
Ceph系统中海量气象小文件存取性能优化方法
2019-06-26 07:57:48陆小霞雷晓春
桂林电子科技大学学报 2019年1期
陆小霞, 王 勇, 雷晓春
(1.桂林电子科技大学 信息与通信学院,广西 桂林 541004;2.桂林电子科技大学 计算机与信息安全学院, 广西 桂林 541004;3.桂林电子科技大学 广西云计算与大数据协同创新中心,广西 桂林 541004)
Ceph[1-2]分布式存储系统因其高有效性、高可靠性、高可扩展性等优异的性能使其在企业和科研领域得到了广泛关注。由于Ceph采用对象存储方式,其数据处理过程高度并行化,通过添加普通服务器至集群,可轻松将存储规模扩展至PB级,CRUSH[3](controlled replication under scalable hashing)作为Ceph核心算法,能动态计算数据存储位置,实现了元数据服务器的功能,使之成为一个无单节点故障的系统。但Ceph集群在存储海量小文件时,仍存在着几个问题:1) 由于Ceph集群的数据双倍写入导致实际磁盘的输出吞吐量是其物理性能的一半。2) 由于Ceph集群要求高度的数据一致性,对副本一致性的要求较高,在文件写入时,文件必须先写入到主副本的OSD,主副本的OSD写入成功后再同时向一个或者多个次副本的OSD写入相同的数据,只有在所有OSD都写入完成后,主副本的OSD才向客户端返回写入成功,但是这样就会降低Ceph的存储效率,特别是面对数量规模特别大的情况。
目前,针对海量小文件存储和访问效率较低问题,主要有2种解决方法:1) 文件合并方法。该方法通过小文件合并来减少文件元数据的数量,以提高小文件的存储效率。2) 文件预读取方法。该方法通过读取文件时将与其相邻的文件一起取出放入缓存,减少用户与系统的交互以提高文件的访问效率。已有文献并未考虑文件合并后,文件之间的关联性对文件预取的影响[4-8]。
文献[9-10]针对HDFS在存储海量小文件时NameNode内存消耗高等问题,提出了通过相关小文件的合并和预取来提高结构相关小文件的方案,但并未给出独立小文件的相关解决方法;游小容等[11]提出一种利用教育资源小文件间的前驱后继关系,通过空间向量模型VSM算法计算出2个文件间的相关性合并的解决方案,以解决HDFS在存储海量小文件时NameNode内存消耗高的问题;FU Songling等[4]针对并行网络文件系统在大规模访问小文件时,由于元数据访问频率较高,磁盘效率较低导致小文件访问性能较低的问题,提出一种小文件元数据预取优化机制,该机制可以明显降低用户访问延迟并充分利用客户端缓存,提高了并行网络文件系统的小文件访问效率。LI Hongqi等[6]针对Ceph在面对海量小文件同时访问时性能下降等问题,提出将同一个目录下的相关小文件归档为一个大文件的方法,以减少文件元数据的数量来提高文件的访问效率,并采用2-3-4树索引以提高小文件添加查找的灵活度,但其并未考虑各个小文件间之间的关联性问题,也未考虑文件读取优化机制。
