
经济社会转型背景下道德基尼系数的测算及其分解
2020-03-03 04:50:02李庆梅聂佃忠
甘肃社会科学 2020年1期
李庆梅 聂佃忠
(中共甘肃省委党校(甘肃行政学院) a.社会和生态文明教研部;b.经济学教研部,兰州 730070)
提要: 在国内率先提出道德基尼系数的概念,还运用专属的中国社会道德现状调查数据(SCSCSM)测算出当前我国道德基尼系数的大小,并运用科学严谨的定量分析方法进行分解。依据分解结果,得出两点研究结论:一是在国内率先提出当前我国的道德基尼系数远远高于0.445,已经超过警戒线;二是从分解的结果看,所有的变量都不同程度地扩大了道德水平差距,而从贡献大小来看,婚姻和职业变量的贡献率合计超过一半,被调查者父母的孩子数量、订阅报纸份数变量与有无娱乐活动场所、月收入水平、性别和有无手机等变量的贡献率基本相当,各占1/5强。在此基础上,提出相应的对策建议,即我国政府面临既要如何提升道德水平,又要如何缩小道德水平个体差距异常艰巨的“双重任务”。
一、引 言
党的十九届四中全会提出,加快完善社会主义市场经济体制,并且将之“扩容”为社会主义基本经济制度的重要组成部分。但不可否认的是,我国社会主义市场经济与西方发达国家的市场经济相比,至少有四个方面的不同。一是发育时间不同。西方发达国家的市场经济迄今已有500年的历史,而我国从1992年党的十四大正式提出建立社会主义市场经济体制开始算起,至今也只有区区27年的时间。二是发育速度不同。西方发达国家的市场经济发育速度是非常缓慢的,而我国社会主义市场经济的发育(经济转型)速度是非常急速的。三是发育的经济基础不同。西方发达国家的市场经济是在自然经济的基础上生长出来的,我国社会主义市场经济却是在计划经济的基础上脱胎换骨的结果。四是发育方式不同。西方发达国家的市场经济是通过“爬”(坡)的方式一路走来,而我国社会主义市场经济却是在“转”(型)与“拐”(弯)的阵痛中实现浴火重生[1]。
在我国经济社会转型的同时,还应该有文化转型和道德转型。这必然涉及核心价值观的重构。诚然,我们需要的道德文明应既与原有的植根于本土的道德传统不同,也与西方的植根于开放性市场经济道德传统迥异。从更深的层次上讲,西方国家完成与市场经济相适应的社会价值体系的重构用了400~500年的时间,考虑到我国的市场经济体制、文化传统和复杂国情,这一过程也至少需要几百年的时间[2]。换言之,与经济转型、社会转型相比,我国实现道德转型的难度更大、花费的时间也更长。正是基于这一背景,如何客观地评价、比较我们目前的社会道德状况,从而有利于加快建立与现代市场经济体制相适应的社会主义道德文明,这是一个亟须解决的重大课题。
