
基于三维卷积神经网络与支持向量机的微表情自动识别
2019-06-27 00:38何景琳梁正友孙宇
现代计算机 2019年13期
何景琳,梁正友,孙宇
(广西大学计算机与电子信息学院,南宁530004)
0 引言
人脸表情在我们日常生活中扮演着重要的角色。与人脸表情相比,自发式的微表情更能够反映人的真实情绪。自发性微表情是指人们尽最大努力抑制真实表情的视频片段,它的持续时间短,仅为1/25~1/3 s[1],并且动作幅度小。尽管能够通过人力进行识别,但识别的准确率并不高,经过培训的人员识别准确率不超过50%[2]。因此,有必要使用先进的计算机视觉技术来提高识别率。
最先用于微表情识别的是手工描述特征识别方法。LBP-TOP[3]作为手工描述特征识别的一种基准方法,在微表情识别史上首次被采用,该方法是在平面图像特征LBP 的基础上,结合微表情视频在时域和空域方面提出的,通过在三个正交平面上对像素及其邻居之间的信息进行编码,从而提取微表情的特征。另外,Huang 等人[4]提出了时空全局部量化模式(STCLQP),包括信号、大小和方向因素。Liu 等人[5]提出了一种基于时空空间局部纹理描述符(SLTD)的主方向平均光流(MDMO)法,更为简单有效。
近年来,深度学习技术在识别方面获得巨大成功,已经广泛应用于多个领域,如行为识别[6]、自然语言处理[7]、语音识别[8]等方面,也逐步被应用到微表情自动识别当中。Kim 等人[9]提出结合时域和空域不同维度特征的提取方法,时域维度特征通过搭建CNN 提取帧序列的五个不同状态信息获得,时间维度特征通过LSTM网络获得,提高了微表情识别准确率。Peng 等[10]采用两种时域维度差异的卷积神经网络(DTCNN)对不同数据集的微表情进行识别,通过一种数据增强的算法提高数据样本量,也提高了识别的准确率。
本文提出了一种三维卷积神经网络与支持向量机(3D Convolutional Neural Network and Support Vector Machine,C3DSVM)的方法,通过C3D 提取微表情在时域和空域上的中间层特征,并采用SVM 分类器进行分类,实现微表情的自动识别。所提出的方法在CASME2[11]微表情数据集上做了实验,实验表明该方法在采用五折交叉验证法的情况下,提高了微表情自动识别的准确率。
1 C3D
C3D 是一种在时域和空域上进行同时进行深度学习的一种技术,可用于行为识别、场景识别、视频相似度分析等领域。Ji 等人[12]首次提出一种能够同时作用在时间和空间上的3D 卷积网络,在实时视频环境中识别人类行为。
C3D 的优点在于,采用三维卷积核对上一层网络中的图像感受野进行卷积操作,可以一次性提取时域特征,即可以捕捉到多个帧的动作信息。具体地,对于第i 层网络的第j 个图像感受野上的像素点( )x,y,z 的特征值可以记作,公式为:
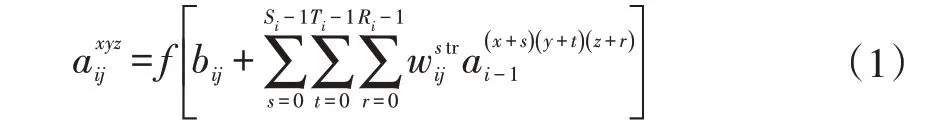
其中,而Si和Ti分别是三维卷积核的高度和宽度,Ri是三维卷积核的时域维度大小,为连接上层图像感受野的三维卷积核位置( )s,t,r 的权重。f(x)表示激活函数,常用的激活函数有ReLU(Rectified Linear Unit)、sigmoid 等。Hinton 等人[13]提出实验中使用Re-LU 比sigmoid 更好,因此,实验中采用ReLU。ReLU 可以表示为:

最后一层输出层采用Softmax 激活函数,Softmax在输出层中表示当前神经元输出的概率,公式为:

其中,c 为输出层神经元个数。
2 C3DSVM微表情自动识别
2.1 微表情数据集
目前自发的微表情数据集较少,仅有的三个数据集分别是CASME1[14]、CASME2 和SMIC[15]。本文的全部实验采用CASME2 数据集。
CASME2 是中国科学院心理研究所收集的CASME 数据库的升级版本。CASME2 包含由200fps相机记录的26 个受试者的255 个微表情视频序列。获得的微表情样品由AU 编码,包括三个部分:起始、顶点和结束。微表情数据集可以分为七个类:高兴、惊讶、恐惧、悲伤、厌恶、压抑、其他。
在我们的实验中,由于两个类的样本量不足以进行特征学习的训练,因此不使用样本过少的视频序列类别(即恐惧和悲伤)来进行识别,即其余的246 个样本用于实验,如表1 所示。

表1 实验中使用的微表情数据集情况
2.2 C3DSVM
C3DSVM 微表情自动识别方法就是通过C3D 提取微表情在时域和空域上的中间层特征,再将中间层特征送入SVM 分类器,实现微表情的分类。图1 为微表情自动识别示意图。
图1 注释:输入视频序列尺寸为(16×112×112),其中16 表示为微表情视频帧长,112×112 分别表示帧的长和宽。
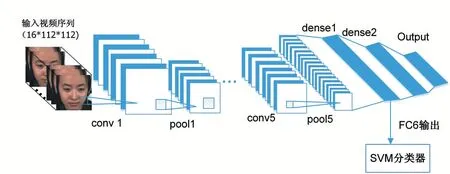
图1 C3DSVM微表情自动识别方法
图2 注释:蓝色表示卷积层(conv),黄色表示最大池化层(pool),绿色表示完全连接层(dense)。所有的卷积层的卷积核大小为(3×3×3)。除了pool1 的降采样核大小是(1×2×2),其他pool 层均为(2×2×2),并且全部采用的是最大采样,每个完全连接层有4096 个神经元。

图2 实验的网络结构
如图1 所示,输入的微表情序列在C3D 网络结构上经过反复的训练后,在dense1 这个中间层输出特征,并送入SVM 分类器,实现分类。具体的网络结构如图2 所示。所提出的三维卷积神经网络包括6 个卷积层、4 个最大池化层、2 个完全连接层以及1 个输出层。除了最后一层输出层采用Softmax,其余层的激活函数都采用ReLU,参数训练采用随机梯度下降算法(Stochastic Gradient Descent,SGD)。
后面的分类采用SVM 分类器。SVM 是用于分析数据的一种监督学习算法,在小样本训练集上能够得到比其他算法好很多的结果[16],也具备泛化能力。实验中的SVM 分类器采用径向基函数(Radical Basis Function,RBF),RBF 是空间中任一点x 到某一中心c 之间欧氏距离的单调函数,其作用往往是局部的,即当x 远离c 时函数取值很小,形式为:

其中c 为核函数中心,t 为函数的宽度参数,控制了函数的径向作用范围。RBF 通过将样本映射到一个更高维的空间,实现非线性可分的样本。微表情由非线性的图片序列构成,使用RBF 核函数的SVM 分类器能够有效实现分类。
3 实验
3.1 实验过程
预处理。微表情识别的预处理流程包括人脸识别、裁剪以及规范化处理环节。如图3 所示,首先在微表情预处理阶段检测人脸区域,对每个视频序列的第一帧采用Haar 人脸检测器[17]进行人脸识别,第一帧识别得到的人脸区域矩形识别框适用于剩余帧,最后将整个视频序列对应的人脸区域裁剪下来。在规范化处理中,由于每个视频的大小尺寸不统一,我们首先通过平面线性差值的方法将每一帧的平面尺寸统一为112×112。其次,由于帧序列长度不统一,在时域序列上(Temporal Interpolation Method,TIM)[18]通过TIM 的方法统一帧数为150。经过这样的调整,每个样本大小统一为112×112×150×3(3 为RGB 通道)。最后,为了获取更细致的特征,等步长截取视频帧,如图4 所示,实验以16 帧为步长无重叠地截取每个样本中的16 帧,即新的样本大小为112×112×16×3,实验中由于微表情出现的高峰在视频时域上的中间段,尽量取该段的帧序列。

图3 微表情识别的预处理流程
验证方法和指标说明。本文的实验均采用五折交叉验证的方法,即将样本随机打乱后平均分为5 份,4份用作训练集,剩余1 份用作测试集,循环下来,就能得到五个测试集的预测结果(准确率)。本文的指标采用该准确率。

