
话语填充任务在中国英语学习者语用能力测试中的应用研究❋
2020-01-17 08:41:54李清平中南大学
外语与翻译 2019年4期
李清平 中南大学
【提 要】国务院《关于深化考试招生制度改革的实施意见》指出,我国的外语考试应改革考试形式和内容。但综观我国各类外语考试,基本上还是以词汇-语法能力和听说读写译的技能考试为主。本研究考察了过去10多年国际逐渐流行的语用能力测试形式,尤其是话语自我评估(DSAT)、听说话语填充(ODCT)、书面话语填充(WDCT)和选择性话语填充(MDCT)应用于中国英语学习者语用能力测试时的信度、效度和相对难度等问题。测试工具的开发包括情境采样、情境可能性调查、元语用调查、确定MDCT选项及答案等步骤。结果显示,除MDCT外,其它三种工具都具有可接受的信度和较好的效度;学习者在不同测试中的表现呈现出显著差别,但他们的英语水平与语用表现之间没有显著相关。这些结果表明,传统的外语水平测试不能代替语用能力测试,后者需要专门的测试工具,但选用哪一种测试工具要视测试对象、目的和用途而定。基于这些结果,文章讨论了外语语用能力测试工具开发过程中应注意的问题,并为构建中国外语测评体系的战略配套,尤其是测评工具开发和题库建设提供了有益的启示。
1.引言
2014年9月,国务院颁发了《关于深化考试招生制度改革的实施意见》,其核心之一就是改革考试内容和形式。但综观我国现行的外语考试,基本上测试的还是词汇-语法知识和听说读写译等语言技能。不可否认,这种考试在我国的基础教育和高等教育的人才培养中发挥过且仍在发挥巨大的作用。但新时代的人才培养目标定位的变化,尤其是高等教育国际化人才培养的目标要求我们的考试因时而变。2018年发布的“中国英语能力等级量表”就“不仅涵盖了传统的听、说、读、写技能,还从语用能力和翻译能力(包括口译与笔译)角度描述英语能力”(刘建达、彭川2017:6)。但这些新增加的能力目标如何检测是研究者和一线教师十分关心的问题。
实际上,上个世纪90年代以来,语用能力就被认为是外语交际能力中不可或缺的一部分(Bachman 1990;Bachman&Palmer 1996),但到目前为止,测试语用能力的工具还很不成熟。有人主张语用能力的测试应该评估交互中的语用能力(Youn 2015),或实时的语言运用(Roever 2011),但这样的测试工具用于大规模的测量时可行性较低,因此大量的研究者仍然对基于言语行为理论和礼貌原则的话语填充任务(Discourse Completion Test/Task,DCT)感兴趣。尽管有研究者(Hudson,Detmer&Brown 1992,1995)开发出原型的DCT测试工具,但随后的信度和效度研究并没有得出令人满意的结果,尤其是有些工具在某种环境中得到了某种程度的验证,但换了测试对象,结果却不一样。用这些工具测得的语用能力与语言水平之间的关系也不明朗。这表明,现有DCT测试工具在特定环境中真正投入使用之前还需要大量的研究以确定其信度和效度(刘建达2013)。本文以中国英语学习者为对象,检测DCT在语用测试中的相关问题,以期促进我国外语语用教学并为中国外语测试中的语用测试及其题库建设提供有益的启示。
2.研究背景
发展语用学的兴起(Kasper&Schmidt 1996)引发了学界对语用能力测试的关注。最早的原型语用能力测试工具是 Hudson,Detmer&Brown(1992,1995)开发的,他们将同样的24个情境分别制成六种形式的测试卷,分别是1)书面话语填充(Written Discourse Completion Task,WDCT),要求受试写下在指定情境中要说的话;2)选择性话语填充(Multiple-choice Discourse Completion Task,MDCT),要求受试从三个备选项中选出在指定情境下最合适的话语;3)听说话语填充(Listening Oral Discourse Completion Task,ODCT),需要受试说出在指定情境中要说的话;4)话语角色扮演(Discourse Role-play Task,DRPT),要求受试与母语者进行角色扮演,并在其引导下说出指定言语行为;5) 话语自我评价(Discourse Selfassessment Task,DSAT),需要受试对自己在特定情境中的可能表现进行自我评价;6)角色扮演自我评价(Role-play Self-assessment,RPSA),要求受试对自己在角色扮演中的表现进行自我评价。