
基于SSD的图像神经网络检测模型的研究
2019-06-20 03:40刘靓葳董延华
通化师范学院学报 2019年6期
王 铭,刘靓葳,董延华
随着人工智能的高速发展,从智能AI的出现到海面船只的检测,人工智能变得越来越重要.而目标检测作为人工智能的重要领域之一,受到越来越多的人的关注和重视.目前,目标检测的算法主要分为两类,第一类是两步走的目标检测算法,先进行区域推荐,而后进行目标分类,典型代表有Regions with Convolutional Neural Network Feature(简称 R-CNN)[1]、Spatial Pyramid Pooling Convolutional Networks(简称 SPP-net)[2]、Fast R-CNN[3]等.第二类是端到端的目标检测,即采用一个网络进行一步到位,基于深度学习的回归思想,其典型代表为 You Only Look Once[4](简称YOLO)、SSD等[5].在上述的几种算法中,SSD的性能相对更好,具有速度快、精度高等优点.SSD有许多网络模型,主要区别在于检测图像的大小不同,例如:SSD500表示支持的检测图像的大小为500*500,SSD300表示支持的检测图像大小为300*300.本文主要介绍TensorFlow在图像识别的领域,图像识别过程主要包括训练和测试两个阶段的应用.训练阶段对图像特征进行训练得到分类模型,测试阶段可以利用已训练模型得到识别结果[6].
1 TensorFlow框架
Google发布人工智能系统TensorFlow不仅能够实现机器学习算法的接口,而且也是机器学习的框架.TensorFlow可被用于语音识别、自然语言处理和图像识别等多项机器深度学习领域.
1.1 TensorFlow的基本特点
TensorFlow以高度的灵活性、真正的可移植性、自动求微分、多语言支持、性能最优化等特征被越来越多的人应用.而TensorFlow的库Tensor-Flow Object Detection API其用途为训练能够识别出物体的神经网络.这个库几乎没有任何限制,可以用他训练AI识别照片里的人物、猫、狗、汽车等,本文用于识别“皮卡丘”.
1.2 TensorFlow Object Detection API库
TensorFlow Object Detection API目的是创建一个能够在单个图像中定位和识别多个对象的精确机器学习模型.TensorFlow Object Detection API是在Tensorflow上构造的开源框架,易于构建、训练和部署目标检测模型,也是用于解决物体检测问题的库,物体检测即在一个画面帧中检测各种不同物体的过程,本文中是识别皮卡丘的过程.这个库较为特殊的是,它能根据不同的速度和内存使用情况变换模型的准确度,因此可以让模型适配于自己的需求和所用平台.这个库还有一些非常创新的物体检测架构,比如SSD、Faster R-CNN、R-FCN和MobileNet等,本文采用的是SSD.
2SSD算法
SSD学习算法结合了YOLO算法中的回归思想和Faster-RCNN算法中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO算法速度快的特性,也保证了窗口预测同Faster-RCNN算法一样精准[7].SSD算法的核心是在不同尺度的特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移.
2.1 SSD结构模型
SSD结构模型以VGG-16为基础,使用VGG的前五个卷积,后面增加从CONV6开始的5个卷积结构,输入图片要求300*300.SSD框架主要分成两部分,其一是位于前段的深度学习网络part_one;其二是位于后端的多尺度特征检测网络part_two.SSD结构模型如图1所示[8].
