
一种基于深度学习的中文文本特征提取与分类方法
2019-12-25 09:06:48曹鲁慧邓玉香陈通李钊
山东科学 2019年6期
曹鲁慧,邓玉香,陈通,李钊
(1.山东大学,山东 济南 250100;2.山东财源保障评价中心,山东 济南 250001;3.山东省电子政务大数据工程技术研究中心,山东 济南 250014;4.齐鲁工业大学(山东省科学院)山东省计算中心(国家超级计算济南中心)山东省计算机网络重点实验室, 山东 济南 250014)
特征提取是机器学习中一项非常重要的特征工程任务,是处理机器学习任务的关键,同时也是数据挖掘、信息检索等领域中非常重要的一项内容。在机器学习领域众多的任务中,特征提取往往决定任务结果的好坏,就常用的分类任务而言,其分类结果的好坏同样取决于其所提取的特征的质量。传统的特征提取方法通常是人工提取,这种方法提取的特征通常包含与分类任务无关以及冗余的特征,此外其特征的维度通常比较大,这不仅使得模型训练过程效率降低、消耗资源,也会使模型过拟合并降低分类的准确率。为了解决特征维度过大、效率低下的问题,通常会对传统方法提取的特征进行降维,在所有的特征中挑选一部分最能够表示文本信息并使得分类效果最好的特征子集,但是这将使得分类任务的工作量增大。
近年来越来越多的研究者通过深度学习技术对特征进行提取。Chen等[1]提出使用多个卷积层与池化层的卷积网络来对高光谱图像的特征进行提取,然后将提取的特征用于图像分类以及目标检测并取得了不错的效果。在文本特征提取方面,Liang等[2]对文本特征提取的方法进行了概述,介绍了常用的传统特征提取方法以及基于深度学习的特征提取方法。其中基于深度学习的特征提取方法主要包括自编码神经网络特征提取、受限波兹曼机特征提取、循环神经网络特征提取以及一些其他的特征提取方法。Saxena等[3]讨论了从传统的词袋模型方法到非传统神经网络方法在文本分类特征提取中的所有应用方法,包括词袋模型、向量空间模型、人工神经网络、模糊神经网络、卷积神经网络以及深度信念网络。Meng等[4]采用弱监督多级神经网络对文本特征进行提取。Yao等[5]使用了图卷积神经网络对文本进行了特征提取和分类。因此,结合深度学习进行文本特征提取已经成为研究领域的热点。
目前使用深度学习技术提取特征在图像领域应用相对比较广泛,在文本特征提取方面文献报道相对较少,尤其是针对中文文本的特征提取研究成果较为稀缺。同时,使用传统的手工特征提取方法提取的特征维度通常比较大,使模型训练效率低、消耗资源。因此使用深度学习方法对中文长文本数据集进行特征提取,能够降低文本特征提取的难度,提高模型训练效率,同时也能够更准确地表示文本语义信息。本文使用两种不同的深度学习神经网络结构对文本特征进行提取。一种是卷积神经网络结构,该结构源于Kim[6]提出的用于句子分类的卷积神经网络结构;另一种是本文新提出的卷积循环神经网络结构。同时,使用传统的TF-IDF以及Word2vec特征提取方法对文本特征进行表示,提取的特征分别放入SVM与随机森林分类器中,对中国知网中文学术论文数据集进行分类。实验结果表明,使用卷积神经网络和卷积循环神经网络结构提取的高层文本特征比传统方法提取的特征更能准确表示文本信息,同时使用SVM和随机森林分类器取得的分类效果比原生的神经网络的效果更好。
1 特征提取方法
1.1 卷积神经网络
卷积神经网络(CNN)最早应用于计算机视觉领域并且在处理计算机视觉任务上已经比较成熟,如图像分类、物体检测[7-9]、图像分割等。随着深度学习技术的发展,越来越多的研究者将其应用到自然语言处理领域,Kim[6]使用卷积神经网络对文本进行分类并取得较好的分类效果。鉴于卷积网络在分类任务中的应用比较成熟,本文同样使用卷积神经网络对中文学术论文数据集进行分类,并建立特征提取模型以提取网络中的高层特征来表示文本的语义信息,使用的卷积神经网络结构如表1所示。

