
基于FPGA的CNN加速器设计与实现*
2019-11-12 09:08:32卿粼波何小海廖海鹏
网络安全与数据管理 2019年11期
窦 阳,卿粼波,何小海,廖海鹏
(四川大学 电子信息学院,四川 成都 610064)
0 引言
随着人工智能和大数据时代的到来,卷积神经网络(Convolutional Neural Network,CNN)的受关注度越来越高。卷积神经网络是一种多层神经网络,在图像分类、机器视觉和视频监控等领域具有重要的应用价值和研究意义[1]。CNN由于其庞大的计算需求,同时受制于CPU的串行处理方式,目前CNN的软件实现方式效率并不高,难以满足许多实时应用的需求[2]。于是,基于GPU、ASIC、FPGA的不同加速器被相继提出以提升CNN的设计性能[3]。
目前卷积神经网络的硬件实现主要集中于基于图形处理器(GPU)的加速。基于GPU的卷积神经网络能够很好地实现硬件与软件部分的结合,使得神经网络的训练得到很好的加速。然而GPU的电力消耗巨大,其硬件结构固定,限制了卷积神经网络在移动式系统的应用[4]。与GPU相比,ASIC芯片具有功耗低、体积小、计算性能高的特点,也可以实现对CNN的加速训练。但ASIC芯片开发周期较长,灵活性极低,研发成本极高,使得它不适合搭载结构灵活的卷积神经网络[5]。FPGA是一种可自定义编程的硬件电路结构,其具有强大的并行运算能力,契合了CNN的计算特点,灵活的设计方法也适合于神经网络多变的网络结构,除此之外,它还具有较低的功耗[6]。因此采用FPGA实现CNN的加速具有广阔的应用前景。
针对卷积神经网络计算在硬件平台的加速,本文以设计的卷积神经网络算法DoNet为网络模型,提出了一种基于FPGA的CNN加速器设计与实现方法。首先,本文采用定点量化的方法降低了网络计算所需的存储和计算资源[7];其次,运用Vivado HLS分别将各层网络编译生成IP核,随后在Vivado中对各层IP核进行硬件集成,实现每层全并行的计算效率;最后,以Minist手写数据集作为测试集,对该加速器性能进行评估分析。
