
A Novel Shilling Attack Detection Model Based on Particle Filter and Gravitation
2019-11-07 05:16LingtaoQiHaipingHuangFengLiRezaMalekianRuchuanWang
China Communications 2019年10期
Lingtao Qi,Haiping Huang,4,*,Feng Li,Reza Malekian,Ruchuan Wang
1 College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
2 Jiangsu High Technology Research Key Laboratory for Wireless Sensor Networks,Nanjing 210003,China
3 “Broadband Wireless Communication and Sensor Network Technology” Key Lab of Ministry of Education,NUPT,Nanjing 210003,China
4 College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
5 Department of Computer Science and Media Technology,Malmö University,Malmö,20506,Sweden
Abstract: With the rapid development of e-commerce,the security issues of collaborative filtering recommender systems have been widely investigated.Malicious users can benefit from injecting a great quantities of fake profiles into recommender systems to manipulate recommendation results.As one of the most important attack methods in recommender systems,the shilling attack has been paid considerable attention,especially to its model and the way to detect it.Among them,the loose version of Group Shilling Attack Generation Algorithm (GSAGenl)has outstanding performance.It can be immune to some PCC (Pearson Correlation Coefficient)-based detectors due to the nature of anti-Pearson correlation.In order to overcome the vulnerabilities caused by GSAGenl,a gravitation-based detection model (GBDM)is presented,integrated with a sophisticated gravitational detector and a decider.And meanwhile two new basic attributes and a particle filter algorithm are used for tracking prediction.And then,whether an attack occurs can be judged according to the law of universal gravitation in decision-making.The detection performances of GBDM,HHT-SVM,UnRAP,AP-UnRAP Semi-SAD,SVM-TIA and PCA-P are compared and evaluated.And simulation results show the effectiveness and availability of GBDM.
Keywords: shilling attack detection model; collaborative filtering recommender systems; gravitation-based detection model; particle filter algorithm
I.INTRODUCTION
As the development of big data technology,recommender systems based on the collaborative filtering [1] are widely used in mobile Internet business (e.g.Taobao),social networking (e.g.Facebook),search engines (e.g.Google)and movie video recommendation sites (e.g.YouTube)[2].However,due to openness and anonymity of collaborative filtering recommendation systems,malicious users probably inject a large number of fake profiles into the recommender system to manipulate the recommendation results [3],and this kind of behavior is called "shilling attack".The user profiles record users' ratings data of various items,and these rating data indicate users' preferences,where the false user profile is possibly the attacked profile [4].Shilling attack aims to facilitate target products recommended to real users,i.e.push attack [5],or hinder target products recommended to real users,i.e.nuke attack.Reliable evaluation mechanism on items should be established based on real users' preferences,which is also the foundation of collaborative filtering recommender systems.The real profile is likely to reveal true intention of the user,and meanwhile it can offer the effective recommendations for their neighboring users [6].Therefore,how to detect and resist the shilling attack has become a concern of recommender systems.
Currently,shilling attack can be organized and carried out based on two models [7]: the single attack model and the group attack model.The single attack model is easy to be recognized by the detector for the reason that it usually launches a single shilling attack,and its influence on recommendation systems is inadequate due to the inherent defects of those single attack methods.Bhebe and Kogeda [8] achieved a series of meta-learning algorithms to effectively detect the common single shilling attack.However,Wang et al.[9] proposed a group attack modelGSAGenlfor shilling attackers,the model strengthens the organization form of attacks and makes any two single attacks in the same group lack of relevance in order to rationalize the rating series of target items.Most of detectors based on Pearson correlation coefficient (PCC)fail to detect the attacks fromGSAGenlmodel,and meanwhile theGSAGenlmodel is effective to reduce the probability of being detected by some special algorithms such as C4.5 algorithm [10].
From another perspective,actually,current detection methods are not perfect,especially when facing with diversified attacks or well-designed group attacks,the detection accuracy of recommend systems will decline.This is because these well-planned attacks will be probably immune to the similarity detection from PCC-based detectors.Although Yi et al.[11] found out the PCA (Principal Component Analysis)detection algorithm proposed by Mehta and Nejdl [12] can be used to deal with the group attack model,this algorithm must predetermine the ratio of attacked profile,and it cannot ensure the successful rate of detection on lower filler size group attacks.Once a new group attack model appears,it will probably degrade the desired performance of prevalent detectors.
Aiming at these challenging problems,the main contributions of this paper can be summarized as follows:
(1)A gravitation-based detection model (GBDM)is designed,and it abandons PCC and introduces the particle filter algorithm which is the first time applied to the shilling attack detection.This model can also achieve online detection by using novel detection attributes to describe injection profiles,and these attributes can intuitively display the anomalies of the recommender system.
(2)Based on the experimental tests in MovieLens and Amazon data sets,we compare the detector based on GBDM with that of HHTSVM,UnRAP,AP-UnRAP,Semi-SAD,SVMTIA and PCA-A,and our proposal achieves the best detection performance.
The rest of this paper is organized as follows.Section 2 reviews the related work about shilling attack methods and detection algorithms.Section 3 presents the GBDM model in order to addressing the challenging problems caused byGSAGenl.Experiment results and performance analysis are discussed in section 4.And we conclude our work in section 5.
II.RELATED WORK
2.1 Shilling attack methods
The intention of attack model is to create the fake user profile by forging or tampering the user data and items' ratings in recommender systems [13],where the fake profile is quantified intongroups of score vectors,as shown in Figure 1.To clearly describe the attack model,generally,the shilling attack vectors are divided into four parts: the target items (it),the selected items (IS),the filler items (IF)and the unrated items (Iφ).
Shilling attack models are mainly comprised of the following categories: the random attack,the average attack,the bandwagon attack and the segment attack,as show in Table 1,where the target item usually has the highest rating when encountering a push attack,or has the lowest rating when suffering a nuke attack.In the random attack,the injected profiles are filled with random rating values obeying the normal distribution.And meanwhile the normal distribution is determined by the mean and standard deviation of real rating values in the recommender database.All these items involved in the attacked profiles are called as “filler items”.In order to make attacked profiles to be more similar as real profiles,the average attack assigns the mean rating of some certain kinds of items to randomly chosen filler items and the highest (or lowest)rating to the target item corresponded to the push (or nuke)attacks.The bandwagon attack [14] is one of the evolution forms of random attack,and it adopts the Zipf's Law where only a small number of items arouse most of users' attention.In bandwagon attack,an attacker generates the profiles with high ratings to well-known popular items and the highest rating to the target item as far as possible.The attacker usually makes the popular items as selected items,and the prevalence of selected items are commonly measured by the number of scoring.The segment attack selects these special users who are interested in a specific item segment (e.g.,swimmers pay more attention to goggles).The segment attack offers the highest rating to the target item and item segment while the lowest rating to filler items.
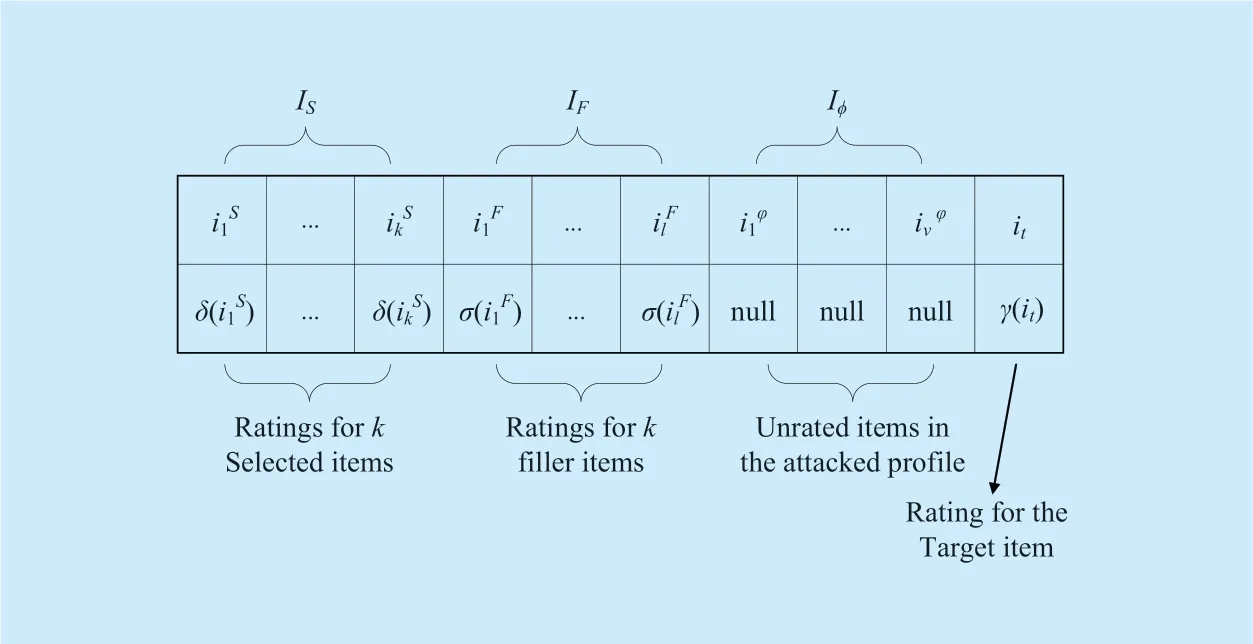
Fig.1.The model of shilling attacks.
However,as the development of shilling attack detectors,it is more difficult to successfully promote (or suppress)the target product with single shilling attacks.Therefore,group shilling attacks [15] are gaining more popularity,which are different from traditional attacks.Based on the observation that the attacked profiles with low similarity are difficult to be discovered by traditional detectors,Wang et al.proposedGSAGenlmodel to generate shilling attack group in which each pair of attacked profiles has high diversity.This model can effectively avoid the detection by the traditional methods and has a great negative influence on recommender systems.
2.2 The detector algorithms
The increasing threats from shilling attacks force all kinds of detection algorithms to strengthen the robustness and security of recommendation system [16].The essence of the detection algorithm is to distinguish those attacked users from the real users.According to the degree of dependence on preliminary knowledge,the detection algorithms may be classified into the supervised learning algorithm,the unsupervised learning algorithm and the semi-supervised learning one,which have their respective advantages and disadvantages.
The supervised learning detector usually has the deep reliance on training sets due to the use of the predefined data features,so it sometimes lacks of the availability especially using the SVM (Support Vector Machine)or the decision tree methods which cannot support the incremental training.If we want to improve the accuracy of supervised learning detector,the frequent updating of training sets is necessary,and consequently the complexity is also increased.In order to effectively detect the attacked profiles,or eliminate the influence of attacked profiles on recommendation systems,Morid et al.[17] proposed a supervised detection algorithm,which is absorbed in detecting the influential users by extracting their data features and finally achieving "kNN classification".This detection algorithm is effective to the bandwagon attack and the lower filler size attacked profiles,but usually fails to the unknown attacks or group attacks.Zhang and Zhou [18] described a supervised learning detector based on HHT (Hilbert-Huang transform)-SVM,which designs some new detecting attributes applied to the feature extraction and profile inspection.This algorithm enhances the detection accuracy compared with the traditional SVM algorithms,and it can be used to deal with the overtime injection of attacked profile.Zhou et al.[19] put forward a two phase detecting method SVM-TIA.In the first phase,Borderline-SMOTE algorithm is used to alleviate the unbalance problem of classification,and a rough detecting result is obtained in this phase; the second phase is a fine-tuning phase where the target items in the potential attacked profiles are analyzed.However,once the new shilling attacks generated,the SVM classifier must be trained off-line,which indicates the availability of this detector needs further improvement.Actually,incremental support vector learning has been investigated,based on which,some online algorithms are proposed for trainingv-support vector classification [20].However,these algorithms have not been verified their effectiveness to identify attacked profiles in recommender systems.
The unsupervised learning detector [21] has commendable detection performance,which can be executed based on clustered data sets.However,many unsupervised learning detectors prefer to use PCC,which requires the rating data undergoing shilling attacks have a great similarity,so the accuracy of this detector depends on whether the requirement is met.Bryan et al.[22] suggested an unsupervised learning detector UnRAP (Unsupervised Retrieval of Attack Profiles),which employs a comprehensive evaluation of the Hv-scoremetric.This detector can detect some unknown shilling attacks without beforehand acquiring any parameters associated with these attacks,and only utilizing the difference between the attacked profiles and the scoring matrices.However,this detector cannot obtain the satis-factory detection performance under the lower filler size attacked profiles and the bandwagon attacked profiles.Wang et al.[23] present the AP-UnRAP detection algorithm based on the unsupervised learning detector UnRAP,which can suppress group attacks to some extent,through comparing and analyzing the features of every single attack behavior,finally clustering these single attack behaviors into a certain attack group.However,when facing with the bandwagon attack,its detection performance is not as good as UnRAP algorithm.Deng et al.[24] proposed an unsupervised shilling attack detection algorithm which combines PCA and perturbation (a.b.PCA-P).Wherein PCA is applied before and after inserting Gaussian noise to each user profile.Shilling attacks are detected by combining the results from the twice utilization of PCA.Compared with using PCA alone,PCA-P achieves higher detection accuracy.

