
基于深度学习的文本自动摘要方案
2019-08-01 01:57张克君李伟男钱榕史泰猛焦萌
计算机应用 2019年2期
关键词:自然语言处理
张克君 李伟男 钱榕 史泰猛 焦萌


摘 要:针对自然语言处理(NLP)生成式自动摘要领域的语义理解不充分、摘要语句不通顺和摘要准确度不够高的问题,提出了一种新的生成式自动摘要解决方案,包括一种改进的词向量生成技术和一个生成式自動摘要模型。改进的词向量生成技术以Skip-Gram方法生成的词向量为基础,结合摘要的特点,引入词性、词频和逆文本频率三个词特征,有效地提高了词语的理解;而提出的Bi-MulRnn+生成式自动摘要模型以序列映射(seq2seq)与自编码器结构为基础,引入注意力机制、门控循环单元(GRU)结构、双向循环神经网络(BiRnn)、多层循环神经网络(MultiRnn)和集束搜索,提高了生成式摘要准确性与语句流畅度。基于大规模中文短文本摘要(LCSTS)数据集的实验结果表明,该方案能够有效地解决短文本生成式摘要问题,并在Rouge标准评价体系中表现良好,提高了摘要准确性与语句流畅度。
关键词:自然语言处理;生成式文本自动摘要;序列映射;自编码器;词向量;循环神经网络
中图分类号: TP181; TP391.1
文献标志码:A
Abstract: Aiming at the problems of inadequate semantic understanding, improper summary sentences and inaccurate summary in the field of Natural Language Processing (NLP) abstractive automatic summarization, a new automatic summary solution was proposed, including an improved word vector generation technique and an abstractive automatic summarization model. The improved word vector generation technology was based on the word vector generated by the skip-gram method. Combining with the characteristics of abstract, three word features including part of speech, word frequency and inverse text frequency were introduced, which effectively improved the understanding of words. The proposed Bi-MulRnn+ abstractive automatic summarization model was based on sequence-to-sequence (seq2seq) framework and self-encoder structure. By introducing attention mechanism, Gated Recurrent Unit (GRU) gate structure, Bi-directional Recurrent Neural Network (BiRnn) and Multi-layer Recurrent Neural Network (MultiRnn), the model improved the summary accuracy and sentence fluency of abstractive summarization. The experimental results of Large-Scale Chinese Short Text Summarization (LCSTS) dataset show that the proposed scheme can effectively solve the problem of abstractive summarization of short text, and has good performance in Rouge standard evaluation system, improving summary accuracy and sentence fluency.
Key words: Natural Language Processing (NLP); abstractive automatic text summarization; sequence to sequence (seq2seq); self-encoder; word vector;Recurrent Neural Network (RNN)
