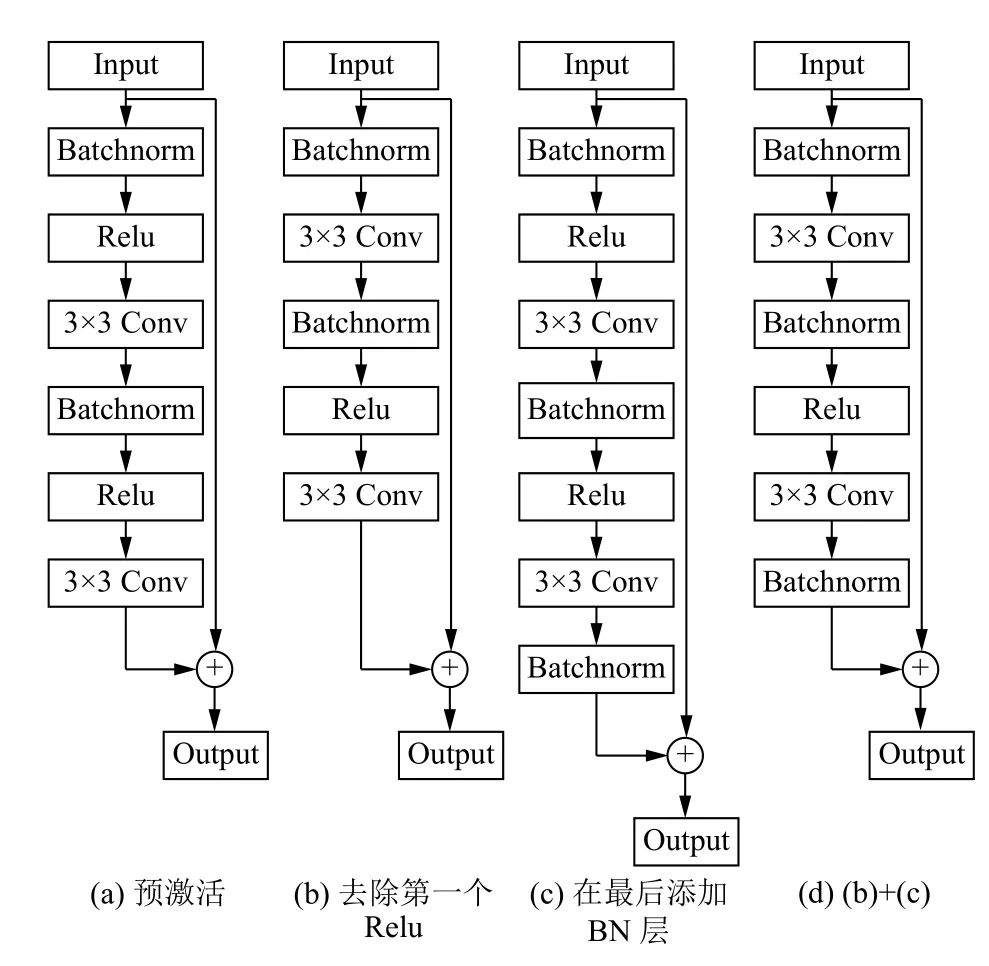
图3 不同残差单元结构图
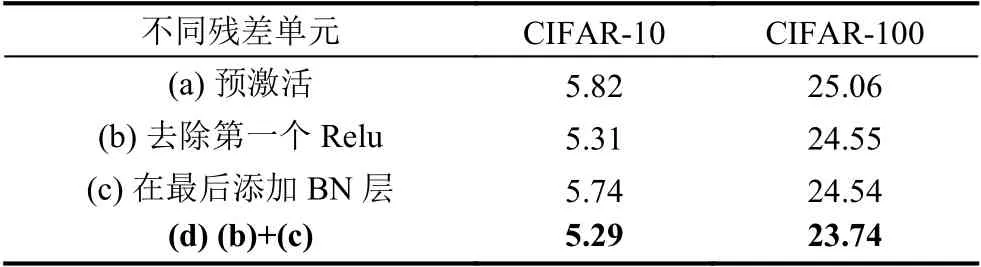
表1 不同残差单元错误率对比(单位:%)
2 常用图像分类数据集介绍
CIFAR-10和CIFAR-100是图像分类领域常用的比较性能的数据集.CIFAR-10数据集由来自10个类的60 000个32×32彩色图像组成,其中每个类包含6000个图像,有50 000个训练图像和10 000个测试图像[19],如图4.
