
基于词性标注与分词消歧的中文分词方法
2019-05-27 09:53翟紫姹
广州大学学报(自然科学版) 2019年5期
熊 健, 翟紫姹
(广州大学 经济与统计学院, 广东 广州 510006)
0 引 言
随着信息时代的来临,自然语言处理作为一门涉及语言学、数学、计算机科学等多领域的综合性学科,被广泛运用于计算机、人工智能等领域,致力于实现人与计算机之间的有效通信.中文信息处理是自然语言处理的一个重要分支,在搜索引擎[1]、信息抽取[2]、语音识别[3]、机器翻译[4]等新兴领域中被广泛运用.词作为汉语中最小的可独立活动的语义单位,是自然语言处理系统中基本的操作单元和不可替代的知识载体[5].中文分词是中文信息处理的前提和基础,其算法的精度和效果直接影响中文信息处理技术后续工作的实用性与有效性.在英文中,词与词之间皆有空格相隔,而中文文本是连续的字串,词语之间没有明显分隔符,词语的边界难以确定;此外,由于汉语一直没有一个统一的构词标准,故造成中文的分词歧义繁多.如何提高中文分词精度,解决分词歧义问题和未登录词的识别问题,成为广大学者研究的热点.
目前,中文分词方法大体分为三类方向:基于语义理解、基于词典,以及基于统计的分词方法.
基于语义理解的分词方法指依据待切分文本的句法、语义信息,模仿人的阅读理解方式,从而对文本进行切分[6].该方法不仅需要很好的汉语分词词典,还需要融入语义和句法的知识.但由于汉语语义规则的复杂性和笼统性,使得将各种语义和句法信息转成计算机可直接读取的形式较为困难.
基于词典的分词方法指通过汉语分词词典与切分规则来对中文字符串进行切分,该过程也被称为机械匹配分词.根据分词时对中文字符串的扫描方向以及词典匹配时所选的词长大小,基于词典的分词方法可分为正向匹配法、逆向匹配法、双向匹配法、最大匹配法以及最小匹配法.但该方法的有效性依赖于所使用词典覆盖的词汇量,且当汉语语义存在歧义时,正向与逆向匹配法的切分结果将存在差异,影响分词的效果.目前,一些学者针对最大匹配法提出改进.莫建文等[7]提出一种结合双字哈希结构和改进的正向最大匹配法的中文分词方法,提高了分词速度以及分词精度.熊志斌等[8]提出一种改进Trie树结构对词典进行改进,优化正向最大匹配法,提高了分词速度.陈之彦等[9]提出一种新的词典构造方法,以要开始进行匹配的字作为索引项,利用单字索引表得到与该字相关的词语开始位置,并设计了相应的双向最大匹配算法.麦范金等[10]提出一种结合最大匹配与HMM的分词模型,利用隐马尔可夫模型对正向和逆向最大匹配方法的分词结果进行消歧,得到较为准确的分词结果.杨贵军等[11]提出一种基于最大匹配算法的似然导向中文分词方法,将训练语料的统计信息与最大匹配分词方法相结合,并基于最大似然原理确定最优的分词模式,从而提高分词准确率.
基于统计的分词方法的主要思想是通过统计相邻汉字在语料训练集中出现的频率,来判断相邻汉字或相邻词是否能够组合成新的词.近年来,基于统计的分词算法逐渐成为自然语言处理的主流方法,分词中常用的统计模型有隐马尔可夫模型、最大熵模型、条件随机场模型等.张梅山等[12]通过将词典信息以特征的方式融入到条件随机场模型,实现领域自适应性.周祺[13]结合条件随机场模型识别新词的优势、t-测试和双向最大匹配法歧义消除及切分速度的优势,改进了条件随机场算法的解码方式,并提出一种基于哈希算法的词典组织方法.刘善峰等[14]提出一种改进的HMM分词方法,将邻近的两个字作为观察单元来代替传统的单字作为观察单元,通过加宽处理,结合词位信息,较好地解决了由于HMM算法的独立性问题而导致分词准确率不高的问题.周晓辉[15]提出一种基于HMM的法律命名实体识别模型,通过串联多个HMM模型,先使用N-gram模型进行分词,以低层HMM模型的输出作为高层HMM模型的输入,从浅至深层次地对文本进行实体识别.这些方法以大量语料库作为分词的基础,能有效利用训练语料的信息,具有较好的歧义处理能力.