0 引言
在互联网大数据时代,文本信息的数量已经远远超出了人工处理的极限,自动摘要技术的研究显得越发迫切和重要。自动摘要技术可应用在广泛的领域内,如推荐系统、新闻行业;特别是在信息安全领域,舆情监控系统直接处理社交平台的评论信息会给系统带来极大的压力,如果在保持原有主要信息不变的情况下,经过信息压缩后再交给监控系统,就能适当地减轻监控系统的计算负担。
自动摘要问题按照实现方式可以分为抽取式和生成式。抽取式是将原文中已存在的重要句子抽取出来拼凑在一起作为摘要;生成式则是要通过语义理解技术理解文章主旨,再使用自然语言技术生成新的句子作为摘要。可见,抽取式摘要的特点是实现难度低、摘要句的生成过程简单,但摘要句可能出现上下文不匹配的问题;而生成式摘要虽然实现难度高,但其生成摘要句的过程更加拟人化,生成的摘要自然、质量高、语句通顺。
本文将深度学习的相关技术融入自动摘要问题中,提出一种新的生成式自动摘要问题的解决方案,以提高生成式自动摘要的质量,完善生成式自动摘要在核心信息检索领域的应用。
自动摘要任务的过程又可以被转化成从一个输入词序列到另一个输出词序列的映射过程,这个过程被称作序列映射,因此可以使用序列到序列建模的方法来解决。sequence-to-sequence(seq2seq)框架就是用来解决序列映射问题的,目前这个框架已经很好地解决了一部分自然语言处理(Natural Language Processing, NLP)问题,如机器翻译[1]、语音识别[2]和视频字幕[3]。
Facebook公司的Rush等[4]率先将深度学习相关技术用于生成式自动摘要的研究,采用了卷积神经网络(Convolutional Neural Network, CNN)编码原文信息,利用上下文相关的注意力前馈神经网络生成摘要。他们的分析表明采用序列映射框架来解决自动摘要问题是切实可行的。
IBM公司的Nallapati等[6]采用循环神经网络对原文进行编码,同时对词特征、停用词、文档结构等有用信息进行利用,实验结果远远优于单纯使用深度神经网络的效果。这表明深度神经网络并没有充分挖掘到文章的全部特征,如果能针对所研究的问题将相应的特征加入到研究范围内,会极大地改善方案的效果。
谷歌公司在2016年开源了其自动摘要模块的项目Textsum[7],该模块同样使用了RNN对原文进行编码,并采用另一个RNN生成摘要,在摘要生成的最后阶段还使用了集束搜索(beam-search)策略来提高摘要准确度。Britz等[8]对序列映射模型进行了一定的实验与分析,结果表明集束搜索对摘要质量的影响非常大。
2017年Facebook的AI实验室公布了它的最新模型[9],该模型采用卷积神经网络作为编码器,在词向量中加入词语的位置信息,采用线性门控单元(Gated Linear Unit, GLU)作为门结构,并在自动摘要数据集上刷新了记录,但这并不能说明基于CNN的序列映射模型就一定要比RNN的好。虽然CNN效率高,但参数多,且CNN无法像RNN一样对词语的序列敏感,必须向词向量中引入词语的位置信息来模拟RNN的时序特性,可见RNN在处理序列化信息时有着其天生的优势。
以上工作已经在自动摘要问题上取得了一定的成果,但还是有一些问题,例如:词特征提取不充分、摘要句不准确、流畅度不够高。本文针对以上情况进行了以下两个方面的工作:1)引入注意力机制、门控循环单元(Gated Recurrent Unit, GRU)結构、双向循环神经网络、多层循环神经网络和集束搜索,构建了一种新的模型Bi-MulRnn来处理生成式摘要问题;2)在词特征提取方面,基于Skip-Gram方法生成词向量,引入词性(Part Of Speech, POS)、词频(Term Frequency, TF)和逆文本频率词特征(Inverse Document Frequency, IDF)以提高模型对词语的理解能力。最后通过两组基于大规模中文短文本摘要(Large-Scale Chinese Short Text Summarization, LCSTS)数据集的实验,在Rouge标准评价体系下对方案生成的摘要作了一定的评估,结果表明该方案能够有效提升摘要质量。
1 基于深度学习的自动摘要模型的构建
本文设计的模型是基于自编码器结构的。自编码器结构是sequence-to-sequence框架中最常用的结构,它包括一个编码器和一个解码器。本文使用两个独立的RNN。
随着深度学习的相关技术在自然语言处理方面的广泛应用,开始有研究人员将注意力机制引入自编码器结构。
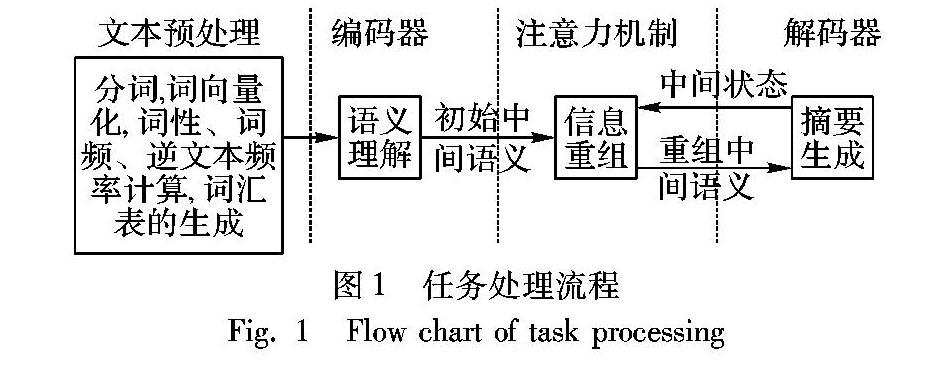
注意力机制是一种聚焦的思想,使神经网络具备重组输入信息的能力,即根据问题的需要,将原始数据的每一项做一个放大或缩小的变换,与问题无关的部分缩小,反之则放大。本文的设计也引入了这种注意力机制。任务处理流程如图1所示,具体包括以下四个步骤:
