
大数据驱动下的刑事审判专家系统建模分析
2020-01-13 08:18司卫云戴非凡倪进平杨桂松李常青
智能计算机与应用 2020年1期
司卫云, 宋 燕, 戴非凡, 倪进平, 杨桂松, 李常青
(1 上海理工大学 光电信息与计算机工程学院, 上海 200093; 2 上海最闻信息科技有限公司, 上海 201210)
0 引 言
机器学习是AI的一个重要分支,旨在使计算机在完全没有或有限的人类干预下,设计一系列“运算法则”,通过经验学习自动做出最优选择[1]。近年来,大数据和云计算等现代科技高速发展,为机器学习算法提供了丰富的训练样本[2],人工智能技术呈现出加速发展的态势,已经在人类生产、生活及社会管理的众多领域存在并发挥作用[3]。
司法领域,卷宗资料数量众多、信息繁杂,面对庞大复杂的证据链,在短时间内完成人工数据筛选和分析十分困难。并且司法工作专业性较强,审判尺度难以拿捏,这将直接关系到司法工作的后续顺利开展。为了解决上述问题,国内外各大法律机构拟将人工智能引入司法领域,构建基于大数据的智能专家审判系统以代替常规的基于规则的专家审判系统,力争在辅助法官办案、服务律师和社会公众等方面有所突破[4]。此外,运用计算机对海量多源的司法数据进行高速处理,并结合国家发展战略、政策法规和社会大众生活情况,对相关案件变化动态及发展趋势进行深度关联分析,能为司法部门严谨治法提供合理评估[5]。
尽管人工智能的作用显而易见,然后在司法领域机器学习尚处于起步阶段,主要存在以下问题:从数据层面上看,目前的法律数据存在不充分、数据量大、不客观且结构化不足的缺点;从算法层面上看,算法单一、隐秘且低效,缺乏系统性的智能审判专家模型;从人才层面上看,缺乏法律界和人工智能等多学科交叉性的复合型人才[6]。因此,如何高效合理地利用人工智能算法优化工作流程,建立智能判案模型,辅助法官提升工作效率,加快结案时间成为了亟待解决的问题。
综上所述,本文基于贵州高级人民法院提供的2016年1月至2017年5月“故意伤害罪”卷宗,设计了一种融合多种机器学习算法的故意伤害罪案件智能判案模型。基于建立的专家模型,对故意伤害罪案件判罚刑期进行有效预测,既提高办案效率,又能减少同案裁量的差异性,以实现执法的公证性。
1 模糊C均值聚类
模糊C均值算法通过把m个样本分成c个类别,求出每个类的聚类中心,并最小化目标函数实现聚类。其目标函数的表达式为:
(1)
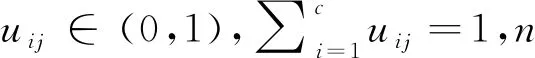
考虑到上述约束条件,由拉格朗日乘数法可构造新的目标函数如下[8]:
(2)
(3)
(4)
FCM通过不断迭代来更新式(3)、(4),研究得到该过程的设计表述如下:
(1)确定聚类个数c,隶属度因子n,随机初始化的隶属度矩阵U,最大迭代次数I=100;
(2)通过式(3)求解新的隶属度矩阵;
(3)通过式(4)求解新的聚类中心;
(4)直到满足最大迭代次数,算法停止,否则就转向式(2)。根据最后一次迭代的隶属度矩阵,若uij=max{uij},则xj属于第i类。
2 基于PSO的DNN故意伤害罪分类模型
DNN能提取更复杂和抽象的高维特征,并在大量的数据中获得输入空间的有效表征。相比手动提取特征或专家设计规则的方法,DNN具有高效和高精度的优势。但确定DNN的网络结构参数是本文构建高精度DNN分类器的困难之一。针对以上问题,本文设计了基于PSO的DNN故意伤害罪分类模型,通过PSO优化算法确定DNN网络结构参数,并在优化过程中实现DNN的训练,以便在保证模型精度的同时,更科学地确定网络结构。
2.1 粒子群优化算法研究