Table I.The categories and modes of shilling attacks.
The detector of semi-supervised learning combines the advantage of supervised learning and that of unsupervised learning,and it conducts the training based on a small amount of labeled samples and the classifying based on a lot of unlabeled samples.However,how to determine the minimum quantity of required labeled samples according to different scenarios has already been the obstacle to achieve an effective detection.And previous studies have shown that an inappropriate semi-supervised learning detector may lead to an obvious degrading of machine learning generalization ability.Wu et al.[25] designed a semi-unsupervised detection algorithm Semi-SAD (Semi Shilling Attack Detection),which learns from both labeled and unlabeled user profiles based on the combination of naive Bayes classifier and EM-λalgorithm.It first trains a naive Bayes classifier on a small set of labeled users,and then classifies unlabeled users with EM-λalgorithm to improve the initial naive Bayes classifier.Though Semi-SAD can obtain a desirable accuracy in most instances,its detection effect is unstable in the face of the hybrid sample attack.
Apart from the above three kinds of methods,other detection algorithms have also been proposed.For example,Tang et al.[26] concluded that most current algorithms focus on the data feature analysis of users' scores,which results in the one-sided trend when designing detectors.They take the rating time intervals into consideration,conduct the reliable data removal in abnormal rating time intervals,and then suggest an attack detection algorithm based on Time SFM (Span Frequency Mount)Factor which reflects the characteristics of time intervals in recommender systems.It can more effectively prevent the target items' interference with the real top-N recommendation lists for users.However,when this algorithm encounters the lower filler size attacked profiles,its detection effect is not prominent.Zhou et al.[27] proposed TS-TIA for detecting suspicious ratings by constructing multi-dimension time series.They reorganize all ratings on each item sorted by time series,each time series is examined and suspicious rating segments are checked.And then both statistical metrics and target item analysis are used to detect shilling attacks in these anomaly rating segments.Although this method can effectively detect items under attacks,fake profiles has not been exactly located.
Above all,there exist some defects in current detectors such as the dependence on preliminary knowledge,the requirement for rating data similarity and the vulnerability from lower filler size attacks.In this paper,the proposed detector based on GBDM would devote to address these problems.
III.GRAVITATION-BASED DETECTION MODEL (GBDM)
As mentioned above,GSAGenlachieves immunity to the detection algorithms based on PCC and the time sequence,which makes most of detectors invalid.To address this problem,we put forward a gravitation-based detection model (GBDM),which no longer uses PCC and can provide satisfactory detecting services for recommender systems.
3.1 The detector model
GBDM is composed of the feature extraction module,the tracking predictor module and the judging module,and their respective function description is shown in Figure 2.The feature extraction module devotes itself to detecting the related attributes and extracting the abnormal data.The tracking predictor module is responsible for tracking the abnormal data and making the probability prediction.The predictive results are returned to the judging module,which determines whether the abnormal data are from malicious users.
Based on this model,we will put forward two new basic detection attributes,which improve the performance of the target model focus (TMF)detector and provide with an easier way to extract the basic features of group attacks.The tracking predictor will adopt the
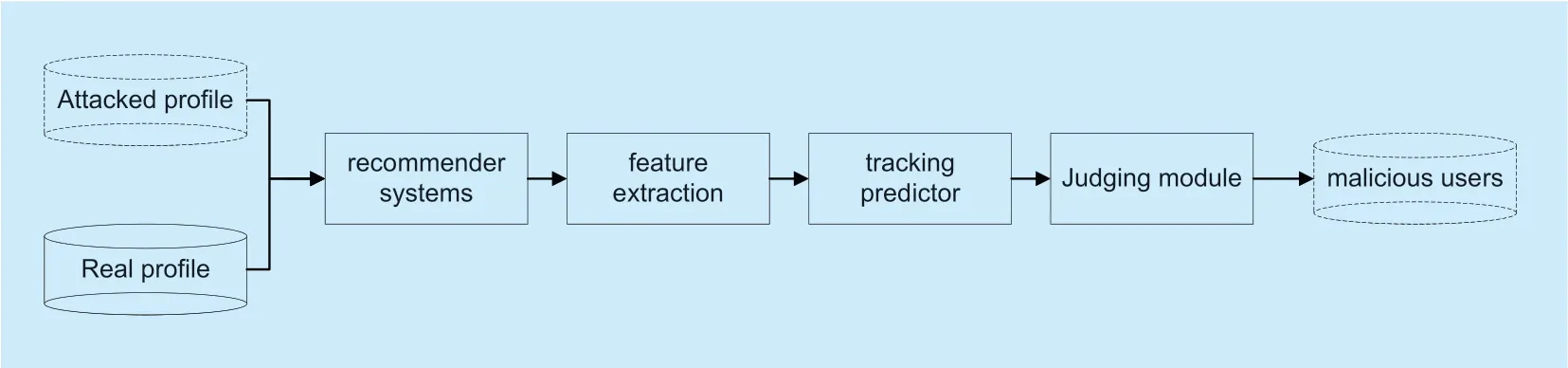
Fig.2.The construction of detection model.
particle filter algorithm due to its non-Gaussian and nonlinear characteristics.Through tracking,weighting and re-sampling for the basic detection attributes,the particle filter algorithm can achieve the short-term tracking to potential abnormal items,and can figure out the probability of these potential abnormal items being the real target items according to several groups of state transfer values and observed values.The judging module,which is based on the gravity model and the universal speed,abandons PCC and achieves more effective detection toGSAGenlattacks.
3.2 Related definitions of basic detection attributes
The basic detection attributes of recommender systems display the difference of statistical characteristics between the attacked user profile and the real user profile.In this paper,total five basic detection attributes are adopted to describe data features,which can be used to distinguish the real profile from the attacked profile.
Definition 1.Short-term average change activity (SACA).It reflects that the attackers constantly push up the target item's ratings,which leads to a short period of rapid ascension of the average score of target item.SACA can reflect the increment of abnormal users whose ratings are higher than the average score of target item in unit time,so it is a kind of basic detection attribute based on users,as shown in (1)(for push attack):
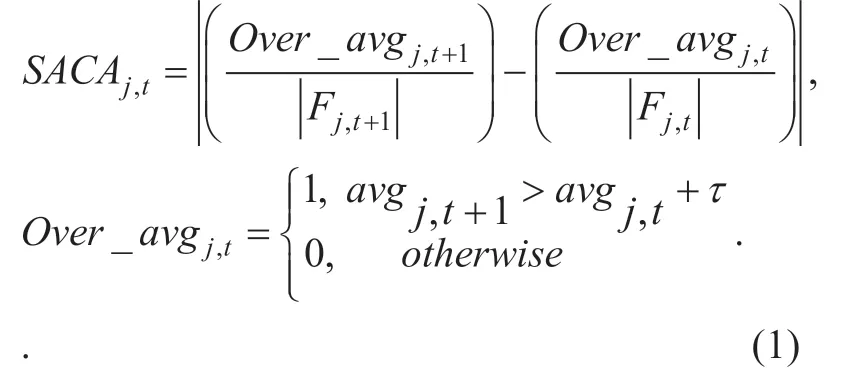
Wherein,avgj,trepresents the average score of itemjat timet,τis the corrected value of SACA.In the practical scenario,the average score of item at timet+1 may be slightly larger than that at timet,however if the increment exceedsτ,this item will be considered as an probably abnormal one.Fj,trepresents the set of all ratings to itemjexcept those abnormal ratings (i.e.the highest score and the second highest score)at timet,and meanwhile |Fj,t| represents the number of ratings inFj,t.All in all,when the target item in the recommender system encounters the profile injection group attack,its SACA value will quickly increase and maintain a high value in the short term.
Definition 2.Short-term variance change activity (SVCA)is another basic detection attribute based on the variances of item's ratings,similarly as SACA.SVCA reflects that the attackers consecutively push up the target item's rating which causes the score variance of target item decreases rapidly during a short period.This attribute can be used to show the tempestuous change of ratings of target item in the short term,which is expressed as (2):
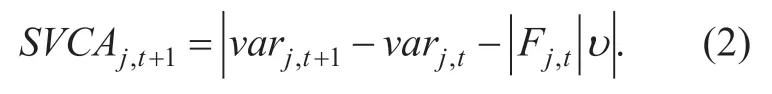
Wherein,varj,trepresents the score variance of itemjat timet,υ(determined by the amount of data)is the corrected value of SVCA,which is used to fix the difference value of variance between timet+1 and timet.And only when the score variance of itemjchanges sharply and exceedsυ,itemjcan be regarded as an probably abnormal one.SVCA value will vary quickly and maintain a low value in the short term when the target item faces with the profile injection attack launched by group attackers.
Definition 3.Target model focus (TMF)[28].The background of TMF is based on the fact that a single attacked profile cannot effectively influence the recommender system,and only the sufficient attacks containing a great number of targeted profiles can achieve this influence.It is benefited to inspect the density of items across profiles.The higher the density of one item,the greater the probability that it becomes the target item,and the relevant users will have more probability to be the group attackers.The calculation expression of TMF is shown in (3):
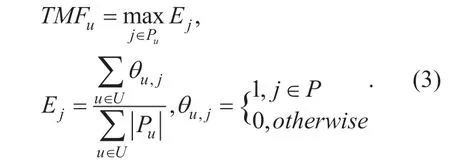
The setPucontains all items with the high score (the score must be greater than a threshold set according to the practical scenario)given by useru.It is noted that not all high scores are abnormal and some of them are rated in line with the real preferences of the normal users.|Pu| is the size of this set andUis the set of all users.θu,j=1 indicates that the useruhas rated a high score to itemj,andEjrepresents the ratio of the number of high ratings to itemjfrom all users to the total.TMFucan be used to represent the user aggregation of probably abnormal rating items,and the higher value ofTMFuindicates that the higher possibility of the userubeing a potential attacker.
Definition 4: RDMA (Rating Deviation from Mean Agreement)[29] can be seen as a measurement of the deviation between ratings of one user and ratings of other users on a set of target items,which is conductive to distinguish the malicious one from normal users.The expression is shown in (4):
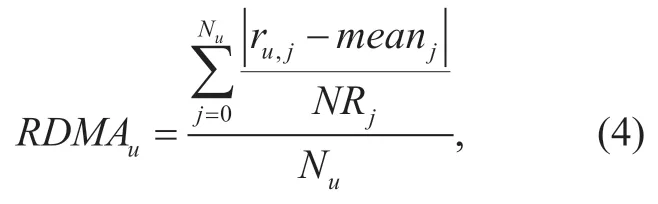
whereNuis the number of items rated by useru,ru,jis the rating given by useruto itemj,meanjrepresents the average rating of itemj,andNRjis the total number of ratings to itemjin the system.
Definition 5: DegSim (Degree of Similarity with top-N Neighbors)is an attribute used to describe the rating behavior similarity between one user and itsNnearest neighbors,which can be expressed as (5):
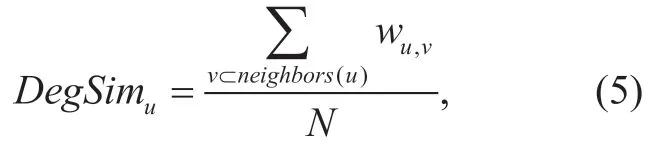
wherewu,vis the rating similarity between useruandv,and meanwhile it represents the number of their common rating items and can be calculated by Hamming distance.More common rating items indicate their interests are more similar.Additionally,neighbor(u)is the set of nearest neighbors of useruandNis the size of this set.
Furthermore,the malicious user may employ the obfuscation techniques such as noise injection and target offset.It can be easily detected by test attributes if a malicious user gives the highest score or lowest score for the target item,so the purpose of target offset is to give the secondary or third highest or lowest score to the target item.In order to eliminate the target offset,all the basic test attributes introduced by this paper use the corresponding correction value to obtain more accurate results.The treatment of the injected noise will be provided in the following algorithms.
3.3 Tracking and prediction
As shown in Figure 2,firstly the feature extractor forms the basic test attributes by extracting the user profile's features.Secondly,if the tracking predictor can accurately predict the abnormal user behavior (attacks)by tracking these anomalies,the prediction results will be returned to the judging module.And then,the particle filter algorithm is adopted due to its superior performance in the nonlinear and non-Gaussian systems.The algorithm uses a random sample to describe the initial probability distribution,by adjusting the weight of each particle and the location of the sample.And then it approximates the actual probability distribution and finally takes the average value of sample as the estimation of the system.
3.3.1 Initialization
The predictor initializes the particles which are assigned with the basic test attribute values,mainly including the SACA and SVCA values.And then a specified number of particles will be selected and released in a random manner.For example,we can initial the states of 200 particles and mark them consistently with the "tracking state",i.e.the related parameters of these particles have the same values as the test attribute values in the tracking area.
3.3.2 State transition
We take the sample composed of basic test attributes as a moving object,where the SACA attribute can be treated as a displacement,and the SVCA attribute acts as an acceleration.The nonlinear physical dynamics model is used to describe the motion state of the object,which makes the prediction overcome the defects of short-term and non-real time,and more accurately determine whether the system is attacked by a group of attackers.As shown in (6),the mathematical expressions of abnormal state fluctuations can be deduced according to the characteristics of group attacker model.
