
基于DNN-HMM的陆空通话声学模型构建方法
2019-09-28 07:01:10杨金锋李凯涛贾桂敏师一华
中国民航大学学报 2019年4期
杨金锋,李凯涛,贾桂敏,师一华
(中国民航大学天津市智能信号与图像处理重点实验室,天津 300300)
2010年美国国家航空航天局的调查报告显示,由于陆空通话内容不正确、用语不规范、信息纰漏、复述错误或无复述造成的民航飞行事故所占比例分别为14%、9.9%、5.5%和13%[1]。将语音识别技术应用到民航陆空通话中,通话内容可转换为相应文本,辅助飞行员正确地理解管制员的指令,从而保障飞行安全。但通用语音识别声学模型无法直接应用到陆空通话中,这是由民航陆空通话语法规则不同于通用语音决定的。民航陆空通话主要规则[2-3]如下:①通话过程中对字母、数字及呼号有特定的发音标准,如1 读作幺,A 读作ALPHA 等;②陆空通话语法规则较为固定,管制员发出的指令,飞行员应予复诵,复诵必须包括指令与飞行器呼号,且呼号后置等。目前,针对中文陆空通话语音识别和声学建模的研究较少,且大多集中在陆空通话关键词的语音识别和基于传统高斯混合模型-隐马尔可夫模型(GMM-HMM,Gaussian mixture modelhidden markov model)的声学建模[4]。因此,利用深度神经网络(DNN,deep neural networks)[5]对中文陆空通话连续语音识别的声学建模问题展开研究,提出一种基于深度神经网络-隐马尔可夫模型(DNN-HMM)[6-8]的陆空通话声学模型构建方法。
声学模型是语音识别系统的重要组成部分。由于语音信号特征序列的产生类似于隐马尔可夫(HMM)[9]状态转移过程,传统声学模型使用GMM-HMM 进行构建。深度学习算法中的神经网络结构具有强大的信息分析和提取能力,在语音识别领域有着广泛应用。卷积神经网络(CNN,convolutional neural networks)[10]各隐层之间非全连接,通过卷积核卷积计算降低特征维度;长短时记忆网络(LSTM,long short-term memory)[11]各隐层之间为全连接,且可得到时序信息,但计算复杂度较高。较之CNN 与LSTM,DNN 结构更加简单且更易实现,各隐层之间全连接能够保留更多信息。语音特征作为声学模型的输入,对其性能也有重大的影响,常用的语音特征有Fbank(filter-bank)、梅尔倒谱系数(MFCC, Mel frequency cepstrum coefficient)等[12]。好的语音特征应该具有优秀的区分性,主要体现在声学模型利用不同的建模单元建模时,具有较强的鲁棒性[13]。