针对上述已有文献所给出优化方法的不足,以及Ceph在处理海量小文件时存在的问题,提出一种Ceph系统中海量气象小文件存取性能优化方法。该方法的主要创新点是:1) 在Ceph集群中增加文件日志分析模块,该模块用于统计分析用户的访问行为,得到同一空间不同时间及同一时间不同空间气象文件间的关联概率,并根据其关联关系进行相关合并,通过减少文件的数量来提高文件的存储效率;2) 提出一种基于文件块的利用率和相关率的文件预取算法,通过将相关文件预取至缓存,可以减少用户与集群交互,提高文件的访问效率。
1 基于关联的小文件合并及预读取方法
1.1 小文件关联合并
在气象研究中,气象小文件之间一般存在着同一空间不同时间或同一时间不同空间的关联关系,可以通过统计分析文件的历史访问日志,利用式(1)和式(2)计算这些气象文件间的关联概率,并将相关联的文件进行合并存储至Ceph集群。
定义1P(B|A)表示用户在访问过文件A之后T时间内再访问文件B的概率。
(1)
其中:NAB为T时间内文件A和文件B同时被访问的次数;NA为文件A被访问的次数。
定义2P(AB)表示T时间范围内,文件A和B都被访问的概率,其中N为历史文件访问日总数。
(2)
1.1.1 文件关联概率算法
计算文件关联概率时首先通过分析文件历史访问日志并统计出文件A和B被访问的次数NA和NB,以及历史日志的访问总数N,然后通过式(1)和式(2)分别计算出文件的关联概率。
1.1.2 文件关联合并算法
定义3在关联关系(file1,file2,, filen)中,其中,称file1为其关联关系的前驱,而filen为其后继。
由算法1得到文件的关联集合,但该关联关系只限于2个小文件之间,如(file1,file2)和(file2,file3),若只是将该关联集合内的文件进行合并,将会导致文件重复存储且浪费存储空间。因此,在文件合并前需要将文件关联集合的关联关系先进行合并,其合并过程如下:
输入:文件历史日志
输出:文件关联集合
1.遍历文件历史访问日志分析统计得到fileA和fielB的访问次数NA、NB和NAB
2.利用公式P(B|A)=NAB/NA和P(AB)=NAB/N// 计算文件之间的关联概率
3.ifP(B|A)>minP(B|A)&&P(AB)>minP(AB):
4.file_set.append(fileA,fileB)
5.else:
6.remove(fileA,fielB)
7.return file_set
1) 在文件关联集合file_set中选取一个小文件,该文件在关联关系中前驱出现次数最多,并从这些关联关系中选择关联概率最大的作为首个合并对象。
2) 依次将其余关联关系中的前驱与此关联关系后继相同的关联关系合并在一起,若有多个关联关系满足条件,则选取关联概率最大的合并,每次合并一个关联关系就将其从file_set中移除。
3) 重复执行过程2直到找不到合适的关联关系,结束此次合并,返回过程1开始下一次合并。
在文件进行合并时,为避免文件分块存储,设置的文件块大小为4 MB,当文件块小于4 MB时,遍历关联文件集合将每个关联关系中的小文件进行合并存储到Ceph中。文件关联合并算法的伪代码如下:
输入:文件关联集合file_set