1 卷积神经网络
本文设计目的是在FPGA平台实现对轻量级卷积神经网络的加速,完成对Minist手写数据集的识别。实现方法是运用Vivado HLS分别将各层网络编译生成IP核,然后在Vivado中对各层IP核进行硬件集成。
1.1 设计的DoNet网络结构
LeNet作为识别Minist数据集的经典卷积神经网络,其识别准确率可达98.5%,但其权重参数总量达431 080个以上,很消耗片上资源。因此本文以LeNet为基础,设计了一种轻量级卷积神经网络DoNet,以降低权重参数量,节省FPGA片上资源消耗。DoNet网络结构如图1所示,该卷积神经网络主要包括了输入层、卷积层、池化层、全连接层以及分类层。网络的输入为28×28×1像素大小图片,输入图像依次经过conv1、pool1、conv2、pool2、conv3、pool3、inner1、relu1、inner2层后,得到10个特征值,然后在softmax分类层中将10个特征值概率归一化得出最大概率值即为分类结果。网络中的具体参数设置如表1所示。

图1 CNN网络结构图
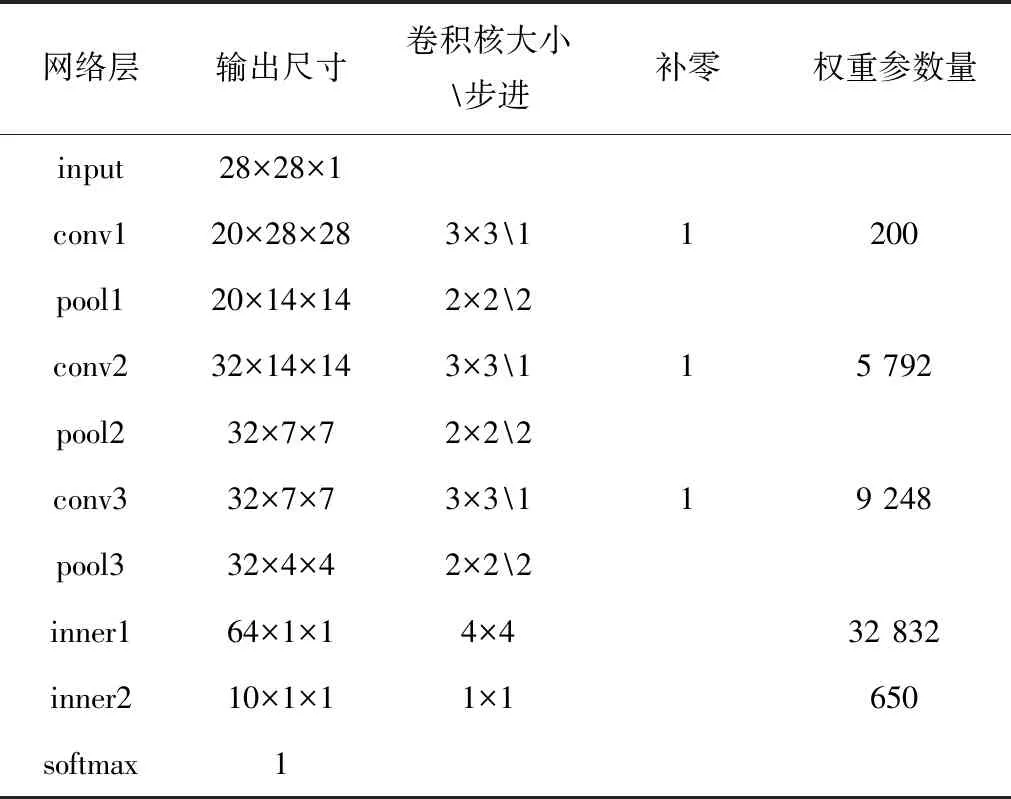
表1 网络参数表
由表1可以计算出,该CNN网络总共的权重参数量为200+5 792+9 248+32 832+650=48 722。将该网络在软件平台中进行训练和测试,得到其对Minist数据集的识别准确率为98%。与LeNet相比,其权重参数量是LeNet的1/9,识别准确率比LeNet下降了0.5个百分点,在减少参数量和维持识别准确率之间,DoNet达到了很好的平衡。
1.2 HLS工具介绍