陆空通话语法规则较为固定,即使不使用复杂的网络,也能取得很好的识别效果,因此可利用DNN-HMM构建陆空通话声学模型。为提高输入语音特征的区分度并减少说话人口音对声学建模的影响,利用线性判别分析(LDA,linear discriminant analysis)、特征空间最大似然回归(FMLLR,feature-space maximum likelihood linear regression)和说话人自适应训练(SAT, speaker adaptive training)对模型输入的语音特征进行增强,从而提高声学模型的性能。利用项目组建立的中文陆空通话数据库,通过实验对比分析不同语音特征、特征维数和连接帧数对陆空通话声学模型的影响。实验结果表明,提出的基于DNN-HMM 的陆空通话声学模型与传统方法相比具有更低的音素错误率。
1 DNN 模型的基本原理
DNN 是由受限玻尔兹曼机(RBM,restricted Boltzmann machine)叠加而成的一种自底向上训练的网络模型[14],其结构如图1 所示。通过无监督训练生成DNN模型的初始权重,再通过有监督训练,利用各层之间的连接关系,使用期望输出与实际输出之间的误差自顶向下逐层传递,不断调整网络参数,完成整个网络的训练。RBM 是一种无向网络模型,其训练的关键在于训练网络中各层之间的连接参数。RBM 由包含随机节点的输入层与服从二值分布的隐层相连接而构成,其能量函数为
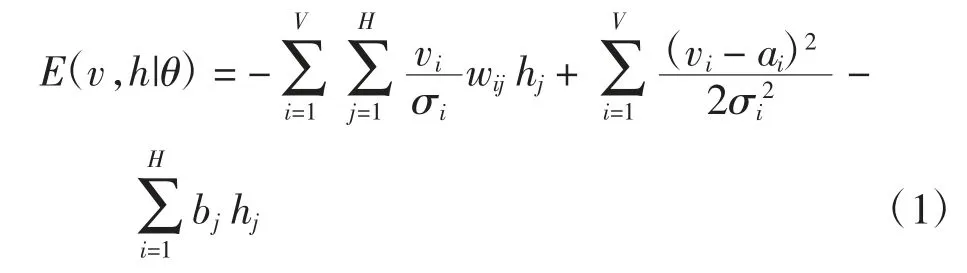
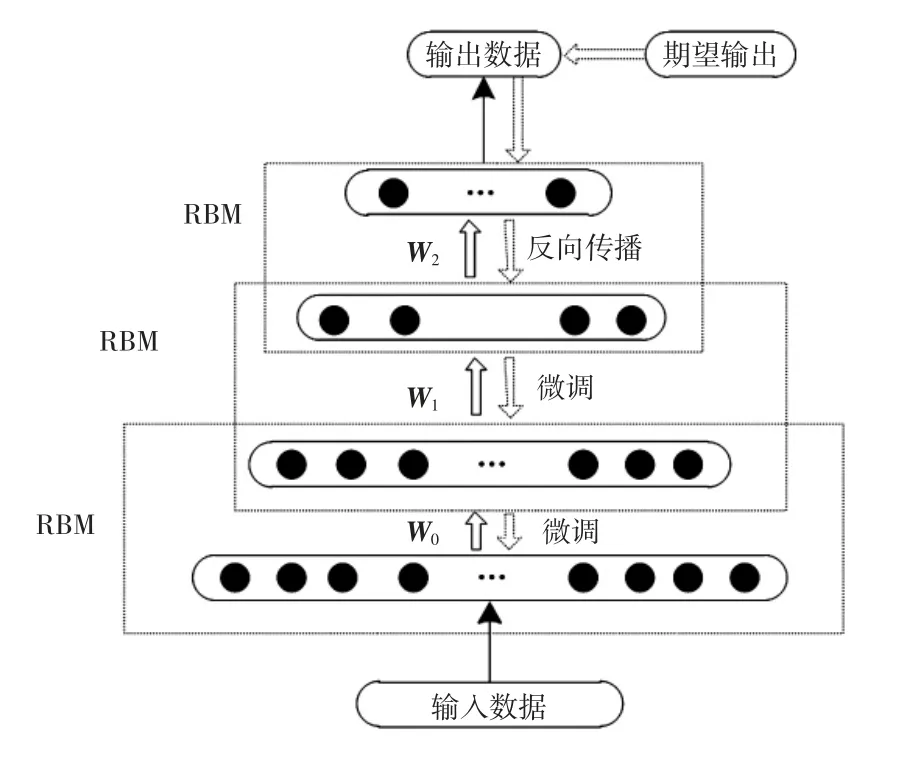
图1 DNN 结构图Fig.1 DNN structure diagram
其中:v 为输入层状态参数;h 为隐层状态参数;θ={ai,bj,wij}表示每个RBM 的参数集合;ai表示输入层第i个输入单元的偏移量、bj表示隐层第j 个隐含单元的偏移量;wij表示第i 个输入单元和第j 个隐层单元之间的连接权重,且wij=wj;vi表示第i 个输入单元状态;hj表示第j 个隐层单元状态;V 表示输入层节点个数;H表示隐层节点个数。似然函数P(v|θ)和归一化因子Z(θ)为
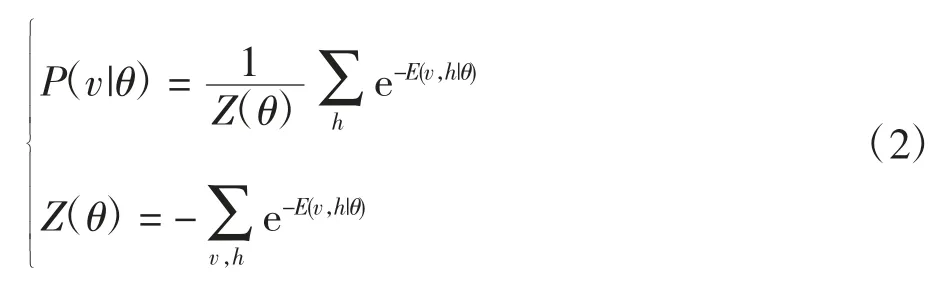
若已知输入层各个节点,根据输入和连接权重值,可求隐层第j 个单元的激活概率为

