
基于机器学习的贫困户识别指标体系模型研究
2019-10-08 07:21:00徐姝婧陆一啸徐嘉瑞
上海立信会计金融学院学报 2019年4期
徐姝婧,陆一啸,徐嘉瑞
(上海立信会计金融学院,上海201209)
一、引言
2018年2月12日,习近平总书记在打好精准脱贫攻坚战座谈会上指出,打好精准脱贫攻坚战是党的十九大报告提出的三大攻坚战之一,对如期全面建成小康社会,实现第一个百年奋斗目标具有十分重要的意义。
近年来,国家高度重视精准扶贫工作,出台了一系列相关政策以探求新形势下贫困村脱贫致富的方法,但我国现阶段仍缺乏科学、健全的贫困户人口识别模型。 精准扶贫在贫困对象精准识别等方面仍存在问题。 因此,贫困户精准识别模型的确立迫在眉睫。 在经济效应上,精准识别模型的确立可确保真贫困户的精准识别,有效避免人工识别不精准及人为造假的情况,避免扶贫资源的浪费。 在社会效应上,精准识别模型可以节省人力资源,提高政府扶贫工作的效率。 为此,如何建立合理的贫困识别技术,构建创新的贫困户精准识别办法,值得进一步思考和探索。
本文基于机器学习技术建立的贫困户识别新指标,能更精确地量化家庭贫困情况,准确定位真实贫困户,从而促进我国精准扶贫政策的进一步落实,推动全面小康社会的建成。
二、国内外研究现状
(一)精准扶贫政策与贫困户精准识别指标
党的十九大报告提出精准扶贫攻坚战前后,国内有诸多学者团队对精准扶贫领域进行研究。 周晓露和胡萌萌(2018)研究发现农村贫困人口的精准扶贫“瞄准偏差”现象一直未能解决,政策落实中应考虑复杂多样的乡土人情。 刘斐丽(2018)以“地方性知识”影响瞄准偏差的角度,肯定了国家精准识别政策需要与地方性知识相沟通的事实,同时进一步从精准识别执行偏差上,分析其对精准扶贫政策实施成效的影响,指出执行偏差主要由三种原因造成——政策精细化实施中过于教条、基层执行者忽视了如动态化管理和群众公认原则的弹性指标、“一刀切”的僵化执行政策。 欧阳胜(2018)以武陵山区为例,从扶贫瞄准对象识别机制的五个方面进一步完善瞄准机制的理论研究,点明扶贫瞄准机制建设中的关键环节。 