
Android 平台下OpenCL 加速的说话人识别系统∗
2019-07-31 09:54张竞丹韩俊刚
计算机与数字工程 2019年7期
张竞丹 韩俊刚
(西安邮电大学计算机学院 西安 710100)
1 引言
近年来,移动端图形处理单元(Graphic Processing Units,GPU)已经开始在低功耗的片上系统(system-on-a-chip,SoC)设备中使用,因其通用计算性能和软件栈的发展使得人们开始致力于研究移动设备的加速能力。随着人工智能狂潮的到来,大数据异构计算再次兴起,由苹果、AMD 和IBM 等公司联合开发的一个通用开放API——OpenCL,因其普适性和易于理解的良好性能成为搭建移动异构计算的最佳选择,它为异构计算系统上的并行编程提供了工业标准[1]。在最初,Android 官方没有明确声称移动设备可以支持OpenCL,但直到2014年左右,Android 移动设备供应商开始提供OpenCL SDK,这种转变是由于MaliT604 和高通Adreno 320移动端GPU 的产生。由于种种限制,OpenCL 在移动 GPU 上的编程存在很多挑战[2]。OpenCL 是一个基于C 语言的软件库,在Android 系统中必须通过Android NDK(Native Development Kit,NDK)交叉编译在生成动态库并在应用程序中调用。
说话人识别是根据收集到的语音信号鉴别说话人身份的技术。根据识别对象,说话人识别可以分为文本相关(text-dependent)的和文本无关的(text-dependent)两种类型[3]。在文本相关的说话人识别中,在训练和识别阶段说话内容都要保持一致,文本无关的说话人识别则在训练和测试阶段说话的内容不影响系统的判别。从另一方面,根据待识别的说话人是否在已知集合内,可以分为闭集识别问题和开集识别问题,前者待识别的人在集合内,判断测试语音是否属于集合内的某个说活人;后者待识别的人不一定在集合内,判断待测试语音是否属于集合内的某个说话人[4]。按照识别任务来区分,说话人识别还可以分为说话人辨认(Speaker Identification,SI)和说话人确认(Speaker Verification,SV),SI 根据说话人的语音确定其为待选的多个说话人中的某一个;SV 则是证实说话人的身份与其声明的身份是否相同。本文的说话人识别系统,是文本无关的闭集合内的说话人辨认系统,在Matlab 上实现后,将系统重写成C 语言移植于Andoid 端,通过OpenCL 并行加速,将加速前后的系统运行时间做对比。Android 端实验结果表明,通过OpenCL加速后的加速比1.5左右。
2 BP神经网络说话人辨认系统
说话人识别系统通常分为三个模块:1)特征提取;2)说话人模型训练;3)说话人打分[5]。文章中,输入的语音信号经过预加重后按20ms 帧长,10ms帧移进行分帧,使用汉明窗进行帧加窗减小截断效应,对每个短时分析窗通过FFT变换得到对应帧频谱,再将帧频谱通过Mel 滤波器组映射到Mel 频谱中,最后在Mel 频谱上进行倒谱分析(取对数,DCT逆变换)[6]获得 13 维 MFCCs。由于 MFCCs 反映的是说话人频谱包络静态特征,有实验表明,二次特征提取的动态特征有利于更充分地表示说话人特征,所以加入MFCCs 一阶、二阶差分值,共24 维特征。为了反映出说话人相对较长时域的特征,本文中不单独使用一个帧长的MFCCs,而是根据[7]中的方法,将相邻的7 个MFCCs(左边3 个,右边3 个)拼接起来,通过 LDA(Linear Discrimination Analysis,LDA)将高维样本特征投影到最佳鉴别矢量空间,投影后保证样本在新的子空间有最大类别间距和最小类内间距。具体算法为[8]
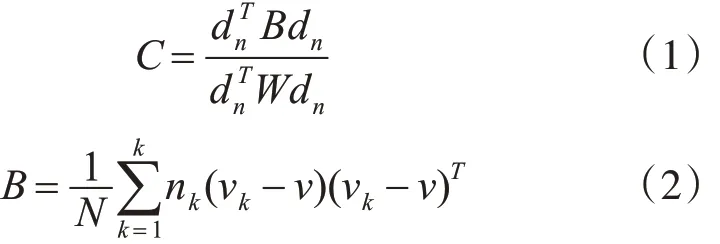
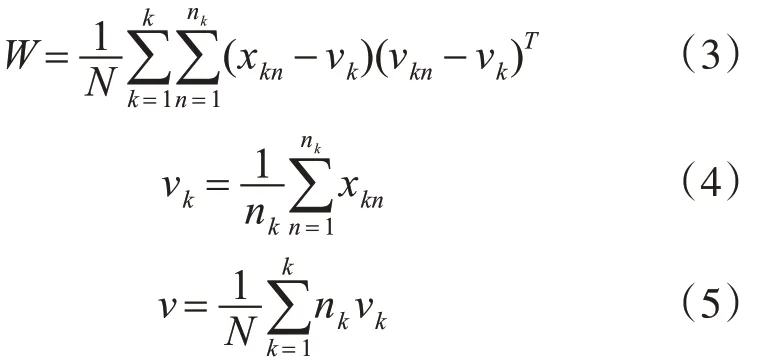
其中B为类间方差矩阵,W 为类内方差矩阵,N为样点总数,k 为类别数,nk为第k 类样点数,式(4)、(5)是第k 类样本和所有样本的均值向量。将连接的 7 帧共 168 维 MFCCs 根据式(6)进行 LDA 投影为47维特征向量。