党的十九大报告提出,要提高人民思想觉悟、道德水准、文明素养,提高全社会文明程度。这是因为,在经济与社会急遽转型的大背景下我们面临的社会道德现状堪忧。国内伦理学家唐凯麟先生甚至从现代性危机的高度来看待上述重大问题。这种“社会乱象”与“转型之痛”突出表现为道德失范(个人层面)、伦理缺失(社会层面)、社会脱序以及三大底线(法律底线、公序良俗底线、道德良知底线)不断下移。这种难以令人满意的社会道德现状迫使我们不得不探索测算社会道德水平差距的方法,理性看待与客观评价经济社会转型背景下的我国社会道德问题[3]。
基尼系数是广义的分析工具,不但可以用于收入(或财产)分配问题的研究,而且可以用于一切分配问题和均衡程度的分析。因此,常用的基尼系数除了收入基尼系数和财富基尼系数之外,学者还将这一概念拓展到非经济领域,陆续提出教育基尼系数[4-5]、资源环境基尼系数[6]、权力基尼系数等。沿袭同样的逻辑思路,本文在国内率先提出道德基尼系数的概念,用来衡量社会道德水平的差距大小。道德基尼系数跟一般意义上的基尼系数一样,也介于0~1之间。同样,道德基尼系数越大,社会道德水平的差距程度就越高;道德基尼系数越小,社会道德水平的差距程度就越低。此外,道德基尼系数也存在一个警戒线(系数同样假定为0.4),如果大于这一数值容易出现社会动荡。本文不仅提出道德基尼系数的概念,还测算出当前我国的道德基尼系数的大小,并运用科学严谨的定量分析方法进行了分解。依据分解结果可知,社会道德水平的差距究竟主要是由哪些因素造成的。
二、变量选取、数据来源与统计描述
(一)有效问卷统计
本文运用的数据是课题组自己专属的中国社会道德现状调查数据(SCSCSM)。调查问卷分为城市问卷与农村问卷。在调查过程中共发放问卷912份。其中,调查环节产生废卷或无法回收问卷34份,验收环节剔除无效问卷56份。经过上述两个环节后有效问卷为822份。接下来的录入环节剔除无效问卷20份,问卷修正环节建议作废40份。经过4个环节的“过滤”之后,有效问卷合计762份。其中,城市问卷569份,涵盖14个省份;农村问卷193份,涵盖8个省份。经过简单计算可以得出,问卷回收率为90.13%,问卷有效率为92.70%。前者一般没有特别要求,后者一般要求90%以上即可。
(二)变量统计描述

表1 关于被解释变量与解释变量的统计描述