输出:上传至Ceph集群
1.merge(file_set,correlation){//关联关系合并
2.if (correlation=null):
3. 首个合并对象firstfile
4. nextfile=firstfile.next
5. if(size(firstfile)+size(nextfile))<4M:
6. correlation_set.append(nextfile)//关联合并
7. remove nextfile
8. else:
9. firstfile=correlation
10. if(nextfile=null):
11. correlation_set.append(firstfile)
12. remove firstfile from file_set
13. merge(file_set,correlation)//开始
下一次关联合并
14.for nextfile in correlation_set: //文件合并上传
15. if(size(mergefile)+size(nextfile))<4M:
16. mergefile.append(nextfile)
17. else:
18. upload mergefile to Ceph
19.}
1.1.3 索引文件
在小文件访问时,目前有2种方法可以提高小文件的访问效率。一种是减少用户与集群的直接交互;另外一种是减少小文件的查找时间。为了提高文件的查找效率,减少用户小文件的查找时间,在小文件合并时为各个小文件建立了相应的索引文件,通过索引文件Ceph集群可以快速找到小文件在合并后大文件中的具体位置信息,并迅速获取小文件的相关属性。在建立索引文件时,首先为大文件建立索引文件,再为大文件中的小文件建立局部索引。索引文件结构由
1.2 文件预取
1.2.1 文件预取因素
通过文件关联合并算法已将有关联的文件进行了合并,为了证明合并之后各个文件之间的关联关系是最优解,使用文件块内的利用率和块内相关率来衡量小文件合并之后的相关性。当用户访问某个小文件时,不仅要考虑文件块中小文件的相关性,还要考虑文件预取时间、用户等待时间等因素。
定义4文件块的利用率ΦURFB(utilization ratio of file block,简称URFB):表示一段时间内,用户访问某文件块中不同文件的个数与该文件块的所有小文件总个数的比值。
(3)
其中:d_f为一段时间内访问该文件块中不同小文件的个数;sum_f为该文件块中小文件的总数。
定义5文件块的相关率ΨCRFB(correlation ratio of file block,简称CRFB):用来衡量一个文件块中的小文件是否能同时传输。
(4)
(5)
其中:n为该时间段内访问该文件块的总次数;Υ表示当前文件块的相关率,对于每个文件块,Υ的初始值均设为0.1,i=1,2,3,由定义可看出,文件块的相关率是一个不断随时间变化的过程。