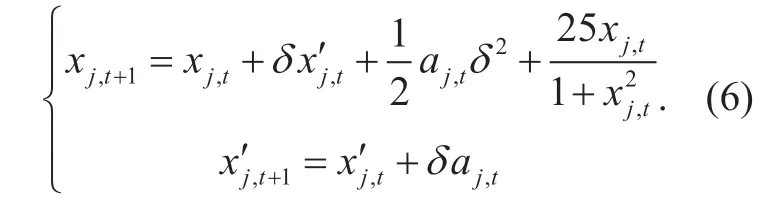
Wherein,'denotes the derivation operation,xj,trepresents the position of a moving objectj(a particle)in the x-coordinate at timet,aj,trefers to the acceleration of moving objectjfrom timetto timet+1,andδindicates the long-term movement trends factor whose value is the value of RDMA (Definition 4).
The particle filter uses the Monte Carlo algorithm to solve the integral operation of Bayesian estimation,and the algorithm utilizes the particles obtained from the dynamic state space to approximate the posterior probability density of estimated state.Each particle has its own weight for the re-sampling process.When one particle has a large weight,its state distribution at the next moment is not necessarily the same as that at the current moment,but must be closely associated with it.The appropriate model will be established to describe the kind of state transition,and the specific mathematical expressions of state transition equationXj,t+1and corresponding observation equationZj,t+1are respectively displayed as (7)and (8):
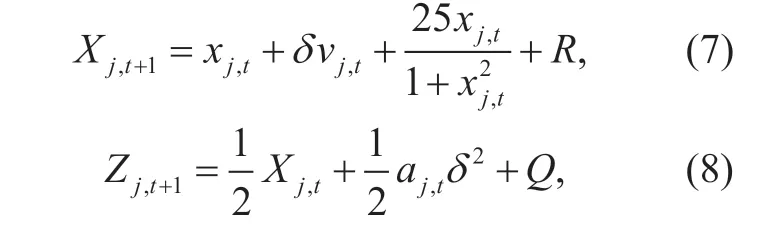
whereRis the noise variance value of state transition equation,vj,trepresents the speed of a moving objectj(a particle)in the x-coordinate at timet,andQis the noise variance value of observation equation.
3.3.3 Calculation of weights
With the continuous changes of system states detected by the basic test attributes,the states and positions of particles also change accordingly.In the current period,not all of the particles can obviously display the system status (whether or not the system is under attacks),and it means that not all particles are effective.Therefore,each particle will be evaluated and given a score as its weight.The particles with low weights will be omitted,and those with high weights will generate more particles,which can be considered as the particle re-sampling process.
3.3.4 Particle re-sampling
The re-sampling procedure is based on the probability density function generated by the particle and its corresponding weight,and it is inclined to select those particles with higher weights to clone the new population.After several re-sampling,the final particles with high weights will be selected to represent the current system status,and meanwhile as the inputs of the state transition equations.With convergence to an ideally status (all particles own the high weights),the particle filter algorithm will be terminated.Subsequently,the desired particles for prediction will form a set,and their attribute values will be the output of the tracking predictor.
3.3.5 Prediction
The validity of prediction results is determined by whether the historical data-based predictor can accurately foresee the attackers' next actions,and it also depends on the following two necessary conditions: (1)the timeliness of prediction results only permits a short-term (for example 600s-259200s)tracking in order to successfully catch the exact changes of system status; (2)the positioning ability of prediction results can be used to accurately detect the abnormal basic test attributes of target items instead of the unnecessary data derived from non-target items.The specific calculation can be shown as (9):
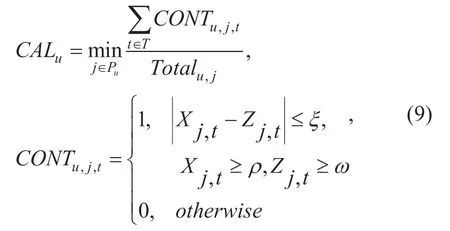
whereCONTu,j,tdenotes the proximity number aiming at itemjwhen the solution difference value between the state transition equation and the observation equation is less than the given minimum thresholdζin a short timet,and meanwhileXj,tmust be greater than the abnormal state transition thresholdρ,Zj,tmust be greater than the observation outlier thresholdω,and these conditions meet the tracking requirements for abnormalities of useru.Totalu,jdenotes the total number of tracking itemjrated by useruin a short-termT.CALuis the probability of userubeing a potential attacker due to its ratings to abnormal items,which can be expressed as the form of percentage,and its value greater than the maximum threshold indicates that the user is likely an attacker.
3.4 Judging the group attackers
The gravitation-based detection model contains the judging module,and the related definitions are listed as follows.
Definition 6: User object.Each user is treated as an object in the gravitation system,and the data attributes of object can be used to detect the attacks.
Definition 7: The mass of user object can be determined by the degree of aggregation of its adjacent objects; initially the mass of each fresh user tends to 0 and it will be gradually attracted by the heavier user object (i.e.the user object with the high degree of aggregation); if the greater the mass of user object,the more the number of its adjacent user objects and the higher the degree of aggregation.
Definition 8: User object gravity (the gravitation between two user objects).A user can only attract others rating to the same items as itself.
Definition 9: The distance between two user objects is defined as the vector distance between the centers of mass of two user objects.
Definition 10: Gravitation field.The users in the recommender system will form a fullfield throughout the data space due to the gravitational interactions between any two users; the gravitational field varies accordingly with the continuous data changes.
Definition 11: The center of gravitation field.The gravitation-based detection model is absorbed in making the abnormal user become the center point of the entire gravitational field in order to greatly improve the judging efficiency.Users are classified according to the TMF values and the outputs of the tracking predictor.
Definition 12: The gravitation law of user object: there exit a gravitation between any two user objects,which is proportional to the masses of two user objects and inversely proportional to the distance between them,and the direction of gravitation coincides exactly with the connection direction between the centers of gravity of two user objects.
A is a fresh user object with the massmAand B is an existing one with the massmB,the distance between A and B isdAB,and the gravitation between A and B can be calculated by (10):
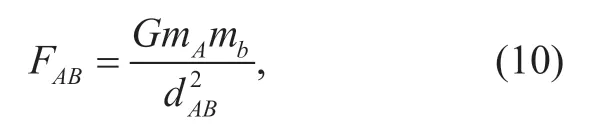
whereGis the gravitational constant.It is worth emphasizing that A and B must have the same rating items in order to attract each other.
Definition 13: The judging law of user object: The law of gravity and Newton's second law consider that a certain user object with a specific velocityvcan break through the Earth's gravitation,and Formula (11)shows its mathematical form wherevAdenotes the velocity of A andvBis the velocity of B.
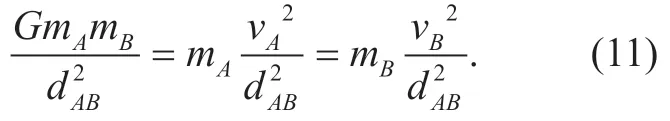
The judging module make choices based on the user profiles,and the judgment of shilling attack can be designed as follows: based on the law of universal gravitation,TMF values of basic test attributions obtained by the judging module together with the output results of the tracking predictor will be as the inputs of (12):
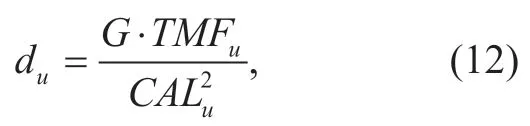
where the gravitational constantGis the Deg-Sim value;TMFuis the TMF value which represents the user aggregation degree of the abnormal ratings items;CALuis the percentage value of prediction results,as mentioned above,if its value is more closer to 100%,the user is more likely to be a group attacker; when the value ofduis 1,we can confirm the user is a group attacker.
3.5 Algorithms description
Algorithm 1 describes the execution process of the feature extraction,the basic test attributes such as SACA and SVCA values can be figured out through continuous monitoring in step 1-16,and similarly TMF,RDMA and DegSim values are obtained from step 22-25.
The prediction algorithm can be seen in Algorithm 2,where parameters initialization is executed in step 1-4,step 5-9 calculate the particles and their respective weights,step 12-13 generate the state transition equations and observation equations in order to calculate the total weight.Tracking these particles is displayed in step 14-19,the weight normalization occurs in step 20-25,and the particle re-sampling is completed in step 26-36.Finally the accurate predicting ratio of abnormal items will be calculated in step 37-53.
Algorithm 3 is used to describe the running of the judging device,and this algorithm use the TMF values and CAL values to identify group attackers.ωis a decision threshold assigned according to the actual situation.
IV.EXPERIMENTAL EVALUATION AND DISCUSSION

Algorithm 1.Execution of feature extraction.Input: the ratings matrix denoted as D(u,j,t)Output: the values of SACA,SVCA,TMF,RDMA and DegSim 1.for j=1 to n2do /*n2is the number of all items*/2.for u=1 to n do /*n is the number of all users*/3.for v=1 to n do 4.for t=1 to T step tj do /*T is the system analog time,tj is a given rating time interval */5.avg avg u j t j t,← ((,,))D/*Get the average score of item j at time t*/6.var var((,,))j t,← Du j t /*Get the score variance of items j at time t */7.w u j t v j t u v,←D D(,,)(,,)∩/*Use the hamming distance to get the rating behavior similarity between any two users u and v,if u=v,then wuv,=1*/8.if avg avg + > +τ then j t j t ,1 ,/*Compare the average score of item j between time t+1 and timet */9.Over avg Over avg+ ← + /*When the rating in time t+1 is abnormal,the counter pluses one*/10.else 11.F F__ 1j t j t ,1 ,+ ← +1 j t j t ,1 ,/*Get the number of normal rating about item j at time t+1 */12.end if 13.)()SACA Over avg F Over avg F←,1 ,1 ,1 ,,+(_ / _ /+ +-j t j t j t j t j t/*Calculate the SACA value*/14.var var υ SVCA F← - -j t j t j t j t ,1 ,1 ,,++/*Calculate the SVCA value*/15.end for 16.end for 17.if j P∈u then /*Detect whether item j is an abnormal item */18.θ θ← +1 u j u j ,,/*θu,jmeans that the user u rates a high score for item j */19.end if 20.end for 21.end for 22.θ ,/* Calculate the ratio of the number of high ratings to item j from user u to that from all users */23.TMF EEj ←∑ ∑P u j uu U u U ∈∈u ←max j P∈u /* Calculate the TMF value*/j 24.RDMA r mean NR Nu ∑jN =u 0= -((/))/,u j j j u/* Calculate the RDMA value*/25.DegSim w N ,/* Calculate the DegSim value*/ u =()/⊂∑()u vv neighbors u

Algorithm 2.Prediction algorithm.Input: the value of SACA and SVCA Output: the value of CAL 1.x SACAj t j t ,← ,,′jt jt jt,,1 ,x x x t←-Δ+/ ,a SVCAj t j t ,←,/* parameters initialization,Δt denotes the time slice */2.R = input(' Please enter the state transition noise variance value of R: ')3.Q = input(' Please enter the observation noise variance value of Q: ')4.T= 100,Np = 200,P = 2 /*T is the analog time length,Np is the number of particles,P is the variance of the initial estimation value */5.for j=0 to n2do /* Initializing the particle filter,the function xpart(j,t)randomly generate the particles at different moment */6.for i=1 to Np do 7.xpart(i,j)= xjt,+ sqrt(P)* Г /* Г generates standard distribution of the random matrix,sqrt()is the square root */8.end for 9.end for 10.for j=0 to n2do 11.for t=0 to T do 12.X x v x x R δ 25 /(1)2 /* Calculate the value of state transition */13.Z X a Qj t j t j t j t j t ,1 ,,,,+ = + + + +0.50.5δ 2 /* Calculate the value of observations */14.for i=1 to Np do /*Start the particle filter tracking */15.xpartus i j t xpart j t v xpart j t xpart j t Rj t j t j t ,1 ,,+ = + +2(,,)(,)25 (,)/(1 (,))=+ + + +δ jt,/* xpartus(i,j,t)represents a state transition value of particle i at time t after adding the noise variance value R*/16.ypart i j t xpartus i j t a + jt,δ2 (,,)0.5 (,,)0.5=/* ypart(i,j,t)represents the prediction value of particle i at timet */17.vhat i j t Z ypart i j t (,,)(,,)= -j t,/* vhat(i,j,t)represents the difference value between the observe value and the prediction value of particle i*/18.q i j t sqrt pi R vhat i j t R- 2 (,,)(1/ (2* *))*exp((,,)/2*)=/*q(i,j,t)represents the weight of each particle,wherepi is 3.14*/19.end for 20.for i=1 to Np do 21.qsum sum q i j t = ((,,))/* qsum indicates the probability of each prediction,sum is the cumulative sum function */22.end for 23.for i=1 to Np do 24.q i j t q i j t qsum (,,)(,,)/= /* Normalize each particle's weight,a larger weight divided by qsum is not zero,most of the smaller weight divided by qsum is zero */25.end for 26.for i=1 to Np do 27.η=rand(0,1)28.qtempsum = 0 /* η is a random number of uniform distribution between 0 and 1,qtempsum is a temporary variable */29.for k=1 to Np do 30.qtempsum qtempsum q k j t = + (,,)/* Calculate the total weight by accumulating each particle's weight */
4.1 Experimental data sets
Two different data sets,MovieLens and Amazon,are used in our experiments.The MovieLens 100K dataset is widely used in simulation experiments of data mining and other fields due to the properties of real and aplenty.This data set is provided by the GroupLens research team at the University of Minnesota U.S,which includes 100,000 rating records of 943 users to 1682 movies.Each rating record includes a user ID,an item ID,a value of rating in the interval [13,20] and a TimeStamp.The user ID and item ID start with 1 and increase by degree,the higher the rating indicates that the user more likes the movie,and the format of reference time is 1/1/1970 UTC.The Amazon data set contains information for a variety of items,divided into one data subset that only has scores,and the other data subset that has both reviews and ratings.The instant video data set of Amazon product is selected in our experiments,which includes 583,933 ratings (1-5 marks)spanning 1996-2014,presented as (user,item,rating,timestamp)tuples.