注:(1)解释变量不含虚拟变量;(2)样本总数为762个,其中党员数量(含民主党派)为233个,非党员为529个,后面的均值、标准差、最小值以及最大值是针对党员数量而非样本总数而言的;(3)样本总数为762个,其中未婚者为181个,已婚者(含离婚者、丧偶者、再婚者等)为581个,后面的均值、标准差、最小值以及最大值是针对样本总数而非已婚者数量而言的;(4)样本总数为762个,其中持城市户口者为470个,非城市户口者为292个,后面的均值、标准差、最小值以及最大值是针对非城市户口者而言的。
关于变量的统计描述如表1所示。其中,道德指数为被解释变量,用它来衡量社会道德水平的高低,其他的均为解释变量。关于道德指数的构建,课题基于利他行为的角度从亲缘利他、互惠利他和纯粹利他3个维度测度道德水平。其中,互惠利他又进一步细分为直接互惠和间接互惠。因此,总指标——道德资本存量由4个一级指标构成,依次是亲缘利他、直接互惠、间接互惠和纯粹利他。在此基础上,每个一级指标再细分为若干个二级指标,共计14个。以此类推,每个二级指标又细分为若干个三级指标,共计28个。
三、运用逐步回归法分析影响道德的因素
本文是从道德影响因素的角度进行实证分析,运用逐步回归法进行估计,采用多元回归法中的“后退法”和“前进法”进行自变量筛选。鉴于剔除异常值前的前进法与后退法在计算结果上存在某些差异,为了减轻异常值的影响,在回归过程中还对所有离散变量在1%和99%水平上进行了Winsorize处理。数据处理后,绝大多数变量的标准误下降,估计结果有所改善(见表2和表3)。在后退法中,除了10%显著性水平下的信仰、父母孩子数量以及截距项的标准误变大以外,其他变量的标准误均出现不同程度的下降。在前进法中,所有变量(剔除异常值后第一次出现的变量不除外)的标准误均出现不同程度的下降。
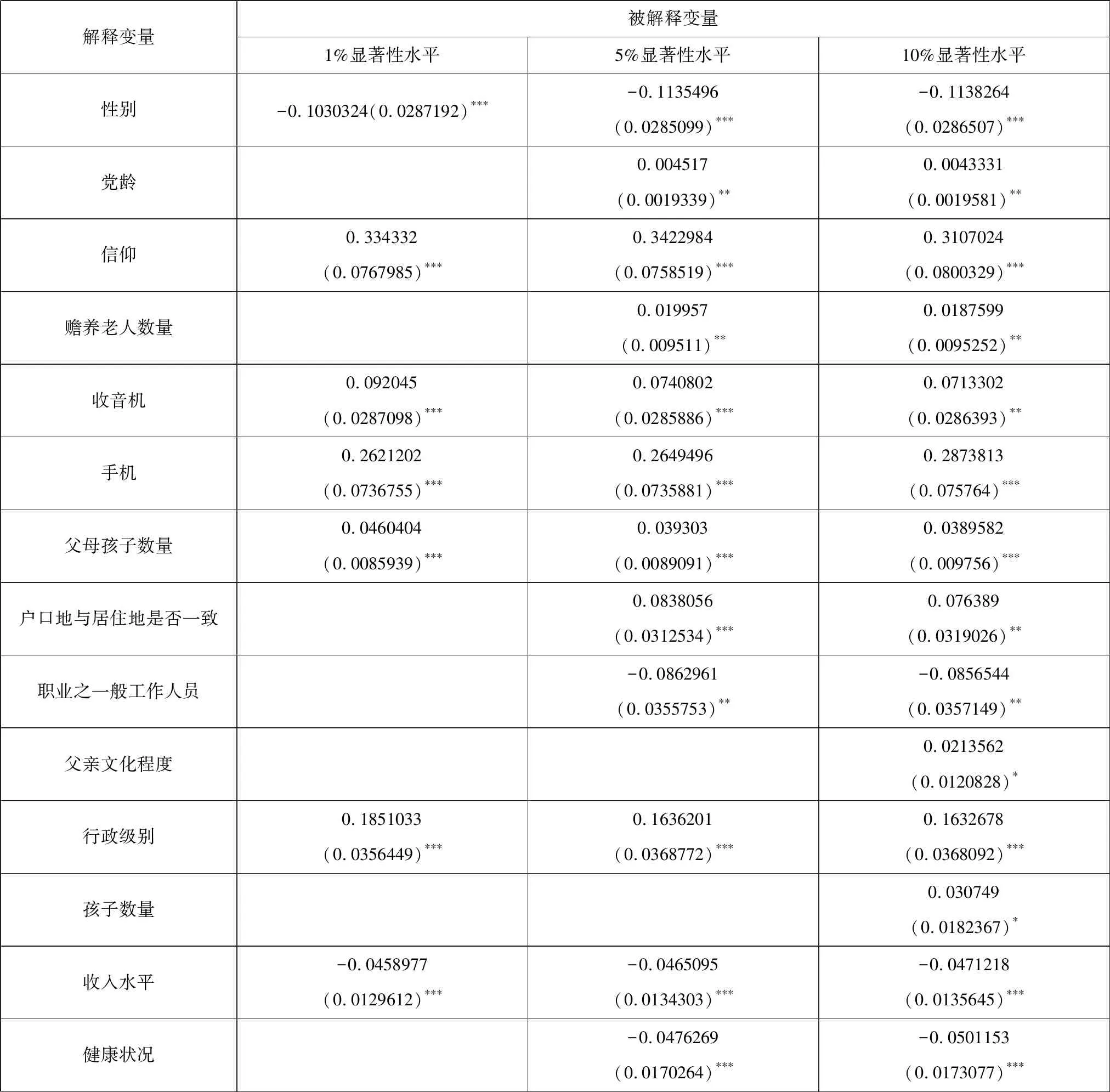
表2 道德指数与解释变量之间的回归结果(剔除异常值后采用后退法)
(续表2)
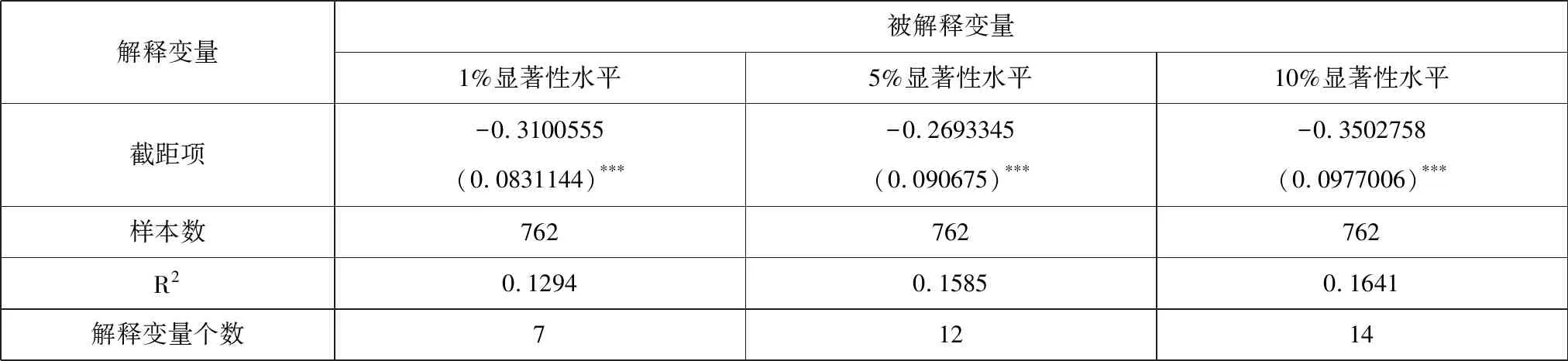
解释变量被解释变量1%显著性水平5%显著性水平10%显著性水平截距项-0.3100555(0.0831144)-0.2693345(0.090675)-0.3502758(0.0977006)样本数762762762R20.12940.15850.1641解释变量个数71214
注:括号内为标准误,表示1%统计水平上显著,表示5%统计水平上显著,表示10%统计水平上显著。
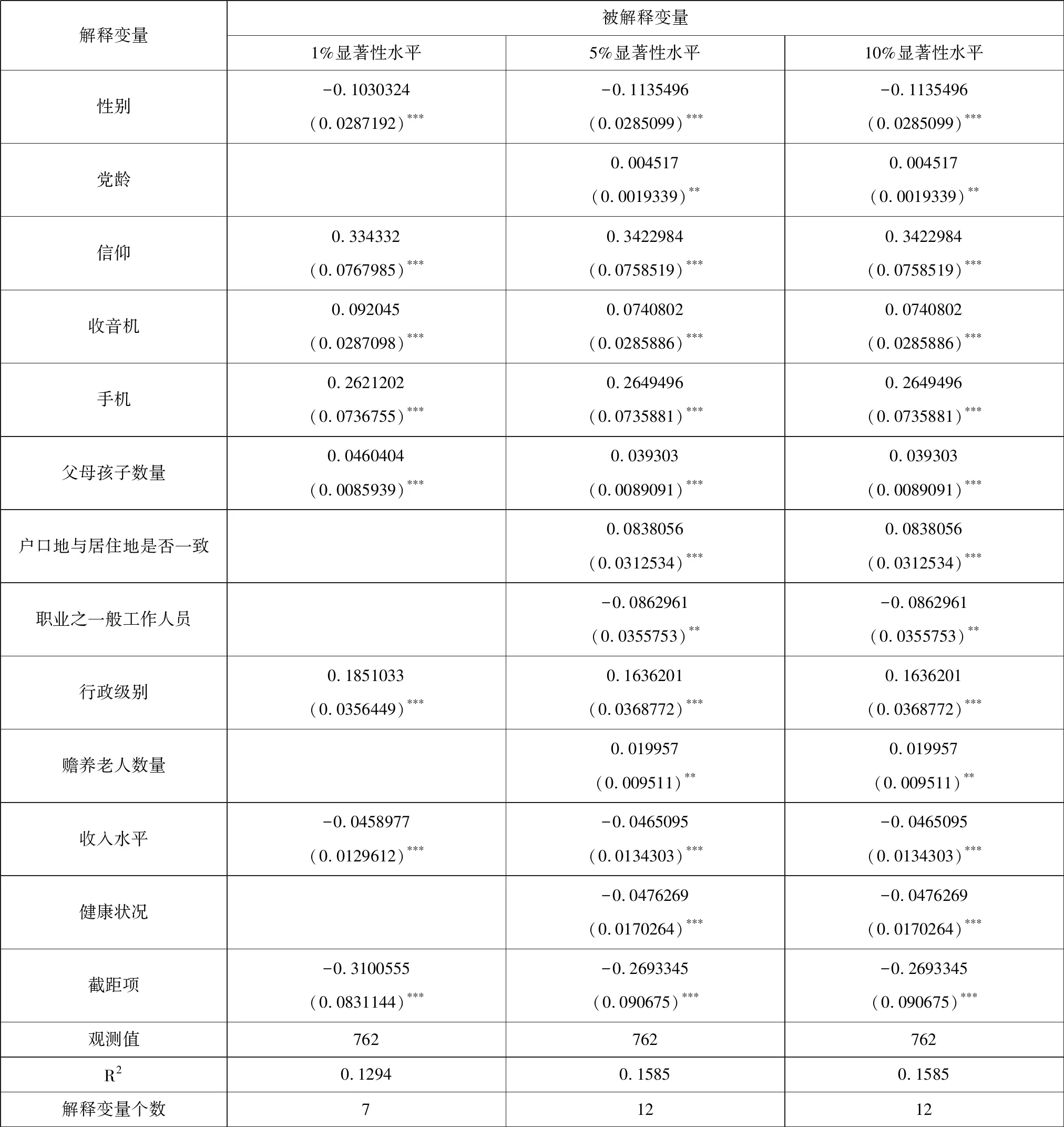
表3 道德指数与解释变量之间的回归结果(剔除异常值后采用前进法)
