
基于四元数局部编码和卷积网络的表情识别
2020-03-07 13:12:00薛志毅邵珠宏赵晓旭尚媛园
计算机工程与设计 2020年2期
薛志毅,邵珠宏,2+,江 筱,赵晓旭,尚媛园,2,3
(1.首都师范大学 信息工程学院,北京 100048;2.北京成像理论与技术高精尖创新中心, 北京 100048;3.高可靠嵌入式系统北京市工程研究中心,北京 100048)
0 引 言
为了避免对彩色人脸表情图像进行灰度化预处理的过程中丢失颜色信息,近年来基于四元数矩阵表示的彩色图像处理与分析成为图像处理领域的研究热点。比如,Shao等[1]提出四元数正交Bessel-Fourier矩并应用于彩色图像重建与识别。Lan等[2]提出基于四元数矩阵表示的彩色图像局部二值描述子,通过借助参考四元数对原始像素进行等距映射,但是该方法仅对相位信息进行编码,没有充分利用四元数矩阵的信息。卷积神经网络(CNN)在表情识别领域已经被广泛的应用,比如Lu等[3]使用CNN进行表情识别,但是其仍然使用灰度图像。Zhang等[4]将深度网络应用于自然环境中的表情识别,也取得了不错的效果。
本文结合四元数的相关理论,将彩色人脸表情图像用四元数矩阵表示,并使用Clifford平移运算对矩阵进行变换,分别计算其加权L1相位以及幅值并使用LBP算法得到对应的相位图谱和幅值图谱。将融合的相位特征和幅值特征与卷积神经网络结合进行训练和识别。采用四元数表示方法能够减少颜色信息的丢失,提取的混合特征可以有效表征面部特征,使得算法具有更高更稳定的识别率。
1 四元数及彩色图像表示
1.1 四元数基础
作为传统复数的推广,四元数包含一个实部分量和3个虚部分量[5],一般可以表示为
q=a+bi+cj+dk
(1)
其中,a、b、c、d∈R,i、j、k为虚数单位且满足
i2=j2=k2=-1,ij=-ji=k,jk=-kj=i,ki=-ik=j
(2)
a称为四元数q的实部,bi+cj+dk称为虚部;当a=0时,称q为纯四元数。
根据四元数的实部分量和虚部分量,可以定义四元数的相位。其中,基于L1范数的四元数加权L1相位定义为
(3)
ω=(α1,α2,α3)T表示权重系数,β=(|b|,|c|,|d|)T, 当ω=(1,1,1)T时,ωTβ是 (b,c,d) 的L1范数。通过选择适当的权重值不仅能够凸显某个虚部分量,而且不同的权重选择可以得到不同的δ值。
假设q是一个四元数,通过引入一个单位纯四元数p可以对其进行平移变换。由于四元数的乘法不满足交换律,则定义式(4)、式(5)分别为q的右边型Clifford平移、左边型Clifford平移[2]
CTQr(q,p)=qp
(4)
CTQl(q,p)=pq
(5)