CIFAR-100数据集是CIFAR-10的扩展数据集,它包含的类别数更多(100个类别),每个类别中有600张图像(500张训练图像和100张测试图像).除此之外,CIFAR-100中的100个小类还可以被分成20个大类.数据集中的每个图像都带有一个“精细”的类别标签(它所属的小类)和一个“粗糙”标签(它所属的大类).
3 不同变体在图像分类任务中的表现
在原始深度残差网络的启发下,研究者们从不同的角度出发(例如继续增加网络的深度、增加的网络的宽度、更细化的网络架构设计、引入注意力机制等等),为了增加模型的表示能力和泛化能力,提高模型提取特征的能力,对于深度残差网络进行了不同方向的改进,同时在CIFAR-10,CIFAR-100这两个图像分类数据集上进行了性能验证.

图4 CIFAR10数据集示例图[19]
3.1 更宽的残差网络
Zhang等人[20]的研究表明,不同于以往不断的叠加网络的深度,网络的宽度作为一个重要的维度也需要被关注.随着模型深度的加深,在梯度进行反向传播时,并不能保证能够流经每一个残差单元(Residual unit)的权重层,绝大多数的残差单元只能提供很少的信息,只有少数几个残差单元能够学到有用的表达提取到有用的特征[21,22].这里的“宽度”指的是特征映射的通道数,在卷积层中指的式增加卷积核的个数.Sergey等[23]从增加网络的“宽度”入手,提出了Wide Residual Netork (WRN),使用一种较浅的但是宽度更宽的模型,来更加有效的提升模型的性能.
宽残差网络的实验结果表明,宽度可以提高特征的复用,能够带来网络表现能力和泛化能力的提升,同样的参数数量,宽的网络训练训练速度也更快.WRN的具体构造如表2所示,不同深度的网络在数据集上的表现如表3所示.
3.2 “金字塔”型残差网络
Veit等人[24]的实验证明深度残差网络其实可以看做是相对较浅网络的集合.他们的研究表明,从残差网络中删除一个单独的残差单元,即只保留一个恒等映射,不会对整体性能产生明显的影响,经过不同的实验证明删除残差单元相当于删除集成的网络中的一些浅层的网络.但是在普通网络如 VggNet 和GoogleNet中,删除任意一个网络层都会导致网络的性能的骤降.