粒子群优化( Particle Swarm Optimization,PSO)是一种基于迭代的进化计算算法[9]。算法中,首先要随机初始化种群粒子,此时的粒子信息可以用位置Xi和速度Vi来表示。每经过一次进化,粒子便通过跟踪粒子的个体极值(pbest)和种群的全局极值(gbest)来更新粒子的速度和位置[10]。pbest和gbest是根据适应度函数找到的最优解。找出这2个最优解后,粒子根据以下公式来更新自己的速度和位置,即:
vij(t+1)=w*vij(t)+c1r1*[pbestij(t)-xij(t)]+c2r2*[gbestj(t)-xij(t)],
(5)
xij(t+1)=xij(t)+vij(t),
(6)
其中,w为惯性权重;vij(t)是粒子i在第t次迭代中第j维的速度;xij(t)是粒子i在当前时刻的位置;r1,r2是(0,1)之间的随机数,用来模拟自然界中的一些微小扰动;c1,c2是学习因子,分别表示粒子对自身记忆的依赖程度和其他粒子对其施加的影响[11]。1999年,SHI等人[12]提出了惯性权值线性调整策略,也称标准PSO。w的线性递减迭代公式如下:

(7)
其中,tmax是迭代的最大次数;t是当前迭代次数;wmax为最大权重,建议取值0.9;wmin为最小权重,建议取值0.4。当w较大时,全局搜寻能力较强;当w较小时,局部搜寻能力较强。因此,针对不同的搜寻问题,依赖w的动态变化,可以相应调整全局和局部搜寻能力,使得PSO算法的性能有了极大的提升,并成功应用于很多实际优化问题。
2.2 利用PSO优化DNN模型算法步骤
本文提出基于PSO的DNN故意伤害罪分类模型,即通过PSO优化算法确定神经网络结构参数。算法的整体设计流程详述如下。
算法1 PSO优化算法
输入:训练集Z={(x1,y1),(x2,y2),…,(xz,yz)}
输出:最优神经网络结构参数
Step1设置需要优化的变量,如神经网络层数、每层神经元个数、激活函数类型;
Step2设置PSO算法参数:学习因子、最大进化次数、惯性权值等;
Step3初始化粒子群,确定粒子群规模,确保每个粒子的位置向量和速度向量的维度;
Step4基于六折交叉验证法将训练集划分为DNN训练过程中的训练集和测试集,将每个测试集预测精度的平均值作为本次粒子规模下DNN分类模型的预测精度;
Step5计算各粒子的适应度,使用Step 4中预测精度的倒数作为PSO的适应值用作粒子空间位置优劣的度量,适应值越小,表明粒子位置越好;
Step6寻找pbest与gbest;
Step7根据速度更新公式(5)和位置更新公式(6)分别更新粒子的速度和位置,得到新的随机解;
Step8当迭代次数大于最大迭代次数时,算法停止,得到最优解。否则,返回Step 4继续搜寻最优解;
Step9将优化得到的最优神经元层数、每层神经元个数及激活函数这些超参数作为神经网络的结构参数,然后根据实际输出值与期望输出的误差进行反向传播训练神经网络,不断调整网络权值和阈值,直到满足迭代条件。
为证明本文提出的基于PSO算法优化DNN模型参数得到的分类器的确在性能上优于普通DNN分类器,本文将在4.3节中,对有无PSO优化的DNN模型分类结果进行比较。
3 基于ET的故意伤害罪刑期预测算法
极限随机树(Extra-Trees,ET)也称极端树[13],与标准的基于树的方法相比,其强大的随机性使得该方法在减少切分点方差的力度上更强,同时,在精度和泛化性能上也遥遥领先于其他集成方法。在后续的4.3节中,分别运用随机森林、前向逐步线性回归和ET三种算法对刑期进行预测及对比。在极限随机树的构建过程中,主要需确定3个参数。首先,确定最终极限随机树包含的决策树数目N,即这N棵回归树的预测结果的普通算数平均数作为回归模型最终的预测结果;其次,在每棵决策树的每个节点随机选择当前节点属性集中的属性个数k;最后,分裂一个节点所需的最小样本大小nmin。以贵州法院故意伤害罪案件为训练样本,对该样本及其要素集分别定义为:
Q={(x1,y1),(x2,y2),…,(xm,ym)},P={p1,p2,…,pz}
其中,xi(i=1,2,…,m)表示第i个案件对应各要素(属性)的取值,yi表示案件的真实判罚刑期。
基于ET的故意伤害罪量刑预测算法详见如下。
算法2Build_Extra_Trees_ensemble(Q)
输入:训练样本Q={(x1,y1),(x2,y2),…,(xm,ym)}
输出:极限随机树T={t1,t2,…,tN}
Step1fori=1 toNdo
Step2生成一棵极限随机树ti=Build_an_Extra_Tree(Q);
Step3返回极限随机树T。
算法3Build_an_Extra_Tree(Q)
输入:训练样本Q={(x1,y1),(x2,y2),…,(xm,ym)}
输出:一棵极限随机树t
Step1ifStop_split(Q)=True
Step2返回一个叶节点;
Step3else
Step4从当前节点属性集中随机选择k个属性{p1,p2,…,pk};
Step5得到k个切分点(s1,s2,…,sk),其中si=Choose_a_random_split(Q,pi);
Step6依据Score(s*,Q)=maxi=1,…,kScore(si,Q),选择最优切分点s*;
Step7依据切分变量p*和切分点s*,将训练样本分为2个子集Ql和Qr;
Step8利用样本子集Ql和Qr分别构建左子树和右子树:tl和tr,即:
tl=Build_an_Extra_Tree(Ql)
tr=Build_an_Extra_Tree(Qr);
Step9返回一棵极限随机树t。
算法4Stop_split(Q)
输入:训练样本Q={(x1,y1),(x2,y2),…,(xm,ym)}
输出:布尔值(True/False)
Step1if |Q|nmin
Step2返回True;
Step3else if
Step4Q中的所有样本在所有属性上取值相同;
Step5返回True;
Step6else if
Step7Q中所有样本的输出结果相同;
Step8返回True;
Step9else
Step10返回False。
算法5Choose_a_random_split(Q,P)
输入:训练样本Q={(x1,y1),(x2,y2),…,(xm,ym)},属性p
输出:切分点
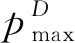
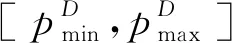
Step3返回切分点[ppc]。
4 实验结果与分析
本文数据由贵州法院整理并提供,故意伤害罪案件时间跨度为2016年1月~2017年5月,刑期跨度为0~240个月,案件总数量为5 000多件。
4.1 模糊C均值聚类结果与分析
由于案件数量较多,刑期横跨0~240个月且分布不均匀。因此,本文采用FCM聚类算法基于案件刑期进行聚类分析。为确定最优类别数,本文分别进行了4类、5类、6类的聚类实验,通过观测聚类有效性评价指标得到结果为5的聚类效果最佳。每类偏差分别为:0.09,0.22,0.7,0.88,0.72个月。
4.2 分类器模型评价与分析
由于贵州法院提供的故意伤害罪原始数据并不包括案件的类别划分,因此本文将4.1节FCM得到的聚类结果作为构建分类器模型的数据集真实类别标签。