以上方法对中文分词研究的发展有着重要贡献,然而在实际的应用中,汉语切分歧义和未登录词识别仍然是提高分词精度的主要困难[16-17].鉴于此,为减少切分歧义,提高分词准确率,本文主要针对汉语歧义的问题,综合基于词典的分词方法和基于统计的分词方法的优势,提出一种基于词性标注和分词消歧的中文分词方法.该方法首先基于正向和逆向最大匹配法及隐马尔可夫模型对中文文本进行初次分词,并利用Viterbi算法对初步的三种分词结果进行词性标注,然后基于词信息和词性信息,对三种分词结果进行对比消歧,最后得到较为准确的分词结果.
1 最大匹配法
最大匹配法是指以词典为依据,设置最长单词字数作为第一次取字数量,切分出单字串并同词典进行对比.最大匹配算法主要包括正向最大匹配法(Maximum Matching Method,FMM法)和逆向最大匹配法(Reverse Maximum Matching Method,RMM法),分词过程中一般采用减字的方式进行匹配.FMM法的分词过程如下:
假设待切分句子为O,其长度为n,设置最大词长为Max_len.
(1)取Max_len和n中的较小值,设为L.
(2)从O的开头第一个字往右截取L个字作为待匹配字符串W.
(3)W与词典进行匹配,若匹配成功,则把W从O中切分出来,O剩余的部分作为新的O,重复前面步骤;若匹配不成功,则从O的开头第一个字往右截取L-1个字作为待匹配字符串W,重复第(3)步,直到W匹配成功或W减至一个字为止.若W只剩下一个字,则从S中切分出W,剩余的部分作为新的O,重复三个步骤,直到O被完全切分.由于汉字具有重要信息后置的特征,RMM分词的准确率要比FMM分词的稍好,根据相关研究表明,FMM分词与RMM分词的错误切分率分别为1/169、1/245[18].这两种方法原理简单,易于实现,但对于存在切分歧义的语句,这两种方法往往得到不同的切分结果.
2 基于隐马尔可夫模型的中文分词与词性标注
隐马尔可夫模型[19]是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程.隐马尔可夫模型需要大量的训练语料来达到较高的标注准确率,常用于随机序列数据的统计模型.隐马尔可夫模型的基本表达为μ=(Q,O,A,B,π),其中Q={q1,…,qn}为所有状态的集合,O={O1,…,Om}为所有观测序列的集合,分别是状态转移概率矩阵、观测概率矩阵和初始状态概率向量,其中ti为i时刻随机过程所处的状态.
