
拉美一体化发展特征可视分析方法
2019-12-16 10:47李佳芮吴亚东
西南科技大学学报 2019年4期
李佳芮 吴亚东 王 松 王 娇 廖 竞
(西南科技大学计算机科学与技术学院 四川绵阳 621010)
一体化是指地理位置上相邻、有密切边缘政治经济关系的国家之间的聚合。拉美一体化虽然是在发展中国家中最早推行,但迄今也尚未形成以单一组织区域为核心的内涵逐步深化、外延持续扩大的一体化道路[1],而是形成各组织成员国在政治、经济、社会等多层次的发展特性。
拉丁美洲国家数据具有高维多元特征,含有17条国家数据对象,每个国家有1 441个独立或相关属性。多元是指每个国家具有的多个属性,维度指属性的数量[2]。评估拉美发展的因素众多且存在大量对需求无关因素的干扰,传统分析手段又耗费大量人力资源,有效地处理拉美数据,关键在于发现其包含的重要信息以及隐含的规律。可视化与可视分析技术为复杂高维多元数据提供了大量新颖的有效手段。在信息可视化领域,对高维多元数据的可视分析一直是研究的热点问题,其目的是探索数据项的分布规律和模式,并揭示不同元之间的隐含关系。常用的高维多元可视方法处理属性的个数有限,否则,将面临关键信息遮挡、空间利用率低下等问题。因此,针对具有高维多元特征的拉美数据在维度空间探寻的需求,需要设计有效的可视化分析方法。
本文提出一种利用层次数据划分和子空间分析相结合的可视分析模型来探寻拉美一体化发展特性。(1)针对拉美数据中的多个属性,利用文本分类将其构建成层次数据,建立出新的类别作为新的维度空间,方便自定义快速地探寻和筛选数据子集;(2)针对拉美数据中蕴含重要信息会被无关信息干扰的问题,利用子空间方法分析属性间的相关性,并结合视觉隐喻快速探寻维度空间的差异,该差异有助于全面认识影响拉丁美洲国家经济的贫困因子;(3)在重构的局部子空间中观察国家降维后的聚类特征;(4)使用多种可视化手段探寻拉丁美洲一体化发展的特征,以帮助拉美研究员和各经济学家对拉美国家制定精准的扶贫计划,促进各国经济发展。
1 相关工作
1.1 拉美国家数据分析现状
目前对拉美国家数据分析主要分为量化和非量化两种方法。非量化是指根据研究员的专业知识和经验,利用统计手段探索国家发展的规律与特征。例如文献[3-4],均借用传统统计手段对国家数据特定属性进行分析,通过对属性值变化规律的总结来分析具体问题。该方法工作量巨大繁杂,容易忽视重要因素,且需要相关专业知识和经验,缺乏对数据更深层次的认识。
量化是利用数据分析方法进行建模,例如,采用面板数据模型方法来分析拉美旅游业与经济增长之间的关系[5],用数据挖掘技术预测拉美人口发展指数[6],利用半参数面板模型估算拉美二氧化碳的排放量[7]。通过数据分析方法对拉美数据进行建模,具有分析效率提高、可靠性高等优点。本文研究主要用层次数据划分和子空间分析相结合的可视分析模型对拉美一体化发展特性进行探索分析。