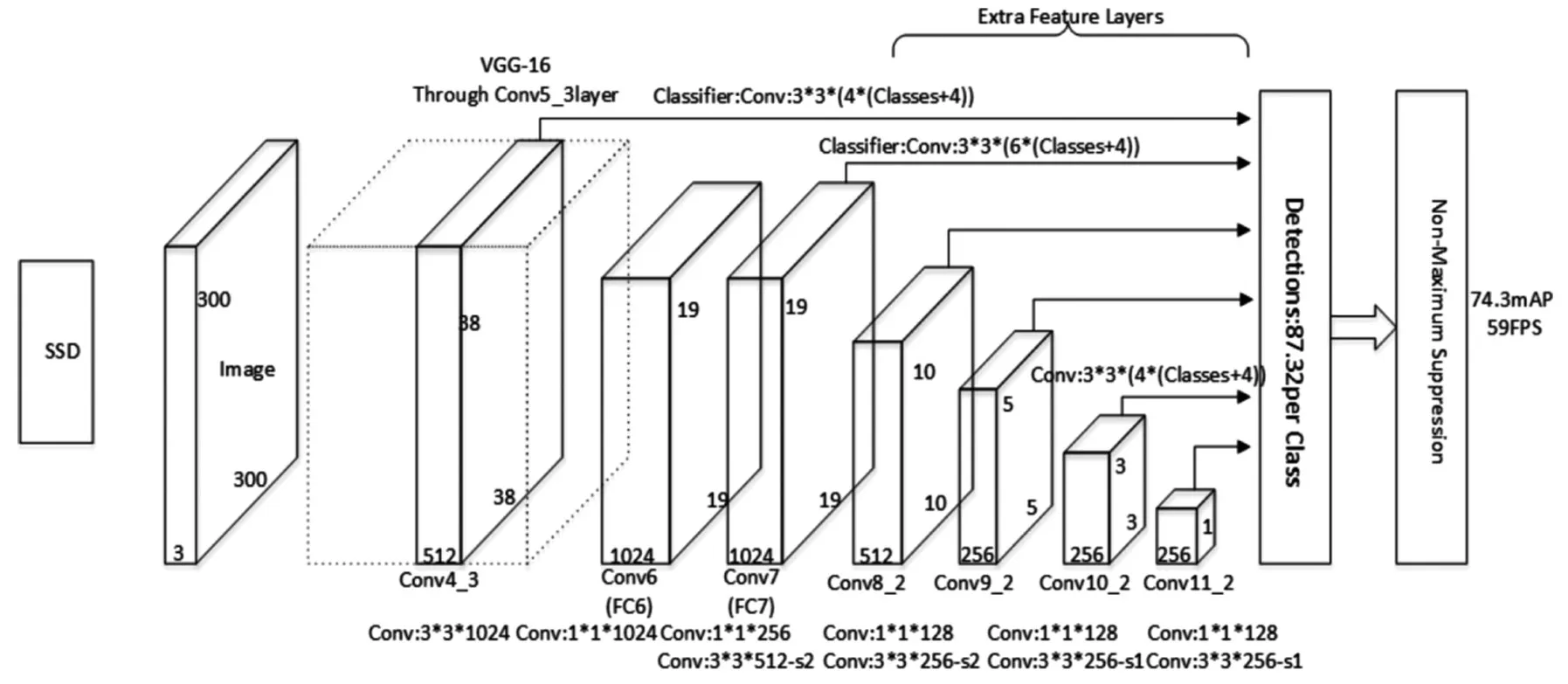
图1 SSD的结构模型图
2.2 SSD流程
SSD中引入了defalut box,实际上与Faster R-CNN的anchor box机制类似,目的是预设一些目标预选框,不同的是在不同尺度feature map[9]所有特征点上是使用不同的prior boxes.part_one的feature map大小为38*38,经过规格层的处理后,保持大小不变,传至SSD特有网络,表示为conv4_3;part_two输出fc7,feature map大小为19*19,传至SSD特有网络[10].为获取更多的特征图像信息,增加了4个卷积神经.输出的feature map大小分别为 10*10、5*5、3*3、1*1,以上均传至SSD特有网络.Detector&classifier的三个部分,分别为 default boxes、localization、confidence.default boxes表示为默认候选框,其本质是得到坐标数据,本部分可由开始确定的网络模型参数进行计算得到.localization表示位置偏移量,其本质是得到坐标的调整参数,即每个数据都要分别进行同样的处理,localization最后会进行维度的合并.confidence表示置信度,其本质是得到最终的可能性,即属于某一类别的概率.本文中则是识别“皮卡丘”的概率.SSD原理过程图如图2所示.