这24个情境包含请求、拒绝和道歉三个言语行为,将权力、距离和强加度三个社交变量构成八种不同的组合,测试英语作为二语的语用能力。虽然这六种原型测试工具及其变体在二语习得研究中经常用作研究工具,但很少用作教育测量工具。随着发展语用学的兴起,人们愈发关注这些工具的信效度问题,并进一步探索如何开发新工具以满足大规模考试的需要。
Yamashita(1996)将Hudson等人的语用测试卷翻译成日语,在母语为英语的日语学习者中进行测试,结果表明除MDCT外,另外五种测试工具都有较高的信度和效度,且受试者的语言水平与WDCT、ODCT、DRPT产出型测试中的成绩显著相关。Yamashita(1996)还发现,学习者与目标文化接触时间的长短明显影响了他们在DRPT和ODCT中的表现。Yoshitake-Strain(1997)和 Enochs&Yoshitake-Strain(1999)用这些工具对日本的英语学习者进行了测试,结果显示MDCT与WDCT的信度和效度都不高,受试者的语言水平与他们的语用能力没有显著相关,接触目标文化的程度影响了语用表现。这些结果似乎表明,同样的语用测试工具在不同的测试对象中会产生不同的信度和效度,关于语言水平和语用能力相关性的结果也不一样,但MDCT都显示出较低的信度和效度。
二十一世纪以来,基于这些工具的信度效度研究进一步深入。Hudson(2001)以25名来自日本的英语学习者为样本进行了研究,结果表明WDCT、ODCT与DRPT都有较高的信度,且受试在WDCT与DRPT中的表现好于在实验室中录制的ODCT的表现。Brown(2001)对这六种工具在英语作为外语与日语作为二语两种环境下的实际应用进行了比较,发现MDCT在两种环境下信度都很低。Ahn(2005)将Hudson等人的试卷(MDCT除外)翻译成韩语,对二语为韩语的大学生进行了测试,结果表明这五种工具的信度都很高。这些研究是在不同环境和测试对象中进行的,似乎表明MDCT都不太理想,而对于其它的测试工具则没有达成一致的结果。
以上的研究都是基于Hudson等人提出的原型工具进行的,但Hudson等人没有详细交待工具开发过程,因此不清楚试卷中的情境和MDCT中的选项是如何获取的,也不清楚这些工具中的情境在多大程度上符合受试者的实际情况。鉴于此,刘建达(2006;2007)经过严格的情境采样、情境可能性筛选、元语用调查、试测和MDCT选项设计等步骤开发了自己的MDCT、WDCT和DSAT,并对中国的英语学习者进行了测试,结果表明这三种工具都有较高的信度和效度,且MDCT的信度指数高达.88,这与以往的研究结果不同,说明语用能力测试工具的开发如果遵循严格的程序,MDCT是可以达到理想的信度和效度的;但学生的语言水平与他们的语用表现没有显著相关。需要注意的是,刘建达的MDCT中的正确选项采用的是本族语者的话语,而干扰项采用的是学习者话语,受试有可能根据本族语者话语的地道性做出正确选择,从而影响了试卷的信度。
综上所述,笔者发现,1)ODCT、DRPT、DSAT 和RPSA四种工具似乎具有良好的信度和效度,但MDCT和WDCT的信度还有待进一步研究。2)外语水平与语用能力的相关性有待进一步确定。3)母语文化有可能影响外语语用表现。现有的研究涉及日语、英语、韩语、汉语等母语背景,但在二语环境下进行的居多,需要有更多的研究考察外语环境下学习者的语用表现。4)除了Hudson(2001),目前还鲜有研究考察受试在不同的测试中是否有不同的表现,而这类研究有利于确定不同测试工具的难度系数,以便确定什么样的工具用于什么样的测试目的。
基于此,本研究聚焦以下问题:不同的语用测试工具在中国外语环境中的信度和效度如何?中国英语学习者在不同语用测试中的表现怎样?他们在不同语用测试中的表现与外语水平是什么关系?