四元数Clifford平移是一种等距映射,即平移前后四元数的模相等。同时,两种平移类型的加权相位也相等。
1.2 彩色图像四元数表示
通常将彩色图像的像素值作为四元数的虚部分量进行编码,可以表示为
fq(x,y)=fR(x,y)i+fG(x,y)j+fB(x,y)k
(6)
其中,fR(x,y)、fG(x,y)、fB(x,y) 分别代表彩色图像每一像素点的红、绿、蓝分量。
使用式(6)这种纯四元数的方法可以实现一幅RGB彩色图像的整体处理,有效考虑了颜色通道之间的关联性和整体性。
2 结合卷积网络与四元数局部编码的表情识别
本文使用基于四元数相位信息和幅值信息的局部二值模式编码提取人脸图像的纹理特征,然后将特征融合输入CNN网络进行训练,算法的流程如图1所示。
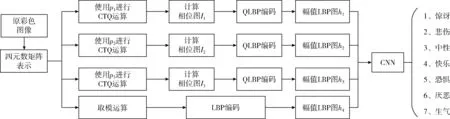
图1 算法流程
2.1 四元数局部编码特征
使用式(6)将一幅彩色图像表示成四元数矩阵,基于彩色图像的四元数矩阵表示,文献[2]提出一种通过引入参考四元数构建彩色图像局部特征描述子的方法。令彩色图像的像素点表示为:qs=ir+jg+kb, 参考四元数为:qr=ir′+jg′+kb′。 首先对像素点进行四元数Clifford平移(CTQ)运算
CTQr(qs,qr)=(ir+jg+kb)(ir′+jg′+kb′)= -(rr′+gg′+bb′)+i(gb′-bg′)+j(br′-rb′)+k(rg′-gr′)
(7)
然后使用式(3)计算四元数矩阵的加权的L1相位得到相位图。假设Sm是加权L1相位图中的3×3像素块,δm为中心像素值,则编码方法为
(8)
考虑到彩色图像包含3个颜色通道,选择3个适当的纯四元数分别对相应的相位信息矩阵进行LBP编码,从而可以提取四元数矩阵表示的相位局部二值模式(QPLBP)特征。同时,彩色图像的灰度值能够反映色彩强度信息,计算四元数矩阵的模并进行二值编码即可得到幅值局部二值模式(QALBP)特征,将两者结合起来可以进一步提高表征能力。
2.2 卷积神经网络
表1为本文使用的CNN结构及网络参数。

表1 CNN网络结构及参数设置
最大池化(Max-pooling)是CNN模型中最常见的一种池化方法,即最大子采样函数取区域内所有单元的最大值。使用Max-pooling操作,一方面可以保证表情特征的位置与旋转不变性,不用考虑其出现位置而能把它提出来。对于图像处理来说这种位置与旋转不变性是很好的特性;另一方面,能减少模型参数数量,在一定程度上可以防止模型过拟合。因此选择最大池化保留图像中明显的特征。