图4 以16帧为步长截取原始帧序列
训练参数及硬件说明。网络结构如2.3 节所述,用Keras 实现。训练时,目标函数使用均方误差(Mean Square Error,MSE);初始学习率设置为0.01,epoch 设定为60。以上参数通过反复试验确定。实验的主要硬件设备是两个NVIDIA Titan X GPU。
3.2 实验结果及对比
(1)和其他方法的对比
实验结果如表2 所示,与其他前沿方法相比,本文提出的C3DSVM 的识别方法获得了最高的准确率,为88.79%。表2 前两行是手工特征描述的识别方法,后面为深度学习方法。相比之下,C3DSVM 作为一种深度学习方法,能够自动提取特征,省去了人工寻找特征的步骤,也提高了识别准确率。
相比二维卷积神经网络,C3DSVM 能够提取在时域和空域上的特征。二维卷积神经网络在提取视频特征上,是将时域上的特征图堆叠得到,容易丢失时域的信息。对于微表情本身动作幅度小的特性来说,使用C3DSVM 能够有效提取时域上的特征,实现了很好的分类。

表2 不同微表情识别方法的准确率
(2)不同条件下方法对比
使用SVM 分类能够提高识别准确率。图5 表示C3DSVM 和C3D 的五折识别准确率,图6 表示对应的平均识别准确率。由这两个表格可以看出,C3DSVM的总体识别准确率高于C3D,这是由于SVM 适用于样本量较少的数据集,C3DSVM 不直接在C3D 网络的最后一层分类,而将C3D 提取出的dense1 中间层特征放入SVM,在小样本的数据集下SVM 能够发挥其优势,实现微表情的有效分类。

图5 使用C3DSVM和C3D的五折识别准确率(%)比较

图6 使用C3DSVM和C3D的平均识别准确率(%)比较
使用预处理中TIM 统一帧长处理的视频帧可以提高微表情识别准确率。no-TIM+C3DSVM 表示没有采用TIM 的对比方法。图7 表示C3DSVM 和no-TIM+C3DSVM 的五折识别准确率,图8 表示对应的平均识别准确率。由这两个表格可以看出,C3DSVM 的总体识别准确率高于no-TIM+C3DSVM,发现在采用TIM的情况下,C3DSVM 能够发挥出最好的效能,在使用C3D 网络的前提下,输入层的输入大小一定,微表情段帧长统一有利于网络提取特征,进而提高识别准确率。

图7 使用C3DSVM和noTIM+C3DSVM的五折识别准确率(%)比较
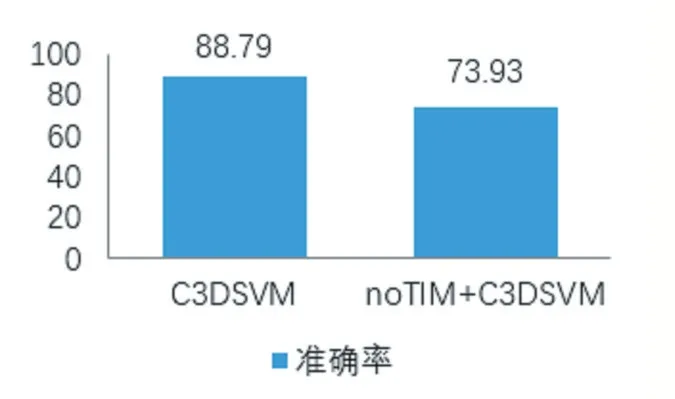
图8 使用C3DSVM 和noTIM+C3DSVM 的平均识别准确率(%)比较
4 结语
本文提出了C3DSVM 的微表情自动识别方法,通过C3D 对微表情视频序列在时域和空域上的中间层特征提取,再用SVM 分类器分类。和传统的手工方法以及现有的深度学习方法相比,所提出的方法明显提高了识别准确率。另外,本文也探索了采用TIM 的预处理方法对识别准确率的作用,实验结果说明采用TIM能够有效提高微表情识别率。
然而,深度学习极度依赖硬件设备,参与训练的参数过大,训练时间过长,训练效率不高,这也是使用深度学习技术普遍存在的弊端。另外,实验中探索网络结构设置、网络参数设置和激活函数等参数较为复杂。如何优化网络结构,优化网络参数,以进一步提高识别准确率是今后研究的重点。
猜你喜欢
电声技术(2022年7期)2022-09-23
农业工程学报(2022年5期)2022-06-22
舰船科学技术(2022年10期)2022-06-17
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
花火彩版B(2020年5期)2020-09-10
科技视界(2020年24期)2020-08-26