4.2 Evaulation metrics
Both "Precision" and "Recall" are commonly used to evaluate the performance of the detection algorithm in the recommender systems.Both of them can also be integrated into the metric of "F-measure" in order to comprehensively evaluate the detection ability of algorithms.The mathematical expressions are shown in (13)-(15)respectively:

wherein,TP represents the number of attacked profiles detected correctly,FP represents the number of false positives of the real profiles to be mistaken for attacked profiles,FN denotes the number of attacked profiles to be mistaken for the real profiles.The greater the "Precision",the lower the proportion of real profiles being mistaken for attacked profiles.The higher "Recall",the lower the proportion of attacked profiles being mistaken for real profiles.
4.3 Parameters selection in experiments on MovieLens
Formula (16)is used to calculate theOver_avgj,tofSACAwhen detecting push attack,and Formula (17)is used to calculate theOver_avgj,tofSACAwhen detecting nuke attack.200 normal items and 150 target items are randomly selected based on MovieLens data set.With the changes ofavgover a period of time,figure 3 shows the corresponding changes ofτ(the difference betweenavgj,t+1andavgj,t)in push attack,where the symbol of ‘+' in this figure represents the value of target items'τ,and the blue dot represents the value of normal items'τ.In order to track all target items,we need to choose the appropriate value ofτ.It can be found that the values of target items'τare all greater than 0.001,soτis set to 0.001 in face of push attack.Similarly,Figure 4 shows the changes ofτin nuke attack.As the values of target items'τare all less than -0.0001,τis set to -0.0001 in face of nuke attack.
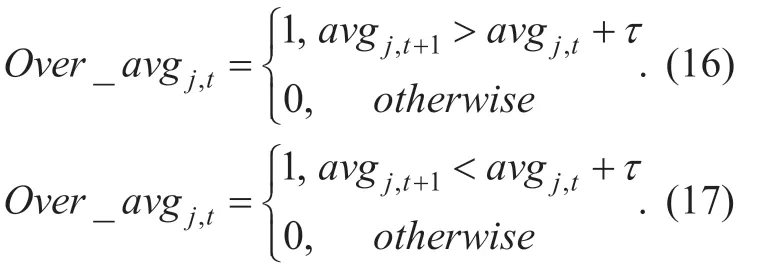
Similar to the method of setting the appropriate value ofτ,υis set as 0.00025,ζis set as 0.0001 andωis set as 0.025.ρis influenced by the frequency of tracking and prediction.With the increase of the tracking frequency,ρwill decrease and be close to the reciprocal of sample size.However,in order to reduce the amount of calculation,ρis usually set as a fixed small value.In this experiment,it's value is 0.0001 according to the sample size.In addition,the tracking time is 1s.

?

?
The effect of the value ofϖon the experimental results can be observed while keeping other parameters fixed.Table 2 shows the F-measure values of GBDM in face of several different shilling attacks when the filler size is 3%,the attack size varies from 3% to 15% andϖvaries from 0.88 to 0.92.When the value ofϖis set smaller,the number of FP will increase,which will result in the decrease of F-measure.On the contrary,the larger value ofϖwill result in the decrease of both TP and F-measure.Taken together,GBDM performs best whenϖis set as 0.9.
4.4 Analysis of detection performance on MovieLens
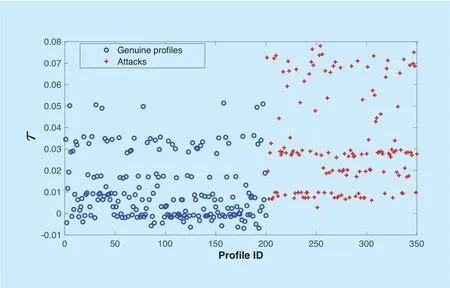
Fig.3.The change of avg in push attack.
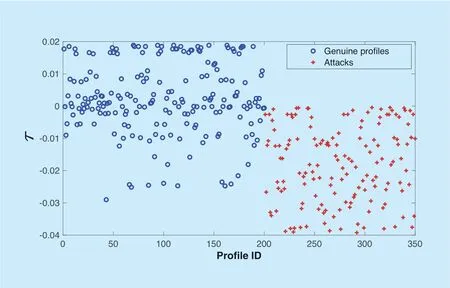
Fig.4.The change of avg in nuke attack.
Some traditional detection algorithms or detectors such as HHT-SVM [18],SVM-TIA [19],AP-UnRAP [23],PCA-P [24] and Semi-SAD [25] are compared with the proposed gravitation-based detector model (a.b.GBDM).These algorithms are respectively used to withstand four kinds of enhanced shilling attacks based onGSAGenlwith the attack sizes of 3%,9% and 15% and the filler sizes of 3%,10% and 25% respectively.The detection performances are shown from Table 3 to Table 14,which are the average results of several experiments.
From Table 3 and 4,it can be found that the recall values of five detection algorithms are satisfactory in the face of the random attack based onGSAGenl.The random attack can be launched just obtaining the mean value and the standard deviation of all ratings.Moreover,many recommender systems even directly provide the rating statistics for users.However,the random attack is easy to be caught due to the test attributes SACA and SVCA are special to focus on detection of the mean and the variance.The detector of GBDM has a slightly better performance on the recall metric than other five algorithms,and it achieves more superior precision than others,which benefits from the well-designed test attributes such as SACA and SVCA against random attacks.
The average attack based onGSAGenlprefers to produce filler items based on the average score of items.From Table 5 and 6,it can be seen that the detector based on GBDM obtains better performance when comparing with other five detectors,especially on the precision.This is because a series of corrected values such asτ,ζ,ρare set in GBDM in advance,which can be used to effectively deal with the average attack.Furthermore,when encountering the average attack,the number of basic test attributions (except for the average value)extracted from the feature extractor of GBDM is the least among four shilling attacks,which indicates that GBDM can achieve satisfactory performance with less system cost during the data tracking and prediction.
It can be seen from Table 7 and 8,the detector of GBDM performs slightly unsatisfactorily in the face of the bandwagon attack based onGSAGenlunder the massive filler size and attack size.The reason is that the increase of abnormal data in the system causes some false profiles are more difficult to distinguish from normal profiles.And meanwhile,it can be found that the detectors of SVMTIA,AP-UnRAP and PCA-P fail under the low filler size or low attack size attacks.Due to the use of PCC,the HHT-SVM detector is also disabled when the recommender system suffers the bandwagon attacks fromGSAGenl.The detection performance of Semi-SAD detector is impressive,however it is not as good as that of the GBDM detector especially under the low filler size attacks.
The detection results aiming at the segment attack based onGSAGenlcan be seen in Table 9 and 10.Similar as the bandwagon attack,the segment attack can cause worse destruction than the random attack and the average attack.The filler items selected by the segment attack are usually the popular items with a high score rated by real users,which makes it difficult to distinguish the attacked profile from the real one using the ordinary detectors.However,this disguise can be still found by GBDM due to the continual tracking to abnormal items.Consequently,shown as Table 9 and 10,the detector based on GBDM achieves the desired and steady precision and recall.
The more intuitive evaluation results based on F-measure can be found in Table 11 to Table 14.The higher the F-measure value,the more excellent the detection performance.In contrast to other five detectors,GBDM achieves almost the best detection effect when facing with no matter what kinds of group shilling attacks based onGSAGenlwith different attack sizes and filler sizes.This benefits from the characters of "less tracking items and higher precision" of GBDM and its stable and persistent performance in recommendation service.
4.5 Analysis of detection performance on Amazon
In order to comprehensively demonstrate the advantage of GBDM,more experiments need to be conducted on the instant video data set of Amazon product data.SVM-TIA,PCA-P and Semi-SAD are selected and compared with GBDM due to their better performancethan the remainder from Table 3 to Table 14.The four detectors are respectively used to withstand three kinds of shilling attackswith the filler size of 3% and 10% and the attack sizes of 1%,3%,5% and 10%.Since this data set lacks detailed information about the items,it cannot implement the segment attack.The metric of "F-measure" is used to comprehensively evaluate the detection ability of these detectors.And the detection performances are shown from Figure 5 to Figure 8,which are the average results of several experiments.When the filler size is fixed,the trend of the F-measure of the four detectors is rising with the increase of attack size.And when the attack size is fixed,the F-measure of the four detectors slightly increases as the filler size increases.This is because with the increase of attack size and filler size,the features of shilling attacks will become more and more obvious.No matter what type of push attacks or nuclear attacks,the performance of GBDM is the best and the most stable.When the attack size is over 10%,the precision of GBDM reaches 95% due to the optimal evolution of particles.However,in face of the bandwagon attack,GBDM's performance declines a little compared with that when facing with the random attack or the average attack.Since the bandwagon attack involves the profiles with high ratings to well-known popular items orlow ratings to non-mainstream items,which also increases the possibility of misjudgment in GBDM with the increase of attack size.
