
基于双重加强特征的人脸年龄估计方法
2019-06-26 07:57梁晓曦蔡晓东库浩华
桂林电子科技大学学报 2019年1期
梁晓曦, 蔡晓东, 库浩华, 王 萌
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
现如今人脸图像的年龄估计问题变得越来越令人关注,因为有很多重要的应用场景,比如安全控制、人机交互、社交媒体和视频监控等。年龄估计模型的主要问题就是如何从人脸图片中提取有效的年龄特征,然后通过回归或分类的方法来进行年龄估计。年龄估计问题的关键就是学习人脸图片和真实年龄之间的一种非线性映射函数。
年龄估计可以被视作一个基于标签分布学习问题(LDL)[1],其注重的是年龄相关性的建模,可以发现相近年龄的人脸看起来比较相似。基于LDL的年龄估计方法[2]可以获得不错的效果,但是标签分布模型在适应多样的跨年龄的复杂人脸数据时就不太灵活。SMMR(soft-margin mixture of regressions)[3]的方法,通过将数据空间区分开来学习多个局部回归器,在输入输出空间中找到同类的划分,并对每个划分学习一个局部回归器,但是回归模型不能结合深度网络成为一个端到端的模型。
随着深度网络的快速发展,越来越多的端到端CNN年龄估计方法被用来解决这个非线性映射问题,并且基于CNN的方法相较于传统方法在年龄估计任务上有更好的效果。首次使用CNN来进行年龄估计[4],并引进了多任务学习的方法,但是提出的CNN非常浅,只有4层。DEX[5](deep expectation)的方法是基于VGG16[6]网络,它在IMDB-WIKI[5]库上训练了50万张图片,并且这个CNN模型获得了2015年ChaLearn LAP挑战赛第一名,之后DEX的改进版[7]不再包含人脸关键点定位技术,且能降低平均误差。OR-CNN[8]是用多输出CNN把年龄估计的顺序回归问题转化成一系列的二分类子问题,在MORPH库上能达到3.27的平均误差。Ranking-CNN[9]包含了一系列基础CNN,每个都是由顺序年龄标签训练而成,用多个二分类基础子网络的输出联合来预测年龄。但OR-CNN和Ranking-CNN所需训练模型数量较多,复杂度较高。
现在也有一些研究是采用分割人脸局部区域的方法来预测年龄。采用不同区域的人脸图片输入46个并联CNN[4],并且能在MORPH库上能达到3.63的平均误差。但是,它并未考虑到局部区域和全局区域的关系,并且网络结构非常复杂。文献[10]采用了类似于文献[4]的方法,但是无太大进步,因为它忽略了子区域间的不同性导致增加了训练的复杂度。
受到使用分割子区域作为输入的启发,首先通过人脸关键点定位来裁剪人脸图片获得局部区域,然后结合全局区域和局部区域输入基于压缩激励模块的并联残差网络中,并通过多网络联合判断的方式预测年龄。本方法能够获得较低的平均绝对误差,并保证较低的复杂度。
1 基于双重加强特征的人脸年龄估计方法
