
基于Doc2Vec和深度神经网络的战场态势智能推送研究
2020-01-13 08:18黄志良王适之
智能计算机与应用 2020年1期
申 远, 黄志良, 胡 彪, 王适之
(空军预警学院, 武汉 430019)
0 引 言
随着战场信息搜集手段、处理分析方法的快速发展,使得作战用户能够获得大量的不同类型、不同粒度、不同时空的战场态势资源,但是也会使得指挥员需要耗费很大的时间精力才能从海量的态势中发掘有效信息资源,会出现“态势泛滥”和“态势缺乏”的矛盾,即一方面战场态势呈指数级增长,另一方面作战用户可以利用到的合适态势资源却很少[1]。目前解决该矛盾问题最直接有效的方法就是智能推送,态势智能推送是以推荐算法为核心,利用知识发现、数据挖掘、机器学习、人工智能等多种方法为用户提供合适的态势资源,态势智能推送能够根据用户个性化需求,主动为用户提供合适的态势,并且当用户需求变化时,态势智能推送也能自适应变化,及时准确地为用户提供个性化、智能化、动态化的态势资源。
智能推送的核心是推荐算法,常见的推荐算法有协同过滤推荐算法[2]、基于内容的推荐算法[3]和组合推荐算法[4]。目前在军用领域,推荐算法理论研究也有一定的成果。胡旭等人[5]针对协同过滤推荐算法的数据稀疏性、扩展性差问题,提出了初始聚类中心优化的K-均值项目聚类推荐算法;余苗等人[6]利用层次向量空间构建用户兴趣空间,根据情报用户少量的定制信息和朴素贝叶斯分类算法建立用户兴趣模型,提出了一种基于朴素贝叶斯分类算法的雷达情报按需分发技术;傅畅等人[7]设计并实现了一个包括采集、处理、存储与检索的Web军事情报挖掘模型,提出了一种面向军事情报应用的文本聚类方法;袁仁进[8]围绕军事新闻推荐模型构建与更新、融合地理情境的军事新闻推荐模型构建等方面进行了研究,提出了一种基于向量空间模型和Bisecting K-means聚类的军事新闻推荐方法,针对顾及时间上下文的用户兴趣模型更新问题,构造了一种基于时间的遗忘函数,最后针对地理推荐问题,提出了基于地理上下文的军事新闻推荐算法,并构建了军事新闻个性化推荐原型系统。
上述研究主要是利用用户和态势两者之间的历史交互关系进行学习建模,但该方法存在的问题是用以实现算法模型训练的用户历史行为记录数据是比较稀疏的,并且很难解释用户与这类态势产生交互行为(如定制、浏览、评价等)的原因,比如用户定制这类态势而不定制另外一类态势,很难用用户—态势需求度矩阵来解释。如果能够对用户产生交互行为的相对应态势内容进行分析,那么必将使得用户建模更为准确,并具有很强的解释性,能够描述用户历史行为记录背后隐藏着抽象的用户—态势需求关系。因此本文在神经网络推荐算法的基础上,利用自然语言学习中的Doc2Vec算法来提取态势内容特征信息,并训练成态势内容特征向量,再与用户—态势需求度矩阵中的用户—态势交互行为向量进行融合,这就使得算法模型能够学习到态势更多的特征信息,在一定程度上缓解数据稀疏性问题,从而提升推荐效果。
1 基于Doc2Vec的词嵌入模型
在对态势进行建模时,一般采用向量空间模型来表示。以预警情报为例,预警情报则可以表示为n维的特征向量{(t1,ω1),(t2,ω2),...(ti,ωi),(tn,ωn)},ti、ωi分别表示这些特征的关键词和相应的权重。这种表示方法的核心是对关键词进行提取,如文献[9]将预警情报特征提取为位置、高度、航向、速度、属性、机型等特征,这样一来该特征选取方法明显带有主观性,无法将情报更多的特征信息挖掘出来,会造成情报特征信息的流失,使得用户需求建模就会变得不准确。
