
基于图像处理的棉亚麻纤维的自动检测
2019-09-11 11:09赵宇涛黄仰东邓中民
棉纺织技术 2019年9期
赵宇涛 黄仰东 邓中民
(武汉纺织大学,湖北武汉,430200)
麻纤维具有吸湿性好、导湿快、强度高等优点,但纯麻织物具有刺痒感,因此麻纤维大多与棉纤维混纺成为棉麻织物[1]。在生产、贸易与检验环节中,棉麻纤维在混纺纱中的种类及含量需要进行准确的标注。目前的纤维识别机构普遍运用显微镜直接计数法来测定棉麻混纺纱的混纺比,但此方法的缺点明显:人工计数耗时长,受识别人员主观影响较大[2-3]。本课题将棉亚麻纤维图像在Matlab中进行预处理,提取纤维特征值后对特征值进行比较分析,最后将特征值参数输入BP神经网络进行学习。通过6特征参数6阈值与BP神经网络的组合识别模式,最终有效地提高识别精度及识别效率,为实现棉亚麻纤维的自动化检测提供参考。
1 棉亚麻纤维纵向切片图像的提取
采用Y172型哈氏纤维切片器,随机截取棉亚麻混纺样品中长度约为0.4 mm的一段,在显微镜图像中截取竖直的单根纤维。显微镜下截取的部分棉纤维和亚麻纤维见图1。

(a) 棉纤维
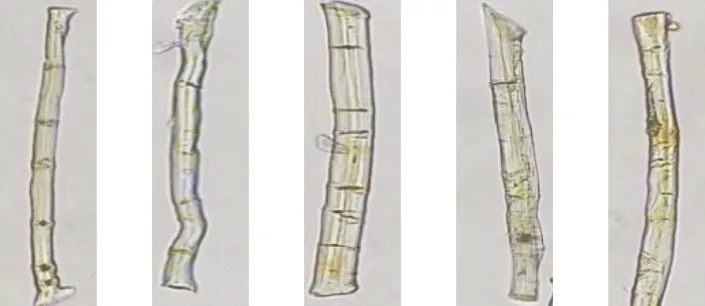
(b) 亚麻纤维
图1 截取的部分棉纤维与亚麻纤维显微镜图像
2 纤维图像的预处理
纤维图像在采集过程中,时常会遭遇光照不匀、噪声或纤维不在同一水平面引起的重叠虚影。为了消除这些对后续提取纤维特征参数造成的不良影响,需要对纤维图像进行预处理,包括图像的灰度化处理、杂质噪声滤除、图像增强处理、图像偏斜矫正以及图像边缘提取与修补。
2.1 灰度化处理
棉纤维与亚麻纤维之间的特征差异主要集中于纤维结构上的差异,因此在特征值的提取上,颜色差异不在特征值提取范围内。灰度图即为图像中RGB三个分量数值相等[4]。由于彩色图像的存储量为灰度图像的3倍,为了提高图像预处理的效率,需将彩色的棉纤维与亚麻纤维图像进行灰度化处理。
灰度化处理通过加权平均值法得到灰度图像,其运行效率更高,处理后的灰度图像更清晰柔和。棉纤维与亚麻纤维进行灰度化处理后的图像见图2。
(a)棉纤维 (b)亚麻纤维
图2 棉纤维与亚麻纤维进行灰度化处理后的图像
2.2 噪声消除及图像增强处理
经由灰度化处理后的棉纤维与亚麻纤维图像仍然有许多噪声,如纤维图像中的气泡杂质等,噪声的存在会对纤维图像的识别造成干扰。通过平滑处理的均值滤波方法可以有效去除噪声,其方法运算简单,易于实现,而且能较好地保护边界,有利于后续的边缘提取[5]。
显微镜下观察到的纤维图像特征不突出,为了提取棉纤维与亚麻纤维的局部细节特征,提高识别的准确率,需要对纤维图像进行增强处理,以强化特征。通过改变纤维图像的直方图来进行图像的增强处理是比较常用的方法,纤维图像的灰度直方图在低灰度值区间上的情况较多,因此需要进行直方图均衡化,使灰度区间和灰度级增大,增强较暗处的细节特征[6]。
棉纤维与亚麻纤维图像进行噪声消除和增强处理后的图像见图3。
(a)棉纤维 (b)亚麻纤维
图3 棉纤维与亚麻纤维噪声消除和增强处理后图像
2.3 二值化处理
二值化处理是将纤维图像由灰度图像转化为二值化后的黑白图像。将图像进行二值化后,图像的边缘提取将能更有效地进行,其轮廓特征也更容易识别。棉纤维与亚麻纤维进行二值化后的纤维图像见图4。
(a)棉纤维 (b)亚麻纤维
图4 棉纤维与亚麻纤维二值化处理后的图像
2.4 偏斜矫正
在纤维图像的拍摄和截取过程中,绝大多数纤维不是处于水平或竖直方向的,无序的排列会对识别过程有极大的干扰,例如在亚麻纤维识别过程中,倾斜的亚麻纤维可能会使计算机将亚麻纤维的横节部分错误地识别为外部边缘部分,引起错误的结果。纤维图像的偏斜角度不同,会造成识别结果的精准度有所降低,识别过程所需要的时间也将增长。
在Matlab软件中,利用imrotate函数,可以实现纤维图像的偏斜矫正。通过识别两种纤维在整个图像中的最大横行数与最小横行数中的像素所在列的大小,可以判断纤维的倾斜角度。通过imrotate函数进行偏斜矫正后,可以使纤维图像处于竖直状态,便于后续的轮廓提取。偏斜矫正后的纤维图像见图5。

