
恶意计算机程序基因形式化研究*
2019-11-12 09:37:26丁建伟陈周国刘义铭
网络安全与数据管理 2019年11期
丁建伟,陈周国,刘义铭
(中国电子科技集团公司第三十研究所 保密通信重点实验室,四川 成都 610041)
0 引言
近年来,随着云计算、大数据等技术的发展以及互联网基础设施的不断完善,大量的恶意计算机程序、应用、可执行代码等[1](以下统称“恶意程序”)在互联网间大肆传播,用以破坏宿主计算机、非法收集敏感数据、非授权登录等,给个人、企业以及政府部门带来了极大的困扰。
根据国家计算机网络应急技术处理协调中心2018年发布的《互联网网络安全态势综述》,中国全年计算机恶意程序传播次数日均达 500 万余次。根据全球第二大市场研究机构的调研报告,超过90%网络安全事件都涉及恶意软件的传播和影响。以“永恒之蓝”勒索软件的恶意传播影响分析,仅2018年因恶意软件引起的全球经济损失超过4 000亿美元。面对日益增长的恶意程序的威胁,学术界和产业界也开展了大量的恶意程序分析技术的研究和实践。
当前多数恶意程序分析方法是基于签名特征的分析方法,通过搜索和匹配未知样本中的特定模式、统计特征以及签名特征等,实现恶意程序的分析检测[2-3]。目前的反病毒软件通过收集和分析大规模的恶意程序样本的静态特征,不断更新自身的恶意程序特征库,实现恶意程序的检测与防御。但是,随着恶意程序的动态快速增长,恶意程序分析中的网络对抗也在不断升级,恶意程序的新型变种呈现爆发式增长,传统以静态特征匹配为基础的恶意程序分析方法受到极大的挑战[4-7]。
(1)加密、加壳、混淆等反分析、反编译的网络对抗技术不断发展,使得恶意程序的新型变种、多态越来越难以分析和检测。
(2)主流的恶意程序分析的静态特征以操作系统的系统调用行为和应用程序接口行为为主,涉及更多底层的原始操作行为,不能有效描绘。
(3)恶意程序特征库的建模和抽取以及恶意程序分析的方法的模型训练时间很长,对于新的恶意程序需要提取新的恶意程序特征用以检测。
针对以上恶意程序分析存在的调整,恶意程序分析从底层的恶意程序的本质特性出发,恶意程序基因技术被提出,用以应对恶意程序的动态快速增长。恶意程序基因受到生物基因技术的启发,从计算机程序体系结构入手,构建不同恶意程序行为的静态元素构成的恶意行为的动态特征表达。面对恶意程序底层的静态元素如何形式化建模,成为后续恶意程序基因萃取的关键。本文提出了一种恶意程序基因形式化的方法,可以有效解决目前恶意程序基因分析中的相似度计算的难题,本文的主要贡献有:(1)提出一种恶意程序基因的六元组形式化模型,能够有效完整地表达恶意程序基因的语义和行为信息;(2)针对恶意程序基因的形式化模型,提出了一种恶意程序基因相似度度量的方法,能够有效刻画和计算不同恶意程序基因间的相似程度;(3)基于以上形式化的方法,提出了一种恶意程序的检测方法,经过样本集合的对比测试,恶意程序基因的方法有更好的检测分类结果。
1 恶意程序基因的定义与符号约定
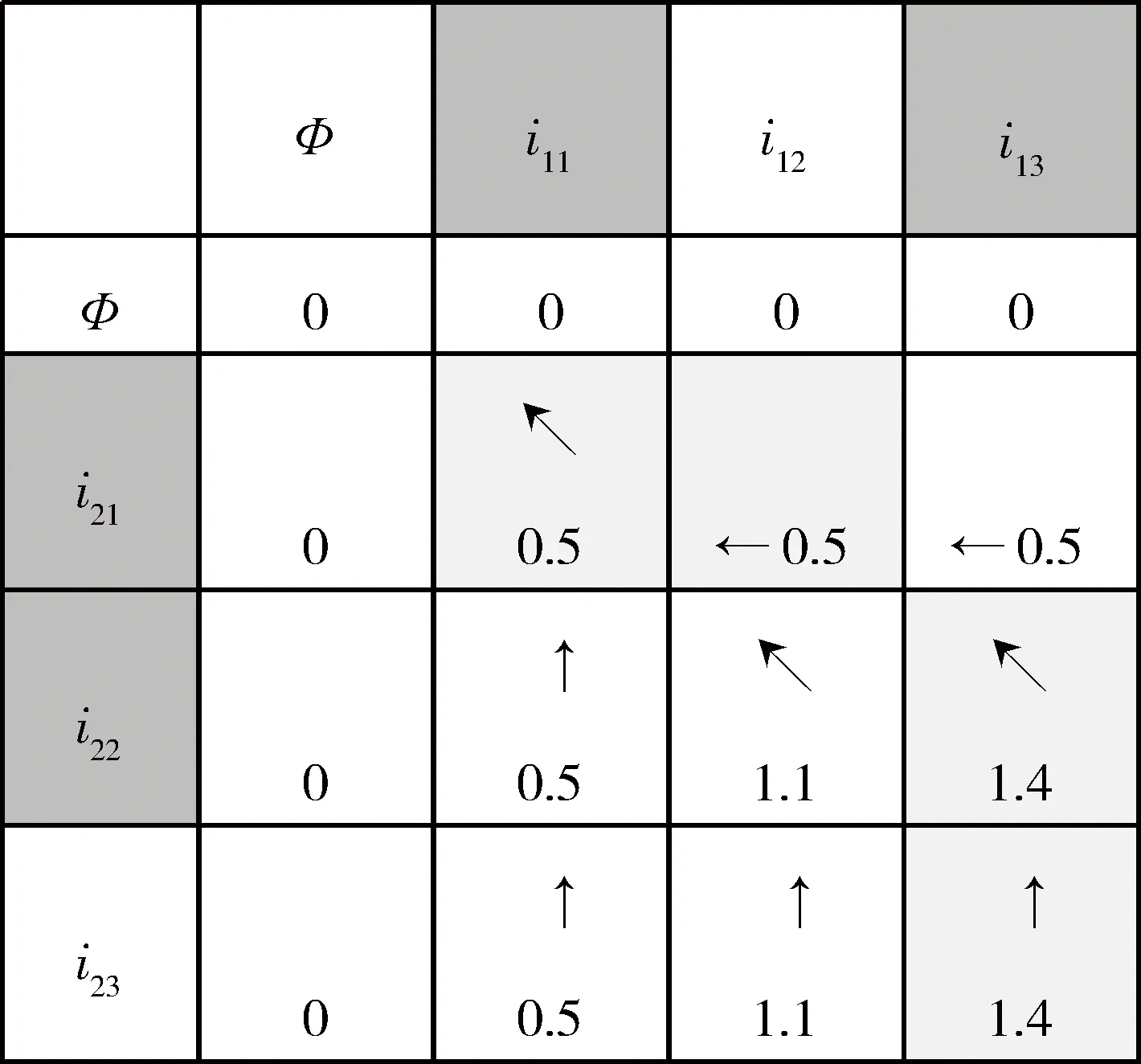