表2 k倍宽残差网络具体架构设计
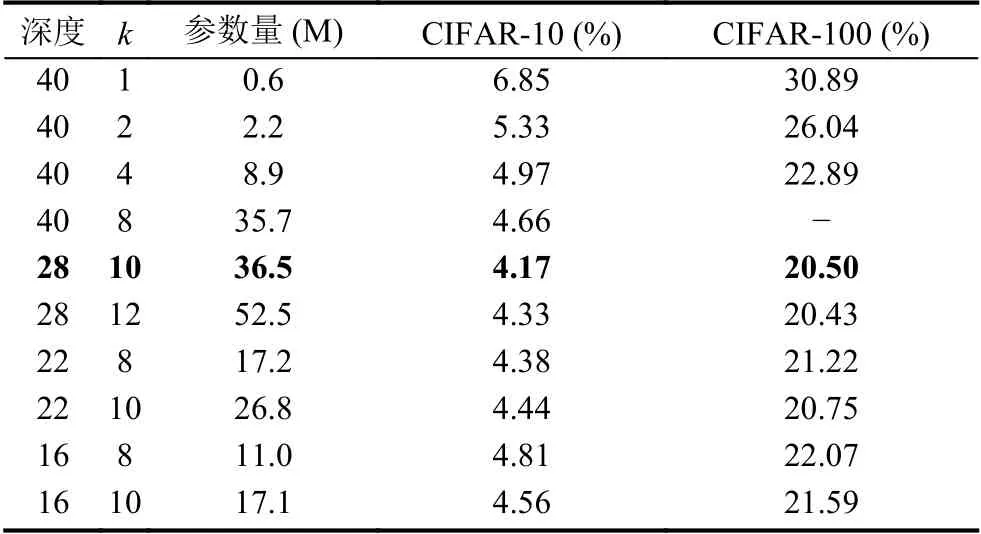
表3 不同配置的宽残差网络实验结果
深度残差网络下一般在下采样残差单元中将通道数加倍.实验发现,在深度残差网络中分别删除下采样功能的残差单元和非下采样的残差单元,删除下采样的残差单元会造成网络更多的性能下降.为了更好的解决这个问题,Han等人[18]设计了一个“金字塔”残差网络(Pyramidal residual Network,PyramidNet).如图5所示,不同于以往在下采样单元时网络突然加倍,该网络的宽度随深度的增加而逐渐增加,这种形状类似于从顶部向下逐渐变宽的金字塔结构.金字塔型残差网络具体结构如表4,分类错误率对比如表5.
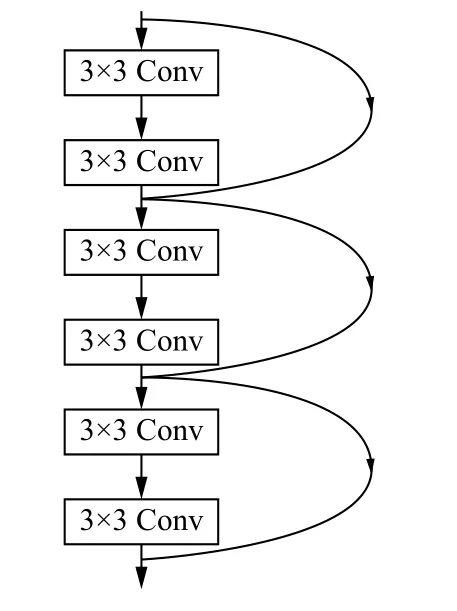
图5 金字塔型网络残差单元

表4 金字塔型残差网络具体架构

表5 金字塔型残差网络分类错误率对比
金字塔残差网络的通道数的具体计算公式如式(2),其中k代表第k层,N代表总的层数,Dk代表第k层的通道数,α代表最后一层输出通道数.
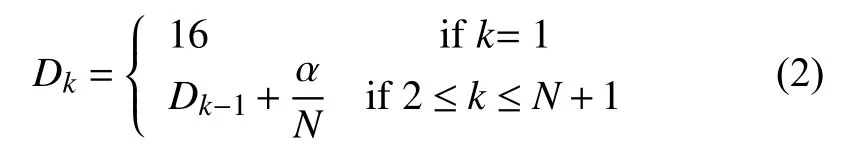
这种网络设计可以有效的改善过拟合的问题,与其他网络架构设计相比,它显示出很好的泛化能力;而且在金字塔型的残差网络中,删除具有下采样功能的残差单元不会降低性能.
3.3 密集型网络
受到 ResNet 将输入和输出相加形成残差结构的启发,Huang等人[21]设计出一种将输出与输入并联到一起的网络架构,实现了每一层都能直接得到之前所有层的输出的密集型卷积网络(Densely convolutional Network,DenseNet).该网络可以有效的缓解梯度消失的问题,增加特征的重用性,并大幅减少参数数量.在这种新型网络架构中,每层的输入由所有之前层的特征映射组成,其输出将传输给每个后续层.