(a)棉纤维 (b)亚麻纤维
图5 棉纤维与亚麻纤维进行偏斜矫正后的图像
2.5 外围轮廓提取与修补
通过观察图5,纤维的外轮廓全部包括在白色像素点内,因此可以通过扫描白色像素点来得到纤维的外围轮廓图像。由计算机对两种纤维的二值图像从图像左上角的第一个像素点开始进行由左至右、由上至下扫描,并记录下第一个扫描到的白色像素点,可以得到纤维的左侧外围轮廓。同理可从右侧扫描后得到纤维的右侧外围轮廓。将两侧轮廓拼接,即可得到纤维完整的外围轮廓。
提取外围轮廓后的图像中,纤维轮廓还可能存在部分不连续情况。在Matlab软件中,利用imerode与imdilate函数相结合,进行数学形态学开运算与闭运算,可以对提取纤维轮廓后的图像进行修补,将轮廓上绝大多数不连续部分连接起来[7]。修补后的纤维外围轮廓图像更有利于后续特征值的提取。修补后的棉纤维与亚麻纤维外围轮廓图像见图6。

(a)棉纤维 (b)亚麻纤维
图6 棉纤维与亚麻纤维的外轮廓图像
3 特征值提取
棉纤维与亚麻纤维具有不同的形态结构,因此可以通过两种纤维形态结构上的细节特征进行区分。在保证准确性和提取速度的前提下,本文的特征值主要通过提取棉纤维与亚麻纤维样本的直径、扭曲度和充满度来取得,并列举了其中50根纤维的特征值,通过这些特征值的比较,进行后续BP神经网络训练即可完成棉纤维与亚麻纤维的识别。
3.1 直径特征值提取
纤维直径大小的统计通过计算机系统可以轻松实现,在同一水平面上,只需统计纤维图像的左侧边缘与右侧边缘之间的像素大小,即可得到某一水平面上的纤维直径大小。棉纤维存在天然转曲,其直径分布不均匀,直径分布的离散性更大。因此可以取直径比与直径标准差作为特征值参数。直径比为纤维的最大直径与最小直径的比值,直径标准差则反映了纤维直径大小的离散程度。经由计算机的统计,绘制出的棉纤维与亚麻纤维的纤维直径比见图7,两种纤维直径标准差对比见图8。