生物基因是一段用于表达生物特性的脱氧核糖核苷酸分子(DNA)组合序列片段,其中DNA是四种基本的生物大分子。类比于生物基因,从恶意程序的底层汇编指令角度,恶意程序的单个汇编指令类比于生物的单个生物DNA;汇编指令的执行序列类比于生物的DNA序列片段,用于语义表达恶意程序的行为或者功能。进一步地,恶意程序基因,即恶意程序的执行汇编指令序列的片段,对应恶意程序的某种行为或者功能。
针对恶意程序的汇编指令、恶意程序汇编指令序列以及恶意程序基因,为了后续形式化描述的统一性,本文采用通用的符号约定。本文定义,恶意程序采用符号M表示,从汇编指令层级,一个恶意程序的执行逻辑是由一组汇编指令序列组合完成的。一个汇编指令通过访问和改变计算机的内存和中央处理器(CPU)来完成相应基本功能。本文采用符号M、C和I分别表示计算机所有可能的内存状态、所有可能的CPU状态以及所有的汇编指令。特别地,每个汇编指令包含基本的操作数和操作码,一个汇编指令的执行语义可以看作是计算机状态的变换映射σ,即
σ:I×M×C→I×M×C
恶意程序的执行逻辑由一组汇编指令执行序列来表达语义,即M={i1,…,in},其中每一个汇编指令代表一个计算机状态迁移映射,即σP(il,ml,cl)=(il+1,ml+1,cl+1)。进一步,计算机程序执行的汇编指令集合是一个有限集合,本文针对恶意程序汇编指令集合标示唯一的整数编号,采用符号1,…,I标示。
进一步地,每一个恶意程序M在执行时对应一个汇编指令序列,即M={i1,…,in},这个序列,本文类比为恶意程序的DNA序列。为了对比不同恶意程序的相似程度,需要度量不同恶意程序的DNA序列的相似度。类比生物基因,本文把汇编指令称作恶意程序的DNA分子。为了有效度量恶意程序DNA序列相似度,本文针对汇编指令,即恶意程序的单个DNA分子进行形式化建模。
1.1 恶意程序DNA的形式化定义
计算两个恶意程序DNA序列的相似度,首先需要确定DNA分子,即汇编指令间的相似度度量算法。本文采用符号ii表示第i(i=1,…,I)个恶意程序的DNA分子,利用六元组记录一个汇编指令,即i=
根据汇编指令六元组
SimC=Similarity(
元素

表1 汇编指令六元组的形式化表示
SimB=Similarity(
SimS=Similarity(
根据汇编指令六元组
SimI=SimC×(λbSimB+λsSimS)
由于指令操作码包含了最高程度的语义信息,因此SimC作为公式的乘法因子。同时,公式需要满足如下要求:
λb+λs=1,1≥SimC≥0,1≥SimB≥0,1≥SimS≥0
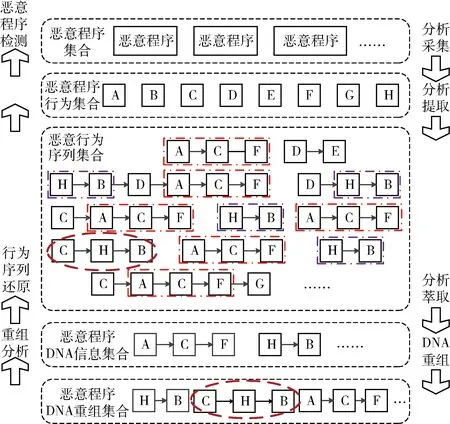
SimIE满足1≥SimIE≥0,描述了两条汇编指令间的语义、行为和结构的归一化相似度。
1.2 恶意程序DNA序列的形式化定义
恶意程序DNA序列,即汇编指令序列相似度度量算法采用双序列比对算法原理,计算两个汇编指令流对应的抽象编码序列的归一化相似度。双序列比对算法一般使用动态规划方法,用来从两个字符串或其他类似单元素序列中选出相似度最高的有序公共元素序列。
针对恶意程序DNA序列的相似度计算,假设有两个长度分别为N1和N2的指令序列,指令序号下标从1开始。其中M1=(i1,1,i1,2,…,i1,N1),M2=(i2,1,i2,2,…,i2,N2),定义序列相似度SimI(i,j)表示序列1的前i条汇编指令和序列2的前j条汇编指令的序列相似度,其计算公式如下:
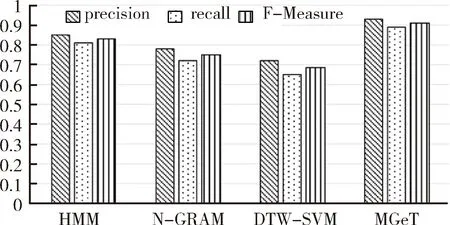
SimIES(i,0)=0, 0 (1) SimIES(0,j)=0, 0 (2) SimIES(i,j)= 0 0 (3) SimI(i,j)是对两个恶意程序DNA序列的非归一化全局序列相似度。为了对相似度进行归一化表示,并且能够计算两个恶意程序DNA序列的局部序列相似度。定义归一化的局部子序列相似度SimI(i1,i2,j1,j2)用以表示局部子序列(i1,i1,…,i1,j1)和局部子序列(i2,i2,…,i2,j2)的归一化相似度,其计算公式如下: cmpSimI(i1,i2,j1,j2)=SimI(i2,j2)-SimI(i1-1,j1-1) (4) MaxIESLen(i1,i2,j1,j2)=max(i2-i1+1,j2-j1+1) (5) (6) 其中,公式(4)计算了两个局部序列的非归一化相似度,公式(5)则选出了两个局部序列中最长的长度,通过公式(6)计算的局部子序列相似度可以保证归一化。要计算两条指令序列的归一化全局相似度,只需要计算SimI(1,N1,1,N2)即可。 根据SimI(i,j)计算公式可以绘制一个二维矩阵,i,j分别表示两个序列中汇编指令的下标。以N1=N2=3的两个恶意程序DNA序列为例,绘制的二维矩阵如图1所示。矩阵中每个单元格中,箭头表示局部路径继承选择方向,右下角的数值代表最大相似度SimI(i,j),浅灰格表示选定的子序列路径,深灰格表示选定的i。以图1为例,两条汇编指令流的相似度为: 图1 序列相似度比对矩阵示意图 本文针对一个恶意程序样本的样本集合,可以通过提取每个恶意程序运行时对应的汇编指令流序列i(即恶意程序DNA序列)。 一个恶意程序集合包含N个恶意程序样本,每个恶意程序对应一个恶意程序DNA序列。因此,该恶意程序样本集合对应一个恶意程序的DNA序列集合,表示为i∈IN×Q,其中表示有N个恶意程序DNA序列,每个DNA序列长度为Q,因为DNA序列长度是不定长度的,为了建模方便,统一为相同长度。 如图2所示,根据恶意程序基因的定义,恶意程序基因是具有相同行为或者功能的恶意程序DNA序列片段。 图2 恶意程序基因提取示意图 针对每一类恶意程序DNA行为序列,目标是提取每一类恶意程序DNA序列集合中K个相同的平凡子序列片段,即提取一个长度为L(L≪Q)的恶意程序DNA序列片段,即恶意程序基因序列,表示为GK×L。不同长度的序列之间的距离采用如下公式计算: (7) 其中Mn,k表示第n个恶意程序DNA序列与第k个恶意程序基因的距离,J=:Q-L+1。因此对于恶意程序基因序列的提取,转化成对于k个平凡子序列的计算,即: (8) 针对一组恶意程序的DNA序列组合,计算不同DNA序列之间的最长的平凡子序列(相同攻击行为基因),本项目采用最优化的方式,计算得到最优的恶意程序基因信息,计算公式如下: (9) 计算Fn针对变量W的偏微分使其等于0,即: 通过计算具有相同功能或者行为的恶意程序的DNA序列中相同的DNA序列片段,用于语义表达攻击行为,同时通过映射能够定位具体的攻击行为的汇编指令的位置、调用参数等,便于后续分析。 本文将恶意程序基因的提取方法应用到恶意程序的分类,与现有主流方法的分类结果作对比。