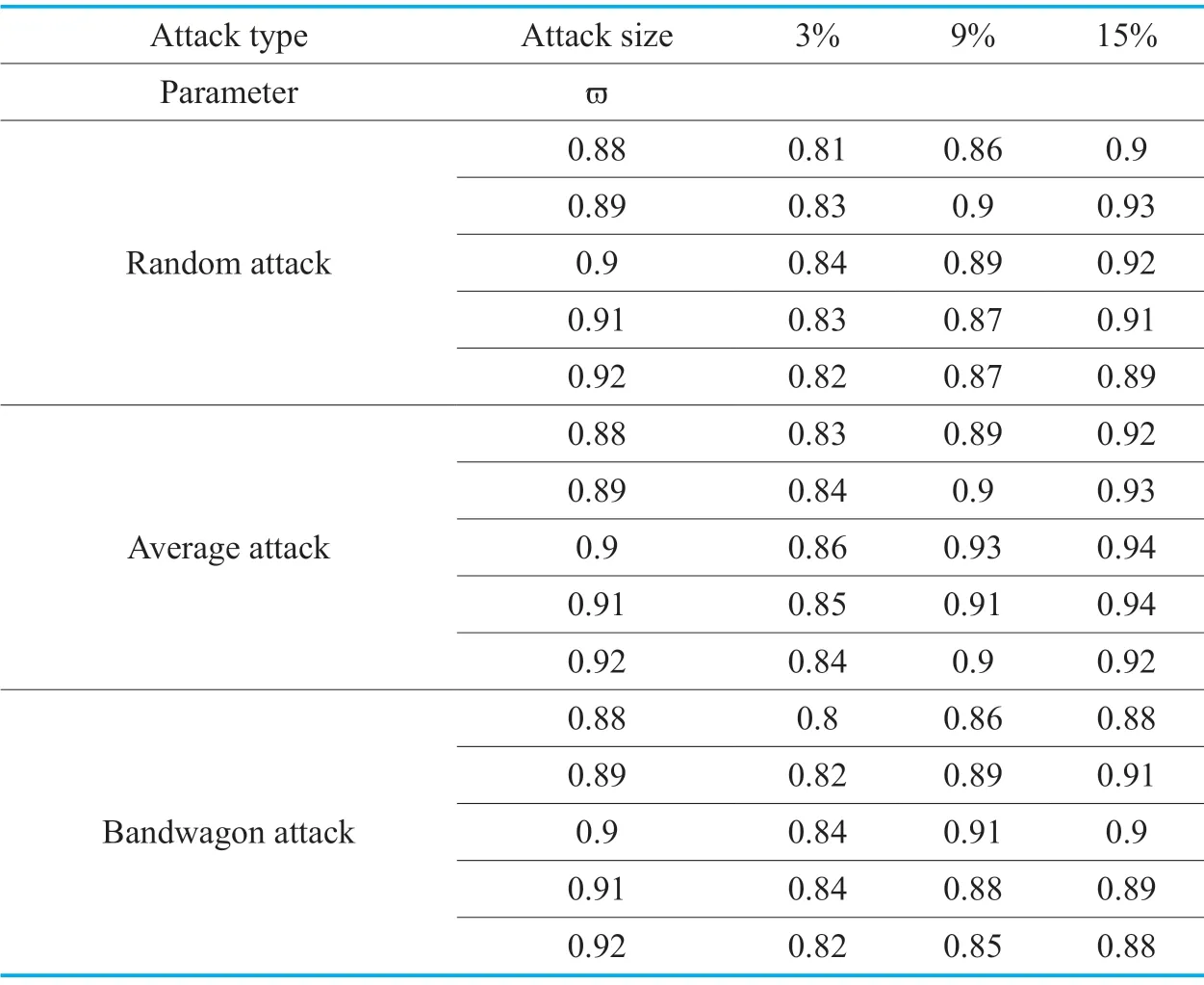
Table II.The F-measure of GBDM when ϖ varies
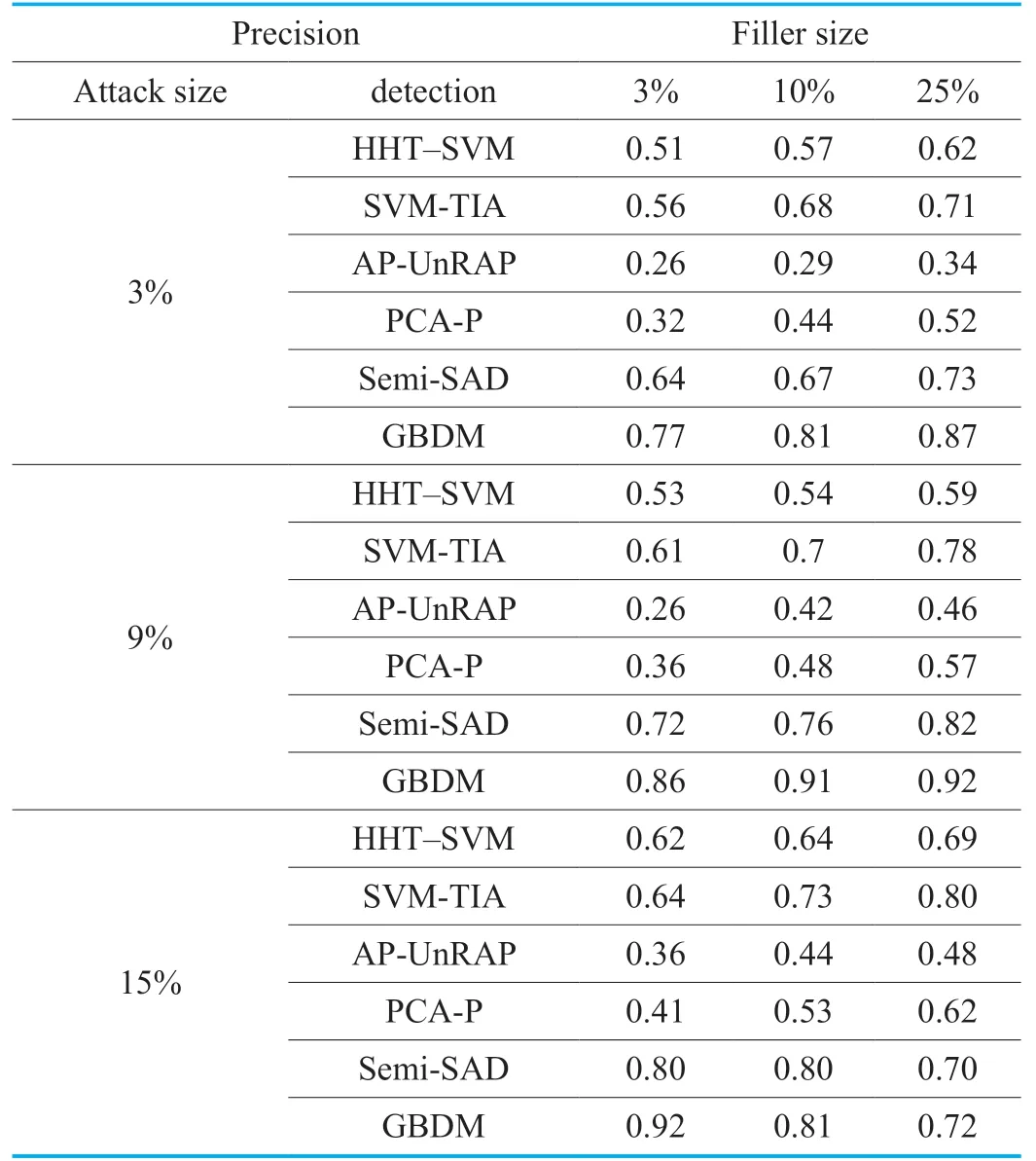
Table III.The Precision of GSAGenl(Random attack).
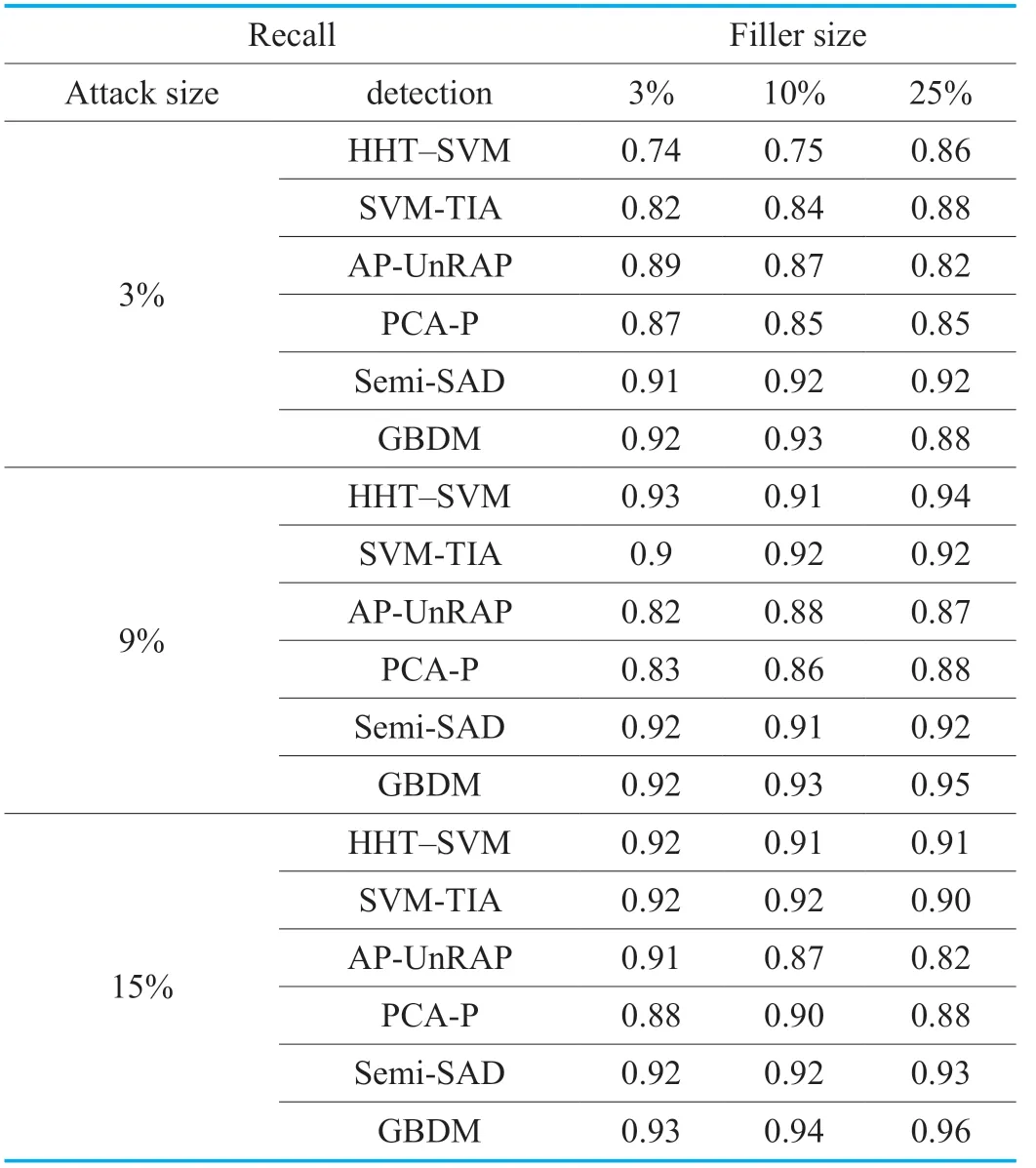
Table IV.The recall of GSAGenl(Random attack).
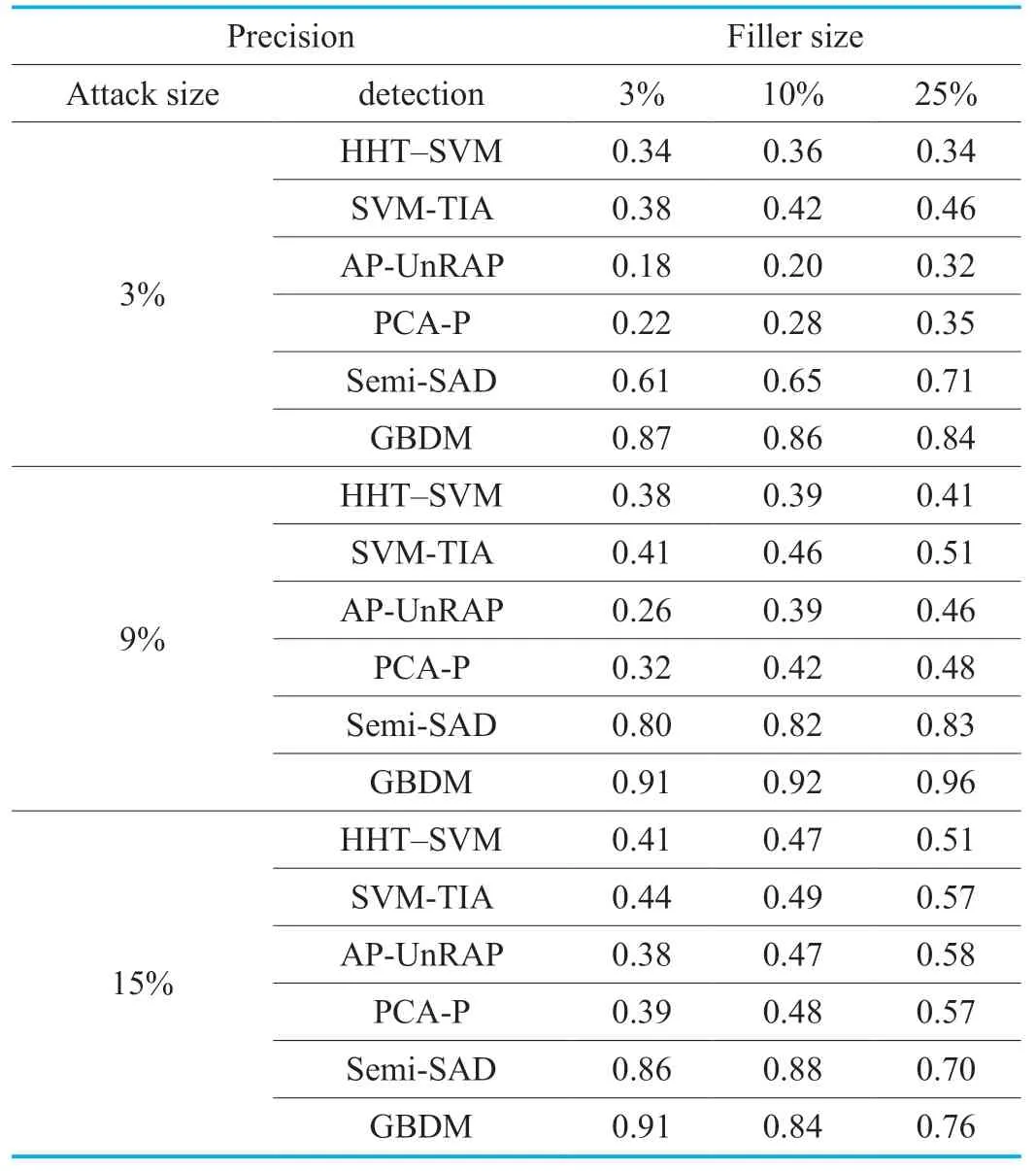
Table V.The Precision of GSAGenl(Average attack).
