
一种改进的基于峭度指标的FastICA算法*
2019-05-27 06:08:28孟令博耿修瑞杨炜暾
中国科学院大学学报 2019年3期
孟令博,耿修瑞,杨炜暾
(中国科学院电子学研究所 中国科学院空间信息处理与应用系统技术重点实验室, 北京100190;中国科学院大学,北京 100049)
多/高光谱遥感图像通常包含多个光谱波段[1],可提供关于地物的丰富的光谱信息,但同时也会造成一定的数据冗余及数据处理过程的计算负担[2]。因此,在很多情况下需要引入数据降维或者特征提取的手段对数据进行预处理[3]。主成分分析[4-5](principal component analysis,PCA)是一种最常用的特征提取方法,并常被应用于遥感图像的数据降维。PCA以图像方差为指标进行特征提取,而没有考虑噪声在光谱特征空间的分布,因此降维结果易受具有较大方差的噪声影响。Green等[6]提出基于图像信噪比的特征提取方法,即最大噪声成分(maximum noise fraction,MNF)算法,以解决这一问题。Lee等[7]提出噪声调整的主成分分析方法(NAPC),也能够减少噪声对特征提取结果的影响,它基本与MNF等价。此外,还有考虑了图像空间特征的最大/最小自相关因子分析算法,它基于图像数据的自相关性而不是方差,因此不受向量幅值的影响。
以上这些特征提取算法都是基于数据的二阶统计特性,它一般假设图像数据服从高斯分布。但实际的遥感图像数据往往并不满足这一条件,所以基于二阶统计特性的特征提取方法很多情况下并不能有效反映数据中的感兴趣结构。比如,当感兴趣目标为小目标时,基于二阶统计特性的特征提取方法往往将其作为不重要的信息舍弃。而基于高阶统计特性的特征提取方法就能很好地解决这类问题[8-9]。高阶统计特性在遥感图像处理中有很多应用,例如目标自动识别、异常检测、光谱解混、特征提取等[10-12]。基于高阶统计特性的特征提取方法绝大多数是基于独立成分分析(independent component analysis,ICA)的方法及其改进算法[13-15],其中FastICA算法以其快速的收敛速度和较高的计算效率得到广泛应用。FastICA算法有4种优化指标,其中基于峭度指标的FastICA算法具有明确的物理意义,且相比基于偏度指标的FastICA算法有更好的收敛性能和更快的收敛速度,因此应用最为广泛[16-20]。但是,在求解各个独立成分时每一步迭代过程均需所有像元的参与,所以当图像尺寸较大时往往计算量很大且耗时较长。然而,遥感图像尺寸一般较大,此时FastICA算法的计算优势大打折扣。
因此,本文提出一种基于峭度指标的FastICA算法的等价算法。通过引入协峭度张量,将FastICA的固定点迭代问题转化为代数形式的张量计算,在每次迭代中避免所有像元的参与,因而大大降低计算复杂度。
1 基于峭度指标的FastICA算法
ICA算法是一种从盲源分离技术发展而来的算法[15],它能够将多维观测信号分解为尽量相互统计独立的独立分量,分离出的分量是源信号的一种近似,因而在图像处理、语音识别、远程通信等领域得到广泛应用。
为了更为方便和简洁地说明ICA,假设观测信号是源信号的线性变换。假设观测信号为
(1)
它由相互独立且均值为零的源信号
(2)
(3)
ICA可以描述为在源信号和混合矩阵都未知的情况下,根据观测矩阵X找到一个分离矩阵W能够尽可能地分离出源信号S。FastICA是ICA算法中最为流行,应用最广泛的一种算法。相比于其他算法,FastICA算法计算效率高,运算量小,相对容易实现。
对于零均值的随机变量x,其峭度可以表示为
kurt(x)=E{x4}-3(E{x2})2,
(4)
显然,对于高斯信号,它的峭度值为0。
假设观测信号X是源信号S线性混合而成,经过向量w可以分离出一个源信号分量wTX。一般情况下,在处理观测信号之前会进行数据白化,因此,不妨假设,观测信号X的均值向量为0,协方差矩阵为单位阵,令y=wTX,则它的峭度计算可以进行如下简化[20]
kurt(y)=E{(wTX)4}-3(E{(wTX)2})2
=E{(wTX)4}-3(wTXXTw)2
=E{(wTX)4}-3‖w‖4,
(5)
式中:w满足约束条件‖w‖=1,基于峭度指标的FastICA算法的目标函数可以最终表示为
J(w)=E{(wTX)4}-3‖w‖4+F(‖w‖2),
(6)
式中:F是关于约束条件的惩罚函数。固定点算法求解式(6)可以得到迭代公式
(7)
式中:“⊙”符号代表矩阵点乘,表示2个矩阵对应位置的每个元素相乘。下同。
综合上文,基于峭度指标的FastICA算法步骤表示如下
1)首先随机生成一个模为1的向量w(0),并令k=0;
2)将其代入迭代公式
w(k+1)=