注:括号内为标准误,表示1%统计水平上显著,表示5%统计水平上显著,表示10%统计水平上显著。
通过比较发现,剔除异常值前后的后退法在计算结果上的差异主要表现在:第一,显著性水平为1%时,剔除异常值前后选取的变量数相同(均为7个),且构成也完全相同;第二,显著性水平为5%时,剔除异常值前后选取的变量数相同(均为12个),且构成也完全相同;第三,显著性水平为10%时,剔除异常值前后选取的变量数相同(均为14个),但构成不完全相同。除了剔除异常值前的婚姻状况之离婚、娱乐活动室两个变量(含分量)与剔除异常值后的孩子数量、父亲文化程度两个变量不同,其余12个变量完全相同。
通过比较发现,剔除异常值前后的前进法在计算结果上的差异主要表现在:第一,显著性水平为1%时,剔除异常值前后选取的变量数相同(均为7个),且构成也完全相同。第二,显著性水平为5%时,剔除异常值前后选取的变量数相同(均为12个),但构成不完全相同。除了剔除异常值前的婚姻状况之已婚、娱乐活动室两个变量(含分量)与剔除异常值后的赡养老人数量、户口地与居住地是否一致两个变量不同,其余10个变量完全相同。第三,显著性水平为10%时,剔除异常值前后选取的变量数略微不同(剔除异常值前为13个,剔除异常值后为12个),构成也不完全不同。除了剔除异常值前的婚姻状况之已婚、娱乐活动室两个变量(含分量)与剔除异常值后的赡养老人数量一个变量不同,其余11个变量完全相同。
通过比较发现,剔除异常值后的前进法与后退法在计算结果上的差异主要表现在:第一,显著性水平为1%时,两种方法选取的变量数相同(均为7个),且构成也完全相同。第二,显著性水平为5%时,两种方法选取的变量数相同(均为12个),且构成也完全相同。第三,显著性水平为10%时,两种方法选取的变量数略微不同(前进法为12个,后退法为14个),构成也不完全不同。除了后退法中的孩子数量、父亲文化程度两个变量不同,其余12个变量完全相同。
综上,以显著性水平为10%时剔除异常值后的前进法与后退法共同选取的12个自变量为准进行回归,求出各自的偏回归平方和U(i),并求出各方程项对回归的贡献百分比(按偏回归平方和降序排列)。
从线性回归结果来看,道德指数(Index)与信仰(dIslam)、本人行政级别(F12)、父母孩子数量(F21)、性别(dmale)、有无手机(dmobile)、收入水平(F2)、健康状况(F4)、户口地与居住地是否一致(dhouseholdregister)、有无收音机(dradio)、职业为党政企事业单位一般工作人员(dstaff)、党员党龄(F05)及赡养老人数量(F09)之间具有非常显著的线性相关关系(在显著性水平α=0.10上统计显著)。