本文采用的数据样本是恶意程序样本集合,一共包含恶意程序1 014例,被分为8类族群。 在实验中,本文采用了三种主流的分类方法作为基线对比方法: (1)HMM方法[8]:采用隐马尔可夫模型作用于恶意程序样本的系统调用图上,利用识别恶意程序不同行为的系统调用子图识别和检测不同类型的恶意程序。 (2)N-GRAM方法[9]:采用N-GRAM方法作用于恶意程序样本的系统调用图,利用识别N-GRAM的系统调用关系图,用以识别和检测不同类型的恶意程序。 (3)DTW-SVM方法:采用动态时间游走(DTW)计算两个恶意程序DNA序列的相似度;采用支持向量机分类方法识别与检测不同类型的恶意程序样本。 实验采用交叉验证,随机抽取80%的恶意程序样本用以训练,20%的恶意程序样本用以测试,反复训练与测试100次,计算平均的准确率(precision)、召回率(recall)以及F值(F-measure)用以评测方法,其中F值的计算是准确率与召回率的调和平均数,即: (10) 实验结果如图3所示,利用文本的MGeT方法在所有的评价参数上都取得了最优的结果。 图3 实验结果 进一步分析实验结果,分别采取20%、40%、60%以及80%的恶意程序样本数据规模,本文提出的恶意程序基因的形式化方法有较强的鲁棒性,能够提高恶意程序分类和检测效率。 本文从恶意程序的底层汇编指令入手,借鉴生物基因的提取思路,从操作语义、行为语义、结构语义三个维度形式化定义了单个汇编指令的形式化信息。进一步,采用序列匹配的建模方法,将恶意程序基因的形式化转化为恶意程序DNA序列的最平凡子序列的提取问题,通过剪枝的方法,实现不同行为或者功能的恶意程序基因的快速提取与形式化描述。通过实验证明,利用恶意程序基因的手段,能够很好地反映恶意程序的分类语义信息,提高恶意程序的识别效率。本文下一步的工作包括恶意程序基因的深度分类学习、恶意程序基因的语义映射、恶意程序追踪分析等。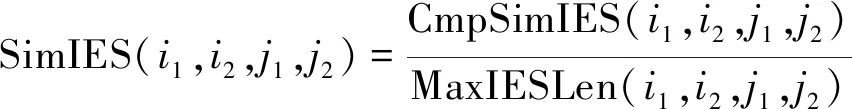
2 恶意程序基因形式化
2.1 恶意程序集合形式化
2.2 恶意程序基因形式化问题描述
2.3 恶意程序基因形式化推导
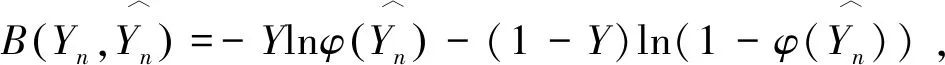
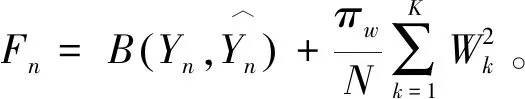
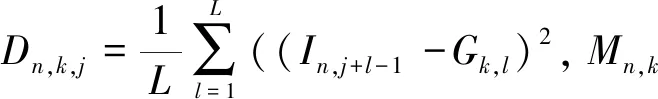
3 实验分析
3.1 对比方法
3.2 实验结果分析
4 结论
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02开放教育研究(2020年2期)2020-03-31 01:54:14数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38测控技术(2018年5期)2018-12-09 09:04:26电子测试(2018年18期)2018-11-14 02:30:34现代语文(2016年21期)2016-05-25 13:13:44中国学术期刊文摘(2016年1期)2016-02-13 14:05:23大连民族大学学报(2015年2期)2015-02-27 08:28:11