1.1 基于全局与局部加强特征的多网络联合预测方法
从单张图片上判断一个人的年龄是个极其挑战性的任务,因为在不同的年龄范围反映年龄的脸部特征有不同的类型。比如,在儿童时期年龄的增长在脸型上的变化很明显,而在成年时期的变化主要在于皮肤的皱纹。因此,不仅仅注意到全局区域,也注意到局部区域,因为一些重要区域的局部特征对于年龄估计很重要,比如眼睛、嘴巴、鼻子等。
为了能够获得人脸图片的局部区域特征,采用了基于人脸关键点的局部区域裁剪方法。利用dlib库[11]定位出人脸关键点,然后根据眼睛、嘴巴、鼻子的关键点位置,裁剪出3个子区域,分别是左眼区域、嘴巴区域、鼻子区域。
除此之外,还使用了多网络联合预测年龄的方法,每个网络都是一个局部结合全局的联合网络,可以在已有的全局特征的基础上有效地加强关键性的局部特征信息。如图1所示,将输入的整张人脸和3个不同的人脸局部区域都输入到局部结合全局联合网络,每个网络以两张人脸区域作为输入,一张是全局脸,另一张是重要子区域。最终把3个估计的年龄结果结合起来得到联合预测年龄。
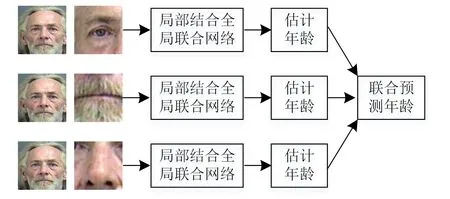
图1 多网络联合预测年龄
因为只有3个子区域,所以联合预测年龄的计算公式为:
其中:F为最终的预测年龄;Ak为第k个子区域的估计年龄;wk为第k个子区域的加权权值。取wk=1/3,也就是把3个估计年龄取均值。
1.2 再次加强特征的压缩激励并联残差网络
图1中的局部结合全局联合网络采用的是一种基于压缩激励[12]模块的并联残差网络,该模块使用了特征重标定的方法进一步加强了对于年龄估计任务有用的特征。压缩激励残差模块的结构及示意图如图2所示。
图2中Conv为卷积层,Global pooling为全局平均池化层,Sigmoid为激活函数层,Scale为缩放层。示意图中每个小长方体代表一个通道,不同的颜色代表各个通道的不同权值。

图2 压缩激励残差模块
该模块首先使用全局平均池化来进行特征压缩操作,将每个通道的二维特征变成一个实数,即W×H×C变成了1×1×C,这个实数某种程度上具有全局感受野,它代表特征通道上响应的全局分布,通过训练学习后用来表征特征通道间的相关性。
紧接进行特征激励操作,首先通过一个卷积层将特征通道数降低到输入的 1/16,然后经过激活函数后,再通过一个卷积层升回到原来的维度。相比仅使用一个卷积层,这样做可以保证更多的非线性,可以更好地拟合通道间复杂的相关性,同时也极大地减少了参数量和计算量。然后通过一个Sigmoid获得0到1之间归一化的权重。
最后是重标定操作,将特征激励输出的权重看作经过特征选择后的每个特征通道的重要性,通过一个缩放层将归一化后的权重加权到每个通道的特征上,完成在通道维度上的对原始特征的重标定。
特征重标定的方法可以通过学习的方式来自动获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征,并抑制对当前任务用处不大的特征。
