
面向开放式信息抽取系统的知识推理验证
2019-12-16 10:47陈泽东赵旭剑杨春明
西南科技大学学报 2019年4期
陈泽东 赵旭剑 张 晖 杨春明 李 波
(1.西南科技大学计算机科学与技术学院 四川绵阳 621010;2.西南科技大学理学院 四川绵阳 621010)
互联网包含着海量的文本信息,从中大规模地抽取知识是一项艰巨的挑战。开放式信息抽取系统(OpenIE)以各种技术手段从互联网中开放式地抽取实体E和实体间的关系R,并以实体和关系构成的三元组(E1,R,E2)作为知识的表达,为构建知识库和形成知识图谱提供研究基础。目前OpenIE技术已经广泛应用于问答系统、信息检索、知识图谱等研究领域,成熟的系统包括NELL[1],TextRunner[2],Yago2[3]等。图1是开放式信息抽取系统的基本框架,利用知识抽取方法从Web等自由文本中抽取三元组关系作为候选知识,再经过进一步整合将候选知识放入知识库中。

图1 开放式信息抽取系统的知识抽取框架Fig.1 Framework of open information extraction system
与特定领域的信息抽取方法不同的是,OpenIE系统通常以粗略的种子迭代学习为主要抽取方法,抽取结果往往存在大量噪声,主要表现为抽取结果中的实体关系违反实体间的语义约束,导致知识表达错误。因此,针对OpenIE系统的抽取结果进行推理验证,能有效解决知识集合中的噪声,提高知识表达的语义规范性和正确性,对于知识库构建和知识图谱生成具有重要的研究意义和应用价值。
针对上述问题,本文首先使用一阶逻辑语言对知识抽取结果进行转化和推理,并且在推理过程中引入本体规则进行约束,并在此基础上建立推理规则的自动学习机制,解除传统规则推理对于实体解析规则的依赖,进而实现对知识的自动推理和验证。本文的主要工作如下:(1)提出一种基于本体约束的PSL规则学习方法,通过将本体语义约束引入PSL规则学习,利用规则的逻辑运算进行关联规则的自动推理,提高规则生成效率,增强规则的可读性;(2)建立面向知识库的标签核类簇模型,基于该模型提出一种基于关联度的知识推理验证方法,有效降低知识推理验证对实体解析规则的依赖,减少推理规则数量,提高推理验证效率;(3)在NELL官方数据集上与马尔科夫逻辑网、传统概率软逻辑模型进行对比实验,验证方法的有效性,同时探讨不同类型规则对模型性能的影响,为推理规则的产生提供新的研究思路。
1 相关工作
开放式信息抽取系统的知识推理验证是当今NLP领域的一个研究热点。目前针对该问题的主要研究方法是以TransE[4]为主的表示学习方法。该方法受到word2vec[5]的启发,其直观描述为将每一个三元组(head,relation,tail)形式的知识向量化表示,然后通过不断学习使head+relation=tail,从而解决链接预测等问题。TransE是作为知识库向量化的一个基础工作,之后的TransH[6],TransR[7],TransD[8]都是以不同的实体关系问题为背景在TransE基础上做改进。Trans系列模型在实体关系的链接预测问题上一直有不错的表现,但是因为此类方法根本上是利用知识库中已有关系对向量进行学习,并且无法使用规则,所以它无法解决实体之间存在错误关系的问题。
Jiang等[9]提出了一种基于马尔可夫逻辑网(Markov logic network,MLN)[10]的方法。MLN使用带有权重的一阶逻辑规则对实体关系进行建模用于概率推理,这使得规则的约束力有了一定的灵活性,当某条知识违反了规则,那么它是正确知识的可能性就会变小而非不可能,换而言之一条知识违反的规则越少那么它正确的可能性就越大。
Pujara[11]等最先提出了采用概率软逻辑模型(Probabilistic Soft Logic,PSL)[12]对知识抽取结果进行推理验证。PSL是马尔可夫逻辑网的进一步延伸,其最大优点在于可以使实体关系三元组中实体和关系在[0,1]区间内取任意值而不是布尔值,实验结果表明这种做法使模型的推理性能和推理效果都有明显提升。然而,目前PSL模型的推理规则仍为人工构建,成本大、效率低,并且规则数量和推理方法往往会影响模型的推理结果,因此,基于传统PSL模型的知识推理验证方法对于面向Web的开放式信息抽取系统是不适用的。针对该问题,本文提出一种基于PSL规则自动生成模型的知识推理验证方法。我们首先使用一阶逻辑语言对知识抽取结果进行转化和推理,并且在推理过程中引入本体规则进行约束,在此基础上建立PSL规则的自动学习机制,解除传统PSL推理对于实体解析规则的依赖,进而实现对知识的自动推理和验证。
2 知识表达的PSL规则构建
PSL模型采用加权一阶逻辑规则对知识进行推理,所以首先要对OpenIE系统抽取的知识表达进行逻辑谓词转化,进而构建PSL推理规则。
2.1 概率软逻辑模型
概率软逻辑是由马里兰大学和加利福尼亚大学圣克鲁斯分校的统计关系学习组LINQS开发的机器学习模型。该模型采用带有权重的一阶逻辑规则与图模型相结合,提供有效的推理机制。与其他机器学习的方法不同,PSL以其可人工制定高可读性的规则被用于集体分类、社会信任分析[13]、个性推荐[14]等各个领域并取得了不错的效果。概率软逻辑推理规则由具有权重的一阶逻辑规则构成,例如:

该条PSL规则表示如果x,y是朋友关系并且y投票给了z,那么x也会有一定概率投票给z,投票概率用权重w表示。在该逻辑规则中,逻辑谓词friends(x,y)和voteFor(y,z)组成了规则体,而vote-For(x,z)构成规则头。逻辑谓词都有各自的解释概率,代表某事发生的可能性。规则r被满足的概率φ(r)根据公式(2)计算得到。

式(2)中Ibody和Ihead分别表示规则体和规则头的概率值,且逻辑符号的数值运算方式如下:
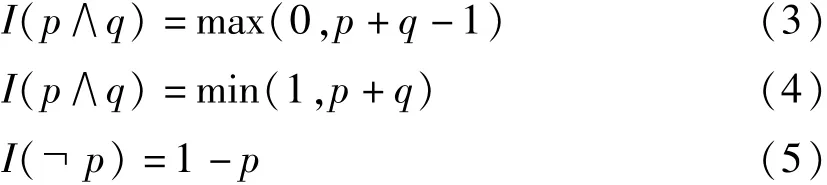
p和q代表逻辑谓词,例如公式(1)中的friends(x,y)。PSL对于每个谓词的概率计算方式如下:
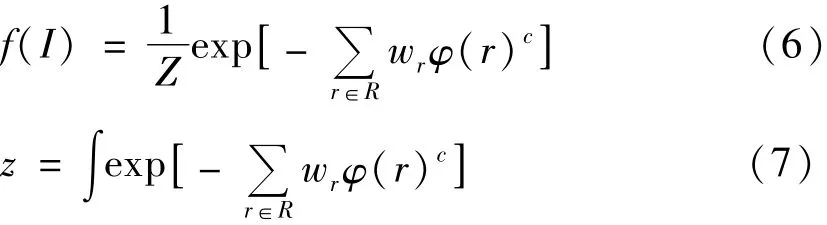
其中:w为规则的权重;Z表示规一化因子;c取值为1或者2,代表两种不同的损失函数。
2.2 逻辑谓词转换
为了使用PSL模型对OpenIE抽取得到的知识进行推理,首先需要对知识进行对应的逻辑谓词转化。在知识库中知识主要以实体-关系(E1,R,E2)和实体-标签(E,L)两种形式存在。实体-关系谓词和实体-标签谓词分别表示为Relation(E1,E2,R)和Label(E,L),具体如表1所示。

表1 实体-关系谓词和实体-标签谓词转换实例Table 1 Examples of entity-relational predicate and entity-label predicate transformation
2.3 基于本体约束的PSL规则学习
从2.1对于PSL模型的描述中可以看出,规则的质量和规则对应的权重会极大程度影响推理的结果。然而,PSL规则的获取是完全独立于PSL模型的。传统的PSL模型规则生成一般依赖于专家方法,专家制定规则的优势在于规则的质量高,但是数量有限且效率较低,对于复杂场景下的知识推理存在明显不足。张嘉等[15]尝试使用C 5.0算法,通过半自动学习生成PSL规则。然而,通过C 5.0生成的规则可读性不高,这与PSL旨在建立可理解的机器学习模型的初衷相违背。因此,本文根据不同的本体约束关系分别构建PSL规则自动学习方法,提高规则生产的效率和可读性。考虑到知识库中主要以实体-关系和实体-标签为知识构成的主要形式,我们主要通过外部语料库等一系列方法自动获取了Inverse,Mutual Independence,Range,Domain和Subordination等本体约束关系,并结合实体-关系谓词和实体-标签谓词学习PSL规则自动生成,如表2所示。经过实验验证,自动获取的规则也同样得到了很好的推理效果。