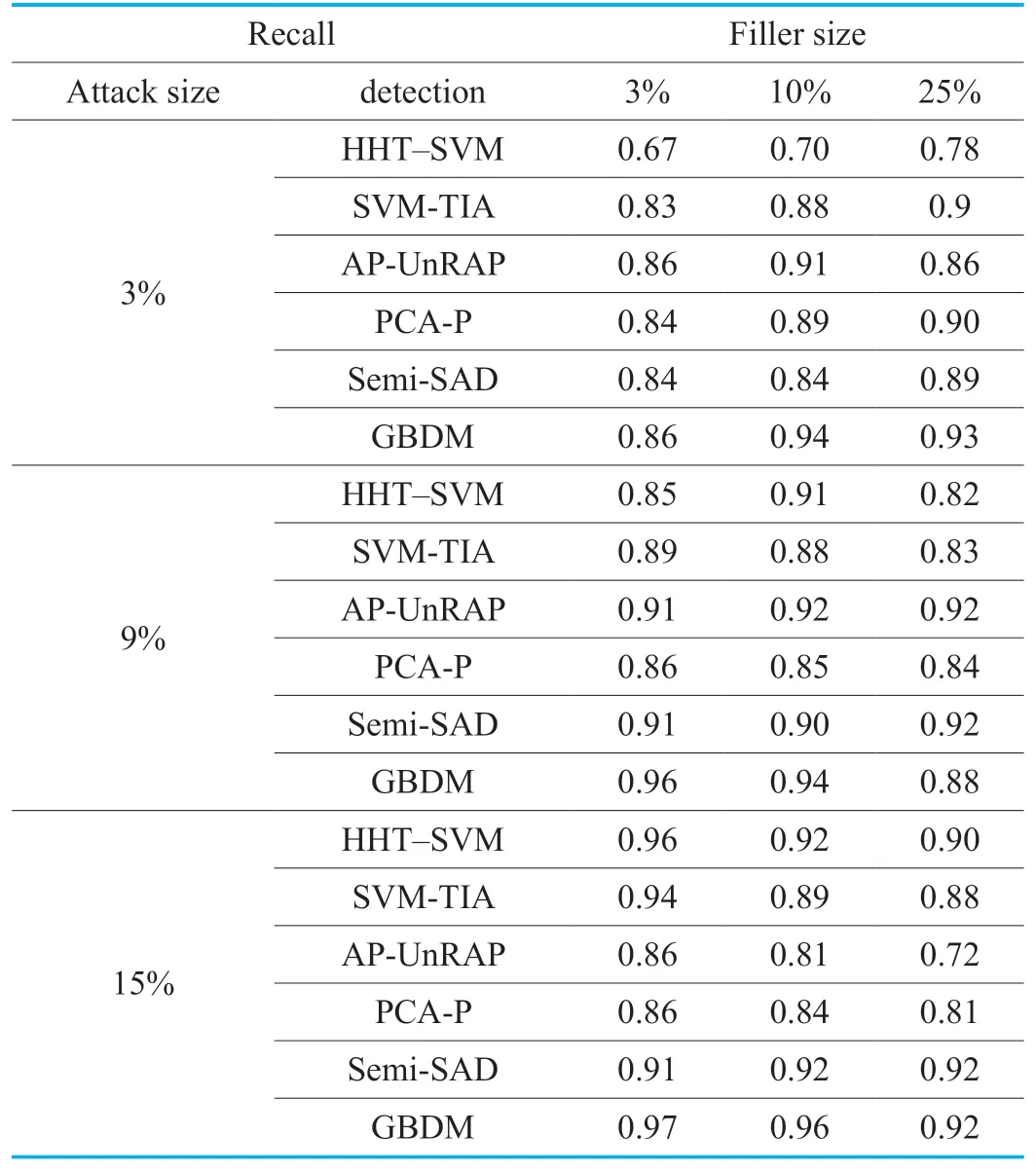
Table VI.The recall of GSAGenl(Average attack).
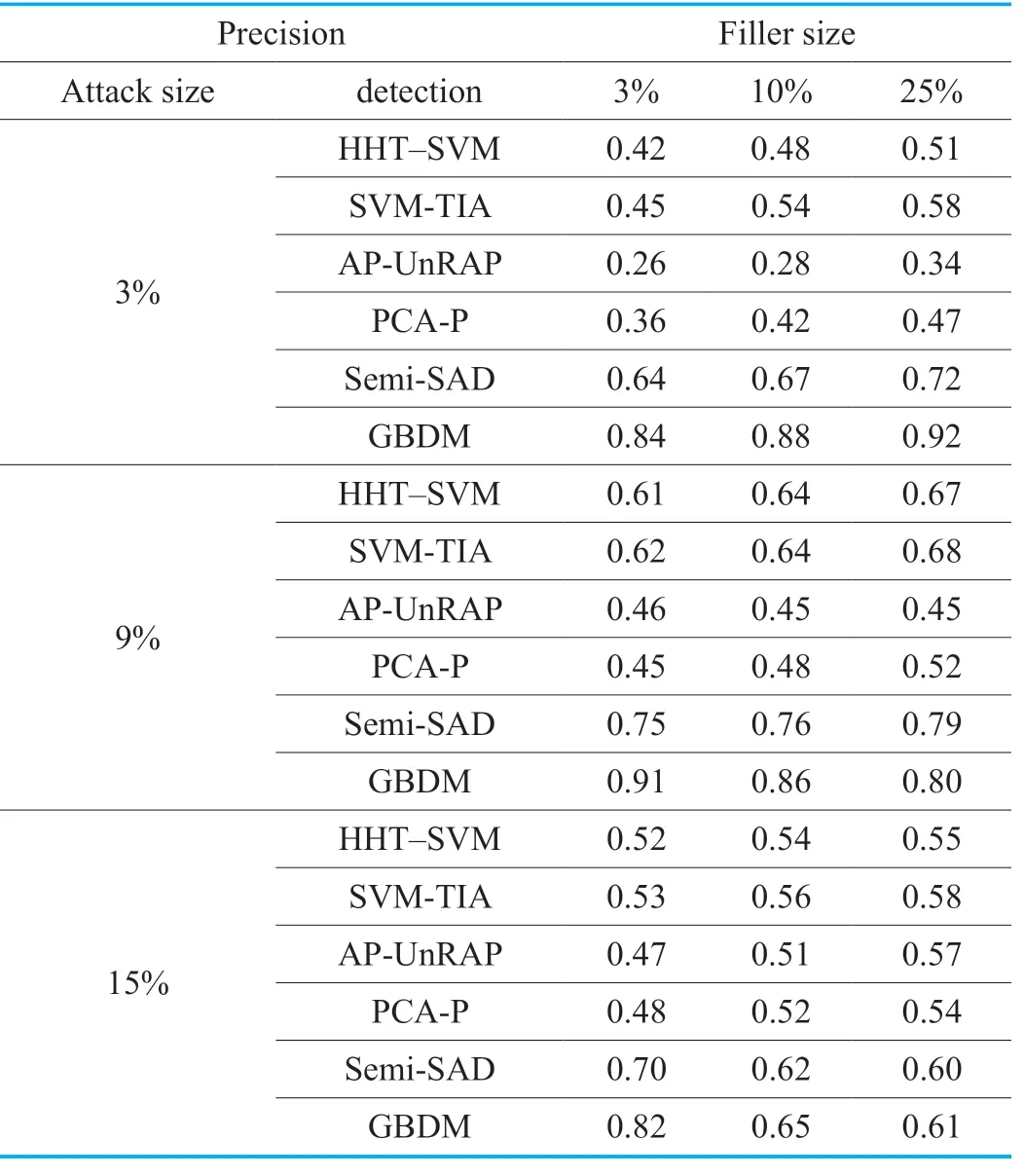
Table VII.The Precision of GSAGenl(Bandwagon Attack).
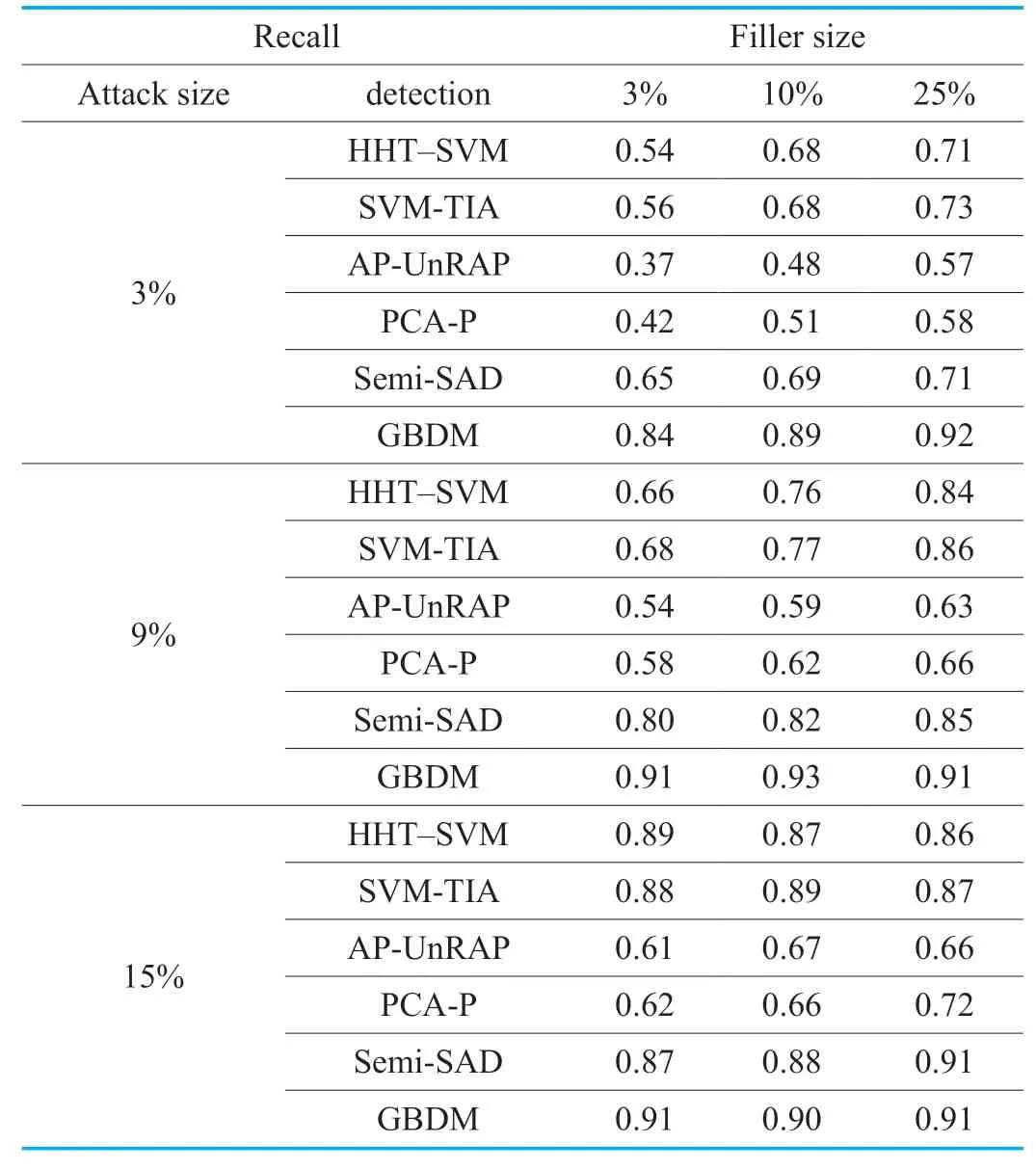
Table VIII.The recall of GSAGenl(Bandwagon Attack).
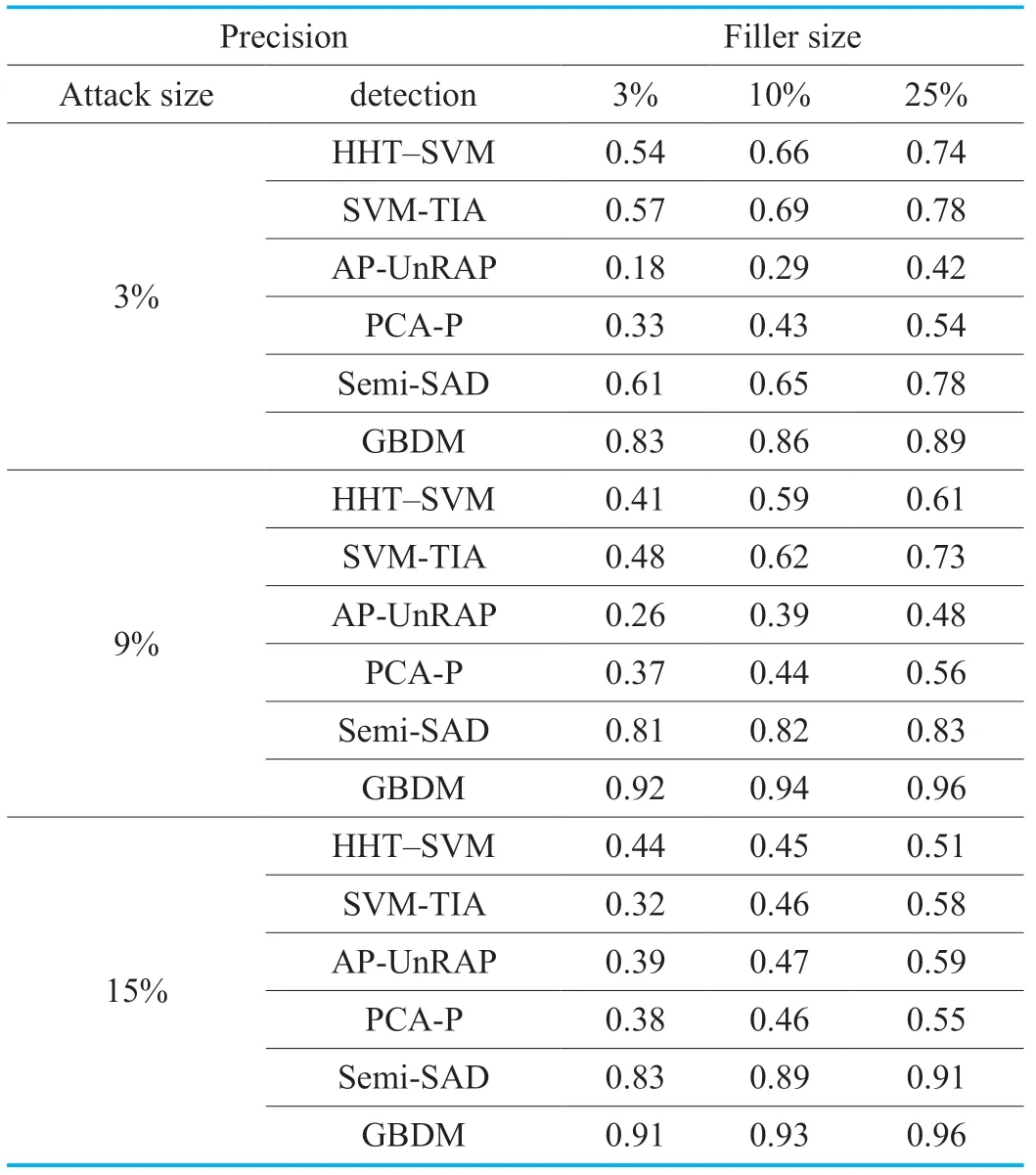
Table IX.The Precision of GSAGenl(Segment Attack).
