
代码克隆检测方法研究进展
2019-06-27 00:38王婷牟永敏张志华
现代计算机 2019年13期
王婷,牟永敏,张志华
(北京信息科技大学计算机学院,北京100101)
0 引言
在软件开发过程中,一些常见的操作会为代码库引入代码克隆,如通过复制粘贴并加以修改的方式复用已有代码、由IDE 自动生成代码片段等[1]。软件开发人员经常故意进行代码克隆,因为代码克隆具有一些潜在的好处,如可以加快开发进程,使已经过良好测试的代码的得到重用等。研究显示,一般的软件系统中,大约存在7-24%的代码克隆,在一些软件中甚至达到了50%[2]。
然而,过多的代码克隆会给软件项目维护带来一些问题。复用一段包含未知bug 的代码会导致bug 在开发者没有意识到的情况下传播到软件系统的其他地方,进而为以后的bug 修复带来困难。并且,对于一处代码的修改可能导致需要修改其他多个位置的克隆代码,进而增加开发人员的工作负担。另外,对多个克隆片段进行了不一致的修改后,还可能导致软件系统出现意想不到的效果。因此,代码克隆被认为是使得软件项目维护成本增加的一项重要因素,在所有软件开发成本中占比达到80%[3]。
因此,如何高效地检测出软件系统中的代码克隆片段成为一个有实际意义的课题。代码克隆检测是定位软件系统中相同或相似的代码片段的过程,一对相同或相似的代码片段被称为“克隆对”(Clone Pair)[4]。在过去的20 年中,代码克隆检测获得了越来越多的关注,已有很多主流方法被提出和实现。这些代码克隆检测方法的不同之处主要在于它们的检测目标和检测粒度。
与代码克隆检测相近的研究课题包括代码相似性检测、软件抄袭检测等。熊浩等人[5]在2010 年发表过一篇代码相似性检测的中文综述,但已无法涵盖最近十年取得的最新进展。田振洲等人[6]在2016 年发表过一篇软件抄袭领域的中文综述,但论文主要讨论二进制代码的克隆检测,对源代码的克隆检测未做深入探讨。因此本文只关注源代码克隆检测,介绍其基本概念与主流方法,并重点介绍近几年基于信息检索、机器学习的代码克隆检测的主要方法。
1 基本概念
1.1 基本定义
(1)代码片段(Code Fragment)
一个代码片段(CF)是软件项目源代码中一段连续的代码行。在代码克隆问题中通常以至少6 行或50个token 的代码片段为最小克隆检测单位[7]。
(2)克隆对(Clone Pair)
如果两个代码片段CF1 和CF2 在语法或语义上相似,则认为这两个代码片段构成一组克隆对(CF1,CF2),二者互为克隆。
(3)克隆等价类(Clone Class)
一个克隆等价类是一个由克隆对构成的集合,其中任意两个代码片段都构成一组克隆对。代码片段间的克隆关系是一个等价关系,具有自反性、对称性和传递性[8]。
1.2 克隆类型
目前对代码克隆的分类主要有如下四类[8]。
(1)第一类克隆(文本层面的相似):
除了空白符、布局和注释外,完全相同的代码片段。第一类克隆又称为完全克隆(Exact clone)。
(2)第二类克隆(词法,或token 层面的相似):
除了标识符名和字面量外,完全相同的代码片段。第二类克隆又称为renamed/parameterized clone。
(3)第三类克隆(语法层面的相似):
对一份代码片段做语句级别的增加、修改、删除操作得到的克隆代码。第三类克隆又称为near-miss clone/gapped clone。
(4)第四类克隆(语义层面的相似):
实现同一功能的、语法上不相似的代码片段。第四类克隆又称为语义克隆(semantic clone)。
1.3 数据集与评测标准
克隆检测工具常采用信息检索领域的准确率与召回率以及运行时间对检测效果进行评估。