A=[aij]n×n=[P(tk+1=qj|tk=qi)]n×n=
(1)
B=[bj(Ok)]n×m=[P(Ok│ti=qj)]n×m=
(2)
(3)
在中文分词中,给定待切分字符串O,状态集合则为{B,M,E,S},其中,B表示词首,M表示词中间,E表示词尾,S表示单字成词.字符串中所有的字串,包括标点符号组成的集合称为观测状态集合.而在词性标注中,给定待标注的文本O=O1O2…Om,状态集合为词性集{q1,q2,…,qn∈G},观测状态集则是文本中所有切分好的词O1、O2、…Om.要计算状态转移概率矩阵A以及观测概率矩阵B,首先需要对语料库进行统计.状态t出现的概率为
(4)
由马尔可夫性可得,
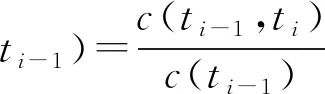
(5)
但鉴于分词系统的训练语料集的局限性,比如训练语料不够全面、涉及领域不够广泛,或语料年限较为久远,导致一些本该出现的语料没有出现或一些本该大量出现的语料出现的次数却很少,从而造成语料信息不全的问题.由于训练样本不足所导致估计不可靠的问题即数据稀疏(Data sparseness)问题.在自然语言处理中,由于语料有限,无论怎样扩大训练样本,都不可能保证所有的词都能出现,数据稀疏问题总是存在,可采用数据平滑技术,将训练语料的概率值进行折扣,并将该折扣值重新分布给零概率语料词,可以保证每个语料词的概率均大于零,并且可以使得模型参数概率分布趋向更加均匀[20].常见的数据平滑法有加法平滑(Additive smoothing)[21]、Good-Turing平滑[22]、Katz 平滑技术[23]、线性差值平滑法(Linear interpolation smoothing)[24]等.
本文采用的平滑法在基于Add-δ平滑技术[25]的基础上稍作调整,对模型中本该出现但没有出现事件的出现次数上添加δ,并统计总添加次数V,其中δ=0.5,即对于零概率事件Ok-1=ti,Ok=tj:
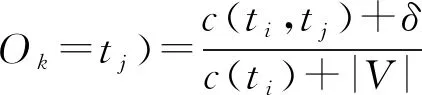
(6)
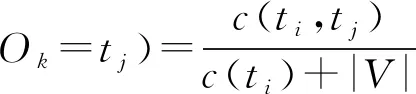
(7)
给定观测序列O=O1O2…Om和模型λ=(A,B,π),如何利用隐马尔可夫模型计算出该观测序列最优的状态序列,是HMM中的解码问题[26].
Viterbi算法[27]通过动态规划求得概率最大路径(最优路径),解决HMM模型的解码问题.该算法从第i=1个观测开始,递推地计算在第i个观测状态为t的各条部分路径的最大概率,直到第m个观测状态为t的各条路径的最大概率.给定观测O=O1O2…Om与隐马尔可夫模型μ=(Q,O,A,B,π):
(1)第1个观测处于状态t的概率为
δ1(t)=πtbt(O1),i=1,2,…,n
(8)
(2)第i个观测处于状态t的概率为
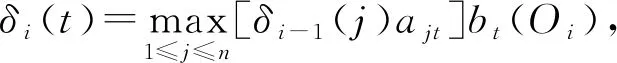
(9)
HMM到达第i个状态ti=t的最大概率路径(t1,t2,…,ti=t)的前一个状态ti-1为
(10)
(3)对于观测Om的状态tm,最优的状态为
(11)
(12)
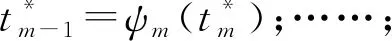
(13)
3 切分歧义
在中文分词中,若一个待切分的中文语句中存在多种切分结果,则表明该语句存在切分歧义[28].常见的切分歧义类型有组合型切分歧义以及交集型切分歧义.组合型切分歧义指中文字串“AB”即可切分成“A|B”,亦可作为整体而不切分,如中文字串“墙面会不会太平了”中的“太平”即为组合型歧义字段,既可切分成“太|平”,也可以不作切分;交集型切分歧义指中文字串‘ABC’即可切分为‘AB|C’又可切分成‘A|BC’,如中文字串“出现在”,正向最大匹配和HMM分词的切分结果为“出现|在”,而逆向最大匹配的切分结果则为“出|现在”.
可见,由于切分歧义的存在,正向、逆向最大匹配法以及HMM分词三种分词的结果往往会存在不同之处,本文旨在找出三种分词结果的歧义之处,并对歧义部分进行消歧,从而提高分词的精度.