图7 纤维的直径比

图8 纤维的直径标准差
通过图7、图8中的对比可以得出,棉纤维的纤维直径比和纤维的直径离散程度更大,因此可以通过对特征值参数设定自适应阈值来区分棉纤维与亚麻纤维。
3.2 扭曲度特征值提取
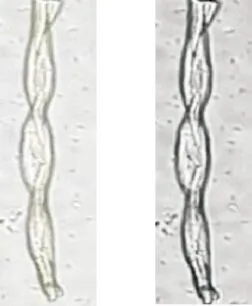
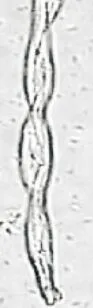
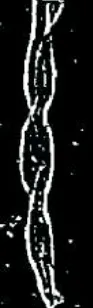
棉纤维具有天然的转曲,其图像提取边缘轮廓后,可以观察到其扭曲度较大。亚麻纤维为竖直状态,其扭曲度较小。因此通过两种纤维扭曲度大小,可以较好区分棉纤维与亚麻纤维,纤维扭曲度示意图见图9。本课题中,在亚麻纤维图像的轮廓边缘取第一横行的第一个白色像素点与最后横行的第一个白色像素点,通过沿纤维图像边缘连接两个像素点得到弧线L2,直接连接两个像素点得到直线L1,扭曲度=L2/L1,即可得到单根亚麻纤维的扭曲度大小,扭曲度的大小表示了纤维的转曲程度。同理,棉纤维只需提取扭曲处的白色像素点,与下一个扭曲处的白色像素点,即可计算出棉纤维的扭曲度大小。

(a)棉纤维 (b)亚麻纤维
图9 纤维扭曲度示意图
本课题提取出平均扭曲度和最大扭曲度作为特征值,经由计算机统计,绘制出棉纤维与亚麻纤维的平均扭曲度和最大扭曲度见图10和图11。
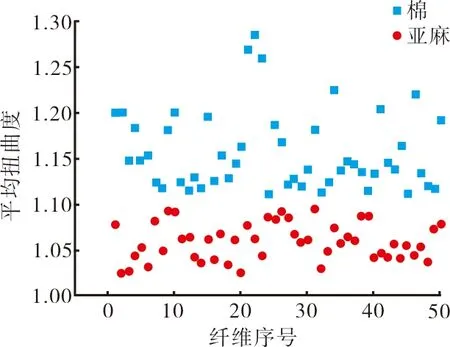
图10 纤维的平均扭曲度
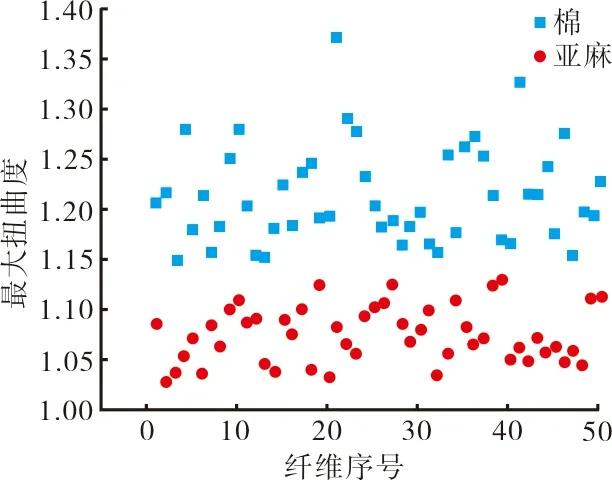
图11 纤维的最大扭曲度
通过图10和图11的对比可以得出,棉纤维的扭曲度较大,因此可以通过对特征值参数设定自适应阈值来区分棉纤维与亚麻纤维。
3.3 充满度特征值提取