由前面的偏回归平方和以及回归贡献百分比的大小得知,12个因素的主次顺序为dIslam>F12>F121>dmale>dmobile>F2>F14>dhouseholdregister>dradio>dstaff>F105>F109。
四、基于夏普里值过程的回归方程分解方法分析影响道德的因素
继续从道德影响因素的角度进行实证分析,主要是基于夏普里值(Shapley Value)过程的回归方程分解[7-9]。
(一)道德水平决定方程的估计
首先强调的是,与逐步回归法相比,基于夏普里值过程的回归方程分解方法有三点不同:一是前者主要适用于线性方程,而后者可以运用于非线性方程;二是前者在选择自变量时没有考虑平方项、交叉项及其对数形式,而后者充分考虑了这些内容;三是估计的观测值有较大差异,前者的样本数是762个,而后者的样本数是339个,意即只取道德指数大于零的部分。
当然,鉴于Heckit估计参数的标准误比OLS估计要小一些,这里的回归方程仍然采用前面的Heckit方法进行估计,样本数也是339个,唯一不同的是在分解环节大幅度压缩了解释变量的数量。
具体而言,研究分为两步:首先,估计一个半对数的道德水平决定方程;然后,在这个道德水平决定方程的基础上,进行道德水平差距分解。
估计的道德水平决定方程如下:
(1)
其中,Index系被调查者的道德指数,表示个人道德水平的高低;X是一组解释变量构成的向量;β是由待估系数构成的向量;下标i表示调查样本中的被调查者个人;ε是残差项。
由于在道德水平决定方程中选用了半对数模型,如果在分解时仍使用道德水平的对数作为因变量来分解,就会造成对道德水平变量分布的扭曲,所以在写分解决定方程时对两边取了指数e,得到方程式(2):
(2)
关于方程式(2)中参与分解的自变量的选择,陈光金从所有显著的变量中选择需要分解的对象,而王鹏、陈钊、万广华、陆铭则把回归中部分不显著的变量(少数民族、工作经验、经验平方项等)也投入分解的行列当中[10-12]。经慎重考虑,笔者筛选参与分解变量的原则:一是OLS回归中显著的9个变量(含分量):性别、订阅报纸数量、手机、父母孩子数量、兄弟姐妹排行、职业变量(生产工人和单位负责人两个分量)、婚姻状况(已婚分量)、娱乐活动室。二是重点考虑Heckman两步法估计显著的6个变量(含分量),即订阅报纸数量、手机、父母孩子数量、职业变量(单位负责人和个体经营人员两个分量)、婚姻状况(已婚分量)。