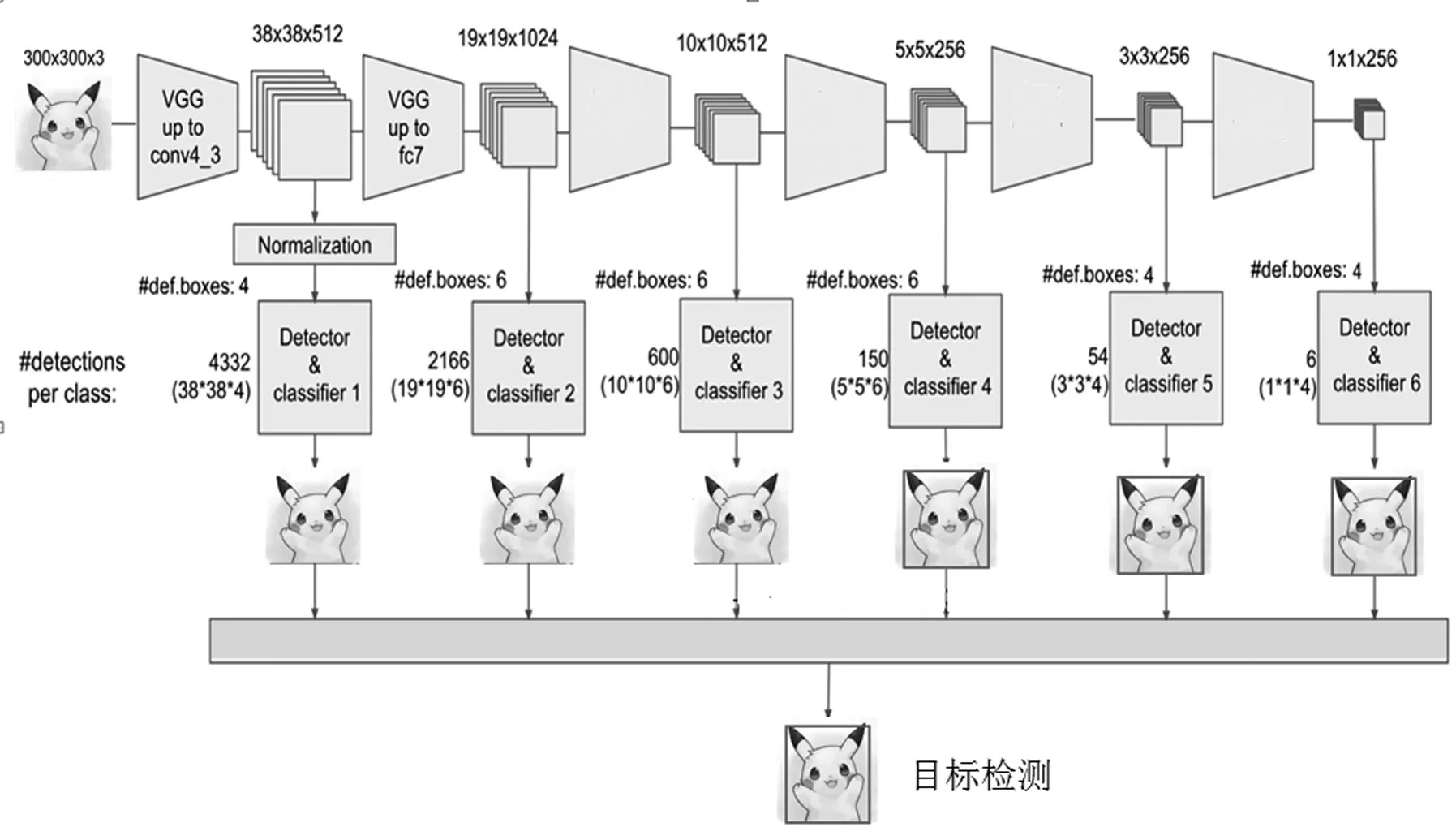
图2 SSD原理过程图
2.3 选取默认框
SSD利用多尺度的方法来进行目标检测.假设模型检测时采用m层特征图,则第k个特征图的默认框的比例为[11]:
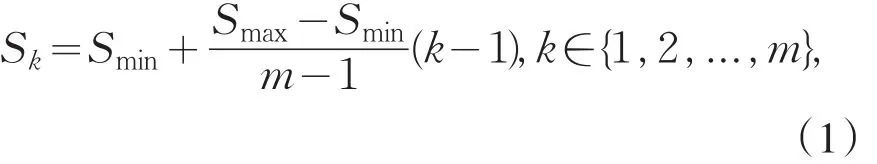
式中:Smin代表特征层默认框所占输入图像的最小比例,一般取值为0.2;Smax代表特征层默认框占输入图像的最大比例,一般取值为0.9.同时,SSD采用Faster-RCNN中的anchor机制,对于一个特征层中的默认框采用不同的高宽比,增强对不同形状的物体的检测效果,增强鲁棒性.本文中将采用5种高度比,即:

当r1=1时,添加,每个默认框高度分别代表为:

SSD在训练的同时对位置和目标种类进行回归,其目标损失函数L(x,c,l,g)是置信损失之和[11],即为:

其中N代表ground truth物体框匹配的默认框的个数,Lconf(x,c)代表置信损失函数,Lloc(x,l,g)代表位置损失函数,x为默认框与不同类别的ground truth物体框的匹配结果,c为预测物体框的置信度,l为预测物体框的位置信息,g为ground truth物体框的位置信息;α为权衡置信损失和位置损失的参数,一般为1.在目标损失函数中同时包含置信损失和位置损失,在训练中,通过减少损失函数的函数值可以确保在提升预测框类别置信度的同时也提高预测框的位置可信度而用于数据集训练,通过多次结果的反馈,不断提高模型的目标检测能力,从而训练出模型.
3 实验准备及过程
3.1 数据集的创建与处理