4 分词消歧模型
4.1 文本特征表示
设待切分中文文本为O,已知语料库C共有M个词,词性集G共有n种词性,表示为q1,q2,…,qn∈G.假设对一段文本O进行分词的结果为O=O1O2…Om,共分成m个词,需要对这段文本标注词性:T=t1t2…tm,其中,词O1的词性为t1,词Om的词性为tm.
4.2 评估函数
定义count(q)为词性q∈G在语料库C中出现的次数,count(o)为在C中词o出现的次数,count(ti-1,ti)为有序连续词性ti-1,ti在C中出现的次数,count(t,o)为在C中词o的词性为t出现的次数.
(14)
(15)
对于词o,以极大似然估计来评估词o的成词可能性:
(16)
funo,t=P(ti|ti-1)×P(oi)×P(oi|ti)
(17)
4.3 消歧步骤
基于分词消歧与词性标注的中文分词方法主要流程如图1所示.
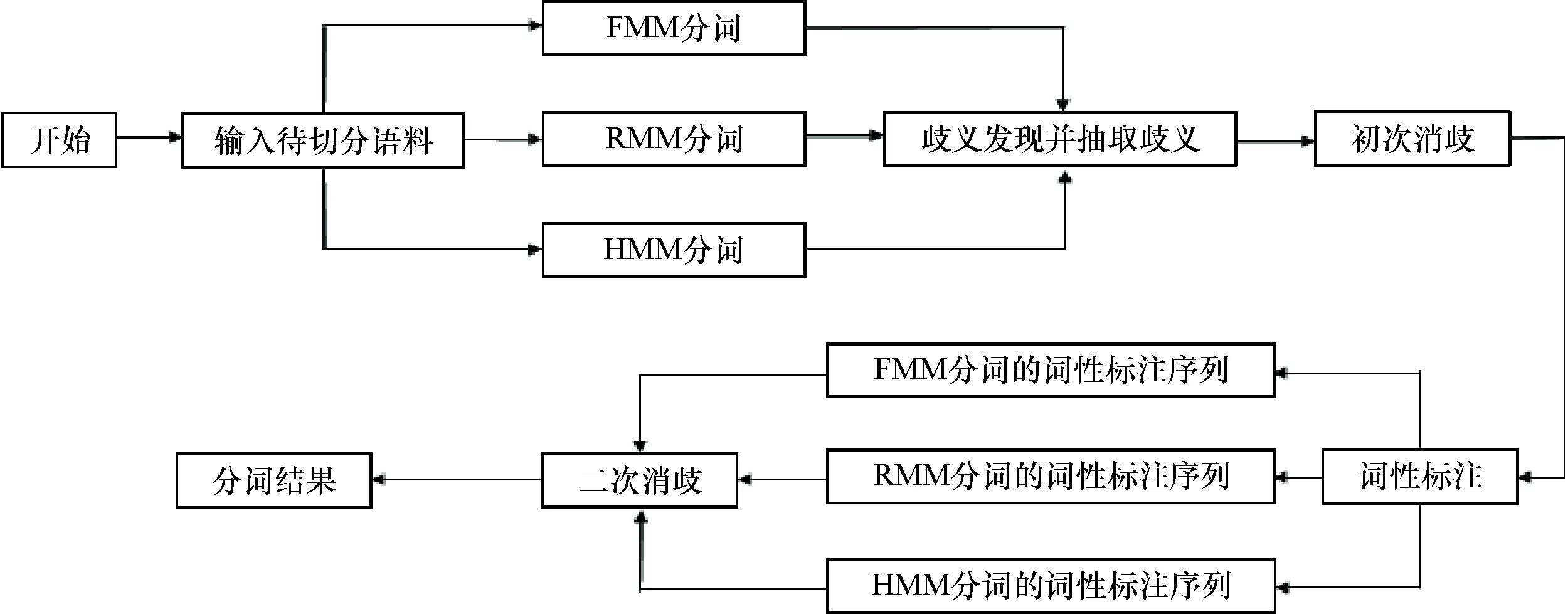
图1 分词流程
(1)首先在输入端输入待切分语料S,并得到基于正向最大匹配法、逆向最大匹配法、HMM分词的结果.对于待切分语句O∈S,正向最大匹配法、逆向最大匹配法以及HMM分词三种方法的切分结果分别记为O1,O2,O3.
