
基于PCM构建的索引数据结构设计研究
2020-02-02 01:18:12崔莹,刘兵
铜陵职业技术学院学报 2020年4期
崔 莹,刘 兵
(铜陵职业技术学院,安徽 铜陵 244000)
随着大数据技术应用的推广,计算机系统对内存的容量要求越来越高,需要足够的页面缓存来保证程序能够快速执行。冯诺依曼结构计算机的处理器从大容量存储中获取数据一般都会花费许多时间,这已经成为提升当代计算机性能所能遇到的最大瓶颈。单纯通过优化算法来改善效果十分有限,需要通过构建新的存储系统才能改善。
随着材料和存储技术的发展,以相变存储器(PCM,Phase change Memory)为代表的新型非易失性存储(NVM,non-volatile memory)技术近年来取得了重大进展,研究者们建议用新型NVM技术来代替传统存储技术,因而需要研究与其适配的高效率存储系统。PCM技术的迅速发展让学术界开始关注如何设计适用于PCM的数据索引结构这个课题。不同于一些传统研究项目,在这个新兴领域目前我国专家学者暂处于较领先的水平。
一、背景知识
(一)PCM存储器简介
PCM的基本存储原理是在元器件上施加不同的电流信号,使得相变材料(硫化物)发生物理相态的变化,从而产生导电性的差异来存储数据。即使在断电情况下PCM也能保存数据,同时数据擦写速度还很快,是目前技术最成熟的新一代存储器。
PCM技术的主要优点在于存储密度高和具有非易失性,前一个优点可使得内存容量比现在有所扩大,后一个让存储器即使掉电数据仍可以长期保存,最长的期限可达10年。另外PCM还有字节可寻址、低能耗等特点。
PCM也有很明显的缺点。首先这种存储器较易磨损,读写次数有限一旦达到一定的次数,就无法对存储在其中的数据进行读写操作;其次PCM内存写速度缓慢读写速度不平衡,读性能与DRAM相似(约1-5倍),但在写运算中,DRAM速度约是它的5-50倍。因此,如果用PCM全部取代DRAM,引入实际内存系统时,可能会产生意想不到的性能下降和寿命缩短的现象,因此目前主要是将两种技术组成混合架构投入实际应用。
(二)PCM带来的数据结构问题
索引是重要的数据结构,对系统性能有着重要的影响,在大数据应用背景下,数据库的性能主要体现在高效率的索引查找上。常见的索引结构有以下几种:B+树、hash表等。B+树形索引结构在区间索引上占据优势,而hash结构在查找单个值索引上有优势。比如:MYSQL的innodb引擎采用了B+树索引结构,而Memcache和redis采用了hash索引结构。为了同时支持范围查询和单点查询,也有学者提出了混合索引的设计。
以往的数据结构都是为DRAM内存设计的,提供对称的读写速度,而PCM最明显的一个特征就是读写速率的不平衡。这些索引结构中插入,删除和拆分等操作以及保持数据的一致性的方法,均会引入较多的写操作,对于PCM来说会带来性能下降问题。
在现有的PCM性能提高研究中,已经出现了对各类不同技术层次的探索。比如,有的研究者从硬件角度考虑,在底层通过磨损均衡机制来减少写操作;在应用层次,有研究者提出各种的内存调度算法,将读操作和写操作进行区分等等。本文将主要分析在应用层次,总结现有的PCM数据结构设计方法和思路。
二、PCM数据结构设计
(一)B+树索引
B+树是B树的变体,是一种多路索引树。B+树的特点就是每层结点数目非常多,层数很少,目的就是为了减少交互次数,当查询数据的时候,由于内部结点和叶子结点的键是有序排列的,通过二分查询可以高效率的读取数据。一旦需要新插入一个结点的时候,首先要找到相关叶子结点,如果已满,就需要进行分裂操作。同样删除结点的时候也会带来结点的拆分和合并操作。
