
教育资源个性化推荐方法研究与实现
2019-06-14 07:36李文欣文勇军唐立军
计算机技术与发展 2019年6期
李文欣,文勇军,唐立军
(1.长沙理工大学 物理与电子科学学院,湖南 长沙 410114;2.长沙理工大学 近地空间电磁环境监测与建模湖南省普通高校重点实验室,湖南 长沙 410114)
0 引 言
近年来,国内外对个性化推荐技术研究越来越重视,个性化推荐技术广泛应用于在社交网络、电子商务等领域[1-2]。随着网络教育资源的爆发式增加,教育资源的查找效率越来越低,而教育资源的用户数量越来越大,用户需求迫切与教育资源利用率低的矛盾越来越突出,因此,教育资源的推荐方法研究和推荐系统的实现引起了国内外研究人员的高度重视[3-4]。文中利用大数据分析技术开展预测算法的研究,构建基于用户和教育资源之间的预测模型,探讨教育资源的推荐方法,设计并实现教育资源个性化推荐系统。
1 教育资源的推荐范围与要求
1.1 教育资源推荐范围
根据教育资源的更新频率和权威性,文中选择参考书、论文、教学资源(课件)和教育发展动态等四类关键资源为研究对象[5-6],选定四个官方网站公开信息作为本课题研究的数据:选取“中国高校教材图书馆”作为参考书的数据来源,选取“中国知网”作为论文的数据来源,选取“高等教育资讯网”下的“中国高校课件下载中心”作为教学资源(课件)的数据来源,选取“中国教育新闻网”作为教育发展动态的数据来源。
1.2 教育资源推荐要求
一般的推荐系统必须将一定范围内的资源全面、准确、实时地推荐给用户,文中针对教育资源推荐主要考虑推荐覆盖率、推荐准确率、推荐实时性的要求。
(1)推荐覆盖率:推荐的教育资源信息必须涵盖参考书、论文、教学资源(课件)和教育发展动态等资源类型。
(2)推荐准确率:推荐的教育资源信息必须符合用户的特征属性,即必须与用户的实际需求相关联,要求推荐准确率大于80%。
(3)推荐实时性:用户自身特征值的改变,或教育资源的更新,系统能及时响应,自动调整用户-教育资源模型参数,推荐出最新最适合用户的教育资源信息。
2 预测推荐的原理和技术
2.1 预测推荐的原理
(1)矩阵分解模型(GMF)。
GMF模型[7]是一种在推荐领域中常用来降低维数的技术,将原始矩阵分解为两个或多个矩阵的乘积,用来弥补稀疏矩阵的缺陷,因此可用于推导和完善用户和教育资源特征值信息,能够很好地处理用户和教育资源中的线性关系,如图1所示。为获得用户-教育资源稀疏矩阵中的未知预测值,将用户特征值u和教育资源特征值r作为参数输入到GMF模型中,形成用户特征值矩阵pT和教育资源特征值矩阵q,将用户特征值矩阵与教育资源特征值矩阵进行点乘运算pT*q,得到用户-教育资源关系矩阵中Y12、Y21、Y23等预测值,表示为:
(1)
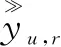
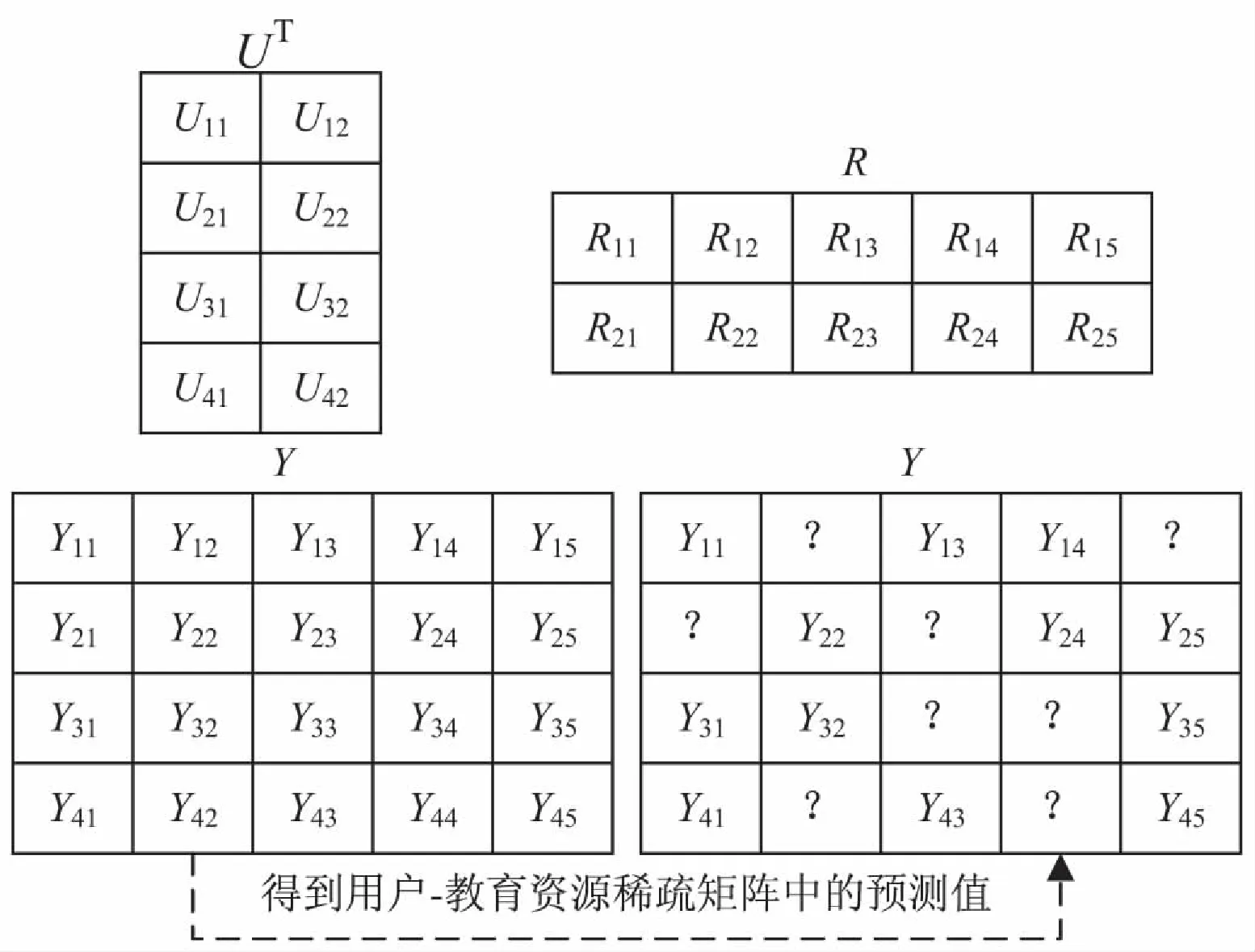
图1 教育资源预测中GMF原理
(2)多层感知机模型(MLP)。
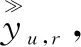

(2)
2.2 预测算法分析与模型
将NeuMF预测模型[9]引入教育资源推荐中,结合上面讨论的线性GMF模型和非线性的MLP模型,处理用户-教育资源间线性和非线性关系,得到教育资源预测值。
NeuMF教育资源推荐模型流程如图2所示。

图2 NeuMF教育资源推荐模型流程
在NeuMF教育资源推荐模型中,线性的用户-教育资源预测值由GMF模型输出,用yGMF表示;非线性的用户-教育资源预测值由MLP模型输出,用yMLP表示。由式3可知,Sigmoid函数在特征比较中权值更新准确,使用Sigmoid函数激励yGMF和yMLP,得到式4表示的最终教育资源预测值。
(3)
(4)
2.3 相关技术
(1)爬虫技术。
爬虫技术[10],是按照一定规则,自动抓取互联网信息的程序或者脚本,功能上分为数据采集、处理和储存三部分,可以很好地用于教育资源数据获取。实现方法分为分布式爬虫、Python爬虫和Java爬虫等。文中采用Java爬虫技术实现教育资源的获取。
教育资源爬虫技术中,设定资源名称、资源类型、资源更新时间等作为爬虫标签,提取数据库中教育资源信息网站库中的URL,作为爬虫URL队列,模拟用户发送访问请求,得到特定网页源代码。通过对网页源代码的解析,根据资源标签找到标签中的资源名称、资源类型和资源更新时间等内容。内容依照教育资源信息表中的资源名称、资源类型、资源来源等字段格式化,存入本地MySQL。
通过MySQL定时任务,每天自动启动Java爬虫操作,模拟用户请求,对URL队列中资源信息进行及时更新,保证教育资源信息爬虫的时效性。同时利用定时任务,定期启动自动删除操作,删除过期的资源数据,保证MySQL中教育资源读取效率。
(2)个性化推荐技术。
基于用户-项目特征匹配的个性化推荐技术是一种用户和项目矩阵分解的技术[11-13],其推荐模式可以直接应用到教育资源推荐。结合教育资源推荐的原理和方法,可以得到教育资源推荐中用户-项目特征匹配推荐模式,教育资源中个性化推荐技术为提取用户ID、专业领域、学习兴趣、行为等特征值u和教育资源ID、资源名称、资源类型等特征值r,作为模型参数,形成用户特征值矩阵pT和教育资源特征值矩阵q,经过内积、求导等反复运算,ReLU函数激活,得到预测值。选取大于预定值K的预测值,根据预测值优先级得到最终的推荐教育资源。