王斌(2018)利用多维测度方法,评估延安市甘泉县抽样调研的贫困户家庭的脱贫指数,研究贫困户各脱贫指标对脱贫指数的贡献额和贡献率。 马志雄等(2018)在贫困人口识别指标选取上,强调要重视家庭发展能力考核指标的构建,以贫困户自身的脱贫认同作为真脱贫标准。 陆模兴等(2018)从理论研究转向模型实践,在前期基础上否定了用单一收入维度作为贫困衡量指标,基于Alkire-Foster 多维贫困测度模型选取六个维度、十二项贫困指标,考察各维度贫困对总体多维贫困的贡献度。 韩莹(2018)继续以多维贫困为基础,利用主成分分析法对绵阳市数据进行分析,建立多维贫困识别体系。
(二)精准扶贫领域的人工智能应用研究
传统扶贫依托于执行部门的执行效率与政府拨款,扶贫聚集在教育、基础设施等公共部分,但在贫困信息的更新迭代与贫困人口的精准识别上,受到地理环境、人力物力资源的较大限制。 而人工智能技术正处于跨越式发展的崭新阶段,其便利的信息整合效率、资源的可视性、低成本均为精准扶贫进程带来不可估量的现实意义。
Jean et al.(2015)研究认为夜间灯光亮度与经济发展存在紧密的内部关联,综合卷积神级网络与遥感数据实现超过90%的贫困户瞄准准确度。 彭飞霞(2016)从教育脱贫角度出发,认为人工智能独具的智能型、反馈性、精准性、有效性四大特征,对贫困生的精准定位与帮扶意义巨大。 尚纹玉(2018)分析了扶贫道路上存在的遗漏率、错配率高的两个问题,认为人工智能的应用可提高扶贫的精准性。 陆倩倩(2018)分析当前人工智能与精准扶贫的结合现状,发现人工智能基本作用于扶贫的支援方,人工智能对于扶贫工作的有效应用仍待进一步深入。
(三)评述
通过对扶贫理论与扶贫政策的梳理可以发现,国内外均高度重视国家扶贫的进展,积极推进精准扶贫政策的实施。 国内一些学者分析了目前贫困人口识别方法存在的问题,从精准识别执行偏差上探究贫困人口瞄准偏离实际的原因;另一些学者认为精准扶贫的核心机制是瞄准识别机制,从扶贫瞄准对象识别机制的五个方面,进一步完善瞄准机制的理论研究,揭示了扶贫瞄准机制建设中的关键环节。 