在实际运用过程中,战场态势种类是多种多样的,如视频类、音频类、图像类、文本类等。其中,文本类态势特征明显,特征提取相对容易,而诸如视频类、音频类、图像类这些态势特征提取较为困难,因此需要对这些非结构化数据进行结构化处理,形成文本类态势。在得到同类型的态势文本数据后,可以利用相应的方法对态势内容进行表示。而文本内容一般采用词袋模型将文本转化成低维空间的稠密向量,这样的表示方法会使得文本所有重要的特征被提取出来,而不是仅仅取几个主要的文本特征[10]。以“敌方/导弹/距离/我方/20km”和“敌方/飞机/在/我方/东北/方向”为例,基于以上文本内容则可建立词典为:{“敌方”:1,“导弹”:2,“飞机”:3,“距离”:4,“在”:5,“我方”:6,“20km”:7,“东北”:8,“方向”:9}。假设每一个词都有唯一的索引,根据各词的出现顺序及频率,则上述文本用词袋模型中9维的词向量分别表示成[1,1,0,1,0,1,1,0,0]、[1,0,1,0,1,1,0,1,1]。这种表示方式好处在于将文本内容的所有关键词都提取出来,态势信息主要信息被提取出来。缺点在于该方法忽略了各词语的上下文顺序,且当存在大量且特征繁多的战场态势时,态势特征的表示就会变得非常稀疏,即用词袋模型表征所有的态势特征时,对于单个态势而言,所拥有的特征相对有限,则词袋模型表示的大部分特征对单个态势是没有意义的。因此用向量空间模型来表示态势将具有很大的局限性。
基于Doc2Vec的词嵌入模型是Le和Mikolov提出的一种深度文本学习算法。Doc2Vec算法是从大型原始数据中以完全无监督的方式进行训练,而无需任何针对于特定任务的标记数据[11]。该方法的优点在于应用场景广阔,可利用神经网络将任何长度的文本生成词向量嵌入到算法模型。Doc2Vec方法的基本思想是通过神经网络学习训练,将文本中每一个词表示成低维稠密向量形式,最终的目标是生成可表示的词向量。根据文本领域的不同,该向量的维度会有所不同,通常的做法是取值50或100,针对特定领域,向量维数固定的好处在于不会产生高维向量造成“维数灾难”问题。其中,向量的每一个维度包含着文本的某一种潜在特征,每个维度的取值范围为0~1的实数。对于一个文本而言,在经过预处理后,文本主要内容特征很容易人工提取,关键问题战场态势是海量的,不可能对每个文本都采用这样的方式,因此要根据文本内容的上下文顺序,利用Doc2Vec训练模型训练语料库来预测下一个词语,根据预测结果可以为每一个文本生成词向量,然后, Doc2Vec方法具有2种模型。一种是分布式记忆模型(Distributed Memory,DM),另外一种是分布式词袋模型(Distributed Bag of Words, DBOW)。2种方法的训练方式相同,都采用神经网络为基础进行训练。不同之处在于前者是设定一定阈值后,利用当前词语去预测阈值范围内的词语,从而形成词向量,而后者是根据词语之间的上下文关系来预测下一个词语,从而形成词向量。对于态势文本而言,文本中各类词语往往具有很大的关联性,采用分布式词袋模型来对文本建模更为准确,分布式词袋模型结构如图1所示。


图1 分布式词袋模型结构
2 深度神经网络推荐算法
深度神经网络算法因其鲁棒性好、自适应能力强、处理非线性关系能力优异、并行计算速度快等优点而广泛应用于图像处理、模式识别、经济预测、业务决策等领域。文献[13]提出将深度学习方法—多层感知机应用于协同过滤推荐算法,该深度神经网络推荐算法(Deep Neural Network,DNN)通过建立多层前馈神经网络模型来学习用户—态势交互关系,使得算法模型更具备非线性建模能力。
深度神经网络推荐算法是利用需求度的已知项来预测需求度未知项。深度神经网络推荐算法通过建立利用用户—态势交互函数f∈RX×Y来表示用户历史反馈行为数据,R为用户—态势需求度矩阵,X和Y分别表示用户和态势的数目,定义如下:
(1)

(2)
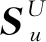
(3)
和矩阵分解推荐算法一样,在得到预测需求度后,可建立目标函数进行参数优化来找到最合适的参数P、Q和OT。
综上所述,研发得到深度神经网络推荐算法的流程步骤分述如下:
Step1输入用户—态势需求度矩阵;
Step2对P、Q和OT等模型参数进行初始化;
Step3通过相关处理,将用户和态势特征向量输入到深度神经网络来预测需求度;
Step4利用随机梯度下降法对模型进行训练,直到模型收敛;

Step6对各态势的预测需求度进行排序,将排序高的态势推送给用户。