(2)通过比较三种分词结果,得到三种分词结果中不全相同的部分,即作为歧义部分.歧义部分可分为两种情况:第一种情况是O1≠O2=O3∩O1=O2≠O3,即三种分词结果中有任意两种结果是相同的,并且不与第三种情况相同;第二种情况是O1≠O2≠O3,即三种分词结果中两两皆不相同.
(3)对初步分词歧义部分中的第一种情况进行初次消歧.鉴于本次实验初步分词结果中,正向最大匹配法的正确率高于逆向最大匹配法以及HMM分词的正确率:如果O1与O2相同,无论O1与O3是否相同,皆以O1作为最终切分;如果O2与O3相同且与O1不同,并且PML(O2)>PML(O1),则以O2作为最终切分;否则,依然以O1作为最终切分.
(4)对歧义部分的第二种情况进行二次消歧.首先,利用HMM分别对三种分词结果进行词性标注,并筛选得到分词结果中两两皆不相同的歧义部分;计算得到使得评估函数funOi,T最大化的切分方法,并以该切分作为最终切分,即最优切分为
(18)
5 实验与分析
5.1 语料训练
本文中的训练集和测试集来自哈尔滨工业大学提供的中文树库语料.在进行实验之前,由于最大匹配法的需要,首先建立一个分词词典.本文所用的分词词典共有10万个词,不包括标点符号、字母和数字.该词典包含了现代汉语词典中的所有语料.词性标注所用的训练语料是中文树库语料中的训练集,共783 294个字.
5.2 实验结果
树库语料中的测试语料总共31 622字,对本文所提出的方法进行测试.
评价中文分词的指标主要有:准确率(Precision)、召回率(Recall)、F测度(F-measure)[27],各指标的计算公式如下:

(19)

(20)
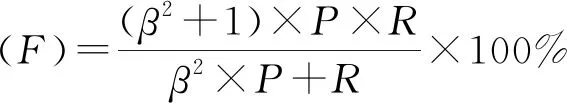
(21)
其中,取β=1,此时F值又称为F1值.
本次实验中,将测试集中出现切分歧义的语句作为该测试集的歧义集.为了更好地展示本文提出的分词方法的有效性,在测试集进行测试的同时,也对歧义集的测试结果进行比较分析,见表1.
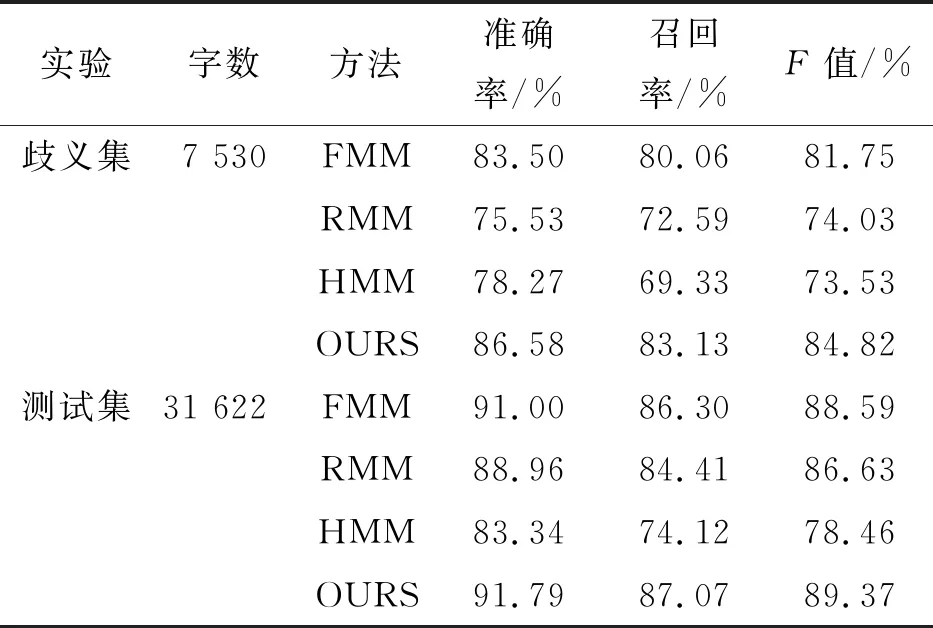
表1 实验结果与评价
将本文所用方法的最终分词效果与正向最大匹配法(FMM)、逆向最大匹配法(RMM)、隐马尔可夫模型(HMM)的最终分词效果进行对比(表1).从表1可以看出,与其他常见的分词方法相比较,本文提出的方法分词效果更好.在歧义集中,分别相较于FMM、RMM、HMM,本文提出的方法其准确率提高了3.08%、11.05%、8.31%,召回率提高了3.07%、10.54%、13.80%,F测度值提高了3.07%、10.79%、11.29%;在测试集中,相比于其他方法,本文的方法在分词效果上也有所提高.