3.研究方法
3.1 测试对象
39名非英语专业大二的学生参加了测试,他们在6月份参加了CET-4考试,同年10月参加此研究。所有受试都在2个小时内完成了全部测试。在完成了DSAT,ODCT,WDCT和MDCT后,大部分人表示不再愿意参加后面的角色扮演,因此本研究没有考察DRPT和RPSA。个人信息问卷结果显示,39名受试均未去过英语国家,平时很少或几乎没有与英语本族语者交流的机会。
3.2 工具开发
本研究中四套语用测试卷采用的情境是一样的,涉及九种常见的言语行为,包括请求、道歉、拒绝、问候、批评、提醒、赞美、建议和安慰。试卷的开发按以下四个步骤进行。
第一步,情境采样。收集现有研究中使用过的言语行为情境(参见何自然、阎庄1986;洪岗 1991;甘文平2001;李悦娥、范宏雅2002;刘建达2006;姜占好2009),根据Hudson等人(1995)对语用测试情境选择的原则(规定交谈双方的性别、规定交谈双方面对面交流、每个场景都与交谈双方的角色有关等),将这些情境进行一定程度的修改,不合适的剔除,统一格式,共获得56个情境。
第二步,情境可能性调查。将第一步收集到的56个情境制成问卷,每个情境后是一个李克特5级量表,1=不可能发生,5=很可能发生(例1),30名与受试同年级的学生据此对每个情境进行判断,每个情境的平均分大于3的得以保留,共获得25个情境,将这25个情境通过回译法(back-translation)确定问卷的中英两个版本(限于篇幅,附录省略)。
例1 昨天上课时,老师有事出去了,同学们开始聊天,有的同学声音很大,班长请大家安静一点。
不可能发生 1 2 3 4 5很可能发生
第三步,元语用调查。每个情境的元语用信息十分丰富,但本研究只考察最能影响言语行为的三个社交语用变量,即地位(Power)、熟悉程度(Distance)和强加度(Imposition)。中英两种问卷分别在30名中国大学生和15名本族语留学生中发放。首先向他们解释每个变量的意义,当他们表示明白无误后要求他们就每个情境中的三个变量进行判断,具体方法如例2所示(参见Liu 2007)。若中国大学生就每个变量达成70%及以上相同意见,且跟本族语者达成70%及以上相同意见,则该情境保留,据此获得21个情境。
例2 你与老师讨论作业。老师语速很快,你没听清楚他讲的话,你请老师再说一遍。
I.你认为双方的熟悉程度如何?
A.陌生 B.熟悉
II.你认为该情境中谁的地位更高?
A.你 B.老师 C.平等
III.你认为该请求的强加度如何?
A.低 B.高
You are discussing your assignment with your teacher.Your teacher speaks very fast.You cannot follow what he is saying,so you want to ask your teacher to say it again.
I.How familiar do you think you are with the teacher?
A.Stranger B.Familiar
II.Who do you think enjoys more power?
A.You B.Teacher C.Equal
III.How impositive do you think the request is?