式(6)中p 为帧数;m 为特征维数;U 是最优线性变换矩阵。
典型的说话人模型分为两种,即模板模型和随机模型[9]。前者将训练特征参数和测试特征参数进行比较,两者间的失真作为相似度;后者用一个概率密度函数模拟说话人,训练过程用于预测概率密度函数的参数,匹配过程通过计算相应模型的测试语句相似度来完成。本文中采用文献[10]的方法,用含有一层隐藏层的前馈神经网络作为说话人的模板模型。文献[10]中指出,该模型的表现比基于码本(codebook)的模型较好,但略逊色于较大的模型。在网络的训练过程中,将样本随机打乱后,采用batch 梯度下降学习方法进行参数更新[11],batch大小取值128。
3 实验过程
本文系统在Matlab 上进行仿真。实验数据使用TIMIT数据库中随机抽取的20个说话人,其中男人10个,女人10个,每人使用6条语音训练,4条语音测试。每条语音时长约为3s 左右。根据2 中的方法提取说话人特征。
在准备数据过程中,训练正样本为目标说话人的语音,训练负样本为其余19 人非目标说话人,但这样会导致正负样本比例不平衡。本文中采用SMOTE[12]过采样算法对正例进行插值来增加样本,同时随机抽取负样本使得正负样本比例保持在1∶1左右。
在网络搭建过程中,最重要的是要确定网络隐藏层节点数。本文对不同的隐藏层神经网络的分类能力做了详细的实验,用ROC 曲线下的面积指标来判定哪一个隐层节点数下的网络分类能力较好。通过实验,发现隐层节点数取值为20 时,ROC曲线面积最大,如表1所示。

表1 Roc面积对比
在网络训练过程中,学习率是影响梯度下降过程中收敛到全局最小值的关键因素。在实验中,学习率过大,验证集误差值震荡不收敛,如对比图1和图2;学习率较小导致训练时间长,所以只有选择合适的学习率才能是模型很好的工作。在本文中,采用以10 倍的比例减小学习率,观察loss 曲线图找到最佳学习率。
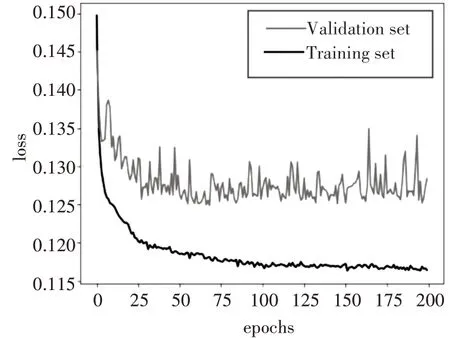
图1 学习率为0.5的训练误差
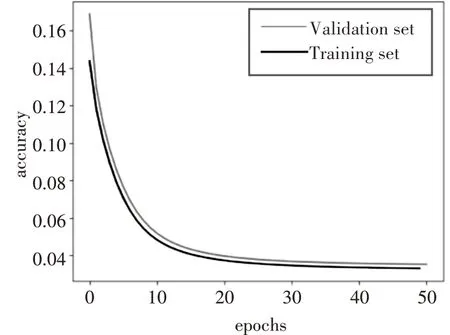
图2 学习率为0.0005的训练误差
最终的网络结构如表2所示。

表2 网络结构
实验采用等错误率(Equal Error Rate,EER)[15]对实验结果进行评判。本文系统在该数据集上EER值为10.6%。
4 Android下OpenCL系统实现
本文代码实现运行在高通Adreno 530 GPU下,Adreno 530 可以支持完整 OpenCL 2.0 标准[13]。本文代码中,将上述说话人识别系统改写成c 代码,通过Android NDK 将c 代码编译成动态库在java 中通过接口调用并一起打包生成APK。
由于BP训练算法在正向传播和反向传播的过程涉及大量矩阵运算,且在迭代过程中每个batch size 内的数据相关性较小,所以本文中分别针对前向传播和反向传播的数据流各设计一个kernel 函数进行并行计算[14]。
在前向传播中,每次计算输入特征值到输出误差的计算过程中,各个特征值之间没有依赖性,所以设计kernel1 来实现隐藏层输入输出以和输出层输入输出及输出误差,并开启batch size 个线程并行计算。在反向传播中由于隐藏层和输出层的连接权重、输入层和隐藏层的连接权重可以分别单独计算,所以设计kernel2 实现对单个权重进行计算,并以线程的global_id标识每个权重,达到并行加速的目的。设计中kernel2需要等待kernel1的结果计算 batch size 的累积误差,cpu 端通过 OpenCL 接口clEnqueueNDRangeKernel()函数指定 kernel2 等待kernel1的event事件。Android端实验结果如表3所示。表中分别对比了一层隐层和两层隐层的网络训练速度。

表3 Android端试验结果对比 (单位:s)
通过试验发现OpenCL 加速后,系统的运行时间有了一定的提升,加速比1.5 左右。在随着硬件厂商对移动端OpenCL 支持逐步完善,以及GPU 性能的提升,可以很好地利用OpenCL对应用加速。
5 结语
在近些年兴起的移动平台,并行计算已经在移动平台具备硬件条件和编程标准的支持,而并行化又可以带来提升设备硬件利用效率,同时GPU 的低主频特性又可以在一定程度上降低功耗,因此在智能手机等移动平台实现并行计算具有巨大的潜在价值,特别在当前手机续航时间不能满足用户要求的背景下,并行化的特性显得尤为重要。将并行计算与机器学习算法相结合,将理论落实到应用才能进一步响应“AI革命”的号召。
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
防爆电机(2022年3期)2022-06-17
复旦学报(自然科学版)(2022年1期)2022-06-16
火力与指挥控制(2020年2期)2020-04-02
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子技术与软件工程(2019年12期)2019-08-22
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信产业报(2018年40期)2018-01-22