在DRAM内存系统中,B+树得到了广泛的应用。由于B+树结点记录是有序的,可以直接使用二分查找,因此查询的性能较好。但是,插入、删除包含了过多的写操作,不适合PCM环境,效率低下。因此需要对B+树结构进行调整,以适应新的内存体系。
1.对叶子结点内部排序
一些研究通过叶子结点乱序存储来是减少排序带来的写操作,提高了插入和删除结点性能,但是增加了查询的读操作。Chen等人提出无序方式有3种:全部结点无序,仅叶子结点无序和部分叶子结点无序(带有位图信息)。1)内部结点无序排列会让查找效率减低,而结点分裂需要对结点重新排序计算,增加了CPU计算开销。2)部分节点无序,文献[3]提出了基于PCM内存的B+树方案,做了部分优化:采用了对叶子结点部分无序,并对叶子结点设置了合并因子,来判断叶子结点的合并。3)仅叶子节点无序,文献提出了NV-tree,适用于PCM/DRAM混合内存。因为只有叶子结点信息需要持久化,所以将B+树的所有叶子结点保存在PCM内存,而将中间结点保存在DRAM内存中的连续地址。为了降低叶子节点的排序开销,叶子节点也是无序排列。
2.溢出结构
由于叶子结点的插入和删除操作,往往对B+树的多个结点产生影响。例如,当需要拆分叶子结点的时候,需要改写3个结点,分别是原始的分裂结点、拆分到的结点、父结点。为了提高效率,很多研究采用溢出结点结构。这种结构通过将一部分叶子节点的合并和拆分操作,保留在溢出结点(稍后再对父结点进行批量处理),如图1所示,这样不影响父结点的结构,减少了写操作的次数。文献[3]叶子结点包含多个溢出结点,这样只有当叶子节点的溢出深度达到树的溢出因子时,其后的结点分裂操作才会导致树的重组,分裂时所有溢出节点的叶子节点独立出来和一组键被一次性插入到父节点中,这样提高了写操作的效率。如果溢出链过长,也会对数据查询(读操作)带来性能下降的影响。
3.数据一致性
wB+-Tree为每个数据项增加了一个位图(bitmap),为每个结点增加了一个位图数组,通过原子更新来保证数据的一致性。FP-Tree在NV-Tree基础上,对数据项也是采用了设置位图的方式保持插入、删除数据的一致性。同时,为了提高查询性能,它还对叶子结点的每个数据项目都保存了一个哈希值,用哈希索引加快查询过程。
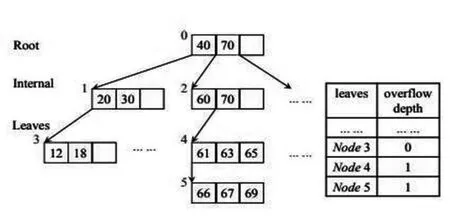
图1 带溢出结点的B+树
由于CPU和PCM之间的缓存以缓存行(cache line)为单位进行读写,而故障原子写单元为8B而非64B的缓存行大小,因此需要设计更细的访问粒度来达到性能提升和减少一致性开销。除了PCM中的B+树外,也有学者研究了其他类型的树状结构,如基数树(radixtree)。
(二)Hash 索引改进
传统哈希索引并不适用于PCM,主要原因可以归纳为以下3个:
1.哈希索引一旦在遇到哈希冲突的时候,通常采用4种方法来处理:链式哈希、线性探测、二选哈希和布谷哈希。无论哪一种,都会带来较多的写操作。
2.PCM的非易失性没有充分使用
由于在DRAM存储上,为了防止断电故障,保持数据的一致性,需要使用日志来保证系统的可恢复。数据在更新前先在日志中保存,然后再写入到磁盘,性能开销很大。
3.哈希扩容问题
哈希表的容量是有限的,当不能容纳新的元素的时候就必须要扩容。扩容的经典操作是新开辟一块空间,然后将原来的哈希元素移动到新的哈希表中,会带来很多的写操作。
自布谷哈希以来,很多研究人员使用两个hash函数,构造出备选位置,来降低哈希冲突。文献首先提出了索引结构在PCM环境中面临的问题,提出了PFHT算法,是布谷哈希的改进。每次插入操作只允许一次替换。另外,将多个哈希元素放到一个地方,提升了效率。使用Stash辅助存储所有插入失败的哈希元素。