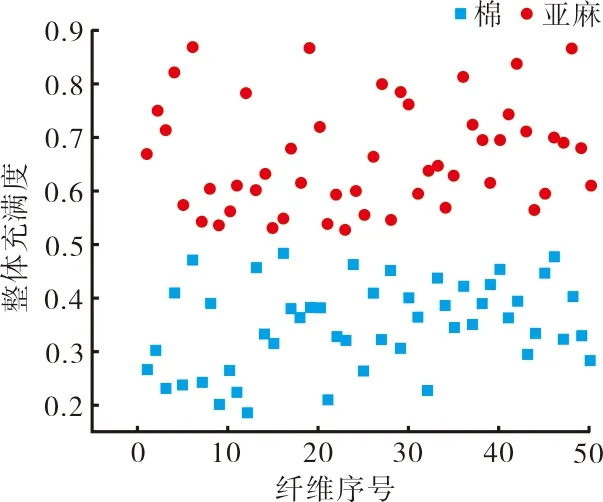
图12 纤维整体充满度

图13 纤维充满度标准差
由图12、图13可以看出,棉纤维的整体充满度较小,充满度标准差较大,因此可以通过对特征值参数设定自适应阈值来区分棉纤维与亚麻纤维。
3.4 特征值的归一化处理
由于特征值提取时特征值的数据跨度较大,对后续的相关性分析及神经网络处理造成了困难,因此需要将特征值进行归一化处理,运用离差标准化对原始特征值数据进行线性变换,归一化后的特征值数据均在[0,1]范围内,便于输入神经网络中进行计算,进一步提高识别效率[8]。离差标准化的计算见公式(1)。

(1)
式中:A为归一化处理后的特征值数据,A0为原始数据值,Amin为样本中最小的数据值,Amax为样本中最大的数据值。
在本课题中,选取直径比、直径标准差、平均扭曲度、最大扭曲度、整体充满度和充满度标准差6个特征值对棉纤维与亚麻纤维进行区分识别。表1为样本中随机抽取的10个棉纤维与10个亚麻纤维的归一化后的特征值参数。
表1棉纤维与亚麻纤维归一化后的特征值参数

序号平均扭曲度棉 亚麻最大扭曲度棉 亚麻直径标准差棉 亚麻直径比棉 亚麻整体充满度棉 亚麻充满度标准差棉 亚麻123456789100.070 40.229 30.023 70.511 90.212 10.107 20.511 90.107 20.152 20.272 10.790 40.009 20.155 30.788 90.065 90.890 60.870 40.837 30.759 90.639 50.326 20.174 20.228 50.249 20.227 80.271 10.207 00.093 60.009 90.201 40.304 60.230 40.560 30.611 90.781 00.480 00.940 90.274 50.437 80.374 20.509 30.507 10.210 30.419 20.212 20.242 40.070 20.043 10.400 40.507 80.752 50.009 10.027 10.265 00.387 40.099 60.821 60.346 60.956 30.952 70.262 00.309 80.589 60.136 70.293 90.042 60.165 90.452 80.591 90.243 50.561 80.084 10.270 40.415 50.071 30.545 70.346 10.698 30.778 10.580 40.271 90.391 90.144 20.751 90.175 20.951 60.175 20.679 80.047 90.260 90.418 30.641 80.544 90.865 20.137 50.996 50.047 80.222 70.040 50.102 30.440 00.135 80.258 20.225 80.084 00.102 20.083 90.491 90.193 60.374 90.300 40.566 50.155 70.040 80.151 80.058 20.277 10.959 80.045 10.411 4
3.5 特征值参数的相关性
归一化后的特征值参数并不能直观反映出是否能够有效识别棉纤维与亚麻纤维,因此需要对特征值参数的相关性进行分析[9]。本文通过公式(2)计算各特征值的相关系数R。