A.Low B.High
第四步,确定MDCT选项及答案。15名母语为英语的本族语者参与了这一环节。从文献中为每个MDCT情境配备三个备选答案,并请本族语者从中确定最合适的答案,如果就某一个选项的合适度达到70%及以上的相同意见,则该选项确定为标准答案;如果他们觉得备选答案都不适合用作标准答案,则要求他们用英语写下自己认为最合适的答案,经集体商议确定最后标准答案。
至此,四种语用测试卷的开发全部完成,每套试卷的中英两个版本合并为中英对照版。ODCT的情境描述采用汉语标准普通话录制,以防止受试由于自身英语水平的限制对情境的理解出现偏差。ODCT的每个情境后留有20秒供受试口头作答(笔者请了五名不同水平的同年级学生进行试测,所有情境他们都能在15秒内作答)。其他三种测试没有时间限制。测试按照 DSAT、ODCT、WDCT、MDCT 的顺序进行,以减少各测试方法间的交叉影响。DSAT测试受试设想自己在特定情境下所说话语的恰当性,按李克特6级量表选择。ODCT在实验室中进行,受试通过耳麦说出在设定情境下自己将会说的话,电脑自动录音。WDCT要求受试写出在设定情境下要说的话。MDCT要求受试从三段备选话语中选出设定情境下最合适的话语。例(3)列出了一位受试对“情境一”在四种测试中的表现。
例3 You are discussing your assignment with your teacher.Your teacher speaks very fast.You cannot follow what he is saying,so you want to ask your teacher to say it again.
(1) DSAT:I think what I would say in this situation would be
very inappropriate 0----1-----2------3-----4-----5 completely appropriate
(2)ODCT:Pardon?
(3)WDCT:I’m sorry,I just can’t follow you.Please pardon me.
(4)MDCT:A.I think you are right.But if you explain it more clearly,I may understand it better.
B.Sorry,teacher,can you repeat it?
C.Excuse me,may I have your pardon?
3.3 评分
评分标准的制定是语用能力测试中最具争议的问题(刘建达2008),通行的做法是依据本族语者的文化准则来制定(North 2000)。本研究聘请了两名美国教师对ODCT和WDCT评分,规则参照Hudson等人的标准,包括言语行为的正确性、话语表达的正确性、信息量的大小、话语的正式程度、言语策略的直接性及礼貌度。两位评分员详细研读并讨论了评分标准,并进行试评,直到他们觉得完全掌握了评分标准之后再正式评阅全部试卷。每个情境中每位受试的得分为两位评分员所给分数的平均值。MDCT部分,每个正确的选择得5分,错误的得0分。DSAT中受试者的得分为他们自我评估的分数,评估采用李克特6级量表进行,(非常不恰当)0—1—2—3—4—5(完全恰当)。
4.研究结果与讨论
4.1 不同测试工具的信度
由于该研究涉及到大量的主观题评分,因此除了传统的试卷信度外,还必须考察评分员间的评分信度。
4.1.1 评分员间的信度