Bellon 等人[9]的工作是最早提出的一个能够适用于多个克隆检测工具的数据集和评测标准。克隆检测工具可以Bellon 提供的4,319 个人工验证过的克隆对为标准计算准确率与召回率。Bellon 的数据集已被广泛用于后续的各类克隆检测工具的评测,并且已有很多工作对Bellon 数据集进行了扩展和优化。Bellon 数据集对克隆的判断具有较大的主观性,且对新的克隆工具存在较大的误判可能。而对真实系统中的克隆的判定确实无法找到绝对权威的结果(称为oracle)[2]。
C.K.Roy 等人[10]提出的Mutation/injection-based framework 为解决真实系统中对克隆的判定存在歧义的问题,提出了人工生成克隆的新思路,并采用变异分析的方法构建人工克隆数据集和评测标准。Mutation/injection-based framework 将特定的编辑操作映射为一组代码变异操作符,将操作符应用于一段代码即可得到特定类型的克隆代码。将克隆代码注入到原始代码所在的系统中,构成克隆对已知的代码库。
BigCloneBench 是J.Svajlenko 等人[11]在2014 年提出的代码克隆检测数据集和评测标准。Bellon 的数据集不适用于很多现代的克隆检测工具,而基于mutation/injection 的框架在大数据应用的背景下又存在两个问题:框架只能通过算法植入克隆,而不能发现软件中自然存在的克隆;植入一组克隆对所需的时间复杂度较高,因而无法应用于超大规模的软件系统。Big-CloneBench 为弥补上述不足,采用真实环境中的IJaDataset 2.0 数据集中的超过25,000 个Java 软件项目(365,000,000 行代码),基于启发式搜索的方法发现项目内的实现特定功能的克隆,生成候选克隆对集合,并人工对候选克隆对集合进行校验和标注。BigClone-Bench 中的克隆对涵盖了所有四个类型的克隆。
2 主流方法
2.1 通用检测流程
通用的克隆检测工具读入一个或多个源文件,经过克隆检测过程,给出克隆片段集合或列表。假设初始时认为给定源文件集合中存在的所有代码片段构成一个克隆等价类,即任意两个代码片段都具有克隆关系,那么克隆检测过程就是利用从源代码中提取的特征把不可能为克隆对的元素从集合中去除,不断过滤克隆对集合、缩小集合的规模,得到最终的克隆对的过程。
代码克隆检测的通用流程可以划分为如下四个阶段:

图1 代码克隆检测的通用流程
(1)代码预处理:预处理阶段移除对检测结果无关的代码,将源代码文件切分成代码片段并确定比较单位。
(2)代码形式转换:转换阶段将源代码转换为对应的中间表示,以便后续的比较。不同的属性以及中间表示是不同代码克隆检测方法的重要区别所在。常用的属性包括:各关键字的出现次数、圈复杂度等软件工程的指标;常见的中间表示有:词法分析后的token 流、抽象语法树、程序依赖图等。常用的提取中间表示的流程如下:
①token 提取:可通过编译前端工具或静态分析工具进行词法分析实现对token 的提取。源代码在此阶段被转换成由token 构成的序列。token 层面相似度较高的代码可以被判定为第二类克隆。
②抽象语法树(AST)提取:对上一步得到的token序列进行语法分析,得到抽象语法树(Abstract Syntax Tree)。
③程序依赖图(PDG)提取:程序依赖图(Program Dependency Graph)包含代码中的控制依赖关系和数据依赖关系。程序依赖图的节点对应源代码中的语句或控制条件,边对应控制依赖或数据依赖关系。
④正则化(Normalization)[8]:此步骤为可选步骤,用于去掉注释、空白符等格式上的差异。经过正则化后文本层面完全一致的代码可以被判定为第一类克隆。