1.2 高维多元数据分析与可视化
拉丁美洲数据具有高维多元特征,涵盖着数据的多种性质,例如层次性、时空性、多属性等。国内外研究人员从不同的角度利用不同技术来研究高维多元数据。
1.2.1 高维多元数据分析
由于受“维度效应”[8]的影响,当采用传统的降维算法处理高维数据时,降维结果的精确度和稳定性将会大幅度降低,同时大量对聚类的并无贡献的属性会干扰结果的准确性。为解决这类问题,研究人员进行了大量研究工作:文献[9]利用子空间分析对维度局部相关性进行了研究;夏佳志等[10]提出发现有意义的数据子集并揭示其局部相关性的方法;Yuan[11]利用数据的层次性合并或拆分子空间来探索高维数据的数据对象间的相关性和维度相关性;张彰[12]对VSM改进来划分文本数据的层次性;Sirius[13]运用加权高维距离函数来同时分析数据对象和维度;陈谊[14]利用KNN自动将相关维度分组成簇来分析维度子集,进而利用Pearson计算各维度之间的相关性程度。
本文研究结合上述工作,将拉美数据的属性转化成层次结构,再结合子空间方法分析属性之间的相关性,研究拉美数据属性相关性和局部子空间下数据对象的降维结果。
1.2.2 高维多元时空数据可视化
目前高维多元可视化方法主要分为多重协调视图[15]、关联对比和视觉隐喻。平行坐标、散点图以及雷达图是常用的关联对比可视化方法,其形式简洁、可扩展性强,但其对数据属性数量有限制,否则将会造成视觉重叠,增加认知负荷。Chenyi等[16]提出MCT,将平行坐标的思想应用于树图布局之中,充分利用有限的空间展示数据的层次结构和多维属性信息。Chernoff[17]将多个维度利用人脸的各部分来表示,采用视觉隐喻的方法相对于文字更为直观。时空数据是指带有地理位置与时间标签的数据,是一类与时间密切相关的高维数据,需将各属性在时间上的规律进行可视化。Charles[18]在19世纪利用国家地理位置和从法国出口到世界各地的葡萄酒的数量,设计了显示葡萄酒出口数量走势的地图。
本文结合上述工作,选用以下可视化方法:(1)选用最传统的节点-链接可视化方式但其空间利用率较高的缩进图来展示属性分类后的层次结构;(2)因视觉隐喻的方式传递信息效果比文字更为显著,选用图标与散点图结合方式来表示属性间的相关性同时传递分类信息;(3)因平行坐标可扩展性强,为其添加轴选取操作来实现对多个或特定的国家进行多种属性的关联对比。
2 可视化任务和分析流程
2.1 数据描述
本文数据来源于World Bank,其中包含拉丁美洲及加勒比地区17个国家在内的1960年到2016年的数据,且每个国家包含1 441个属性,如:耕地(公顷数)、PPG、IDA(DOD,现价美元)等,是典型的高维多元数据。