高层次综合工具(High-Level Synthesis tool,HLS)是Xilinx在2012年发布的一套集成于Vivado开发环境的开发工具,主要用于可编程逻辑器件的设计和开发。使用HLS设计工具,用户可以选择多种不同的高级语言(如C,C++,System C)来进行FPGA的设计,通过仿真、优化及综合等步骤就可以以RTL代码的形式输出,既可以是网表形式,也可以导出为Xilinx的IP核。引入HLS设计工具,在代码生成时可以快速优化FPGA硬件结构,提高执行效率,降低开发难度,在开发过程中可以快速验证和修改算法,及时查看算法的实际效果,缩短开发周期[8]。
1.3 基于FPGA的加速器框架
本文运用HLS将DoNet网络的每层运算过程分解为单个的IP核进行编写,然后通过Vivado将各层的IP核进行硬件集成,整体的加速器硬件实现框架如图2所示。
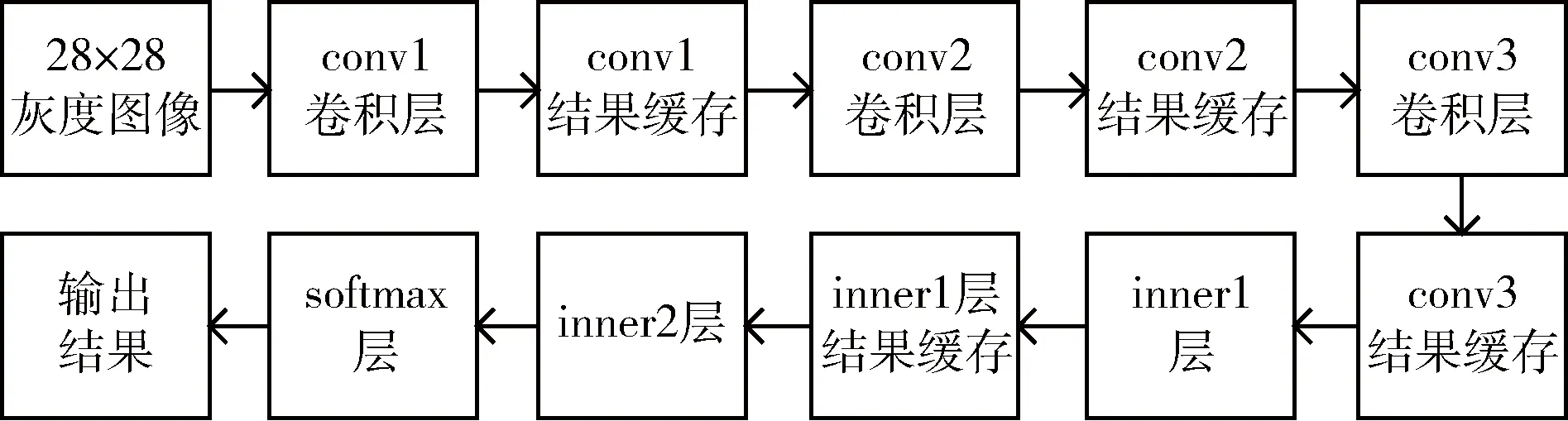
图2 加速器硬件实现框图
由图2可以看出,其中每一层计算出结果后将计算结果暂存,作为下一层的输入。层与层之间只能顺序执行,只有上一层计算过程结束,全部结果缓存完毕才能送入下一层进行运算。因此若要达到加速的目的,必须在每一层单独运算时,充分利用计算中的并行性。
2 加速器硬件实现
本文设计的加速器首先将浮点型参数定点量化为定点数,节省硬件资源;然后充分利用卷积计算中的并行性,分别对各层卷积运算进行并行设计,以使各个卷积层达到全并行的计算效率。
2.1 定点量化
从模型中提取出的权值参数均为浮点型,网络计算过程中的特征图结果也为浮点数。在FPGA中实现浮点数的运算复杂度较高,并且会耗费大量的硬件资源,因此本文对每层权值参数采用乘以65 536处理,将网络参数从64位浮点数转化为16位定点数。以单独综合的conv1层的IP核为例,计算的数据采用浮点数类型和定点数类型时的资源和时间对比如表2所示。

表2 conv1层定点量化前后资源和时间对比
表2中BRAM_18K为FPGA的片内存储资源,DSP48E为FPGA内部可用于计算的DSP资源,Latency为使用HLS综合生成IP核后预计运行所需时钟周期。由表2可看出,将网络参数采用数据量化处理后,使存储网络所需的存储空间和硬件实现所需的计算时间都得到了降低。