4)如果|(w(k+1))Tw(k)|的值不足够接近1,则令k=k+1,跳到步骤2);否则输出向量w(k+1)。
上述过程得到的向量w(k+1)为分离矩阵W的一个列向量,(w(k+1))TX可以分离出一个源信号的近似,即一个独立分量。为了分离出p个独立分量,需要将上述步骤运行p次。同时为保证每次分离出的独立分量是不同的,要对w(k+1)进行正交投影,使其与已求得的其他向量均正交,可通过下式进行正交化
(8)
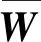
上述算法具有较快的收敛速度,一般情况下,它在10~100次迭代甚至几次迭代内就会得到最优解。但它的运算量依然很大,而且循环迭代求解过程需要全部数据的参与,因此下面提出一种改进的FastICA算法以减少运算量,新算法引入协峭度张量的概念使得循环迭代过程中不需要所有像元的参与。
2 改进的FastICA算法
改进的FastICA算法是对原始FastICA算法的迭代公式的改进,通过引入协峭度张量,在降低算法计算复杂度的同时避免所有像元参与算法的迭代过程。下面,首先介绍协峭度张量的概念。
2.1 协峭度张量的计算
(9)
式中:“∘”代表外积,xi∘xi∘xi∘xi可以生成一个p维的4阶张量。根据式(9)可知,
(10)
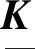
2.2 改进的FastICA算法原理
定理2.1对于任意向量w=[w1,…,wp]T,有下面的结论成立:
X[(XTw)⊙(XTw)⊙(XTw)]/n
(11)
则式(7)的迭代公式变为
(12)
式中:×1×2×3代表模乘,下同。
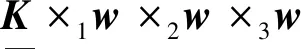