其中:激活函数σ(x)=1/(1+exp(-x))。由于RBM 是无向网络,输入层第i 个单元的激活概率为
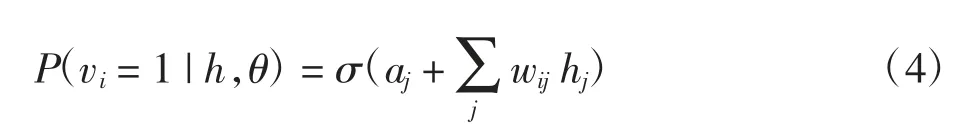
要得到输入样本的分布,可利用RBM 训练样本的最大似然函数对数值估算参数θ 的近似值θ*,即

其中:L 为对数函数;T 为训练样本的数目。
使用训练样本初始化输入单元的各个状态,计算得到隐层各单元的状态,再根据隐层各单元的状态反向推测出输入单元的状态,完成单层RBM 网络的参数更新和训练。将计算所得输出状态作为下一个RBM的输入数据,以此类推完成DNN 网络的训练。
2 陆空通话声学模型
2.1 基于DNN-HMM 的陆空通话声学模型
与传统声学模型相比,基于DNN-HMM 的陆空通话声学模型不需要对陆空通话的分布进行高斯拟合,利用DNN 估计HMM 状态的后验概率分布,有利于利用语音相邻帧之间的结构信息[15]。对陆空通话进行声学建模时,首先根据语料库标注的音素信息,将陆空通话的各个音素映射为HMM 结构的各个状态,音素序列随时间变化的过程构成了HMM 状态转移过程。然后,利用陆空通话语料库标注的音素信息作为期望输出,根据DNN 模型训练基本方法可得到DNN 模型的输出。最后,给定陆空通话语音信号,设在t 时刻处于状态sj,定义前向概率αt(sj)和后向概率βt(sj),计算状态占有概率γt(sj)和每一时刻的状态转移概率,找出每一个语音特征的后验概率并映射为HMM 状态,与DNN 的softmax 输出相对应,完成基于DNN-HMM 的陆空通话语音识别声学模型的构建。一个M 隐层的DNN-HMM 框架[16]如图2 所示。
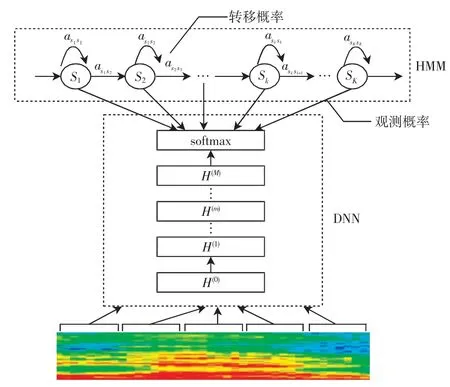
图2 DNN-HMM 框架图Fig.2 DNN-HMM schematic diagram
2.2 陆空通话语音特征提取
将不同的语音特征作为DNN-HMM 模型的输入,会影响陆空通话声学模型的性能。语音识别大多使用MFCC 特征和Fbank 特征作为声学模型的输入。Fbank特征与MFCC 特征相比没有进行离散余弦变换(DCT,discrete cosine transform),从而减少语音特征在时域的前后关联性丢失[17]。因此,采用Fbank 特征构建基于DNN-HMM 的陆空通话声学模型,同时,利用LDA、SAT、FMLLR 3种语音特征变换方法,增加语音特征的区分性并减少说话人口音的影响。
语音信号是时变的非平稳信号,通过分帧加窗转换成短时平稳信号进行处理。由于实际民航陆空通话语速明显快于日常对话,语音信号帧长设置为10 ms,帧移设为帧长的50%;使用过零点端点检测技术提取陆空通话语音信号的语音段,去除非语音段;再通过预加重处理来提升语音信号的高频分量。对每一帧信号进行离散傅里叶变换(DFT,discrete Fourier transform),然后输入到39 个等带宽的三角状带通滤波器,计算39 个滤波器输出能量的对数与每一帧语音信号的总能量,共同构成一个40 维的Fbank 特征。Fbank 特征提取流程如图3 所示。

图3 Fbank 特征提取提取流程Fig.3 Fbank feature extraction flow chart
3 实验及分析
3.1 民航陆空通话语料库
根据民航陆空通话标准,以实际陆空通话录音和相关课程教材作为建立语料库的原始参考,建立中文陆空通话语料库。该语料库由空管专业学生与一线管制员共同录制(共21 人,男性15 名,女性6 名,每人录音640 句),包含飞行各阶段的民航陆空通话录音。该语料库共包含13 400 条音频文件,容量为4 G。录音格式为:采样率8 kHz,比特率256 kbps,单声道,wav 格式。
3.2 实验结果与分析
一般使用音素错误率[18](PER,phoneme error rate)作为声学模型评价标准。其计算公式为