在语用测试中,信度和效度研究可以通过多层面Rasch模型分析进行(Linacre 2000)。但Rasch模型分析主要用于每套试卷的信度或效度,而在多项选择题型中(如本研究中的MDCT),如果考生靠猜测或练习效应进行选择,则其表现有可能不符合Rasch模型的特征曲线。况且,本研究需要同时对比几种工具的信度和效度,因此采用了传统的定量对比方法。
从表1可以看出,两位评分员对ODCT和WDCT的评分信度分别为.895和.865(Pearson r),这种信度指数在如此开放和主观的测试中是可以接受的。这一结果与刘建达(2007)的结果一致。刘建达通过Rasch模型分析,发现评卷人在WDCT中的评分体现了较好的内部一致性。这说明在语用测试中,利用本族语者的直觉,同时制定严格而又详细的评分标准,是可以对说话人的语用表现进行评判的,即使是在DCT这样开放的试题中也一样。
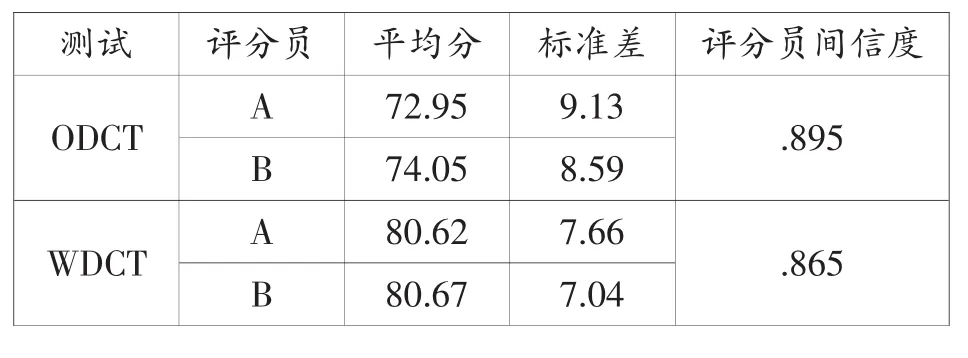
表1 评分员间的评分信度
4.1.2 试卷信度
表2呈现了各试卷的内部一致性信度(α)与折半信度(Guttman Split-Half Coefficient)。折半信度的分半依据是先算出受试在各题中所得分数的平均分,然后根据平均分从高到低将试卷题目分为两部分。结果表明,DSAT 的信度很高(α=.918),折半信度高达.969。ODCT和WDCT的信度分别为.793和.773,折半信度分别达到.869和.883。但MDCT的信度很低,这尽管与国外的一些研究结果相似(Yamashita 1996;Enochs&Yoshitake-Strain 1999;Hudson 2001;Ahn 2005),但与刘建达(2006)的研究结果大不一样。刘建达也是在中国外语环境中进行的研究,其MDCT信度达到.88,如前所述,这种高信度有可能是正确选项的地道性所致。本研究MDCT的低信度有可能是因为测试中的情境不是从受试的真实生活场景中得来,虽然经过了情境可能性调查,但这种可能性只是理论可能性,与受试的生活还是有一定差距。而且MDCT的备选项也不像刘建达那样来自受试的语用表现。由此看来,要想开发出可靠的MDCT试题,必须经过非常严格的开发过程,不仅要选择适合受试的情境,还要严格筛选备选项。由于本研究中的MDCT试卷信度过低,接下来的分析均不考虑MDCT。

表2 四套语用测试卷的信度
4.2 不同测试工具的效度
4.2.1 内容效度
本研究的试题包括了21种生活中常见的情境,涵盖了九种常见的言语行为,符合全面性的要求(Roever 2011),也就是说,这些试题具有代表性,能充分体现所测试的目标内容。并且本研究还按照Hudson等人(1995)的模式选择情境,每一个情境中都包含了地位、熟悉程度、强加度三种社交语用变量,受试需要正确判断每个情境中的社交变量的值,然后调用合适的语用语言资源才能恰当地执行相关的言语行为,因此,受试在这些情境中的表现完全可以看成是他们的语用能力,符合可靠外推(extrapolation)的要求(Roever 2011)。
从表3可以看出,在21个情境中,14个情境中的听者与说者地位平等,16个情境中两者之间较熟悉,15个情境中的言语行为强加度较低。如果只考虑任何单一变量,这些情境中的言语行为策略不需要太多的内部外部修饰,可以较直接,不能全面测试学习者的语用能力。但如果考虑三个语用变量的交互效应,则需要受试者充分调动全部语用语言资源才能完成各个情境中的言语行为。如在情境12中,说者和听者地位平等,双方也很熟悉,但言语行为强加度较高,受试者需要调用相应的礼貌和委婉策略,才能实现成功交际。在情境11中,虽然交谈双方地位平等,言语行为强加度也不高,但双方不熟悉,说话人同样需要调用相应的语用策略来实现语用功能。照此类推,所有的21个情境呈现了丰富的社交变量组合,充分考察了受试的社交语用能力(将形式与情境匹配的能力)和语用语言能力(将形式与功能匹配的能力)(Kasper&Rose 2002),具有较好的内容效度。