将Resnet18[13]中的残差模块替换成压缩激励残差模块后可以得到SE-Resnet18,如图3所示,将2个SE-Resnet18并联起来就可以构建基于压缩激励模块的并联残差网络,也就是图1中局部结合全局联合网络。
图3中SE-Resnet18表示经过压缩激励模块改进后的Resnet18网络,Concat为连接层;Pooling为平均池化层;Fc为全连接层;Softmax为分类层。

图3 基于压缩激励模块的并联残差网络
2 实验预处理、数据库简介与评价指标
实验基于Caffe[14]深度学习框架,硬件配置包括Intel i5-4460(4×3.2 GHz处理器)、8 GB内存、GTX980Ti显卡以及 Ubuntu14.04操作系统。
2.1 人脸预处理与区域裁剪
首先dlib库对样本图片进行人脸关键点定位,并根据两眼中心进行人脸对齐。继续使用dlib库对对齐后的人脸图片进行人脸检测并裁剪。之后根据人脸关键点的位置裁剪3个局部区域,分别是左眼区域,嘴巴区域和鼻子区域,如图4所示,具体裁剪方法如下:
基于dlib库的人脸关键点定位一共可以得到68个人脸关键点,用序号0~67表示。
1)左眼睛区域分块:以点17到点30的距离为长宽,以点30为切割方形的右下角点。
2)嘴巴区域分块:以点48到点54的距离为长宽,点33在切割方形的上边,点48、点54在切割方形的左右两边。
3)鼻子区域分块:以点27到点33的距离为长宽,点33为切割方形的下边中点。

图4 人脸预处理与人脸分块
2.2 训练库与测试库
对MORPH库[15]的人脸图片进行人脸关键点定位和人脸检测,舍弃无法定位关键点和无法检测到人脸的图片。从得到的51 327张图片的MORPH库随机挑选80%作为训练集,20%作为测试集,训练集共41 062张,测试集共10 265张。图片年龄分布在16~66岁,共51类。并对样本图片进行分块,并将所有图片尺寸转化成224×224,得到整张人脸、左眼区域、鼻子区域、嘴巴区域4部分图片。
2.3 评价指标
年龄估计的评价指标通常有2个,分别是平均绝对误差MAE(mean absolute error)和累积分CS(cumulative score)。
MAE是指测试集的平均绝对误差,公式为
其中:MMAE为平均绝对误差;n为测试图片数量;pi为第i张图片的年龄预测值;ti为第i张图片的年龄真实值。
累积分CS的计算公式为
其中:CCS为累积分;N为测试集图片的全部数量;Na为测试人脸图片中满足估计值和真实值之间的绝对误差不大于a岁的数量,取a=5。
3 实验结果及分析
3.1 全局特征与局部特征的对比分析
针对不同局部区域做了对比实验,如表1所示。从表1中可发现,使用整张人脸结合左眼区域、整张人脸结合嘴巴区域、整张人脸结合鼻子区域的方法在年龄估计问题上效果差不多,并且都好于仅使用整张人脸的结果。说明使用全局特征结合局部特征进行年龄估计的方法好于仅使用全局特征来判断年龄。原因就是全局结合局部的方式可以在全局特征的基础上加强关键性的局部特征信息,有助于提升年龄估计的精度。