对于识别皮卡丘的项目,本文下载了230个中等大小的皮卡丘照片,将保存照片的目录命名为“images”.为了提高结果的精确度找了些不同角度和不同形状的皮卡丘的照片,在图像获取完毕后,用Labelme进行标记,即围绕物体画一个边界框,告诉系统框里的这个物体实际上就是要学习识别的物体.当标记完毕时,得到一个名为“annotations”的目录,描述了每张图像的边界框的xml文件.
3.2 拆分和创建新的数据集
拆分数据集,即将230个中等大小的图片,分为训练集和测试集.本文中向训练目录里添加了约70%的图像及其xml文件,向测试目录里添加了约30%的图像及其xml文件[5].创建新的数据集为将图像及其xml文件的格式转换成Tensor-Flow可读取的格式,也就是Tfrecord格式.
3.3 创建标签
“标签”映射会指明标签及其需要的索引.如下所示:

3.4 运用SSD识别“皮卡丘”过程
Google发布了新的TensorFlow物体检测API,其中包含了预训练的模型,本文使用百度下载的数据集对模型进行重新训练,并通过对库的载入、环境的设置、物体检测的载入、模型的准备、下载模型、将模型载入内存、载入标签图、开始检测.部分核心代码如下:


4 结论
不同模式下的目标和对象识别已经成为研究的热点.本文主要在基于TensorFlow框架中Object Detection API基础上,结合SSD算法,设计实现了图像神经网络检测模型,并将其应用于“皮卡丘”的图像集的识别中.实验证明如图3所示,即标签为pikachu的置信度率达到99%,因为本实验只有一个识别的物体“皮卡丘”,经过十组的测试结果,九组可以达到识别结果98%以上,表示检测结果准确率较高.具体识别率如表1所示.