三是重点考虑Heckman两步法排除性约束之后估计显著的7个变量(含分量),即订阅报纸数量、手机、父母孩子数量、兄弟姐妹排行、职业变量(生产工人分量)、婚姻状况(已婚分量)、娱乐活动室。四是考虑Stepwise之前进法(显著性水平为10%)的11个变量(含分量),即性别、订阅报纸数量、手机、现居住地居住时间、收入水平、职业变量(生产工人、单位负责人、一般工作人员和个体经营人员分量)、婚姻状况(已婚分量)、娱乐活动室。五是考虑Stepwise之后退法(显著性水平为10%)的12个变量(含分量),即性别、订阅报纸数量、手机、父母孩子数量、兄弟姐妹排行、现居住地居住时间和户口地与居住地是否一致的交叉项、收入水平、职业变量(生产工人、单位负责人和个体经营人员分量)、婚姻状况(已婚分量)、娱乐活动室。
统筹考虑了以上5个方面后,笔者将参与分解的自变量确定为14个(含分量):性别、订阅报纸数量、手机、父母孩子数量、兄弟姐妹排行、现居住地居住时间、现居住地居住时间和户口地与居住地是否一致的交叉项、收入水平、职业变量(生产工人、单位负责人、一般工作人员和个体经营人员分量)、婚姻状况(已婚分量)、娱乐活动室。
更进一步地,由于分解方法涉及的运算量非常大,每增加一个变量,该程序的计算量将呈几何级数增长;当变量超过10个时,由于运算量过大,往往无法得到结果。因此,为了简化计算,在分解时对相关变量进行了处理,即鉴于现居住地居住时间、户口地与居住地是否一致以及两者的交叉项在OLS估计和Heckit估计中均不显著,剔除以上3项。模型中还有几个虚拟变量,即婚姻状况变量和职业分类变量,可以基于它们的回归系数,对其做进一步归并整理:一是分别以已婚、离婚、丧偶以及其他情况的回归系数作为预测值(参照类型即未婚者的观察值仍为0),建立一个统一的婚姻状况变量;二是分别以10个阶层类别的回归系数为预测值(参照群体即农林牧副渔生产人员的观察值仍为0),建立一个统一的职业分类变量。这样一来就可以将进入夏普里值分解程序运行的变量减少到10个。
(二)道德水平差距的分解
将方程式(1)转换为一个指数方程式(2),对道德水平不平等的基尼系数进行夏普里值分解,得到如表4、表5所示的结果[13-14]。

表4 道德水平差距和被解释比例
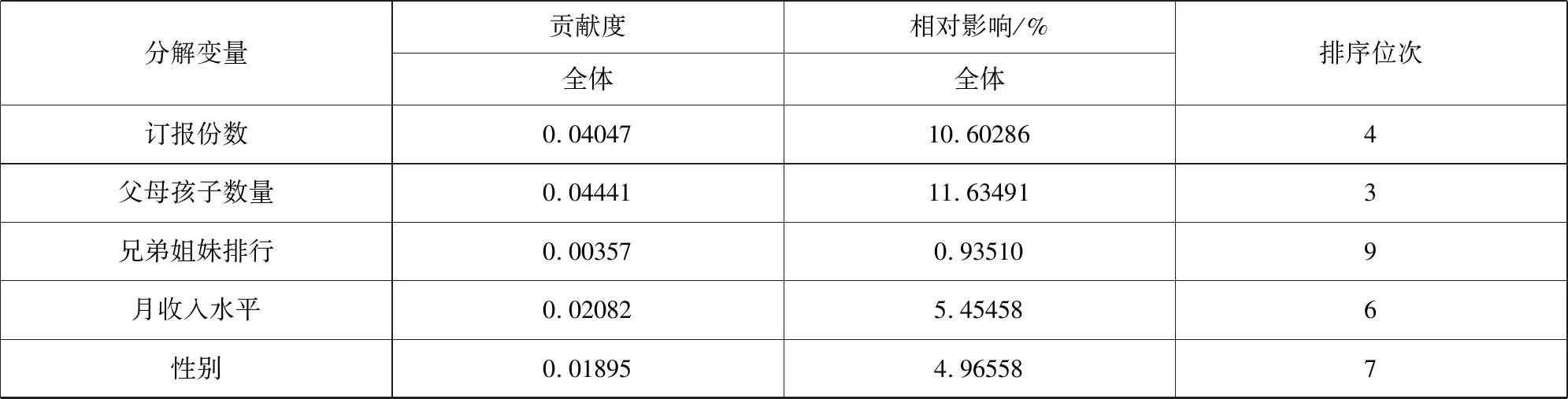
表5 道德水平差距分解结果
(续表5)
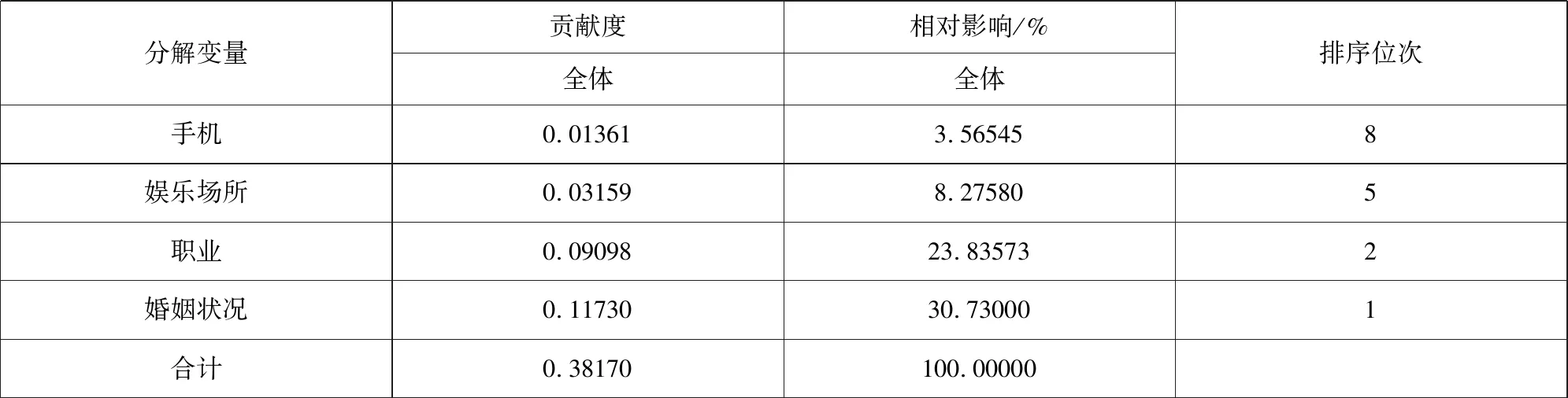