Dropout层是指在深度学习网络的训练过程中,对于神经元,按照一定的概率将其暂时从网络中丢弃,但在测试时仍然有效。它是一种有效防止训练过拟合的方法,通过在反向传播误差更新权值时随机选择一部分权值不更新,相当于训练出多个更为简单的模型,这些模型组合在一起,提高了整个网络的泛化能力,并且能够加快训练的速度。Dropout可以使用在各层之后,本文使用两层Dropout层。经过交叉验证,隐含节点Dropout率为0.5的时候效果最好,Dropout随机生成的网络结构最多[6]。
CNN使用前向传播(Feedforward Pass)来得到每个样本的预测输出,定义第L层的神经元输出为
xL=f(uL), 其中uL=WLxL-1+bL
(9)
其中,f是激活函数,本文选用的激活函数为ReLU函数,xL-1是L-1层的输出,W和b分别是L层的权值和偏置。通过式(9)实现样本信息逐层传递,直至得到最终输出层结果即表情类别。定义平方误差代价函数
(10)
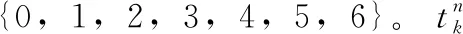
CNN权值W和偏置b的更新依靠BP算法来完成,BP算法反馈过程本质即为梯度从后向前传播,因此梯度下降法是BP算法的核心,由此可以得到参数W和b的更新规则
(11)
式中:η为学习率,为了保证网络的稳定性,在此η=0.01。 由式(11)可以看出,梯度下降法更新权值主要是利用误差代价函数对参数的梯度,所以权值更新的目标就是让每一层得到这样的梯度,然后更新。
3 实验结果与分析
为了验证本文算法的有效性,使用Radboud Faces Database(RafD)表情库和MMI表情库进行识别实验。RaFD表情库是一组包含67个模型的高质量的脸部数据库,根据面部动作编码系统,每个模型都经过训练以表达以下表情:愤怒,厌恶,恐惧,快乐,悲伤,惊奇,蔑视和中立。用3种不同的注视方向显示每种情绪,并且所有照片都是从5个相机角度同时拍摄的。本文选取RafD表情库中67个人的正面样本图像,每人包含7种表情(中性、生气、高兴、厌恶、恐惧、惊讶、悲伤),共1407张。MMI表情库包含2900多个视频和75个高分辨率的静态图像,标签主要是面部动作单元的标签,选取MMI表情库中自发表情库的17个人的样本图像,每人有6种表情(喜悦、愤怒、哀伤、恐惧、厌恶、惊奇),共306张。
3.1 人脸图像检测
SeetaFace Engine[7]是一个开源的C++人脸识别引擎,包含3个关键部分,即:人脸检测(detection)、面部特征点定位(alignment)、人脸特征提取与比对(identification)。SeetaFace Detection基于一种结合经典级联结构和多层神经网络的人脸检测方法实现。首先,使用SeetaFace Detection对RafD表情库和MMI表情库进行统一处理(人脸区域检测、对齐),然后将裁剪后的图像尺寸归一化为96×96像素,原样本图像和裁剪后的结果如图2所示,其中图2(a)和图2(c)为原图,图2(b)和图2(d)为人脸定位裁剪处理的结果。