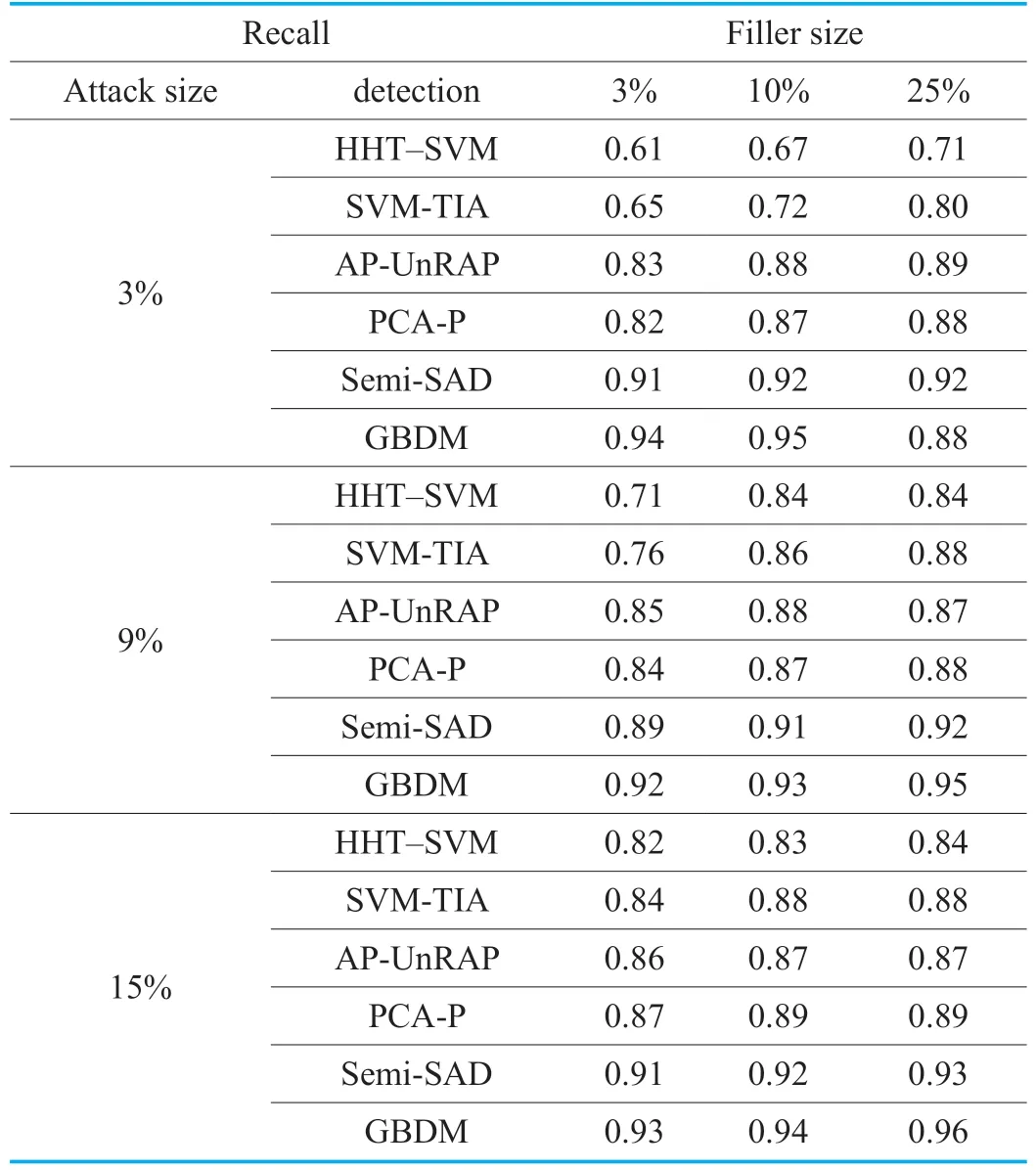
Table X.The recall of GSAGenl(Segment Attack).
4.6 Discussion of the time complexity
Assuming thatn2is the total number of all items,nis the total number of all users,Tis the system analog time,tjis a given ratingtime interval,Npis the counts of particles,n4is the number of users who rates to the abnormal items,the worst-case time complexity of Algorithm 1 is O(n2n2((T-1)/tj+1)),that of Algorithm 2 is O(n2Np+n2T(Np+n)),and that of Algorithm 3 is O(n4).Considering that the values ofn2andnare much larger than other parameters,the whole time complexity of GBDM is O(n2n2)after simplification.In addition,the time complexity of SVM-TIA is O(m2N)(mis number of samples andNis the feature dimension),and that of PCA-P is O(kn2)(kis the number of principal components).Both of them have the same time complexity level as GBDM.Since the current calculation capacity for civilians can achieve trillions-point operations per second,the polynomial time complexity of GBDM is acceptable.
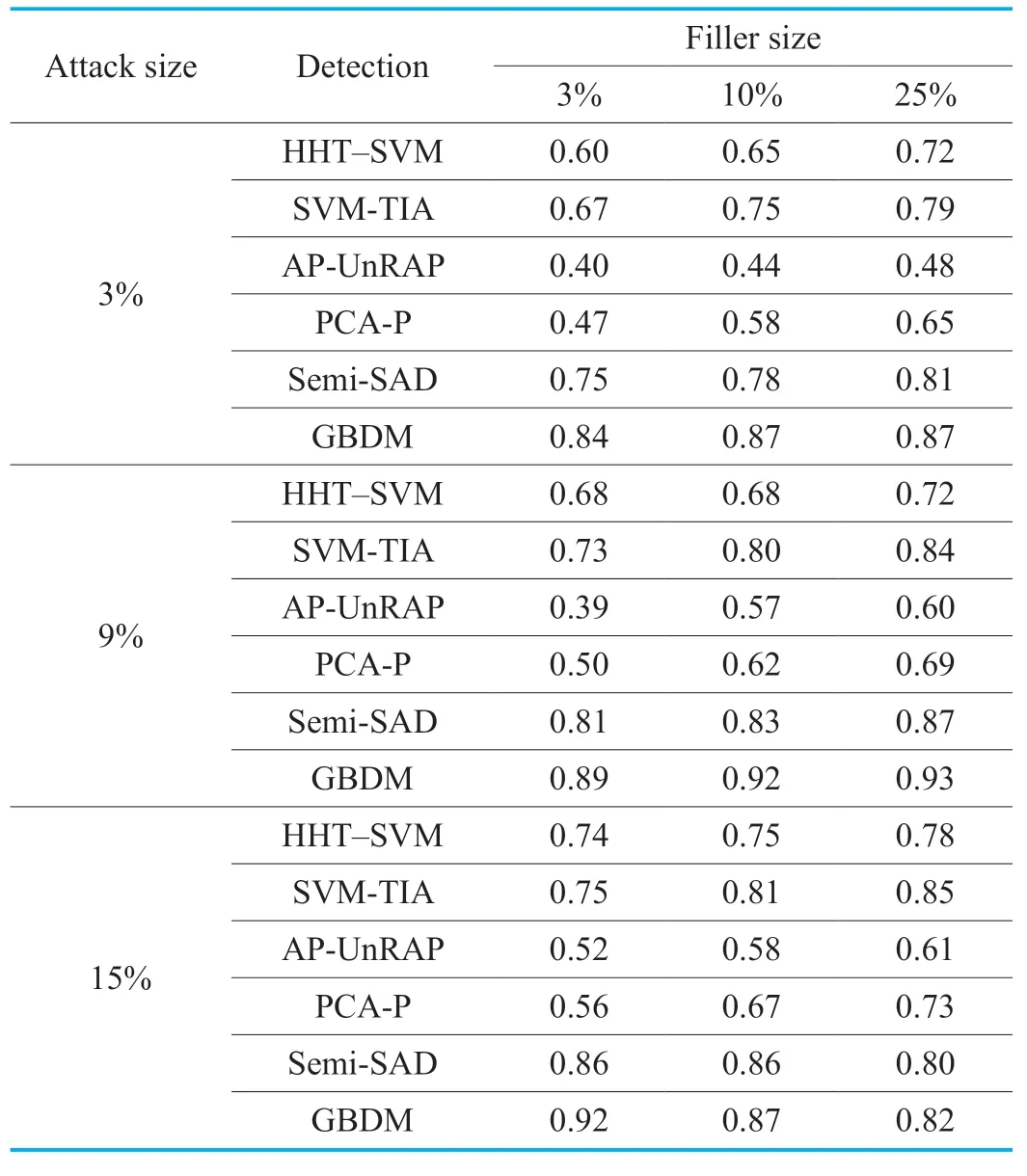
Table XI.The F-measure of GSAGenl(Random attack).
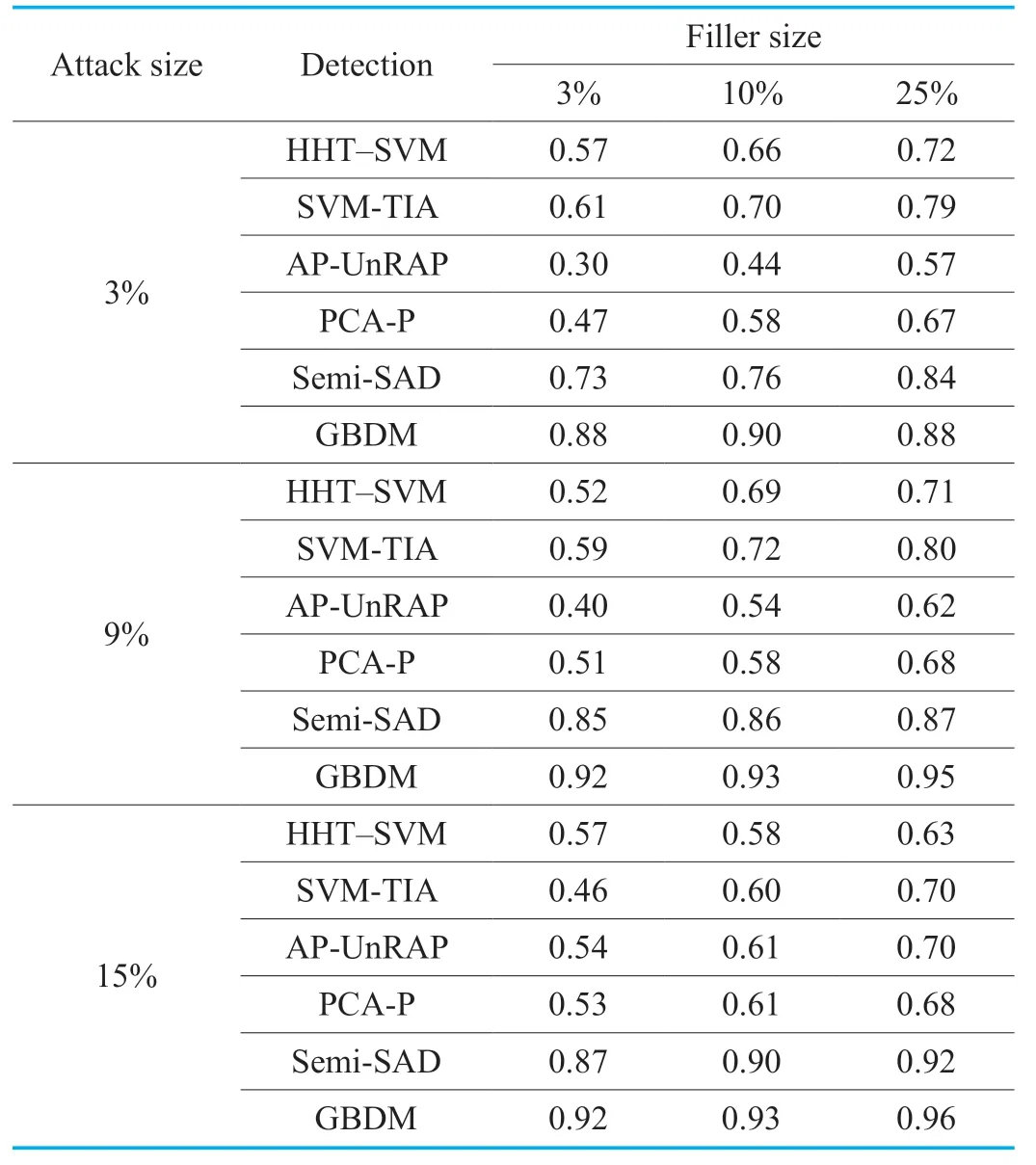
Table XIV.The F-measure of GSAGenl(Segment Attack).