4.2.2 标准关联效度
本研究通过相关分析考察了各测试工具的关联程度,以此考察它们的标准关联效度。表4显示,三种测试工具都有显著意义的相关。ODCT与WDCT属于产出型测试,两者在0.01显著性水平上相关系数为.636,具有较高的相关性。在0.05显著性水平上,DSAT与ODCT相关系数为.320,与WDCT的相关系数为.331,尽管属于弱相关,但达到了显著水平。这在一定程度上说明这三种测试方法测试了学生相似的能力,即语用能力。上述研究结果与前人(Ahn 2005;刘建达2006)的研究基本一致。Ahn(2005)的研究中DSAT与WDCT的相关系数为.50,属于弱相关。刘建达(2006)的研究中,DSAT与WDCT和MDCT之间的相关系数分别为.27和.47,都属于弱相关。所有这些研究结果都表明DSAT与其它工具呈弱相关关系。导致这种弱相关的原因有可能是因为DSAT是学习者对自己语用能力的主观评价,与真实表现有一定的差距。未来的研究需要开发出高信度的MDCT试卷,以便考察产出型测试与理解型测试之间、自我评估与其它测试工具之间的相关关系。

表4 三种测试工具的相关性
4.2.3 构念效度
为了考察这些工具的构念效度,首先对DSAT、WDCT和ODCT进行主成份分析,结果显示,这三套试卷的KMO值分别为.600、.517和.574,Bartlett球形度检验显著性分别为.000、.003和.005,解释的总方差分别为76%、73%和75%,可以做主成份因子分析。成份矩阵提取的主成份DSAT 6个、WDCT 8个、ODCT 7个,但每一个情境在这些主成份上的负荷量都不高。具体说来,在DSAT中,有14个情境负荷于同一个 主 成 份 (情 境 3,5,6,7,8,9,12,13,14,15,18 ,19,20,21);在WDCT中有12个情境负荷于同一个主成份(情境 2,6,7,9,11,13,15,16,17,19,20,21);在ODCT中有13个情境负荷于同一个主成份(情境2,4,6,7,8,9,11,14,15,16,17,20,21)(每个情境的详细内容见表3)。由此可以看出,有6个情境(6,7,9,15,20,21)在三个测试中都共同负荷于同一主成份。尽管由于数据分散,正交旋转失败,但绝大部分情境都指向了同一个主成份,尤其是在三套试卷中共同负荷值较高的6个情境,都属于高强加度的情境,需要说话人调用大量的语用语言资源才能完成指定的言语行为。由于没有受试在线加工数据,我们不知道他们在不同的情境中是否调用了不同的语用资源,从而展现出不同的语用表现,未来需要加强这方面的研究,以便确定到底什么样的变量组合最有利于测试语用能力。这给我们的启示是,在基于DCT的语用测试中,不仅要进行仔细的情境采样,这些情境最好来自受试的亲身体验,而不是可能的情境,而且还要认真操控情境中的变量组合,否则有可能没法有效的测出语用能力。
接下来,通过因子分析提取了三套语用测试卷共同的特点,考察语用测试和水平测试是否测试了不同的能力。经过最大方差法旋转后,提取出两个特征值大于1的因子,结果(表5)显示,三种语用测试工具在因子1上负荷值较高,而CET-4听力和CET-4阅读在因子2上负荷值较高。共性方差也表明CET-4听力和CET-4阅读已解释的方差为0.662和0.696,DSAT、ODCT、WDCT 解释的方差分别达到 0.408、0.761和0.827,全部已解释的方差为63.084%。这说明DSAT、ODCT和WDCT三种测试方法测试了同一种能力(语用能力),而CET-4听力和CET-4阅读测试的是另一种能力(英语水平)。这一结果与前人的结果基本一致。刘建达(2006)对学生在WDCT、DSAT、MDCT三种语用测试中的成绩和他们在TOEFL考试中的成绩进行因子分析,得到了类似的结果,说明DSAT、ODCT和WDCT可以用作语用能力的测试工具。但这一结果有可能是测试方法产生的效应,需要谨慎对待,因为CET-4的两种测试格式相同,而DCT的三套试卷情境一样,这种测试方法的共性形成了两个不同的因子。未来需要进一步研究语用测试和水平测试的不同测试形式是否确实测试了不同的构念,以此确定语用测试的构念效度。