(2)
式中:x为特征值参数,y为纤维种类,Cov(x,y)为x与y的协方差,Var[x]与Var[y]为x,y的方差。R的范围为[0,1],R的值越接近1,则特征值参数与纤维种类的相关性越高。经计算,可以得出6个特征值参数与纤维种类之间的相关性,各特征值与纤维种类之间的相关系数如下。
纤维种类 棉纤维 亚麻纤维
平均扭曲度 0.96 0.96
最大扭曲度 0.96 0.95
直径标准差 0.93 0.92
纤维直径比 0.92 0.92
整体充满度 0.93 0.94
充满度标准差 0.94 0.95
可以看出,所选取的6个特征值与纤维种类之间的相关系数均较高,可以作为正确识别棉纤维与亚麻纤维的特征值参数进行BP神经网络训练。
4 BP神经网络训练
神经网络是模仿人类大脑运作方式的计算机智能技术,它通过若干个神经元组成神经网络。具有自学习、自组织、自适应和很强的非线性映射能力,特别适合于因果关系复杂的非确定性推理、判断、识别和分类问题[10]。
BP神经网络通常有一个或多个隐含层,隐含层中的神经元均采用sigmoid型变换函数,输出层的神经元采用纯线性变换函数。sigmoid型变换函数和纯线性变换函数公式见公式(3)、公式(4)。
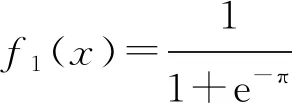
(3)
f2(x)=x
(4)
在本课题中,BP神经网络输入层输入参数为上述6个特征值参数,通过计算后在输出层输出结果为棉纤维或亚麻纤维。输出层若得到的结果错误,则会将错误结果反向传播,修改神经元的权值,经反复训练之后,可以提高识别的准确度[11]。
BP神经网络的优点在于非线性运算,通过多个输入参数对结果进行判断,其训练学习过程可以通过错误反馈逐渐逼近期望输出值,提高识别正确率。由于本课题需要对棉纤维与亚麻纤维进行形态学上的区分,不同地域环境中生长的棉纤维与亚麻形态结构上也存在细微差异,因此样本的基数越大,得到的试验结果越准确。通过BP神经网络训练,可在后期不断扩充试验样本,随着数据库的不断完善,识别正确率也将进一步提高。
经过BP神经网络训练后,对试验样本388个棉纤维图像与371个亚麻纤维图像进行识别,结果如下。
纤维种类 棉纤维 亚麻纤维
识别正确数/次 369 348
总识别数/次 388 371
识别正确率/% 95.1 93.8
识别时间/s 124.4 113.5
可以看出,经由BP神经网络训练后的棉纤维与亚麻纤维识别正确率较高,识别速度较快,其应用软件可以应用于纤维检验机构实际的棉纤维与亚麻纤维图像识别工作中,由于计算机图像识别的高效,可以代替人工识别。
5 结语
本文基于计算机自动化图像处理技术,以Matlab为基础,研发出全新的棉纤维与亚麻纤维自动识别系统。与传统人工识别相比,该系统可以更高效、准确地识别棉纤维与亚麻纤维;与其他识别系统相比,该系统加入BP神经网络训练环节,通过扩充纤维图像数据库可以不断提高识别精度。本课题的研究成果可以代替纤维检验机构中传统的人眼识别,其快速、准确、智能化的优势也符合当今各行业逐步实现人工智能化的趋势。
猜你喜欢
中国纤检(2022年8期)2022-09-22
纺织标准与质量(2022年4期)2022-09-05
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
棉纺织技术(2021年4期)2021-07-14
现代电子技术(2021年1期)2021-01-17
中国纤检(2019年12期)2019-11-28
微型电脑应用(2019年1期)2019-01-23
电脑知识与技术(2018年35期)2018-02-27
散文诗世界(2017年3期)2017-11-13
家庭百事通·健康一点通(2016年7期)2016-08-04