2.2 可视化任务
拉美研究人员在面对大量的属性时,使用传统的数据统计方法并不能区分出重要的属性,因此提出以下需求:分析某一具体问题,例如环境、经济等,筛选出相关属性的任务相对繁重,希望能快速找到同种类的属性;分析拉美国家经济变化问题的时候,希望能同时对多个国家多个属性值进行关联对比并观察其时变信息;希望能直观感受各国的经济随时间的发展变化。综上所述,可视化任务需求如下:
T1:展示全部属性的层次结构和属性间的相关性,以供用户发现并筛选出兴趣子空间;
T2:展示兴趣子空间上各国降维后的聚类特征;
T3:展示多个或特定国家多属性的关联对比;
T4:展示特定成员国多属性的时变演化规律。
2.3 分析流程
本文提出的可视分析流程如图1所示。首先对拉美数据属性的层次结构进行全面浏览,对数据有初步认识;接着在属性投影中分析属性间的相关性,根据需求发现对应的相关元,将其组成称之为兴趣子空间,并快速地筛选重构出新的局部子空间;接着在局部子空间中对拉美国家进行降维投影,进入数据抽象化的浏览和探索;最后利用地理空间位置、多属性的时序变化和指标排名变化可以实现多对象多属性的时序变化和关联对比,对降维结果和属性投影进行辅助验证,进入数据具体化的探寻和分析阶段。

图1 可视化任务和分析流程Fig.1 Visualization task and analysis flow chart
3 系统总体框架和数据处理
3.1 系统总体框架
系统的整体框架如图2所示。系统由数据预处理模块、算法模型和可视化界面组成。数据预处理模块是指对原始数据进行整理、清洗、筛选和规范化等处理。算法模块中首先利用文本分类将拉美数据的属性转化成层次结构,接着利用子空间分析属性间的相关性。可视化界面通过多视图协调来展示拉美数据多个国家和多属性之间的关联对比和时变规律,配合交互使用户从多个角度深层次探寻拉丁美洲国家数据。
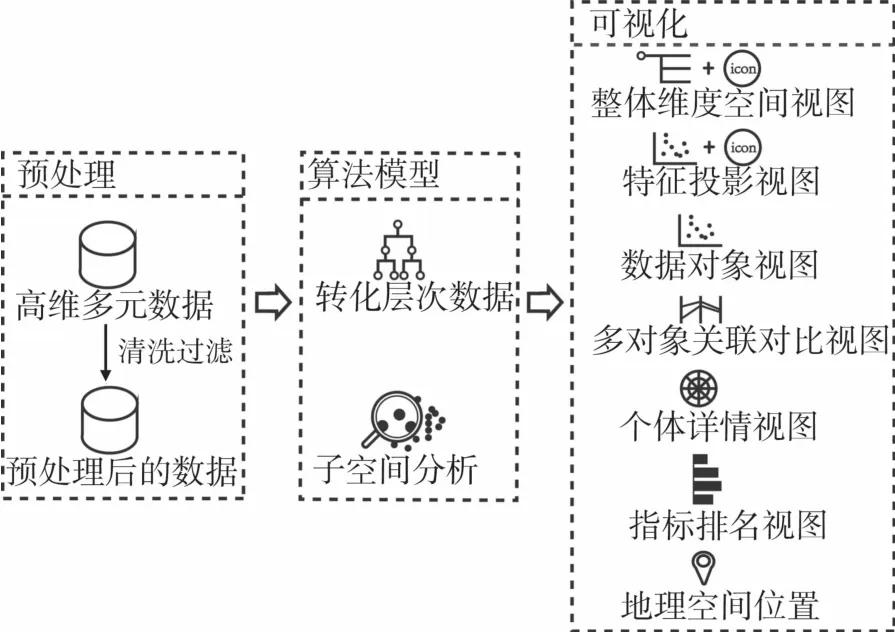
图2 系统框图Fig.2 System block diagram
3.2 数据处理
3.2.1 数据预处理
原始拉美数据规模较大,信息杂乱无序,数据对象独立存在,且常伴有稀疏特征及时变的性质,故单纯利用均值填充对原始数据填充会使结果准确性降低。本文运用完整数据的期望最大化来推算每条数据对象的缺失值,处理成标准的数据格式方便后续分析使用。
3.2.2 转化层次数据
利用文本分类对拉美数据的属性进行分类,主要过程为:首先利用TextRank对属性提取分类的关键词,公式为:

其中,WS(vi)表示每个单词的TextRank值,d为阻尼系数,一般设置在0.85。In(vj)指在单词i前面的单词集合,Out(vj)指在单词i后面的单词集合。基于公式(1)计算出每个单词的重要性,最重要的若干词为关键词。