表5 各测试工具的因子分析结果

表6 受试在不同测试中的表现
4.3 不同语用测试中受试的表现
虽然不同的测试采用的是同样的情境,但由于呈现模态不一样,学生的表现有可能不一样。描述性统计(表6)显示,受试在DSAT的平均分最低,在WDCT的平均分最高,在ODCT的平均分居中。这可能是由于在WDCT测试中,没有时间限制,受试者可以充分思考。而ODCT测试是在实验室中进行的,有严格的时间限制,可能影响了受试的表现。这一结果与Hudson(2001)的实验结果相似,即受试在WDCT中的成绩要高于ODCT。但出人意料的是受试自我评估的分数最低,标准差也最大,这也许是因为这些学生没有接受语用训练,学习过程中语用信息也不足,即使有语用信息,也没有引起老师和学生的注意,因而接触到这样的测试感觉没有把握。
方差分析(表7)显示,三种测试中受试的表现有显著差异。这一结果似乎表明,虽然不同试卷信度和效度都不错,但并不是所有的测试工具都是最佳的选择,最能测试语用能力的工具是WDCT,在外语环境中尤其如此。受试在ODCT中的表现比在WDCT中的表现差,这是因为ODCT的时间限制,还是实验室录音导致的心理压力,抑或是在外语环境中学生的口语输出本来就比笔头输出表现差,未来需要大量的实证研究才能回答这类问题。同时,中国英语能力等级量表以运用为导向,采用“能做”描述,关注语言在交流中的作用。但这些“能做”描述语主要是围绕以言行事的内容拟定,本研究结果表明,同样的“能做”内容,执行模态不一样,反映出来的能力是不一样的。

表7 受试语用表现的方差分析结果
4.4 受试英语水平与语用能力的相关性
如前所述,在本研究中,英语水平指CET-4测试中的客观题成绩,语用能力指受试在不同语用测试中的表现。相关分析显示,受试CET-4听力、CET-4阅读和CET-4总成绩与DSAT和WDCT成绩间没有显著意义的相关。虽然CET-4总成绩和ODCT成绩有显著意义相关(p<0.05),但相关系数只有.268,这也许说明在外语环境中,受试在ODCT中的表现更多地依赖外语水平。以上这些结果与Enochs&Yashitake-Strain(1999)和刘建达(2006)的研究结果相似,但Yamashita(1996)发现受试的语言水平与其在ODCT、WDCT和DRPT中的表现显著相关,并且学习者与目标文化接触的时间越长,在ODCT和DRPT中表现越好。产生这种不同结果的主要原因有可能是本研究、刘建达(2006)和 Enochs&Yashitake-Strain(1999)中的受试都没有直接接触英语国家文化的经历(后者的部分受试有不同程度地接触过目标文化),但同时也似乎说明,在外语环境中,语用能力与语言能力确实是两种不同的能力(Bardovi-Harlig&Dörnyei 1998),尽管口头的语用表现(如ODCT、DRPT)有可能更多地受语言水平的影响,我们不能简单地用语言能力代替语用能力,也不能用语言能力测试代替语用能力测试。随着外语教学越来越重视语用能力和跨文化交际能力的培养,外语测试也应该与时俱进,开发出合适的工具以检测学习者这些方面的能力。
5.结语