2.2 卷积层模块的硬件实现
本文设计的卷积层模块包含conv1、conv2、conv3三个卷积层以及各自所对应的池化层。以conv2层计算为例,其硬件实现框图如图3所示,该卷积层输入多张特征图及其对应系数,分别经过乘累加运算后得到一组卷积结果,将该组卷积结果相加后,经过池化后得到一个输出特征图,然后结果经过缓存,输出到下一个卷积层。可以看到多个特征图计算并行,从结构层面实现了对卷积神经网络的并行加速。conv1、conv3卷积层的计算与conv2层类似,在此不再描述。
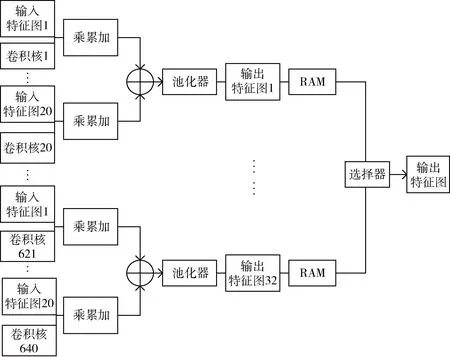
图3 conv2层硬件实现框图
由于卷积层模块中的conv2层计算需要输入20张特征图,输出32张特征图;conv3层计算需要输入32张特征图,输出32张特征图。考虑到芯片资源有限,并未将输入特征图采用并行方式同时输入计算,而是串行输入,所以每一个卷积层计算完成后,将输出特征图并行输入至各自的RAM中暂存,然后再通过自行编写的选择器将RAM中的特征图串行输出至下一层。
综合以上4种情况,在最坏情况下是7-点关联着(3,3,7)-面,3面及面上的点最多从7-点拿走的权值为称之为最坏3-面7-点情形。
2.3 全连接层与分类层的硬件实现
全连接层的硬件实现过程与前面卷积层类似,只是由于inner1的输出结果仅为1个值,因此在inner缓存模块不再使用单独的RAM来存储计算结果,而是直接采用一个选择器输出结果,这里不再详细介绍。softmax层硬件实现框图如图4所示。
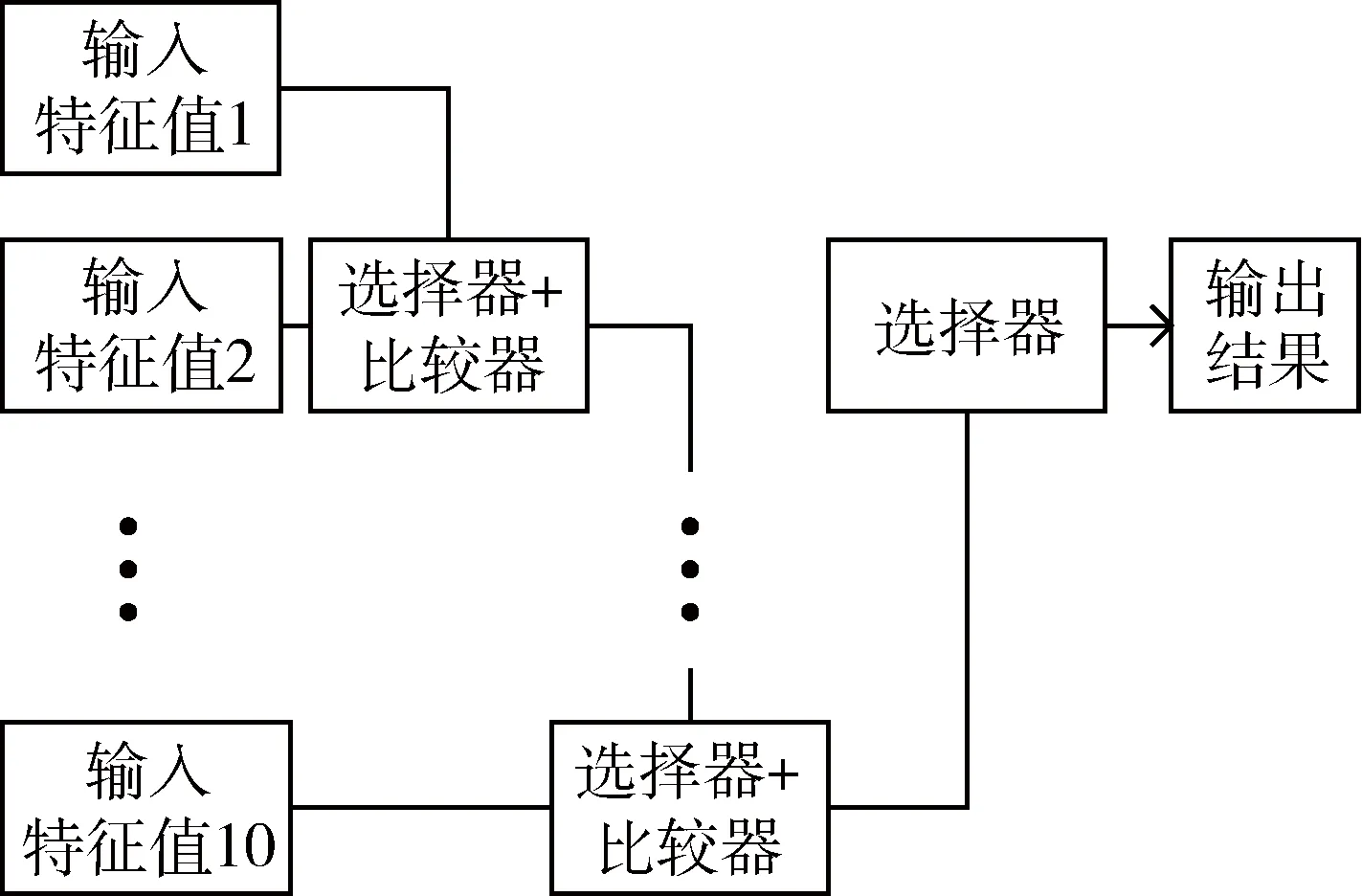
图4 softmax层硬件实现框图
由图4可看出,10个输入特征值同时输入到softmax层。首先根据比较器和选择器的结果可以选择较大值输出,接着继续往下比较。10个特征值依次比较之后通过一个选择器模块输出其中的最大值,这便是加速器识别的结果。