由关键词和词频大于阈值的名词生成类核心词CoreWord(Cj)={w1,w2,…,wn},再将每条属性下的属性名称、属性介绍、属性来源提取出合并为一个文本文档,对其进行特征提取和特征值计算后建立文本向量空间模型[12]。

式中,Score为衡量选出类核心词与单个属性文本向量的重要程度的打分函数,Cj为类核心词CoreWord的集合,a,b为权重,a+b=1,V(Ti,Cj)为文本Ti属于Cj的影响值,若共有m个类别,则重要的类别为:

3.2.3 子空间分析
拉美数据集蕴含着多重信息,而仅靠人工分析耗费人力资源,因此需要借助子空间分析属性间相关性,即提供对属性分布态势的宏观浏览,也为用户探索兴趣子空间提供凭证。将拉美数据集的n个国家表示成X=(x1,x2,…,xn)和每个国家的m个属性表示成Y=(y1,y2,…,ym)构成一个n×m的矩阵。运用KNN-Pearson[14]来计算出属性间的距离,先利用KNN算出国家xn在某个维度ym上最近的各点的距离d(n,m),由式(4)得到国家xn在某个维度ym上的密度,任意2个属性yj和yh间的距离公式如式(5)所示。

将式(5)构造出的距离矩阵利用多维尺度变换,在二维空间重构其欧几里得坐标进行降维投影,使其保持与原始维度空间的大体匹配来表示属性间的相似性。
4 可视化系统设计
可视系统总览图见图3,主要包括七大主要交互视图:整体维度视图(a)、属性投影视图(b)、数据对象降维投影视图(c)、地理空间位置(d)、指标排名视图(e)、个体详情视图(f)、多对象关联对比视图(g)。
4.1 整体维度空间视图
经预处理后的数据通过关键词提取和分类后,转化成层次结构,对划分出的新类别用不同的图标隐喻其含义,如图4所示,本文数据处理后最后分为以下七类:Agriculture,Development,Economics,Eucation,Environment,People,Resources。整体维度视图如图3(a)所示,利用缩进树来展示分类以后的属性,使分析者能浏览整个属性的层次结构,并且能快速筛选出特定属性,后续的属性投影视图也可作为本部分层级结构分类结果的验证。
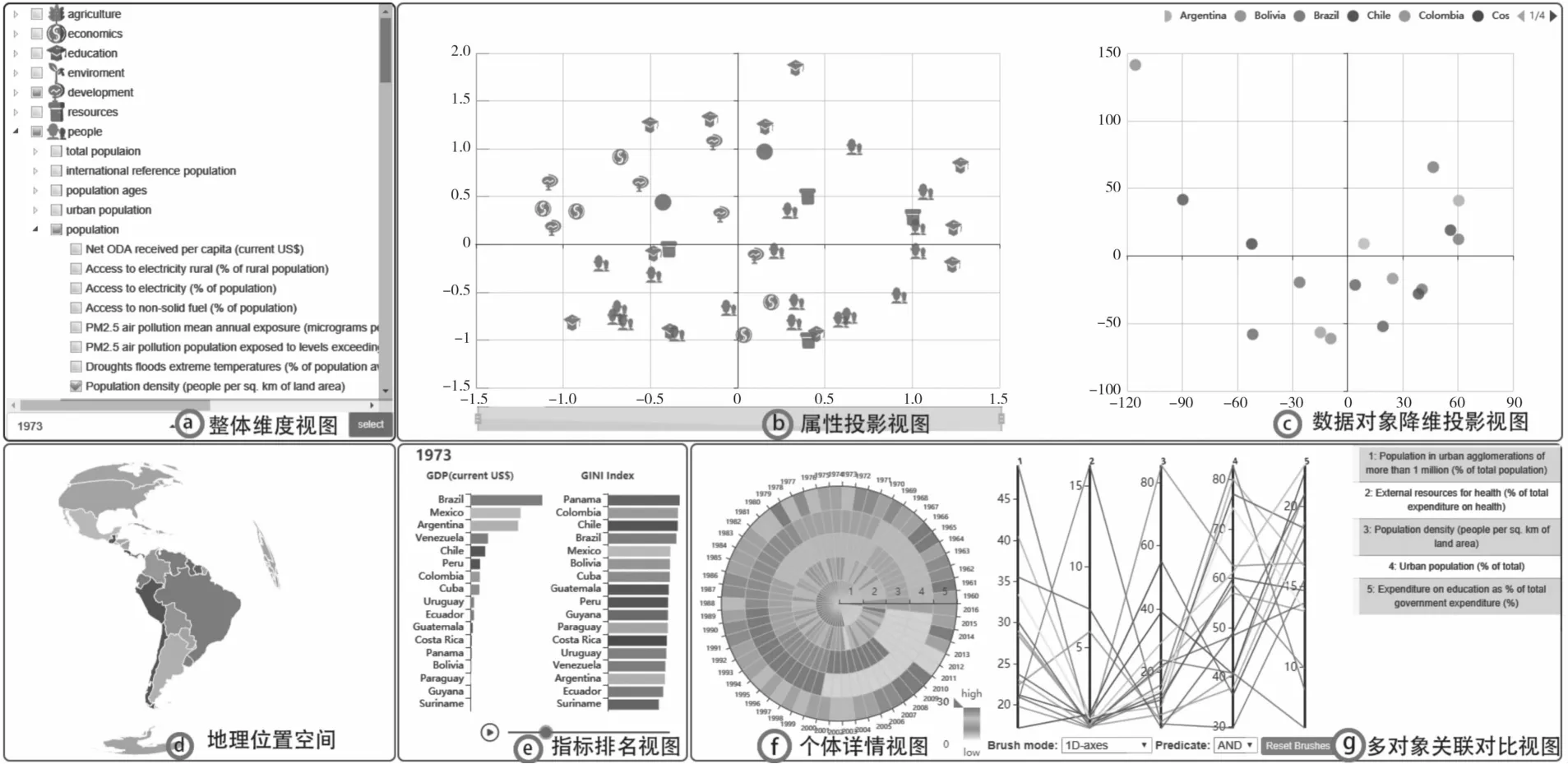
图3 系统概览Fig.3 System overview

图4 图标设计Fig.4 Icon design
4.2 属性投影视图
属性投影视图如图3(b)所示。经过层次结构划分后,数据的每条属性都可根据其所属的类别抽象为特征元,在投影视图中用散点图和图标隐喻结合的方法展现了属性的分布态势,系统地为用户发现兴趣子空间提供参考。根据已分好的7类,样本的每条属性用不同图标表示在散点图中,并将直接反映国家经济情况的GDP和GINI单独标注,可以直观地分析拉美国家经济状况与财政收入、教育水平、利民措施、能源短缺和人口组成等指标随时间变化的关联性,从多个指标的角度全面探寻拉美一体化发展特性,对拉美国家制定更完善的经济政策和扶贫政策有重要意义。