3 系统设计与结果分析
3.1 系统架构
采用网络爬虫技术和基于NeuMF模型的特征匹配技术,设计实现教育资源个性化推荐系统。系统使用开源的Java语言开发设计,采用Liger UI框架,结合JavaScript和CSS技术,对系统的前端页面进行设计。后台采用SSM框架,Spring中实现业务对象管理,Spring MVC中的View层和Controller层响应用户请求,Mybatis中的Dao层作为数据对象的持久化引擎,封装数据库中用户和教育资源数据[14]。数据存储采用关系型数据库MySQL,其查找速率快和灵活性高等优势为系统性能提供保障。
3.2 系统实现
教育资源个性化推荐系统包含教育资源获取、教育资源信息、推荐资源信息、个人教育资源、学科信息管理等10个模块,下面主要介绍教育资源获取模块和教育资源推荐模块的实现。
1)教育资源获取模块的实现。
采用爬虫技术中的Java爬虫技术,在特定URL页面,获取需要的教育资源信息。将爬虫获取的数据格式化后存入到本地MySQL数据库。
在特定的教育资源网站中,包含众多公开的教育资源信息,首先要分析其教育资源信息发布页面的源代码,找出教育资源相关信息点位置及内容标签结构,确定正则表达式或标签选择器作为爬取规则,再利用Java语言编写爬虫程序,获取教育资源信息的标题、作者、分类属性、链接地址等大数据信息[15-16]。将获取的数据格式化后存入到本地MySQL数据库。实现步骤如下:
(1)以HTTP Web Request为基类,创建DAL操作类Request Helper;
(2)通过Request Helper,创建实体Request;
(3)在Request中构造请求HTML,以Post方法提交给Remote server;
(4)获得server 302响应后,Data flow合并写入Document;
(5)调用专用文件操作类,逐条读取文件;
(6)调用DAL,写入MySQL。
2)教育资源推荐模块的实现。
系统从本地MySQL数据库中提取数据,将用户特征值u和教育资源特征值r进行特征匹配,建立用户-教育资源特征匹配模型进行分析预测,得到用户-教育资源间的预测值,然后将预测值高于预定值K的教育资源信息推荐给Web用户,完成教育资源信息推荐。
推荐流程如图3所示。
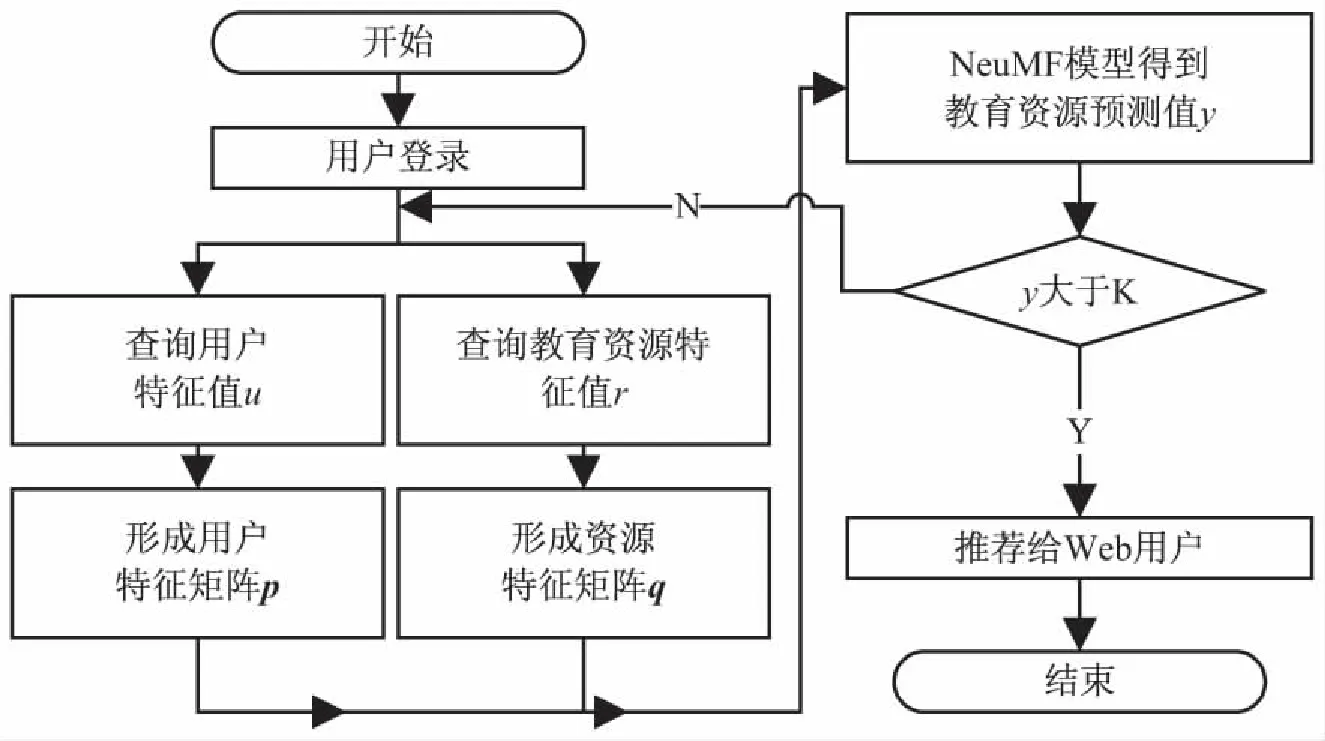
图3 推荐流程
3.3 系统测试及结果分析