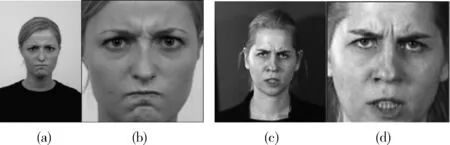
图2 RafD库和MMI库的人脸图像预处理示例
3.2 实验参数选择
3.2.1 权重系数的选择
式(3)中选取不同的权重系数也将会影响最终的分类效果,为了讨论如何选取合适的权重,在RafD表情库上进行了以下实验:按照 {0.1,0.2,0.3}, {0.2,0.3,0.4}…{1.0,1.1,1.2} 的规则设置10组不同的权重测得分类准确率,结果如图3所示。
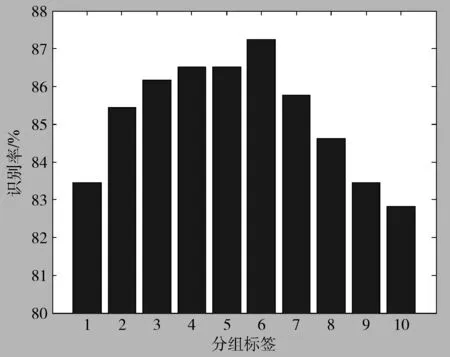
图3 选择不同权重时所取得的识别率
图3可以看出,第六组即权重为 {0.6,0.7,0.8} 时,分类准确率达到最大,在MMI数据库上测试能够得到相同的结论,该组权重即为本文实验时选用的权重。
3.2.2 参考四元数的选择
实验结果表明,特征提取过程中使用的参考四元数对识别率有一定的影响。为了保证选取的参考四元数经过CTQ运算后能够突出各个通道的特征,又不至于信息冗余,本文实验时选取3个参考四元数,参考四元数的选取可以使用基于学习的方法和手工选取的方法,为了计算的效率,本文选用手工选取的方法,3个参考四元数的选取规则如下
(12)
其中,随机数αmn∈[0,0.1](m=1,2,3;n=1,2,3)。 本文选取的参考四元数分别为:p1=0.9922i+0.0857j+0.0907k,p2=0.912i+0.9908j+0.0999k,p3=0.0852i+0.0855+0.9927k。 图4中给出了一幅彩色样本图像及相应的四元数相位局部二值模式(QPLBP)编码、幅值局部二值模式(QALBP)编码,其中图4(a)为原图像,图4(b)~图4(d)分别为使用p1、p2、p3提取的QPLBP编码,图4(e)为QALBP编码,可以看出通过QPLBP和QALBP能够提取丰富的纹理特征,将两种特征融合可以增强图像纹理特征的描述能力。

图4 样本图像及相应的QPLBP编码、QALBP编码
3.3 实验结果
实验中每次选取一个样本作为测试集样本,剩下两个样本作为训练集样本,进行交叉验证,表2和表3给出了使用两个表情库进行多次实验的结果。
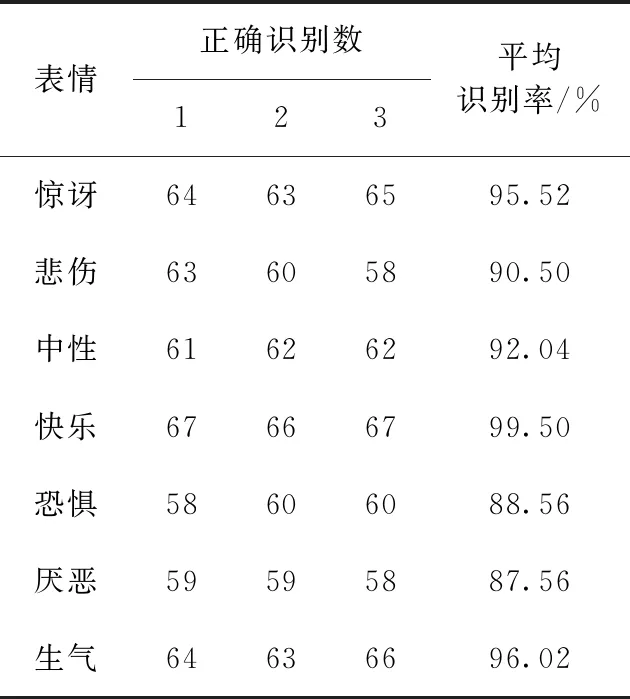
表2 RafD库表情识别的实验结果

表3 MMI库表情识别的实验结果
每种表情均获得了很好的识别率,可以看出本文算法能够有效识别分类表情,对快乐、惊讶、生气3种表情具有较高的识别率,而对恐惧、厌恶表情容易出现误识别。