2.4 加速器各层资源和时间分析
对单层IP核综合后可看到分析结果,conv1层的单个IP核进行编译占用的资源以及运行时间如表3所示。

表3 conv1层的资源和时间消耗
由图1的CNN网络结构可知,conv1层输出为20张特征图。如果conv1层进行全并行运算,需要20个conv1层的IP核同时运行。因此conv1层需要的具体硬件资源应该在表3的数值上乘以20才为该层最后消耗的资源。因为可以达到全并行,所以conv1层计算所需全部时钟周期便为6 163个,由于一个时钟周期为10 ns,即conv1层计算所需时间为61 630 ns。其余各层单个IP核编译占用的资源和运行时间与conv1层类似,这里不再详细描述。
conv2层、conv3层、inner层与softmax层综合编译后单个IP核的资源消耗与时间周期如表4所示。
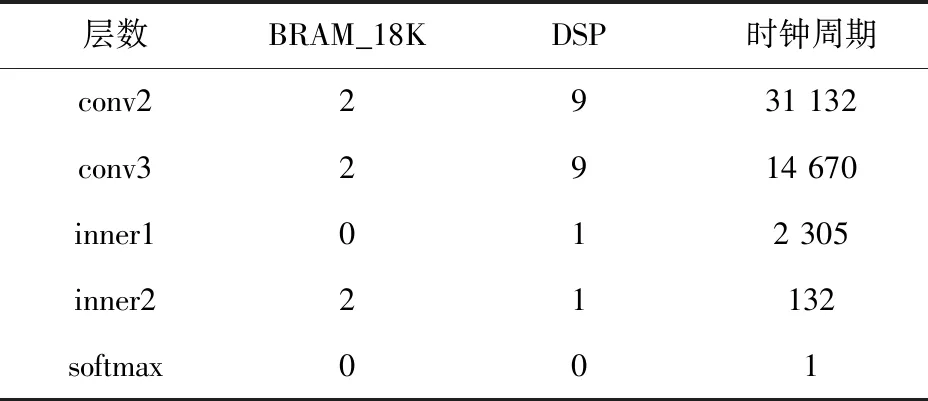
表4 conv2、conv3、inner、softmax的资源和时间消耗
以上为本文选取的CNN结构中每一层IP核编译后的资源消耗和时钟周期,结合各层资源以及CNN网络结构图可以预估出DSP总数为27×20+9×32+9×32+1×64 =1 180,本文选择的VC707开发板的主芯片上DSP资源总数为2 800个,因此DSP的资源数满足设计需求。同理也可计算出其他资源都在芯片的可用范围内。加速器计算所消耗的时钟周期大致为各层时钟周期之和即为54 403,在100 MHz的时钟运行频率下,可计算出预计运行时间为0.544 ms。
经过前面的设计已经将加速器设计进行了硬件实现,接着将综合生成的程序下载到FPGA开发板上运行并进行实际测试。为了准确测试程序运行时间,在程序里添加了计时器来进行计数。采用Vivado自带的debug功能进行波形的实时抓取,抓取的波形如图5所示。
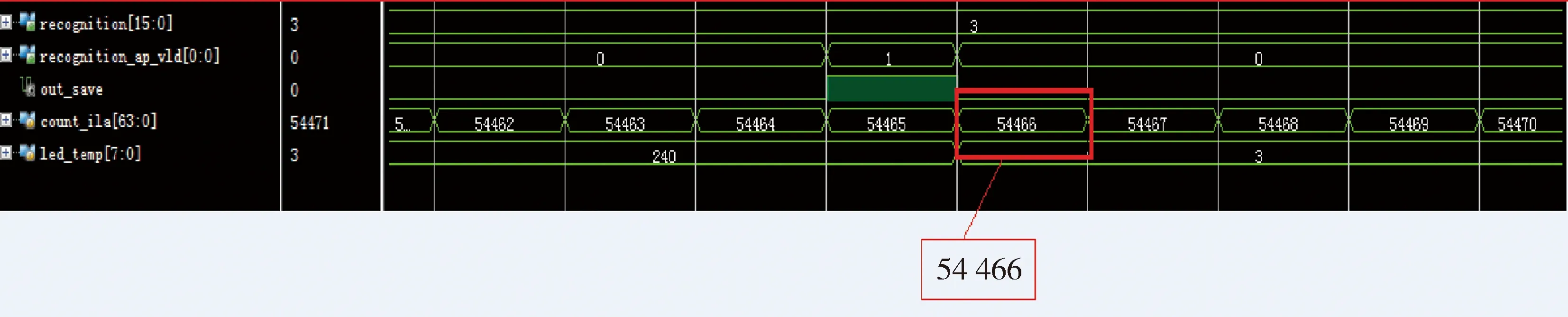