⑤属性提取:此步骤可对代码段的属性(如代码规模、各关键字的数量、控制结构的数量、圈复杂度等)进行统计计数,得到一系列数值型的属性特征。
(3)匹配检测与候选克隆对生成:此阶段利用上一步得到的代码的中间表示和属性特征计算代码片段的相似度,将相似度高于特定阈值的代码片段纳入候选克隆对集合。此阶段的相似度计算方法通常采用基于向量、字符串等方法,可基于启发式规则[8],或借助提前构建好的索引[12]以及训练好的机器学习模型[1][4]进行过滤。通常此阶段的算法复杂度较低、适用于大规模代码库,目的是快速过滤掉相似度低的候选克隆对。因此此阶段也可称为粗粒度(coarse-grained)的克隆检测[12]。
(4)克隆对的过滤与聚合:对于上一阶段得到的候选克隆对集合,进行更细粒度的相似度计算。此阶段的相似度计算方法可基于更复杂的数据结构(如抽象语法树、程序依赖图),进行更加精细的计算,目的是发现更加隐蔽的第三、第四类型的克隆。对于过滤后的候选克隆对,可进行聚合操作,将克隆对转换为克隆等价类。
2.2 基于信息检索的方法
近年来,随着代码托管平台如GitHub、SourceForge的日益流行,越来越多的软件系统将源代码公开在互联网上,已有不少研究工作基于开源软件生态提供的规模庞大的数据集进行处理与挖掘分析[13],构建支持快速查询的代码搜索与代码推荐系统。基于信息检索的代码克隆检测框架如图2 所示。

图2 基于信息检索的代码克隆检测框架
Seunghak 等人[14]提出的SDD(Similar Data Detection)采用基于文本的克隆检测方法,实现了一个Eclipse IDE 的插件。SDD 使用了倒排索引来加快相同或相似代码的查找效率,有效降低克隆检测中比较操作的复杂度。
H.Jiang 等人[12]在2016 年提出的ROSF(Recommending cOde Snippets with multi-aspect Features)工具基于信息检索与有监督学习的方法实现了代码片段推荐。ROSF 接收自然语言格式的描述代码功能的语句,经过粗粒度搜索(coarse-grained searching)和细粒度重排序(fine-grained re-ranking)两阶段的处理,返回前K个最可能满足所需功能的代码片段。ROSF 基于包含921,713 个代码片段的数据集进行实验,比原有方法的准确率提高了20%。
P.Wang 等人[7]在2017 年提出的CCAligner 工具采用基于e-编辑距离的滑动窗口的方法,在large-gap 类型的克隆的检测上取得了良好的效果。large-gap 类型克隆指包含大量的语句级别修改的第三类克隆[7]。CCAligner 以代码窗口(code window)作为比较单位,q为窗口大小,e 为编辑距离阈值。对于每个滑动窗口,CCAligner 抽取所有(q-e)-grams 并建立到代码块的倒排索引。CCAligner 针对large-gap 克隆问题设计了emismatch 索引,避免了采用动态规划策略计算编辑距离带来的较高复杂度。实验表明,CCAligner 在largegap 类型克隆上的检测效果优于已有工具,并在前两类的克隆检测任务上仍能保持较好的效果。
2.3 基于机器学习的方法
近年来,人工智能的快速发展也使得机器学习的方法渗透到软件工程领域,在代码克隆检测的研究上,已有很多运用机器学习的方法取得了比以往更好的效果。机器学习的训练阶段与预测阶段分离的特点,使得很多精度高同时复杂度较高的方法(如基于AST 和PDG 的方法)可以在机器学习的训练阶段使用[4]。图3展示了一个分类器的训练与预测过程。

图3 分类器的训练与预测过程