4.3 数据对象降维投影视图
如图3(c)所示,数据对象降维投影视图显示了拉美国家对象在局部子空间下的降维结果,避免了直接对高维数据降维后造成的特征丢失等问题,用户也可自定义探寻筛选出新的子空间,通过多维尺度来分析数据对象降维后的聚类特征。
4.4 个体详情视图
如图3(f)所示,个体详情视图用来展示拉美各国多属性的时变信息,用户可通过缩进树图选择4个属性,极轴上则对应分为n段,平面上的圆弧长顺时针表示年份的变化,左下角的颜色由白色到红色编码范围从0到30,表示数据值从低到高的变化,利用滑块可自定义筛选编码范围内的数据。
4.5 多对象关联对比视图
如图3(g)所示,多对象关联对比视图利用平行坐标来同时分析拉美各国和多个属性之间的关系。轴上折线的颜色与地图中国家颜色相对应。另外,在传统的平行坐标上增添刷选取功能,并且提供3种刷选取来展现特定国家间的关联对比,分别为:单轴选取、多轴选取、扫弦选取。单轴选取是将鼠标在轴上的拖选范围进行高亮显示,每条轴上只能选取一次;多轴选取可以在一条轴上执行多个范围的轴选择;扫弦选取相对于单轴选取和多轴选取更为灵活,鼠标作用范围是在轴与轴之间,可以由鼠标自由任意角度选取,当样本数据聚集时,用扫弦选取更为方便。
4.6 指标排名视图
如图3(e)所示,排名视图基于柱状图展示了各国GDP和GINI随年份的排名变化,图中每个柱状图的颜色与地图中国家颜色相对应。GDP指国内生产总值,是从生产角度衡量国家在一定时间内创造的物质财富,代表国家的竞争力。GINI指数指一个国家和地区的财富分配状况,指数值在0到1之间,数值越低表明财富在社会成员之间的分配越均匀,反之亦然。一般把0.40作为收入分配差距的界限,可以看到拉美国家的GINI在0.40~0.59之间。联合国开发计划署等组织规定GINI在此区间属于财富差距较大,比较容易出现社会动荡问题。本文用GDP和GINI作为拉美国家经济变化的综合指标,可以看到各国的经济随时间的排名变化。
5 案例分析
5.1 拉美一体化区域整体发展趋势
经过对拉美数据属性的分类,图3(a)中可浏览整个属性的层次结构,图5和图6显示了1973年和2015年拉美国家属性投影的分布态势。MDS视图的轴本身无意义,要靠分析人员的经验和主观判断其中的文本标签才能给出定义,但本研究运用视觉隐喻方法可加快分析员对坐标轴定义。例如:1973年y轴上教育的属性较多,即可从教育方面来定义y轴,分析得到上方为教育水平高的,如科技期刊文章、专利申请等,下方为教育水平低的,如失业人口、失学率等;在水平方向人口的属性较多即从人口方