国外学者对于精准扶贫研究较少,但已将人工智能应用于扶贫环节,研究偏向扶贫模式与扶贫理论。 但从总的来看,尽管国外对于扶贫的内涵及理论研究较为全面,但未将社会计算、人工智能深入应用于精准扶贫。 因此,如果要将精准扶贫落到实处,整合我国实际情况来制定相应的精准识别模型,应用机器学习的方法,是精准扶贫研究势在必行的新尝试。
三、多层前馈神经网络
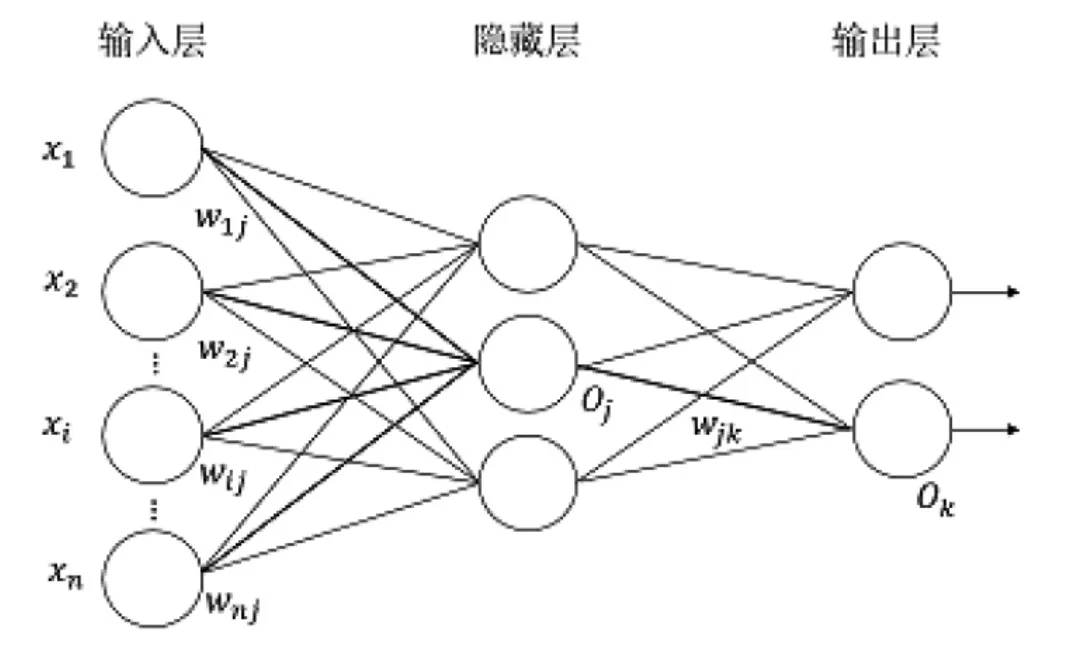
图1 多层前馈神经网络模型
多层前馈神经网络是由输入层、隐藏层和输出层组成的全连接神经网络,每一层都由多个神经元组成,神经元和上一层的神经元全连接,但是同层的神经元和神经元之间没有连接。 每一层的输出会作为下一层的输入,为考虑模型的非线性拟合能力通常还会在隐藏层之间加入激活函数。 在机器学习中需要综合多种指标进行判断,最终的结果为是或否。 在统计学中,逻辑回归被用于根据一些历史数据预测变量的各种结果对应的概率,Logistic Regression(逻辑回归)是最常用的分类算法。但是由于一般的逻辑回归有一定的局限性,通常需要通过增加组合项或高斯项来提高其分类性能,而增加组合项、高斯项就会增加工作量,为解决该问题,我们采用了神经网络。
多层前馈神经网络的学习过程就是将输入的向量沿着神经网络结构的方向逐层的正向传播至输出层,然后将实际输出与期望输出对比,测算误差值,然后进行反向传播。在反向传播过程中对各神经元的权重和偏置项进行更新(见图1)。多次循环整个过程,直到满足人为设置的最大迭代次数或者在验证集的准确度达到最高。
四、基于调研数据的精准识别指标体系构建
(一)实地调研获取数据
本次调研通过实地走访与深度访谈探究广西玉林的扶贫现状,进一步了解贫困户信息。 本次问卷调研以发放纸质问卷为主要手段,在广西玉林各村委会的大力支持下,共回收1603 份有效纸质问卷,涵盖被调研对象个人基本信息、家庭情况、享受的帮扶政策、对精准扶贫的理解与建议四个方面。