图3 识别“皮卡丘”
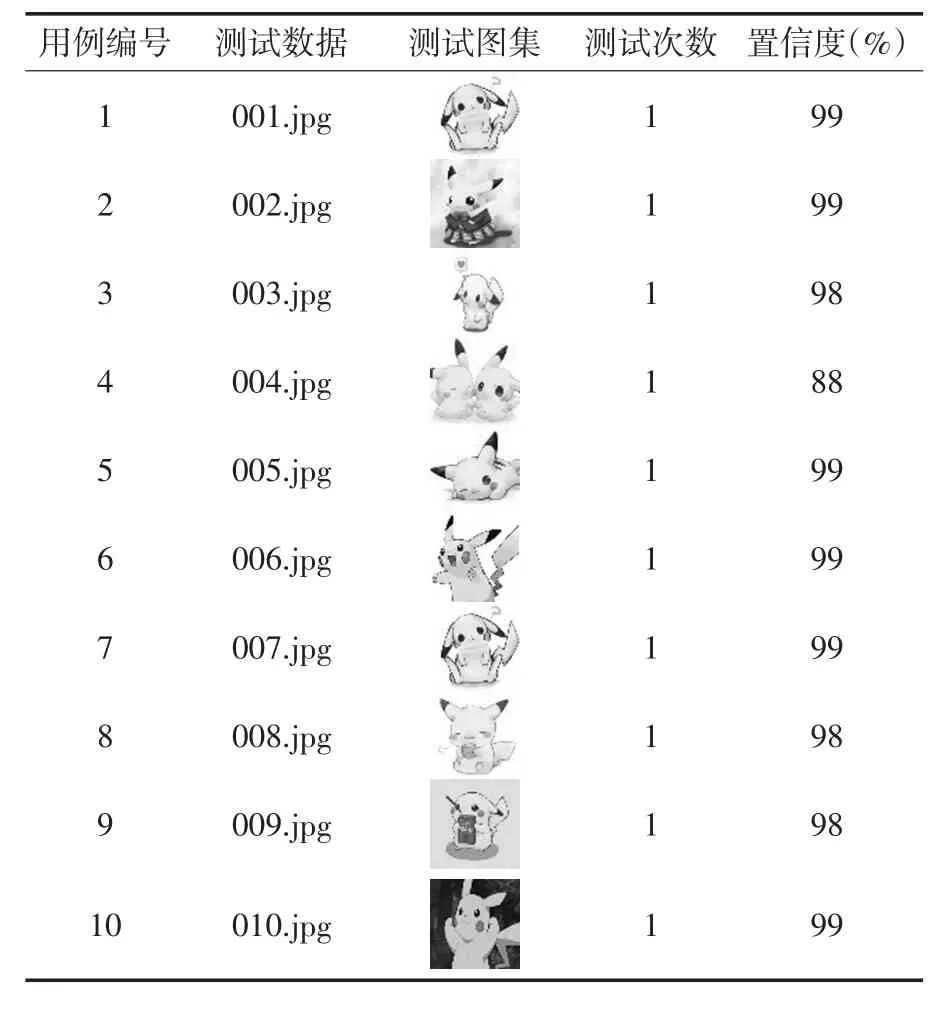
表1 识别“皮卡丘”测试结果
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
作文小学中年级(2020年12期)2020-12-29
中学生数理化·高一版(2020年1期)2020-02-20
小学科学(学生版)(2019年8期)2019-09-02
小哥白尼(野生动物)(2019年5期)2019-08-27
学生天地(2019年28期)2019-08-25
今日农业(2019年15期)2019-01-03
共产党员(辽宁)(2015年2期)2015-12-06
少儿科学周刊·儿童版(2015年2期)2015-07-07
读者·校园版(2015年19期)2015-05-14