若用户在没有预取的情况下,读取2个文件的时间为T1=2TCeph,有预取时读取2个文件的时间为T2=TCeph+Tpre+Tcache。其中TCeph表示在没有预取的情况下,客户端从接收到用户请求到集群返回数据的时间。Tpre表示预取一个文件的时间,Tcache表示从缓存中读取文件的时间。
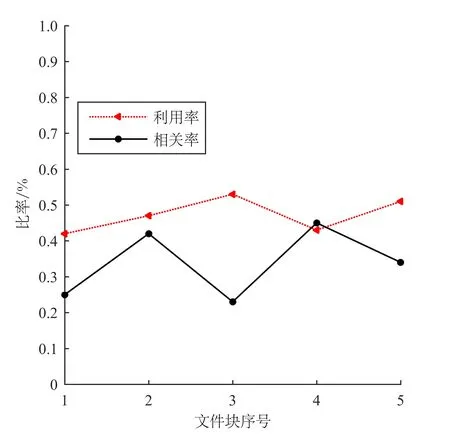
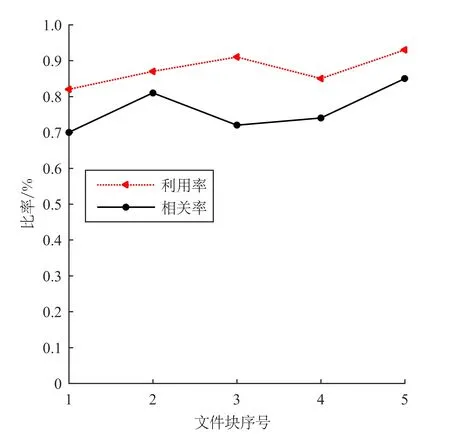
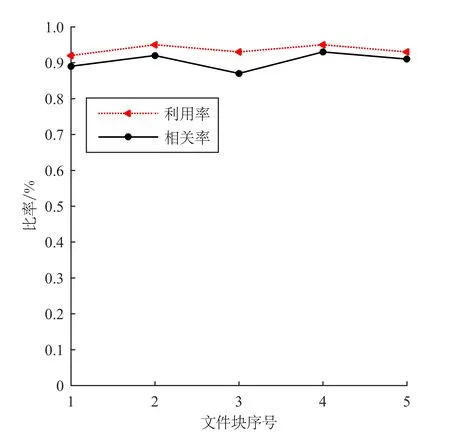
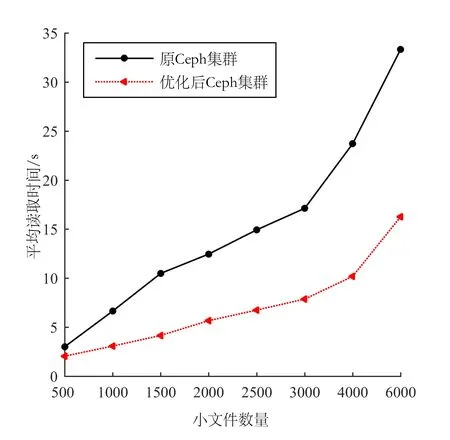
因为从缓存中读取文件时主要是访问内存时间,可以忽略不计。因此当T2 TCeph+(Tpre+Tcache)×P<(1-P)×2TCeph。 (6) 在预取文件时,需要考虑文件块的利用率和相关率及用户的最大等待时间等因素。故当文件块的利用率和相关率均大于阈值F时,说明同时传输该文件块时无效数据较少,因此可以把该文件块中的文件预读取出来;否则在用户最大等待时间内,其文件最大预取个数可通过式(7)计算。 (7) 其中Tw为用户的最大等待时间。 1.2.2 文件预取算法 文件预取算法的伪代码如下: 输入:要查找的文件file 输出:要查找的文件及其相关文件files 1.prefetch(file){ 2.ifΦCRFB&ΨURFB>F: 3. files.append(mergefile) 4.else: 6.for file in mergefile: 7. if (i>max_num): 8. break 9.P=probility(file) // 文件关联概率 10. if (TCeph+(Tpre+Tcache)×P<(1-P)×2TCeph): 11. files. append(file) 12.i=i+1 13. return files 14.} 本实验环境是基于7个节点的Ceph集群,其中:1个Mon节点,6个OSD节点。每个节点的操作系统都是Ubuntu 14.04,Ceph版本0.9.2.1,OSD系统为XFS,Python 版本为3.4,Ceph副本数为3,Ceph文件块的大小为4 MB。 本实验对比的主要性能指标是平均存储时间、文件块的利用率和相关率及平均读取时间。其中,平均读取时间是最主要的性能指标。 该实验的性能指标是:平均存储时间=文件存储时间/小文件总数。该实验分别对原Ceph集群和优化后的集群存储500,1 000,1 500,2 000,2 500,3 000,4 000,6 000个小文件,其文件平均存储时间如图1所示。 图1 文件平均存储时间 由图1可看出,随着存储小文件数目的增大,原Ceph集群存储时间明显上升,而优化后的Ceph集群则增长较为缓慢,主要是因为小文件合并后再存储至Ceph中,可以大大减少小文件的数量,所以小文件存储时明显减少了申请存储空间的次数,从而节省了小文件的存储时间。 该实验的性能指标是文件块的利用率和相关率及平均读取时间。由定义4和定义5可知,文件块的利用率和相关率都是基于一个时间段内用户的访问次数进行计算的,因此,实验针对不同时间间隔对文件块的利用率及相关率的影响进行了测试。