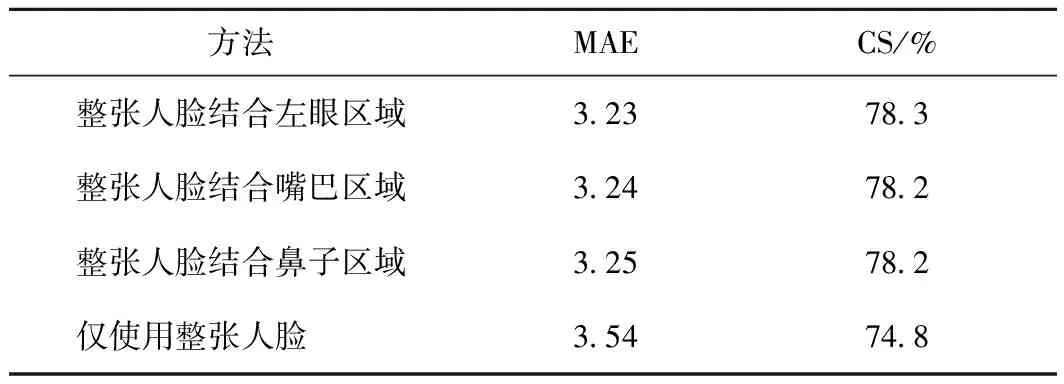
表1 全局特征与局部特征的效果对比
3.2 残差网络与压缩激励残差网络的对比分析
对图3中的基础网络分别用残差网络和压缩激励残差网络做了年龄估计的对比实验。结果如表2所示,可以发现使用压缩激励残差网络来进行年龄估计的效果要好于残差网络。原因就是压缩激励模块进一步加强了有用的特征,抑制了对于年龄估计任务不太相关的特征,因此提高了准确率。
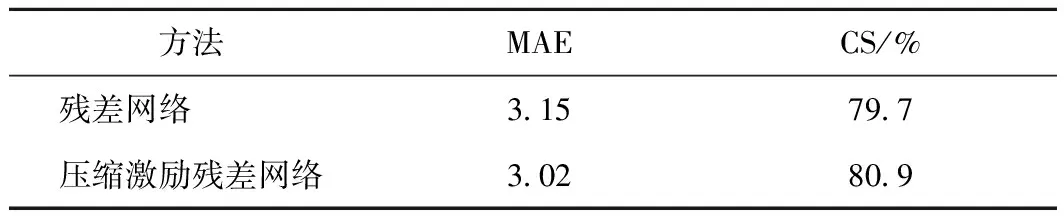
表2 残差网络与压缩激励残差网络的对比
3.3 与其他方法的比较与分析
从表3可知,使用3个模型联合判断年龄结果MAE为3.02,CS为80.9%,均好于表1的结果,说明使用多种局部特征的多网络联合预测的方法要好于仅使用单个局部特征。因为多个子区域包含了更多的关键性局部特征,所以效果要好于仅使用单个子区域。
相对于传统算法[1-3],本方法具有较低的平均绝对误差,因为本方法是一种端到端的深度学习方法,对于复杂函数映射有更好的拟合能力。而相较于深度学习方法OR-CNN,本方法具有更好的效果和更少的操作复杂度。目前Ranking-CNN算法拥有较好的效果,因为Ranking-CNN对于每一岁的判定都需要使用一个模型,所以精度较高,但是这样会增加训练的复杂度,而本方法仅需要3个模型,并且在平均绝对误差的效果上也接近于Ranking-CNN,同时在复杂度上具有一定优势。
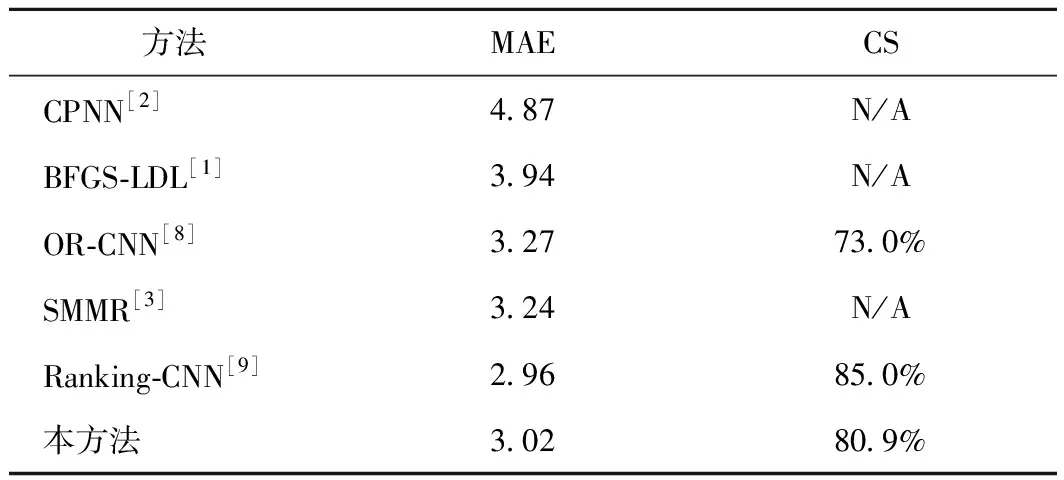
表3 本方法与其他方法的结果对比
4 结束语
提出了一种基于双重加强特征的人脸年龄估计方法。其中通过人脸关键点的局部区域裁剪方法可以有效地获取有用的局部区域,而局部结合全局的联合网络又可以在已有的全局特征下加强关键性的局部特征信息。除此之外,基于压缩激励的并联残差网络可以进一步加强对年龄估计任务有用的特征并抑制用处不大的特征。年龄估计的实验表明,本方法相较于其他方法具有较低的平均绝对误差,且算法复杂度也较低。未来的研究可以考虑结合Ranking-CNN的方法提升年龄估计精度或者改进预处理方法,增加更多的局部特征,以及找到多模型加权的合适权值。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
网络安全与数据管理(2022年3期)2022-05-23
数学物理学报(2022年2期)2022-04-26
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
动漫星空(2018年9期)2018-10-26
金桥(2018年4期)2018-09-26
中国惯性技术学报(2015年1期)2015-12-19