文献提出了的path hashing方法,主要是通过分层处理。path hashing在逻辑上构建了一个二叉树结构,叶子结点用来存储原始的映射地址,而中间结点用来保存发生冲突的备选位置。使用两个独立的哈希函数,找到两条备选路径,只要上面有空位置,就可以插入新的结点。同样,删除请求只需要探测叶结点及其备用位置,而不会导致额外的写入。此算法很大程度上减少了在PCM写入的次数,但查询性能还有改进的空间。
综上两段所述,文献的研究要点在于减少写操作,对查找和插入删除的结构上做了优化,但是对于问题2和3的解决方案都还有改进的空间,特别是问题3哈希扩容问题方面的表现不是很理想。
文献提出了一种基于NVM的level hashing,这种方法结合了PFHT和path hashing的优点,使用了基于共享的两层结构。其中,直接访问的是第1层的哈希元素,第2层的哈希单元用于处理哈希冲突。Level hashing的一大特点是支持自动哈希扩容。在调整大小时候,临时变成一个三级结构,如图2所示,将底层的哈希条目重新分布到上面两层,减少了移动和替换结点的写操作。

图2 Level Hasing扩容过程
Level hashing使用无日志技术来保证数据一致性。主要实现方法是数据的原子修改(主要是8字节的操作),增加和slots(插槽)对应的token(令牌),同时制定无日志删除、查找、扩容、更新的规则,修改数据时同步原子写入修改令牌。
文献[1]提出Group Hashing,即所谓的组哈希策略,主要思路是将散列表分成组,通过组内共享以及组内再次哈希的方式,来提升索引的性能,达到较好的效果,说明哈希索引结构的优化还有空间。
(三)PCM数据结构研究展望
目前并没有成熟的PCM索引数据结构的应用,上述所有的索引数据结构的研究都还处于起步初级阶段。随着PCM内存技术的日益成熟,普及的脚步加快,索引数据结构受重视的程度也会逐渐加强,未来的研究方向主要集中在以下几个方面。
1.混合索引结构
目前,针对PCM环境的索引数据结构主要是B+树和hash表两大类。这两种类别适用于范围查询和单点查询。为了同时支持以上两种操作,混合索引的设计也是一个有应用价值的研究领域。
已经有学者提出HiKV混合索引结构,在PCM中应用Hash索引,在DRAM中采用B+索引,但是缺少在相应体系结构中的索引结构的优化。未来,也有可能将红黑树、跳表(skiplist)等其他结构引入,构造混合索引以适应不同的应用场景。
目前,通过对索引在PCM和DRAM中的差异研究导出如何优化混合索引,以及在混合内存体系中如何配置,还没有成熟的方案,有待进一步的研究。
2.并发索引结构
目前的索引结构研究大多是基于单线程进行,没有涉及到并发的数据结构。在多核多进程环境下的索引的并发控制,成了一个新的研究方向。只有对优化目前的单核数据结构的研究也达到一定水平后再深入研究多个线程中的如何优化调度,才能真正提高PCM数据应用的性能。目前,这种高阶研究成果还很稀缺。
猜你喜欢
数学物理学报(2018年1期)2018-03-26 08:16:42
广东技术师范大学学报(2016年5期)2016-08-22 09:07:32
中国市场(2016年45期)2016-05-17 05:15:48
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
上海理工大学学报(社会科学版)(2014年2期)2014-02-28 14:42:19
计算机工程(2014年6期)2014-02-28 01:25:40
河南科技(2014年5期)2014-02-27 14:08:57
电子设计工程(2014年12期)2014-02-27 11:58:23
电子设计工程(2014年12期)2014-02-27 11:58:03