表2 基于本体约束与逻辑谓词的PSL规则生成Table 2 PSL rules based on ontology constraints and logical predicates
表中Inverse类规则所表达的含义是当两种关系R1和R2属于可逆类型的时候,并且E1对于E2存在关系R1,那么对于E2存在对应于E1的关系R2。比如老师和学生就属于一对Inverse关系,这条本体规则主要用于补全实体之间的相互关系。Mutual Independence(Mut),其主要表达的含义是在封闭世界假定[14]前提下,如果两个关系R1和R2互相独立,且E1和E2拥有关系R1,那么他们之间就不存在关系R2,该类规则主要用于验证关系的正确性。
另外,本体约束Range在规则中表示:如果实体E1和E2具有关系R,那么E2具有标签L。比如Range(首都,城市),对应的实例可以是如果美国的首都是纽约E2,那么E2纽约的标签就是城市,Domain刚好与其相反。这两种规则的主要作用是将关系的推理验证和标签的验证连接起来,使整个推理验证过程不再是实体和关系分别独立的验证,并且使推理可以相互作用。
对象间的Subordination约束反映不同对象之间的上下位关系限制,这类本体约束规则在本文中用于关系补全和验证。目前,上下位获取的方法主要有两类:一类是基于模板匹配的方法[16-17],主要利用语言学和自然语言处理技术,通过词法分析和句法分析获取上下位关系模式,然后利用模式匹配获取上下位关系;另一类是基于外部语料库的方法[18],主要基于语料库和统计语言模型,通过聚类计算概念间语义相似度来获取上下位关系。但是知识库中不存在上下位这种语义环境,因此本文采用WordNet[19]作为Subordination标签和关系的外部依赖获取本体关系。
3 基于PSL模型的知识推理验证
实体解析[20]在传统PSL推理中具有重要作用,因此,PSL推理验证方法对于实体解析依赖较强。然而,通过相似度度量对OpenIE系统富含噪声的抽取结果进行实体解析往往效果较差,甚至影响模型的推理性能。因此,本文建立面向知识库的标签核类簇模型,基于该模型提出一种基于关联度的知识推理验证方法,有效降低知识推理验证对实体解析规则的依赖,减少推理规则数量,提高推理验证效率。
3.1 知识冲突检测
针对具有语义错误的知识抽取结果,本文首先通过建立标签核类簇模型,从抽取结果中快速发现知识的标签核类簇,并根据标签核类簇中实体与实体的关联关系,检测具有语义冲突的知识对象。
定义1 标签核类簇C[L,E(e1,e2,…,em),R(r1,r2,…,rn)]:表示以标签L为核心的实体集合E(e1,e2,…,em)具有同一个标签L,同时,标签核类簇C中实体与实体之间的关联关系用关系集合R(r1,r2,…,rn)表示。图2包含两个标签核类簇,其中城市与湖人队分别为标签核,它们有各自的类簇结构。

图2 标签核类簇定义Fig.2 Definition of label cluster
定义2 知识冲突:存在实体e及标签核类簇C[L,E(e1,e2,…,em),R(r1,r2,…,rn)],如果实体e与实体集合E(e1,e2,…,em)的关联关系数小于阈值θ,则实体e与标签L存在知识冲突。
本文通过遍历所有与目标实体e连接的标签核类簇集合S(C1,C2,…,Cn),选取其中与实体e具有最大关联关系的标签核类簇为候选核类簇,将其与实体e的关联关系数量取值为阈值θ。
如图3所示,实体“马努”存在于两个标签核类簇中,即标签核类簇-马刺队和标签核类簇-城市。然而,由于实体“马努”与标签核类簇-城市中实体的关联关系数为0,小于其与标签核类簇-马刺队的关联关系数,即阈值θ,所以可判断实体“马努”与标签“城市”存在知识冲突。