1)文本预处理阶段。通过将原文信息分词后,再进行词向量化处理,这个过程还包括词性、词频、逆文本频率的计算,最终形成一个词向量序列作为下一个阶段的输入。然后统计语料中高频词汇的邻近词汇,并形成一个邻近词表,协助解码器词汇表的生成。
2)语义理解阶段。循环神经网络具有记忆功能,将上一阶段的词向量序列依次输入编码器,编码器会在每个时间步生成一个当前时间步的语义向量,最后将这些语义向量合并在一起形成全文的语义向量,并传给下一个阶段。
3)信息重组过程:注意力机制根据解码器反馈的中间状态(中间状态即已经生成的词语)重组出最适合当前时间步的全文语义信息,并将重组后的中间语义信息传回解码器用于当前时间步的词语预测。
4)摘要生成阶段。在这个阶段循环神经网络每个时间步预测出一个词,并根据之前预测出的词与概括全文的中间语义共同预测下一个词语,最终形成一个词序列即摘要句。
2 基于深度学习的自动摘要模型关键问题
2.1 基于双向循环神经网络(BiRnn)的编码器
本文编码器的设计引入了双向循环神经网络。传统的循环神经网络偏重于记忆最后时刻的信息,而对最开始的输入信息不敏感。为了解决这一问题,本文采用双向循环神经网络。在这种结构中,网络分别从正向和反向阅读原文,在每个时刻都会生成一个该方向下的隐层信息,结合该时刻下两个方向的隐层信息就能得到该时刻下的语义向量。
在网络的门结构中,我们使用了GRU结构。GRU比长短时记忆网络(Long Short-Term Memory, LSTM)参数更少,并且更加不易过拟合,这一点在Chung等[11]的研究中可以得出结论,因此本文在循环神经网络的门结构中引入了GRU。
2.2 基于多层循环神经网络(MulRnn)的解码器
解码器的设计引入了多层循环神经网络,这种结构在Lopyrev[12]的论文中被单纯地用以解决自动摘要问题,其结论表明该结构在一定程度上提高了摘要的准确度。本文使用了三层循环神经网络,期望提升模型的泛化能力,让它更好地拟合原文到摘要的映射关系,使摘要更加准确。
图3是多层循环神经网络示意图,其中只有第三层会与注意力机制交互。在第i时刻下,解码器接收注意力机制传来的第i时刻下的原文语义向量ci与i时刻下隐层状态向量si,第i-1时刻的输出yi共同预测出i时刻的输出yi+1与i+1时刻下的状态向量si+1。
2.3 带有注意力机制的自编码器
注意力机制首先是在图像处理领域崭露头角[13],其核心思想是,在处理图像中的一小部分时,不再对整个图片做处理,而是使用注意力机制,只集中资源在最关键的部分。实验结果表明该方法可以有效提高程序的运行效率。
随后注意力机制被引入自然语言处理领域。本文的循环神经网络自编码器模型也引入了注意力机制。注意力机制对摘要任务的执行效率有很大的帮助。摘要的生成是输出一个词序列形成摘要句的模式,注意力机制会在预测某个位置的词汇时,偏向注意那些与该位置有紧密联系的原文信息。如果没有注意力机制,那么每次预测时,关注的内容都是整个文章,而有些词语可能因为出现频率很高,导致关键性明显高于其他词语,最终连续预测出同一个词,从而毁掉整个摘要。图4是一个带有注意力机制的循环神经网络自编码器模型。
注意力机制:ci表示第i时刻下的原文语义向量。αij是表示解码器当前时刻原文中的输入词与当前要预测的位置之间的关联程度;eik是对解码器当前时刻下某个编码器隐层输出的评分,评价标准是当前预测位置与该隐层输出的关联程度,具体评价方式由score函数确定。由于本文是针对短文本的摘要,所以使用全局注意力机制与局部注意力机制的区别不大,而且使用局部的方法更加复杂,所以本文使用了全局注意力机制的一般方法[14]。
2.4 解码器词汇表的构建
编码器在使用softmax层计算每个词的概率时非常消耗时间,也是整个任务计算速度的瓶颈。为了解决这个问题,可以重新划定解码器的词汇表。传统方法是使用目标语言的整个词汇表,进一步的方法是仅仅使用待处理句子的词汇与目标语言中的高频词汇,极大地减少了计算成本[15]。
本文在传统方法的基础上作了一定的改进,提出了邻近词表技术,加入了原文词表中属于高频词汇的邻近词汇,邻近度是在词向量空间中体现的,即余弦值越高相似度越低。即解码器的词汇表由三部分组成:原文词汇、高频词汇和邻近词汇。自动摘要任务与机器翻译任務有所不同,机器翻译任务不需要过多的新词汇,而自动摘要任务需要更多新颖有意义的词汇来形成更优的候选句,并且邻近词汇也能进一步提升句子的连贯程度。经过修改,本文提出的邻近词表技术不仅能够减少计算成本,提高收敛速度,还更加适应摘要任务。
2.5 改进的词嵌入技术
传统的词嵌入技术主要采用两种方法:连续词袋模型(Continuous Bag-of-Words, CBOW)与Skip-Gram方法。CBOW是根据某个位置上下文的词汇而推出这个位置的词,Skip-Gram是根据某个词推出该词所在位置上下文的词语。可以看出这两种方法都只关注词语间的位置关系,而没有关注词的其他特性,例如词性、词频和逆文本频率。