故意伤害罪数据集含有不重复要素共75个,若直接将这些数据用于后续模型的建立,将造成巨大的时间开销和计算复杂度。为了解决这一问题,本文使用主成分分析模型(Principal Component Analysis,PCA)[14],通过提取所有故意伤害罪案件要素的主要成分,从而在保证精度的同时,降低特征维度并提高模型构建效率。
在PSO优化过程中涉及到DNN模型的训练,即在每一时刻都需要获得当前粒子所处位置训练得到的DNN分类器的分类质量,也就是准确度,这是通过对训练模型的评估来完成的。为了体现分类器的泛化性能,本文利用K折交叉验证技术(本文取K=6),将训练集划分为K组子样本,一组用于训练过程的验证,其余子样本用于计算梯度更新权重实现模型训练。每一次更新都会获得K个结果,然后对获得的测试精度求取平均作为本次模型精度。
本文利用PSO算法优化DNN网络模型参数的具体搜索空间与PSO求解器的超参数设置见表1。
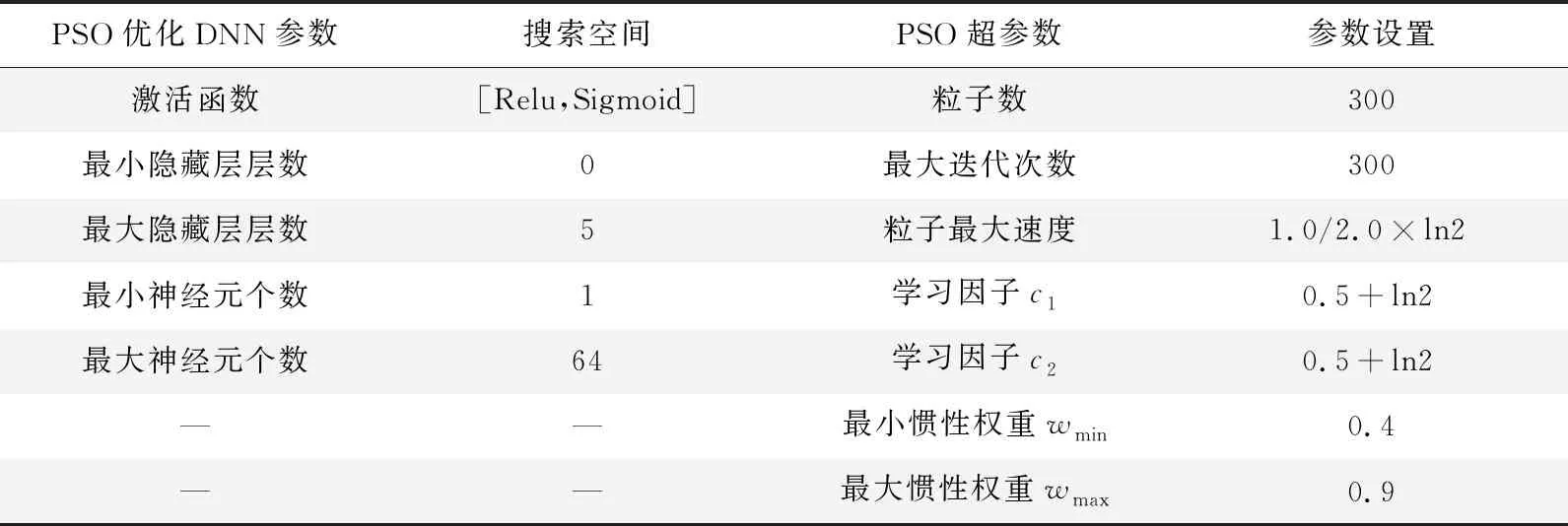
表1 基于PSO的DNN故意伤害罪分类模型参数设置
为表明本文提出的运用PSO算法求解DNN网络模型参数的可靠性,本文做了对比实验,得到的结果见表2。
本文将PSO优化后得到的最优网络参数作为本文拟构建的DNN分类器结构,通过将600次迭代后得到的权重作为DNN分类模型的初始权重,在此基础上继续对分类器做训练,经过1 900次迭代后得到的基于故意伤害罪数据的模型分类精度为81.59%。以上实验充分证明基于PSO算法优化得到的DNN故意伤害罪分类模型不仅具有较科学的网络设计依据,同时模型精度也有所提升。
4.3 预测模型评价与分析
在预测模型训练前,将依据4.2节中分类模型得到的各类别标签将数据集划分为5组。本文针对5组数据集,分别构建预测模型。研究将每组子样本集随机划分为75%训练集和25%测试集。

在该实验阶段,本文运用随机森林、前向逐步线性回归和ET三种算法进行刑期预测,并通过计算平均绝对误差作为每组案件的平均偏差来评价模型优劣,具体表达式为:
(8)

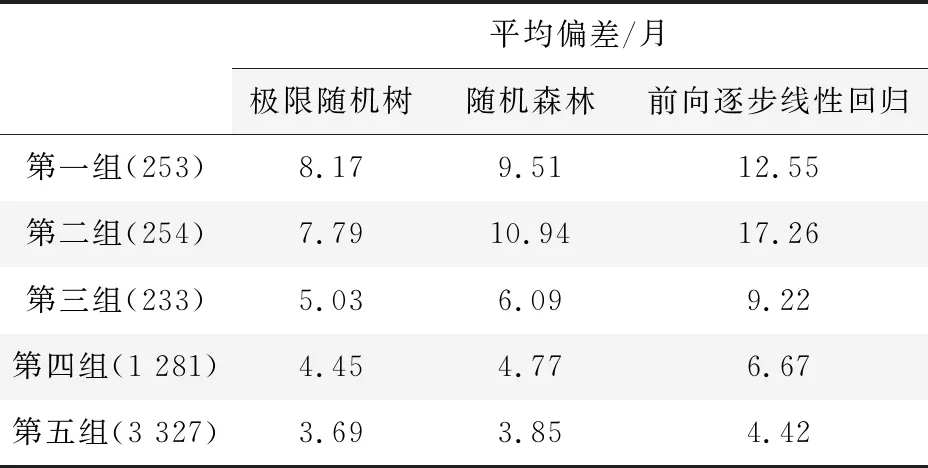
表3 回归结果对比表
5 结束语
本文提出了一种融合FCM算法、基于PSO优化的DNN分类算法、极限随机树等多种机器学习算法的智能专家审判系统。其中,基于PSO优化的DNN分类模型较DNN模型本身有更高的分类精度;同时,极限随机树也比常用的回归方法有更精确的预测结果和更好的泛化性能。通过贵州法院故意伤害罪数据的实验验证表明,该专家审判系统可为司法工作提供更科学的指导,在保证审判公正性的同时,极大地减少了判案时间和工作量。本文旨在挖掘犯罪要素与刑期的隐含关系,为司法领域的研究和应用提供了一种全新的思路。在接下来的工作中,通过改进审判系统中的分类算法,以此获得更高的分类精度,进而提高预测模型的性能,使得预测更为精确。此外,也可尝试对其他类型的法律案件数据进行挖掘分析,在进一步的模型优化后实现审判系统的普适性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
南京理工大学学报(2022年1期)2022-03-17
昆明医科大学学报(2022年1期)2022-02-28
计算机应用与软件(2021年7期)2021-07-16
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
计算机系统应用(2021年2期)2021-02-23
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
分析化学(2018年12期)2018-01-22