问卷设计阶段,综合国家当前贫困人口识别标准与现有精准扶贫政策,针对广西固有扶贫传统与特定贫困现状设计问卷。 问卷发放阶段,各村支书协助走访每户村民发放问卷。 问卷填写回收阶段,每份问卷加盖村委会公章,确保填写对象落实到户、个人信息真实有效。 问卷处理阶段及分析阶段,区别于传统的定性分析,运用SPSS 软件定量分析问卷数据内在联系。
(二)数据清洗
由于被调查者问卷填写不规范、对自身信息不确定、不愿公开个人信息等原因,导致调研数据库中存在一定数量的缺失值。 为提高数据的可用性,方便进一步分析问卷数据,本节进行了缺失值的研究与处理。 被调研者的个人信息、家庭信息与其贫困补助额度,数据集的字段名与数据类型如表1所示。
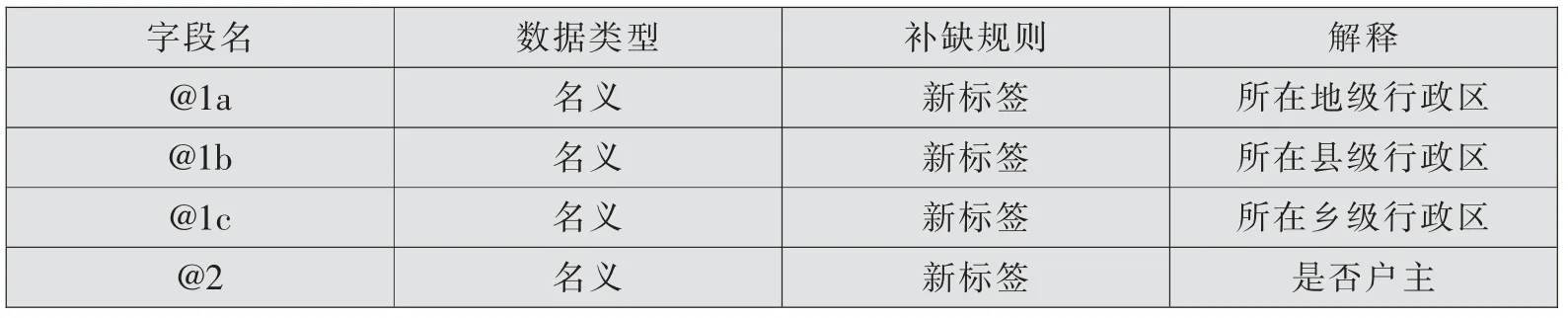
表1 数据集内容与预处理方式
images/BZ_113_339_480_399_540.png@3 名义 新标签 性别@4a 标度 0年教育支出@4b 标度 0年饮食支出@4c 标度 0年医疗支出@4d 标度 0年娱乐支出@4e 标度 0年还贷支出@6 标度 平均 家庭人口@7 标度 平均年龄@8 有序 众数 受教育程度@9 名义 新标签 工作状况@10a 标度 0 耕地面积@10b 标度 0 鱼塘面积@10c 标度 0 山林面积@10d 标度 0 果园面积@10e 标度 0 其他土地面积@11 有序 众数 生活水源@12 标度 平均 家庭年收入@13 有序 众数 住房材质@14 标度 平均 住宅面积@15 有序 众数 社区交通条件@16 有序 众数 健康状况@17 有序 众数 家庭能源@18a 名义 新标签 电器-无冰箱@18b 名义 新标签 电器-无彩电@18c 名义 新标签 电器-无洗衣机@18d 名义 新标签 电器-无热水器@18e 名义 新标签 电器-无空调@18f 名义 新标签 电器-无智能手机@18g 名义 新标签 电器-无计算机@18h 名义 新标签 车辆-无电动& 摩托车@18i 名义 新标签 车辆-无小轿车@18j 名义 新标签 