L.Li 等人[15]在2017 年提出的CCLearner 工具是首个运用深度学习进行基于token 的代码克隆检测的工具。CCLearner 认为代码中的保留字、方法标识符和变量标识符蕴含了代码实现细节的特征,将代码克隆检测问题转换为判断代码对是否为克隆的分类问题。CCLearner 采用ANTLR 工具抽取不同级别的token 数量,构成向量作为代码片段的特征,并利用DeepLearning4j 工具训练一个具有2 个隐藏层、每层10 个节点的神经网络。实验表明,CCAligner 在前三类克隆的准确率和召回率上都有较好的效果,而运行时间有所增加。
V.Saini 等人[4]在2018 年提出的Oreo 工具,采用了Siamese 结构的深度神经网络的方法,在较难检测的部分第三类和第四类克隆(称为Twilight zone)上取得了良好的效果。Oreo 以方法(method)为克隆检测单位,首先提取SQO-OSS(Software Quality Observatory for Open Source Software)[16]属性列表中的属性,并按照一些启发式规则(如代码规模)过滤掉大部分可能性低的候选克隆对(此过程称为size similarity sharding)。基于方法调用信息进行代码的语义和行为上的过滤(action filter)。利用SourcererCC 工具[17]生成训练集,训练深度神经网络模型,并基于训练好的模型对较难判断的候选克隆对进行预测。实验表明,Oreo 在Twilight zone 类型克隆的检测上的准确率和召回率优于已有工具。
U.Alon 等人[18]在2019 年提出的Code2Vec 工具,借鉴了自然语言处理领域的Word2Vec[19],实现了根据代码片段预测代码功能与方法名。Code2Vec 提出了一种将代码片段表示成连续的分布式向量(code embedding)的神经网络模型,将代码片段映射为一个长度固定的向量,以便用来计算代码片段的语义属性。为了实现代码片段的分布式表示,首先将代码转换为抽象语法树中的路径,然后利用神经网络学习每个路径的原子表示(atomic representation)。实验表明,Code2Vec与以往的技术相比在同一数据集上的表现有75%的效果提升,成为首个在大型、跨项目语料库中实现代码方法名预测的工具。
3 实验部分
3.1 实验内容
本文在已有研究的基础上采用基于token 的融合信息检索和机器学习的方法进行了代码克隆检测的实验。
实验数据采用BigCloneBench 经过约减后的数据集bcb_reduced。bcb_reduced 数据集包含两文件:第一类是43 个功能已知的代码,每个源文件中包含一个功能(如计算最大公约数、解析CSV 文件等)的多种实现,每种实现构成一个方法。因此本实验以方法为克隆检测的粒度。去掉只包含一个实现的文件,保留的19 个文件如表1 所示。
第二类文件是功能未知的、待检测克隆的文件,共有50,491 个源文件。
实验所采用的方法基于这样的假设:构成克隆关系的代码倾向于实现类似的功能,而实现类似的功能通常按类似的顺序调用特定的函数。
实验所用的克隆检测方法的流程如图4 所示。源文件首先经过属性计数器处理,提取每个方法和它的属性。然后,将整个方法集合划分为区段(partition),为查询的方法分配最可能包含克隆方法的区段。对于每个区段,为所有候选代码建立倒排索引。对于每个查询方法,倒排索引将返回一个候选方法列表。利用每个方法的属性计算哈希值,比较查询方法和候选方法的哈希值,相等则判定为克隆,不相等则送入训练好的模型进行预测。

表1 功能已知的代码文件列表
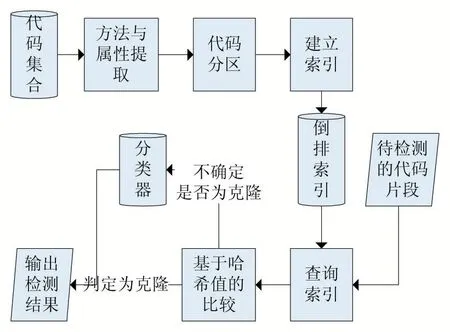
图4 实验克隆检测流程