图3 标签核类簇中的知识冲突Fig.3 Mistakes in label cluster
为了证明定义2具有普适性,本文对抽取结果中存在知识冲突的实体进行了关联统计。为体现出图中点的分布性,图中的关联系数取值为目标实体与各标签核类簇的关联关系数加上[0,1)中的一个随机值。
从图4可以看出,存在知识冲突的实体与正确的标签核类簇的关联系数往往大于错误的标签核类簇关联系数。此外,根据统计结果可以发现:能够与目标实体构成正确的实体-标签关系的标签核类簇,与目标实体具有最丰富的关联关系。

图4 存在知识冲突的实体与各标签核类簇关联系数的统计Fig.4 Statistics of association between mistaken entity labels and label cluster
3.2 知识推理验证
根据对抽取结果中标签核类簇的定义和知识冲突的定义,本文提出一种知识推理验证方案,基本思想如图5所示。
不难看出,图5实例中实体的别称存在错误的标签,将导致知识表示与推理不正确。针对该问题,我们首先通过本体约束规则推理实体与标签的语义关系;其次,利用知识冲突检测模型发现错误的实体-标签候选关系,最后通过基于关联度的知识推理验证方法完成对知识表达的推理与验证。算法1具体描述了基于关联度的知识推理验证方法,最终通过推理得出具有最丰富关联关系的核类簇为目标实体的正确标签核类簇。

图5 知识推理验证基本思想Fig.5 Process of knowledge inference and verification
算法1基于关联度的知识推理验证算法

算法描述:首先对于与目标实体e有关联的标签核类簇集S,依次对其中的实体进行遍历。当标签核类簇中的实体e与目标实体关系服从规则O,则计数器自加1,并且更新相对阈值θ代表与目标实体最大的关联度。最终目标实体属于最大关联度θ对应的标签核,之后利用其他本体规则补全目标实体在标签核中的关系。
4 实验部分
本文基于开放式信息抽取系统NELL进行算法性能评测,实验分为4个任务:第一个任务主要评测实体-标签型知识的推理验证结果;第二个任务主要评测实体-关系型知识的推理验证结果;第三个任务对实验结果进行综合评价与分析;第四个任务主要探究不同类型规则对推理模型性能的影响。实验流程如图6所示。

图6 实验流程图Fig.6 Flow chart of experiment
4.1 数据集
本文采用与参考文献[9,11]相同的数据集进行实验。数据集来自NELL系统第165次抽取结果,包含13类知识表达,共计10 000条数据。取其中5 000条作为训练数据,另外5 000作为测试数据。数据集所包含的知识关系类型以及本体约束关系如表3与表4所示。

表3 知识关系类型统计结果Table 3 Statistical results of knowledge relation types

表4 本体约束关系统计结果Table 4 Statistical results of ontology constraints
4.2 评测标准
本文采用召回率、准确率、F1等评价指标作为实验的评测标准。

表5 评价指标Table 5 Evaluation methods

4.3 实体-标签型知识推理验证结果
首先对实体-标签型知识的推理验证效果进行了比较分析。如图7所示,本文主要选取了其中6类标签做结果展示。其中NELL系统对自己的抽取结果做了一次测评,将其作为基准系统。此外,对比了MLN模型与传统PSL模型。不难看出,本文方法较3种对比方法在整体实验性能上更具优势。相对于MLN模型,本文方法在所有的标签上的验证效果整体提升了31.64%,说明对逻辑谓词采用连续值的软约束对于推理效果有很大提升。与PSL方法相比,本文方法整体提高了11.95%,其主要原因是基于关联度的推理方法在处理标签关系问题上有非常明显的优势。