车辆-无货车@18k 名义 新标签 电器& 车辆-全部拥有@19a 名义 新标签 收入来源-农业生产@19b 名义 新标签 收入来源-经商@19c 名义 新标签 收入来源-工资提成@19d 名义 新标签 收入来源-临时劳动@19e 名义 新标签 收入来源-社会福利@19f 名义 新标签 收入来源-亲友援助@19g 名义 新标签 收入来源-其他
images/BZ_114_351_531_367_561.png@21a 名义 新标签 社保-无保障@21b 名义 新标签 社保-五险一金@21c 名义 新标签 社保-低保@21d 名义 新标签 社保-新农养老@21e 名义 新标签 社保-新农合作医疗@21f 名义 新标签 社保-农村五保@21g 名义 新标签 社保-农村医疗救助@21h 名义 新标签 社保-其他@26 标度 0 扶贫补贴金额
根据表1中所列的缺失值填充规则,将数据集中的缺失值补充完整。 将名义字段通过数值化字典换成整数值标签,以便神经网络模型能更好地完成分类任务。 玉林市数据集的文本转换字典如表2所示。
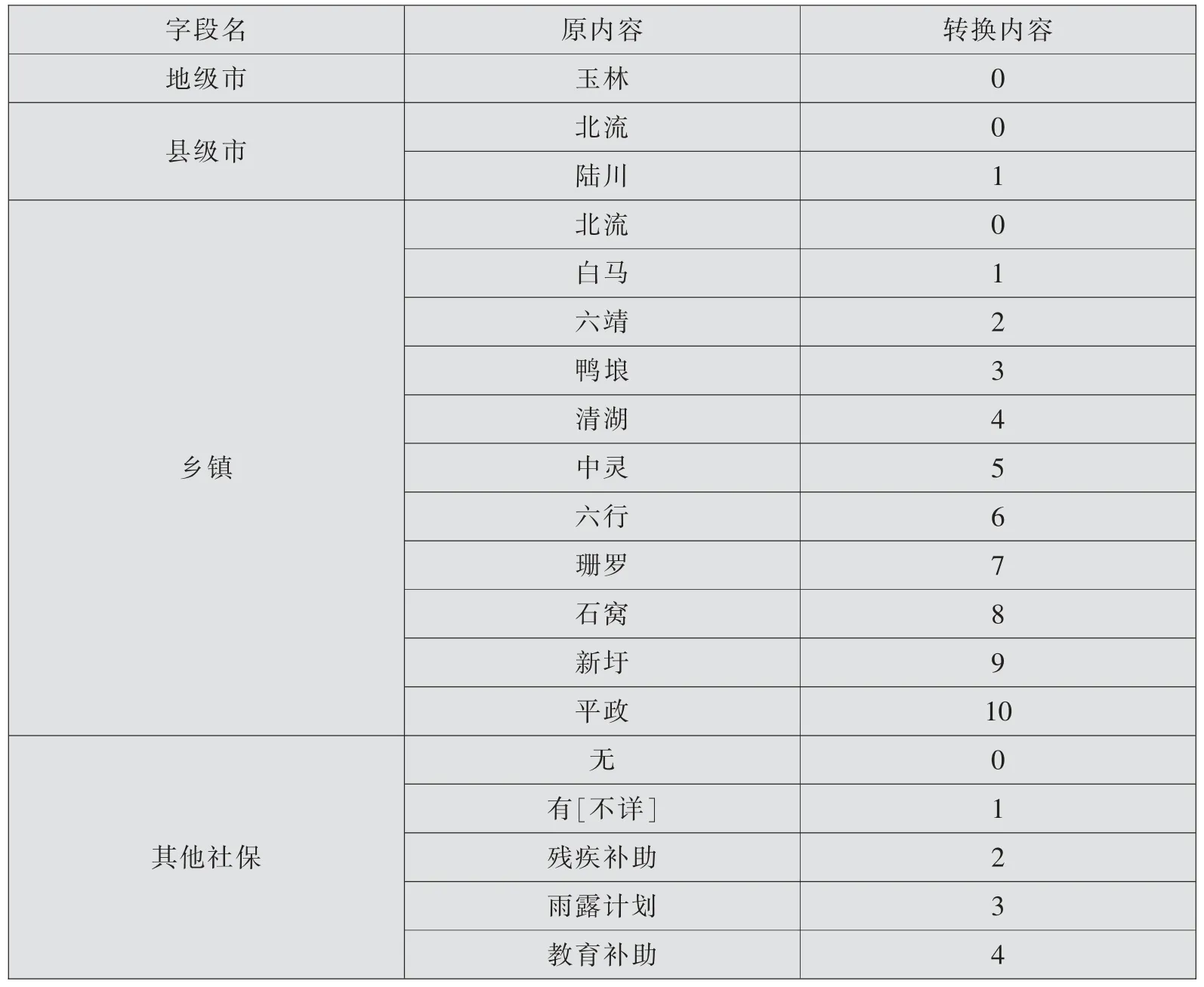
表2 玉林市数据集文本转换字典
对调研过程中产生的偶然误差采用人工修正,对明显错误值纠正,例如误把收入“元”当作“万元”等。如果错误较难改正,按缺失值处理。然后对被填写了多个值的单选题,根据实际情况删去。对标度字段范围超过μ±3σ 的值,人工核验该问卷答案,其中μ 为均值,σ 为标准差。
(二)数据分析
1.基于因子分析的指标提取
通过因子分析的方法,确定贫困认定指标,将问卷信息以一组指标来概括,形成具有当地特色的贫困户精准识别认定指标。
为兼顾指标的简洁性与全面性,对因子分析中得到的每个因子,取原始特征值作出碎石图。 图中横轴是显著性从强到弱的因子,纵轴是因子的原始特征值,值越大的因子在描绘数据特征中贡献度越大。 曲线下降速度显著减缓的地方,就是贡献度较大的因子与其他因子的分界,取该截断点之前的因子为主成分。 玉林市数据的因子分析碎石图如图2所示。