预测采用的模型是Oreo 工具基于Siamese 神经网络训练的模型。Siamese 神经网络的结构如图5 所示。模型的输入为一个48 维的向量,向量的元素由抽取出的属性构成。输入向量被送入两个结构一致的子网络中,两个子网络对应两个待比较的方法。经过两个子网络同样的变换,两个子网络的输出结果被拼接成一个向量,输送到比较网络中。经过比较网络的计算,输出的结果再被送入分类器进行分类,分类器采用逻辑斯蒂回归实现。为防止过拟合,模型为每层加入了20%的dropout 操作。采用相对熵(relative entropy)作为损失函数(loss function)。训练过程采用随机梯度下降法,学习率设定为0.0001,并在每轮迭代后(epoch)将学习率降低3%以加快收敛速度。
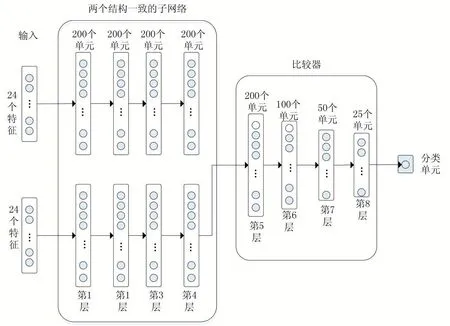
图5 Siamese神经网络结构
实验环境为一台8 核32G 的云服务器,操作系统为CentOS 6.8。
3.2 实验结果分析
利用BigCloneBench[11]和BigCloneEval[20]对克隆的召回率进行检测,结果如表2 所示。

表2 实验结果
实验结果表明,基于token 与信息检索和机器学习的方法可以对前三类克隆实现较为准确全面的检测。对于较难检测的第三类和第四类克隆,此方法可以达到比较好的检测效果。但是部分第三类克隆的检测效果和以往的工具比有所下降,原因可以解释为预测模型所采用的训练数据来自SourcererCC[17]工具的检测结果,未经过人工校验和标注,因此数据的准确性仍有提升的空间。得益于机器学习的训练与预测过程分离的模式,后续可在训练阶段利用更能表征代码语义特征的控制流图、数据流图等数据结构生成特征。
在实验中,发现存在一类假阳性(false positive)代码片段,如检测流程中的行为过滤器在两段代码中都检测到了toString()函数和append()函数的调用,以及控制语句序列的一致(循环、if 语句),并且定义的变量的数目也相同,因此判定两段代码为克隆,但两段代码实现了不同的功能。实际应用中,是否判定此类结构相似而功能不同的代码片段为克隆可根据具体需求确定;评测标准将此类归为假阳性。分析导致误判的原因,发现很多经常被调用的函数(如toString、append等),对区分代码的不同功能并没有太大的贡献。因此,借鉴信息检索中TD-IDF 的设计思路,可以将这些函数或结构归纳为停用词,并在属性计算前增加去停用词操作,可在一定程度上减少这类误判的发生。
4 结语
代码克隆检测是软件工程领域具有广泛应用价值的一个研究课题。经过几十年的研究,已有较为成熟的对代码克隆的定义、分类体系以及数据集与评测标准被提出。本文介绍了代码克隆检测的基本概念,总结了代码克隆检测工具的通用检测流程与主流检测方法,重点介绍了近几年来基于信息检索、机器学习的代码克隆检测方法的基本流程和最新研究进展。对基于token 的融合信息检索与深度学习的方法进行实验,分析实验结果,发现了采用更能表征代码语义的复杂结构与增加停用词列表两个改进方向。
猜你喜欢
环球时报(2022-09-20)2022-09-20
现代信息科技(2021年21期)2021-05-07
湖北函授大学学报(2016年13期)2017-01-03
农家书屋(2016年11期)2016-12-23
世界汽车(2016年9期)2016-09-29
科技视界(2016年12期)2016-05-25
小资CHIC!ELEGANCE(2015年14期)2015-09-23
小资CHIC!ELEGANCE(2015年15期)2015-09-01
时代英语·高二(2015年2期)2015-05-18
图书馆界(2013年5期)2013-03-11