本文将词汇的POS、TF、IDF值离散化后朴素连接在原来的词向量后端形成一个新的词向量作为编码器的输入,用来生成语义编码。
摘要往往是中性的句子,很少附带情感词汇,一般只描述事实,所以摘要任务的词语选择应该重点在名词和动词上,而不是形容词和副词。而词频与逆文本频率能够反映词汇的重要性与代表性。词频表示词汇在原文出现的次数,逆文本频率表示词汇在语料库中出现的频率。词语的关键性会随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。这些信息都是摘要任务所需要的重要信息,期望加入这些信息能够提高摘要质量。
3 实验与分析
3.1 LCSTS数据集
本文实验使用了LCSTS数据集,所采用数据的具体情况如表1所示,该数据集包含三个部分,其中:
3.2 实验设置
将Part1作为训练集,训练样例的选取是随机的。通过jieba工具对文本进行分词,之后,从中选取60000个高频词作为编码器的词汇表,不在词汇表内的词语使用“UNK”表示。本文设计的解码器词汇表大小[16]为4000,先将原文词汇加入词汇表,然后取它们的邻近词汇,最后用编码器词汇表中的高频词汇填充剩下的位置。把邻近度设定为3,即取余弦值最接近的3个词为邻近词汇。词向量维度为250,批尺寸大小为50,学习率初始化为1.0,其他参数均随机初始化。本文采用Adadelta方法来更新学习率。在解码器输出端采用集束搜索(beam-search)方法,束大小设定为7。所有模型的训练过程都在Tesla P4上完成,整个过程持续了将近一周的时间。
选取Part3中评分在3以及3以上的原文摘要组合作为测试集。摘要评价采用了Rouge评价体系[17]。该评价体系自提出以来被广泛应用于自动摘要任务的评价当中,目前已成为世界公认的评价标准。该体系的思路是分析比较候选摘要集与专家摘要集的相似程度来评价摘要质量。本文采用该体系中的Rouge-1、Rouge-2和Rouge-L三种方式对模型进行测试评价,这三种方式分别从字的相似度、词的相似度和句子的流畅度三个方面来评价摘要质量。
由于标准的Rouge工具包通常只能用来评价英文,所以将中文字符编码成了英文字符串,这样就可以把中文字符与英文单词对应起来,可以说本文对系统的评价是基于“字”为单位进行的[18]。
3.3 实验分析
从表2中可以看出,引入了双向循环神经网络、多层神经网络、改进的词嵌入技术与邻近词表技术后, Bi-MulRnn+模型在测试中的表现略优于Bi-MulRnn模型与RNN context模型。这说明Bi-MulRnn+模型在生成摘要的正确性、连贯性和表达性上都有了一定的提升。
導致这种情况的原因有三个:
一是引入了双向循环神经网络与多层循环神经网络,双向循环神经网络能够克服传统循环神经网络注意力偏后的缺陷,多层循环神经网络能够提升循环神经网络的泛化能力。从第二、三组的实验对比中可以表明这两者确实对摘要任务有所提升。
二是邻近词表技术,加入了邻近词。在一些情况下,标准摘要中有可能出现原文中不存在的词汇,例如像在原文中可能出现“在排名中最高”这种表达,但在标准摘要中有可能是“居榜首”这种表达,两者都表达了同一个意思,但后者明显简练一些。邻近词的扩充可以使解码器词汇表中出现这类意思相近的词语,使得摘要句子的词汇丰富性与准确性得以增强。
三是改进的词嵌入技术,加入了POS、TF和IDF三个特征。这三个特征加强了模型对名词、关键词的认识,摘要句往往是陈述句,其中形容词和副词较少,经过学习,模型会自动增强对动词与名词的选择,进一步加强摘要的准确性。
4 结语
本文对生成式自动摘要技术进行了深入的分析与研究,提出了一种生成式自动摘要问题解决方案。该方案构建了一种新型自编码器模型,并对词义表示进行了改进。模型的编码器与解码器部分采用了一种新型的组合方式,编码器采用双层循环神经网络,解码器采用多层循环神经网络,通过对比分析实验结果可以得出结论:这种组合提高了模型对文章的理解能力和模型生成的摘要质量。在词义表示方面,本文采用了Skip-Gram方法生成词向量,并引入了词性、词频和逆文本频率这三个特征,通过对比分析实验结果可以得出结论:改进的词向量技术能进一步地提高摘要质量。在Rouge标准评价体系下,本文模型与单纯使用深度神经网络的模型相比有更好的表现。
生成式自动摘要技术可应用于新闻行业、推荐系统以及信息检索等领域,具有良好的应用价值。但是该模型在对一部分特有名词处理时无法识别这些信息,最终会导致摘要生成不准确,所以在后续的研究中将针对这一问题作进一步的研究。
参考文献:
[1] BAHDANAU D, CHO K H, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2018-03-20]. https://arxiv.org/pdf/1409.0473v7.pdf.