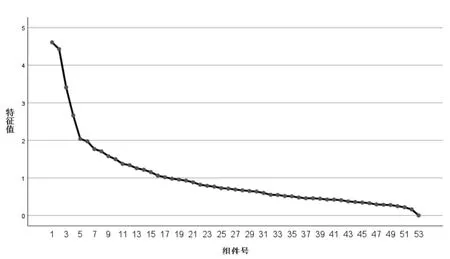
图2 玉林市数据碎石图
综合数据分析,将贫困户精准识别的指标数定为6 个。 经检验,前6 个因子的公因子特征值均大于1,而第7 个之后的因子特征值小于1,说明前6 个因子的影响是显著的。 接着对数据作因子分析,取前6 个主要的因子,定义贫困户精准识别指标。
因子分析将原来51 项属性变换为6 项主要指标,由于贫困补助额度是外生的因变量,而数据已依据玉林市属性处理,因此这2 项属性未参与指标提取。 通过因子最大方差得分可知,提取的6 项指标通过原来数据12%的信息量概括了30%的数据特征。 虽然各种变量包含的信息密度不同,但这6 项指标实际上已包括了识别贫困户所需的大部分信息。 作出成分矩阵,计算每项指标中具体包含原来各项属性的比例。 玉林市数据的成分矩阵如表3所示。
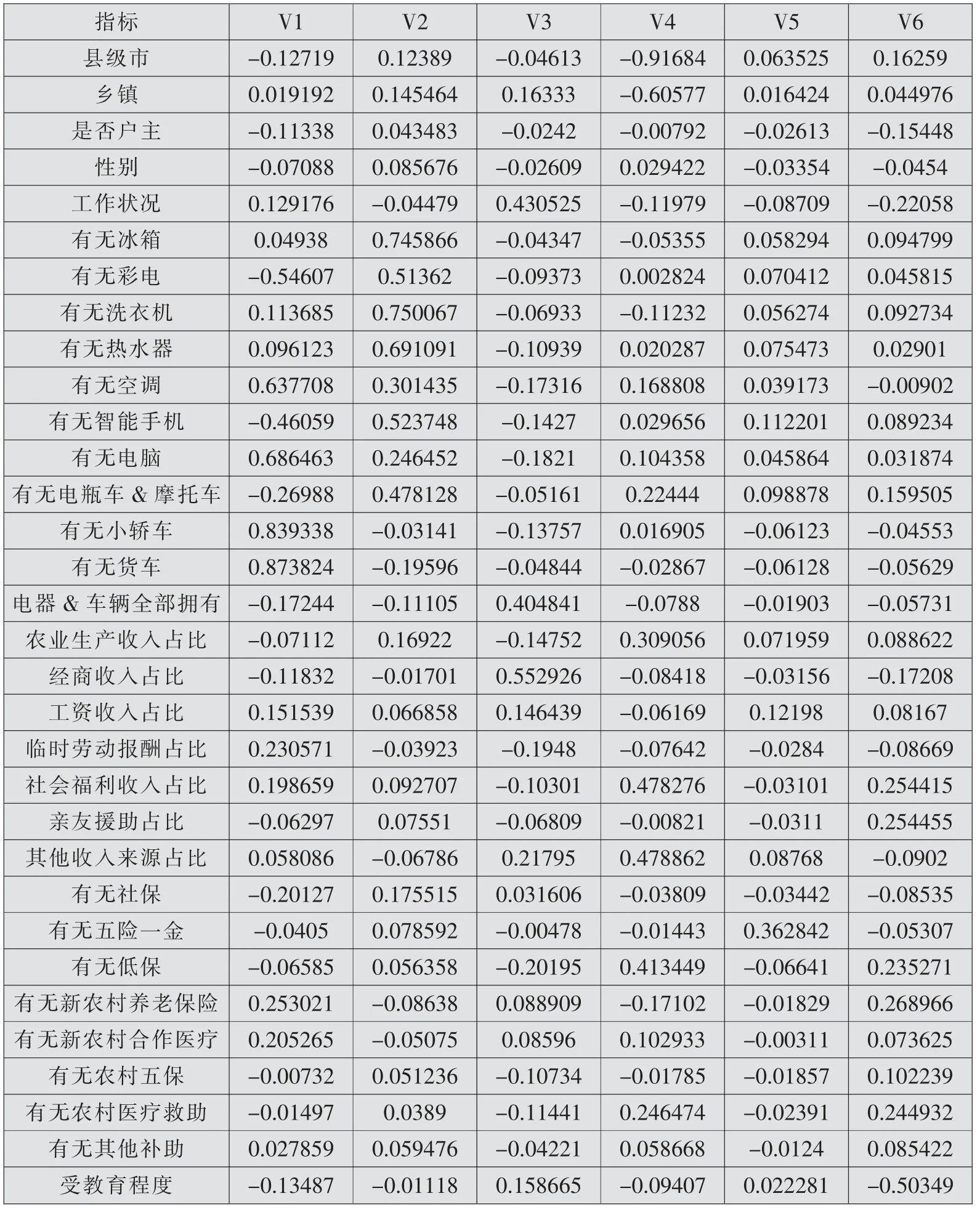
表3 玉林市数据成分矩阵
基于以上成分矩阵,根据信息密度的不同,分名义、有序、标度三种字段,分别选择在每个指标中绝对值占有成分较大的属性,综合定义每个贫困户精准识别指标。指标的定义过程分别如表4所示。
2.改进Lasso 回归的指标权重计算
通过之前的因子分析,得出各项贫困认定指标的公因子得分,而指标的重要性与公因子得分成正比,各指标的相对重要性如表5所示。
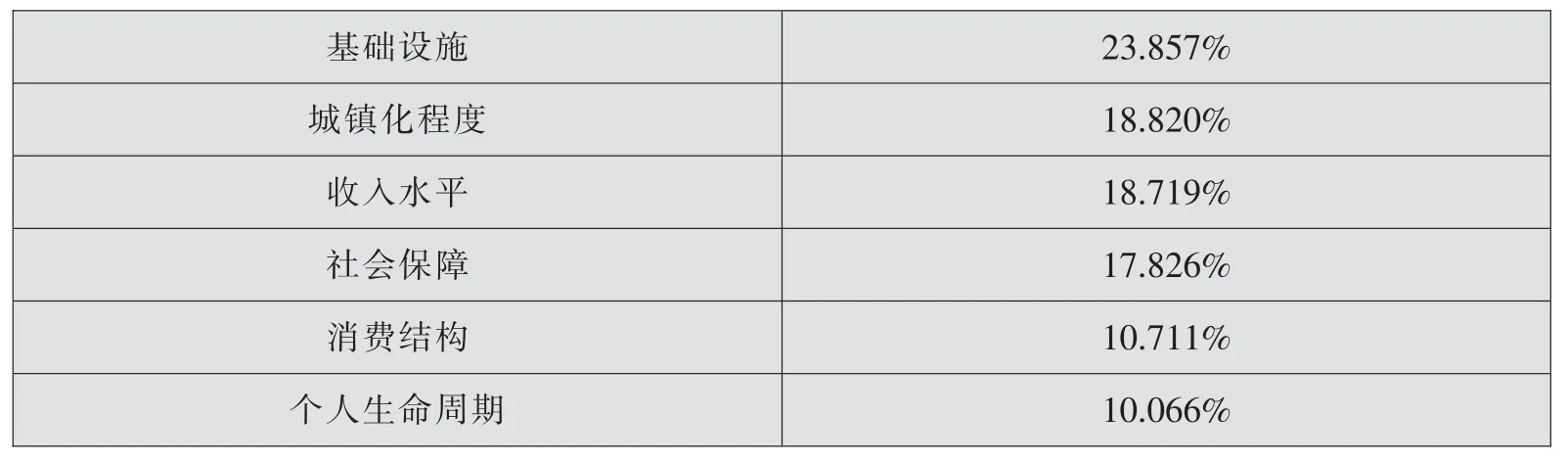
表5 贫困户精准识别指标相对重要性
各地对贫困程度的量化评定通常使用线性回归模型,得到形如(1)式的表达式:

从调研所得的信息中提取综合指标,而非简单筛选指标时,必须对其取值作标准化。此时X~N(0,1),而b 为人均贫困补助额度。为防止某些指标在贫困补助认定中是无效的,使用Lasso 回归搜寻目标函数JL(w)的最小值。

使用创新方法完成α 的自适应。建立Lasso 回归模型,在给定α 时将使目标函数取得最小值的记作最优解y*,即:

接着定义回归损失:

整理公式(2)、公式(3)和公式(4),建立优化函数:

使用Nelder-Mead 算法搜索函数f 的最小值,初始解α=0,经过迭代使L 收敛时α 即为最优的参数。 本算法的实际意义是,在不增加人为干预的情况下,通过调整对贫困认定指标的依赖程度,找到模型在符合当地实际的程度与普适性之间的平衡,使得模型面对新数据时的相对剩余最小,实现模型迁移。
在玉林市数据中,经过迭代α*=0,L*=84%,贫困补助额度y 与各指标V1~V6的关系是:
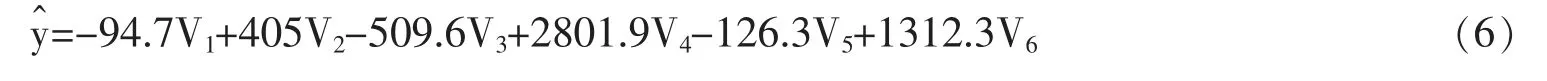
由以上分析可知,各指标没有出现稀疏性,证明指标的选择科学。 而解的相对剩余非常大,说明贫困补助额度不能被各指标线性表示。这是由于贫困户的经济条件和社会环境,会通过一些复杂和隐藏的过程,体现在贫困程度上。 由于上述Lasso 模型只能发现线性关系,故通过讨论神经网络模型,发现在贫困户精准识别指标体系,探究被调研者的数据与贫困补助额度之间的隐含关系。
五、模型实现效果
将被调研的人分为两类:第一类是获得精准扶贫补助的贫困户;第二类是未获得精准扶贫补助的非贫困户,通过神经网络作二分类预测。 以玉林市调研所得数据为例,通过神经网络模型预测被调研者是否贫困。 数据的自变量是被调研者关于6项贫困户精准识别指标的表现,因变量则为一个是否贫困的标签,神经网络参数如表6所示。
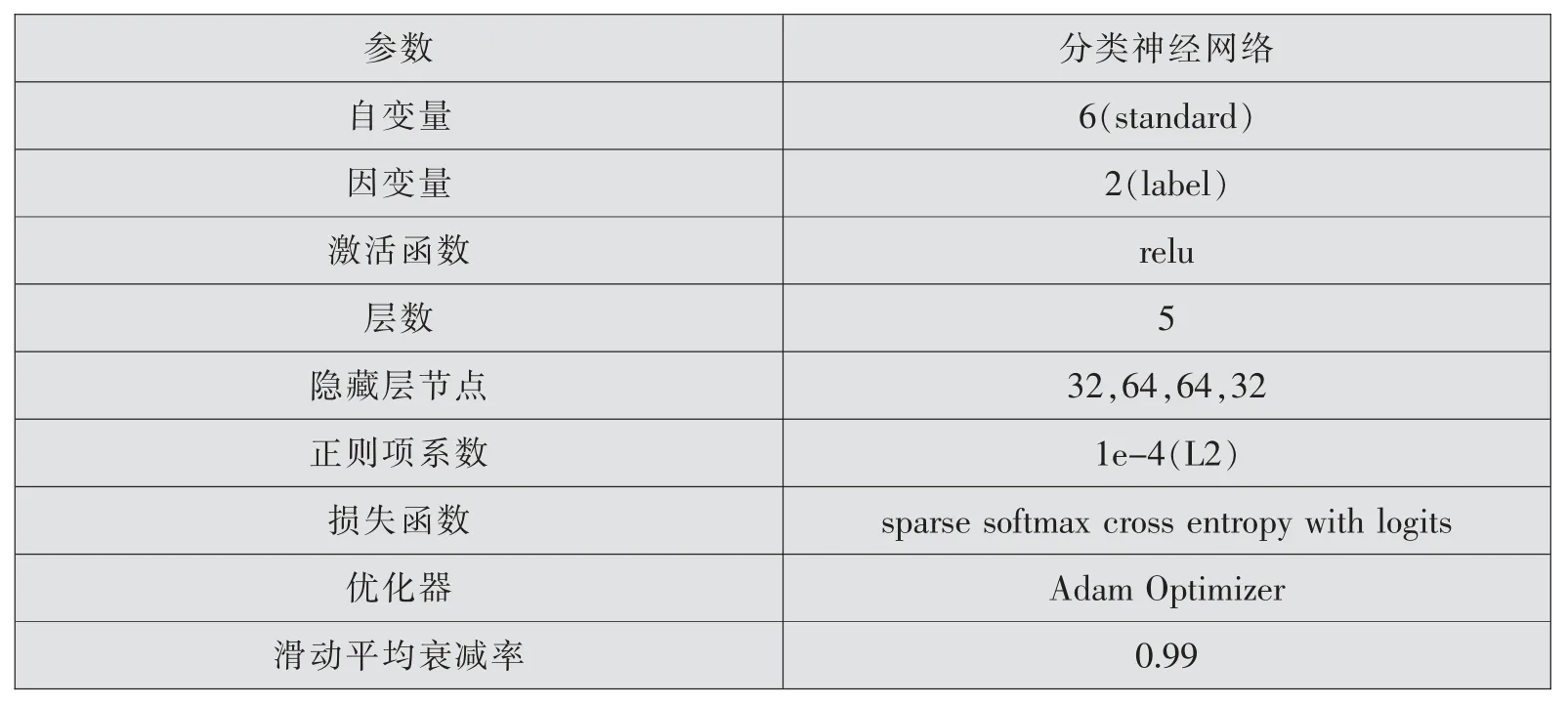
表6 贫困与否预测神经网络参数
对玉林市被调研者的603 条数据进行处理,把数据随机分为数量相当的10 组,取其中9 组建立和优化模型,剩余1 组为验证集,以验证模型在新数据上的表现。 选择不同的验证集重复以上实验5 次,预训练后在验证集上得到的相对剩余如表7所示。
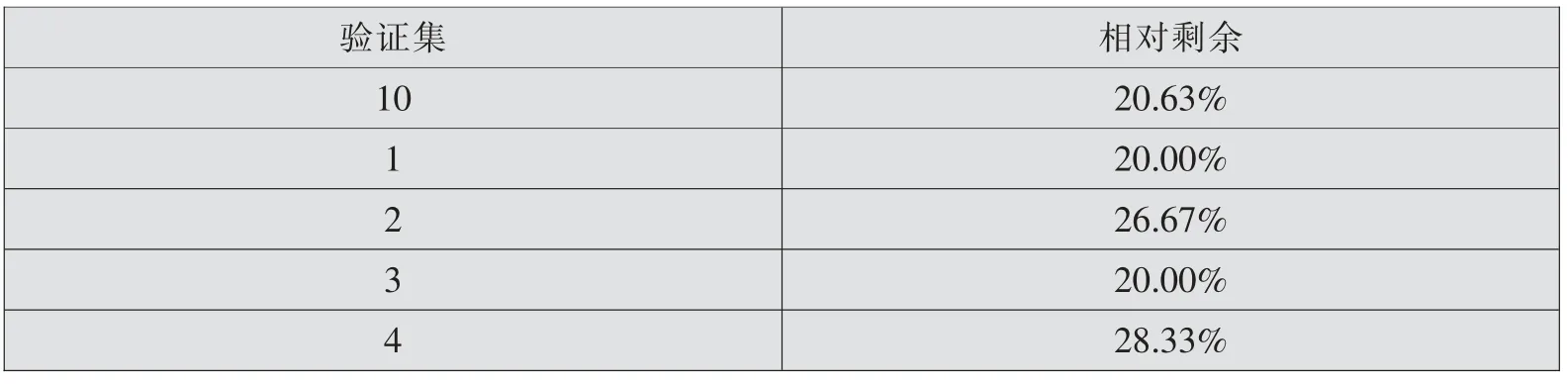
表7 贫困与否预测分组轮替实验相对剩余