实验结果如图2、图3、图4所示。 图2 文件块的利用率和相关率(时间:5 min) 图3 文件块的利用率和相关率(时间:15 min) 由图2可看出,当时间间隔较小时,文件块的利用率和相关率波动较大,但若时间间隔取值较大,如图4所示,文件块的利用率和相关率将接近100%,无法准确反映文件块中各个小文件间的相关性。通过多次实验发现,将时间间隔设为15 min,可以较好地反映文件块中小文件间的相关性,如图3所示,并将关联阈值设为0.6,若文件块的利用率和相关率均大于给定关联阈值,就将该文件块一起预取出来存至缓存。 图4 文件块的利用率和相关率(时间:50 min) 在文件块间利用率和相关率实验的基础上,对比了原Ceph集群和优化后的Ceph集群分别读取500,1 000,1 500,2 000,2 500,3 000,4 000,6 000个小文件时集群的平均读取时间,其文件平均读取时间如图5所示。 图5 文件平均读取时间 由图5可看出,优化后的Ceph集群的文件读取性能明显优于原Ceph集群,并且随着文件数目的增大,原Ceph集群的读取时间逐渐增大,而优化后的Ceph集群的读取时间增长较为缓慢,主要原因是优化后Ceph集群引入了小文件的预读取功能,在读取小文件时,通过将与该文件相关联的小文件预读取到缓存中,可以减少用户与集群的交互,减少用户的访问时间,从而提高用户的访问效率。 针对Ceph集群在处理海量气象小文件时存取效率较低的问题,提出一种Ceph系统中海量气象小文件存取性能的优化方法,该方法主要包括文件历史访问日志统计分析、关联文件合并和文件预读取3部分。Ceph集群存储文件时,首先通过文件关联概率算法得到气象文件间的关联概率,然后利用文件关联合并算法将相关联的文件进行合并,并利用索引机制来提高海量气象文件的查询速率;访问文件时,提出一种文件预取算法,该算法利用文件块的利用率和相关率来衡量合并后小文件间的相关性,并根据其相关性对文件进行预读取。实验结果表明,该方法能有效提高Ceph集群在处理海量气象小文件的存储效率和访问效率。提出的基于文件块的利用率和相关率的文件预取方法,并未考虑同一个数据结点上不同文件块间的相关率,以及不同数据节点上不同文件块间的相关率是否影响小文件的读取效率。2 实验与分析
2.1 文件平均存储时间
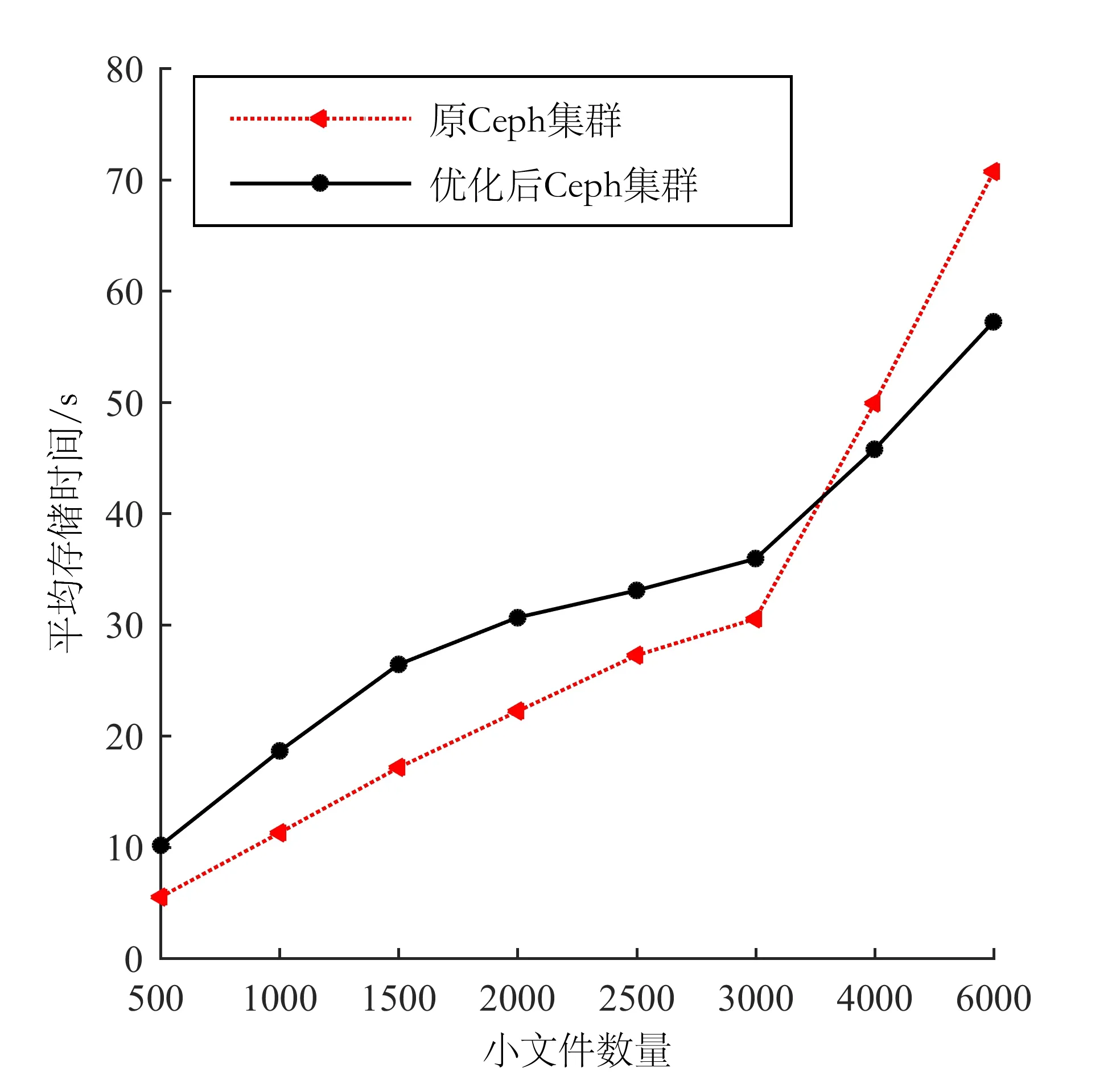
2.2 文件平读取时间
3 结束语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
当代陕西(2019年14期)2019-08-26 09:42:00
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
电子制作(2018年11期)2018-08-04 03:25:40
消费导刊(2017年24期)2018-01-31 01:29:29
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