表1 常用文本特征提取卷积神经网络模型结构
本文建立的卷积网络特征提取模型是以上述网络结构中第8层网络的输出,作为特征提取模型的输出即使用上述网络中最高层的特征作为文本的特征向量。根据上述网络结构可知每个样本可用128维的向量进行表示,这将大为减少特征的维度,加快分类器的训练速度,提高分类的准确率。
1.2 TF-IDF
TF-IDF(term frequency-inverse document frequency)即词频-逆文档频率[10-12],是基于统计学的计算词权重的方法,是特征向量化的一种常用方法,在信息检索、数据挖掘等领域应用非常广泛。该方法用于评估一个词在该文档中对于区分语料库中其他文档的重要程度,即如果单词出现在本文档中的次数越多,在其他文档中出现的次数越少,则表示该词语对于这篇文档具有越强的区分能力,其权重值就越大。
TF表示一个词在该篇文档中出现的频率,用于计算这个词描述文档内容的能力。其计算公式如下。
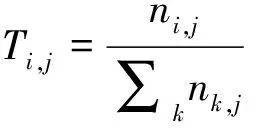
(1)
式中,ni,j表示在第j篇文档中该词出现的次数,∑knk,j表示对第j篇文档中出现的所有词的次数求和。
IDF即逆文档频率主要是度量一个词语的普遍重要性,如果一篇文档的某个词出现在语料库中的大多数文档中,则说明该词不能够对文档进行区分,反之,则说明该词能够将该篇文档与语料库中的其他文档区分开来。某一词语的IDF,是用语料库中所有文档的总数目除以含有该词的文档数目的商取对数。计算公式如下。
(2)
其中,|D|表示语料库中所有文档的数目,|{j:ti∈dj}|表示语料库中包含词语ti的文档数目。如果词语不在语料库中则会导致分母为0,为了避免这种情况的发生,通常分母使用|{j:ti∈dj}|+1。然后
Wi,j=Ti,j×Ii,
(3)
其中,Wi,j表示所计算文本在语料中的TF-IDF权重,文档内的高频率词语以及该词语在整个语料库中的低文档频率能够产生较高的TF-IDF权重值。
1.3 Word2vec
Word2vec[13-14]是词嵌入的一种方式,是谷歌开源出的一种词嵌入工具,也是目前在自然语言处理领域应用比较广泛的一种词嵌入方式。Word2vec将每个特征词映射到向量空间,并使用一个向量进行表示,在一定程度上刻画了文本的语义信息,便于计算特征之间的关系及相似性。主要包括两种模型,即跳字模型(skip-gram)和连续词袋模型(CBOW)。跳字模型是根据中心词去预测其上下文的背景词并根据预测结果来不断调整中心词的词向量。连续词袋模型是根据上下文的背景词去预测中心词,然后根据中心词的预测结果来不断调整上下文背景词的词向量。在模型训练过程中,为了减小计算复杂度,采用负采样(negative sampling)或分层softmax(hierarchical softmax)两种训练方式。
1.4 循环卷积神经网络
卷积神经网络具有提取局部特征的优势,长短期记忆网络(LSTM)具有捕获上下文信息的能力。因此,本文结合二者的优势,提出一种基于卷积循环神经网络(CRNN)的文本分类方法。该模型首先使用卷积网络对输入的文本信息进行多组特征提取,并分别对其进行池化以提取文本中重要的特征,然后将提取出的特征进行融合送入LSTM神经网络并经过全连接层输出分类结果。该模型包含输入层、词嵌入层、卷积层、池化层、LSTM网络层和全连接层,如表2所示。

表2 卷积循环神经网络模型结构
由于卷积循环神经网络模型能够取得较好的分类效果,因此,基于该模型建立的特征提取模型提取出的高层特征能够准确地表示文本的语义信息。本文建立的卷积循环神经网络特征提取模型是以上述网络结构中的第10层的输出作为模型的输出,根据上述模型结构可知,每个样本可用60维的高层特征向量进行表示。
2 实验验证
2.1 实验数据集