分解变量贡献度相对影响/%全体全体排序位次手机0.013613.565458娱乐场所0.031598.275805职业0.0909823.835732婚姻状况0.1173030.730001合计0.38170100.00000
从表4来看,总的道德基尼系数是0.445。实际上,我国目前的道德基尼系数远远高于0.445。这是因为测算样本仅为道德指数为正的部分(339个样本),不包括道德指数为负的部分(423个样本)。严格准确地说,0.445是我国目前的正道德基尼系数,而不是道德基尼系数的全部。
如果简单套用国际通用的收入(或财产)基尼系数的测算标准,照此推算,我国的道德水平差距目前已经超过警戒线(道德基尼系数为0.4),说明正处于经济社会转型深化期的当下中国,不仅面临如何调节收入(财产)分配差距过大的艰巨任务,也同时不得不高度关注公民道德水平差距偏大的事实,甚至出现道德水平“贫富”两极分化的趋势。问题的关键在于,在道德滑坡、伦理失范的大背景下,我国政府在道德运行轨道“纠偏”上花费的时间之长与代价之大绝非缩小收入分配差距问题所能比拟的。诚然,后者的妥善解决本身就不是一个简简单单的经济、社会乃至政治问题。
从表4和表5来看,分解结果非常理想,得到解释的不平等占85.74%,残差部分仅占14.26%。所有9个变量都具有扩大不平等的作用,而从贡献大小来看,由大到小的排序依次是婚姻状况、职业、父母孩子数量、订阅报纸数量、娱乐活动场所、收入水平、性别、手机、兄弟姐妹排行。大体可以把它们分为3组。第1组由婚姻状况和职业变量组成,两者的贡献率合计达到54.57%。第2组包括被调查者父母的孩子数量和被调查者订阅报纸份数,它们的贡献率都略高于10%,合计为22.24%。第3组包括娱乐活动场所、收入水平、性别和手机变量,它们的贡献率合计为22.26%。其余1个变量是被调查者在其兄弟姐妹中的排行位次,它的贡献率仅为0.94%,对道德水平差距的贡献可以忽略不计。
五、研究结论、政策含义与不足之处
(一)研究结论旨在说明道德基尼系数有多大、道德水平差距的扩大是谁造成的
本文的研究结论主要有两点:一是在国内率先提出当前我国的道德基尼系数远远高于0.445,已经超过警戒线,说明正处于经济社会转型深化期的当下中国,必须高度重视公民道德水平差距偏大的事实,甚至出现道德水平“贫富”两极分化的趋势。二是从分解的结果看,所有的9个变量都不同程度地扩大了道德水平差距,而从贡献大小来看,大体可以把它们分为3组。第1组由婚姻状况和职业分类变量组成,两者的贡献率合计超过一半。第2组(包括被调查者父母的孩子数量和被调查者订阅报纸份数)与第3组(包括有无娱乐活动场所、月收入水平、性别和有无手机变量)的贡献率基本相当,各占1/5强。