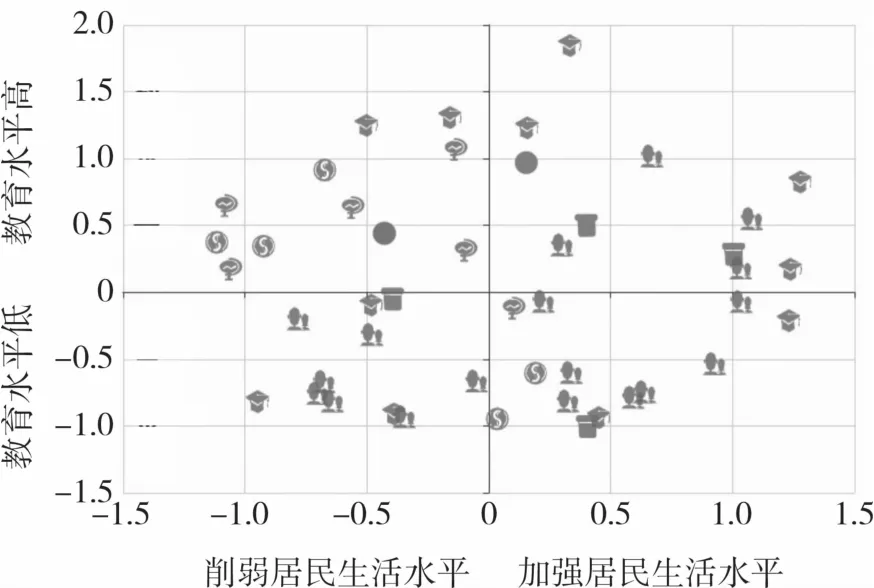
图5 1973年属性投影Fig.5 Attribute projection in 1973
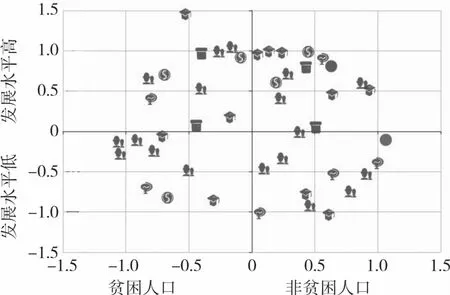
图6 2015年属性投影Fig.6 Attribute projection in 2015
5.2 各国贫困因子分析
将1973年和2015年的贫困因子作为新的子空间来展示拉美各组织成员国降维后的聚类特征和关联对比,如图7所示。1973年Cuba,Guatemala明显偏离,Costa Rica,Guyana次偏离,与其他国家在这些属性上最不相似。Cuba,Guatemala在大城市群和卫生外部资源上与其他国家差异巨大,均成较低水平,其都属于大城市群较少且人口密度多的国家;Costa Rica和Guyana有较少的大城市群,且Guyana人口密度、城市人口也较低。图3(e)中1973年Cuba面来定义x轴,左边为削弱居民生活水平因素,如自付医疗开支、在职儿童、无薪家庭工人等,右边为改善居民生活水平因素,如可再生内源淡水资源、国际旅游收入、医疗卫生开支等。2015年轴上的属性多是关于发展,即从发展方面定义y轴,分析得到上方为国民生产层面对经济所做的措施,如工业就业、工资及受薪工人总数,下方为国家政府层面所做的措施,如卫生外部资源、卫生支出总额、公共卫生支出;x轴上人口属性最多,所以从人口方面来定义,左边为贫穷阶层人口,如居住在贫民窟的人口、农村人口、失业人口,右边为非贫穷阶层人口,如人口100万以上的城市群、大城市人口。分析可知,与拉美一体化区域的经济水平相关由教育水平低和削弱居民生活水平的因素变成国家政府层面和非贫困人口阶层影响的因素,可推断拉美一体化区域发展趋势从教育水平低和居民生活条件差变成有社会保障和受贫困阶层影响,可看出经济与教育水平、生活条件、社会保障均相关,这也正如文献[3]中提出对国家贫困性要从多个角度定义,货币收入不再是衡量贫困的唯一标准,而是受多个维度相互影响。经济高于Guatemala,Costa Rica经济高于Guyana,但Costa Rica的GINI要低于Guyana,说明Costa Rica相对于Guyana地区财富分配要均匀。结合图3(d),这4个国家国土面积都小,可推断:对于小面积国家,大城市群和城市人口对经济有重要影响。GDP的排名也可看出1973年各国经济跟城市人口和人口密度有重要关系,其中排名靠前的Argentina,Mexico和Brazil在国土面积上也是靠前的,可推测出国家经济跟国土面积也有一定关系。