在原始的深度残差网络中,恒等映射的输出是通过加法结合起来的.在这种情况下,如果两个层的特征映射的分布差异性很大的话,这有可能会影响特征的重用同时阻碍信息流的传播.密集型网络(DenseNet)(如图6)通过将特征映射级联而不是将特征映射直接相加,可以在保留所有特征映射的同时增加输出的多样性,促进特征被重用.实验证明,在相同的参数量下密集型网络具备更高的参数效率,有更好的收敛效果.表6是不同增长率k下的分类错误率.
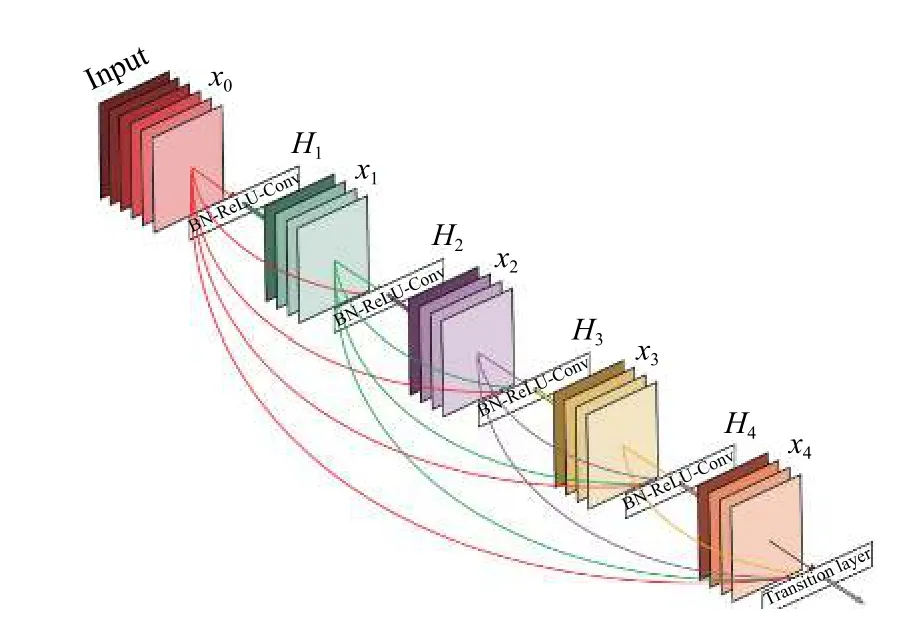
图6 密集型网络结构图[21]
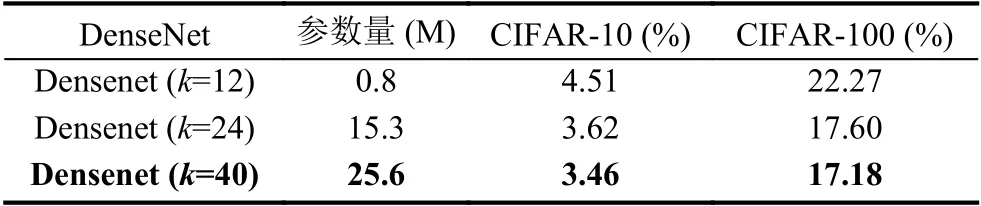
表6 不同增长率k下分类错误率
3.4 深度注意力残差网络
注意力机制在计算机视觉中也起着重要的作用,注意力机制不止能使得运算聚焦于特定的区域,同时也可以使得该部分区域的特征重要性得到增强.为了在深度残差网络中引入注意力的机制,Wang等[22]提出了残差注意力网络(Residual Attention Network,RAN).
一个注意力残差单元如图7所示,分为两个分支,右边的分支就是普通的卷积网络,即主干分支,叫做Trunk Branch.左边的分支是为了得到一个掩码mask,该掩码的作用是得到输入特征x的attention map,所以叫做Mask Branch,这个Mask Branch包含down sample和upsample的过程,目的是为了保证和右边分支的输出大小一致.