(二)政策建议的立足点应既要提升整体道德水平,更要缩小道德水平个体差距
我国政府面临艰巨的“双重任务”:一个是如何提升整体道德水平,以期尽快解决道德滑坡问题,另一个是如何缩小道德水平个体差距,尽快形成道德水平分布较为合理,进而个体差距达到适度性要求,以防接近甚至超过社会容忍度或社会道德底线的格局。第二个任务恰恰是目前理论界和政策界没有引起足够重视的地方。
(三)今后需要进一步深入研究道德异质性等相关问题
从本文的研究内容来看,还有诸多方面的不足之处,需要我们今后进一步深入研究。特别是,传统道德和市场经济道德存在较大的异质性,而目前恰好处于社会文化转型深化期,这一大背景无疑给道德水平测度增加了不少困难。毕竟,转型深化期的社会道德(包括水平、结构)既不完全等同于中国的传统道德,也不能与西方成熟的市场经济道德相提并论。退一步说,即便我们孤立地研究中国经济社会转型中的道德测度问题,也存在较大的异质性。当然,它更多地表现为同一文化传统中不同亚文化圈的异质性。例如,流动人口/非流动人口、城市/农村、沿海/内地、东部/中部/西部、汉族/少数民族等。鉴于此,课题组今后紧紧围绕前期研究主题进一步细化并继续开展后续研究。比如,基于夏普里值过程的回归方程分解时不仅计算全国的道德基尼系数,还要计算流动人口与非流动人口,城市与农村,沿海与内地,东部、中部与西部,汉族与少数民族等不同类型的道德基尼系数,并与全国的道德基尼系数进行比较,同时解释其原因;再如,正是基于夏普里值过程的回归方程分解方法与前面的逐步回归法有3点不同之处,再加上两者方法上的根本性差异,最终导致按照贡献大小筛选出的变量集合不同,先后次序也千差万别,等等。
猜你喜欢
家庭影院技术(2018年3期)2018-05-09 07:06:36
中国证券期货(2017年3期)2017-03-30 15:52:52
统计与决策(2017年2期)2017-03-20 15:25:28
卷宗(2017年1期)2017-03-17 11:48:59
环球时报(2017-02-10)2017-02-10 06:45:12
现代经济信息(2016年16期)2016-07-26 13:47:43
管理现代化(2016年6期)2016-01-23 02:10:51
中国全科医学(2015年33期)2015-12-02 04:07:12
中国卫生(2015年5期)2015-11-08 12:09:58
爆笑show(2014年3期)2014-06-25 06:39:06