本次实验是在三种常用分词方法的基础上,结合隐马尔可夫模型标注词性,利用词信息与词性信息对切分歧义集进行消歧,选出最优切分,该方法具备了机械匹配分词的速度以及统计分词的精度,对解决中文分词中的歧义问题具有较好的效果,能够有效地消除分词结果中的交集型歧义和组合型歧义,具有一定的实用性.
与正向、逆向最大匹配法、隐马尔可夫模型相对比,本文的分词方法虽然在准确率等指标上有所提高,但仍然没有达到精确分词的效果.原因如下:①未登录词识别的问题对本文的实验准确率影响较大.本文提出的分词方法并未对解决未登录词识别问题产生效果,无法识别未登录词不仅会出现错误切分或者遗漏切分,使得切分效果大打折扣,也会影响对未登录词词性的标注,严重影响词性标注的精度;②汉语分词的歧义问题尚未得到完全解决.尽管本文的分词方法能够通过识别三种分词结果中的歧义之处,从而解决部分切分歧义问题,但并未考虑三种分词结果相同部分中存在切分歧义的可能性,对三种切分皆不正确的情况也未作处理,从而直接影响分词的效果.
6 结 语
机械分词速度快、原理简单且容易实现,但无法识别中文分词中的切分歧义以及消减歧义问题[29].统计分词能有效识别分词歧义,但需要大量的训练语料,训练时间较长.本文提出一种基于分词消歧与词性标注的中文分词方法,首先识别出正向、逆向最大匹配以及隐马尔可夫模型分词结果中的歧义集,通过隐马尔可夫模型对分词结果进行词性标注,并通过定义的评估函数对歧义集进行消歧,最终得出较为准确的分词结果.从测试结果可以看出,该方法能够有效利用语料库中的词信息以及词性信息,综合了机械匹配分词与统计分词的优点,能较好地解决分词中的歧义问题,提高了分词效果.但该方法仍存在不足之处,无法识别未登录词,在识别分词歧义方面也不够全面.在下一步的工作中,将考虑如何有效地识别切分结果中的未登录词,不断更新词库,以解决中文分词的未登录词问题;进一步改进切分歧义识别方法,更全面地识别除正向、逆向最大匹配法、隐马尔可夫模型分词结果歧义集以外的可能存在切分歧义之处,提高分词精度.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
中国外汇(2019年12期)2019-10-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
疯狂英语·新悦读(2017年2期)2017-04-08
电信科学(2016年9期)2016-06-15
校园英语·下旬(2016年3期)2016-04-18
中国民航大学学报(2015年3期)2015-03-01