3 基于Doc2Vec和深度神经网络的推荐算法
研究中利用Doc2Vec方法将态势的文本信息融入到深度神经网络模型后,文本中的内容信息被建模成词向量,与深度神经网络中的用户的潜在特征向量和态势潜在特征向量进行拼接融合,通过在嵌入层的特征叠加,则算法模型可以学习用户—态势建立关联关系隐含着的抽象特征。基于Doc2Vec和深度神经网络推荐算法结构如图2所示。
该模型主要分为输入层、嵌入层、隐藏层和输出层。其中,输入层是输入已经分布式处理后的用户特征向量、态势特征向量和态势内容特征向量;嵌入层用于将用户序列、态势序列以及态势内容序列转换成表征各自特征的低维稀疏向量,对于态势内容特征向量,文本中每一个词语在嵌入层表示为多维向量Di={d1,d2,...,di,...,dn},这样的表示方法使得文本中更多的特征被提取出来;在隐藏层,主要是对用户特征向量、态势特征向量以及态势内容特征向量进行连接得到一个用户—态势—态势内容特征向量,用于深度神经网络的多层感知机的输入,其中神经网络的结构采用是倒塔式结构,即下一层的神经元的数目为上一层的一半,此时可以利用多层感知机对用户—态势—态势内容特征向量进行特征学习并作为输出层的输入;输出层主要是根据学习到的用户—态势—态势内容特征,可对用户—态势—态势内容特征向量进行需求度预测,根据预测值与实际值的误差情况进行自适应调整,如果输出结果与实际结果相差太大,则不断调整各个参数,直到预测值与实际值的误差值小到一定程度后,即神经网络训练达到最优值,这时就不再调整参数,每次这样的深度神经网络学习成功的结果都会被神经网络中的神经元记忆储存,当作战用户提出态势需求时,深度神经网络都可以根据学习的结果向该用户主动推送合适的态势资源。
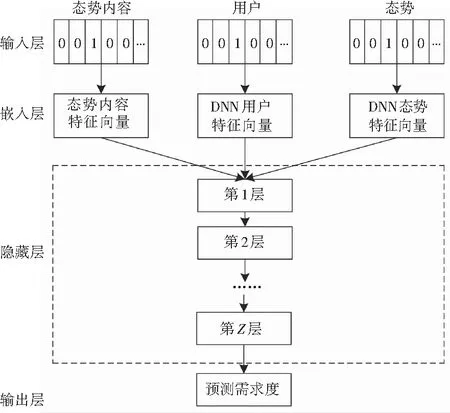
图2 基于Doc2Vec和深度神经网络推荐算法模型
Fig. 2 Recommendation algorithm model based on Doc2Vec and Deep Neural Network

(4)
因为在深度神经网络算法中,态势内容向量也是在进行预测,因此也会存在预测上的误差(预测值与真实值),为防止训练过拟合,添加权重正则化项λD‖G‖2,则此时基于态势内容向量预测的目标函数为:
(5)
对于深度神经网络部分,定义f+表示用户和态势有交互行为,f-表示用户和态势无交互行为,将输出层输出值范围限定为[0,1],输出层激活函数保持不变,则定义似然函数为:
(6)
对式(6)取负对数,f(λDNN)表示深度神经网络的正则化项,用于防止模型过拟合,则此时深度神经网络算法需要进行优化的目标函数为:
(7)
根据式(5)~式(7)可知基于Doc2Vec和深度神经网络的推荐算法的目标函数为:
FDNN+Doc2Vec=FD+FDNN=
(8)
在得到目标函数后,利用随机梯度下降法[14]进行学习训练,根据训练结果,将一组预测需求度高的相应态势推送给用户。
综上所述,则可以得到基于Doc2Vec和深度神经网络的推荐算法的算法步骤详述如下:
Step1输入用户—态势需求度矩阵;
Step2对态势原始数据进行预处理,包括数据清洗,预训练等;
Step3利用Doc2Vec方法训练词向量,并将文本内容特征耦合到用户—态势潜在特征中去;
Step4对推荐模型参数初始化;
Step5利用随机梯度下降法对模型进行训练,直到模型收敛;
Step7对各态势的预测需求度进行排序,将排序高的态势推送给用户。
4 实验结果及分析
本文实验数据采用雷达航迹仿真得到各类情报750 000条,其中用户定制的情报为1 500条,将数据划分为训练集和测试集。将各类情报数据转化成文本类型情报后,首先要对文本进行清洗,包括剔除文本中无用的标点符号信息;其次需要对文本进行分词及同义词合并,在分词的结果中剔除对语义表达没有影响的停用词;最后训练词向量,实现更加精确的词向量表示。