图7 1973年和2015各国在贫困因子维度下的聚类特征和关联对比Fig.7 Clustering characteristics and correlation comparison of countries in poverty factor dimension in 1973 and 2015
2015年Mexico和Brazil最偏离集群,利用轴刷在平行坐标中将两个国家单独选择出来,可以看到两国公共医疗开支、国际旅游人数到达都呈较低水平,自付医疗开支、教育开支呈较高水平;结合排名视图看到Mexico的GDP排名第一,但Brazil的GINI远远高于Mexico,Brazil相对于Mexico国内财富分配极其不均匀,可知国土面积大小对国家GDP有着重要影响,且随着时间的变化对国家经济的影响不再全关乎城市人口,而是跟卫生改善、医疗保障、旅游收入和教育多个角度有关联。
综上所述,拉美一体化经济在较早的时候跟国土面积等相关,但随着时间的变化,拉美一体化经济与教育、环境、发展、资源和人口等多个维度均有关系,所以拉美一体化发展形式复杂。
5.3 巴西城市化发展进程
巴西城市化发展进程如图8所示。Brazil在1960年至2016年城市人口增长率呈从低到高再逐渐减缓的变化趋势,农村人口增长率由高逐步降低并呈负增长,非正规就业人口由高变低,工业就业和服务业人口呈增加趋势,大城市数量增长从缓慢变高到急剧下降,城市贫民窟人口呈中等程度。
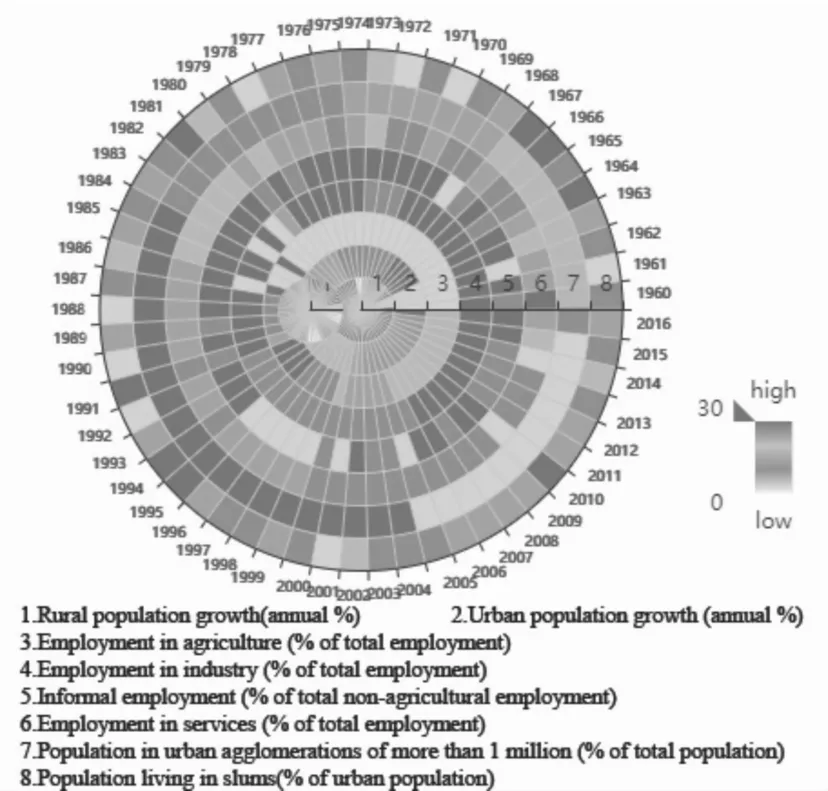
图8 巴西城市化进程Fig.8 Urbanization in Brazil
Brazil城市化进程特点同文献[4]描述基本一致。可以将Brazil的城市化进程分为两个阶段:(1)1960-1980年呈城市化快速推进阶段,此阶段农村人口增速降低,城市人口增速加快,非正规就业人口转化为工业和服务业人口,由于大量人口向城市涌进导致大城市数量增加;(2)1980-2016年基本完成城市化进程,此阶段城市人口增速变缓,农村人口增速呈负增长,大城市数量变少,中心城市规模变大。
5.4 拉美一体化的多层次发展
从失业率、贫穷、不平等、失学等社会经济的属性来观察拉美各国经济的发展。
如图9所示,Argentina的贫困人口呈低水平,失业、失学、艾滋病感染率和贫困差距呈稳步下降的趋势。Bolivia的贫困人口、失业、失学呈一个比较高的状态,但贫困人口随艾滋病感染率的减小而降低,其贫困差距则一直变化。Brazil,Colombia,Ecuador,Mexico,Paraguay贫困比例均从高水平降低,Bolivia,Colombia,Brazil,Uryguay国家失业人口处于较高水平。Brazil失学儿童、贫困差距、未成年生育率均呈较高水平,GINI排名也靠前,可知Brazil国内发展极不均匀。

图9 拉美各国的经济发展Fig.9 Economic development in Latin America