本文使用的学术论文数据集来源于中国知网上的学术论文。数据集中包含10个文献类别,分别为化学、轻工业手工业、畜牧与动物医学、药学、新闻与传媒、铁路运输、儿科学、体育、物理学、农业经济,每个类别选取40 000条数据作为实验数据,其中80%的数据集作为训练数据,20%的数据集作为测试数据。每条数据都包含4列,分别为类别、标题、摘要、关键词。实验中将标题、关键词、摘要合并为一条更长的文本作为实验数据的文本信息,由于数据集为非公开数据集,实验结果数据均采用5次实验的平均值。
2.2 基于深度学习的文本分类实验
本文设计两个对比实验,即分别使用CNN和提出的CRNN直接对中文学术论文数据集进行分类,建立新的文本高层特征提取模型来提取神经网络中高层的文本特征,然后将提取的文本特征分别放入支持向量机(SVM)和随机森林分类器中进行分类,将得到的分类结果进行比对。使用文本高层特征模型提取的特征在CNN、CRNN、SVM以及随机森林中的实验参数设置如表3所示,其中SVM核函数采用高斯核函数(RBF),随机森林estimator参数设为100。

表3 CNN与CRNN文本分类实验配置
2.3 基于TF-IDF的文本分类实验
TF-IDF是基于统计学的一种特征提取方法,本文使用TF-IDF方法对中文学术论文数据集进行特征提取并放入SVM和随机森林分类器中对实验数据进行分类。实验中设置的最大特征个数为30 000,最小文档频率为2。
2.4 基于Word2vec的文本分类实验
本文使用预训练好的基于中文学术论文数据集的中文Word2vec词向量模型,对中文学术论文数据集中的每个特征进行表示,然后将每个样本中的特征词向量进行求和来表示整个文本的特征向量,如下式所示。
ti=xi1⊕xi2⊕…⊕xin,
(4)
式中,ti表示第i个文本的特征向量,xin表示第i个文本中第n个特征的词向量。
实验中,使用神经网络中的词嵌入层将文本数据集中的所有文本特征一次性转化为预训练好的Word2vec词向量,而不是使用迭代的方式对每个特征词进行词向量转换,这将提高实验的效率,节省实验时间。最后将通过Word2vec词向量生成的文本特征向量放入SVM和随机森林分类器中对实验数据集进行分类。
2.5 实验结果分析
分类结果汇总如表4所示。由实验结果可知,使用基于神经网络的特征提取方法提取的高层文本特征在分类器中获得的分类结果比使用TF-IDF以及Word2vec方法提取的特征获得的分类效果更好,因此说明使用神经网络提取的高层文本特征向量更能准确地表示文本的语义信息。
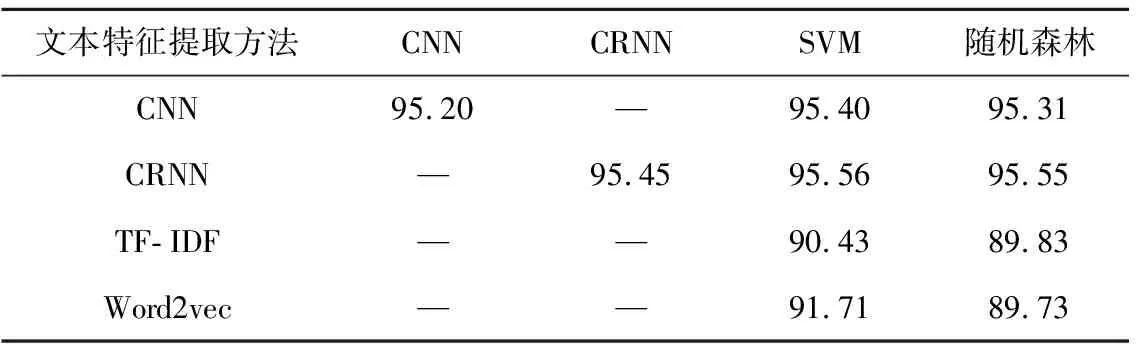
表4 学术论文数据分类结果
分析其中可能原因:使用TF-IDF方法对文本进行表示时打乱了词的顺序,忽略了词的上下文关系;使用Word2vec方法进行文本表示时,由于文本相对较长,使用词的词向量求和来表示文本向量时可能会丢失词的语义信息。此外,使用神经网络特征提取模型提取的特征放入SVM和随机森林分类器所得的分类效果略好于使用原生的神经网络分类方法。
3 结论
本文介绍了自然语言处理中文本特征提取和文本分类的相关研究现状,对比了基于深度学习和传统的TF-IDF、Word2vec等文本特征提取方法。在此基础上提出了一种基于卷积循环神经网络(CRNN)的文本特征提取方法,充分结合CNN在局部特征提取以及循环神经网络LSTM具有记忆的优势,将提取的特征前后关联,可更好地表达文本含义。经过论文数据集文本分类实验验证,基于深度学习的文本特征提取比传统特征提取更有优势,同时提出的算法优于基于CNN的文本特征提取算法。下一步计划对比更多文本特征选择的算法,另外针对中文的文本语义理解,增加注意力机制,实现大规模长文本的分类应用。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电视技术(2014年19期)2014-03-11 15:38:20