若模型在验证集上的相对剩余较高,则可能由两种情况导致:一是模型缺陷,二是数据质量较差。 当模型有缺陷时,该模型在不同验证集上的相对剩余差距较大,而当数据质量较差时,该模型在不同验证集上的相对剩余是稳定的。 由表7可知,模型在不同的数据集上表现是稳定的,最优达到了20%的剩余,并且每次实验的剩余均小于30%,因此导致本模型相对剩余较高的原因更可能是数据质量较差而非模型缺陷。
验证结果表明,贫困户的认定与从其数据中挖掘出的规律,存在一定的不统一性。 这可能由于政策实施时信息采集误差、操作错误,及政策制定未根据当地实际情况变化及时调整所致。 通过本模型,扶贫机构只需采集一些被调研者的经济数据优化模型,模型便可更贴近当地实际情况,即通过当地整体居民信息预测其贫困情况。
六、结论
本文基于神经网络模型,实现居民贫困情况的预测。 该模型可大幅降低扶贫机构识别贫困户的工作量,提供相较于人工审核,更为科学、透明、高效的方法。
按本次调研提出的方法,扶贫机构需要收集当地部分居民的个人经济信息,运用此模型建立针对当地情况的贫困户精准识别新指标体系,并仅需当地一部分数据,便可得出此地主要的贫困情况。 完成以上分析后,贫困户精准识别模型能继续自动地预测其余居民的贫困情况,从而实现机器与人工协同识别贫困户,大幅减少扶贫机构在贫困户精准识别工作中的人力物力投入,降低贫困户认定成本。
猜你喜欢
玉溪师范学院学报(2023年3期)2023-08-31 14:11:56
音乐教育与创作(2020年3期)2020-05-13 06:47:08
好日子(2018年9期)2018-10-12 09:57:18
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
公民与法治(2016年10期)2016-05-17 04:12:58
河北工业大学学报(2016年6期)2016-04-16 02:54:19
计算机工程(2015年8期)2015-07-03 12:20:27
当代县域经济(2015年12期)2015-03-20 15:51:23
技术经济(2014年10期)2014-02-28 01:30:01