图7 实体-标签型知识的推理验证结果Fig.7 Inference and verification results of entity-label relations
4.4 实体-关系型知识推理验证结果
对实体-关系型知识也做了比较实验,主要选取了5种不同类别的实体-关系进行实验,结果如图8所示。其中NELL的抽取结果最差,MLN实现了初步的知识推理验证,对于不同的标签类型它的验证效果差异比较大。本文方法与普通的基于实体解析的PSL方法的推理验证效果较优。与此同时,本文模型对于不同类型的实体-关系型知识的推理性能最为稳定。
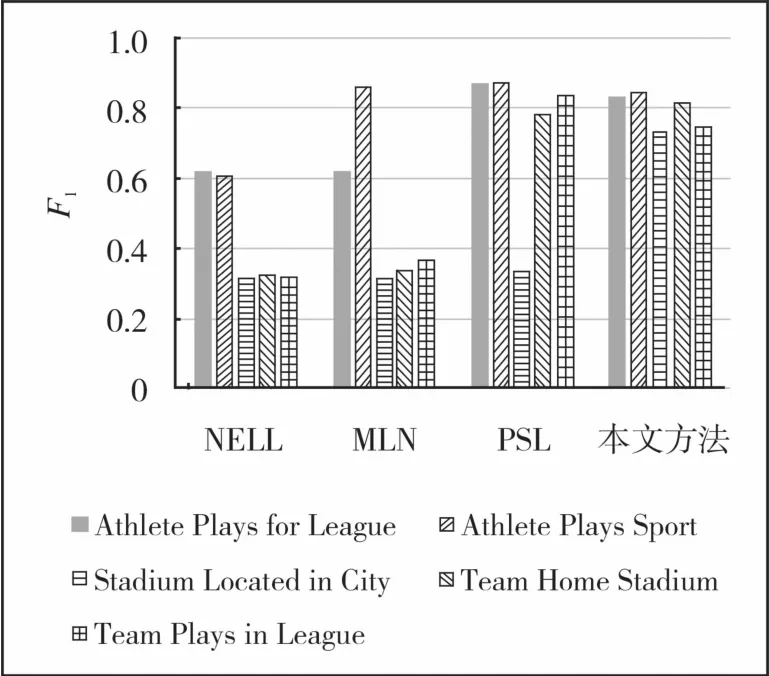
图8 实体-关系型知识的推理验证结果Fig.8 Inference and verification results of entity-relational knowledge
4.5 综合实验结果
最后,给出了对于实体-标签、实体-关系的综合评价结果,如表6所示。本文方法较传统PSL方法略差一点,主要原因是PSL模型中制定了一部分高质量的实体解析规则,这部分规则在推理验证中起了很重要的作用。但是,本文推理模型较传统的PSL模型节省了32条与实体解析相关的规则,使本文模型的推理速度得到了显著提升,并且验证结果也在比较理想的范围内。图9展示了算法的时间复杂度分析结果,不难看出,本文算法具有更高的推理效率。

图9 5 000条实例的推理耗时分析结果Fig.9 Inference time-consuming analysis results of 5 000 examples

表6 实体-标签型知识和实体-关系型知识综合实验结果Table 6 Experimental results of entity-label knowledge and entity-relational knowledge
4.6 不同类型规则对推理模型性能的影响
针对不同类型的推理规则,我们对20次迭代计算结果的精确度进行实验分析,结果如图10所示。其中,No Entity Resolution表示去掉与实体解析相关的规则,No Ontology表示去掉本体约束规则。不难看出,本文提出的方法即使不包含实体解析的相关规则也能取得比较好的推理验证效果。而PSL则不一样,去掉了实体解析的PSL模型由于实体的语义相似性约束不会在推理过程中发挥作用,导致其效果较差,进而说明了本文算法较基于传统PSL模型的推理方法具有更小的规则依赖成本。此外,实验结果表明无论是PSL还是本文模型都对本体约束规则较为敏感,说明本体约束规则在知识库推理验证工作中具有重要的作用。
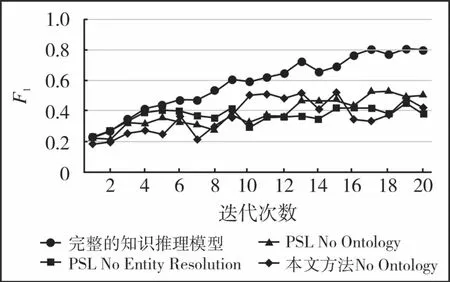
图10 不同的推理规则约束下的实验分析结果Fig.10 Inference results for different PSL rules
5 总结
开放式知识的推理验证是将知识纳入知识图谱中的重要工作基础,概率软逻辑模型在知识验证中的效果虽然很好,但是其需要人工构建规则,而且推理过程过于依赖实体解析,并且因此而增加的推理规则也会降低推理效率。本文提出了一种规则自动学习的知识推理模型验证方法,实现了规则自动学习,降低了推理验证的复杂度,提高了知识推理验证的效率。
在今后的工作中我们会进一步探究新的更具普适性的推理规则自动学习方法。另外我们还考虑将本体约束引入到Trans系列模型中,进一步研究新的推理模型在知识推理验证方面的方法与应用。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
哈哈画报(2021年10期)2021-02-28
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
37°女人(2017年11期)2017-11-14
制造业自动化(2017年2期)2017-03-20
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