本研究用定量的方法在中国英语学习者中考察了 DSAT、ODCT、WDCT、MDCT 四种语用能力测试工具的信度、效度及其它相关问题。结果表明,DSAT、ODCT和WDCT都具有可以接受的信度和效度,可以用于语用能力的测试,但MDCT的信度很低。实际上,在所考察的四种测试工具中,MDCT是最省时省力和可行的一种方法,而且最有可能实现测试的全面性,在大型考试中尤其如此,但这种测试工具的开发过程非常复杂,未来需要更多的研究考察如何开发出高信度的MDCT试卷。第二,虽然DSAT、ODCT和WDCT中并不是所有的情境都能较好地负荷于某一个主成分,但确实测试了语用能力;三者之间相关性较弱,表明在高风险考试中最好不要使用DSAT,因为它评价的毕竟不是语用表现,而是受试者对自己语用表现的一种可能性评估。第三,受试在不同的测试中的表现呈现出显著差别,表明并不是任何测试工具都能最有效地测出学生的语用能力。学生在WDCT中的表现最好,但WDCT需要非常详细的评分规则,且评分员需要非常严格的培训,这增加了在大规模考试中的执行难度。第四,受试的语言水平和语用能力没有相关性,这说明语用能力和语言能力是两种不同的能力,需要不同的工具去测量,但语言水平在口头产出性语用测试中有可能发挥更大的作用。
本研究中MDCT选项不是来源于受试者的真实语用表现,这可能是MDCT信度低的原因之一。其次,Brown(2008)发现增加试题数量能够有效增加试卷的信度,本研究只包括了21种情境,如果将试题数增至30或40个,有可能会有效提高ODCT、WDCT、MDCT的信度。最后,本研究是基于权力、距离和强加度设计的,指向的是个体的认知和言语行为理论,有可能无法解释交互中的语用能力(Youn 2015)。但这并不能否认DCT作为语用测试工具的实用性,因为它测试了语用能力中很重要的一个方面:语用知识。另一方面,英语用作国际通用语,使用本族语者的规范作为语用能力的评判标准也会遭到质疑,因为在跨文化交流语境中,交流双方有可能不涉及本族语者,他们会在协商中建构自认为最合适的语用规范。鉴于此,未来的研究不仅需要考察其它语用测试工具和测试形式(如基于网络的语用测试(Roever 2006)和基于话语分析的方法(Walters 2004))在外语环境中的信度和效度,而且需要拓展理论基础,尤其需要重新审视跨文化交流中的语用能力,以真正实现语用能力测试的可靠性和全面性,并构建更加科学的外语能力测评体系。
最后需要说明的是,构建中国外语测评体系,其战略配套不仅需要建设科学的测评工具,还需要建设国家外语题库(吕生禄2015)。从语用能力测试来说,题库建设首先需要解决的是符合中国国情的情境库,描述典型语言特征、语言活动和语言策略(朱正才2015),并基于这些情景开发相应的试题库。从中国的学情来说,中国学生最熟悉的题型是多项选择题,而且这种题型最适合大规模考试,但开发这样的试题面临的挑战也最大。
猜你喜欢
现代临床医学(2023年4期)2023-09-26 09:41:58
世界科学技术-中医药现代化(2021年7期)2021-11-04 08:12:00
中国非营利评论(2019年1期)2019-06-18 10:51:38
网络安全和信息化(2018年4期)2018-11-09 12:01:54
管理现代化(2016年6期)2016-01-23 02:10:58
上海体育学院学报(2015年6期)2015-12-25 02:04:38
心理学探新(2015年4期)2015-12-10 12:54:02
外语教学理论与实践(2015年1期)2015-06-11 02:51:00
中国康复理论与实践(2015年7期)2015-05-09 08:31:45
单片机与嵌入式系统应用(2015年1期)2015-03-26 12:41:40