改进的FastICA算法伪代码1)首先,计算图像的协峭度张量K=1n∑ni=1xixixixi; 2)令P=I,P为正交投影矩阵;3)for i=1∶p,p为需要提取的独立成分数;4)令k=0,并生成随机单位向量w(k)i;5)将w(k)i进行正交投影w(k)i=Pw(k)i;6)将w(k)i进行迭代更新w(k+1)i=K×1w(k)i×2w(k)i×3w(k)i-3w(k)iw(k+1)i=w(k+1)i‖w(k+1)i‖ìîíïïïï; 7)k=k+1;8)如果满足停止条件,则输出w(k+1)i,否则跳到5);9)令P=I-WWT,W为已求得的向量wi的集合W=[w1,…,wi];10)end;Y=WTX即为特征提取后的结果。
2.3 算法复杂度分析
比较基于峭度指标的FastICA算法及其改进算法的迭代公式可知,改进的FastICA算法的迭代公式更加简洁,且不需要全部像元点的参与,因此会节省更多的计算时间。为了更加准确地比较这两种算法,需要对它们进行详细的计算复杂度分析。
3 基于模拟数据的实验分析
原始的FastICA算法和改进后的FastICA算法虽然都使用固定点迭代算法,但是二者有本质上的不同。原始的FastICA算法在迭代过程中需要全部像元的参与,改进后的FastICA算法则依赖预先计算好的协峭度张量。为了更加客观地比较两种算法,FastICA算法和改进的FastICA算法使用相同的初始向量。所有的仿真实验均在同一电脑上使用相同的操作系统完成。本文中的算法全部使用MATLAB7.1软件实现。
3.1 计算时间和数据维数之间的关系
在本节中,设计一组实验考察数据的维数对两种算法计算时间的影响。首先用MATLAB软件中的rand函数产生10组模拟数据,每组数据尺寸为800×800,维数从2增加到15。考虑到初始值的影响,对两种算法设置相同的初始值,各运行100次取平均计算时间进行比较。图1给出两种算法的计算时间。从图中可以看出随着数据维数的增加,改进的FastICA需要的计算时间急剧增加,当数据维数超过11时,改进的FastICA算法反而需要更多的计算时间。这也和上文分析的结果一致。图2给出计算协峭度张量的时间占总的计算时间的比重,可以看出随着数据维数的增加它所占的比重越来越大,甚至占用绝大部分的计算时间。因此,如果能够准确快速地估计数据的协峭度张量将极大地提高改进的FastICA算法的计算效率。
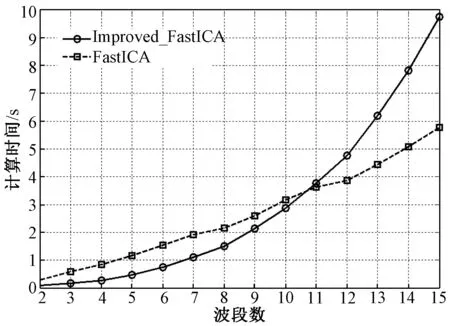
图1 原始FastICA算法和改进的FastICA算法的计算时间随波段数变化的趋势Fig.1 Variations in the computing time of the original andimproved FastICA algorithms with the band number
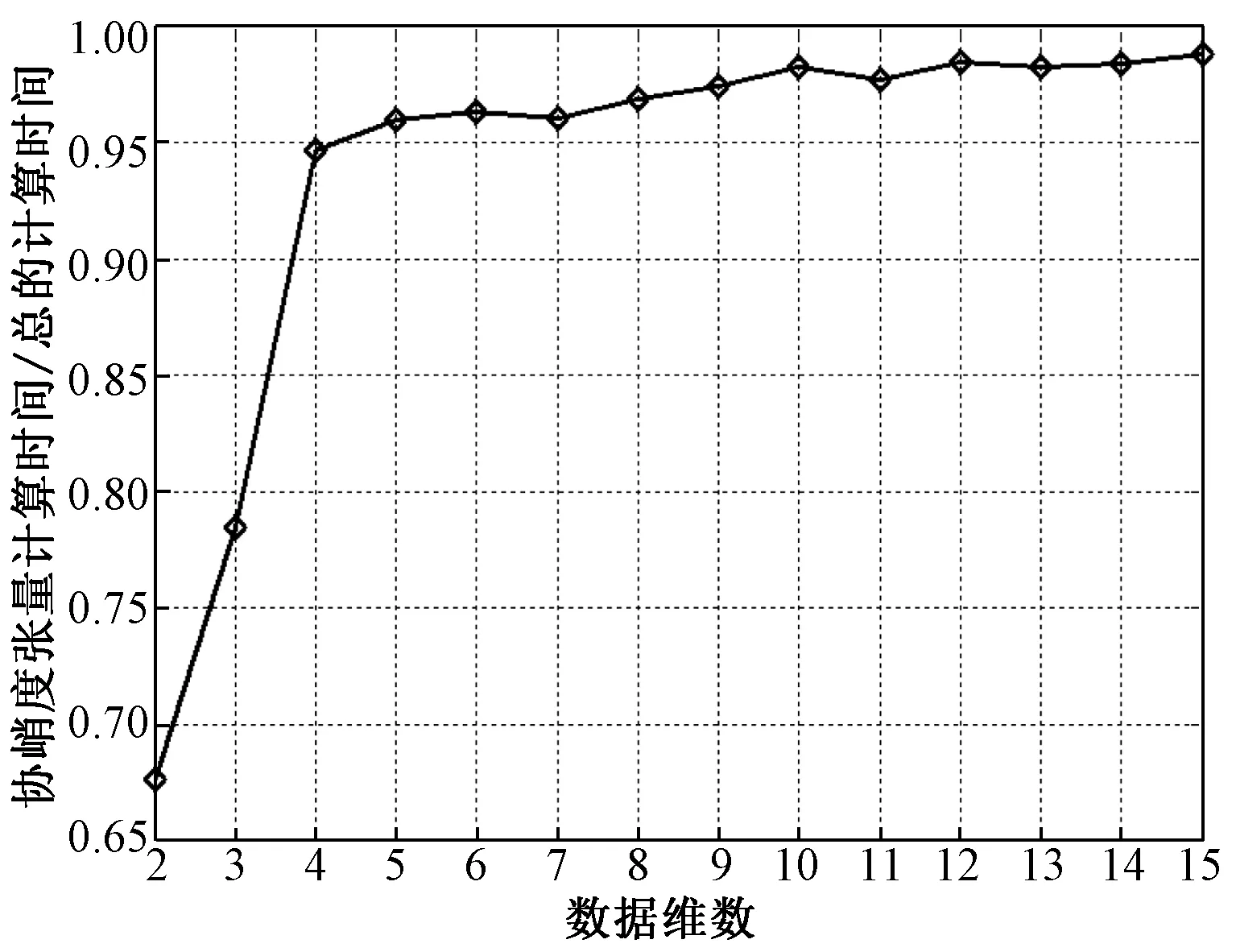
图2 不同数据维数条件下计算协峭度张量的时间占总的计算时间的比重Fig.2 Ratio of the calculation time for cokurtosistensor to the total calculation time
3.2 计算时间和像元数目之间的关系
为考察像元总的数目对两种算法的影响,生成一组维数为6,像元数目从100×100到900×900的随机模拟数据。同样地,对两种算法设置相同的初始值,统计其所需要的计算时间(100次平均),如图3所示。从图中可以看出随着像元数目的增多,两种算法所需的计算时间都在逐渐增加,但改进后的FastICA算法增加得更慢,且它需要的计算时间始终少于原始FastICA算法需要的计算时间。