注意单元的计算公式如式(3),其中M(x)为Mask Branch的输出,F(x)为主分支的输出.借鉴了ResNet中恒等映射的思想,当掩码分支M(x)=0时,该层的输入就等于F(x),所以该层的效果至少不会比原始的F(x)差,残差单元更容易被优化.同时掩码分支的设计,使得特征图可以学习到不同大小的权重值,进而让主干分支输出的特征图中显著的特征更加显著,增加了特征的判别性.
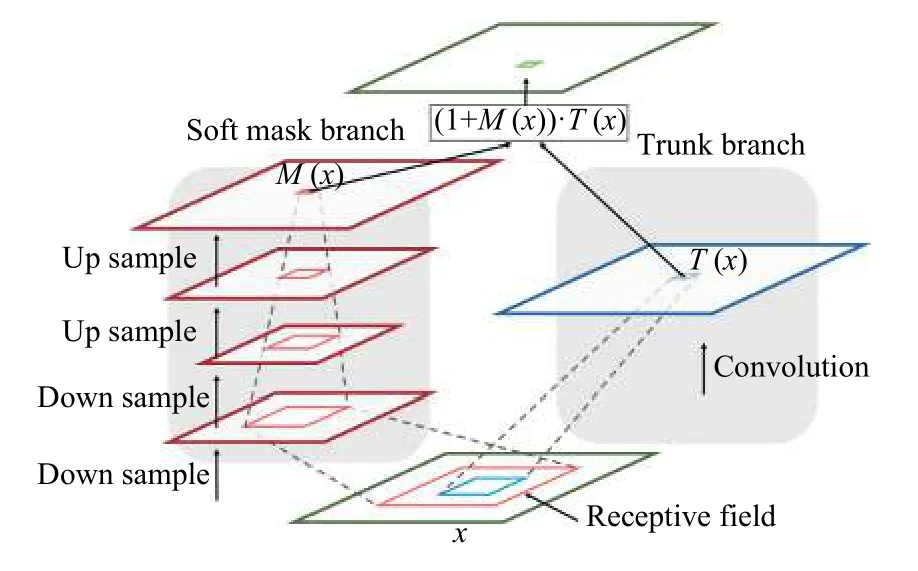
图7 注意力残差单元结构图[22]
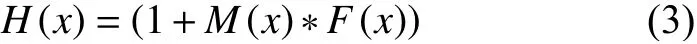
残差注意力模型不仅可以提升网络的性能,还具有很强的扩展性,可以结合到目前的大部分深层网络中,做到端到端的训练.因为残差结构的存在,也可以很容易将网络扩展到百数层.实验证明,使用该种策略可以在达到其他大网络的分类准确率的同时显著降低计算量(计算量基本上为原始ResNet深层网络的69%左右),具体的实验结果如表7所示.

表7 注意力残差网络错误率对比
3.5 随机深度残差网络
深度残差网络的由于网络更深或者更宽,网络的参数量很大,往往非常容易造成过拟合,模型在训练集上表现很好,在测试集上却表现很差.为了解决过拟合的问题,同时受到Dropout思想的启发,随机深度残差网络(ResDrop)[25]在训练时使用伯努利随机变量,随机使得一部分的残差单元”失活”,使得网络不依赖于某个特定的残差单元,起到一部分正则化的效果.和Dropout类似,在进行测试时使用整个网络进行预测.
在训练期间,随机深度残差网络的深度会减小,进而会导致前向传播和反向传播的深度变短,所以其训练时间不会随着深度残差网络的深度而线性地增加.
此外,训练期间网络深度的减少会增强前边层参数的梯度更加有利于梯度的传播,这将使得1000层以上的随机深度残差网络能够正常训练.随机深度的残差网络可以被看做不同深度网络的集成[24],与恒定深度的深度残差网络相比不易过拟合.随机深度残差网络在CIFAR-10和CIFAR-100上分别取得了5.25%和24.98%的错误率.