其中:Ci、Cs、Cd分别为插入、替换和删除音素的个数;C为标准音素序列中音素的总数。
陆空通话声学模型构建中,每人录制500 条语句(共10 500 条)作为模型的训练数据,每人剩余的140条(共2 940 条)作为模型的测试数据。通过对训练数据进行音素标注,使用标注信息作为DNN 模型的期望输出,调整网络结构和参数,完成DNN 网络的训练。同时,作为先验信息计算HMM 的结构,从而完成基于DNN-HMM 的陆空通话声学模型构建。
模型初始学习率为0.008,初始权重为0.5,包含4个隐层,每层节点数为1 024,利用sigmod 函数作为模型激活函数。若每帧语音信号的Fbank 特征为40 维,使用当前帧及其前后5 帧连接共11 帧的语音特征作为输入,输出特征为3 642 维。将提取的语音特征作为模型输入,音素作为基元,使用最大似然估计准则训练并搭建上下文相关的三音素模型,然后对搭建好的三音素模型的语音特征做LDA、SAT、FMLLR 变换(增强变换),增加语音特征的鲁棒性。
为确定陆空通话DNN-HMM 声学模型的最优输入,分别利用MFCC 特征、Fbank 特征及二者增强变换后得到的语音特征作为模型输入,对比声学模型的音素错误率,如表1 所示。从表1 可看出,Fbank 特征更适合作为基于DNN-HMM 的陆空通话声学模型的输入,这是由于基于DNN-HMM 的声学模型不需要做高斯拟合,Fbank 特征更多地保留了原始语音信号的相关信息,可使深度神经网络更好地利用音素的前后相关性,更精确地确定输出特征所对应的音素。同时,通过语音特征增强变换,可进一步降低音素识别错误率。因此,在后续实验中均采用增强变换后的Fbank特征作陆空通话声学模型的输入。

表1 不同语音特征输入DNN-HMM 模型的音素识别Tab.1 Phoneme idenfification of different speech features input to NDD-HMM %
声学模型输入维数对模型的训练十分重要。如果输入维数过大,会造成过度拟合;而输入维数过小会造成拟合不够。在陆空通话声学模型的构建中,固定连接帧数为11 帧,对比不同Fbank 特征维数对音素识别错误率的影响,如表2 所示。

表2 Fbank 特征维数对音素识别错误率的影响Tab.2 Effect of Fbank dimension on error rate of phoneme identification %
当固定每一帧语音信号的Fbank 特征维数时,不同的前后连接帧数对陆空通话声学模型构建也有较大影响,如表3 所示。从表2~表3 可看出,输入特征向量长度为40×11(前后连接11 帧,每一帧包含40 维的Fbank 特征),基于DNN-HMM 的陆空通话声学模型音素错误率最低。

表3 连接帧数目对音素错误率的影响Tab.3 Effect of frames link size on error rate of phoneme identification %
将所提方法与传统GMM-HMM 模型的声学模型构建方法进行对比,在陆空通话语料库上进行实验分析,音素识别结果如表4 所示。从表4 可看出,所提方法的音素错误率更低,更适合陆空通话语音信号的声学建模。需要指出的是,目前的陆空通话数据库规模仍然较小,随着数据库规模的增大,根据相关语音识别工作的实验结论可知,基于DNN-HMM 的陆空通话声学模型优势将更明显。
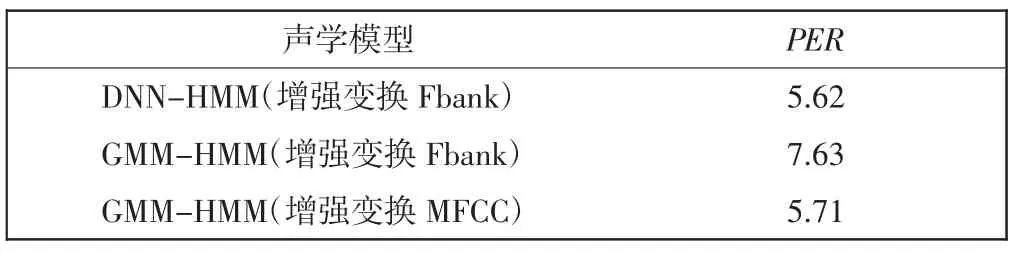
表4 不同声学模型的音素识别Tab.4 Phoneme identification of different acoustic models %
4 结语
针对中文陆空通话语音识别声学模型的构建问题展开研究。建立了中文陆空通话语料库,利用DNN模型对陆空通话语音特征进行建模,采用增强变换后的Fbank 语音特征作为声学模型输入,通过实验对比分析给出一种适用于中文陆空通话声学模型的构建方法。与MFCC 特征相比,Fbank 特征更适合基于DNN 模型的声学建模,且经过特征增强后可以使音素识别错误率进一步降低。对于现有语料库,当采用40×11 的增强变换Fbank 特征作为输入时,基于DNNHMM 的陆空通话声学模型音素识别错误率低于传统GMM-HMM 声学模型,可降低至5.62%。
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
北京教育·普教版(2020年9期)2020-10-09 11:15:09
校园英语·中旬(2019年11期)2019-11-26 10:01:06
电子制作(2019年15期)2019-08-27 01:11:48
人民珠江(2019年4期)2019-04-20 02:32:00
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
科技视界(2017年8期)2017-07-31 12:55:51
学苑创造·B版(2015年10期)2015-11-13 13:14:03
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