[2] BAHDANAU D, CHOROWSKI J, SERDYUK D, et al. End-to-end attention-based large vocabulary speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2016: 4945-4949.
[3] VENUGOPALAN S, ROHRBACH M, DONAHUE J, et al. Sequence to sequence — video to text [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015:4534-4542.
[4] RUSH A M, CHOPRA S, WESTON J. A neural attention model for abstractive sentence summarization [EB/OL]. [2018-02-23]. https://arxiv.org/pdf/1509.00685.pdf.
[5] CHOPRA S, AULI M, RUSH A M. Abstractive sentence summarization with attentive recurrent neural networks [EB/OL]. [2018-03-21] http://aclweb.org/anthology/N/N16/N16-1012.pdf.
[6] NALLAPATI R, ZHOU B W, dos SANTOS C N, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond [C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2016:280-290.
[7] ABADI M, BARHAM P, CHEN J M, et al. Tensor flow: a system for large-scale machine learning [C]// Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation. Berkeley, CA: USENIX, 2016: 265-283.
[8] BRITZ D,GOLDIE A, LUONG M-T, et al. Massive exploration of neural machine translation architectures [EB/OL]. [2018-04-05]. https://arxiv.org/pdf/1703.03906.pdf.
[9] GEHRING J, AULI M, GRANGIER D, et al. Convolutional sequence to sequence learning [EB/OL]. [2018-04-23]. https://arxiv.org/pdf/1705.03122.pdf.
[10] LI P J, LAM W, BING L D, et al. Cascaded attention based unsupervised information distillation for compressive summarization [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017:2081-2090.
[11] CHUNG J Y, GULCEHRE C, CHO K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [EB/OL]. [2018-04-23]. https://arxiv.org/pdf/1412.3555v1.pdf.
[12] LOPYREV K. Generating news headlines with recurrent neural networks [EB/OL]. [2018-03-20]. https://arxiv.org/pdf/1512.01712.pdf.
[13] MNIH V, HEESS N, GRAVES A. Recurrent models of visual attention[EB/OL]. [2018-04-08]. https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf.
[14] LUONG M-T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2015: 1412-1421.
[15] JEAN S, CHO K H, MEMISEVIC R, et al. On using very large target vocabulary for neural machine translation [C]// Proceedings of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2015:1-10.
[16] AYANA, SHEN S Q, ZHAO Y, et al. Neural headline generation with sentence-wise optimization [EB/OL]. [2018-03-23]. https://arxiv.org/pdf/1604.01904.pdf.
[17] LIN C Y, HOVY E. Automatic evaluation of summaries using n-gram co-occurrence statistics [C]// Proceedings of the 2003 Conference of the North American Chapter of the ACL on Human Language Technology. Stroudsburg, PA: ACL, 2003: 71-78.
[18] 戶保田.基于深度神经网络的文本表示及其应用[D].哈尔滨:哈尔滨工业大学,2016:91-94. (HU B T. Deep neural networks for text representation and application[D]. Harbin: Harbin Institute of Technology, 2016: 91-94.)
[19] HU B T, CHEN Q C, ZHU F Z. LCSTS: A large scale Chinese short text summarization dataset [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2015:1967-1972.
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
中国市场(2016年39期)2017-05-26
电子技术与软件工程(2016年24期)2017-02-23
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