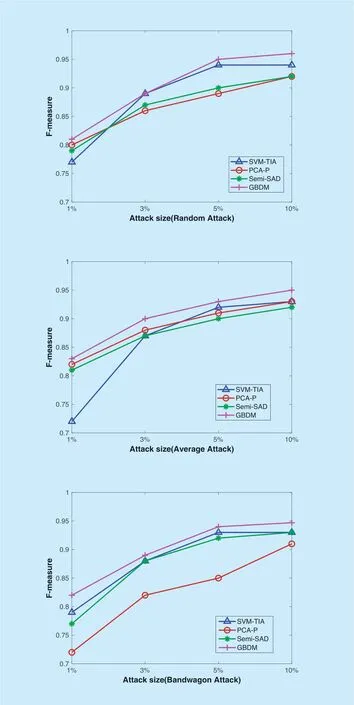
Fig.5.The performance of different detectors when the filler size is 3% and the attack size varies in push attack.
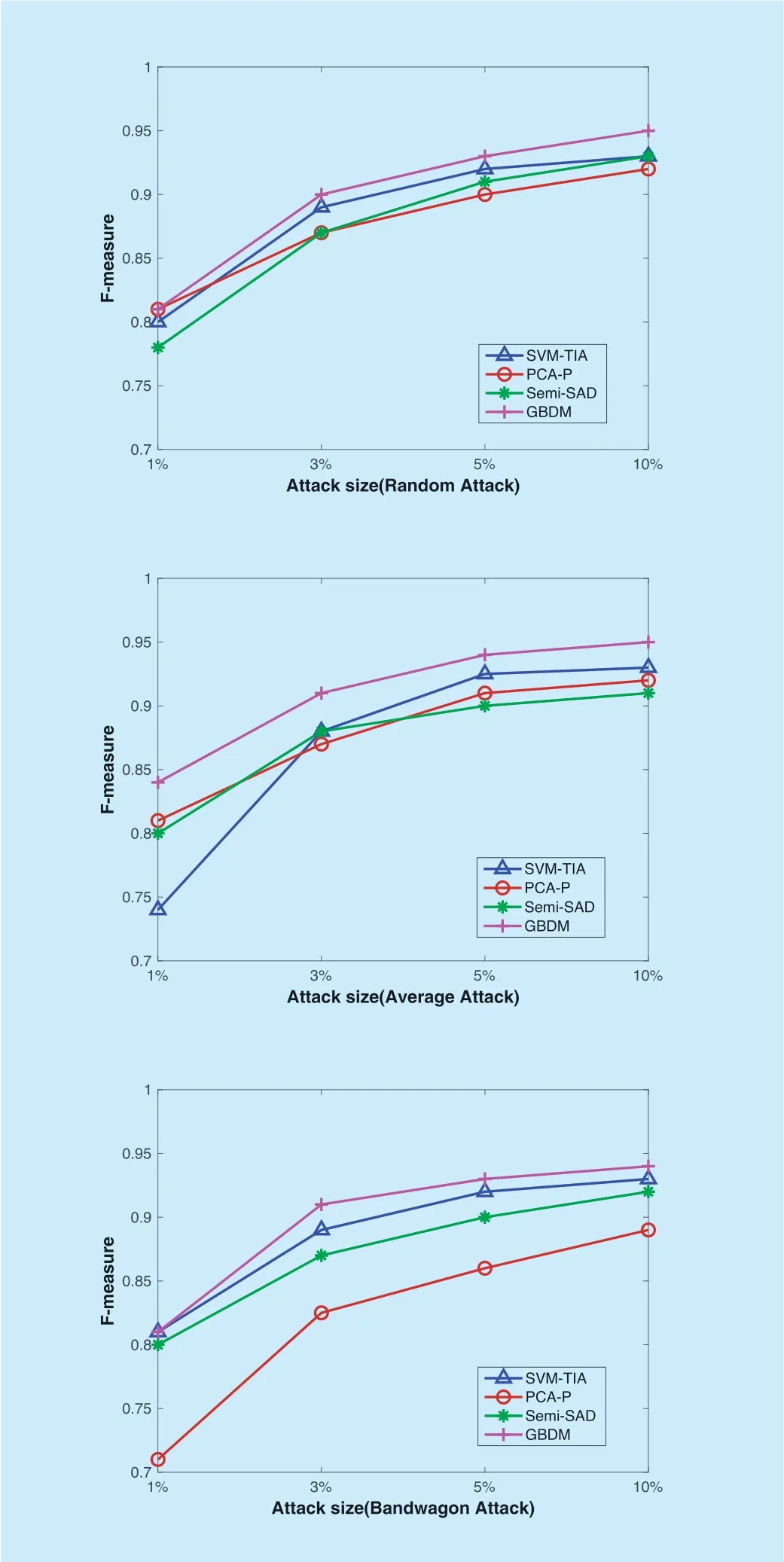
Fig.6.The performance of different detectors when the filler size is 3% and the attack size varies in nuke attack.
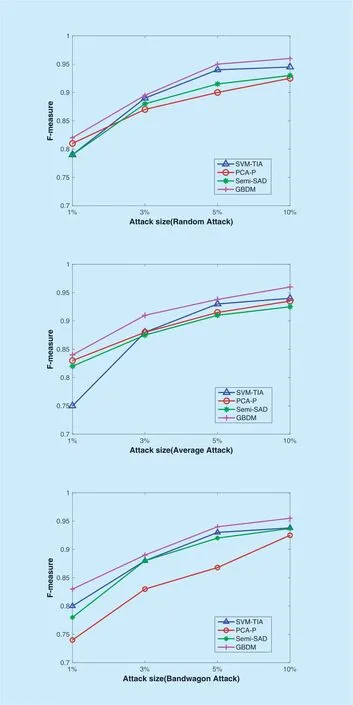
Fig.7.The performance of different detectors when the filler size is 10% and the attack size varies in push attack.
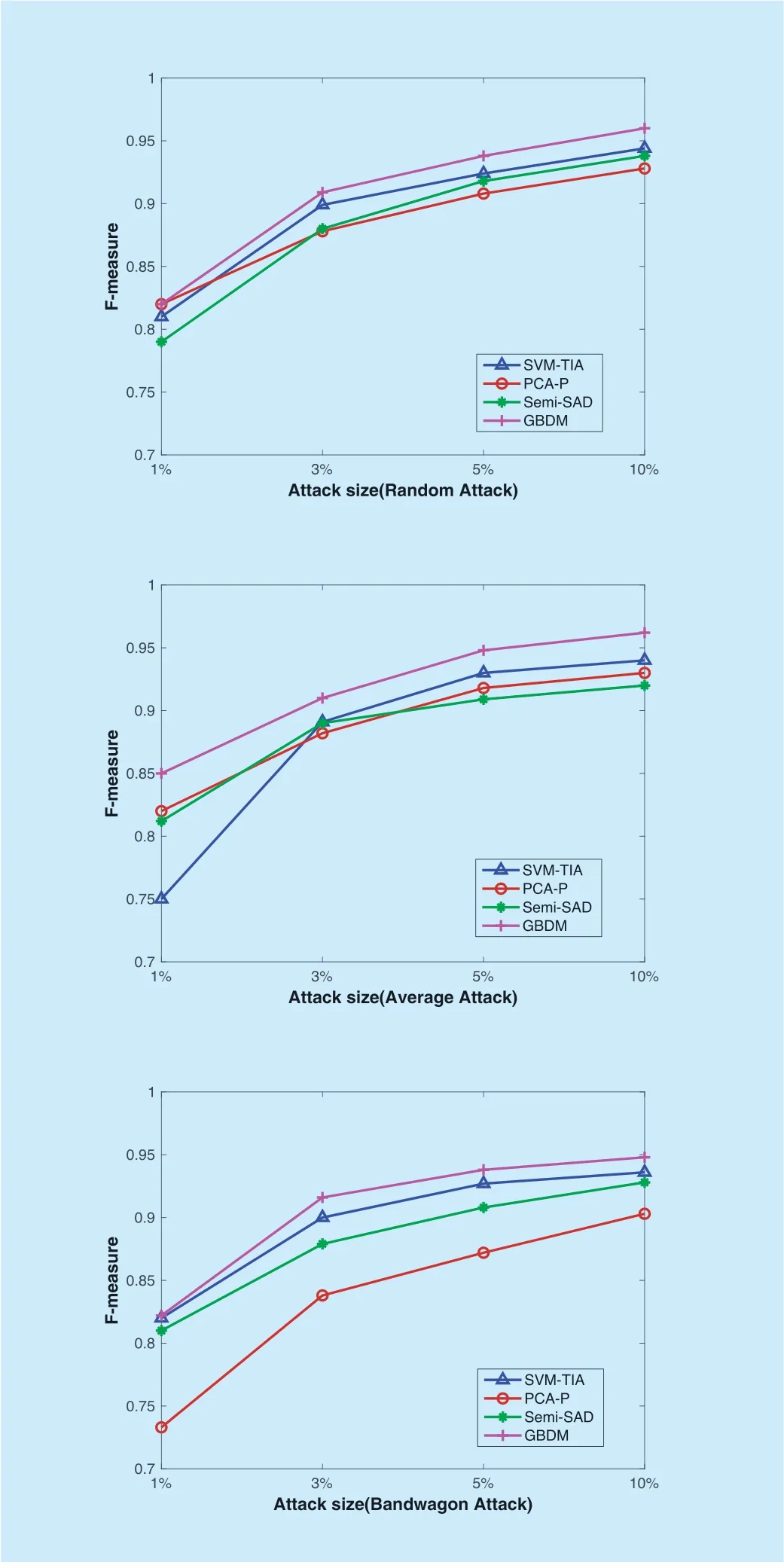
Fig.8.The performance of different detectors when the filler size is 10% and the attack size varies in nuke attack.
V.CONCLUSION
With the widespread applications of recommendation system in electronics business or social networks,the user profile injection attacks have emerged and attracted considerable attentions.Based on the principle of anti-PPC,some group attack models such asGSAGenlstrengthen the power of shilling attacks and pose a threat to the existing detectors.In order to solve this problem,a gravitation-based detection model (GBDM)againstGSAGenlis designed based on novel basic detection attributes.The detector of GBDM abandons PCC and adopts the physical models to classify and aggregate the potential group attackers through continuous online testing and tracking for abnormal items and users in the recommender system.The MovieLens data set and Amazon data set are respectively used to experimental evaluation in order to demonstrate the detection performance of GBDM.All or part of these detectors including HHTSVM,SVM-TIA,AP-UnRAP,PCA-P and Semi-SAD are selected to be compared to the GBDM detector with different filler sizes and attack sizes.On the whole,GBDM performs more satisfactory by the comparison analysis of the precision,the recall and the F-measure.
However,the phenomenon of particle degradation occurs during the tracking and prediction,which probably leads to some inaccuracies of results.How to promote the tracking effect of the particle filter algorithm and how to obtain more accurate results are the future work for further improvement.
ACKNOWLEDGMENTS
This work was supported by the National Natural Science Foundation of P.R.China (No.61672297),the Key Research and Development Program of Jiangsu Province (Social Development Program,No.BE2017742),The Sixth Talent Peaks Project of Jiangsu Province (No.DZXX-017),Jiangsu Natural Science Foundation for Excellent Young Scholar (No.BK20160089).

- China Communications的其它文章
- Distributed Optimal Control for Traffic Networks with Fog Computing
- A Sensing Layer Network Resource Allocation Model Based on Trusted Groups
- New Identity Based Proxy Re-Encryption Scheme from Lattices
- A Real Plug-and-Play Fog: Implementation of Service Placement in Wireless Multimedia Networks
- TVIDS: Trusted Virtual IDS With SGX
- Application of Neural Network in Fault Location of Optical Transport Network