通过分析可以得出:自拉美一体化以来,拉美各国社会经济均不同步,并未实现理想的一体化,而是在不同的内外因下朝着振兴各国经济、脱离贫穷的共同目标发展且呈多层次的发展特性。
6 评估和讨论
为了验证系统的有效性,邀请了拉美研究院工作人员对本文工作进行了初步评估,收集和整理专家们的反馈意见,总结如下:(1)系统功能:整个可视化系统的设计新颖有意义。该系统能浏览数据整个维度空间以及其中明朗的层次结构,可同时分析属性间的相关性和局部维度空间下数据对象的降维态势,能对研究员提供对数据更全面的认识和研究手段,使其做出更具科学性的决策,而不仅仅再依靠经验。(2)可视化技术:可视化的设计基本实现可视化的设计目标。在可视化过程中,可依靠属性相关性对数据进行探索,也可添加人的决策判断,这种可视化的设计对拉美国家数据的研究非常有用。在可视化表达上,专家给出了肯定并发表如下评论:“该研究过程非常有趣且有一定的意义”“能在一种视图上同时看到多个属性时变信息的方式很有效率”“数据的展示模式很新颖”等。(3)交互技术:专家认为个体详情视图和多对象关联视图是一组很好的设计模块,可进行从整体到个体对国家间的关联对比以及多个属性的时序变化趋势分析,但层次化后的属性筛选仍存在一定的认知负荷以及消耗掉较长的时间,在这方面还需要进一步优化。
7 结论
拉美数据属性过多,耗费大量人力资源,若直接对其属性降维则会被噪声干扰而无法有效揭示信息,本文提出利用层次数据划分和子空间分析相结合的可视分析流程来分析拉美一体化的发展特性。该方法首先对属性进行分类并用图标表示,使得分析员更深刻理解数据并快速筛选属性,提高效率;利用子空间分析属性间相关性来发现兴趣子空间,结合视觉隐喻,使得其投影结果能更为直观,更易理解;结合可视化技术和交互技术实现了多对象的关联对比以及多属性的时变信息展示。
在本研究的基础上,未来将从以下几个方面进行进一步研究和改进。首先,利用查询算法使得研究员快速查询属性,提高效率。其次,本文为了节省空间采用的是最传统的缩进树来展示数据的层次结构,未来应同时考虑空间利用率和层次数据可视化创新,例如树图。最后,希望能针对目标进行重要性分析,筛选出所需的属性,从而减轻研究员的分析任务。
猜你喜欢
数学杂志(2022年4期)2022-09-27
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
世界知识画报·艺术视界(2017年7期)2017-07-27
学生天地(2017年11期)2017-05-17
学生天地(2017年11期)2017-05-17
自动化学报(2017年11期)2017-04-04
火控雷达技术(2016年1期)2016-02-06
自然资源遥感(2014年2期)2014-02-27