图5 运行时波形实时抓取图
由图5可以看到FPGA在实际运行时的结果情况,在计数器为54 466时输出正确的分类结果数字3,该结果与加速器所有IP核的时钟周期之和基本一致,证明程序确实达到了全并行的计算效率。
3 实验结果
本节对加速器测试方案进行总体设计,对加速器的测试性能包括识别准确率、计算时间和运行功耗,并将其性能与CPU、GPU进行对比。其中CPU型号为Intel core i7-6700K,主频为4 GHz;GPU型号为NVIDA公司的GTX1080Ti系列,显存容量为11 GB;FPGA平台为Xilinx公司的VC707开发板。
3.1 测试方案设计
本节采用PC+FPGA的架构对加速器测试方案进行设计,完成将PC传输的图片数据通过FPGA端的CNN加速器进行图片识别。主要测试指标为图片识别准确率、加速器运行的时间和功耗。测试方案框图如图6所示。
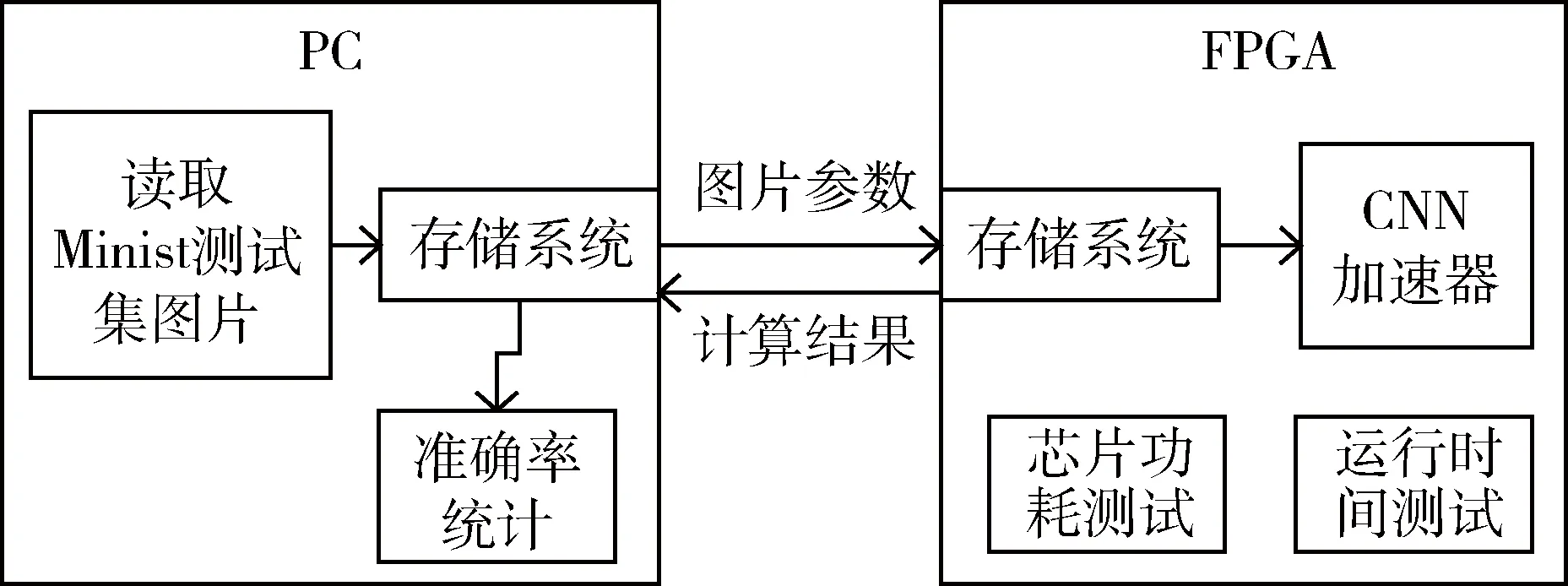
图6 测试方案框图
3.2 准确率测试
PC端批量将图片数据发往FPGA端,然后批量接收FPGA端返回的信息。Minist数据集的测试图片共分为10类,每类1 000张图片[9]。测试中分别将每类图片依次发送至FPGA端进行识别,并统计该类型的平均识别率,最终得到整个测试集的平均识别率,以此作为加速器的准确率性能。加速器在CPU、GPU、FPGA平台上的识别准确率统计如表5所示。

表5 各平台识别准确率统计
由表5可看出,Minist数据集在FPGA端的识别准确率比在CPU、GPU上的低。原因在于本文设计的加速器采用定点量化进行参数压缩,由定点量化引入了识别误差。本文将定点量化后的参数代替原有参数在CPU上进行测试,得到其对Minist数据集的识别准确率为95%。即由定点量化引入的准确率误差为3个百分点。将网络结构在FPGA端实现,识别准确率依然为95%,说明硬件实现并未引入新的识别精度下降。
3.3 计算时间对比