针对上述误识别的情况进一步做了实验,为了更为直观的表现分类结果,将多次实验分类得到的表情分布做成混淆矩阵,表4和表5给出了在两个库上实验得到的混淆矩阵,从表中可以看出恐惧、厌恶在分类时更多的发生混淆现象,甚至误分类为生气、悲伤。根据表中数据以及面部动作单元(action unit,AU)[8]的研究,可以知道恐惧、厌恶表情在一定程度上能够具有极高的相似性,例如这些表情眼睛、鼻子等局部细节的变换上比较相似。对于同种表情,不同的人表情幅度也会不同,因此存在恐惧、厌恶、悲伤等相似表情相互转化的可能性。
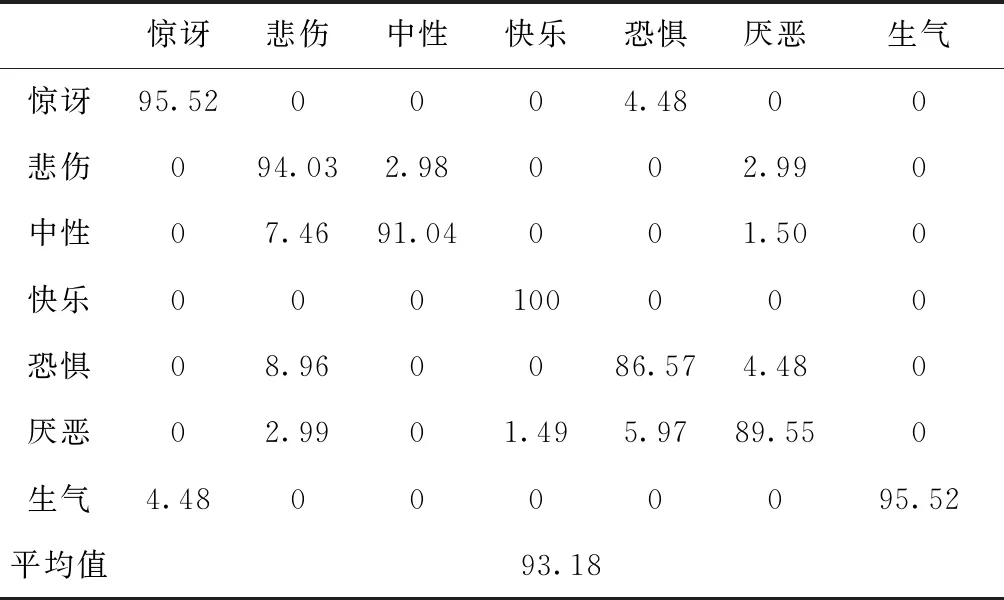
表4 使用RafD库识别的混淆矩阵(识别率/%)

表5 使用MMI库识别的混淆矩阵(识别率/%)
表6给出了不同算法的平均识别率,与仅用传统方法进行识别的分类方法相比,本文算法极大提高了识别精度,验证使用深度网络的有效性,与其它使用深度网络的算法进行比较,在RafD彩色表情库的平均识别率达到93.28%,在MMI彩色表情库的平均识别率达到79.41%,均优于其它算法,验证了人工方法结合深度学习的方法能够更好的提取可供表情识别使用的图像特征。
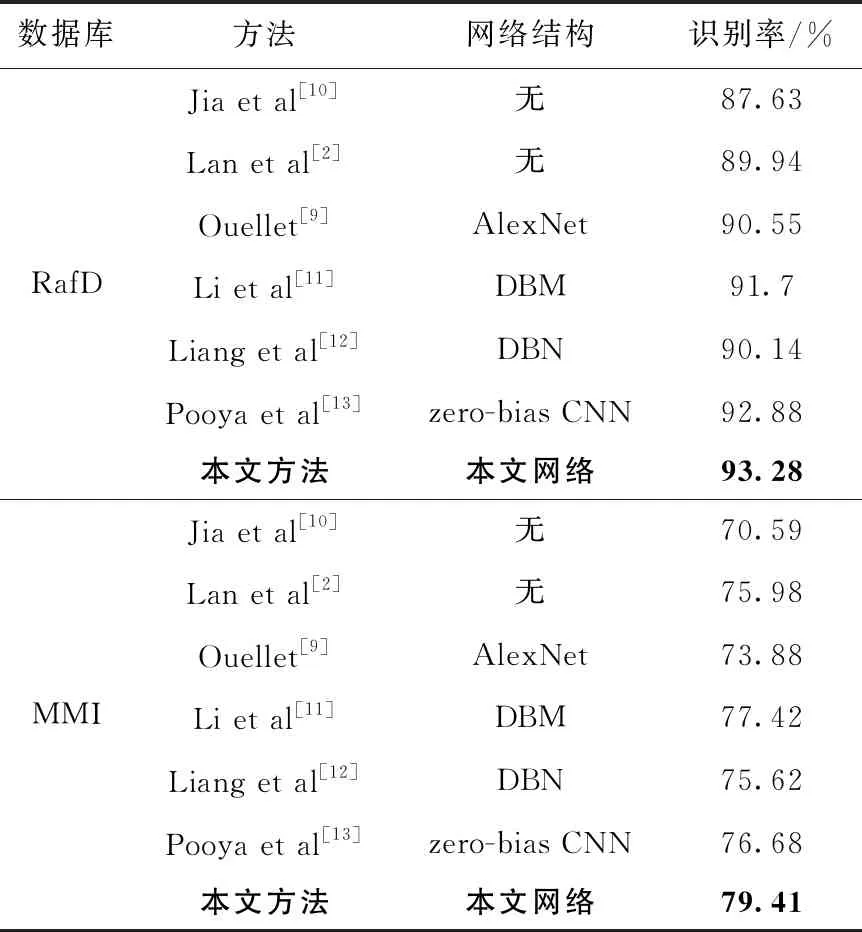
表6 不同算法的实验结果
4 结束语
为了能够充分利用彩色人脸表情图像的颜色信息和实现不同颜色通道的整体处理,本文基于四元数的表示方法对表情图像的相位信息和幅值信息使用局部二值编码提取特征,把两种特征结合起来输入卷积神经网络进行训练识别。与基于传统局部二值编码的算法相比,采用四元数的表示方法避免了图像灰度化过程中颜色信息的丢失,从而提取出比灰度图像更为丰富的特征信息。将人工特征与深度网络结合起来提高了识别精度的同时也能够获得稳定的识别效果。
猜你喜欢
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:10
高技术通讯(2021年2期)2021-04-13 01:09:46
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年16期)2019-09-27 09:34:46
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
测控技术(2018年10期)2018-11-25 09:35:28
中国交通信息化(2018年3期)2018-06-13 03:27:58
自动化学报(2017年5期)2017-05-14 06:20:56
计算机应用(2016年10期)2017-05-12 15:22:34
中国交通信息化(2016年2期)2016-06-06 07:28:02