为评估算法性能,需要设置相应的评价指标来衡量算法优劣。本文采用均方根误差、准确率、召回率和F1这四个指标,各指标详细解析参见文献[15],此处不再赘述。实验编程语言用Python3.5,采用的机器学习库包括Numpy、Pandas、Scikit-Learn、Gensim、Jieba和CPU版本的TensorFlow。
在参数设置上,最大迭代次数为40次、批处理参数为1 000、隐因子个数为8、正则化参数为λD=λDNN=0.05、学习速率为0.001、网络层数分布为[64,32,16,8,1]。本文算法性能受迭代次数(epoch)、隐因子个数(factor)、正则化参数(regulation)、学习率(learningrate)、神经网络层数(layer)、推荐数目(k)等参数的影响。其它参数条件不变,来比较分析单一参数对算法性能的影响。对比实验的研究分析内容具体如下。
(1)对比实验1。其它参数不变,不同迭代次数条件下,对比本文算法(DNN+Doc2Vec)与深度神经网络推荐算法(DNN)、矩阵分解推荐算法[16](MF)的均方根误差。实验结果如图3所示。
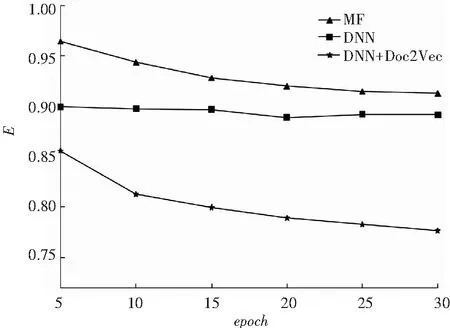
图3 3种算法均方根误差比较
由图3可知,分析得到的研究结论可阐释表述如下:
① 本文算法(DNN+Doc2Vec)均方根误差随迭代次数增加而减少,并且要小于深度神经网络推荐算法和矩阵分解推荐算法,本文算法在深度神经网络推荐算法的基础上,利用Doc2Vec方法学习文本内容特征,能够提升模型精度;
② DNN+Doc2Vec算法均方根误差随迭代次数增加而减少,但减小速率变慢,这是因为此时DNN+Doc2Vec算法训练正逐渐逼近最优解,故而算法推荐性能有所提升。
(2)对比实验2。 其它参数不变,迭代次数为30次,不同推送数目下,本文算法与深度神经网络推荐算法(DNN)、矩阵分解推荐算法(MF)的准确率、召回率和F1指标比较。实验结果如图4所示。
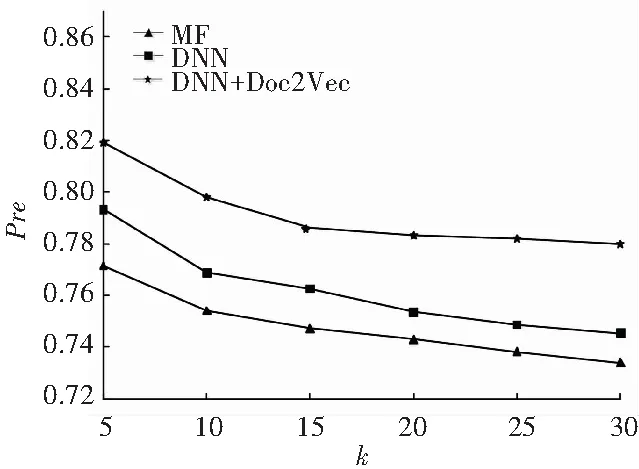
(a) 准确率

(b) 召回率

(c) F1
Fig. 4 Comparison of the precision, recall andF1 of the three algorithms
由图4(a)、(b)、(c)可知,分析得到的研究结论可阐释表述如下:
(1)本文算法(DNN+Doc2Vec)与深度神经网络推荐算法和矩阵分解推荐算法一样,准确率均随推送数目增大而变小,3种算法的召回率均随推送数目增大而变大,3种算法的F1指标均随推送数目增大而变大;
(2)DNN+Doc2Vec算法与DNN算法、MF算法相比而言,前者的均方根误差要小于后两种算法,说明本文算法利用Doc2Vec方法学习文本内容特征后,算法的推荐准确性有一定的提升。
综上所述,深度神经网络是推荐算法的基础,引入Doc2Vec方法来学习态势文本内容,能够挖掘出用户需求背后隐藏的用户和态势更加复杂的交互关系,使得态势特征表征更加明确,推荐效果得以提升,证明本文算法(DNN+Doc2Vec)确实能够提升推荐质量。
5 结束语
本文在军事运用背景条件下,提出了一种基于Doc2Vec和深度神经网络的推荐算法。该算法是在深度神经网络推荐算法对用户—交互关系进行建模的基础上,引入基于Doc2Vec的词嵌入模型来对文本态势实现建模,以期挖掘到态势更多的特征信息,使得用户需求建模更为准确。实验表明,基于Doc2Vec和深度神经网络的推荐算法与深度神经网络推荐算法、矩阵分解推荐算法等算法相比,本文算法得到的推荐效果更为优异。
猜你喜欢
社会科学战线(2022年4期)2022-06-15
今日农业(2022年1期)2022-06-01
新高考·高一数学(2022年3期)2022-04-28
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汽车与安全(2020年1期)2020-05-14
数学学习与研究(2018年15期)2018-11-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