4 深度残差网络改进总结
深度残差网络一直是图像分类领域研究的热点.自从深度残差网络被提出以来,研究者们为了提升深度残差网络的表征能力和泛化能力,提高在分类任务上的表现,研究出了多个改进的版本[26–28].这些改进或变体可以大体可以分成基于残差单元的优化改进,基于整体网络结构的设计的改进、加入attention机制3种.
基于残差单元的改进主要是通过修改残差单元的不同层的摆放位置和修改残差单元的残差函数.Zhang在残差单元中加入Dropout[29]层取得了更好的表现,Xie等人[30]引入了一个“基数”的超参数通过增加残差单元独立路径的数量提高了准确率,在此基础上Gastaldi提出Shake-Shake正则化残差网络[31],采用随机仿射组合替换并行分支的标准求和来提高多分支网络的泛化能力.
基于整体网络结构设计的改进的研究是指改变网络结构的整体框架.通过改进深度残差网络的架构使得梯度更加容易传播,模型的表示能力更强,残差网络更容易优化.Zhang等人[32]在原始残差网络的基础上增加了一个层级的快捷连接构建了一个多级网络,Yamada等人[33]进一步把随机深度引入到“金字塔”残差网络框架中,提出了PyramidSepDrop网络模型.
将Attention机制引入深度残差网络是目前研究的热点方向之一.Squeeze and excitation networks[34]认为不同的特征映射通道的重要性不同,在他们的压缩和激励模块中,他们使用全局平均池化(Global Average Pooling)来计算通道的注意力(权重值).Woo等人[35]在此基础上,提出了卷积注意力模块CBAM (Convolutional Block Attention Module),利用一个有效的结构设计来结合空间(feature map)和通道的注意力,通过将空间注意力和通道注意力结合取得了在不同的数据集上取得了更好的性能.
此外,还有一些研究者将3种方法混合也取得了很好的效果,例如Tan等人[36]通过混合改进在CIFAR-10和CIFAR-100上分别取得了1.1%和8.3%的错误率,不同的深度残差网络性能表现如表8所示.

表8 深度残差网络性能对比
5 结论
深度残差网络的出现,极大的提高了深度学习的表征能力和学习能力,成为图像分类领域研究的热点方向.
本文分析了深度残差网络和其变体,比较不同模型在常用图像分类数据集上的性能表现,通过分析可见在图像分类领域深度残差网络已有一定的研究成果.鉴于目前深度残差网络和其变体还存在收敛速度慢、训练时间长、网络参数冗余、网络设计复杂、对于数据需求量大依赖人为标注等缺点,未来的研究方向在于:
(1)减少深度残差网络的参数,在不损失精度的情况下对于深度残差网络进行有效的压缩.深度残差网络由于在宽度和深度上增加了很多,会产生很多的冗余参数,如何在不损失性能的情况下减少深度残差网络的参数量从而提高深度残差网络的计算性能是个具有现实意义的问题.
(2)在数据量较小的情况下,获得更好的性能.目前在图像分类领域深度残差网络的精度仍然依赖于数据集样本的多少,数据增强的策略等.在数据标注不足的情况下,如何获得相同的性能也是一个值得关注的问题.更少的依赖有监督学习和人类的先验标注信息,将无监督学习或者强化学习和深度残差网络结合值得我们不断的探索.
(3)增强深度残差网络的学习能力和泛化能力.深度残差网络的参数量往往很大,模型往往在训练集上效果效果很好,在测试集上效果很差,如何防止过拟合使得模型可以很好地泛化是一个值得研究的问题.另外,在现有基础上,改进残差单元和残差网络的结构、引入注意力机制以及混合改进等,使得深度残差网络在分类任务上取得更高的准确率是值得深入探索的核心问题.
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
传媒评论(2017年3期)2017-06-13 09:18:10
教师·中(2017年3期)2017-04-20 21:49:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
河南科技(2015年8期)2015-03-11 16:23:52