通过在FPGA程序中添加计数器进行时间统计,该计数器在FPGA端接收完毕单张图片的所有数据后,启动CNN计数单元开始计数,在计数完毕时的值即为加速器计算所需的时钟周期。本文使用的DoNet网络在CPU、GPU、FPGA平台上的计算时间对比如表6所示。

表6 各平台运行时间对比
由表6可以知道,本文设计的CNN加速器除了与服务器级别的GPU相比计算时间稍有逊色之外,相较于CPU达到了7.8倍的加速效果。
3.4 芯片功耗测试
在Vivado中将FPGA端程序设计完毕后,进行程序综合和布局布线,在布局布线完成以后在芯片电源报告中可以得到芯片的运行功耗结果。DoNet网络在CPU、GPU、FPGA平台上的运行功耗对比如表7所示。

表7 各平台功耗性能对比
由表7可以看出,加速器在FPGA芯片的运行功耗仅为CPU和GPU的4.6%左右,而FPGA比CPU计算性能更高。
4 结论
本文设计了一种基于FPGA的CNN加速器。首先,采用定点量化的方法对设计的网络的参数进行了压缩;其次,运用HLS对网络的每层运算过程进行编写,生成了各自独立的IP核;最后,将各层的IP核进行硬件集成,充分利用每层网络计算中的并行性,实现每层全并行的计算效率。实验表明,本文设计的CNN加速器运行时间比CPU降低很多,运行时的功耗比GPU降低很多,很好地完成了在低功耗应用中对卷积神经网络加速的功能。
猜你喜欢
故事作文·高年级(2024年5期)2024-06-04 23:39:22
高中数理化(2024年8期)2024-04-24 16:58:14
少先队活动(2021年6期)2021-07-22 08:44:24
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
个人电脑(2016年12期)2017-02-13 15:24:40
电子制作(2016年19期)2016-08-24 07:49:54
少年博览·小学低年级(2016年5期)2016-05-14 11:59:03