图3 原始FastICA算法和改进的FastICA算法在不同像元数目条件下的计算时间比较Fig.3 Comparison of the computing time between the originalFastICA and improved FastICA at different pixel numbers
4 基于真实数据的实验分析
本节使用真实的多光谱图像数据比较FastICA算法及改进FastICA算法的计算效率。该多光谱数据为Landsat5 TM反射率数据,获取时间为2001年6月30日,该数据为江西北部的鄱阳湖部分区域数据,如图4所示。该图像分辨率为30 m,尺寸为800×800,共包含6个波段,分别为485,569,660,840,1 676和2 223 nm。

图4 鄱阳湖第一波段图像Fig.4 The first-band image of Poyang Lake

图5 两种FastICA算法提取结果Fig.5 The feature extraction results of theoriginal FastICA and improved FastICA
将原始的基于峭度指标的FastICA算法和改进后的FastICA算法应用于该多光谱图像,将特征提取结果进行详细对比分析发现,原始的基于峭度指标的FastICA算法和改进后的FastICA算法提取结果一致,特征提取结果如图5所示。同时基于峭度指标的FastICA算法需要的时间为8.529 2 s,而改进后的FastICA算法仅仅需要2.275 5 s。因此,改进后的FastICA算法在保持原有结果不变的同时计算速度远快于原始的FastICA算法。
5 总结
本文提出一种改进的FastICA算法以降低FastICA的计算复杂度,它是原始FasICA算法的代数等价算法,能够产生与之完全相同的特征提取结果。改进的FastICA算法引入协峭度张量的概念,在迭代过程中不需要全部像元的参与,而仅仅需要协峭度张量的参与。当数据维数不是特别高时,改进的FastICA算法相比于原始的FastICA算法计算复杂度更低,能节省更多的计算时间。但当数据维数很高时,改进的FastICA算法实际上并不能节省计算时间。因此该方法更加适用于多光谱图像的特征提取。改进的FastICA算法中计算协峭度张量花费绝大部分时间,因此寻求一种快速计算协峭度张量的方法可以极大地提高算法的计算效率,缩短计算时间。
附录:定理2.1的证明
首先计算X[(XTw)⊙(XTw)⊙(XTw)]/n.
令
(A1)
式(A1)中第k个元素表示为
(A2)
则
(A3)
即
X[(XTw)⊙(XTw)⊙(XTw)]/n=
(A4)
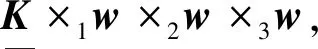
为超对称张量.
(A5)
则S的任一元素为
(A6)

(A7)
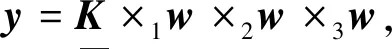
(A8)

(A9)
那么,
(A10)
猜你喜欢
机床与液压(2023年1期)2023-02-03 10:14:18
数学物理学报(2022年4期)2022-08-22 04:06:44
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
数学物理学报(2020年3期)2020-07-27 01:19:56
铁道机车车辆(2020年2期)2020-05-20 02:15:40
电子世界(2018年12期)2018-07-04 06:34:38
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
数学物理学报(2016年5期)2016-08-24 07:38:40
数学物理学报(2016年6期)2016-04-16 04:40:58