教育资源个性化推荐系统设计完成后,通过实验室模拟的方式对系统进行实验测试,包括功能测试和性能测试。测试环境为:硬件平台为Dell Inspiron 3420笔记本;操作系统为正版Windows7 64位;处理器为Intel(R) Core(TM) i5-3210M;内存(RAM)为8 G;数据库为MySQL 5.7。
(1)功能测试。
测试方法:通过模拟系统用户操作,登录教育资源个性化推荐系统后,对各个一级模块和二级模块功能进行操作测试。
系统功能测试结果见表1。

表1 系统功能测试
表1表明,系统一级模块和二级模块等所有功能测试结果均已通过,操作正常,能够正常工作。
(2)性能测试。
测试方法:推荐性能测试,模拟100个特征信息互不相同的用户,通过读取MySQL数据库中1 000份教育资源信息,即参考书、论文、教学资源(课件)和教育发展动态各250份,对系统进行预测性能测试。实时性测试,在原基础上改变用户学科信息、学习兴趣、行为等特征值,得到改变后用户特征值的更新结果;改变教育资源,得到更新的教育资源特征值。在相同环境下对系统推荐性能重新测试,启动10次系统,查看推荐的教育资源更新情况。
测试结果见表2和表3。

表2 改变前的推荐结果
由表2可知,系统推荐信息涵盖参考书、论文、教学资源(课件)和教育发展动态等资源类型,推荐准确率均大于80%,且能推荐最新资源,系统预测推荐性能良好。

表3 改变后的推荐结果
由表3可知,在改变用户特征值和更新教育资源后,系统能够得到新的推荐教育资源,推荐准确率没有太大波动,且在推荐中包含最新的教育资源,可见系统推荐性能较好,能够及时响应用户-教育资源间的特征改变,达到教育资源推荐要求。
4 结束语
将社交网络、电子商务等领域中应用广泛的个性化技术引入到教育资源推荐中,通过对教育资源用户-项目的特征匹配模型研究,构建了基于用户和教育资源之间的预测模型,得到了教育资源的个性化推荐方法,设计并实现了教育资源个性化推荐系统。从测试结果来看,该教育资源个性化推荐方法实时性强、覆盖率大,推荐效果好,可以推广应用到教育资源推荐领域。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2022-01-12
现代信息科技(2021年21期)2021-05-07
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
电子产品世界(2021年6期)2021-02-10
计算机与数字工程(2020年10期)2020-12-07
中国现代医生(2020年2期)2020-04-09
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
电脑知识与技术·经验技巧(2018年1期)2018-05-30
